项目源码及资料
项目介绍

1、从豆瓣网爬取Top10的电影数据
爬取网址: https://movie.douban.com/top250
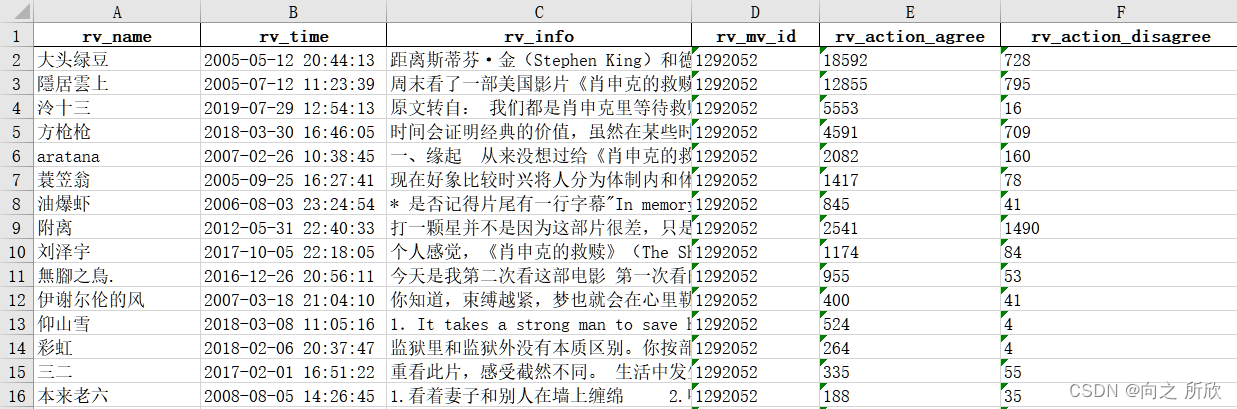
1.1 爬取Top10的影视信息
mv_data = []
i = 0
for x in soup.select('.item'):i += 1mv_name = re.search('>([^<]+)<', str(x.select('.info > .hd > a > .title'))).group(1)# 电影网址mv_href = re.search('href="(.*)"', str(x.select('.info > .hd > a'))).group(1)# 电影详细信息mv_info = x.select('.info > .bd > p')# 电影部分演员表mv_actors = re.search('>([^<]+)<', str(mv_info)).group(1).strip().replace('\xa0', '')# 电影发布时间、发布国家、发布类型mv_type = re.search('<br/>([^<]+)</p>', str(mv_info)).group(1).strip().replace('\xa0', '')# 电影的简评mv_review = re.search('>([^<]+)<', str(x.select('.info > .bd > p > .inq'))).group(1)# 电影评分mv_star = re.search('>([^<]+)<', str(x.select('.info > .bd > .star > .rating_num'))).group(1)# 电影的评价数mv_evaNum = re.search('([0-9]+)人评价', str(x.select('.info > .bd > .star'))).group(1)mv_data.append({'mv_id': mv_href.split('/')[-2:-1][0],'mv_rank': i,'mv_name': mv_name,'mv_href': mv_href,'mv_actors': mv_actors,'mv_type': mv_type,'mv_review': mv_review,'mv_star': mv_star,'mv_evaNum': mv_evaNum,})mv_data = pd.DataFrame(data=mv_data[:10])
mv_data.to_excel('./data/mv_info.xlsx')
print('[info] >> 豆瓣Top10影视信息已保存到当前目录下的./data/mv_info.xlsx')
[info] >> 豆瓣Top10影视信息已保存到当前目录下的./data/mv_info.xlsx
# 查看爬取结果
print(mv_data)
爬取结果如下:

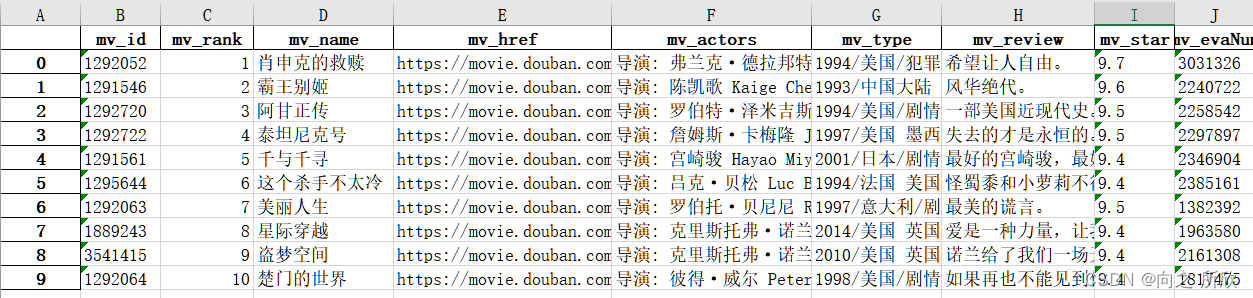
1.2 爬取每个电影的评论情况
'''匹配获取到 >内容< 格式里的内容
'''
def getText(s):# 如果不是str类型,先转为strif (type(s) != str):s = str(s).strip().replace('\n', '')text = re.search('>([^\\)]*)<', s)# 返回匹配的结果return text.group(1) if text != None else None'''爬取评论信息
'''
def getInfo(url: str, mv_id: int) -> pd.DataFrame:print('[INFO] >> 开始爬取 ' + url + ' 的评论')result = []# 获取网页响应的结果文件html = requests.get(url, headers=headers).text# 解析HTML网页内容soup = BeautifulSoup(html, features="lxml")for x in soup.select('.review-item'):# 评论的用户名rv_name = getText(x.select('.name'))# 评论的时间rv_time = getText(x.select('.main-meta'))# 评论的内容rv_info = getText(x.select('.review-short > .short-content')).split('(')[0].replace('<p class="spoiler-tip">这篇影评可能有剧透</p>', '').strip()# 评论的支持与反对rv_action_agree = getText(x.select('.main-bd > .action > .up > span')).strip()rv_action_disagree = getText(x.select('.main-bd > .action > .down > span')).strip()result.append({'rv_name': rv_name,'rv_time': rv_time,'rv_info': rv_info,'rv_mv_id': mv_id,'rv_action_agree': rv_action_agree,'rv_action_disagree': rv_action_disagree})# 数据预处理, 填补空值result = pd.DataFrame(data=result)result['rv_action_agree'] = result['rv_action_agree'].apply(lambda x: 0 if x == '' else x)result['rv_action_disagree'] = result['rv_action_disagree'].apply(lambda x: 0 if x == '' else x)return result'''获取电影的评分信息
'''
def getStar(url) -> list:result = {}# 获取网页响应的结果文件html = requests.get(url, headers=headers).text# 解析HTML网页内容soup = BeautifulSoup(html, features="lxml")for i in range(1, 6):star = soup.select('.droplist > .rating' + str(i))star = re.search('\(([0-9]+)\)', str(star)).group(1)result[i] = int(star)return result'''根据豆瓣电影ID爬取内容
'''
i = 0
def crawlerById(id, name) -> pd.DataFrame:global mv_stars, i# 记录时间startTime = time.time()# 基础网址base_url = 'https://movie.douban.com/subject/' + str(id) + '/reviews?'# 默认按热度排序(start = i * 20) "https://movie.douban.com/subject/1292052/reviews?start=0"url_by_hot = base_url + 'start='# 按星级排序 "https://movie.douban.com/subject/1292052/reviews?rating=5"# url_by_star = [url_by_hot + '?rating=' + str(i)+'?start=' for i in range(1, 6)]# url_by_star = [base_url + 'rating=' + str(j) for j in range(1, 6)] # 如果只是取前40页评论则用不上# 拼接待爬取的url,取前 40页评论(有问题:只能爬取一页的评论,已解决)urls = []for i in range(0, 801, 20): # 修改1:观察网站不同页数的网址可知,范围应为20*40+1,即801urls.append(url_by_hot + str(i))# for url in url_by_star: # 修改2:根据网站url结构,不需要插入星级评论url# urls.append(url)print('-' * 50 + 'BEGIN:' + str(i) + '-' * 50)print(f'[INFO] >> 正在爬取 id = {id}, 名称={name}, url={url_by_hot} 的影评... \n')mv_reviews = {}# 爬取评论mv_reviews['reviews'] = pd.concat([getInfo(url, id) for url in urls])# 爬取电影总评分情况mv_reviews['star'] = {}mv_reviews['star']['id'] = idmv_reviews['star']['name'] = namemv_reviews['star'].update(getStar(urls[0]))# 将评论的结果保存到本地save_path_reviews = './data/reviews-' + str(name) + '.xlsx'mv_reviews['reviews'].to_excel(save_path_reviews, index=False)print(f'[INFO] >> 爬取的评论结果保存到了当前文件夹的: {save_path_reviews}')# 将影评的评分记录到mv_starsmv_stars.append(mv_reviews['star'])print(f'[INFO] >> 为防止反爬虫机制启动,睡眠 1 s')time.sleep(1)endTime = time.time()print('-' * 35 + 'END:' + str(i) + ' 爬取完毕, 本次爬取耗时:' + f'{endTime - startTime:.3f}' + ' s' + '-' * 35)i += 1return mv_reviewsprint('=' * 50 + '【启动爬虫程序】' + '=' * 50)
startTime = time.time()# 读取电影信息
mv_data = pd.read_excel('./data/mv_info.xlsx')list_mv = []
# 爬取之前电影的评论信息
for (i, mv) in mv_data.iterrows():list_mv.append(crawlerById(mv.mv_id, mv.mv_name))# # 存储list_mv 有问题,存储信息不全
list_mv = pd.DataFrame(list_mv)
list_mv.to_csv('./data/list_mv.csv')
list_mv.to_json('./data/list_mv.json')# 将所有影视评论分布导出到excel
mv_stars = pd.DataFrame(data=mv_stars)
mv_stars.to_excel('./data/mv_stars.xlsx')
print(f'[INFO] >> 所有影评的评分情况已保存到本地的文件: ./mv_stars.xlsx中')endTime = time.time()
print('=' * 45 + '程序执行完毕,总耗时: ' + f'{endTime - startTime:.3f}' + ' s' + '=' * 45)
爬取过程:
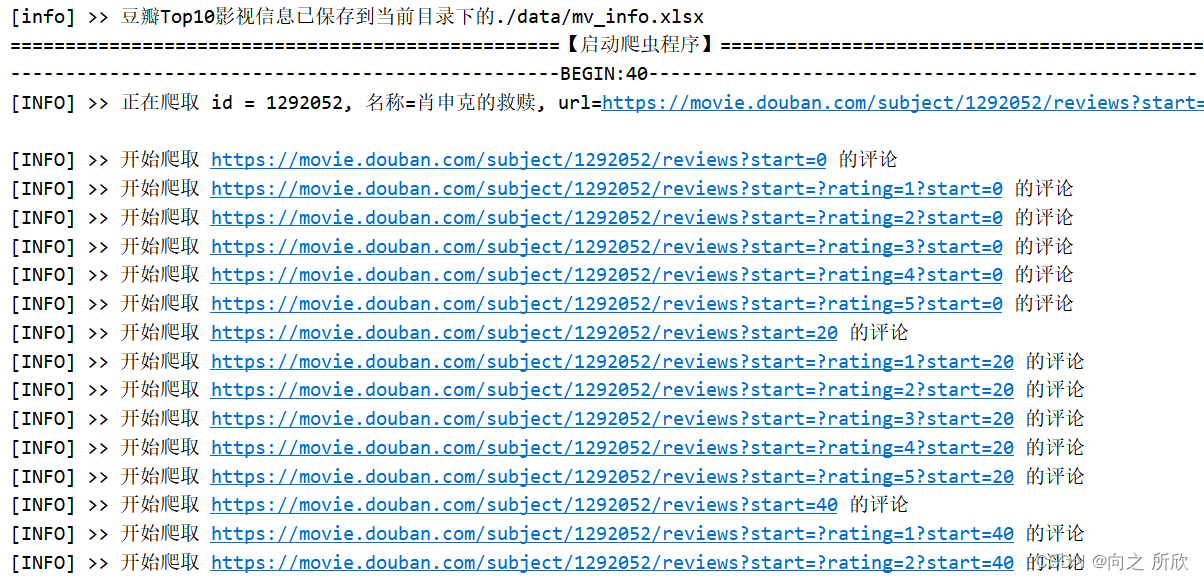

爬到的数据放到.lxml文件里:
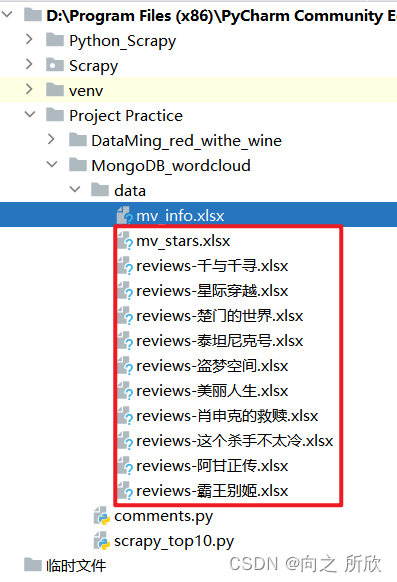
1.3 整理爬取的数据
# 将所有影视评论分布导出到excel
mv_stars = pd.DataFrame(data=mv_stars)
mv_stars.to_excel('./data/mv_stars.xlsx')
print(f'[INFO] >> 所有影评的评分情况已保存到本地的文件: ./mv_stars.xlsx中')
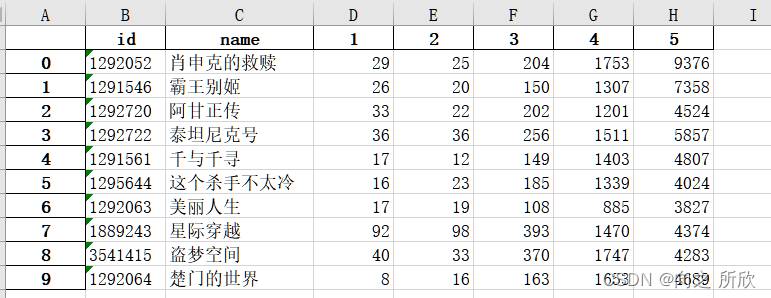
影视评分:
2、MongoDB 操作豆瓣影评数据集
2.1 创建 MongoDB 连接实例
client = MongoClient('localhost', 27017)db = client.mv
# 创建电影信息集合
ct_mv_info = db.dc_mv_info
# 创建影评集合
ct_mv_review = db.dc_mv_review# 查看创建结果
print(ct_mv_review)

2.2 向 MongoDB 集合插入文档
这里先将影视信息转化为dict字典格式
# 将影视信息转化为dict字典格式
dc_mv = []# 获取每一列的列名
mv_info_cols = mv_info.columns
for i in range(len(mv_info)):# 创建用于存储mv_info的字典dict_info = {}# 指定文档的_id为电影IDdict_info['_id'] = mv_info['mv_id'][i]# 循环遍历mv_info数据,存入dict_infofor col in mv_info_cols[2:]: # 因为第一列取了别名'_id',故不用再次遍历'mv_id'(原作者取了又取了'mv_id')dict_info[col] = mv_info[col][i]dc_mv.append(dict_info)
2.3 查看插入到MongoDB的数据
ct_mv_info.find_one()
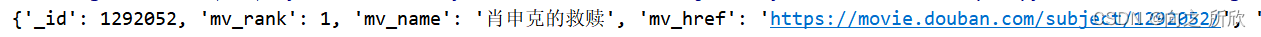
MongoDB中的数据:

2.4 同样的操作插入影评
先处理信息,将影评信息转化为可插入到MongoDB的dict字典
# 读取各 "电影.xlsx" 评论信息,顺序与 mv_info.xlsx 中的排名要保持一致,否则后续评论标号会不一致
mv_names = ['肖申克的救赎', '霸王别姬', '阿甘正传','泰坦尼克号', '千与千寻', '这个杀手不太冷','美丽人生', '星际穿越', '盗梦空间', '楚门的世界']def getAllReviews() -> list[list]:index = 0 # mv_info 中的索引reviews = [] # 用于所有电影的影评信息# # 创建数组,用于存储影评信息 (冗余语句)# mv_comments = pd.DataFrame()# 记录当前电影的所有影评信息for i in range(len(mv_names)):dc_reviews = [] # 用于存储每部电影的影评信息# 表示当前的评论 _id (标号)c_id = 0# 读取对应电影的评论信息save_path_reviews = './data/reviews-' + mv_names[i] + '.xlsx'mv_comments = pd.read_excel(save_path_reviews)print(mv_comments)# 获取列名rv_cols = mv_comments.columns# 遍历每个评论,将其汇总for j in range(len(mv_comments)):# 根据电影ID和当前评论序号定义_iddict_info = {'_id': str(mv_info['mv_id'][index]) + str(c_id)}c_id += 1# 拼接影评信息for col in rv_cols:dict_info[col] = mv_comments[col][j]dc_reviews.append(dict_info)index += 1 # 更换电影# 将每部电影的影评汇总信息添加到reviews中reviews.append(dc_reviews)return reviews
读取如下文件的内容:

文件内容:
2.5 插入影评信息到 MongoDB
# 插入影评信息到 MongoDB
ct_mv_reviews.delete_many({})
for rv in dc_reviews:# print(rv)rv = pd.DataFrame(rv).to_dict("records")ct_mv_reviews.insert_many(rv) # 类型转换
# 查看插入结果
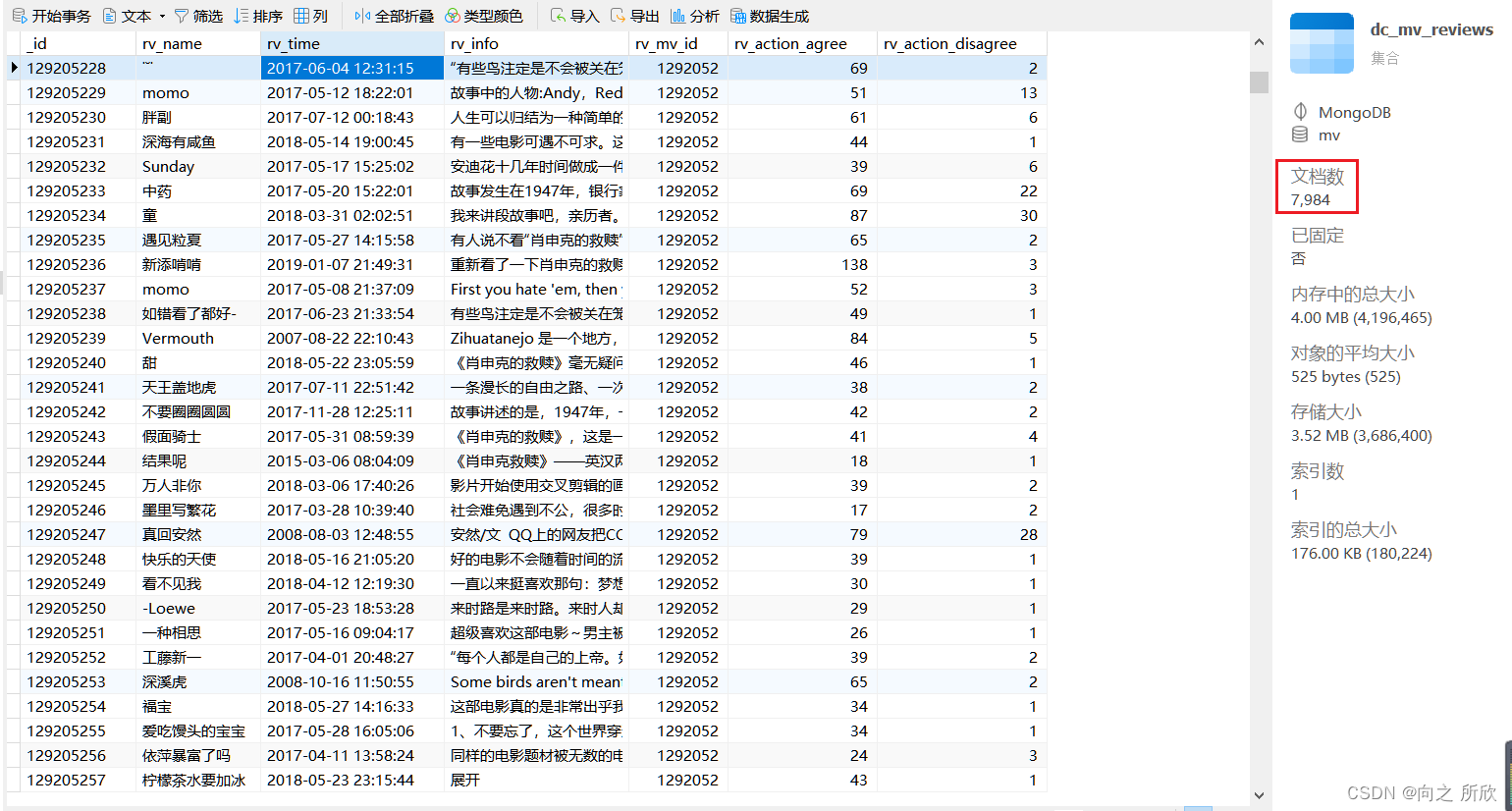
print(ct_mv_reviews.find_one())

MongoDB中的数据:
3、MongoDB 实战
3.1 计算豆瓣 Top 10 影视的平均评分
# 定义聚合管道
pipeline = [{"$group": {"_id": None,"count": {"$sum": 1},"mv_star_total": {"$sum": {"$toDouble": "$mv_star"}}}},{"$project": {"_id": 0,"count": 1,"mv_star_total": 1,"mv_star_avg": {"$divide": ["$mv_star_total", "$count"]}}},{"$out": "mv_star_avg"}
]# 执行聚合管道
ct_mv_infos.aggregate(pipeline)# 输出结果
ct_mv_star_avg = db.mv_star_avg
for x in ct_mv_star_avg.find():print(x)
根据结果得出,10部电影里的平均评分为9.48分

注:在PyMongo3.5中删除了
Collection.map_reduce和Collection.inline map_reduce,所以这里使用聚合管道实现map_reduce所实现的功能。MongoDB的聚合管道(Aggregation Pipeline)是一种用于处理和转换数据的强大框架,它类似于UNIX风格的管道操作。通过将多个数据处理阶段串联在一起,聚合管道可以执行复杂的数据聚合任务。每个阶段都执行一个操作,如过滤、投影、分组、排序和重新整形文档等,最终的输出会被传递给下一个阶段。

3.2 统计Top10电影影评的[赞同 / 不赞同]的平均比率
# 定义聚合管道用于处理影评
pipeline2 = [{"$project": {"rv_mv_id": 1,"rate": {"$cond": {"if": {"$and": [{ "$gt": [{ "$toDouble": "$rv_action_agree" }, 0] },{ "$gt": [{ "$toDouble": "$rv_action_disagree" }, 0] }]},"then": { "$divide": [{ "$toDouble": "$rv_action_disagree" }, { "$sum": [{ "$toDouble": "$rv_action_agree" }, { "$toDouble": "$rv_action_disagree" }] }] },"else": None}}}},{"$match": { "rate": { "$ne": None } }},{"$group": {"_id": "$rv_mv_id","count": { "$sum": 1 },"total_rate": { "$sum": "$rate" }}},{"$project": {"_id": 1,"count": 1,"rate": { "$divide": ["$total_rate", "$count"] }}},{"$out": "mv_agree_divide_disagree_rate"}
]# 执行聚合管道
ct_mv_reviews.aggregate(pipeline2)# 输出结果
ct_mv_agree_divide_disagree_rate = db.mv_agree_divide_disagree_rate
temp1 = []
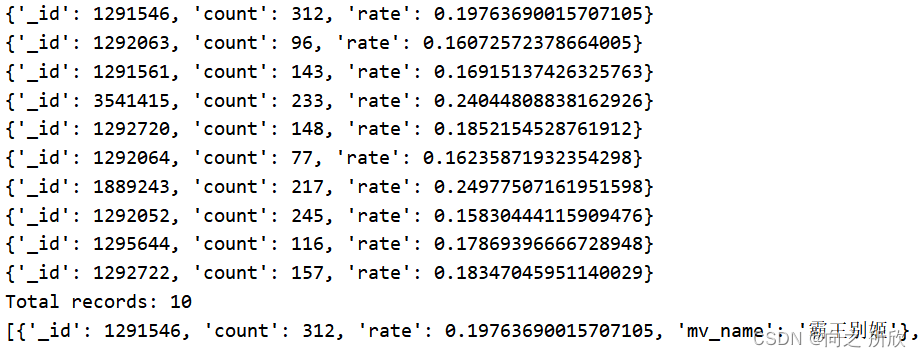
for x in ct_mv_agree_divide_disagree_rate.find():print(x)temp1.append(x)
print(f"Total records: {len(temp1)}")# 准备电影ID到电影名的映射字典
dict_rv_name = {mv['_id']: mv['mv_name'] for mv in ct_mv_infos.find()}# 条件查询, 根据电影 ID 获取到对应的电影名
for i in range(len(temp1)):temp1[i]['mv_name'] = dict_rv_name.get(temp1[i]['_id'], '')
print(temp1)
生成条形统计图:
# 柱形的宽度
bar_width = 0.6
plt.xticks(rotation=35)
x1 = [x['mv_name'] for x in temp1]y1 = [x['value']['rate'] for x in temp1]
# 绘制柱形图
plt.bar(x=x1, height=y1, width=bar_width, color=['skyblue', 'pink'],linewidth=1.5,)#为每个条形图添加数值标签
for x,y in enumerate(y1):plt.text(x,y+0.003,'%.3f' % y,ha='center')
plt.xlabel('电影名称',fontsize=14, color='blue')
plt.ylabel('评论分歧(反对)平均占比',fontsize=14, color='red')
plt.title('豆瓣Top10影视评论分歧占比统计图',fontsize=15, color='puple')
plt.show()

分析过程:
通过PyMongoDB的聚合管道,最终得出的豆瓣Top10部分影评分歧占比统计图如上图所示。
- 从整体来看,Top10影视的评论分歧都相对较低,处于
[15%, 25%]范围。 - 其中占比最多电影的为《星际穿越》,分歧率为
25%,这意味着有100人评论,那么就有将近25人的观点不被赞同,这跟电影的题材、类型、剧情、演员等多个因素都有关。 - 占比最少的为《肖申克的救赎》,仅为
15.8%,这说明观众们的观点大多是一致的,100人里面只有15人左右的观点不一致。
综上,对于Top10的电影,除了评分、观看数等指标,评论分歧率直观体现了影视的影响力,这意味着观众可以选择这个分歧率较小的电影作为参考,达到更好的观看体验,同时对于同行,能更放心地借鉴其中的一些高深的拍摄手法、剧情演绎方法等。
3.3 统计Top10电影在2024年的评论情况
ct_mv_reviews.find_one()

各电影评论的数量
for x in ct_mv_reviews.aggregate([{'$group': {'_id':'$rv_mv_id', 'counter':{'$sum':1}}}]):print(x)

list_rv= []
year, month, day = 2021,1,1
for x in ct_mv_reviews.aggregate([{# 转化类型'$project':{'rv_time': '$rv_time','rv_info': '$rv_info','rv_name': '$rv_name','rv_time_stand':{'$convert':{'input':'$rv_time','to': 'date','onNull': 'missing rv_time'}},},},{'$match':{'rv_time_stand':{'$gte': datetime(year,month,day)},}},]):list_rv.append(x)dict_rv_info = {}
'''处理 MongoDB 聚合后的结果 汇总评论
'''
for rv in list_rv:# 前 7 位是电影的IDmv_id = rv['_id'][:7]dict_rv_info[dict_rv_name[mv_id]] = {} # 键的类型为int,应在生成dict_rv_name的字典出修改为strdict_rv_info[dict_rv_name[mv_id]][rv['rv_name']] = {'rv_time': rv['rv_time'],'rv_info': rv['rv_info']}
print(f'[INFO] >> 已统计完 [{len(dict_rv_info)}] 个电影在{year}年{month}月{day}后的影评')'''词频统计
'''
import jieba
from wordcloud import WordCloud
# 不需要统计的词汇
nope = ['电影', '没有', '一个', '之后', '这部']
for k, v in dict_rv_info.items():dict_word_count = {}# 遍历每个用户的评论for review in v.values():# 遍历每个词for x in jieba.cut(review['rv_info']):if(len(x) >= 2) and x not in nope:dict_word_count.setdefault(x, 0)dict_word_count[x] = dict_word_count[x] + 1#生成词云 保存到本地t = WordCloud(width=600, height=480, # 图片大小background_color='white', # 背景颜色scale=10,font_path=r'c:\windows\fonts\simfang.ttf' ).generate_from_frequencies(dict_word_count)save_path = './count_images' + k + '.jpg't.to_file(save_path)print(f'[INFO] >> 电影[{k}] 评论的词频统计词云生成完毕, 保存位置在[{save_path}]')
print(dict_word_count)
评论词云的结果通过 img 标签展示,如下图所示:
肖申克的救赎

千与千寻

霸王别姬

这里展示了三部电影的评论词云,而且是在21年1月份以后的评论,在MongoDB的强大支持下,检索某个日期里的文档数据十分遍历,通过这样的方式,我们能感受到电影从去年到现在的影响力。
4.完整代码
4.1 爬取豆瓣排名前十的电影
# 一、导库
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup# 二、设置请求网页的信息: 网址url + header请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
}
url = 'https://movie.douban.com/top250'
# 三、使用 requests库 获取网页响应的结果文件
html = requests.get(url, headers=headers).text# 四、使用 BeautifulSoup库 解析HTML网页内容
soup = BeautifulSoup(html,features="lxml")# 五、结果bs库和re库的正则表达式提取需要的数据
mv_data = []
i = 0
for x in soup.select('.item'):i += 1mv_name = re.search('>([^<]+)<', str(x.select('.info > .hd > a > .title'))).group(1)# 电影网址mv_href = re.search('href="(.*)"', str(x.select('.info > .hd > a'))).group(1)# 电影详细信息mv_info = x.select('.info > .bd > p')# 电影部分演员表mv_actors = re.search('>([^<]+)<', str(mv_info)).group(1).strip().replace('\xa0', '')# 电影发布时间、发布国家、发布类型mv_type = re.search('<br/>([^<]+)</p>', str(mv_info)).group(1).strip().replace('\xa0', '')# 电影的简评mv_review = re.search('>([^<]+)<', str(x.select('.info > .bd > p > .inq'))).group(1)# 电影评分mv_star = re.search('>([^<]+)<', str(x.select('.info > .bd > .star > .rating_num'))).group(1)# 电影的评价数mv_evaNum = re.search('([0-9]+)人评价', str(x.select('.info > .bd > .star'))).group(1)mv_data.append({'mv_id': mv_href.split('/')[-2:-1][0],'mv_rank': i,'mv_name': mv_name,'mv_href': mv_href,'mv_actors': mv_actors,'mv_type': mv_type,'mv_review': mv_review,'mv_star': mv_star,'mv_evaNum': mv_evaNum,})mv_data = pd.DataFrame(data=mv_data[:10])
mv_data.to_excel('./data/mv_info.xlsx')
print('[info] >> 豆瓣Top10影视信息已保存到当前目录下的./data/mv_info.xlsx')# 查看爬取结果
print(mv_data)
2. 爬取电影的前四十页评论
# 一、导库
import time
import requests
import re
import pandas as pd
from bs4 import BeautifulSoup'''记录所有的评分情况
'''
mv_stars = []
# 二、设置请求网页的信息: 网址url + header请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36',
}
'''匹配获取到 >内容< 格式里的内容
'''
def getText(s):# 如果不是str类型,先转为strif (type(s) != str):s = str(s).strip().replace('\n', '')text = re.search('>([^\\)]*)<', s)# 返回匹配的结果return text.group(1) if text != None else None'''爬取评论信息
'''def getInfo(url: str, mv_id: int) -> pd.DataFrame:print('[INFO] >> 开始爬取 ' + url + ' 的评论')result = []# 获取网页响应的结果文件html = requests.get(url, headers=headers).text# 解析HTML网页内容soup = BeautifulSoup(html, features="lxml")for x in soup.select('.review-item'):# 评论的用户名rv_name = getText(x.select('.name'))# 评论的时间rv_time = getText(x.select('.main-meta'))# 评论的内容rv_info = getText(x.select('.review-short > .short-content')).split('(')[0].replace('<p class="spoiler-tip">这篇影评可能有剧透</p>', '').strip()# 评论的支持与反对rv_action_agree = getText(x.select('.main-bd > .action > .up > span')).strip()rv_action_disagree = getText(x.select('.main-bd > .action > .down > span')).strip()result.append({'rv_name': rv_name,'rv_time': rv_time,'rv_info': rv_info,'rv_mv_id': mv_id,'rv_action_agree': rv_action_agree,'rv_action_disagree': rv_action_disagree})# 数据预处理, 填补空值result = pd.DataFrame(data=result)result['rv_action_agree'] = result['rv_action_agree'].apply(lambda x: 0 if x == '' else x)result['rv_action_disagree'] = result['rv_action_disagree'].apply(lambda x: 0 if x == '' else x)return result'''获取电影的评分信息
'''def getStar(url) -> list:result = {}# 获取网页响应的结果文件html = requests.get(url, headers=headers).text# 解析HTML网页内容soup = BeautifulSoup(html, features="lxml")for i in range(1, 6):star = soup.select('.droplist > .rating' + str(i))star = re.search('\(([0-9]+)\)', str(star)).group(1)result[i] = int(star)return result'''根据豆瓣电影ID爬取内容
'''
i = 0def crawlerById(id, name) -> pd.DataFrame:global mv_stars, i# 记录时间startTime = time.time()# 基础网址base_url = 'https://movie.douban.com/subject/' + str(id) + '/reviews?'# 默认按热度排序(start = i * 20) "https://movie.douban.com/subject/1292052/reviews?start=0"url_by_hot = base_url + 'start='# 按星级排序 "https://movie.douban.com/subject/1292052/reviews?rating=5"# url_by_star = [url_by_hot + '?rating=' + str(i)+'?start=' for i in range(1, 6)]# 拼接待爬取的url,取前 40页评论urls = []for i in range(0, 801, 20): urls.append(url_by_hot + str(i))print('-' * 50 + 'BEGIN:' + str(i) + '-' * 50)print(f'[INFO] >> 正在爬取 id = {id}, 名称={name}, url={url_by_hot} 的影评... \n')mv_reviews = {}# 爬取评论mv_reviews['reviews'] = pd.concat([getInfo(url, id) for url in urls])# 爬取电影总评分情况mv_reviews['star'] = {}mv_reviews['star']['id'] = idmv_reviews['star']['name'] = namemv_reviews['star'].update(getStar(urls[0]))# 将评论的结果保存到本地save_path_reviews = './data/reviews-' + str(name) + '.xlsx'mv_reviews['reviews'].to_excel(save_path_reviews, index=False)print(f'[INFO] >> 爬取的评论结果保存到了当前文件夹的: {save_path_reviews}')# 将影评的评分记录到mv_starsmv_stars.append(mv_reviews['star'])print(f'[INFO] >> 为防止反爬虫机制启动,睡眠 1 s')time.sleep(1)endTime = time.time()print('-' * 35 + 'END:' + str(i) + ' 爬取完毕, 本次爬取耗时:' + f'{endTime - startTime:.3f}' + ' s' + '-' * 35)i += 1return mv_reviewsprint('=' * 50 + '【启动爬虫程序】' + '=' * 50)
startTime = time.time()# 读取电影信息
mv_data = pd.read_excel('./data/mv_info.xlsx')list_mv = []
# 爬取之前电影的评论信息
for (i, mv) in mv_data.iterrows():list_mv.append(crawlerById(mv.mv_id, mv.mv_name))# # 存储list_mv 有问题,存储信息不全
list_mv = pd.DataFrame(list_mv)
list_mv.to_csv('./data/list_mv.csv')
list_mv.to_json('./data/list_mv.json')# 将所有影视评论分布导出到excel
mv_stars = pd.DataFrame(data=mv_stars)
mv_stars.to_excel('./data/mv_stars.xlsx')
print(f'[INFO] >> 所有影评的评分情况已保存到本地的文件: ./mv_stars.xlsx中')endTime = time.time()
print('=' * 45 + '程序执行完毕,总耗时: ' + f'{endTime - startTime:.3f}' + ' s' + '=' * 45)
3. 将数据存入MongoDB
from pymongo import MongoClient
import pandas as pd# 创建本地MongoDB实例
client = MongoClient('localhost', 27017)# 选择连接的数据库
db = client.mv# 创建电影信息集合
ct_mv_infos = db.dc_mv_infos
# 创建影评集合
ct_mv_reviews = db.dc_mv_reviews# 查看创建结果
# print(ct_mv_reviews) # Collection(Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), 'mv'), 'dc_mv_reviews')# 读取电影信息
mv_info = pd.read_excel('./data/mv_info.xlsx')
# print(mv_info)# 将影视信息转化为dict字典格式
dc_mv = []# 获取每一列的列名
mv_info_cols = mv_info.columns
for i in range(len(mv_info)):# 创建用于存储mv_info的字典dict_info = {}# 指定文档的_id为电影IDdict_info['_id'] = mv_info['mv_id'][i]# 循环遍历mv_info数据,存入dict_infofor col in mv_info_cols[2:]: # 因为第一列取了别名'_id',故不用再次遍历'mv_id'(原作者取了又取了'mv_id')dict_info[col] = mv_info[col][i]dc_mv.append(dict_info)
# for r in dc_mv:
# print(r)# 类型转换否则无法插入
dc_mv= pd.DataFrame(dc_mv).to_dict("records")
# 插入前 先清空
ct_mv_infos.delete_many({})
# 插入文档
ct_mv_infos.insert_many(dc_mv)
# 查看插入到MongoDB的数据
print(ct_mv_infos.find_one())# 读取各 "电影.xlsx" 评论信息,顺序与 mv_info.xlsx 中的排名要保持一致,否则后续评论标号会不一致
mv_names = ['肖申克的救赎', '霸王别姬', '阿甘正传','泰坦尼克号', '千与千寻', '这个杀手不太冷','美丽人生', '星际穿越', '盗梦空间', '楚门的世界']# 创建数组,用于汇总所有存储数据
# mv_comments = pd.DataFrame()
# # 循环读入评论记录,将多个文件内容拼接到一起
# for i in range(10):
# save_path_reviews = './data/reviews-' + mv_names[i] + '.xlsx'
# mv_comments = pd.concat([mv_comments, pd.read_excel(save_path_reviews)])# print(len(mv_comments))
# print(mv_comments.columns)
# print(mv_comments.head())def getAllReviews() -> list[list]:index = 0 # mv_info 中的索引reviews = [] # 用于所有电影的影评信息# # 创建数组,用于存储影评信息 (冗余语句)# mv_comments = pd.DataFrame()# 记录当前电影的所有影评信息for i in range(len(mv_names)):dc_reviews = [] # 用于存储每部电影的影评信息# 表示当前的评论 _id (标号)c_id = 0# 读取对应电影的评论信息save_path_reviews = './data/reviews-' + mv_names[i] + '.xlsx'mv_comments = pd.read_excel(save_path_reviews)# print(mv_comments)# 获取列名rv_cols = mv_comments.columns# 遍历每个评论,将其汇总for j in range(len(mv_comments)):# 根据电影ID和当前评论序号定义_iddict_info = {'_id': str(mv_info['mv_id'][index]) + str(c_id)}c_id += 1# 拼接影评信息for col in rv_cols:dict_info[col] = mv_comments[col][j]dc_reviews.append(dict_info)index += 1 # 更换电影# 将每部电影的影评汇总信息添加到reviews中reviews.append(dc_reviews)return reviews# 主程序
dc_reviews = getAllReviews()count = 0
for i in range(len(dc_reviews)):count += len(dc_reviews[i])
print(f'[INFO] >> 共获取到 {len(dc_reviews)} 个电影 {count} 个的影评')print(f'[INFO] >> 查看其中的一个影评: {dc_reviews[0][:1]}')# 插入影评信息到 MongoDB
ct_mv_reviews.delete_many({})
for rv in dc_reviews:# print(rv)rv = pd.DataFrame(rv).to_dict("records") # 类型转换ct_mv_reviews.insert_many(rv)
# 查看插入结果
print(ct_mv_reviews.find_one())
4. 对MongoDB中的数据进行处理
from pymongo import MongoClient# 连接到本地MongoDB实例
client = MongoClient(host='localhost', port=27017)# 选择连接的数据库
db = client.mv# 创建电影信息集合
ct_mv_infos = db.dc_mv_infos
# 创建影评集合
ct_mv_reviews = db.dc_mv_reviews# 定义聚合管道
pipeline = [{"$group": {"_id": None,"count": {"$sum": 1},"mv_star_total": {"$sum": {"$toDouble": "$mv_star"}}}},{"$project": {"_id": 0,"count": 1,"mv_star_total": 1,"mv_star_avg": {"$divide": ["$mv_star_total", "$count"]}}},{"$out": "mv_star_avg"}
]# 执行聚合管道
ct_mv_infos.aggregate(pipeline)# 输出结果
ct_mv_star_avg = db.mv_star_avg
for x in ct_mv_star_avg.find():print(x)# 定义聚合管道用于统计Top10电影影评的[赞同 / 不赞同]的平均比率
pipeline2 = [{"$project": {"rv_mv_id": 1,"rate": {"$cond": {"if": {"$and": [{ "$gt": [{ "$toDouble": "$rv_action_agree" }, 0] },{ "$gt": [{ "$toDouble": "$rv_action_disagree" }, 0] }]},"then": { "$divide": [{ "$toDouble": "$rv_action_disagree" }, { "$sum": [{ "$toDouble": "$rv_action_agree" }, { "$toDouble": "$rv_action_disagree" }] }] },"else": None}}}},{"$match": { "rate": { "$ne": None } }},{"$group": {"_id": "$rv_mv_id","count": { "$sum": 1 },"total_rate": { "$sum": "$rate" }}},{"$project": {"_id": 1,"count": 1,"rate": { "$divide": ["$total_rate", "$count"] }}},{"$out": "mv_agree_divide_disagree_rate"}
]# 执行聚合管道
ct_mv_reviews.aggregate(pipeline2)# 输出结果
ct_mv_agree_divide_disagree_rate = db.mv_agree_divide_disagree_rate
temp1 = []
for x in ct_mv_agree_divide_disagree_rate.find():print(x)temp1.append(x)
print(f"Total records: {len(temp1)}")# 准备电影ID到电影名的映射字典
dict_rv_name = {str(mv['_id']): mv['mv_name'] for mv in ct_mv_infos.find()} # 已修改 _id 类型为 str# 条件查询, 根据电影 ID 获取到对应的电影名
for i in range(len(temp1)):temp1[i]['mv_name'] = dict_rv_name.get(temp1[i]['_id'], '')
print(temp1)import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'# 柱形的宽度
bar_width = 0.6
plt.xticks(rotation=35)
x1 = [x['mv_name'] for x in temp1]y1 = [x['rate'] for x in temp1]
# 绘制柱形图
plt.bar(x=x1,height=y1,width=bar_width,color=['skyblue', 'pink'],linewidth=1.5,)# 26 # 为每个条形图添加数值标签
for x,y in enumerate(y1):plt.text(x,y+0.003,'%.3f' % y,ha='center')
plt.xlabel('电影名称',fontsize=14, color='blue')
plt.ylabel('评论分歧(反对)平均占比',fontsize=14, color='red')
plt.title('豆瓣Top10影视评论分歧占比统计图',fontsize=15, color='purple')
# plt.show()#
ct_mv_reviews.find_one()
for x in ct_mv_reviews.aggregate([{'$group': {'_id':'$rv_mv_id', 'counter':{'$sum':1}}}]):print(x)#### 生成图云
from datetime import datetimelist_rv= []
year, month, day = 2021,1,1
for x in ct_mv_reviews.aggregate([{# 转化类型'$project':{'rv_time': '$rv_time','rv_info': '$rv_info','rv_name': '$rv_name','rv_time_stand':{'$convert':{'input':'$rv_time','to': 'date','onNull': 'missing rv_time'}},},},{'$match':{'rv_time_stand':{'$gte': datetime(year,month,day)},}},]):list_rv.append(x)dict_rv_info = {}
'''处理 MongoDB 聚合后的结果 汇总评论
'''
for rv in list_rv:# 前 7 位是电影的IDmv_id = rv['_id'][:7]dict_rv_info[dict_rv_name[mv_id]] = {} # 键的类型为int,应在生成dict_rv_name的字典出修改为strdict_rv_info[dict_rv_name[mv_id]][rv['rv_name']] = {'rv_time': rv['rv_time'],'rv_info': rv['rv_info']}
print(f'[INFO] >> 已统计完 [{len(dict_rv_info)}] 个电影在{year}年{month}月{day}后的影评')'''词频统计
'''
import jieba
from wordcloud import WordCloud
# 不需要统计的词汇
nope = ['电影', '没有', '一个', '之后', '这部']
for k, v in dict_rv_info.items():dict_word_count = {}# 遍历每个用户的评论for review in v.values():# 遍历每个词for x in jieba.cut(review['rv_info']):if(len(x) >= 2) and x not in nope:dict_word_count.setdefault(x, 0)dict_word_count[x] = dict_word_count[x] + 1#生成词云 保存到本地t = WordCloud(width=600, height=480, # 图片大小background_color='white', # 背景颜色scale=10,font_path=r'c:\windows\fonts\simfang.ttf' ).generate_from_frequencies(dict_word_count)save_path = './count_images/' + k + '.jpg't.to_file(save_path)print(f'[INFO] >> 电影[{k}] 评论的词频统计词云生成完毕, 保存位置在[{save_path}]')
# print(dict_word_count)
注:本文在现有文章的基础上进行了一定程度的修改,原文链接





)
