摘要:基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)对于使大型语言模型与人类偏好保持一致至关重要。尽管近期的研究主要集中在算法改进上,但提示数据构建的重要性却常被忽视。本文旨在填补这一空白,通过探索RLHF性能扩展中的数据驱动瓶颈,特别是奖励黑客行为(reward hacking)和响应多样性降低的问题。我们引入了一种混合奖励系统,该系统结合了推理任务验证器(Reasoning Task Verifiers, RTV)和生成式奖励模型(Generative Reward Model, GenRM),以缓解奖励黑客行为。同时,我们还提出了一种新颖的提示选择方法,即预策略梯度优化(Pre-Proximal Policy Optimization, Pre-PPO),以维持响应多样性并提高学习有效性。此外,我们发现,在RLHF训练初期优先处理数学和编程任务能显著提升性能。在两个不同模型规模上的实验验证了我们方法的有效性和可扩展性。结果表明,RTV在抵抗奖励黑客行为方面表现最佳,其次是使用真实数据的GenRM,然后是使用监督微调(Supervised Fine-Tuning, SFT)最佳N选一响应的GenRM。我们的策略能够迅速捕捉任务间的细微差别,从而全面提升RLHF的性能。这项工作强调了精心构建数据的重要性,并提供了克服RLHF性能障碍的实用方法。Huggingface链接:Paper page,论文链接:2503.22230
研究背景和目的
研究背景
近年来,随着大型语言模型(LLMs)的快速发展,如何使这些模型更好地与人类偏好和价值观保持一致成为了一个重要的研究方向。基于人类反馈的强化学习(RLHF)技术在此过程中扮演了关键角色。RLHF通过不断迭代地根据人类反馈优化模型行为,使得LLMs能够生成更有用、无害和诚实的响应。然而,尽管RLHF技术取得了显著进展,但其性能扩展仍面临诸多挑战。特别是,数据扩展作为RLHF中的关键环节,其构建和优化过程存在诸多瓶颈,这些问题严重限制了RLHF的性能提升。
当前,RLHF的研究主要集中在算法层面的改进,如减少计算开销、强化奖励模型以缓解奖励黑客行为等。然而,对于RLHF中提示数据(prompt data)的构建及其可扩展性,研究相对较少。提示数据的质量和多样性对RLHF的性能具有重要影响,但如何有效构建和扩展高质量的提示数据,以支持LLMs在更大规模、更复杂场景下的应用,仍是一个亟待解决的问题。
研究目的
针对上述问题,本研究旨在系统探索RLHF性能扩展中的数据驱动瓶颈,并提出相应的解决方案。具体而言,本研究旨在:
- 识别RLHF数据扩展中的关键瓶颈:通过分析现有RLHF方法的局限性,识别出影响RLHF性能扩展的主要因素,特别是奖励黑客行为和响应多样性降低的问题。
- 提出混合奖励系统:设计一种结合推理任务验证器(RTV)和生成式奖励模型(GenRM)的混合奖励系统,以提高RLHF对奖励黑客行为的抵抗能力,并准确评估模型响应与真实解决方案的一致性。
- 提出新颖的提示选择方法:开发一种名为Pre-PPO的提示选择方法,通过显式识别对模型而言更具挑战性的训练提示,以提高RLHF的数据扩展有效性和学习效率。
- 验证优先处理数学和编程任务的有效性:通过实验验证在RLHF训练初期优先处理数学和编程任务对提升模型性能的作用。
研究方法
框架概述
本研究的RLHF框架包括三个主要阶段:
- 初始监督微调:首先,在预训练语言模型的基础上,使用人类编写的演示数据进行监督微调,使模型具备基本的指令跟随能力。
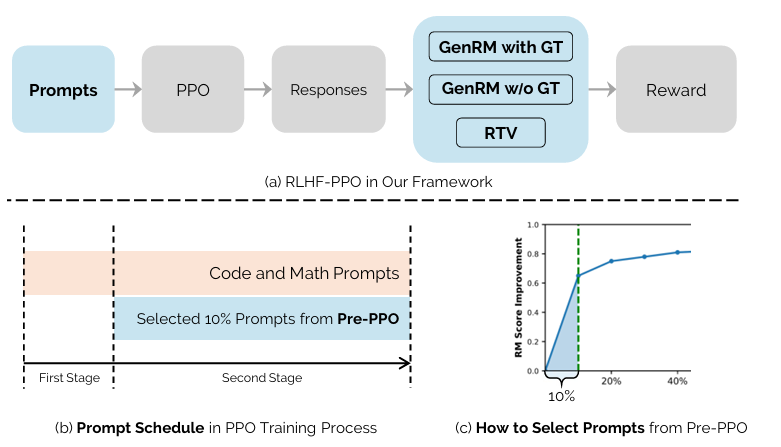
- 奖励模型训练:构建三种类型的奖励模型:Bradley-Terry奖励模型(BT模型)、生成式奖励模型(GenRM)和推理任务验证器(RTV)。BT模型通过成对比较数据学习奖励函数,优化参数以推断人类偏好下的潜在奖励分数。GenRM则通过学习人类对不同输出偏好的成对比较来直接预测比较分数。RTV则针对特定任务构建一系列验证器,如编程任务的代码沙盒,以实时执行和评估代码输出。
- 强化学习优化:利用GenRM和RTV提供的综合反馈,通过策略梯度优化(PPO)迭代优化语言模型。此过程由精心挑选的训练提示和优化的训练策略指导,以稳健地提升模型性能和一致性。
提示选择方法(Pre-PPO)
针对现有RLHF方法在数据扩展方面的不足,本研究提出了一种新颖的提示选择方法——Pre-PPO。该方法的核心思想是显式识别对模型而言更具挑战性的训练提示,这些提示往往具有较低的奖励模型得分,但更能帮助模型学习到细微的任务特定区别。具体步骤如下:
- 初始实验:首先,结合新收集的提示数据与原始提示数据训练RLHF模型。然而,实验结果显示,仅通过增加提示数据数量并不能显著提升RLHF性能。
- 奖励分析:对新收集的提示数据进行奖励分析,发现大多数提示获得了较高的奖励得分,但手动检查发现,许多高得分输出存在奖励黑客行为,且质量上并不优于原始最佳选择响应。
- 提示选择:基于上述分析,设计Pre-PPO方法,选择具有较低奖励模型得分的提示用于初始PPO实验。这些低得分提示对模型而言更具挑战性,且不易受到奖励黑客行为的影响。
早期训练阶段优先处理数学和编程任务
实验发现,在RLHF训练初期优先处理数学和编程任务能够显著提升模型性能。这是因为这些任务自然编码了细微的响应区别,且拥有明确的真实解决方案,从而增强了模型对这些细微区别的捕捉能力。具体实现方式如下:
- 任务分配:在RLHF训练初期,主要训练模型处理数学和编程任务。
- 混合训练:随着训练的进行,逐渐引入其他领域的任务,形成混合训练数据集,以保持模型的通用能力。
研究结果
性能提升
实验结果显示,结合Pre-PPO方法和早期优先处理数学和编程任务的策略,在不同模型规模和评估数据集上均显著提升了RLHF的整体性能。具体表现如下:
- 整体性能改进:与基线方法(使用原始数据集的PPO)相比,本研究提出的方法在逻辑推理、指令跟随、STEM任务、编程、自然语言处理、知识和上下文理解等多个能力上均表现出显著的性能提升。
- 挑战测试集上的泛化能力:在更具挑战性的测试集(V2.0)上,本研究提出的方法也表现出更强的泛化能力,特别是在数学和编程任务上。
数学和编程任务性能提升
特别值得注意的是,本研究提出的方法在数学和编程任务上实现了显著的性能提升。这主要得益于早期训练阶段对这些任务的优先处理,使模型能够更快地捕捉到这些任务中的细微区别。
消融研究
消融研究进一步验证了Pre-PPO方法和早期优先处理数学和编程任务策略的有效性。结果显示,这两种策略在单独使用时均能在一定程度上提升RLHF性能,而当它们结合使用时,则能够实现更显著的性能提升。
研究局限
尽管本研究在RLHF性能扩展方面取得了显著进展,但仍存在一些局限性:
- 数据质量和多样性:尽管Pre-PPO方法能够在一定程度上提高提示数据的质量,但高质量的训练提示在现实世界中仍然稀缺。如何进一步提高提示数据的多样性和质量,仍是一个亟待解决的问题。
- 模型规模:本研究仅在两个不同规模的模型上进行了实验,未涵盖更大规模的模型。未来研究需要进一步验证本研究提出的方法在更大规模模型上的有效性和可扩展性。
- 超参数调整:在不同规模的模型上应用本研究提出的方法时,可能需要调整超参数以最大化性能提升。然而,如何有效地调整这些超参数仍是一个开放性问题。
未来研究方向
针对上述局限,未来研究可以从以下几个方面展开:
- 提示数据生成:探索直接从大型语言模型本身生成提示数据的方法,以提高提示数据的多样性和质量。这种方法可能比依赖现实世界收集的数据更具潜力和前景。
- 更大规模模型的验证:在更大规模的模型上验证本研究提出的方法的有效性和可扩展性,并探索如何调整超参数以最大化性能提升。
- 长期性能监测:对应用本研究提出方法的模型进行长期性能监测,以评估其在不同任务和时间点上的稳定性和一致性。
- 与其他方法的结合:探索将本研究提出的方法与其他RLHF方法(如迭代RLHF、从预训练模型开始的RLHF等)相结合的可能性,以进一步提升RLHF的整体性能。
总之,本研究通过探索RLHF性能扩展中的数据驱动瓶颈,并提出了相应的解决方案。实验结果显示,本研究提出的方法在多个方面均显著提升了RLHF的性能。然而,仍存在一些局限性需要进一步研究和解决。未来研究可以在提示数据生成、更大规模模型的验证、长期性能监测和与其他方法的结合等方面展开探索,以推动RLHF技术的进一步发展。






虚拟地址与页表)