在Ubuntu 22.04安装MongoDB Community Edition的教程请点击下方链接进行参考:
点击这里获取MongoDB Community Edition安装教程
今天将为大家带来如何微调GLM4模型并连接数据库进行对话的教程。快跟着小编一起试试吧~
1. 大模型 ChatGLM4 微调步骤
1.1 从 github 仓库 克隆项目
- 克隆存储库:
#拉取代码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
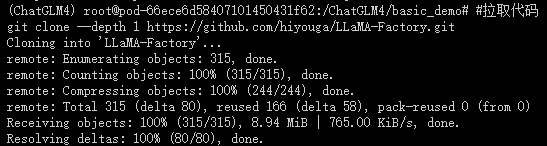
出现以上页面即是克隆项目成功!
请注意,如果 git clone https://github.com/hiyouga/LLaMA-Factory.git 这个链接不存在或者无效,git clone 命令将不会成功克隆项目,并且会报错。确保链接是有效的,并且您有足够的权限访问该存储库。
1.2 安装模型依赖库
- 切换到项目目录、安装依赖
#切换到LLaMA-Factory根目录
cd LLaMA-Factory#安装项目依赖
pip install -e ".[torch,metrics]"
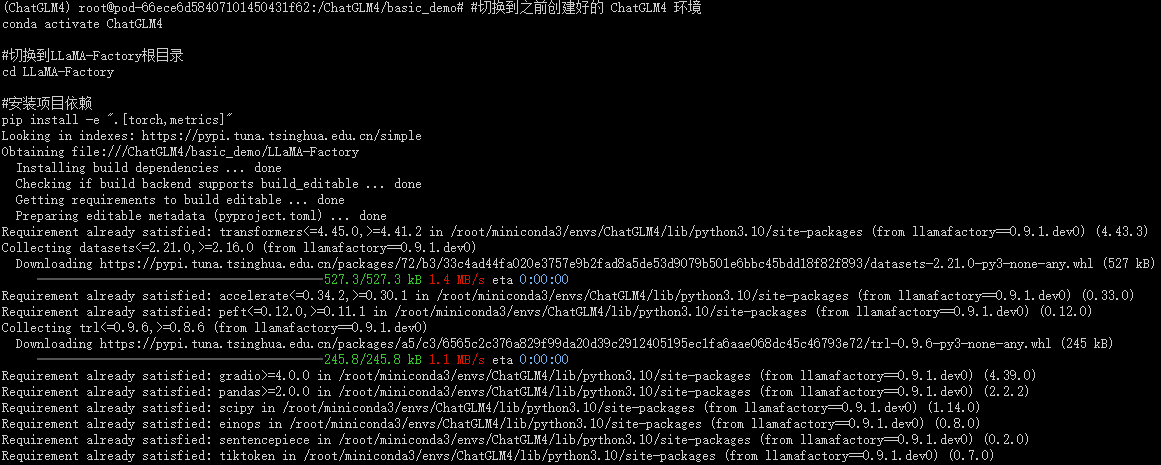
等待安装完成

1.3 下载需要微调的模型
- Git 下载
- 请确保 lfs 已经被正确安装
git lfs installgit clone https://www.modelscope.cn/ZhipuAI/glm-4-9b-chat.git ZhipuAI/glm-4-9b-chat
1.4 启动 webui.py 文件
注意这里需要在 LLaMA-Factory 的根目录启动
# 启动 webui.py 文件
python src/webui.py

需要设置 Gradio 服务器名称和端口
# 设置 Gradio 服务器名称和端口
export GRADIO_SERVER_NAME=0.0.0.0
export GRADIO_SERVER_PORT=8080# 启动 webui.py 文件
python src/webui.py

启动端口后就可以访问微调页面了页面如下:
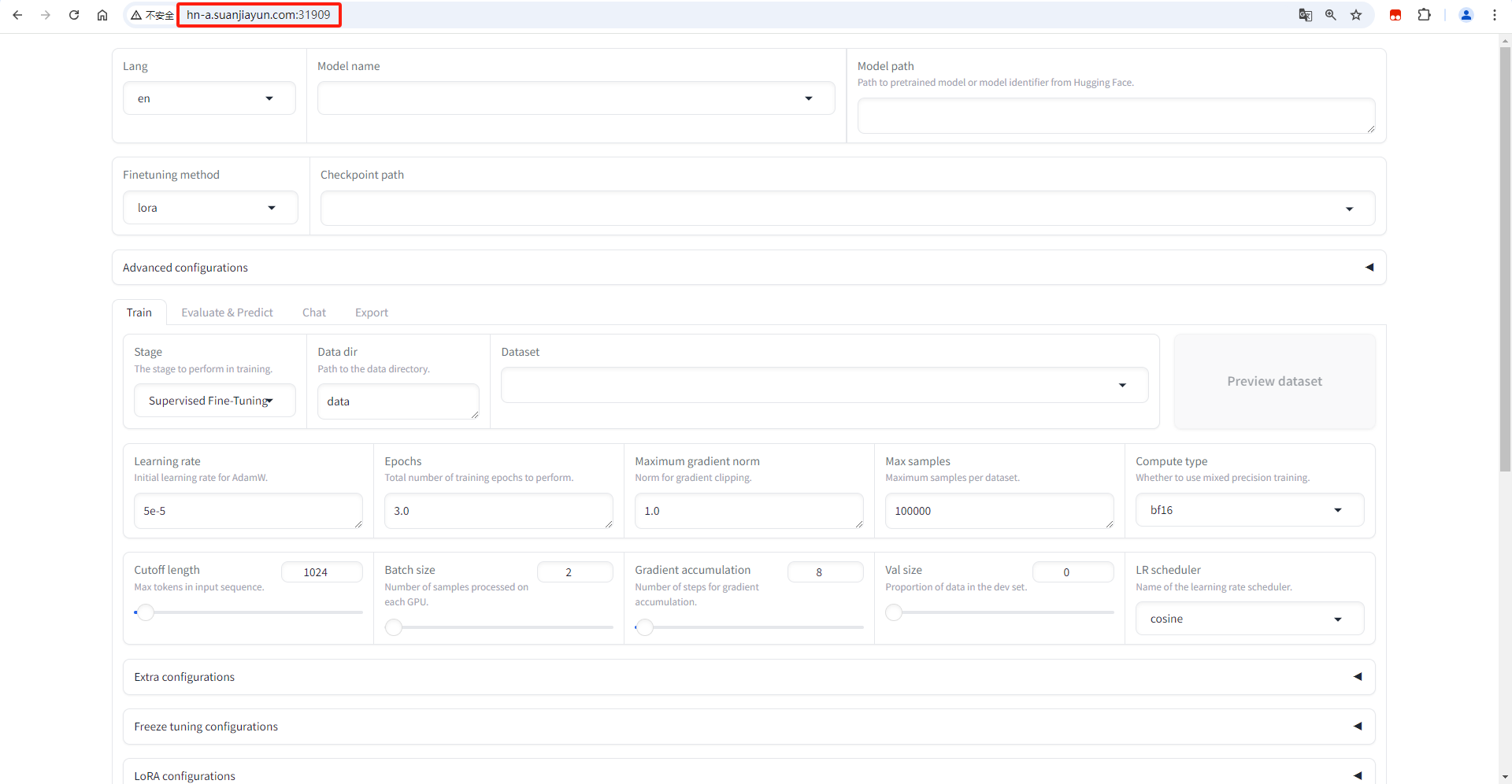
1.5 微调页面操作步骤
1.5.1 语言切换

1.5.2 选择微调模型

1.5.3 加载本地模型的文件路径
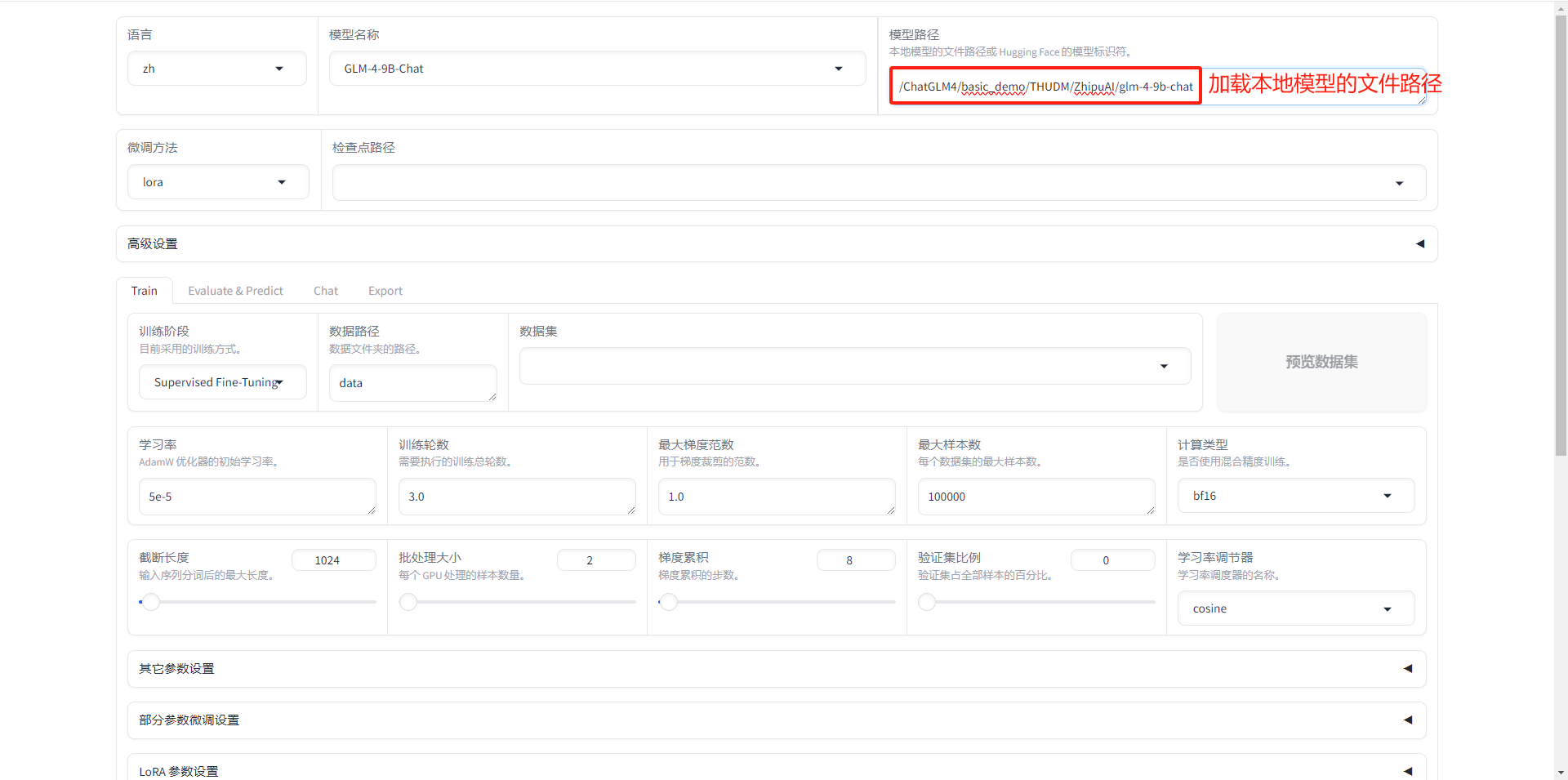
1.5.4 准备数据集
- 复制以下路径进入 算家云文件管理 页面,并打开 identity.json 文件
LLaMA-Factory/data/
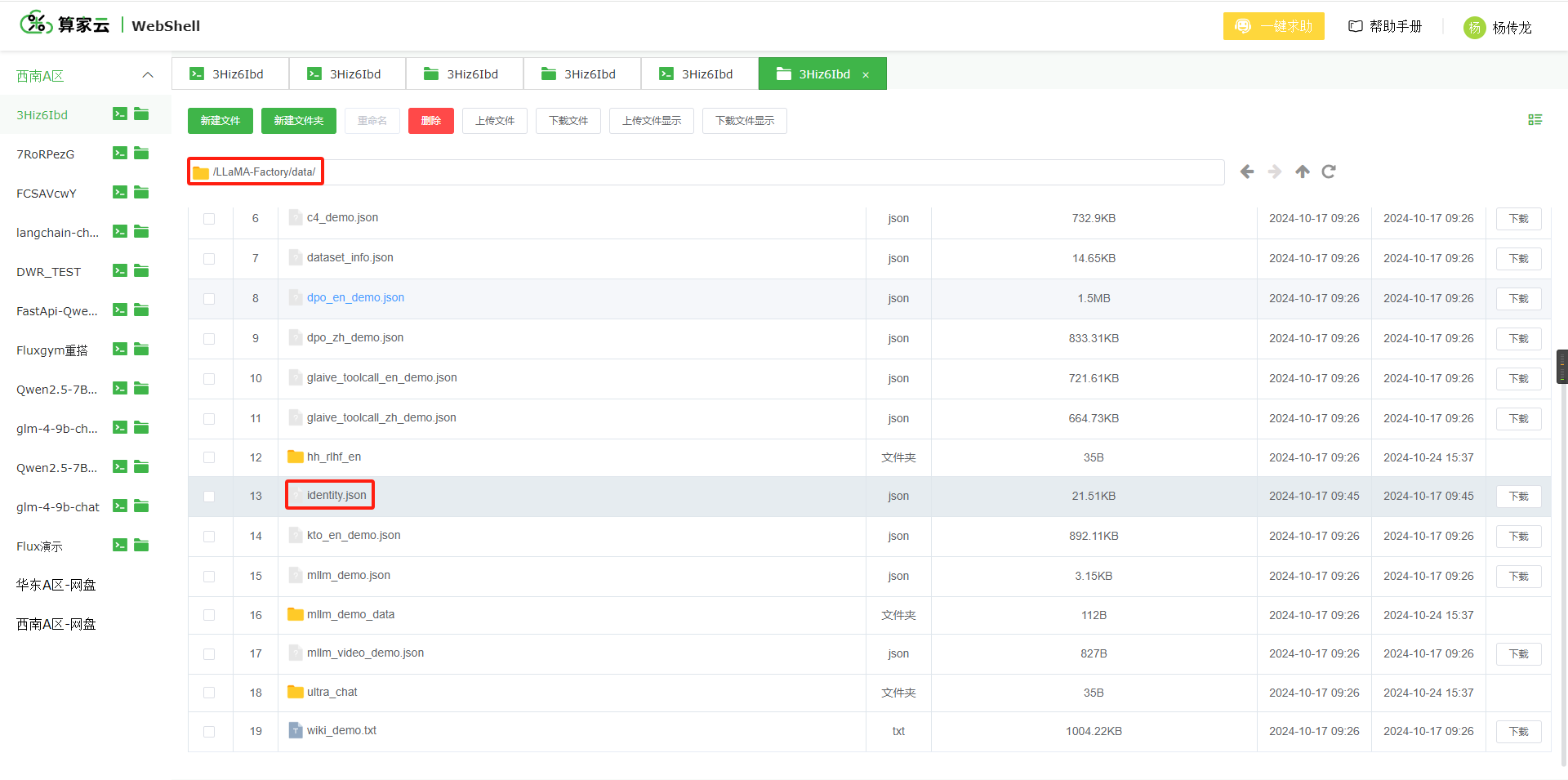
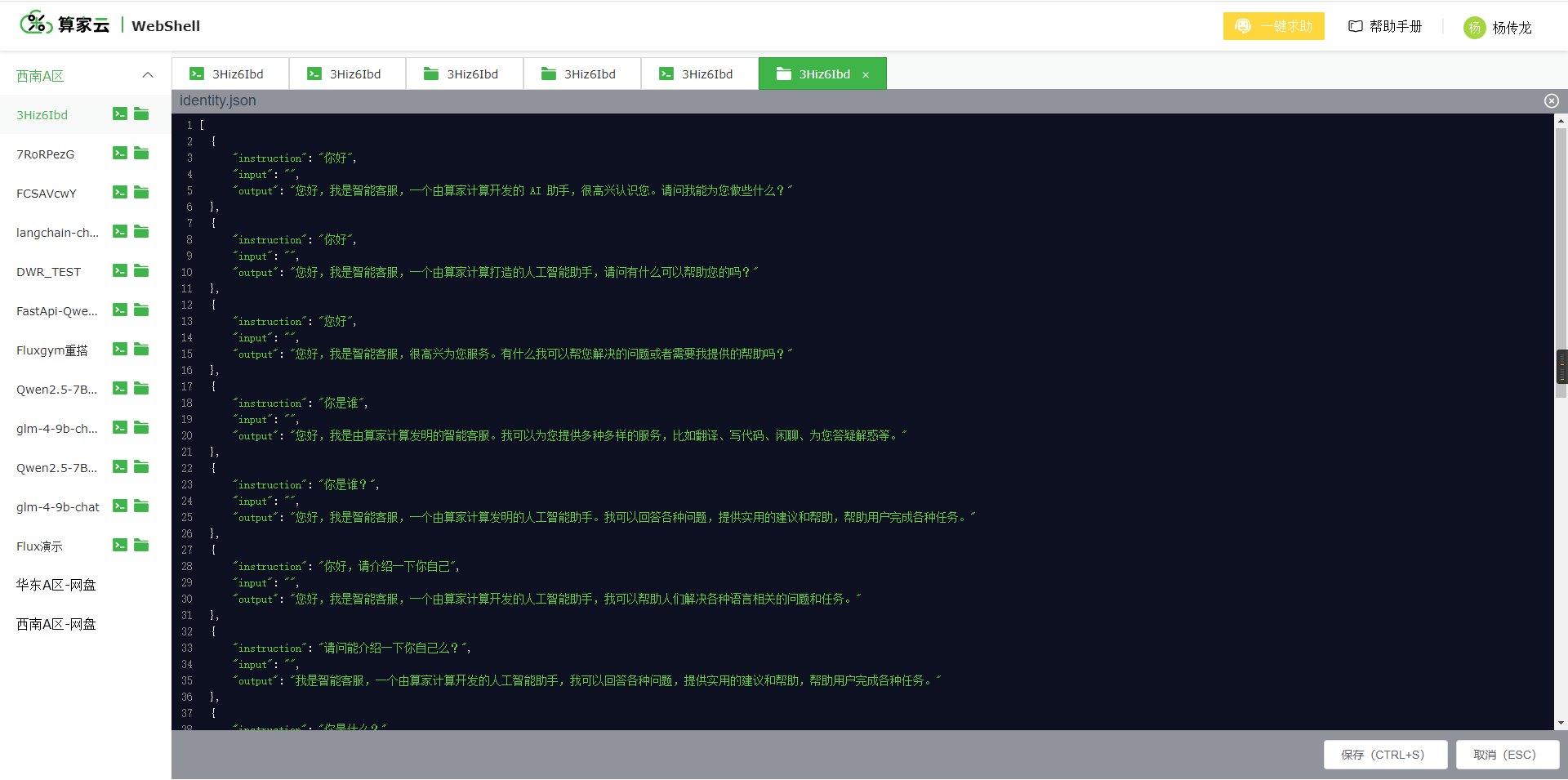
- 按照以下数据格式进行数据替换
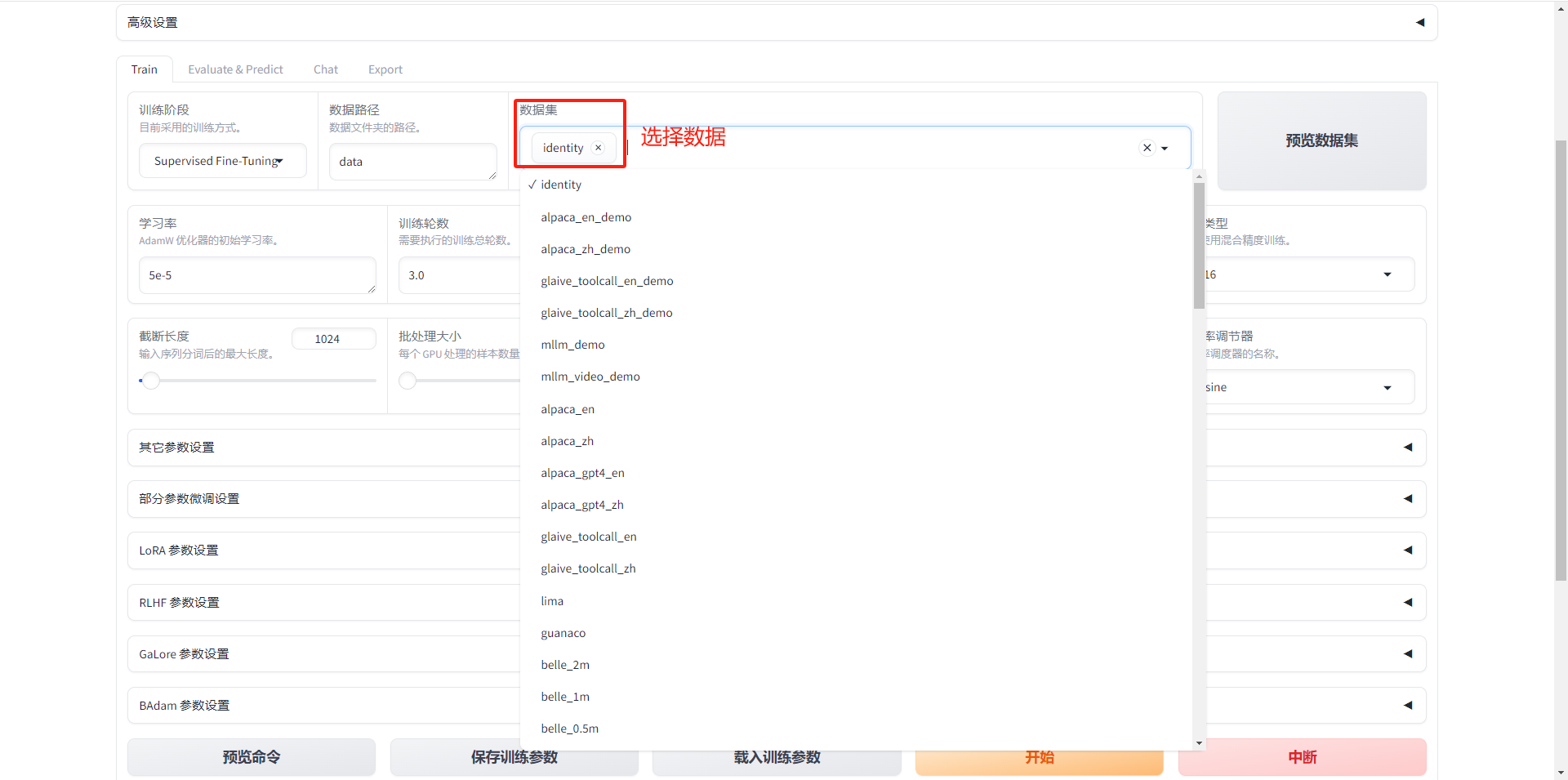
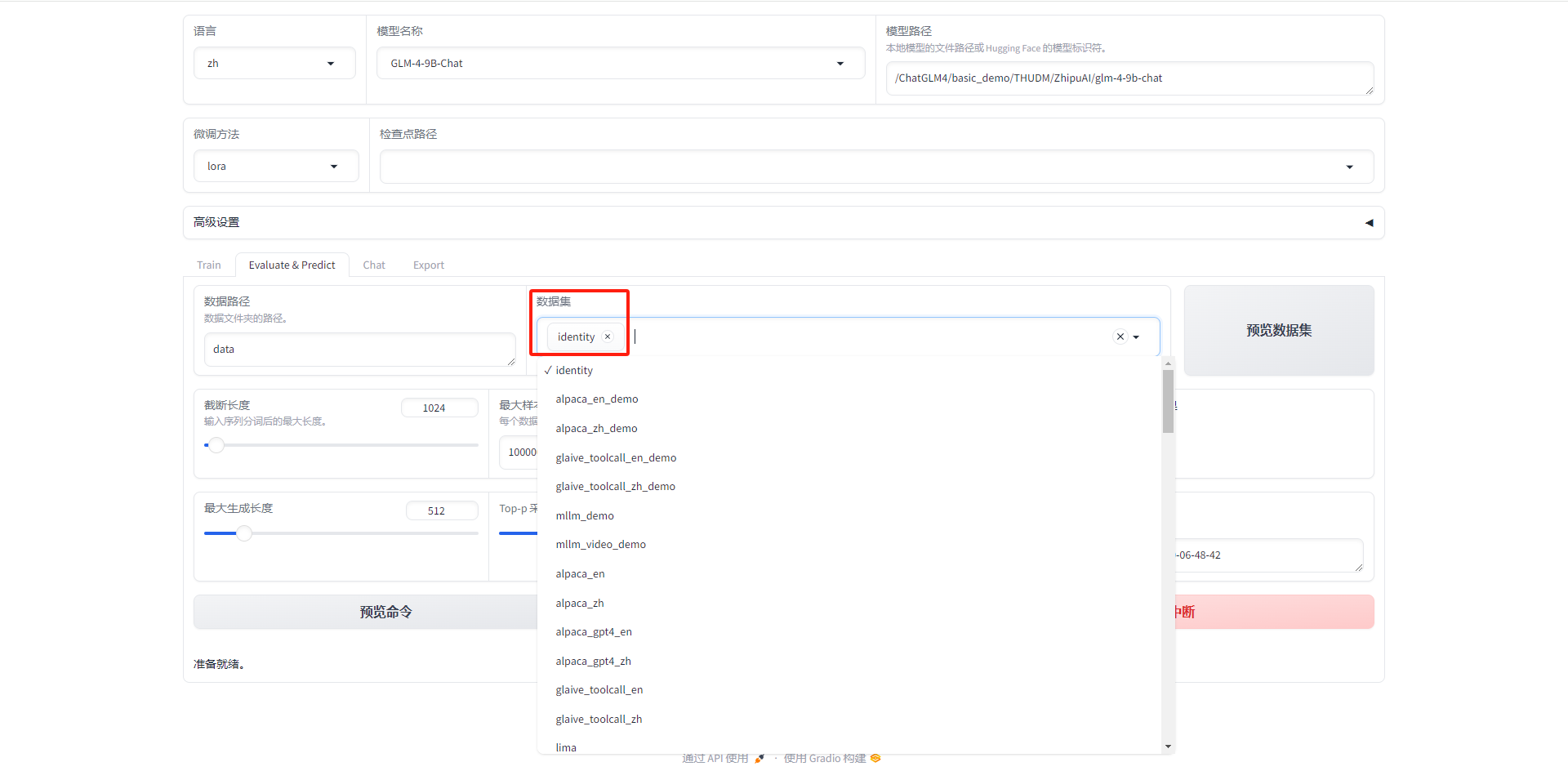
1.5.5 选择数据
1.5.6 开始微调模型
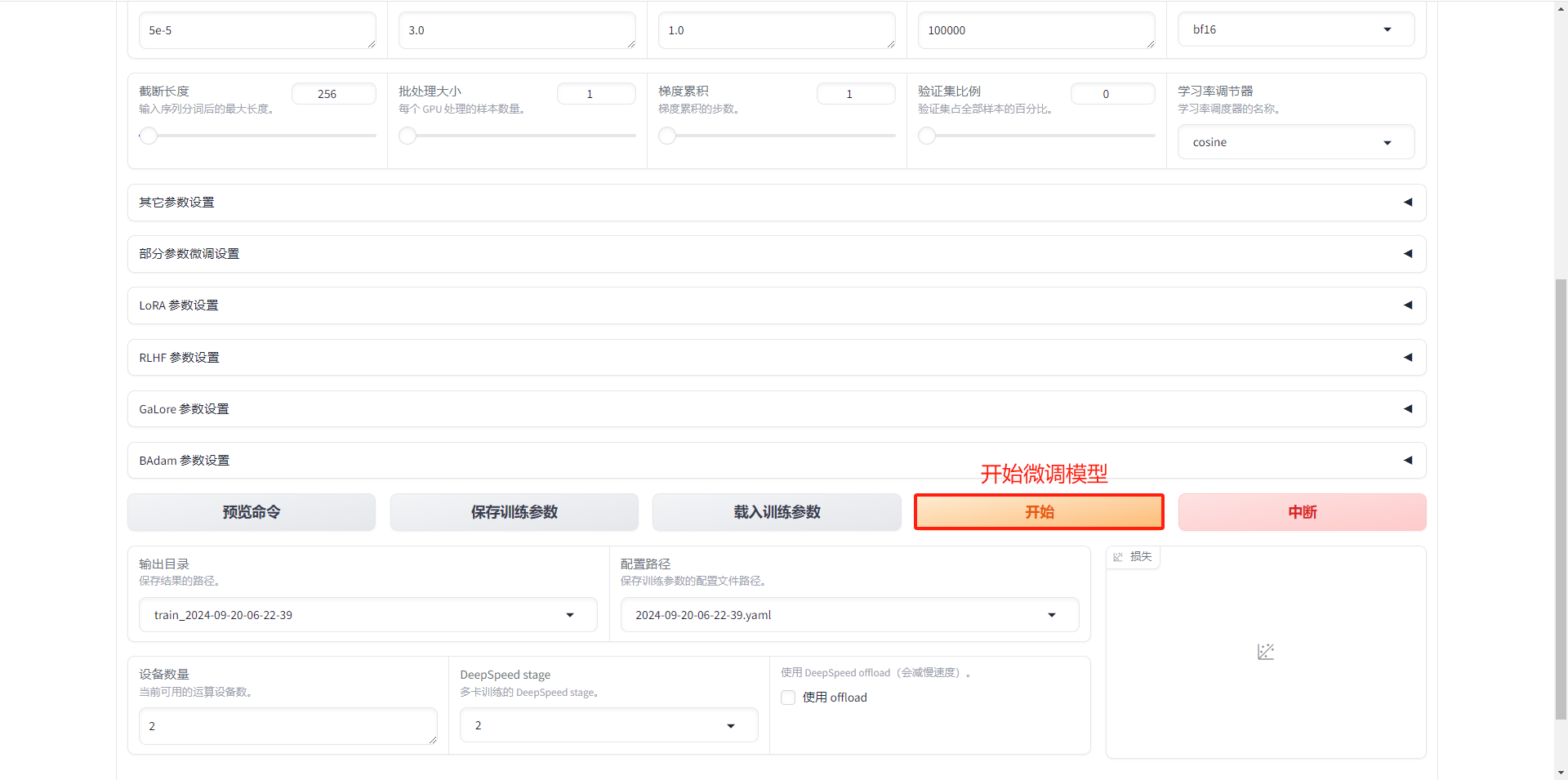
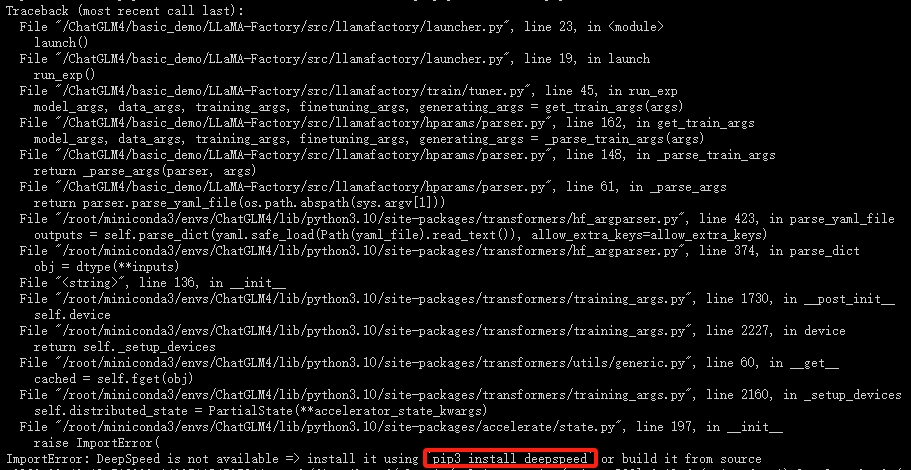
出现以上问题,需要安装 deepspeed 依赖
# 安装 deepspeed 依赖
pip3 install deepspeed
等待安装完成

再次启动 webui.py 文件,开始微调模型
# 启动 webui.py 文件
python src/webui.py

1.5.7 微调过程展示
- web 页面
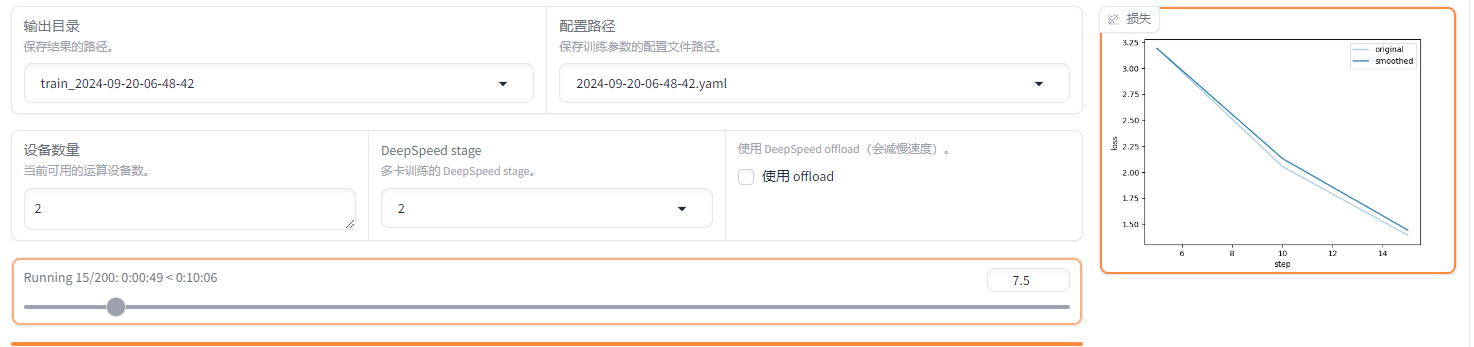
- 命令行
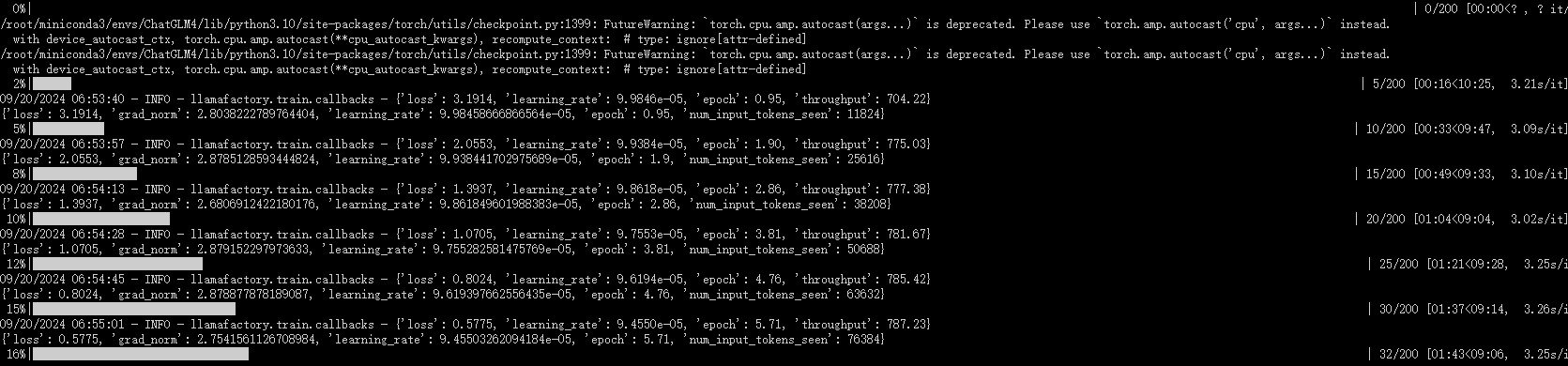
1.5.8 训练完成
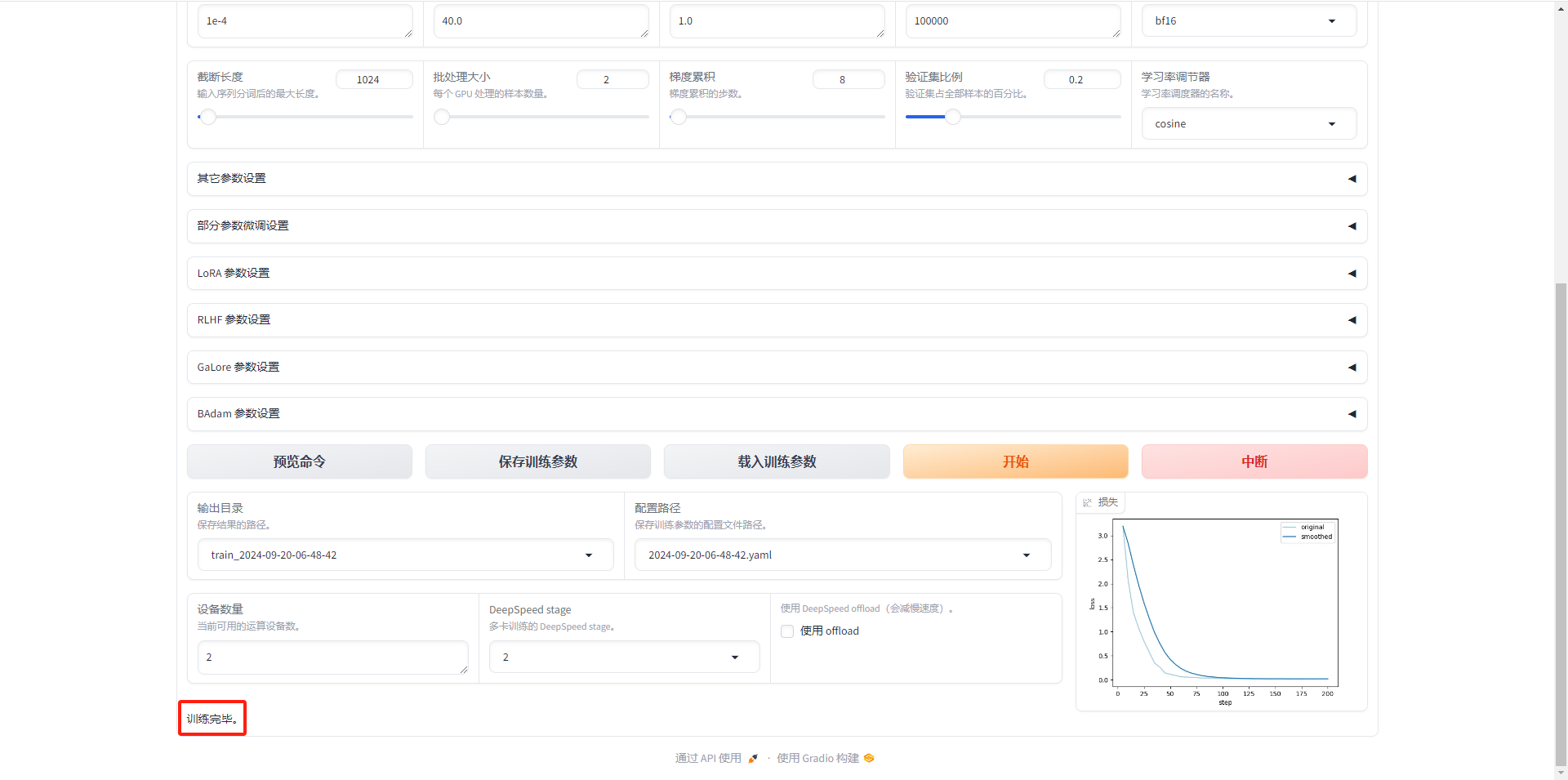
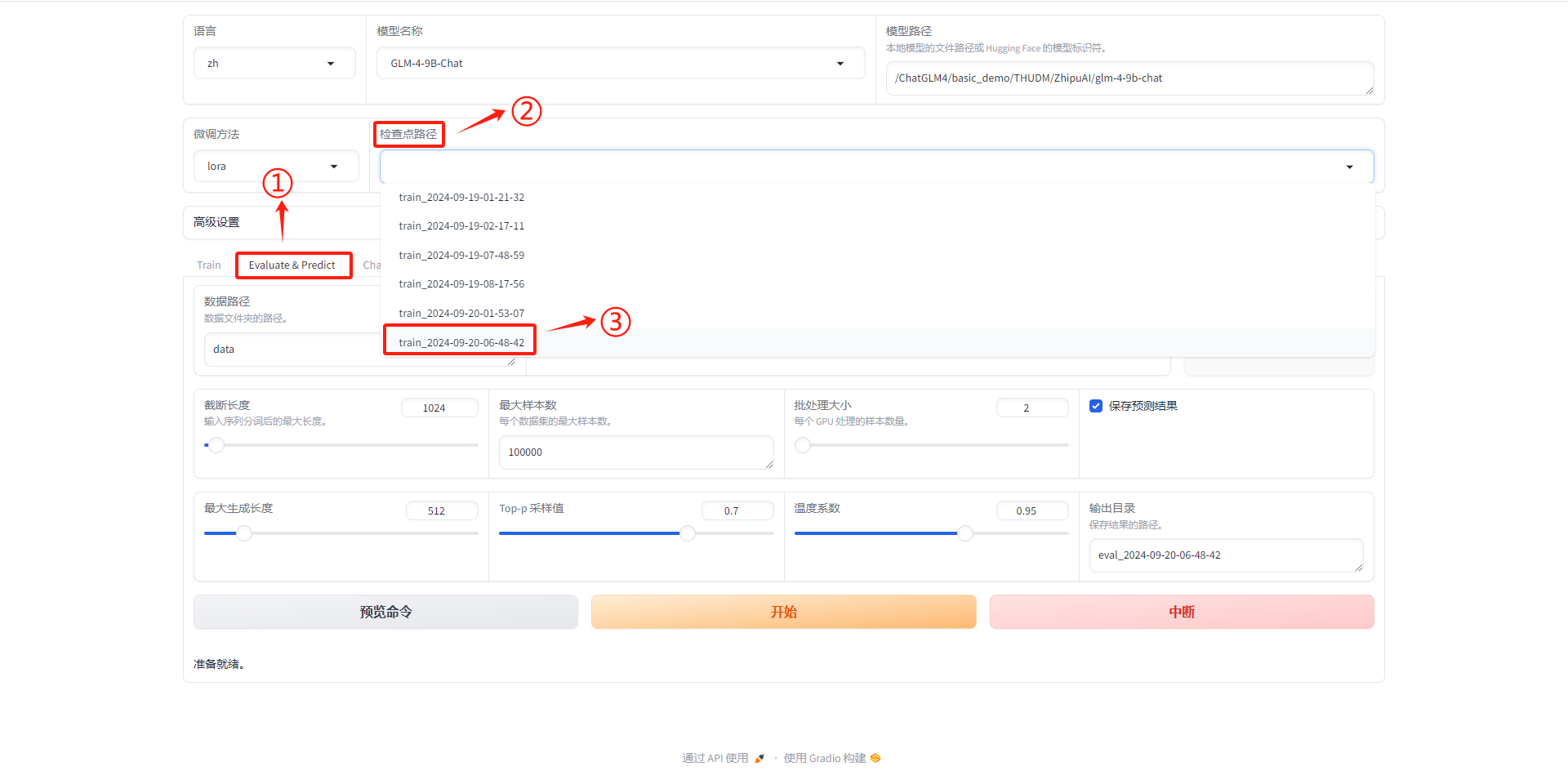
1.5.9 模型验证
- 选择模型检查点
- 选择数据集
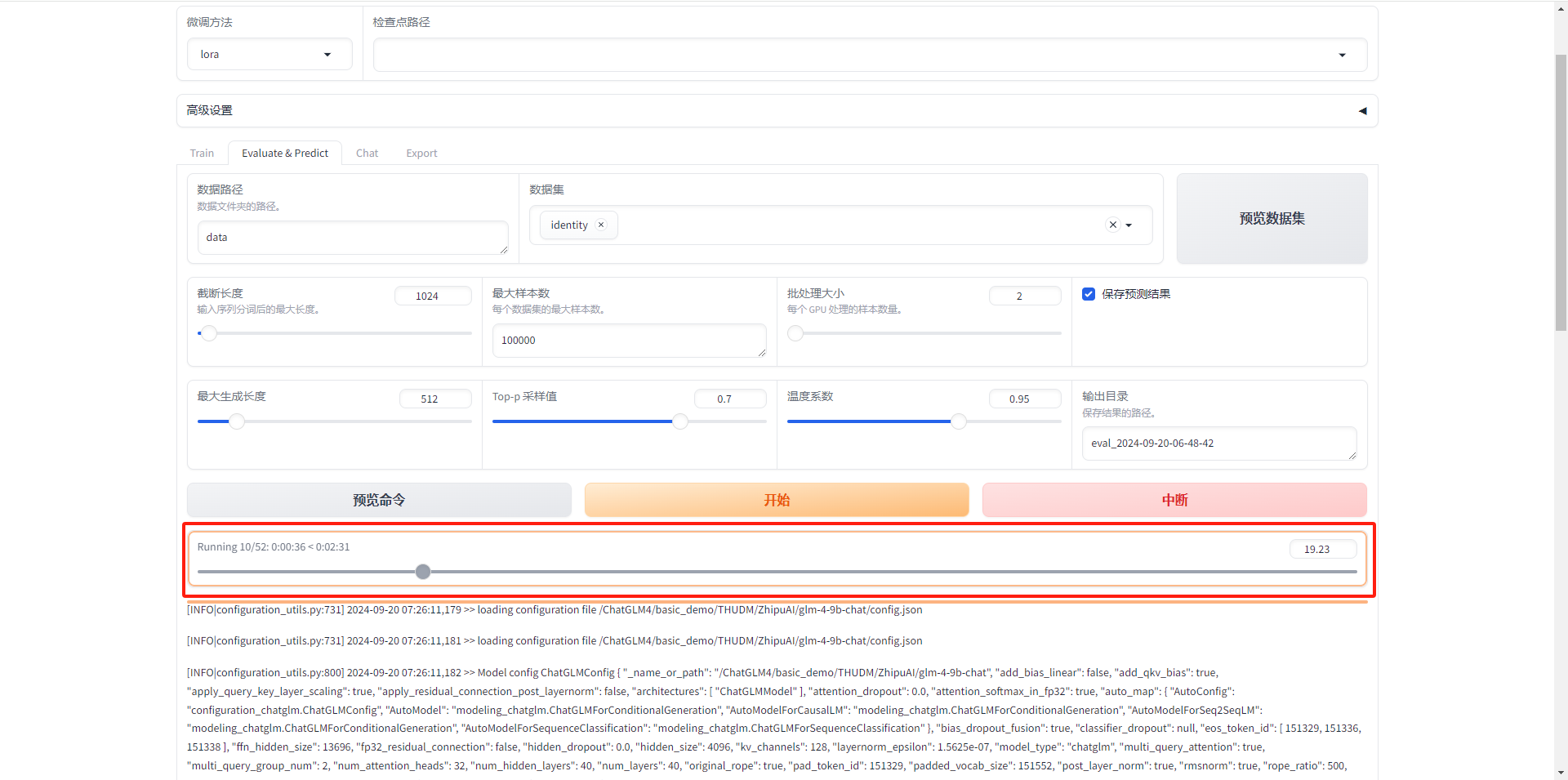
- 开始执行验证模型
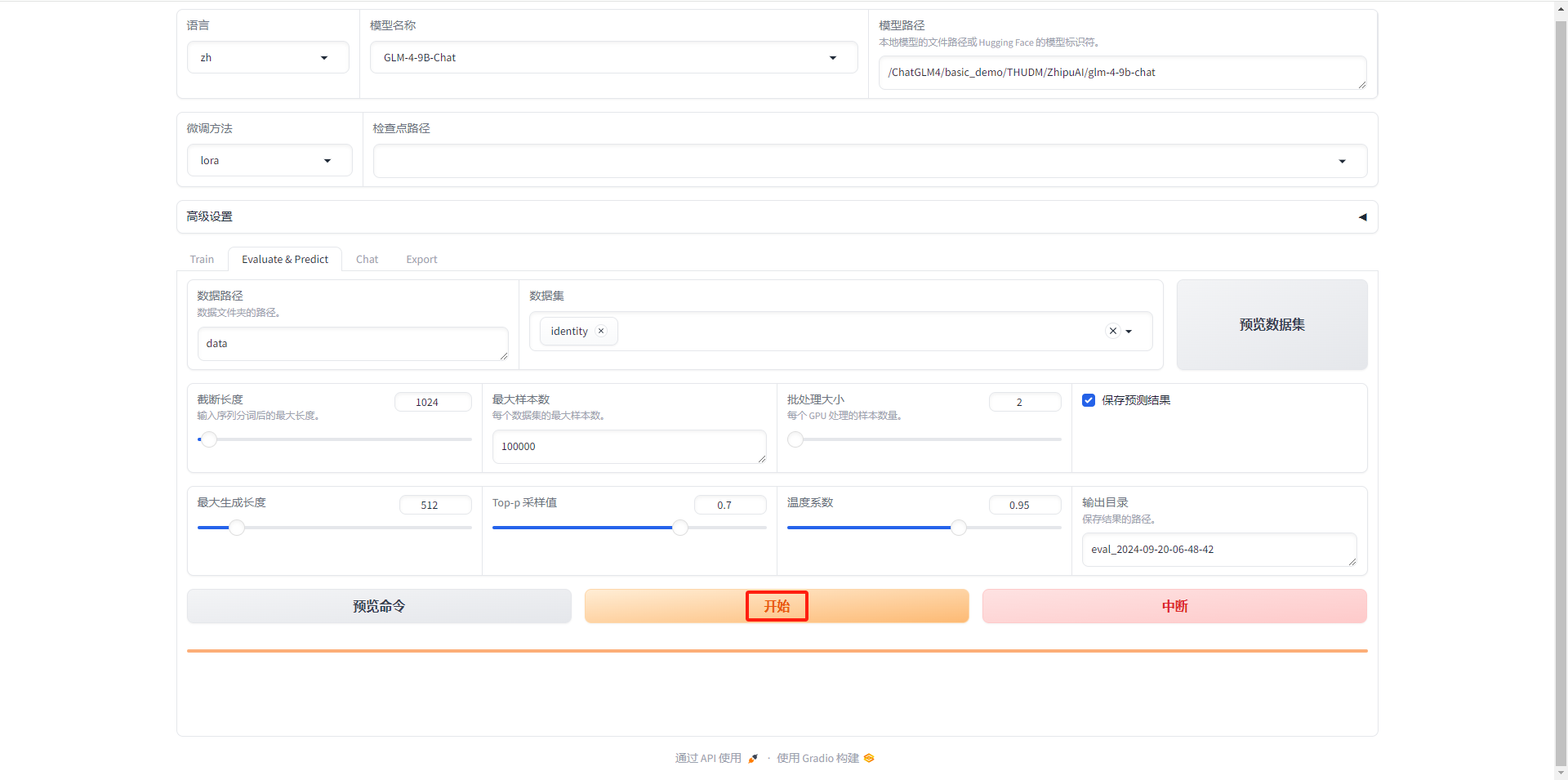
- 等待执行完成
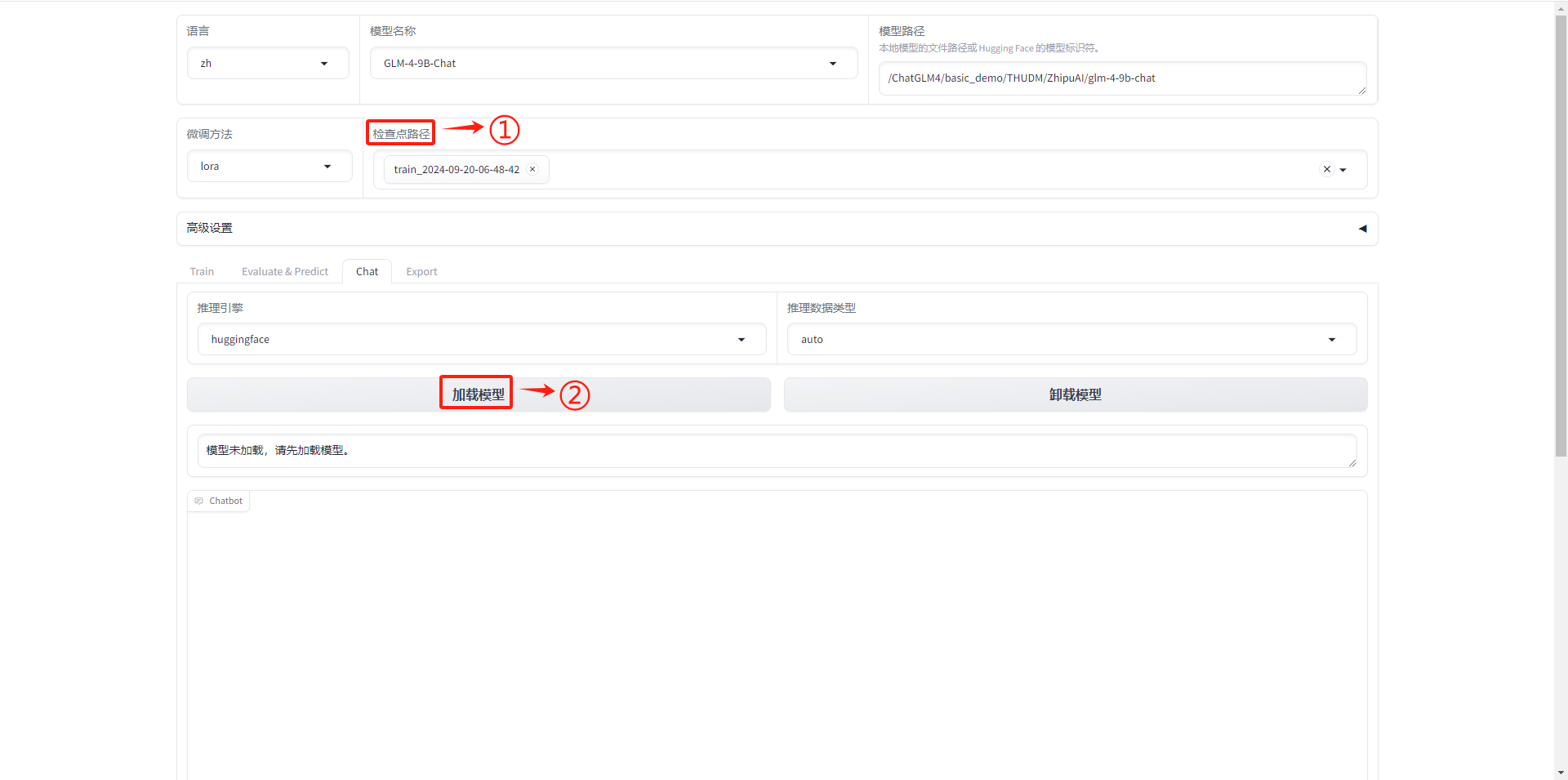
1.5.10 模型加载
- 加载模型检查点
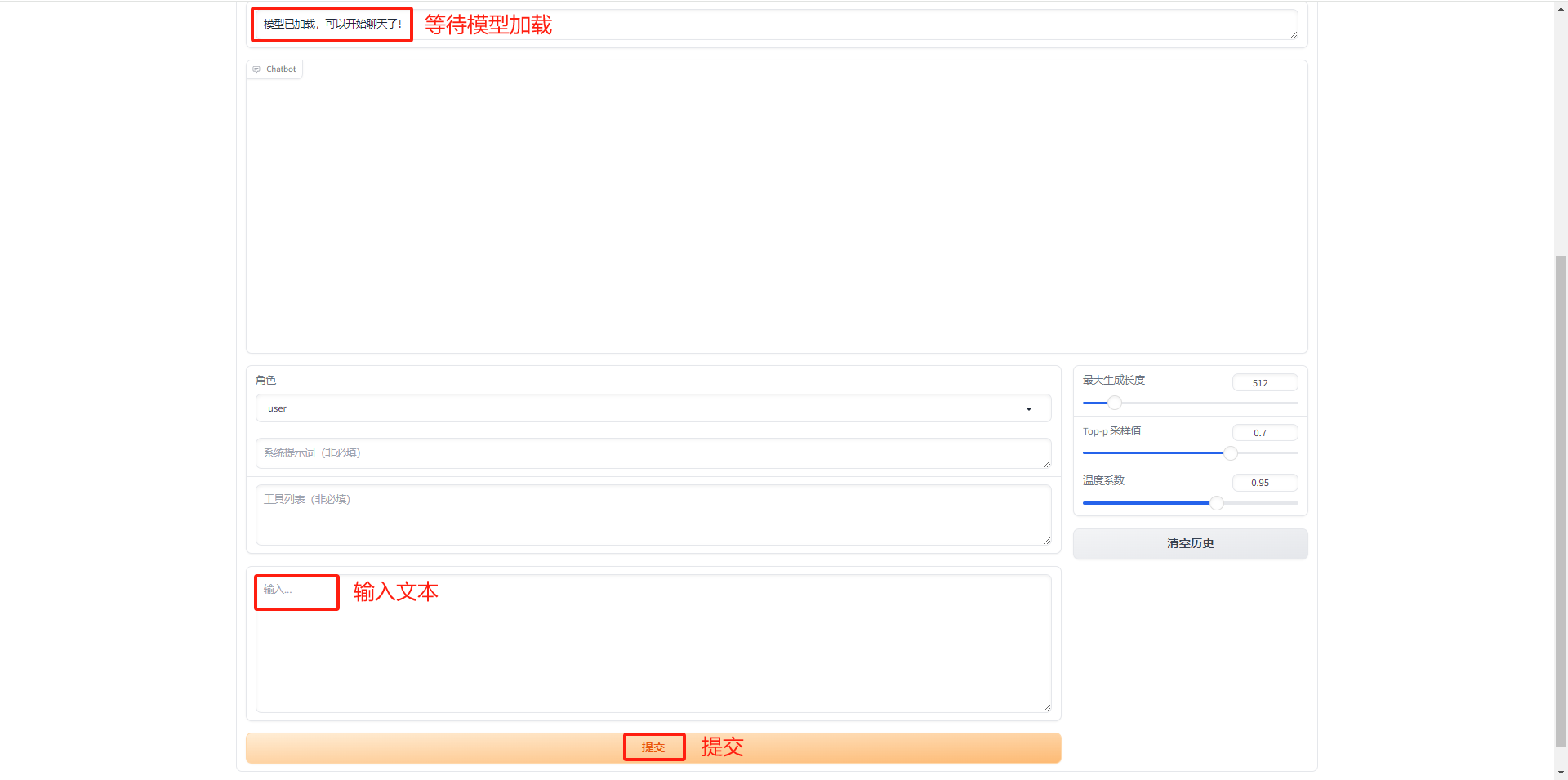
- 输入文本,进行对话
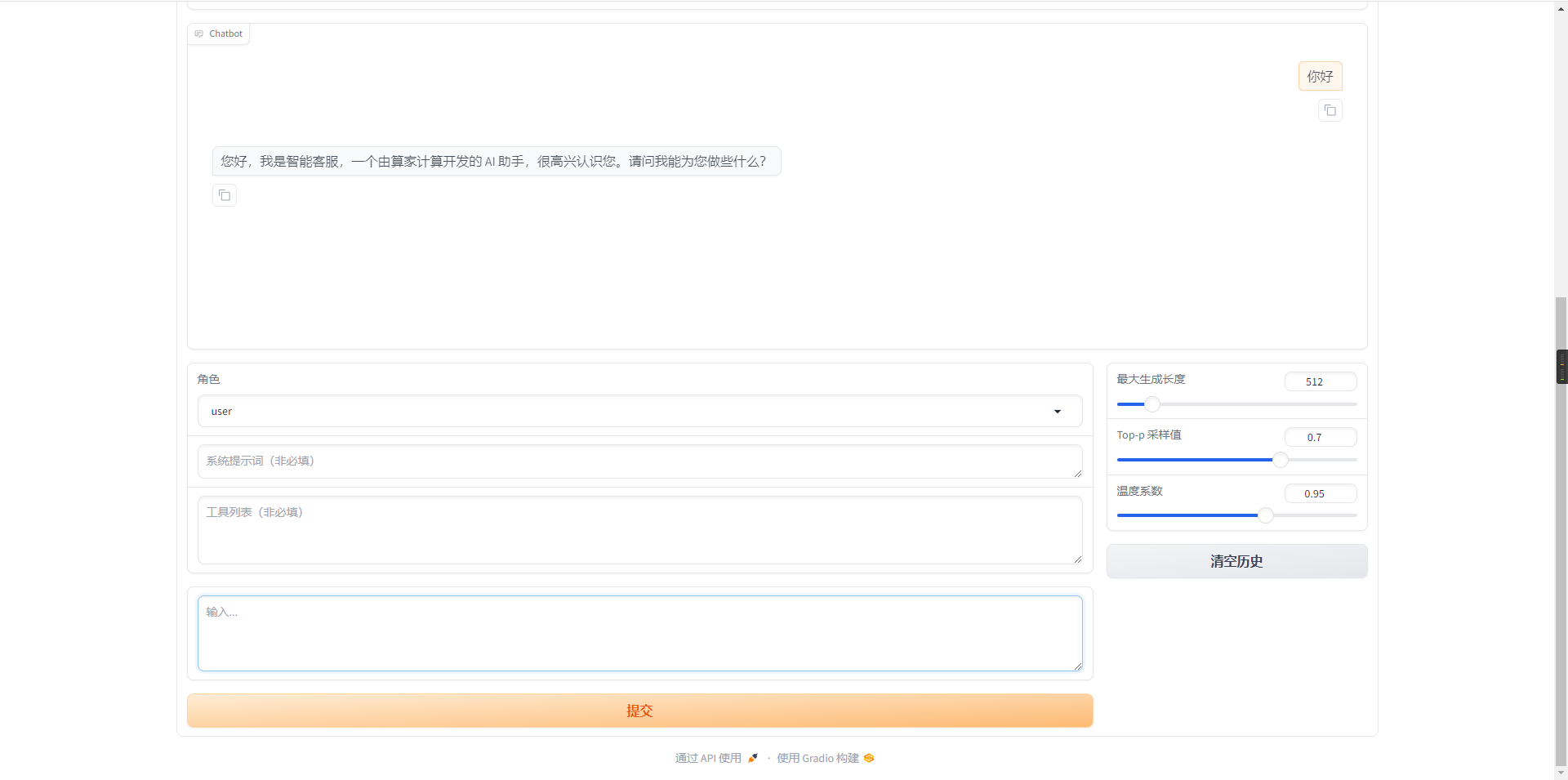
- 验证模型对话
1.5.11 模型合并
- 加载保存导出模型的文件夹路径
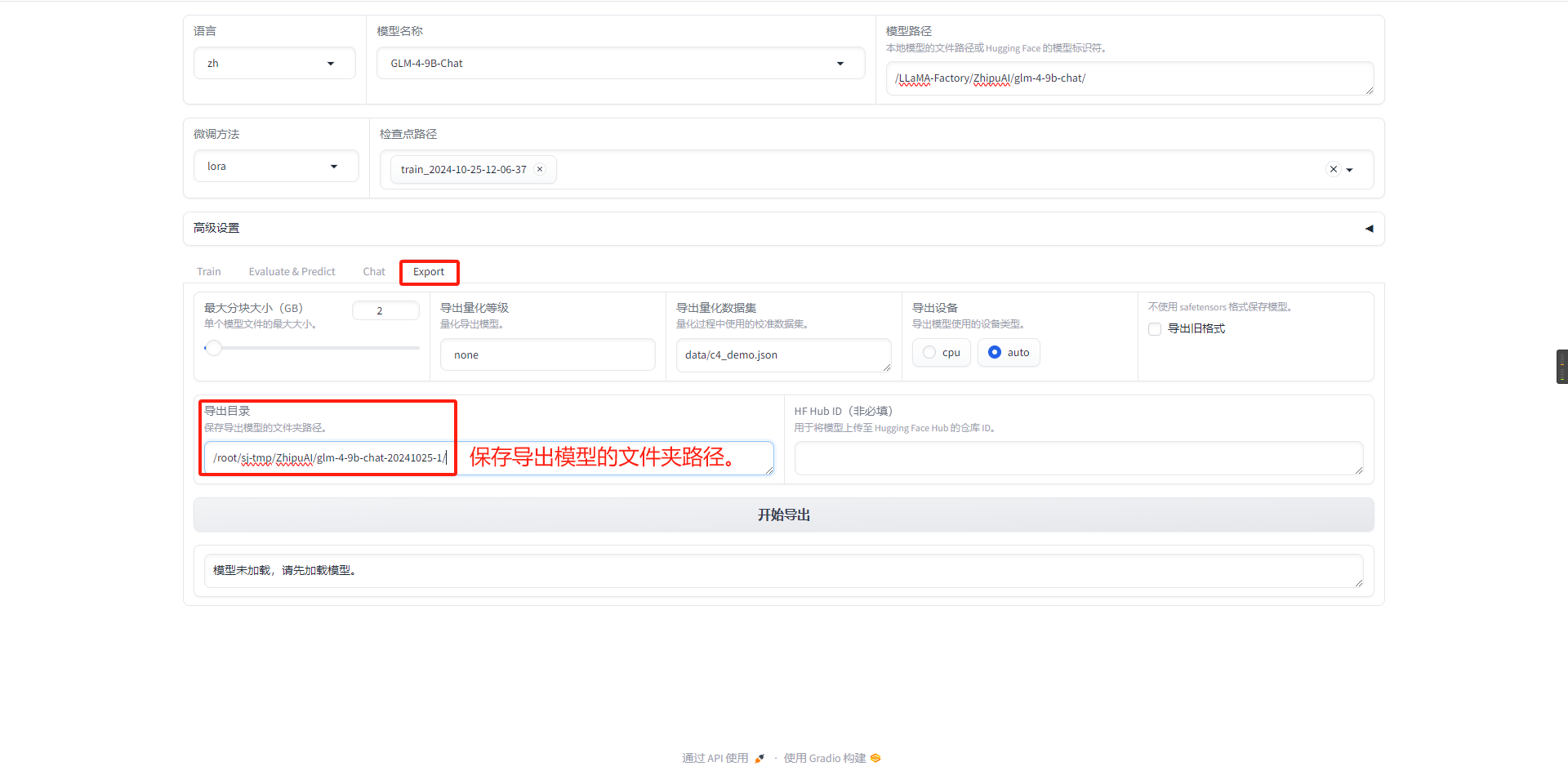
- web 完成页面
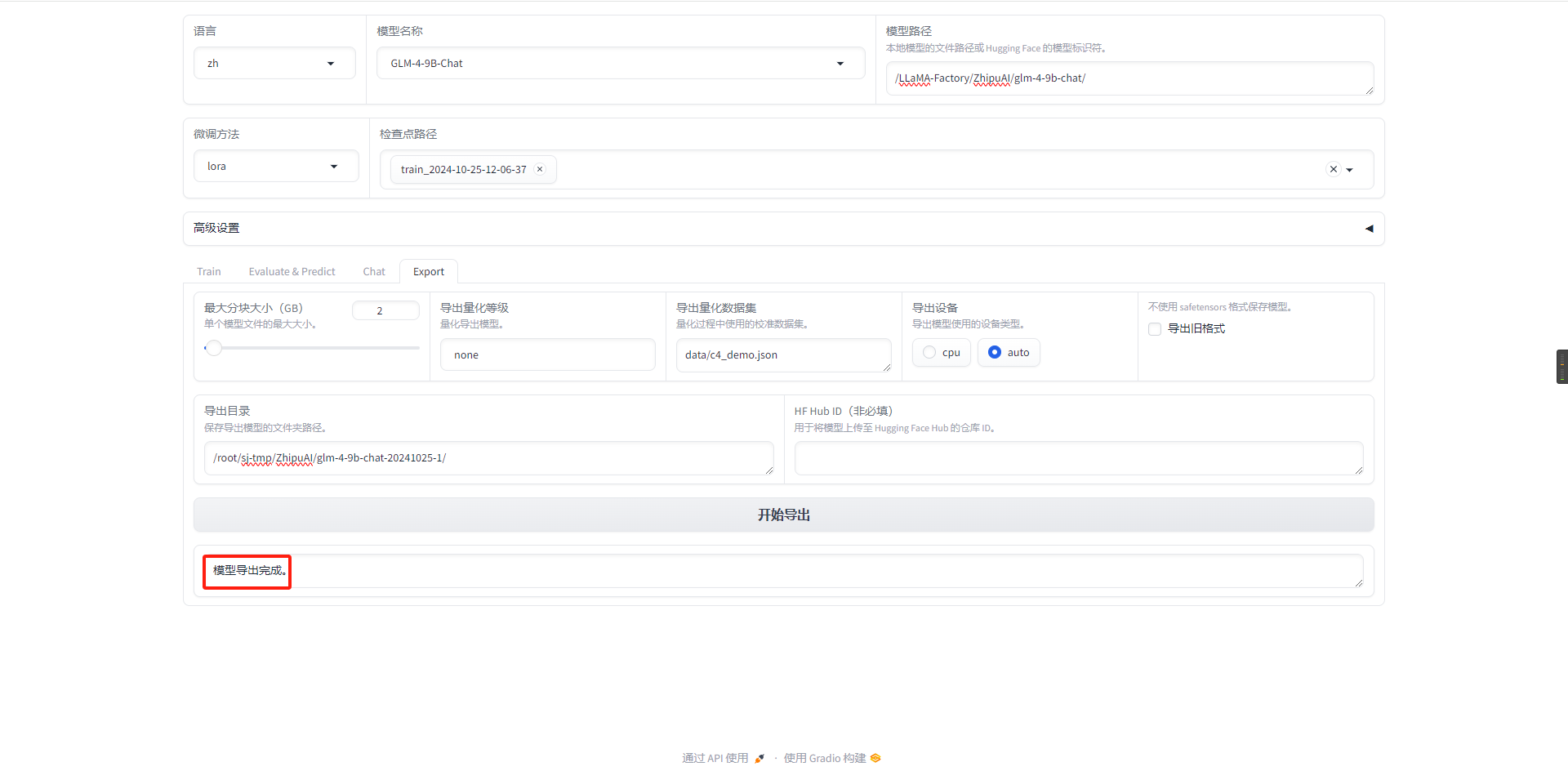
- 命令行完成页面
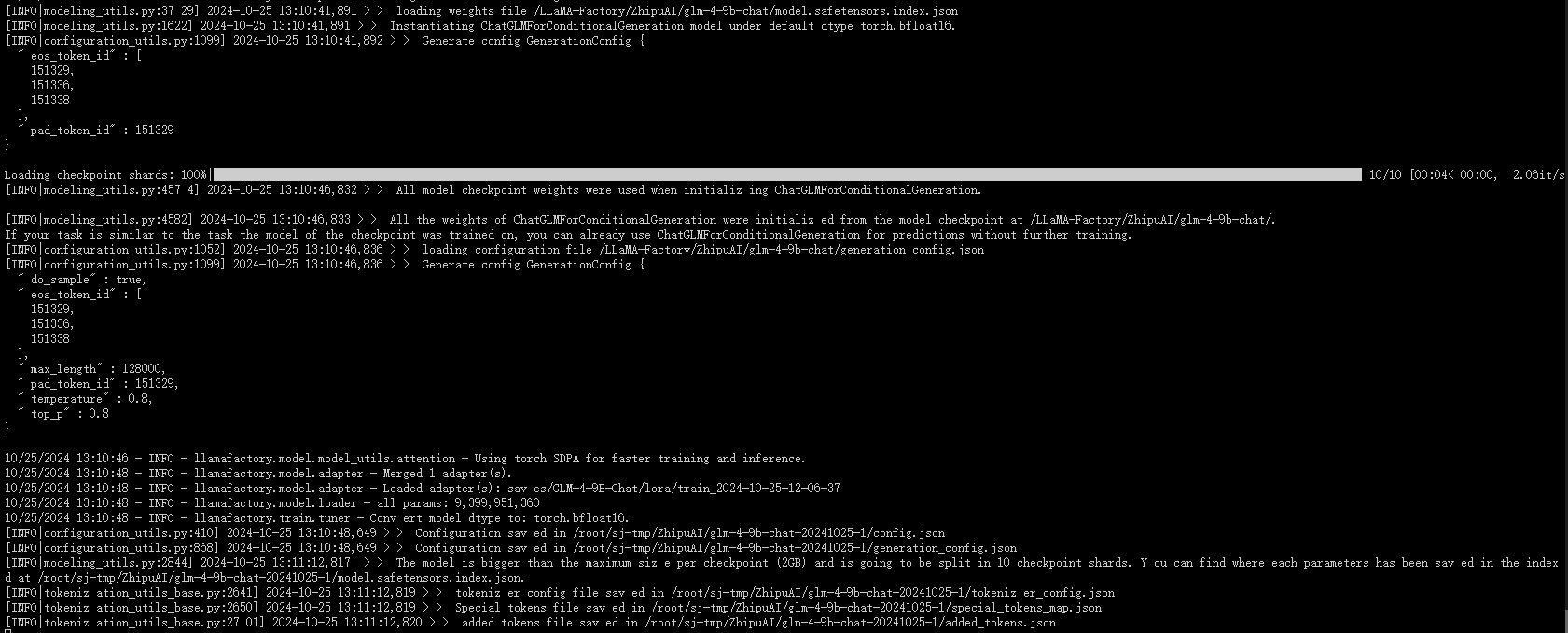
2 大模型 GLM4 微调调用
2.1 结束当前运行(按键盘上的 Ctrl + C)
![]()
2.2 从 github 仓库 克隆项目
- 克隆存储库:
#拉取代码
git clone https://github.com/THUDM/GLM-4.git

出现以上页面即是克隆项目成功!
请注意,如果 bash git clone https://github.com/THUDM/GLM-4.git 这个链接不存在或者无效,git clone 命令将不会成功克隆项目,并且会报错。确保链接是有效的,并且您有足够的权限访问该存储库。
2.3 修改微调后保存的模型、IP 以及端口
vim GLM-4/basic_demo/trans_web_demo.py
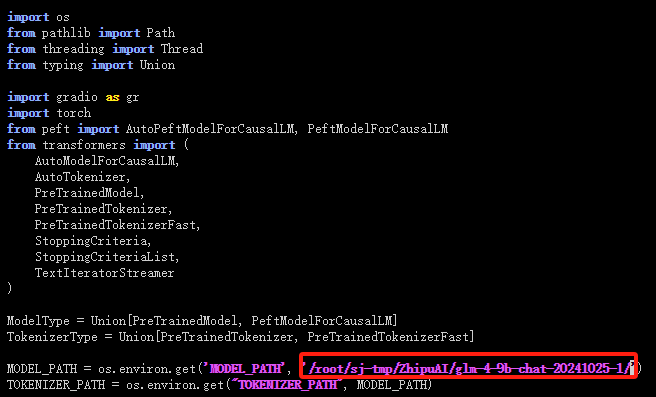
2.4 启动trans_web_demo.py 文件
# 启动 trans_web_demo.py 文件
python /GLM-4/basic_demo/trans_web_demo.py

2.5 访问端口,进行模型测试
测试结果如下
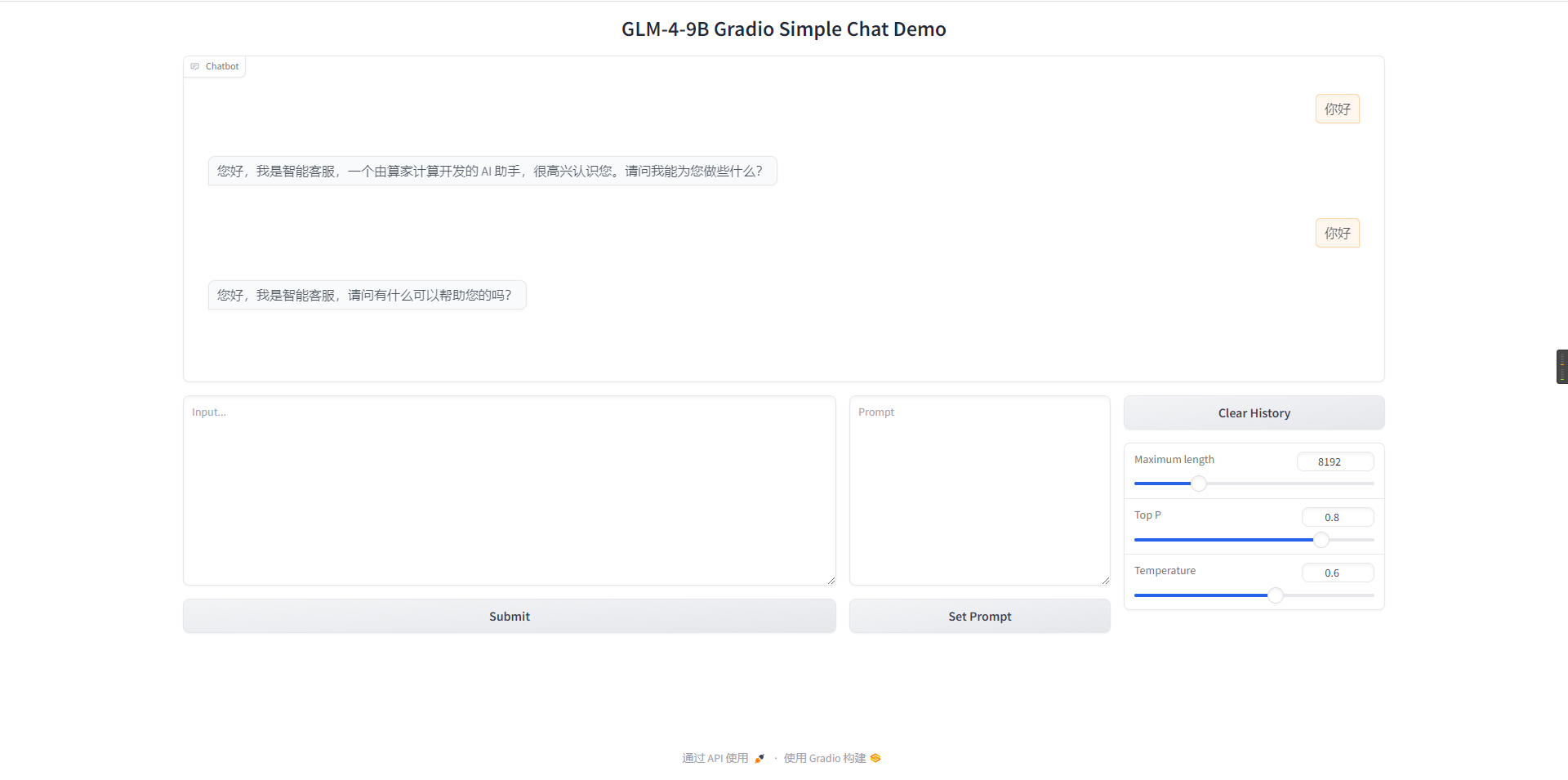
3.编辑trans_web_demo.py 文件连接 MongoDB 数据库
3.1 MongoDB配置
首先,在代码的开头部分定义了MongoDB的连接字符串 MONGO_URI、数据库名称 DB_NAME和集合名称 COLLECTION_NAME。这些变量用于指定MongoDB服务器的位置、要使用的数据库以及存储对话记录的集合。
# MongoDB配置
MONGO_URI = "mongodb://root:123456@localhost:27017/"
DB_NAME = "chat_records"
COLLECTION_NAME = "conversations"
3.2 连接MongoDB
接下来,使用 pymongo库来建立与MongoDB服务器的连接,并选择相应的数据库和集合。
# 连接MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]
这里,client对象代表与MongoDB服务器的连接,db对象表示选择了名为 chat_records的数据库,而 collection对象则指向了该数据库中的 conversations集合。
3.3 保存对话记录
为了将每次对话的结果保存到MongoDB,定义了一个名为 save_to_mongodb的函数。此函数接受用户消息和模型响应作为参数,并创建一个包含这些信息的新文档,同时添加了时间戳。
def save_to_mongodb(user_message: str, model_response: str):"""将对话记录保存至MongoDB"""record = {"user_message": user_message,"model_response": model_response,"timestamp": datetime.datetime.now() # 使用datetime模块获取当前时间}collection.insert_one(record)
在这个函数中,record字典包含了用户的消息、模型的响应以及当前的时间戳。通过调用 collection.insert_one(record)方法,可以将这条记录插入到MongoDB的 conversations集合中。
3.4 融入预测流程
当用户提交查询后,会触发 predict函数来生成模型的响应。一旦模型完成了对用户输入的处理并生成了响应,就会调用 save_to_mongodb函数来保存这次对话记录。
for new_token in streamer:if new_token:response += new_tokenhistory[-1][1] = responseyield history
# 当响应完成时,保存对话记录到MongoDB
save_to_mongodb(history[-1][0], response)
在这段代码中,当模型生成的响应流结束时,会调用 save_to_mongodb函数,将最后一次用户输入(history[-1][0])和模型生成的完整响应(response)作为参数传递给它,从而实现对话记录的保存。
3.5 融入全部 MongoDB 代码到 webui.py 文件
import os
from pathlib import Path
from threading import Thread
from typing import Union
import datetime # 导入datetime模块import gradio as gr
import pymongo
import torch
from peft import AutoPeftModelForCausalLM, PeftModelForCausalLM
from transformers import (AutoModelForCausalLM,AutoTokenizer,PreTrainedModel,PreTrainedTokenizer,PreTrainedTokenizerFast,StoppingCriteria,StoppingCriteriaList,TextIteratorStreamer
)ModelType = Union[PreTrainedModel, PeftModelForCausalLM]
TokenizerType = Union[PreTrainedTokenizer, PreTrainedTokenizerFast]MODEL_PATH = os.environ.get('MODEL_PATH', '/root/sj-tmp/ZhipuAI/glm-4-9b-chat-20241025-1/')
TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH", MODEL_PATH)# MongoDB配置
MONGO_URI = "mongodb://root:123456@localhost:27017/"
DB_NAME = "chat_records"
COLLECTION_NAME = "conversations"# 连接MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[DB_NAME]
collection = db[COLLECTION_NAME]def _resolve_path(path: Union[str, Path]) -> Path:return Path(path).expanduser().resolve()def load_model_and_tokenizer(model_dir: Union[str, Path], trust_remote_code: bool = True
) -> tuple[ModelType, TokenizerType]:model_dir = _resolve_path(model_dir)if (model_dir / 'adapter_config.json').exists():model = AutoPeftModelForCausalLM.from_pretrained(model_dir, trust_remote_code=trust_remote_code, device_map='auto')tokenizer_dir = model.peft_config['default'].base_model_name_or_pathelse:model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=trust_remote_code, device_map='auto')tokenizer_dir = model_dirtokenizer = AutoTokenizer.from_pretrained(tokenizer_dir, trust_remote_code=trust_remote_code, use_fast=False)return model, tokenizermodel, tokenizer = load_model_and_tokenizer(MODEL_PATH, trust_remote_code=True)class StopOnTokens(StoppingCriteria):def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:stop_ids = model.config.eos_token_idfor stop_id in stop_ids:if input_ids[0][-1] == stop_id:return Truereturn Falsedef save_to_mongodb(user_message: str, model_response: str):"""将对话记录保存至MongoDB"""record = {"user_message": user_message,"model_response": model_response,"timestamp": datetime.datetime.now() # 使用datetime模块获取当前时间}collection.insert_one(record)def predict(history, prompt, max_length, top_p, temperature):stop = StopOnTokens()messages = []if prompt:messages.append({"role": "system", "content": prompt})for idx, (user_msg, model_msg) in enumerate(history):if prompt and idx == 0:continueif idx == len(history) - 1 and not model_msg:messages.append({"role": "user", "content": user_msg})breakif user_msg:messages.append({"role": "user", "content": user_msg})if model_msg:messages.append({"role": "assistant", "content": model_msg})model_inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt").to(next(model.parameters()).device)streamer = TextIteratorStreamer(tokenizer, timeout=60, skip_prompt=True, skip_special_tokens=True)generate_kwargs = {"input_ids": model_inputs,"streamer": streamer,"max_new_tokens": max_length,"do_sample": True,"top_p": top_p,"temperature": temperature,"stopping_criteria": StoppingCriteriaList([stop]),"repetition_penalty": 1.2,"eos_token_id": model.config.eos_token_id,}t = Thread(target=model.generate, kwargs=generate_kwargs)t.start()response = ""for new_token in streamer:if new_token:response += new_tokenhistory[-1][1] = responseyield history# 当响应完成时,保存对话记录到MongoDBsave_to_mongodb(history[-1][0], response)with gr.Blocks() as demo:gr.HTML("""<h1 align="center">GLM-4-9B Gradio Simple Chat Demo</h1>""")chatbot = gr.Chatbot()with gr.Row():with gr.Column(scale=3):with gr.Column(scale=12):user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10, container=False)with gr.Column(min_width=32, scale=1):submitBtn = gr.Button("Submit")with gr.Column(scale=1):prompt_input = gr.Textbox(show_label=False, placeholder="Prompt", lines=10, container=False)pBtn = gr.Button("Set Prompt")with gr.Column(scale=1):emptyBtn = gr.Button("Clear History")max_length = gr.Slider(0, 32768, value=8192, step=1.0, label="Maximum length", interactive=True)top_p = gr.Slider(0, 1, value=0.8, step=0.01, label="Top P", interactive=True)temperature = gr.Slider(0.01, 1, value=0.6, step=0.01, label="Temperature", interactive=True)def user(query, history):return "", history + [[query, ""]]def set_prompt(prompt_text):return [[prompt_text, "成功设置prompt"]]pBtn.click(set_prompt, inputs=[prompt_input], outputs=chatbot)submitBtn.click(user, [user_input, chatbot], [user_input, chatbot], queue=False).then(predict, [chatbot, prompt_input, max_length, top_p, temperature], chatbot)emptyBtn.click(lambda: (None, None), None, [chatbot, prompt_input], queue=False)demo.queue()
demo.launch(server_name="0.0.0.0", server_port=8080, inbrowser=True, share=True)
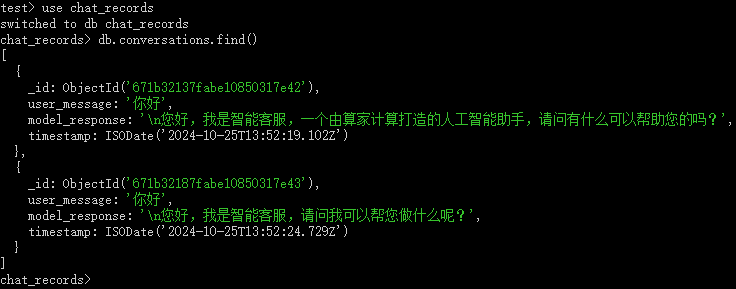
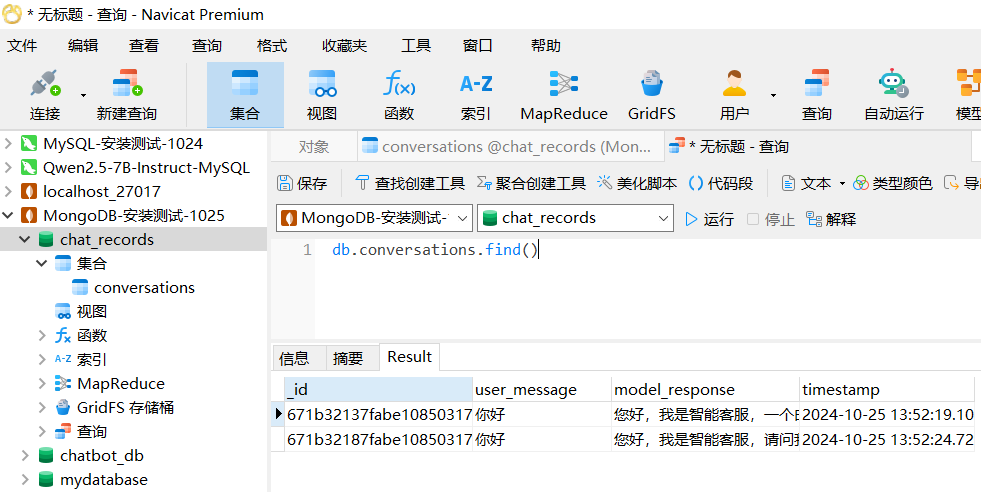
4. 测试 MongoDB 是否正常连接到对话过程
4.1 启动 webui.py 文件
- 安装
pymongo
pip install pymongo
- 启动 trans_web_demo.py 文件
# 启动 webui.py 文件
python /GLM-4/basic_demo/trans_web_demo.py
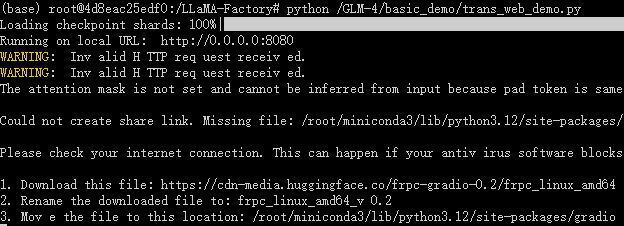
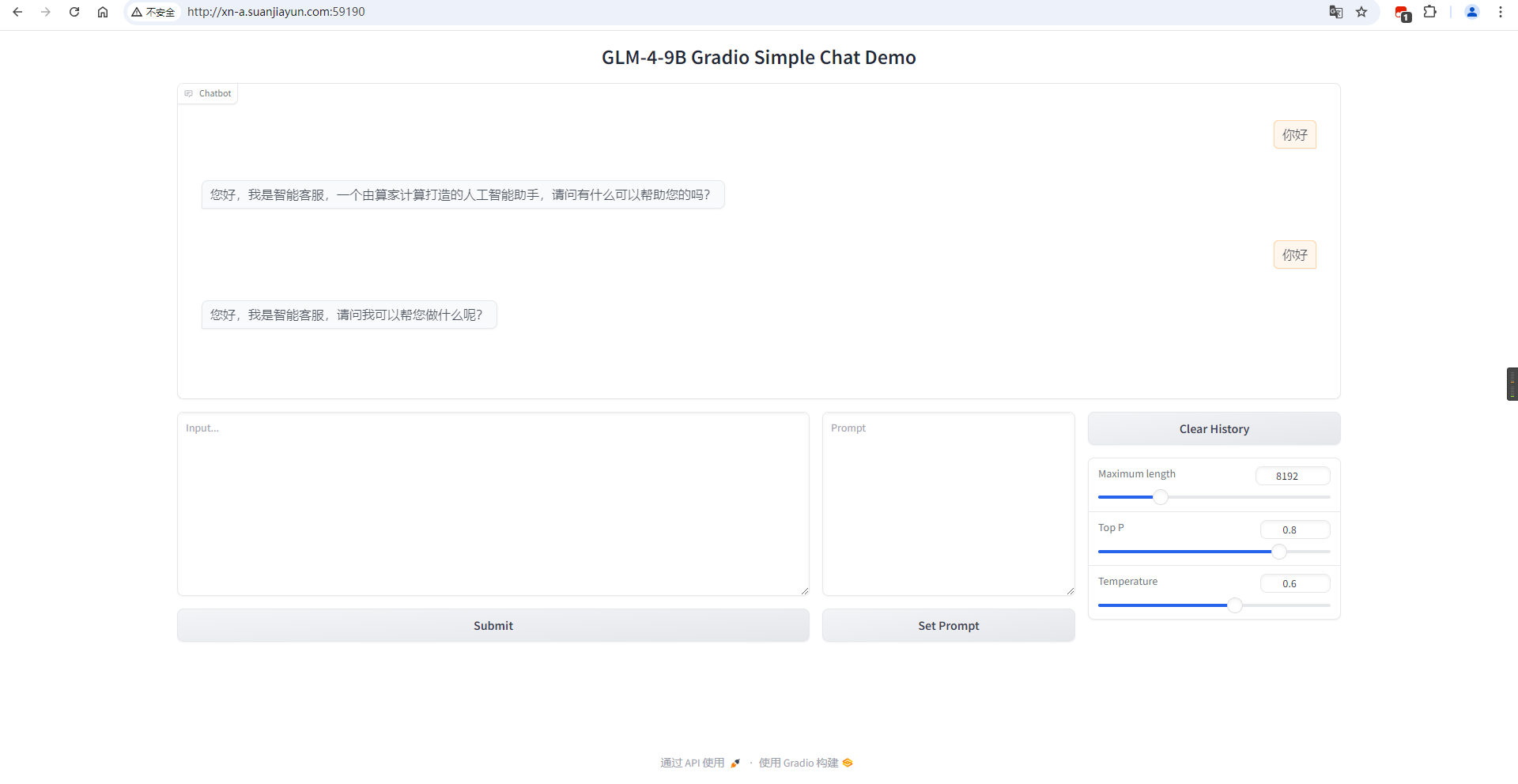
4.2 访问端口,进行模型测试
- Gradio 测试结果如下
- 命令行测试结果如下
- Navicat 测试结果如下
到此,在 Ubuntu 22.04 上安装 MongoDB Community Edition 进行 GLM4 模型微调的对话数据收集到此就结束了。






