
自己训练模pth报错
le "D:\ai\dh_live\app.py", line 42, in demo_mini
interface_mini(asset_path, wav_path, output_video_name)
File "D:\ai\dh_live\demo_mini.py", line 21, in interface_mini
renderModel_mini.loadModel("checkpoint/DINet_mini/epoch_40.pth")
File "D:\ai\dh_live\talkingface\render_model_mini.py", line 24, in loadModel
self.net.infer_model.load_state_dict(net_g_static)
File "D:\CyberWin\devpro\Python311\Lib\site-packages\torch\nn\modules\module.py", line 2581, in load_state_dict
raise RuntimeError(
RuntimeError: Error(s) in loading state_dict for DINet_mini:
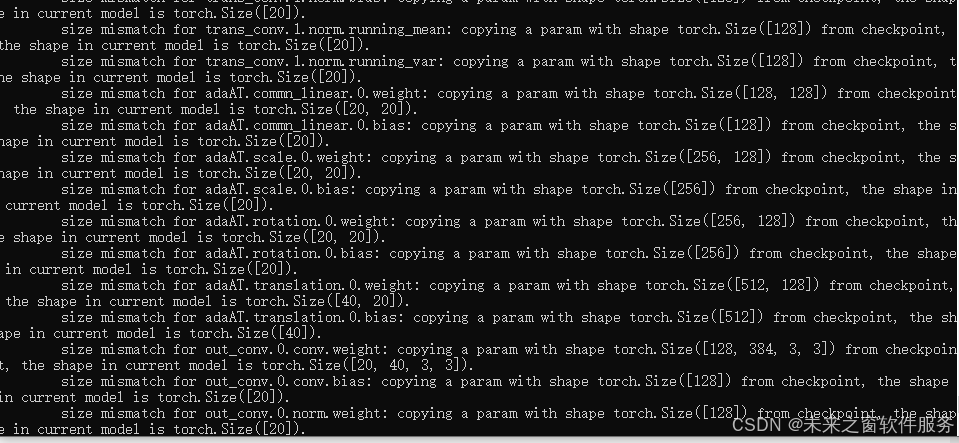
Missing key(s) in state_dict: "ref_in_conv.3.conv.weight", "ref_in_conv.3.conv.bias", "ref_in_conv.3.norm.weight", "ref_in_conv.3.norm.bias", "ref_in_conv.3.norm.running_mean", "ref_in_conv.3.norm.running_var", "appearance_conv.0.conv1.weight", "appearance_conv.0.conv1.bias", "appearance_conv.0.conv2.weight", "appearance_conv.0.conv2.bias", "appearance_conv.0.norm1.weight", "appearance_conv.0.norm1.bias", "appearance_conv.0.norm1.running_mean", "appearance_conv.0.norm1.running_var", "appearance_conv.0.norm2.weight", "appearance_conv.0.norm2.bias", "appearance_conv.0.norm2.running_mean", "appearance_conv.0.norm2.running_var", "out_conv.2.conv.weight", "out_conv.2.conv.bias", "out_conv.2.norm.weight", "out_conv.2.norm.bias", "out_conv.2.norm.running_mean", "out_conv.2.norm.running_var".
Unexpected key(s) in state_dict: "appearance_conv_list.0.0.conv1.weight", "appearance_conv_list.0.0.conv1.bias", "appearance_conv_list.0.0.conv2.weight", "appearance_conv_list.0.0.conv2.bias", "appearance_conv_list.0.0.norm1.weight", "appearance_conv_list.0.0.norm1.bias", "appearance_conv_list.0.0.norm1.running_mean", "appearance_conv_list.0.0.norm1.running_var", "appearance_conv_list.0.0.norm1.num_batches_tracked", "appearance_conv_list.0.0.norm2.weight", "appearance_conv_list.0.0.norm2.bias", "appearance_conv_list.0.0.norm2.running_mean", "appearance_conv_list.0.0.norm2.running_var", "appearance_conv_list.0.0.norm2.num_batches_tracked", "appearance_conv_list.0.1.conv1.weight", "appearance_conv_list.0.1.conv1.bias", "appearance_conv_list.0.1.conv2.weight", "appearance_conv_list.0.1.conv2.bias", "appearance_conv_list.0.1.norm1.weight", "appearance_conv_list.0.1.norm1.bias", "appearance_conv_list.0.1.norm1.running_mean", "appearance_conv_list.0.1.norm1.running_var", "appearance_conv_list.0.
To create a public link, set `share=True` in `launch()`.
ffmpeg -i G:\C盘临时缓存\Temp\gradio\93e68ec176966d4d582e464f62c252b2594238a1f21b8ae03549ab7588398fed\test.wav -ac 1 -ar 16000 -y video_data/tmp.wav
ffmpeg version N-118789-gb5be0c0aa9-20250316 Copyright (c) 2000-2025 the FFmpeg developersbuilt with gcc 14.2.0 (crosstool-NG 1.27.0.18_7458341)configuration: --prefix=/ffbuild/prefix --pkg-config-flags=--static --pkg-config=pkg-config --cross-prefix=x86_64-w64-mingw32- --arch=x86_64 --target-os=mingw32 --enable-gpl --enable-version3 --disable-debug --enable-shared --disable-static --disable-w32threads --enable-pthreads --enable-iconv --enable-zlib --enable-libfreetype --enable-libfribidi --enable-gmp --enable-libxml2 --enable-lzma --enable-fontconfig --enable-libharfbuzz --enable-libvorbis --enable-opencl --disable-libpulse --enable-libvmaf --disable-libxcb --disable-xlib --enable-amf --enable-libaom --enable-libaribb24 --enable-avisynth --enable-chromaprint --enable-libdav1d --enable-libdavs2 --enable-libdvdread --enable-libdvdnav --disable-libfdk-aac --enable-ffnvcodec --enable-cuda-llvm --enable-frei0r --enable-libgme --enable-libkvazaar --enable-libaribcaption --enable-libass --enable-libbluray --enable-libjxl --enable-libmp3lame --enable-libopus --enable-librist --enable-libssh --enable-libtheora --enable-libvpx --enable-libwebp --enable-libzmq --enable-lv2 --enable-libvpl --enable-openal --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenh264 --enable-libopenjpeg --enable-libopenmpt --enable-librav1e --enable-librubberband --enable-schannel --enable-sdl2 --enable-libsnappy --enable-libsoxr --enable-libsrt --enable-libsvtav1 --enable-libtwolame --enable-libuavs3d --disable-libdrm --enable-vaapi --enable-libvidstab --enable-vulkan --enable-libshaderc --enable-libplacebo --disable-libvvenc --enable-libx264 --enable-libx265 --enable-libxavs2 --enable-libxvid --enable-libzimg --enable-libzvbi --extra-cflags=-DLIBTWOLAME_STATIC --extra-cxxflags= --extra-libs=-lgomp --extra-ldflags=-pthread --extra-ldexeflags= --cc=x86_64-w64-mingw32-gcc --cxx=x86_64-w64-mingw32-g++ --ar=x86_64-w64-mingw32-gcc-ar --ranlib=x86_64-w64-mingw32-gcc-ranlib --nm=x86_64-w64-mingw32-gcc-nm --extra-version=20250316libavutil 59. 59.100 / 59. 59.100libavcodec 61. 33.102 / 61. 33.102libavformat 61. 9.107 / 61. 9.107libavdevice 61. 4.100 / 61. 4.100libavfilter 10. 9.100 / 10. 9.100libswscale 8. 13.102 / 8. 13.102libswresample 5. 4.100 / 5. 4.100libpostproc 58. 4.100 / 58. 4.100
[aist#0:0/pcm_s16le @ 00000231d6f122c0] Guessed Channel Layout: mono
Input #0, wav, from 'G:\C盘临时缓存\Temp\gradio\93e68ec176966d4d582e464f62c252b2594238a1f21b8ae03549ab7588398fed\test.wav':Metadata:comment : vid:v0200fg10000c7e0kdbc77u98d4v9c9gencoder : Lavf59.28.100Duration: 00:00:07.62, bitrate: 256 kb/sStream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/s
Stream mapping:Stream #0:0 -> #0:0 (pcm_s16le (native) -> pcm_s16le (native))
Press [q] to stop, [?] for help
Output #0, wav, to 'video_data/tmp.wav':Metadata:ICMT : vid:v0200fg10000c7e0kdbc77u98d4v9c9gISFT : Lavf61.9.107Stream #0:0: Audio: pcm_s16le ([1][0][0][0] / 0x0001), 16000 Hz, mono, s16, 256 kb/sMetadata:encoder : Lavc61.33.102 pcm_s16le
[out#0/wav @ 00000231d6e5cc40] video:0KiB audio:238KiB subtitle:0KiB other streams:0KiB global headers:0KiB muxing overhead: 0.050879%
size= 238KiB time=00:00:07.61 bitrate= 256.1kbits/s speed=22.7x
Traceback (most recent call last):File "D:\CyberWin\devpro\Python311\Lib\site-packages\gradio\queueing.py", line 625, in process_eventsresponse = await route_utils.call_process_api(^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\gradio\route_utils.py", line 322, in call_process_apioutput = await app.get_blocks().process_api(^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\gradio\blocks.py", line 2103, in process_apiresult = await self.call_function(^^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\gradio\blocks.py", line 1650, in call_functionprediction = await anyio.to_thread.run_sync( # type: ignore^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\anyio\to_thread.py", line 56, in run_syncreturn await get_async_backend().run_sync_in_worker_thread(^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\anyio\_backends\_asyncio.py", line 2470, in run_sync_in_worker_threadreturn await future^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\anyio\_backends\_asyncio.py", line 967, in runresult = context.run(func, *args)^^^^^^^^^^^^^^^^^^^^^^^^File "D:\CyberWin\devpro\Python311\Lib\site-packages\gradio\utils.py", line 890, in wrapperresponse = f(*args, **kwargs)^^^^^^^^^^^^^^^^^^File "D:\ai\dh_live\app.py", line 42, in demo_miniinterface_mini(asset_path, wav_path, output_video_name)File "D:\ai\dh_live\demo_mini.py", line 19, in interface_minifrom talkingface.render_model_mini import RenderModel_MiniFile "D:\ai\dh_live\talkingface\render_model_mini.py", line 28 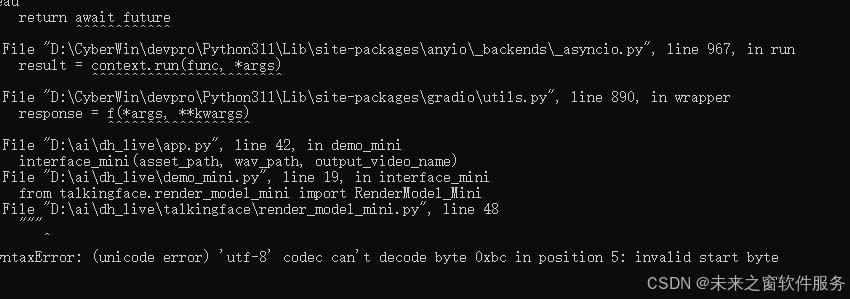
File "D:\ai\dh_live\app.py", line 42, in demo_mini
interface_mini(asset_path, wav_path, output_video_name)
File "D:\ai\dh_live\demo_mini.py", line 21, in interface_mini
renderModel_mini.loadModel("checkpoint/DINet_mini/epoch_40.pth")
File "D:\ai\dh_live\talkingface\render_model_mini.py", line 57, in loadModel
RuntimeError: dictionary changed size during iteration
File "D:\ai\dh_live\app.py", line 42, in demo_mini
interface_mini(asset_path, wav_path, output_video_name)
File "D:\ai\dh_live\demo_mini.py", line 21, in interface_mini
renderModel_mini.loadModel("checkpoint/DINet_mini/epoch_40.pth")
File "D:\ai\dh_live\talkingface\render_model_mini.py", line 61, in loadModel
NameError: name 'net_g_static' is not defined
e "D:\ai\dh_live\talkingface\render_model_mini.py", line 62, in loadModelFile "D:\CyberWin\devpro\Python311\Lib\site-packages\torch\nn\modules\module.py", line 2581, in load_state_dictraise RuntimeError(
RuntimeError: Error(s) in loading state_dict for DINet_mini:size mismatch for source_in_conv.0.conv.weight: copying a param with shape torch.Size([32, 6, 7, 7]) from checkpoint, the shape in current model is torch.Size([12, 3, 3, 3]).FileNotFoundError: [Errno 2] No such file or directory: 'assets\\combined_data.json.gz'





