文章目录
- 一、 窗口函数
- 1.1 OFFSET(动态查询、求连续值)
- 1.1.1 不使用orderBy
- 1.1.2 使用orderBy
- 1.1.3 统计连续值的最大出现次数(待补)
- 1.2 INDEX(静态查询)
- 1.3 WINDOW(滚动求和、累计求和、帕累托分析)
- 1.3.1 滚动求和与累计求和
- 1.3.2 帕累托分析
- 1.4 RANK(待补)
- 1.5 ROWNUMBER(待补)
- 二、视觉计算简介
- 2.1 添加视觉计算
- 2.2 隐藏视觉中的字段
- 2.3 快捷模板
- 2.4 可选参数
- 2.4.1 Axis参数(轴)
- 2.4.2 Reset参数(重置)
- 2.4.3 对比 ORDERBY 和 PARTITIONBY
- 2.5 设置视觉对象计算的格式
- 2.6 预览期间的限制
- 三、 视觉计算原理
- 3.1 SUMMARIZECOLUMNS 与 ROLLUPADDISSUBTOTAL
- 3.2 DAX 查询生成扁平表
- 3.3 VISUAL SHAPE定义层次结构
- 3.4 视觉计算依赖轴定义
- 3.5 使用视觉上下文函数导航虚拟表
- 3.6 COLLAPSE和EXPAND函数的导航规则
- 3.6.1 使用轴作为参数
- 3.6.2 使用列作为参数
- 四、常用视觉计算函数
- 4.1 PREVIOUS、NEXT、FIRST、LAST
- 4.2 RUNNINGSUM:运动求和
- 4.3 MOVINGAVERAGE:移动平均
- 4.4 COLLAPSE 和 COLLAPSEALL
- 4.4.1 基础用法
- 4.4.2 计算各种占比
- 4.5 EXPAND和EXPANDALL
- 4.6 ROWNUMBER
- 五、进阶示例(待补)
- 5.1 可视化排序
- 5.2 动态排序
一、 窗口函数
参考《OFFSET、INDEX、WINDOW介绍》
2022年的最后一次更新,正式发布了三个新的DAX函数,OFFSET、INDEX、WINDOW,下面看一下这三个函数的用法。
- OFFSET:用于在表格中移动行或列,获取偏移后位置的值。
- INDEX:用于根据索引值直接访问表格中的特定单元格。
- WINDOW:用于定义一个窗口范围,并对窗口内的数据进行计算
1.1 OFFSET(动态查询、求连续值)
OFFSET函数用于检索表中偏移特定行后的结果,可返回多行(多个结果时),其语法为:
OFFSET(delta, // 偏移的行数,可以是任何返回标量的DAX表达式。正值表示当前行之后,负值表示当前行之前<relation> or <axis>, // 可选,前者为表表达式,后者为视觉形状中的轴(替换 relation)orderBy, // 可选,定义每个分区的排序方式,可以是表达式。如省略,第二个参数须显示指定blanks, // 可选,指定空值处理方式partitionBy, // 可选,分区依据,如果省略,视同只有一个分区matchBy, // 可选,定义如何匹配数据和标识当前行reset // 可选,整数或字段引用。
)
relation:从中返回输出行的表- 如果指定,partitionBy 中的所有列必须来自它或相关表。
- 如果省略,则必须显式指定 orderBy。
- 默认为 orderBy 和 partitionBy 中所有列的
ALLSELECTED()
matchBy:- 如果存在,OFFSET 将尝试使用matchBy 中的列和 partitionBy 列来标识行
- 如果不存在,并且 orderBy 中指定的列和 partitionBy 无法唯一标识 relation 中的每一行,则可能返回错误
blanks:定义在排序时如何处理空值DEFAULT(默认):数值为空值时,在零值和负值之间排序;字符串为空值时,在所有字符串之前排序。FIRST:BLANK(空白)始终排在开头LAST:BLANK始终排在在末尾
reset:仅在视觉计算中可用,指示计算是否重置- 如果为零或省略,计算不会重置
- 正值:重置到最高层次的列(与粒度无关)
- 负值:重置到最低层次的列。
1.1.1 不使用orderBy
示例:对于一个按季度统计的销售表,如果要获得上个季度的销售额,除了用之前的时间智能函数,还可以这样写:
// OFFSET返回表,度量值中一般利用CALCULATE来返回定位后的结果
OFFSET =CALCULATE([销售额],OFFSET(-1, // 向前偏移1行ALLSELECTED('日期表'[年度季度])) // 输出'日期表'[年度季度])
)
第3个参数ORDERBY省略,默认按照第二个参数列排序,也就是按年度季度排序。向前偏移一行,就得到了上个季度的数据。如果想在每年范围内进行这样的偏移计算,就需要用到最后一个参数进行分区:
OFFSET =CALCULATE([销售额],OFFSET(-1,ALLSELECTED('日期表'[年度季度],'日期表'[年度]),,,PARTITIONBY('日期表'[年度]))
)
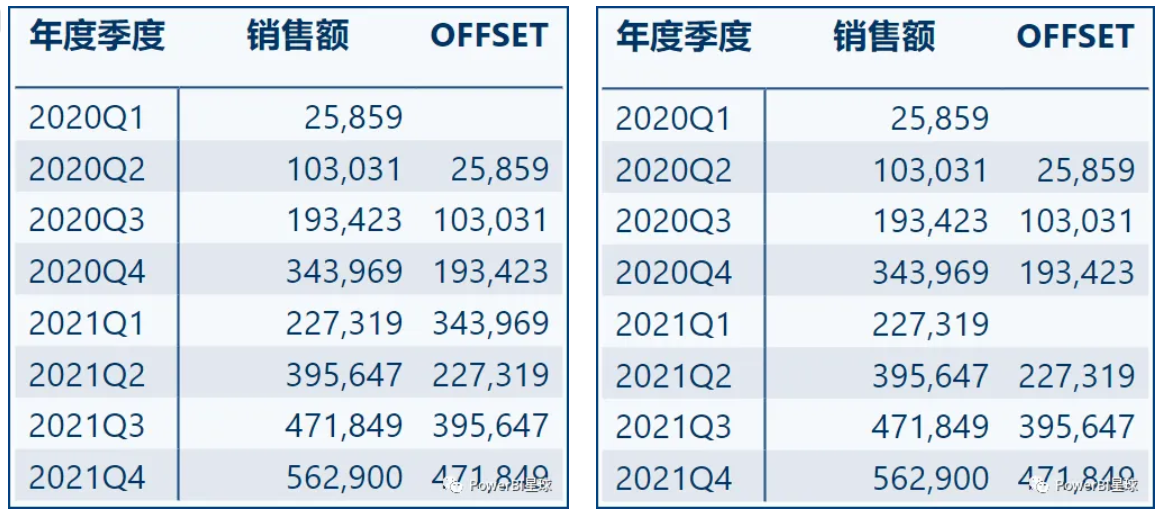
- 对于在PARTITIONBY中的字段(以及在ORDERBY中的字段),必须放到第二个参数中,即第二个参数里面也要带上’日期表’[年度]。
- 这种偏移只在年度的区间内进行,年度变化后,再重新取开始,所以第一个季度都是空值。
1.1.2 使用orderBy
参考《PowerBI DAX 新函数 OFFSET》

这个例子中,使用的度量值为:
KPI.Prev.按月份名称 =
CALCULATE( [KPI] ,OFFSET(-1,ALLSELECTED( 'Dim Calendar'[MonthNameCN] , 'Dim Calendar'[MonthNum] ),ORDERBY( 'Dim Calendar'[MonthNum] , ASC ))
)
- 构建筛选表:使用第二个参数
<relation>,构建一个表用于计算,标记为Table。这里使用了 ALLSELECTED,不受到筛选上下文的影响。 - 排序:按
<orderBy>参数指定的列对表Table进行排序,此处是按照日期序号列升序排序。 - 偏移:根据
<delta>参数的值对表Table中的行进行偏移。 - 返回结果:返回偏移后的行,形成新的筛选上下文,覆盖外部的筛选上下文。
可见, OFFSET 用于将当前筛选上下文中的表按照数据模型中某列引用进行排序,并按指定数字进行偏移。
1.1.3 统计连续值的最大出现次数(待补)
参考《使用OFFSET求最大连续元素》
1.2 INDEX(静态查询)
INDEX函数用于检索表中特定行的结果,它和OFFSET的参数几乎一样,其语法为:
INDEX(position, // 检索位置(基于1),1表示第一行,-1表示最后一行,以此类推。如果越界、零或空白,将返回空表。<relation> or <axis>, // 可选,前者为表表达式,后者为视觉形状中的轴(替换 relation)orderBy, // 可选,排序依据,同OFFSETblanks, // 可选,指定空值处理方式,同OFFSETpartitionBy, // 可选,分区依据,同OFFSETmatchBy, // 可选,定义如何匹配数据和标识当前行,同OFFSETreset // 可选,整数或字段引用,指示视觉计算是否重置。
)
如果要返回第一个季度的数据,可以写作:
INDEX =CALCULATE([销售额],INDEX(1,ALLSELECTED('日期表'[年度季度]))
)
如果想按年度返回本年第一季度的数据,可以写作:
INDEX =CALCULATE([销售额],INDEX(1,ALLSELECTED('日期表'[年度季度],'日期表'[年度]),,,PARTITIONBY('日期表'[年度]))
)
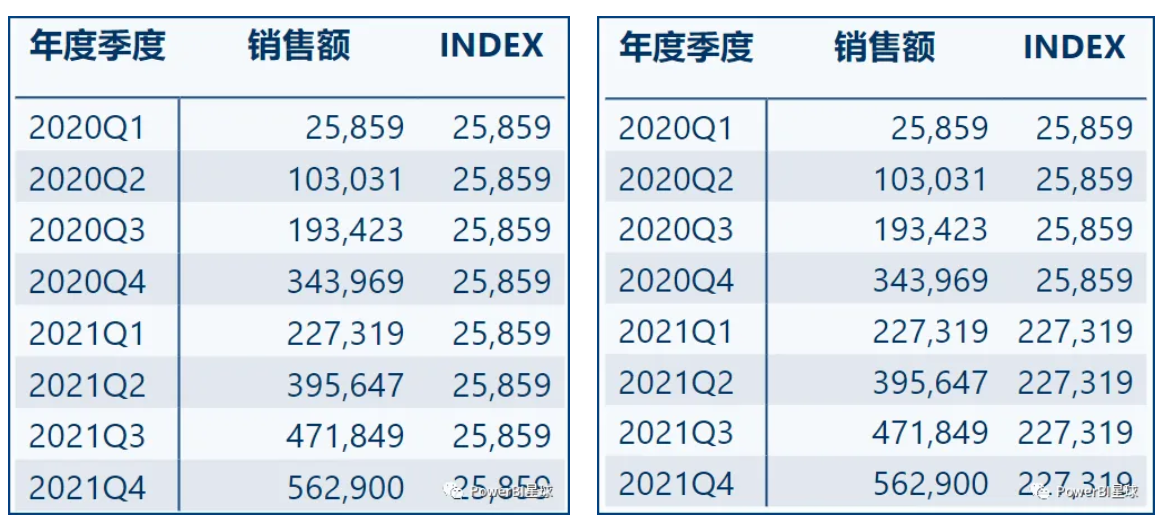
左图返回的都是第一行的数据,右图返回的都是该年第一季度的数据,从这里可以看出OFFSET(偏移)和INDEX(索引)的区别。
| 特性 | INDEX | OFFSET |
|---|---|---|
| 核心用途 | 按固定位置检索数据 | 动态偏移引用范围 |
| 依赖上下文 | 不依赖上下文 | 通常依赖行上下文或筛选器 |
| 输出结果 | 单个值或单元格 | 动态范围(可结合其他函数使用) |
| 典型场景 | 静态查询,如在报表中显示某个固定序号的行 | 动态计算,如累计、移动平均;或在需要结合行上下文(如 EARLIER)进行复杂计算时 |
| 性能影响 | 高效,直接定位 | 可能较慢,涉及范围动态调整 |
OFFSET在 DAX 中通常需要与ROW或EARLIER配合使用才能发挥动态效果。INDEX的行号和列号需严格对应表的物理顺序,而OFFSET的偏移量是相对于当前行的动态计算。
1.3 WINDOW(滚动求和、累计求和、帕累托分析)
WINDOW函数返回位于给定区间内的多个行,其语法为:
WINDOW(from[, from_type], // 窗口的开始位置及其类型to[, to_type], // 窗口的结束位置及其类型<relation> or <axis>, // 可选,表表达式或视觉形状中的轴,同OFFSET<orderBy>, // 可选,排序依据,同OFFSET<blanks>, // 可选,空值处理方式,同OFFSET<partitionBy>, // 可选,分区依据,同OFFSET<matchBy>, // 可选,匹配依据,同OFFSET<reset> // 可选,重置指示,同OFFSET
)
from:指示窗口的开始位置,可以是标量或返回标量值的任何 DAX 表达式from_type:开始位置的类型,可以是 :ABS:绝对位置。正值表示从分区开头开始的位置,负值表示从分区末尾开始的位置,即1就表示表的第一行,-1表示表的最后一行。REL(默认):相对位置,相对于当前行的偏移量。正值表示当前行之后,负值表示当前行之前,0表示当前行
1.3.1 滚动求和与累计求和
常用的滚动求和,比如计算本季度和上季度的和,可以写作:
WINDOW = CALCULATE([销售额],WINDOW(-1,REL,0,REL,ALLSELECTED('日期表'[年度季度]))
)
还可以通过设置起始位置绝对引用,结束位置相对引用,来实现累计求和的效果:
WINDOW =CALCULATE([销售额],WINDOW(1,ABS,0,REL,ALLSELECTED('日期表'[年度季度]))
)
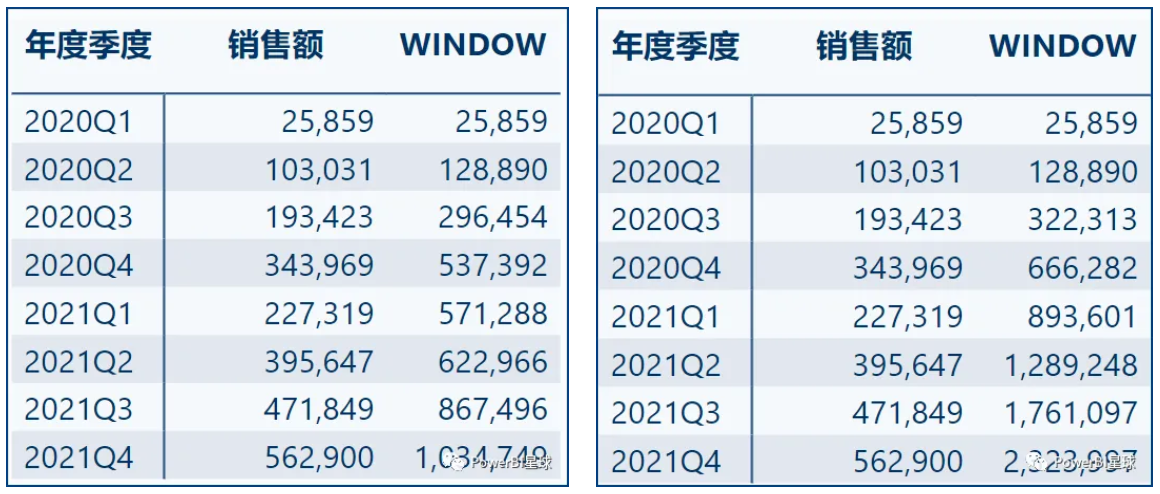
1.3.2 帕累托分析
帕累托分析(Pareto Analysis)是一种基于帕累托原则(Pareto Principle,也称为“二八法则”)的分析方法。帕累托原则指出,在许多情况下,约 80% 的结果往往来自于 20% 的原因,比如少数人的收入占全部人收入的大部分,而多数人的收入却只占一小部分。他将这一关系用图表展示出来,就是著名的帕累托图(结合柱状图和折线图)。

- 柱状图的高度表示每个产品的销售额,左边的产品销售额最高
- 折线图的纵轴表示累计销售额占比,折线图的上升趋势可以帮助我们找到累计占比达到某个关键值(如
80%)的点,从而确定哪些产品是关键贡献者。
帕累托分析通常用于识别那些对结果影响最大的因素,从而帮助决策者优先处理最重要的问题或机会。比如进行产品的帕累托分析,产品累计占比写法如下:
产品销售额累计占比 =
VAR sales = [销售额]
VAR cum_sales= // 计算累计销售额,即所有销售额大于或等于当前产品销售额的产品的总销售额
CALCULATE([销售额],FILTER(ALL('产品表'),[销售额]>=sales)
)
VAR total_sales=CALCULATE([销售额],ALL('产品表')) // 所有产品的总销售额
RETURN
DIVIDE( cum_sales , total_sales ) // 累计销售额占总销售额的比例,即可用来进行帕累托分析
现在可以用窗口函数来实现,更加方便,且性能更优:
产品销售额累计占比-WINDOW =
VAR cum_sales=
CALCULATE([销售额],WINDOW(0,ABS,0,REL, // 等同于1,ABS,0,REL,表示第一行累计到当前行ALLSELECTED('产品表'[产品名称]),ORDERBY([销售额],DESC) // 对产品名称按销售额降序排序)
)
VAR total_sales=CALCULATE([销售额],ALL('产品表'))
RETURN
DIVIDE( cum_sales , total_sales )
WINDOW表达式的含义是对产品名称按销售额降序排序,返回从最大值到当前的数据行,然后再对这些行的销售额求和,就得到了当前产品的累计销售额。

用WINDOW函数来计算累计占比,除了写法上更加简洁,更重要的是它的性能更优,数据量越多时越明显。下图是对客户维度进行了帕累托分析(700个客户),然后用性能分析器进行测试的效果:

1.4 RANK(待补)
参考《RANK函数实现多字段排名》、《窗口函数RANK》
RANK 函数用于返回指定分区中当前上下文的排名,可指定排序依据及排序顺序:
RANK ([<ties>], // 可选,排名并列时的处理方式,可选SKIP(跳跃排名)和DENSE(连续排名)[<relation> or <axis>], // 可选,表表达式或视觉形状中的轴,同OFFSET[<orderBy>], // 可选,排序依据,同OFFSET[<blanks>], // 可选,空值处理方式,同OFFSET[<partitionBy>], // 可选,分区依据,同OFFSET[<matchBy>], // 可选,匹配依据,同OFFSET[<reset>] // 可选,视觉计算重置指示,同OFFSET
)
RANK 函数可用于多字段排名,例如:
指标一合计 = SUM('表'[指标一])
指标二合计 = SUM('表'[指标二])排名 RANK =
RANK(ALLSELECTED('表'[类别]),ORDERBY([指标一合计],DESC,[指标二合计],DESC)
)

1.5 ROWNUMBER(待补)
参考《窗口函数 ROWNUMBER》
二、视觉计算简介
- 本节使用 Power BI Desktop 的 Contoso 销售示例文件
- 参考《使用视觉计算(预览版)》、《在 Power BI Desktop 中创建视觉计算》
视觉计算是一种直接在视觉对象上定义和执行的 DAX 计算。与传统 DAX 计算不同,视觉计算不存储在模型中,而是存储在视觉对象上,只能引用视觉对象上的内容(包括列、度量值或其他视觉对象计算), 这意味着视觉对象计算不必担心筛选器上下文和模型的复杂性,简化了编写 DAX 的过程,便于维护且性能更优。可以使用视觉计算来完成常见的业务计算,例如累加总和或移动平均。
视觉计算结合了计算列的简单性(引用视觉结构,更直观)和度量值的按需计算灵活性,且在聚合数据上操作(而不是细节级别),通常会带来性能优势。如果你的模型中建了太多的度量值,导致模型变得臃肿而混乱,那么可以尝试可视化计算,它只使用于当前的视觉对象,不会存储在模型中。
2024 年 9 月之前,需在“选项和设置”>“选项”>“预览功能”中启用“视觉计算”,之后重启 Power BI Desktop。从 2024 年 9 月起,视觉计算默认启用,但仍处于预览阶段,可通过上述设置禁用。
2.1 添加视觉计算
- 新建视觉计算:选择视觉对象,点击功能区中的“新建视觉计算”按钮(或者右键单击视觉对象,弹出菜单中也会显示此选项)打开视觉计算窗口,开启编辑模式。编辑模式屏幕由三个主要部分组成:
- 视觉预览:显示你正在使用的视觉对象
- 公式栏:用于添加视觉计算
- 视觉矩阵:显示视觉对象中的数据,并显示视觉对象计算结果。注意,应用于视觉对象的任何样式或主题都不适用于视觉对象矩阵。
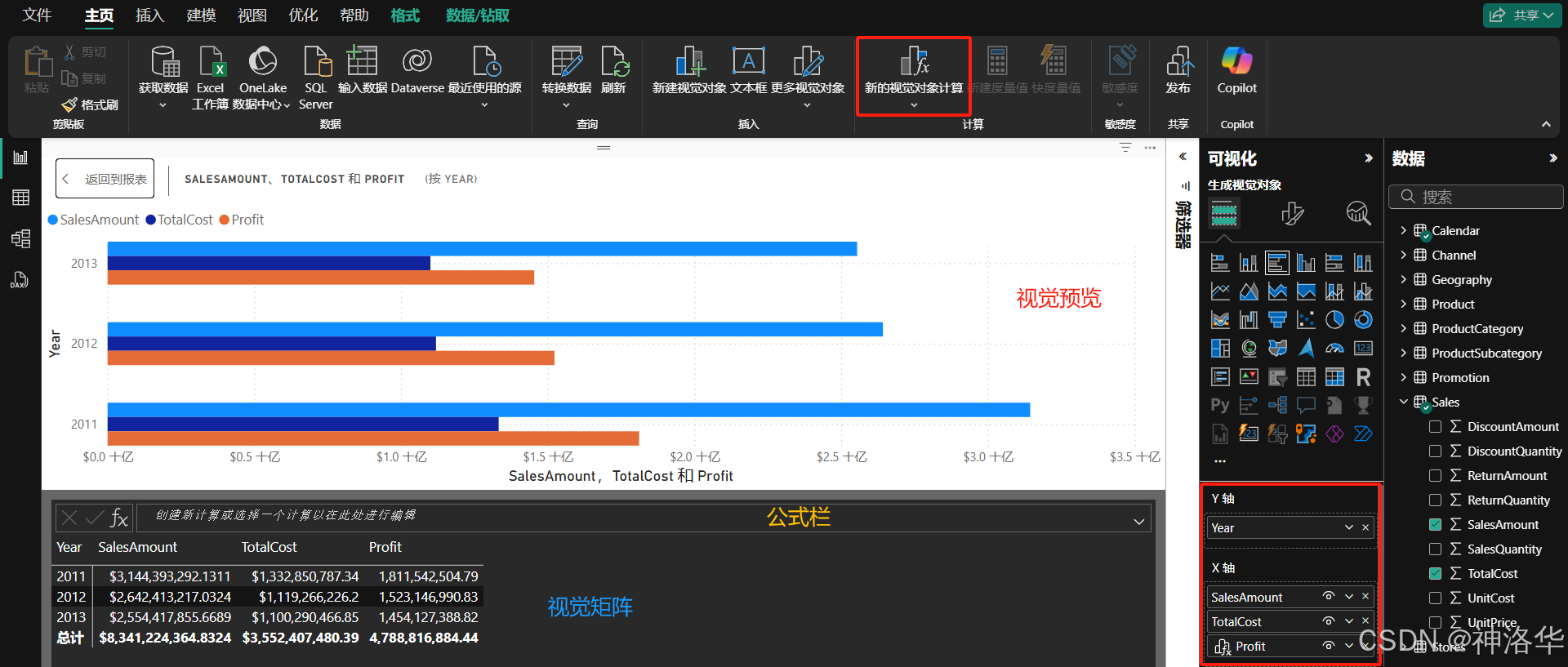
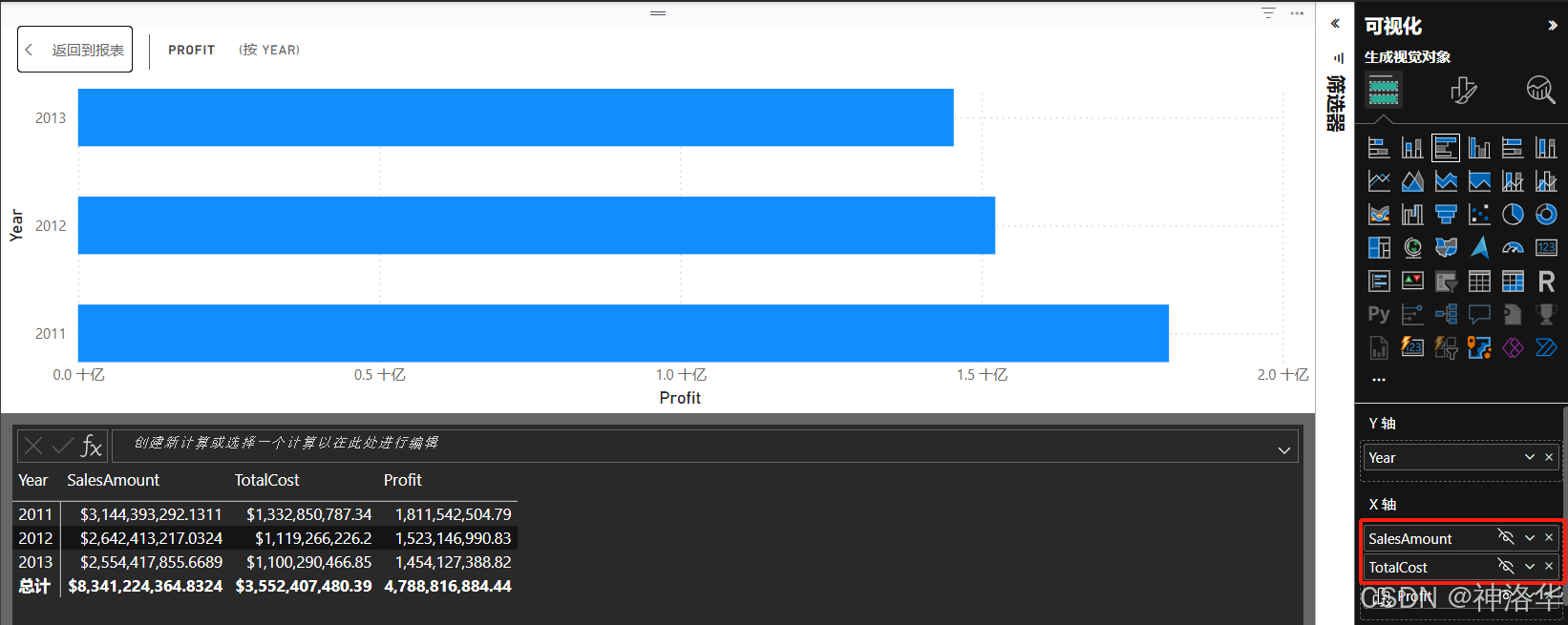
- 编辑视觉计算:下面是一个视觉计算示例,用于定义销售金额的累加和。在包含 Sales Amount 和 Total Product Cost by Fiscal Year 的视觉对象中,输入
Profit = [SalesAmount] – [TotalCost],添加视觉计算,计算每年利润。

- 特性:视觉计算在默认情况下会逐行计算,而不需要额外的聚合操作,这使得它与度量值的计算方式有所不同,并且更加简洁和直观(如果无需聚合,最好不要像在度量中那样添加诸如SUM这样的聚合函数)。本例中,对于视觉矩阵的每一行,会将当前行的“销售额”和“总产品成本”相减,然后将结果返回到“利润”列中,就像是生成一个计算列一样。
- 限制:由于视觉计算在视觉矩阵的范围内工作,因此依赖于模型关系(RELATIONSHIP、RELATED 或 RELATEDTABLE)的函数不可用。
2.2 隐藏视觉中的字段
添加视觉计算时,它们将显示在视觉对象的字段列表中,可以像在建模视图中一样隐藏视觉中的字段。隐藏字段不会从视觉或视觉矩阵中移除,视觉计算仍可引用它们,但不会显示在最终视觉中。比如隐藏“销售额”和“总产品成本”字段,只显示“利润”字段。
2.3 快捷模板
视觉计算提供模板简化常用计算编写。点击模板按钮选择模板,或从“新建视觉计算”按钮底部创建带模板的视觉计算。可用模板包括累计和、移动平均、父级百分比等。

| 模板名称 | 描述 | 使用函数 |
|---|---|---|
| Running sum | 计算累计和,将当前值加到前面的值上。 | RUNNINGSUM |
| Moving average | 在给定窗口中计算一组值的移动平均值,通过将值的总和除以窗口大小来实现。 | MOVINGAVERAGE |
| Percent of parent | 计算值相对于其父级的百分比。 | COLLAPSE |
| Percent of grand total | 计算值相对于所有值的百分比。 | COLLAPSEALL |
| Average of children | 计算一组子值的平均值。 | EXPAND |
| Versus previous | 将值与前面的值进行比较。 | PREVIOUS |
| Versus next | 将值与后面的值进行比较。 | NEXT |
| Versus first | 将值与第一个值进行比较。 | FIRST |
| Versus last | 将值与最后一个值进行比较。 | LAST |
2.4 可选参数
2.4.1 Axis参数(轴)
许多函数有可选的 Axis 参数,仅能在视觉计算中使用,影响视觉计算如何遍历视觉矩阵。Axis 参数默认设置为视觉的第一个轴(通常是行),这意味着视觉计算在视觉矩阵中是逐行从上到下进行计算的。

2.4.2 Reset参数(重置)
许多函数有可选的 Reset 参数,仅在视觉计算中可用,用在设置函数在遍历视觉矩阵时是否将其值重置为 0,或者切换到不同的范围进行计算,默认为 None(不重置)。
NONE:默认值,不会重置计算。HIGHESTPARENT:当轴上最高级别的父级值发生变化时,重置计算。LOWESTPARENT:当轴上最低级别的父级值发生变化时,重置计算。- 数值:通过数值来指定轴上的字段,以确定重置计算的位置。
- 为零或省略:不重置,等同于 NONE。
- 为正数:从最高级别的列开始标识,不依赖于粒度。数值 1 等同于 HIGHESTPARENT。
- 为负数:从最低级别的列开始标识,相对于当前粒度。数值 -1 等同于 LOWESTPARENT。
- 字段引用:只要字段在视觉上可用,就可以通过字段引用进行重置,根据指定字段的值变化来重置计算。
假设轴上有三个字段,分别位于多个级别:年(Year)、季度(Quarter)和月份(Month)。在这种情况下,HIGHESTPARENT 是年(Year),LOWESTPARENT 是季度(Quarter)。
-
按年重置累计和:以下视觉计算是等效的,都返回每个年份从 0 开始的销售金额累计和。
RUNNINGSUM([Sales Amount], HIGHESTPARENT) RUNNINGSUM([Sales Amount], 1) RUNNINGSUM([Sales Amount], -2) RUNNINGSUM([Sales Amount], [Year]) -
按季度重置累计和
RUNNINGSUM([Sales Amount], LOWESTPARENT) RUNNINGSUM([Sales Amount], 2) RUNNINGSUM([Sales Amount], -1) -
不重置累计和:持续将每个月的销售金额值添加到之前的值上,不会重新开始
RUNNINGSUM([Sales Amount])
2.4.3 对比 ORDERBY 和 PARTITIONBY
Axis(轴)和Reset(重置)、ORDERBY(排序依据)和 PARTITIONBY(分区依据)都影响计算评估方式,但是它们的抽象级别不同:
- 前者仅用于视觉计算,因为是引用的视觉结构
- 后者可以在计算列、度量值和视觉计算中使用,它们通过显式指定字段来执行排序和分区
另外,Axis 和 Reset 更灵活,因为它们不依赖于具体的字段。当轴上没有多个级别(例如只有一个字段或多个字段在同一个级别上)时,可以使用 PARTITIONBY。
组合使用时,可以同时指定 Axis,ORDERBY, PARTITIONBY,此时 ORDERBY 和 PARTITIONBY 的设置会覆盖 Axis 的设置。Reset 不能与 ORDERBY 和 PARTITIONBY 一起使用。
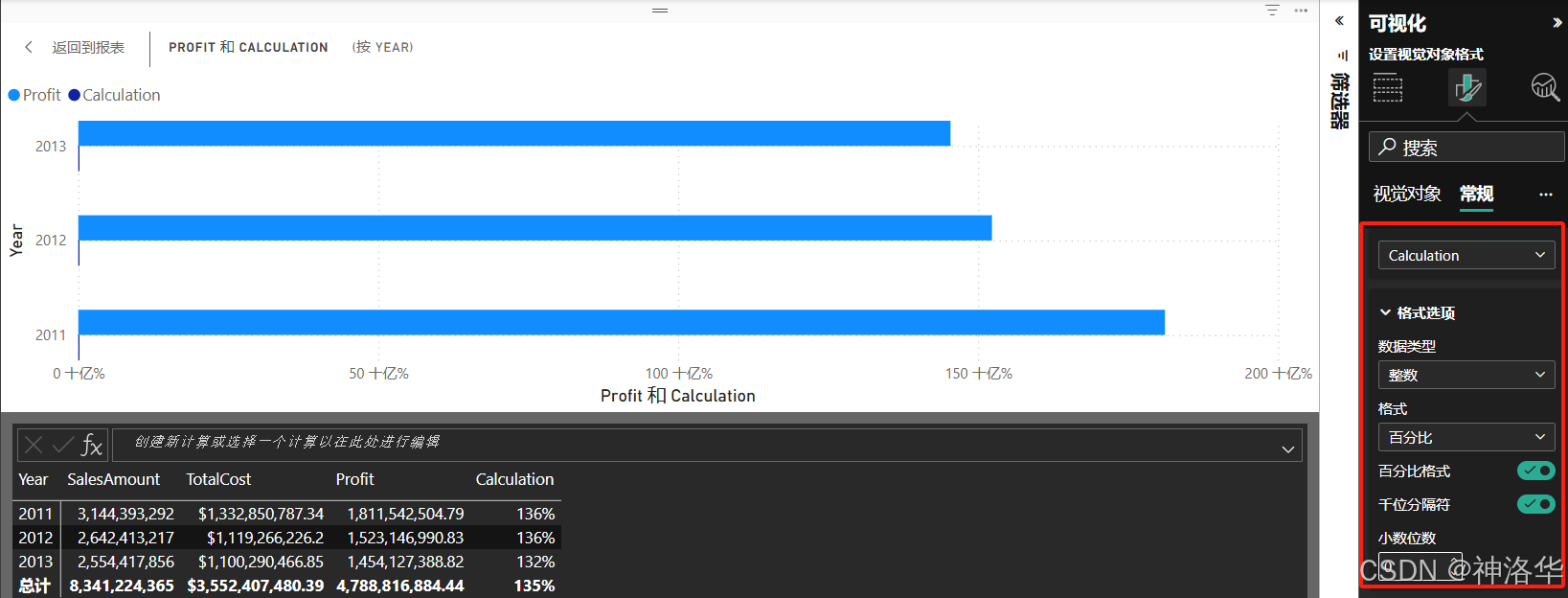
2.5 设置视觉对象计算的格式
可通过数据类型和格式选项格式化视觉计算,比如在视觉格式窗格的常规部分中,使用数据格式选项设置格式。
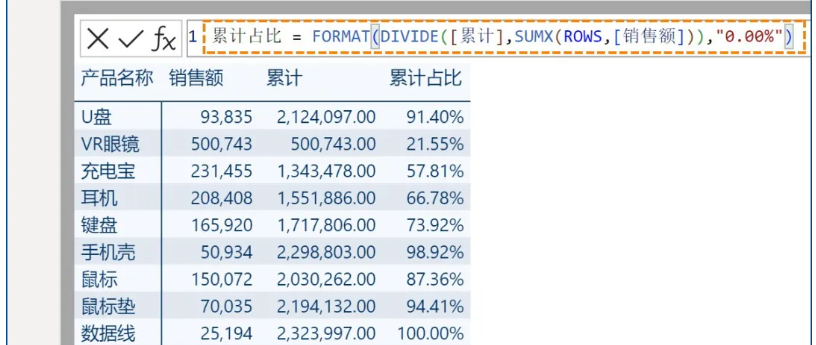
也可使用FORMAT函数来显示格式:
2.6 预览期间的限制
-
不支持所有视觉类型,某些视觉类型和属性不兼容;
-
无法通过复制粘贴重用;无法筛选视觉计算;
-
不能以相同或不同的详细信息级别引用自身;
-
视觉计算或隐藏字段的个性化设置不可用;
-
无法固定到到仪表板;无法使用“发布到 Web”功能;
-
数据导出不包含视觉计算结果; 隐藏字段永远不会包含在导出中,除非导出基础数据。
-
无法使用“查看记录”钻取功能;
-
无法设置数据类别;无法更改聚合、无法更改排序顺序;
-
Power BI Embedded 和 SQL Server Analysis Services 的实时连接不支持;
-
尽管可以对视觉计算使用 字段参数 ,但它们有一些限制;
-
显示无数据的项目选项不可用;
-
无法使用数据限制; 无法设置动态格式字符串。
三、 视觉计算原理
参考《Introducing VISUAL SHAPE forvisual calculations in Power Bl》、《Introducing EXPAND andCOLLAPSE for visual calculationsin Power Bl》
视觉计算作为 Power BI 2024 年 2 月发布的预览功能,旨在简化与特定可视化相关的计算创建然而,一旦开发人员开始创建更复杂的计算,他们就需要了解视觉计算实现的技术细节。这需要了解虚拟表的层级结构、新的视觉上下文、ROWS 和 COLUMNS 的语义、CALCULATE 的行为,以及新的视觉上下文修饰符 EXPAND 和 COLLAPSE。
3.1 SUMMARIZECOLUMNS 与 ROLLUPADDISSUBTOTAL
SUMMARIZECOLUMNS是用于对数据进行分组和汇总。它允许你基于一个或多个列创建汇总表,并对这些组进行计算,其语法为:
SUMMARIZECOLUMNS(<columns>[,...], // 要分组的列,必须是表中的列名[<filter1>], [<filter2>], ..., // 筛选条件,可选,可以是布尔表达式或返回布尔值的 FILTER 函数[<name1>, <expression1>], ... // 汇总列,可选,用于在汇总表中添加新的计算列(列名+计算表达式)
)
比如只汇总销售子表中,零售价大于2000的销售记录:
销售汇总表 = SUMMARIZECOLUMNS('销售子表'[产品名称],'日期表'[年度月份], // 分组列FILTER('销售子表','销售子表'[零售价]>2000), // 筛选条件"销售额合计", // 汇总列列名CALCULATE(SUM('销售子表'[销售额])) // 汇总列的计算表达式
)
SUMMARIZECOLUMNS函数还有一个常用的配套函数ROLLUPADDISSUBTOTAL,用于在 SUMMARIZECOLUMNS 函数中为每个分组级别生成小计行,并在最顶层生成总计行(函数本身只是进行标记,汇总计算实际是调用 ISSUBTOTAL 函数函数),其语法为:
ROLLUPADDISSUBTOTAL([<grandtotalFilter>], <groupBy_columnName>, <name> [, [<groupLevelFilter>] [, <groupBy_columnName>, <name> [, [<groupLevelFilter>] [, … ] ] ] ]
)
<grandtotalFilter>:可选,应用于总计级别的筛选器。<groupBy_columnName>:用于分组的列名,必须是表中的现有列,不能是表达式。<name>:用于标记小计列的名称,该列的值通过 ISSUBTOTAL 函数计算。<groupLevelFilter>:可选,应用于当前级别的筛选器。
ROLLUPADDISSUBTOTAL函数本身不返回值,它只是指定SUMMARIZECOLUMNS函数中需要计算小计的列,且只能在SUMMARIZECOLUMNS表达式中使用。
3.2 DAX 查询生成扁平表
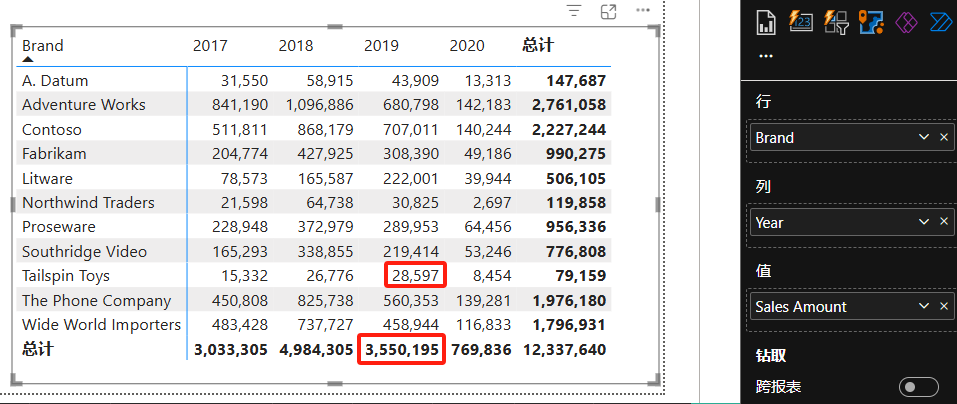
使用本章示例数据,可生成以下矩阵视觉对象。矩阵按产品品牌(行)和年份(列)进行组织。此数据矩阵实际上是由返回平面表( flat table)的查询生成的,平面表包含内部单元格的行以及小计行。
此查询(简化版)示意如下:
EVALUATE
SUMMARIZECOLUMNS (ROLLUPADDISSUBTOTAL ( 'Product'[Brand], "IsGrandTotalRowTotal" ),ROLLUPADDISSUBTOTAL ( 'Date'[Year], "IsGrandTotalColumnTotal" ),"Sales_Amount", 'Sales'[Sales Amount]
)
在DAX查询视图中运行此代码,将输出整个结果集——一个扁平的表格,所有行(包括小计和总计)都在同一级别。查看其中 2019 年 Tailspin Toys 的值以及同年的列小计,其结果和上面矩阵视觉对象中的结果是一样的。

标记列(如 “IsGrandTotalRowTotal” 和 “IsGrandTotalColumnTotal”)用于区分普通数据行、小计行和总计行,具体来说:
ROLLUPADDISSUBTOTAL ( 'Product'[Brand], "IsGrandTotalRowTotal" ):生成行方向的小计/总计。按产品品牌进行分组,并在结果中添加IsGrandTotalRowTotal列,这是一个标记列,当某行是Product[Brand]的总计行时,该列值为TRUE,否则为FALSE。ROLLUPADDISSUBTOTAL('Date'[Year], "IsGrandTotalColumnTotal"):生成列方向的小计/总计。按订单日期进行分组,并在结果中添加IsGrandTotalColumnTotal列,当某行是 Date[Year] 的总计行时,该列值为TRUE,否则为FALSE。
又比如,我们可以使用PREVIOUS视觉计算函数,算出各品牌每一年对比上一年的销售增长率(2017 年的增长率是空白的,因为没有以前的列)。
Growth =
VAR Curr = [Sales Amount]
VAR Prev = PREVIOUS ( [Sales Amount], COLUMNS )
VAR Result = DIVIDE ( Curr - Prev, Prev )
RETURNFORMAT ( Result, "0.00 %" )
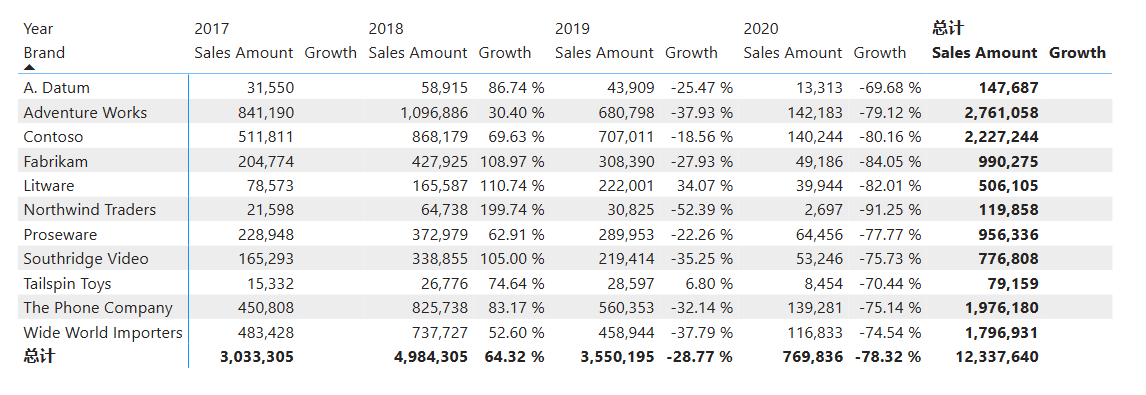
可见,PREVIOUS 函数依赖于视觉上下文(如矩阵的列顺序)来确定前一列的值,而不是直接依赖于表格的物理结构,而DAX查询生成的结果是一个平面表( flat table),这种转变是怎么做到的呢?
3.3 VISUAL SHAPE定义层次结构
VISUAL SHAPE(视觉形状) 是 Power BI 在内部处理数据时添加的一个描述,它通过定义ROWS和COLUMNS的分组逻辑,为数据表添加了层级结构(如品牌、年份、小计、总计)。让我们看一下产生上面矩阵的查询的简化版本:
DEFINE// 1.定义一个计算列 [Growth],用于计算销售增长率。COLUMN '__DS0VisualCalcs'[Growth] =(VAR Curr = [Sales Amount]VAR Prev =PREVIOUS ( [Sales Amount], COLUMNS )VAR Result =DIVIDE ( Curr - Prev, Prev )RETURNFORMAT ( Result, "0.00 %" ))// 2.创建一个基础表 __DS0Core,用于汇总销售数据VAR __DS0Core =SUMMARIZECOLUMNS(ROLLUPADDISSUBTOTAL('Product'[Brand], "IsGrandTotalRowTotal"), // 按品牌分组,并标记是否是小计行ROLLUPADDISSUBTOTAL('Date'[Year], "IsGrandTotalColumnTotal"), // 按年份分组,并标记是否是小计列"Sales_Amount", 'Sales'[Sales Amount] -- 计算每组的销售额)// 3.基于 __DS0Core 创建一个新的表 __DS0VisualCalcsInput,用于后续的计算和处理。VAR __DS0VisualCalcsInput =SELECTCOLUMNS(KEEPFILTERS(SELECTCOLUMNS(__DS0Core,"Brand", 'Product'[Brand], // 保留品牌列"IsGrandTotalRowTotal", [IsGrandTotalRowTotal], // 保留是否是小计行的标记"Year", 'Date'[Year], // 保留年份列"IsGrandTotalColumnTotal", [IsGrandTotalColumnTotal], // 保留是否是小计列的标记"Sales_Amount", [Sales_Amount] // 保留销售额列)),"Brand", [Brand],"Year", [Year],"IsGrandTotalRowTotal", [IsGrandTotalRowTotal],"IsGrandTotalColumnTotal", [IsGrandTotalColumnTotal],"Sales Amount", [Sales_Amount] // 将列重命名为 "Sales Amount")// 4.创建一个表格 __DS0VisualCalcs,并定义其结构和计算逻辑。TABLE '__DS0VisualCalcs' = __DS0VisualCalcsInputWITH VISUAL SHAPEAXIS ROWSGROUP [Brand] // 按品牌分组TOTAL [IsGrandTotalRowTotal] // 添加小计行ORDER BY [Brand] ASC // 按品牌升序排列AXIS COLUMNSGROUP [Year] // 按年份分组TOTAL [IsGrandTotalColumnTotal] // 添加小计列ORDER BY [Year] ASC // 按年份升序排列DENSIFY "IsDensifiedRow" // 填充空行,并标记为 "IsDensifiedRow"// 5.过滤掉填充的空行,只保留有意义的数据。VAR __DS0RemoveEmptyDensified =FILTER (KEEPFILTERS ( '__DS0VisualCalcs' ),OR (NOT ( '__DS0VisualCalcs'[IsDensifiedRow] ), // 不是填充的行NOT ( ISBLANK ( '__DS0VisualCalcs'[Growth] ) ) // 填充的行中,增长率不为空))// 6.移除不需要的上下文列,只保留最终需要的列。VAR __DS0RemoveContextOnlyColumns =SELECTCOLUMNS(KEEPFILTERS(__DS0RemoveEmptyDensified),"'__DS0VisualCalcs'[Brand]", '__DS0VisualCalcs'[Brand], // 保留品牌列"'__DS0VisualCalcs'[Year]", '__DS0VisualCalcs'[Year], // 保留年份列"'__DS0VisualCalcs'[IsGrandTotalRowTotal]", '__DS0VisualCalcs'[IsGrandTotalRowTotal], // 保留小计行标记"'__DS0VisualCalcs'[IsGrandTotalColumnTotal]", '__DS0VisualCalcs'[IsGrandTotalColumnTotal], // 保留小计列标记"'__DS0VisualCalcs'[Growth]", '__DS0VisualCalcs'[Growth], // 保留增长率列"'__DS0VisualCalcs'[IsDensifiedRow]", '__DS0VisualCalcs'[IsDensifiedRow] // 保留填充行标记)
// 7.最终输出表格 __DS0RemoveContextOnlyColumns,展示结果。
EVALUATE__DS0RemoveContextOnlyColumns
- 定义视觉计算列:
DEFINE COLUMNS部分定义了一个名为[Growth]的计算列,用于计算销售增长率; - 基础查询:
__Ds0Core部分定义基础查询,它使用SUMMARIZECOLUMNS函数对数据进行了汇总,这个基础查询是后续处理的起点。 - 重命名列:使用SELECTCOLUMNS函数重命名列。
- 添加视觉形状:使用
WITH VISUAL SHAPE子句,定义了表格的结构(按品牌和按年份分组,并添加了小计行和小计列) - 填充缺失行:使用
DENSIFY填充缺失行。例如某些品牌在某些年份没有数据,但为了保持表格结构完整,会添加这些缺失的行,并标记这些填充行为IsDensifiedRow,以便后续处理。 - 移除空行:使用
FILTER函数过滤掉那些填充行(IsDensifiedRow=TRUE)或增长率([Growth])为空的行,避免在最终结果中显示。 - 移除不需要可视化的列:再次使用
SELECTCOLUMNS函数移除了一些仅用于中间计算的列(例如IsDensifiedRow等),只保留了需要最终展示的列,例如品牌、年份、增长率等。
本章重点关注VISUAL SHAPE部分,VISUAL SHAPE 子句为原本扁平的表添加了层次结构:
TABLE '__DS0VisualCalcs' = __DS0VisualCalcsInputWITH VISUAL SHAPEAXIS ROWSGROUP [Brand]TOTAL [IsGrandTotalRowTotal]ORDER BY [Brand] ASCAXIS COLUMNSGROUP [Year]TOTAL [IsGrandTotalColumnTotal]ORDER BY [Year] ASCDENSIFY "IsDensifiedRow"
- 重命名:
__DS0VisualCalcsInput是基于基础查询__DS0Core创建的,通过SELECTCOLUMNS函数对列进行了重命名。重命名的目的是为了让列名与可视化工具中的矩阵表的列名一致,而不是直接使用数据模型中的列名。 - 基础查询:
__DS0VisualCalcsInput只包含础数据和一些重命名的列,不包含通过DEFINE COLUMNS定义的可视化计算列(如 [Growth])。 - 添加可视化计算列:
__DS0VisualCalcs在__DS0VisualCalcsInput的基础上,通过VISUAL SHAPE子句进一步处理,得到一个包含了所有可视化计算列的表。 - 定义表格结构:
VISUAL SHAPE通过定义ROWS或COLUMNS或两个都进行定义,定义了表格结构。示例代码中,ROWS轴按品牌(Brand)分组,并添加了小计行(IsGrandTotalRowTotal);COLUMNS轴按Year分组,并添加了小计列(IsGrandTotalColumnTotal)。 - 填充列:此部分最后一个子句
DENSIFY "IsDensifiedRow",用于指示某行是否是由于填充而创建的,以便进行后续处理。
3.4 视觉计算依赖轴定义
在简单的矩阵中,每个轴(行或列)可能只有一个层次(如品牌或年份)。但在更复杂的场景中,行轴可以包含多个层次(如品牌、类别、颜色),列轴可以包含多个层次(如年份、月份)。
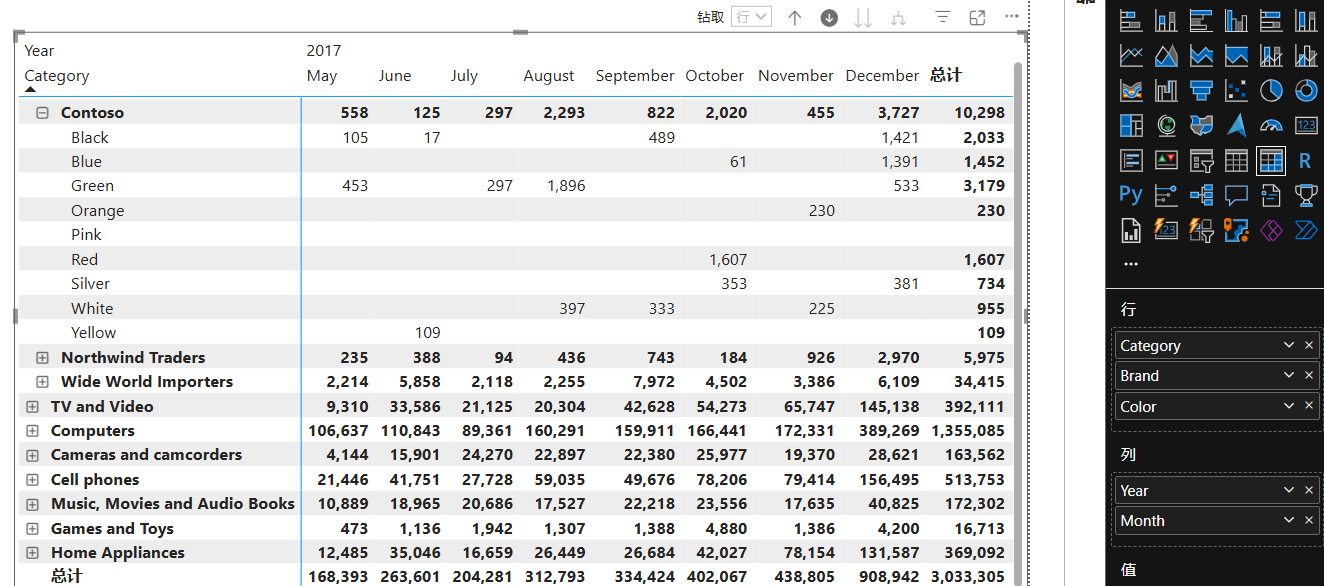
更复杂的层次结构带来了更复杂的视觉形状定义:
TABLE '__DS0VisualCalcs' = __DS0VisualCalcsInputWITH VISUAL SHAPE AXIS ROWS // 定义行结构GROUP [Brand] // 按品牌分组,并标识小计和总计行TOTAL [IsGrandTotalRowTotal]GROUP[Category], // 按类别和类别代码分组,并标识小计。[Category_Code]TOTAL [IsDM1Total]GROUP [Color] // 按颜色分组,并标识小计TOTAL [IsDM3Total]ORDER BY // 按品牌、类别代码、类别和颜色排序。[Brand] ASC,[Category_Code] ASC,[Category] ASC,[Color] ASCAXIS COLUMNS // 定义列结构GROUP [Year] // 按年份分组,并标识小计和总计列。TOTAL [IsGrandTotalColumnTotal] GROUP // 按月份和月份编号分组,并标识小计。[Month],[Month_Number]TOTAL [IsDM6Total]ORDER BY // 按年份、月份编号和月份排序。[Year] ASC,[Month_Number] ASC,[Month] ASCDENSIFY "IsDensifiedRow" // 标记填充行
-
VISUAL SHAPE的作用:- 添加元数据:为
SUMMARIZECOLUMNS的结果添加元数据,定义行和列轴的层次结构; - 查询定义的表格:
VISUAL SHAPE定义的表格不是变量,而是一个DAX查询定义的表格,这意味着可以在查询中定义新列
- 添加元数据:为
-
视觉计算的工作原理
- 视觉计算是通过在查询中定义新列来实现的,这些列可以引用
ROWS和COLUMNS关键字,因为轴的定义是表格的一部分 - ROWS 和 COLUMNS关键字只能在视觉计算中使用,因为它们依赖于 VISUAL SHAPE 定义的元数据;普通模型中的度量值没有轴的定义,无法访问这些关键字
- 视觉计算是通过在查询中定义新列来实现的,这些列可以引用
-
PREVIOUS,NEXT:不直接导航层次结构(lattice),而是基于轴的定义进行导航,这样用户可以避免复杂的PARTITIONBY和ORDERBY操作。比如PREVIOUS等价于OFFSET ( -1, ROWS ),表示向前移动一行,ROWS提供了分组、分区和排序的快捷方式。
例如,Growth使用关键字 COLUMNS 作为 PREVIOUS 的第二个参数,告诉 PREVIOUS 使用列轴的定义来导航虚拟表格:根据视觉上下文的位置(如当前所在的层次级别),引擎会使用列轴定义的排序和分组规则来找到前一列的值。
Growth =
VAR Curr = [Sales Amount]
VAR Prev = PREVIOUS ( [Sales Amount], COLUMNS )
VAR Result = DIVIDE ( Curr - Prev, Prev )
RETURNFORMAT ( Result, "0.00 %" )
- 由轴定义的层次结构是掌握视觉计算的关键,视觉计算列可以引用
ROWS和COLUMNS关键字 VISUAL SHAPE为SUMMARIZECOLUMNS的结果添加元数据,定义行和列轴的层次结构,创建了视觉计算所需的环境PREVIOUS和NEXT函数通过轴定义简化了导航逻辑,避免了复杂的窗口函数操作。EXPAND和COLLAPSE函数允许开发者在层次结构中导航,展开或折叠特定的层次级别。
3.5 使用视觉上下文函数导航虚拟表
《Introducing EXPAND and COLLAPSE for visual calculations in Power BI》
在DAX中,虚拟表是一个临时的、动态生成的表,用于存储计算结果。它可以根据不同的计算需求进行扩展和调整。通过VISUAL SHAPE,可以定义虚拟表的结构,包括行和列的分组、排序以及如何展示数据。一旦虚拟表被VISUAL SHAPE增强,就可以使用视觉上下文函数(visual context functions)EXPAND和COLLAPSE导航其层次结构。
让我们分析下面的矩阵,行包括国家(Country)和州(State),列包括年份(Year)和月份(Month)。

VISUAL SHAPE部分定义如下:
TABLE '__DS0VisualCalcs' =__DS0VisualCalcsInputWITH VISUAL SHAPEAXIS rowsGROUP [Country] TOTAL [IsGrandTotalRowTotal]GROUP [State] TOTAL [IsDM1Total]ORDER BY[Country] ASC,[State] ASCAXIS columnsGROUP [Year] TOTAL [IsGrandTotalColumnTotal]GROUP[Month],[Month_Number]TOTAL [IsDM4Total]ORDER BY[Year] ASC,[Month_Number] ASC,[Month] ASCDENSIFY "IsDensifiedRow"
虚拟表的层次结构可以看作是一个网格(Lattice),其中包含所有可能的分组和汇总组合。下图说明了轴中的不同级别以及它们之间的导航,以及整个网格结构:
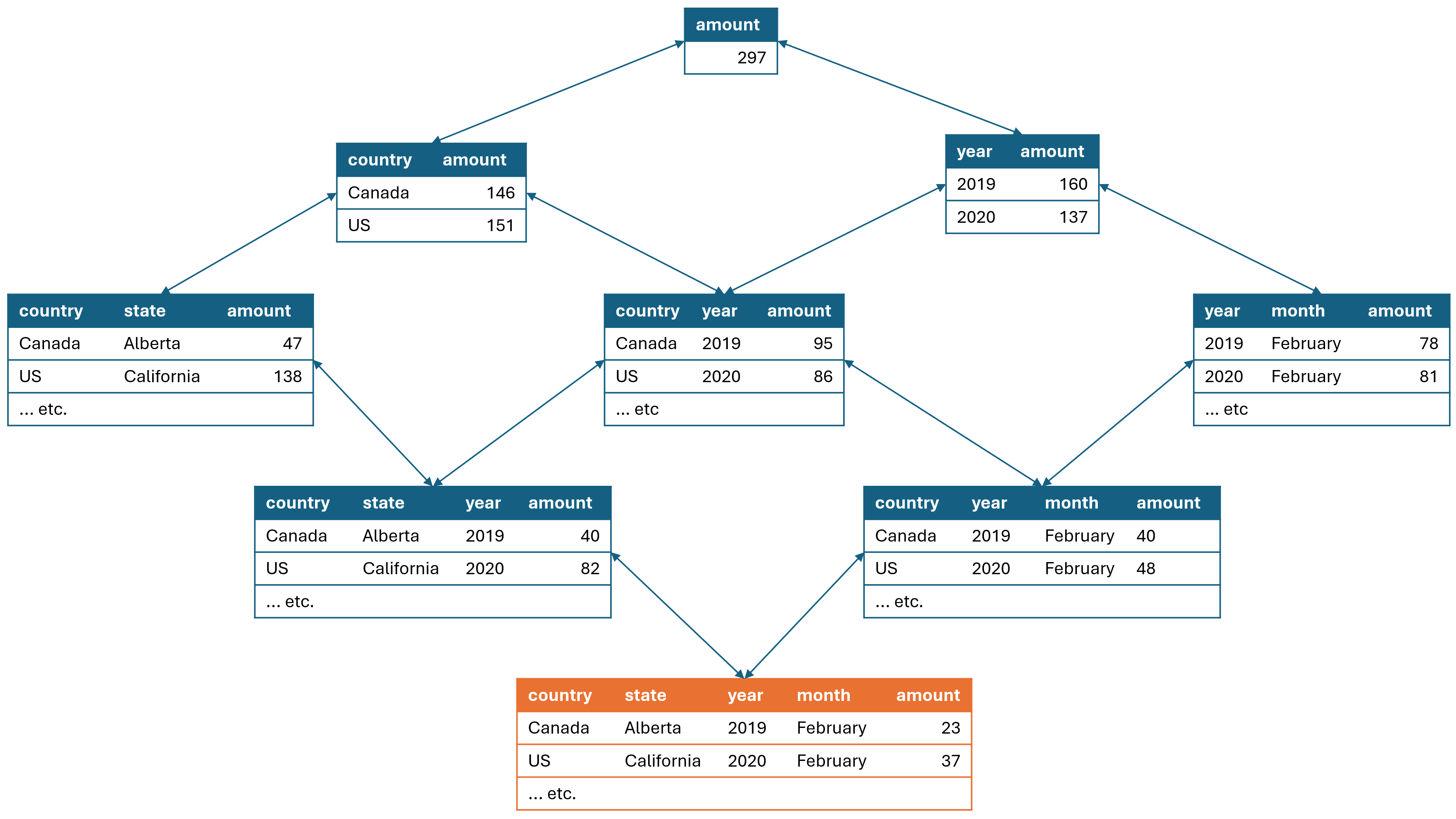
- 最底层的橙色网格包含最详细的数据,例如特定国家、州、年份和月份的金额。
- 汇总行:在每个层次结构的不同级别上,可能会缺少一些列。例如,在总计级别(Grand Total),只有金额列是可用的,而所有分组列都缺失。
视觉上下文可以过滤虚拟表中的行,类似于行上下文和筛选上下文的组合。通过EXPAND和COLLAPSE函数,视觉上下文可以在视觉网格的不同元素之间移动,从而改变当前查看的数据级别。
| 特性 | 视觉上下文 | 行上下文 | 筛选上下文 |
|---|---|---|---|
| 定义 | 用于过滤当前行,并指向虚拟表晶格中的元素 | 因为迭代而存在 | 模型中存在的筛选器 |
| 依赖 | 直接依赖于虚拟表的结构 | 依赖于模型的迭代过程 | 依赖于模型中的筛选器 |
| 作用 | 导航虚拟表晶格,改变当前查看的数据级别 | 用于计算和迭代操作 | 用于筛选数据,影响数据模型的视图 |
| 示例 | 在矩阵中显示特定国家和州的金额 | 在计算列中迭代计算每个客户的销售额 | 使用日期切片器查看特定月份的数据 |
3.6 COLLAPSE和EXPAND函数的导航规则
COLLAPSE用于从当前视觉上下文开始,将级别向上移动(月份➡年份),以查看汇总数据;EXPAND函数用于从当前视觉上下文开始,将级别向下移动(年份➡月份),以查看明细数据;它们都有两种语法形式,一种用于执行导航和计算,另一种仅执行导航。
- 仅导航视觉上下文:只有轴作为参数时,导航到比当前上下文更高级别的上下文,可以用作CALCULATE函数的调节器。仅导航时的语法为:
EXPAND ( <axis>[, N] ) EXPAND ( <column>[, <column>] ... )axis:轴引用。column:数据网格中的列。N:可选,要向上移动的级别数,默认为 1。
- 导航并计算:用表达式和轴同时作为参数时,直接返回新上下文中的表达式的值,不再需要CALCULATE。执行导航和计算时的语法如下,其中,
expression是要在新上下文中计算的表达式。EXPAND ( <expression>, <axis>[, N] ) EXPAND ( <expression>, <column>[, <column>] ... )
3.6.1 使用轴作为参数
使用轴作为参数时,COLLAPSE会将当前上下文向上级别移动,到最高级别为止;EXPAND会将当前上下文向下级别移动,到最低级别为止。以下示例将视觉上下文向上移动一个级别,效果为日期->年度月份;年度月份->年度;年度->年度总计,以下两种写法都可以:
Parent Sales = CALCULATE ( [Sales Amount], COLLAPSE ( ROWS) )
Parent Sales = COLLAPSE ( [Sales Amount], ROWS)

将视觉上下文向下移动一个级别,效果为总计->年度->年度月份->日期。与COLLAPSE不同的是,向下移动会产生更明细的结果,而表格只能返回一个值,所以需要选择一种聚合函数。比如计算子级别的均值,可以写作:
Children Average = CALCULATE ( AVERAGE ( [Sales Amount] ), EXPAND ( ROWS) )
Children Average = EXPAND ( AVERAGE([Sales Amount]),ROWS)

3.6.2 使用列作为参数
- 如果列在当前视觉上下文中存在,COLLAPSE和EXPAND会函数都会找到层次结构中第一个不包含你指定列的级别;
- 如果列不在当前视觉上下文中,则COLLAPSE和EXPAND函数不会移动视觉上下文。
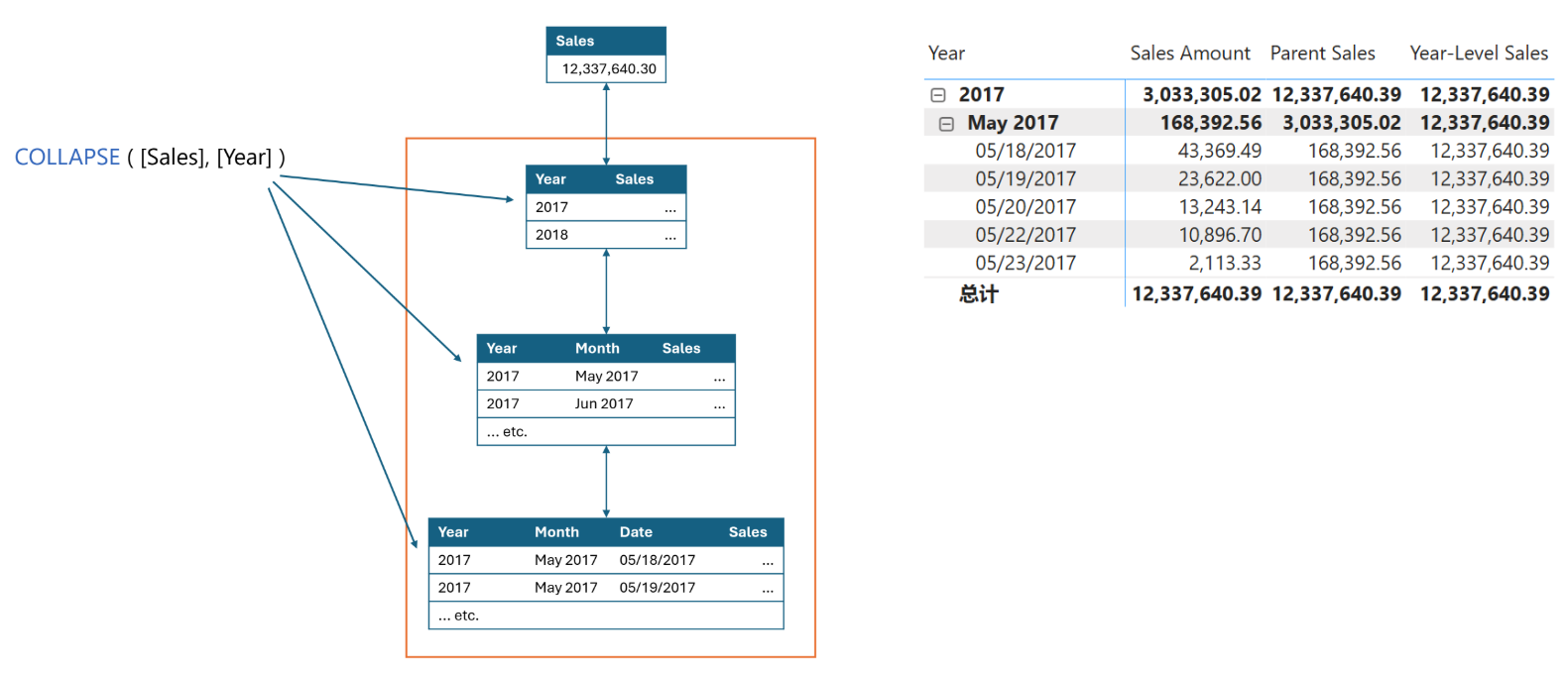
比如在COLLAPS函数中使用Year列作为参数,向上导航时,可以写作:
Year-Level Sales = CALCULATE ( [Sales Amount] ), COLLAPS( [Year] ) )
Year-Level Sales = COLLAPSE ( [Sales Amount], [Year] )
下图可以看出,除总计之外的所有级别上都存在 Year 列,即总计是第一个不包含Year列的级别,或者说是不包含Year列的最低级别,所以都会返回总计级别的计算结果。
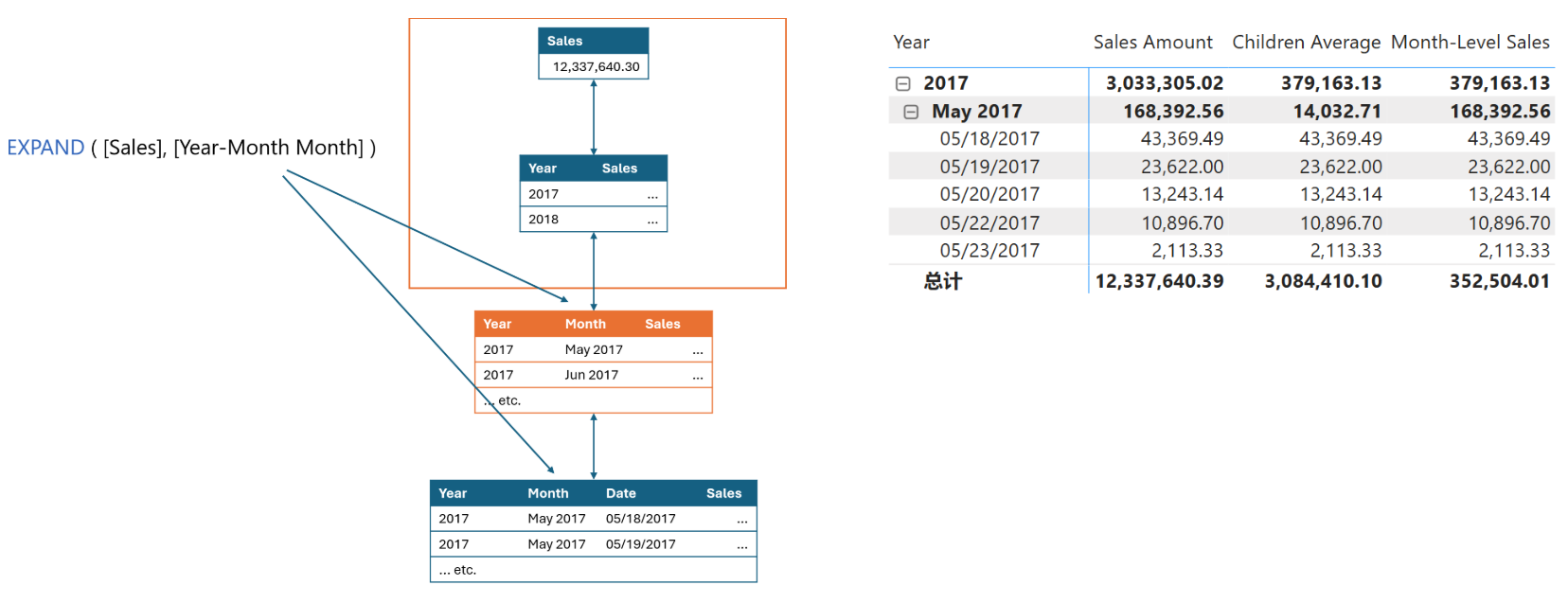
在EXPAND 函数中使用Year列作为参数,向下导航时,可以写作:
Month-Level Sales = CALCULATE( AVERAGE([Sales Amount]), EXPAND([Year Month] ))
Month-Level Sales = EXPAND( AVERAGE([Sales Amount]), [Year Month] )
前两个级别不包含月,所以EXPAND向下移动到第一个包含月的级别,为图中橙色标示的级别:
所以,同样使用Year Month列作为参数,EXPAND 和 COLLAPSE函数会导航到不同的级别:
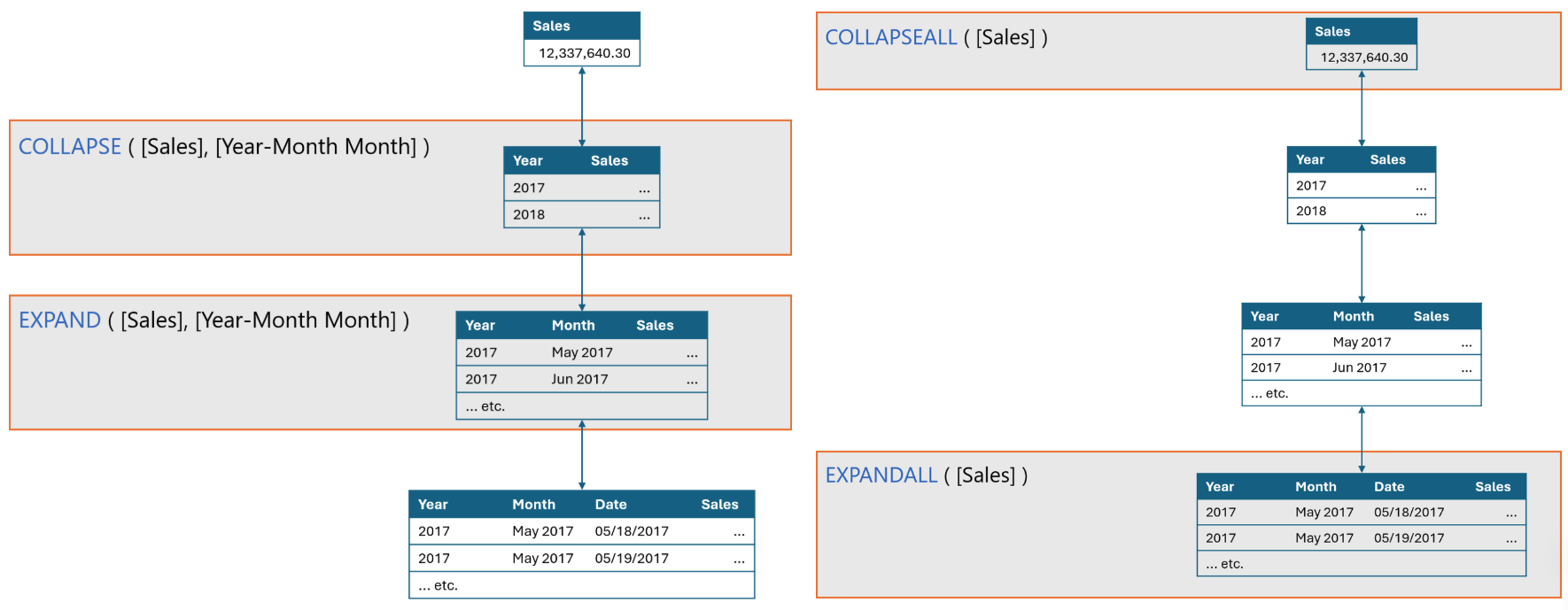
最后,视觉上下下文函数还有COLLAPSEALL和EXPANDALL,分别用于导航到最高级别和最低级别,只能使用ROWS或COLUMNS作为参数,不能使用列名,也没有参数N。
四、常用视觉计算函数
视觉计算可使用许多现有 DAX 函数,还引入了一些特定于视觉计算的函数,例如:
| 函数 | 说明 | 示例 | 快捷方式 |
|---|---|---|---|
| COLLAPSE | 计算在轴的较高级别计算。 | 父级百分比 = DIVIDE([Sales Amount], COLLAPSE([Sales Amount], ROWS)) | 空值 |
| COLLAPSEALL | 计算在轴的总级别计算。 | 总计百分比 = DIVIDE([Sales Amount], COLLAPSEALL([Sales Amount], ROWS)) | 空值 |
| EXPAND | 计算在轴的较低级别计算。 | 子级平均值 = EXPAND(AVERAGE([Sales Amount]), ROWS) | 空值 |
| EXPANDALL | 计算在轴的叶级别计算。 | 叶级别的平均值 = EXPANDALL(AVERAGE([Sales Amount]), ROWS) | 空值 |
| FIRST | 指轴的第一行。 | ProfitVSFirst = [Profit] – FIRST([Profit]) | INDEX(1) |
| ISATLEVEL | 报告指定列是否存在于当前级别。 | IsFiscalYearAtLevel = ISATLEVEL([Fiscal Year]) | 空值 |
| LAST | 指轴的最后一行。 | ProfitVSLast = [Profit] – LAST([Profit]) | INDEX(-1) |
| MOVINGAVERAGE | 在轴上添加移动平均。 | MovingAverageSales = MOVINGAVERAGE([Sales Amount], 2) | WINDOW |
| NEXT | 指轴的下一行。 | ProfitVSNext = [Profit] – NEXT([Profit]) | OFFSET(1) |
| PREVIOUS | 指轴的上一行。 | ProfitVSPrevious = [Profit] – PREVIOUS([Profit]) | OFFSET(-1) |
| RANGE | 指轴的行的切片。 | AverageSales = AVERAGEX(RANGE(1), [Sales Amount]) | WINDOW |
| RUNNINGSUM | 在轴上添加一个正在运行的求和。 | RunningSumSales = RUNNINGSUM([Sales Amount]) | WINDOW |
4.1 PREVIOUS、NEXT、FIRST、LAST
PREVIOUS用于获取视觉矩阵中某一轴上当前元素的前一个元素的值,其语法为:
PREVIOUS ( <column>[, <steps>][, <axis>][, <blanks>][, reset] )
<column>:要获取值的列。<steps>:(可选)表示向前回溯的行数,默认为 1。<axis>:(可选)指定轴,默认为视觉的第一个轴。<blanks>:(可选)定义如何处理空值。<reset>:(可选)定义计算的重置级别。
NEXT函数的语法与PREVIOUS完全相同(功能相反);而FIRST函数和LAST函数与上面的语法相比,只缺少第二个参数(偏移幅度),其他参数也完全相同。
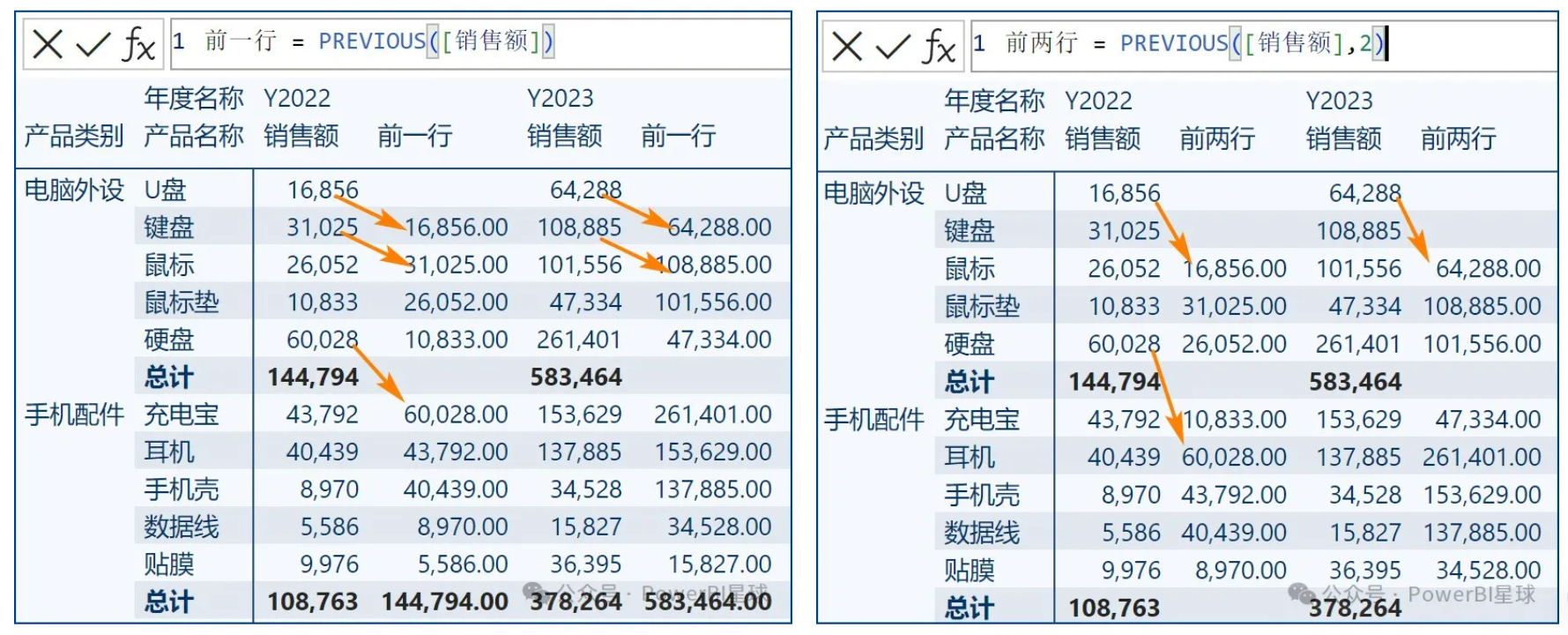
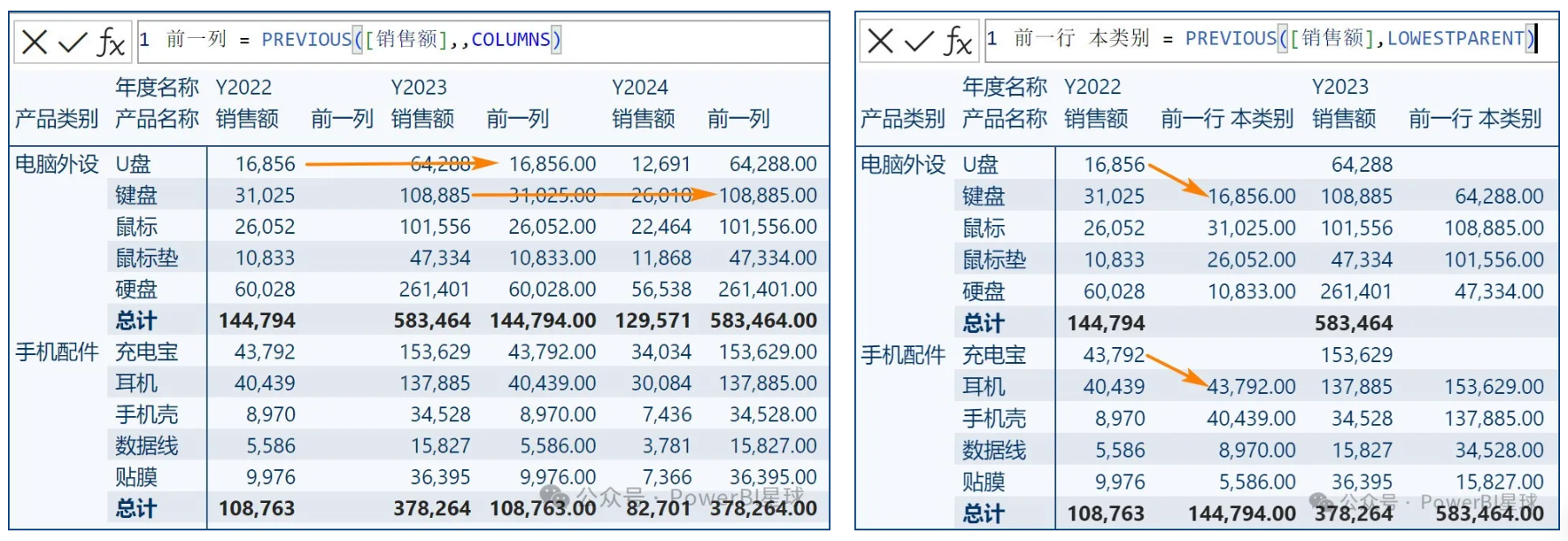
然以PowerBI星球案例模型为例,如果要引用前一行、前两行、前一列的数据,可以写作:
前一行 = PREVIOUS([销售额])
前两行 = PREVIOUS([销售额],2)
前一列 = PREVIOUS([销售额],,COLUMNS)
如果在产品类别内,引用上一行的值,不跨类别引用,就要用到最后一个重置参数
前一行 本类别 = PREVIOUS([销售额],LOWESTPARENT)
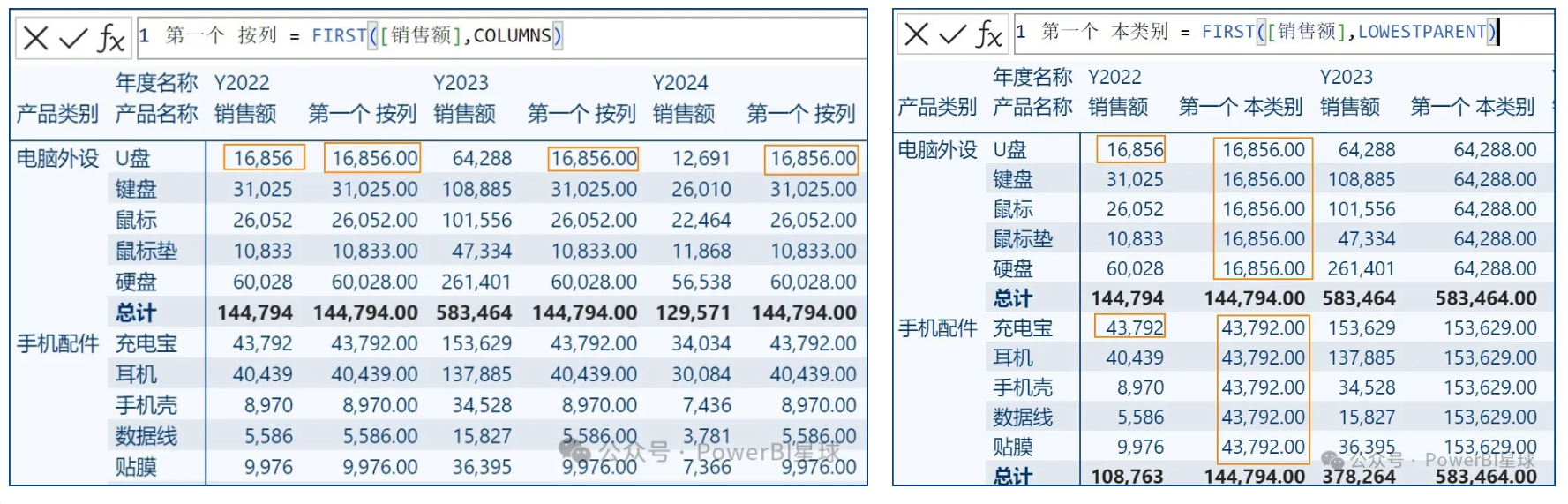
NEXT用法和上面的PREVIOUS完全一样,这里就不再介绍了。再来看一下类似的FIRST函数和LAST函数,如果要引用第一个数据,可以用FIRST函数:
第一个 = FIRST([销售额])
第一个 按列 = FIRST([销售额],COLUMNS)
第一个 本类别 = FIRST([销售额],LOWESTPARENT)
4.2 RUNNINGSUM:运动求和
参考《视觉计算》
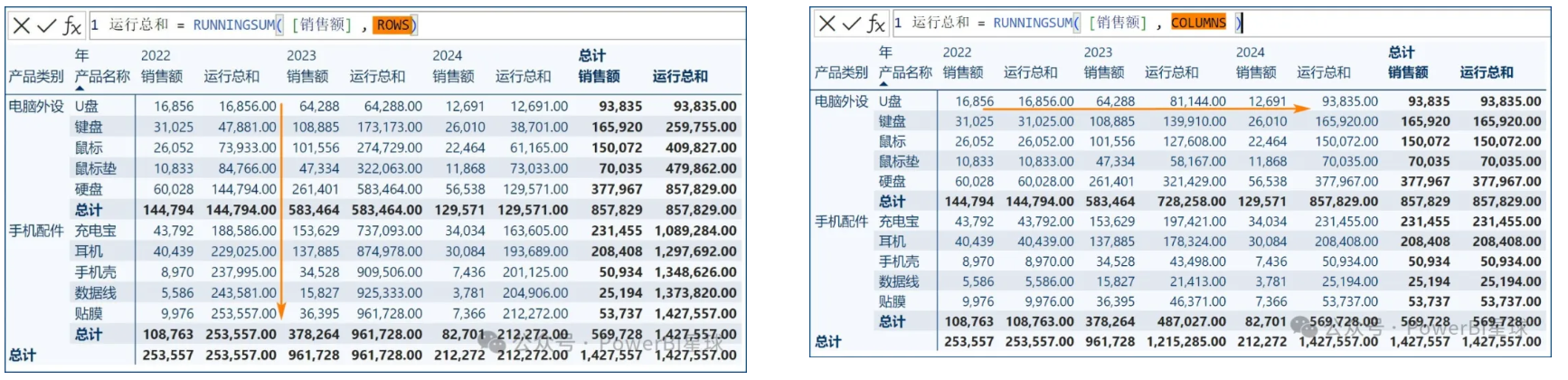
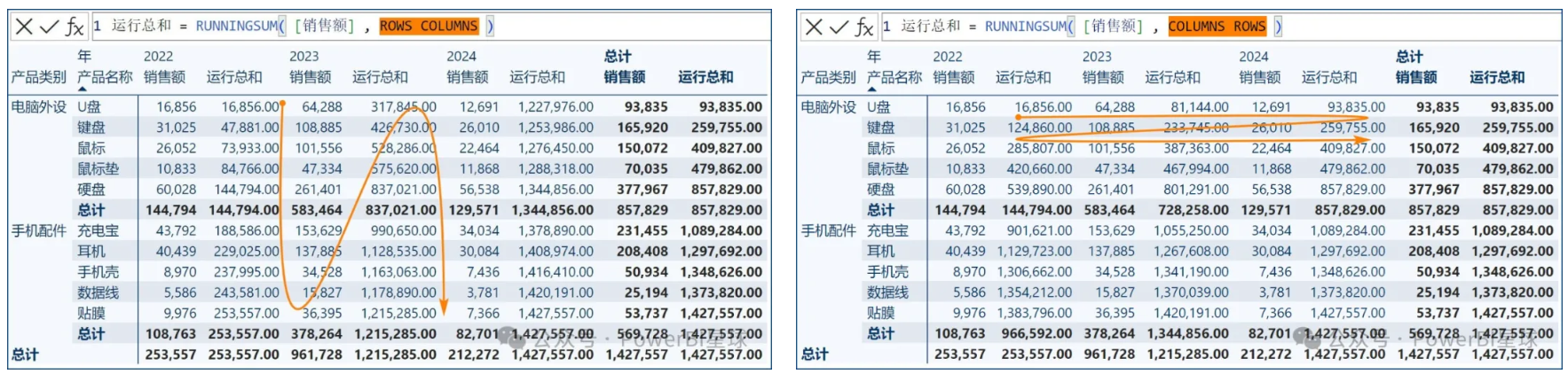
RUNNINGSUM用于沿着视觉对象的轴计算运动总和,也就是在轴的当前元素上计算的给定列的总和,其语法为:
RUNNINGSUM ( <column> // 求和字段;[, <axis>] // 轴参数,可选,确定求和的方向,默认为ROWS(从上到下)[, <blanks>] // 表示空值处理方式,可选;[, <reset>] ) // 重置参数,可选。
blanks:定义在排序时如何处理空值DEFAULT(默认):数值为空值时,在零值和负值之间排序;字符串为空值时,在所有字符串之前排序。FIRST:BLANK(空白)始终排在开头LAST:BLANK始终排在在末尾
以下示例演示了axis参数的用法:
4.3 MOVINGAVERAGE:移动平均
MOVINGAVERAGE函数用于计算沿视觉矩阵的给定轴的移动平均值,其语法为:
MOVINGAVERAGE ( <column>, <windowSize>[, <includeCurrent>][, <axis>][, <blanks>][, <reset>] )
windowSize:窗口大小,或者说是移动平均的长度(必须是常量),可选;includeCurrent:布尔值,可选,表示当前行是否包含在窗口中,默认为True。
比如对于销售总额,计算每2个季度的移动平均值,按年重置计算,可写为:
移动平均线 = MOVINGAVERAGE([销售总额], 2,,,,1)
你也可以将其在其他视觉对象中进行显示,比如在折线图中,可以明显看到,移动平均值的曲线更平滑,且窗口越大越平滑:
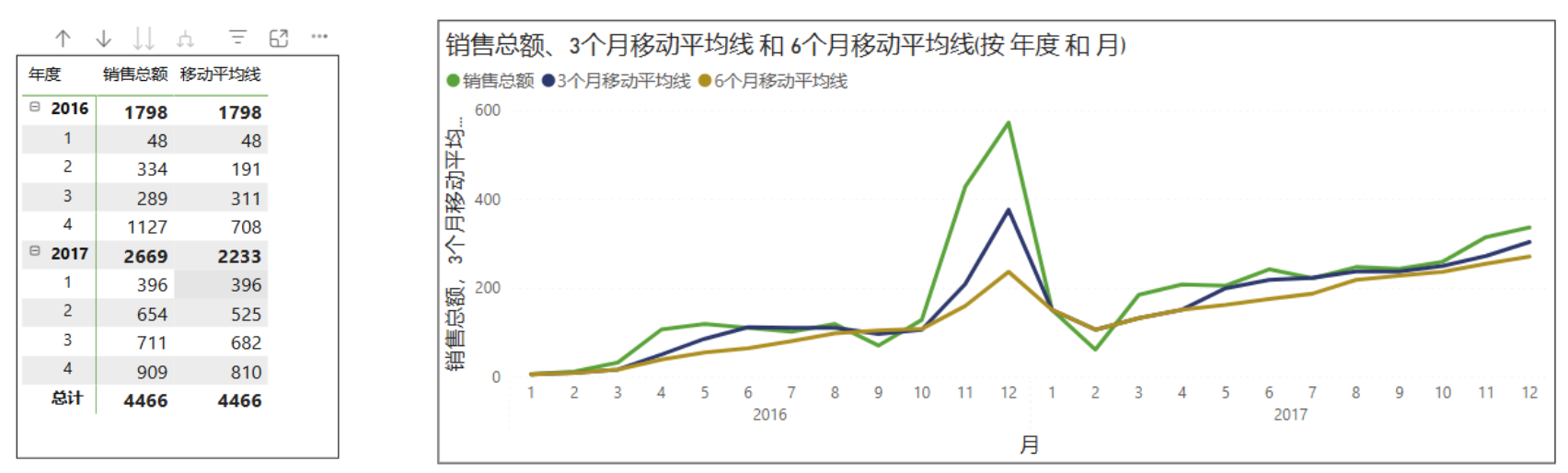
目前windowSize参数必须是常量,不能参数化,这样就无法进行动态交互。如果要来计算任意N月的移动平均,还是得用度量值的方式。
4.4 COLLAPSE 和 COLLAPSEALL
4.4.1 基础用法
假设有以下矩阵,要计算比当前产品级别高一级(产品类别)的销售额,可以写作:
上级销售额 = CALCULATE([销售额],COLLAPSE(ROWS))
上级销售额 = COLLAPSE([销售额],ROWS)
使用轴作为参数,会将当前上下文向上级别移动。在产品名称这个层级上,它移动到产品类别级别;而在产品类别层级上,它移动到总计级别。你也可以使用列参数,作为层级字段。比如返回产品名称上一级的销售额,可以写作:
产品类别销售额 = CALCULATE([销售额],COLLAPSE([产品名称]))
产品类别销售额 = COLLAPSE([销售额],[产品名称])
使用列作为参数时,如果列在当前视觉上下文中存在,COLLAPSE函数会找到层次结构中第一个不包含你指定列的级别;如果列不在当前视觉上下文中,则COLLAPSE不会移动视觉上下文。

如果要返回上2级的数据,N可以改为2,由于我们这个结构只有两级,这样它都返回了最高层级也就是整体销售额,你也可以使用COLLAPSEALL函数直接返回最高层级。
上2级销售额 = CALCULATE([销售额],COLLAPSE(ROWS,2))
上2级销售额 = COLLAPSE([销售额],ROWS,2)总计 = CALCULATE([销售额],COLLAPSEALL(ROWS))
总计 = COLLAPSEALL([销售额],ROWS)

4.4.2 计算各种占比
产品名称向上折叠一次就是产品类别,产品类别向上折叠一次就是总体,所以各种占比可以写作:
// 可视化计算的结果默认保留2位小数,套个FORMAT函数,让它显示百分比格式总体占比 = FORMAT(DIVIDE([销售额],COLLAPSE([销售额],[产品类别])),"0%")
总体占比 = FORMAT(DIVIDE([销售额],COLLAPSE([销售额],ROWS,2)),"0%")
如果要在产品类别内部,计算各产品的占比,以及计算层级占比,可写作:
类别内产品占比 = FORMAT(DIVIDE([销售额],COLLAPSE([销售额],[产品名称])),"0%")
层级占比 = IF(ISINSCOPE([产品名称]),[类别内产品占比],[总体占比])
这里层级占比是使用ISINSCOPE函数判断当前层级是否是产品名称,更简单的方式是直接用内置的“父级的百分比”写法,用ROWS作为COLLAPSE的参数(层级占比的内在逻辑本来就是父级百分比,用ROWS做参数时会自动折叠当前层级):
父级占比 = FORMAT(DIVIDE([销售额], COLLAPSE([销售额], ROWS)),"0%")

4.5 EXPAND和EXPANDALL
还是以上一章节的数据为例,计算下一级别、下两个级别的销售额最大值可写作:
下1级别最大值 = CALCULATE(MAX([销售额]),EXPAND(ROWS))
下2级别最大值 = CALCULATE(MAX([销售额]),EXPAND(ROWS,2))
下2级别最大值 = CALCULATE(MAX([销售额]),EXPANDALL(ROWS))
如果使用列名作为参数,可以写作:
产品名称下1级别最大值=CALCULATE(MAX([销售额]),EXPAND([产品名称])) // 等价于EXPAND(ROWS)
产品类别下1级别最大值=CALCULATE(MAX([销售额]),EXPAND([产品类别])) // EXPAND(ROWS,2)

- 在产品名称上下文中,由于没有更明细的级别,所以它返回的值还是本产品的销售额。
- 在产品类别上下文,向下1个级别是产品名称
- 在总计上下文中,向下1个级别是产品类别,向下两个级别是产品名称
4.6 ROWNUMBER
Power BI中有个窗口函数ROWNUMBER,它的功能是返回当前上下文在指定分区内按指定顺序排序的唯一级别,可以实现行号的效果。虽然作为正常的DAX函数,ROWNUMBER较为复杂,不过它在可视化计算中使用非常简单。
-
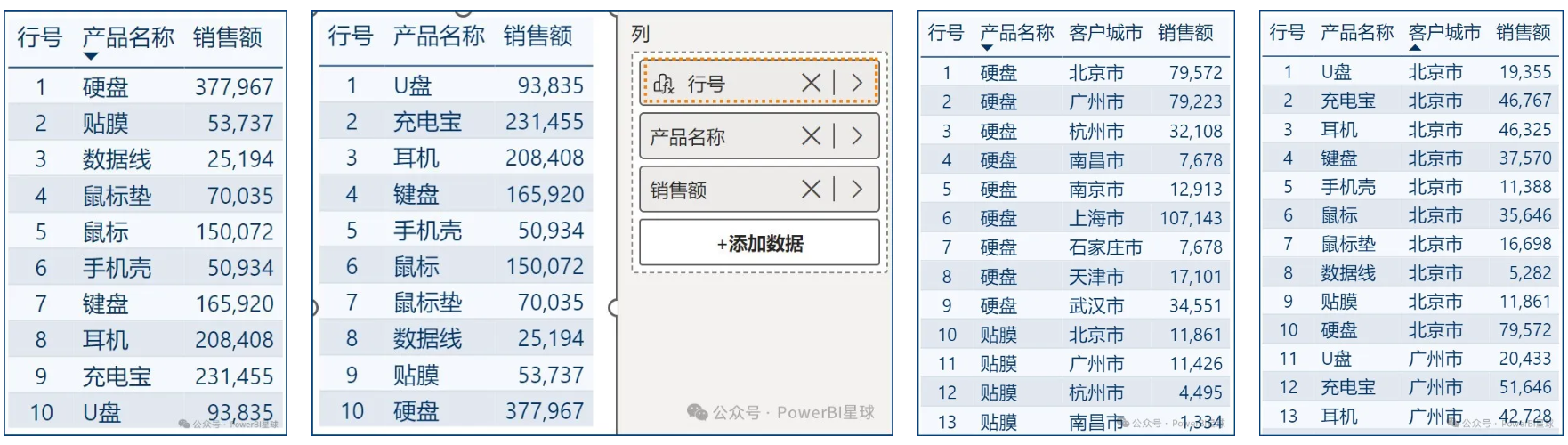
使用默认参数,直接生成行号:
行号= FORMAT(ROWNUMBER(),"0")。
新增的计算列默认在表格右侧,直接将其拖拽到左侧就行。无论产品名称是按升序还是降序排列,或者是多添加一个城市字段,甚至改成按城市升降排序,序号都会会自动适应上下文。
-
指定排序依据:如果按照销售额来排序,这个行号就会错乱,此时就需要就需要用到ORDERBY参数了。可以写成:
行号 = VAR No_=ROWNUMBER( ROWS , ORDERBY([销售额],ASC) ) RETURN FORMAT(No_,"0")
-
层级行号:如在每个产品类别内,生成从1开始的序号,就要用到reset参数。由于reset参数和ORDERBY参数不能共用,所以销售额会错乱。
行号 = VAR No_=ROWNUMBER( ROWS , LOWESTPARENT ) RETURN FORMAT(No_,"0")
-
层级行号,且按销售额排序。如果想实现按类别进行销售额排序的效果,就得使用普通的的DAX函数的写法:
行号 = VAR No_= ROWNUMBER(ALLSELECTED([产品类别],[产品名称]), // 使用ROWS轴字段作为参数ORDERBY([销售额],DESC),PARTITIONBY([产品类别]) ) RETURN FORMAT(No_,"0")也可不用轴作为参数,而是一般的度量值写法:
行号 度量值 = VAR No_= ROWNUMBER(ALLSELECTED('产品表'[产品类别],'产品表'[产品名称]),ORDERBY([销售额],DESC),PARTITIONBY([产品类别]) ) RETURN FORMAT(No_,"0")

五、进阶示例(待补)
5.1 可视化排序
参考《探索可视化计算中的 RANK 函数》
5.2 动态排序
参考《视觉计算实现动态排名》






