目标检测模型的训练过程涉及多个关键性能指标和损失函数的变化,这些数据能够直观反映模型的收敛速度、最终精度以及改进效果。本文旨在通过绘制YOLOv11模型在训练过程中的精准率(Precision)、召回率(Recall)、mAP@0.5 、mAP@0.5 :0.95以及各种损失的变化曲线,支持多文件数据对比,从而为论文中展示不同算法的性能差异提供直观依据。
1. results.csv 文件
在目标检测模型(如YOLO系列)的训练过程中,通常会生成一个记录训练和验证过程性能指标的日志文件。常见的日志文件格式为 .csv,例如 results.csv。该文件包含了模型在每个训练轮次(Epoch)中的关键性能指标和损失值,用于后续分析和可视化。
1.1 基本结构
results.csv 文件以逗号分隔的表格形式存储数据,每一行代表一个训练轮次(Epoch),每一列对应一个特定的指标或损失值。文件通常包含以下字段:
| 字段名称 | 描述 |
|---|---|
epoch | 当前训练轮次编号,从1开始递增。 |
train/box_loss | 训练集上的定位损失(Bounding Box Loss),衡量预测框与真实框的位置偏差。在训练过程中,此值逐渐变小,越小表示模型预测的边界框与真实边界框之间的差异越小。 |
train/cls_loss | 训练集上的分类损失(Classification Loss),衡量目标类别预测的准确性。在训练过程中,此值逐渐变小,越小表示模型对目标类别的预测越准确。 |
train/dfl_loss | 训练集上的分布焦点损失(Distribution Focal Loss),用于优化边界框分布。将边界框的回归问题转化为对边界框四个边的分布预测问题,越小表示预测越准确。 |
metrics/precision | 验证集上的精准率(Precision),反映预测框的准确性。 用于衡量所有被预测为正类的样本中,真正的正类样本所占的比例。 |
metrics/recall | 验证集上的召回率(Recall),反映对真实目标的覆盖能力。 用于衡量所有实际为正类的样本中,被正确预测为正类的样本所占的比例。 |
metrics/mAP_0.5 | 验证集上的mAP@0.5值,交并比(IoU)阈值为0.5时的平均精度。 |
metrics/mAP_0.5:0.95 | 验证集上的mAP@0.5:0.95值,交并比(IoU)阈值从0.5到0.95范围内的平均精度。 |
val/box_loss | 验证集上的定位损失(Bounding Box Loss)。 |
val/cls_loss | 验证集上的分类损失(Classification Loss)。 |
val/dfl_loss | 验证集上的分布焦点损失(Distribution Focal Loss)。 |
x/lr0、x/lr1、x/lr2 | 训练过程中的学习率变化。 |
示例数据
以下是一个典型的 results.csv 文件内容示例:
epoch,train/box_loss,train/cls_loss,train/dfl_loss,val/box_loss,val/cls_loss,val/dfl_loss,metrics/precision,metrics/recall,metrics/mAP_0.5,metrics/mAP_0.5:0.95
1,0.1234,0.0876,0.0543,0.1123,0.0987,0.0456,0.6543,0.7210,0.5821,0.3210
2,0.1123,0.0765,0.0432,0.1012,0.0876,0.0345,0.6789,0.7432,0.6012,0.3456
3,0.1012,0.0654,0.0321,0.0987,0.0765,0.0234,0.7012,0.7654,0.6234,0.3678
...
2. 使用方法
2.1 单个文件指标绘制

此处仅以metrics/mAP50(B)这一列的数据为例进行展示,其余指标的绘制流程,代码与此完全一致,自行修改列名。
import pandas as pd
import matplotlib.pyplot as plt
import logging
import sys
import matplotlib
matplotlib.use('TkAgg')
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')def load_data(csv_path):"""加载 CSV 文件并清理列名中的多余空格。"""try:data = pd.read_csv(csv_path)data.columns = data.columns.str.strip() # 清理列名中的多余空格logging.info(f"成功加载数据文件: {csv_path}")return dataexcept FileNotFoundError:logging.error(f"文件未找到: {csv_path}")sys.exit(1)except Exception as e:logging.error(f"加载数据时发生错误: {e}")sys.exit(1)def extract_column(data, column_name):"""提取指定列的数据。"""if column_name in data.columns:logging.info(f"找到列: {column_name}")return data[column_name]else:logging.error(f"列名 '{column_name}' 未在数据中找到。可用列: {list(data.columns)}")sys.exit(1)def plot_curve(data, column_name, output_file):"""绘制曲线图并保存到文件。"""plt.style.use('ggplot') # 使用 ggplot 样式提升图表美观度# 绘制曲线plt.plot(data, label='Model-1', color='red', linewidth=1)# 添加图例、标题和坐标轴标签plt.legend(loc='lower right')plt.xlabel('Epoch')plt.ylabel('mAP_0.5(%)')plt.title('mAP_0.5 Curve')# 添加网格线plt.grid(True)# 保存图像plt.savefig(output_file)logging.info(f"图表已保存到: {output_file}")def main():# 定义输入输出路径csv_path = 'run/train1/exp/results.csv' # 替换为实际的 CSV 文件路径output_file = 'mAP_05_curve.png' # 输出图像文件名# 加载数据data = load_data(csv_path)# 提取目标列数据column_name = 'metrics/mAP50(B)' # 替换为目标列名mAP_05_data = extract_column(data, column_name)# 绘制并保存图表plot_curve(mAP_05_data, column_name, output_file)if __name__ == "__main__":main()
2.1.1 效果
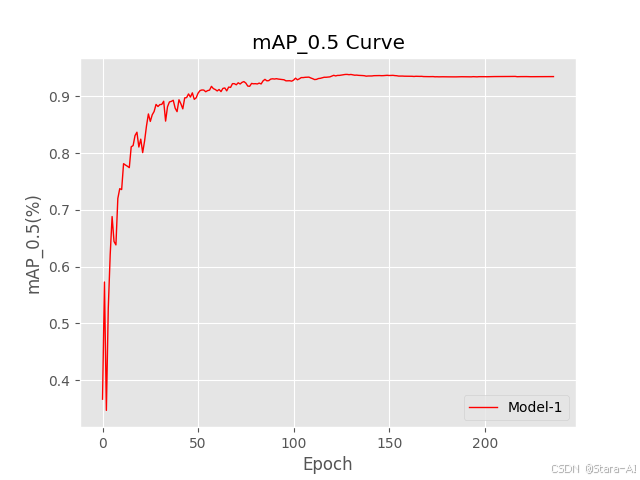
2.2 多文件绘制
import pandas as pd
import matplotlib.pyplot as plt
import logging
import sys
import matplotlib
matplotlib.use('TkAgg')# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')def load_data(csv_path):"""加载 CSV 文件并清理列名中的多余空格。"""try:data = pd.read_csv(csv_path)data.columns = data.columns.str.strip() # 清理列名中的多余空格logging.info(f"成功加载数据文件: {csv_path}")return dataexcept FileNotFoundError:logging.error(f"文件未找到: {csv_path}")sys.exit(1)except Exception as e:logging.error(f"加载数据时发生错误: {e}")sys.exit(1)def extract_column(data, column_name):"""提取指定列的数据。"""if column_name in data.columns:logging.info(f"找到列: {column_name}")return data[column_name]else:logging.error(f"列名 '{column_name}' 未在数据中找到。可用列: {list(data.columns)}")sys.exit(1)def plot_curves(data_list, labels, colors, output_file):"""绘制多条曲线图并保存到文件。"""plt.style.use('ggplot') # 使用 ggplot 样式提升图表美观度for i, data in enumerate(data_list):plt.plot(data, label=labels[i], color=colors[i], linewidth=1)# 添加图例、标题和坐标轴标签plt.legend(loc='lower right')plt.xlabel('Epoch')plt.ylabel('mAP_0.5(%)')plt.title('mAP_0.5 Curve Comparison')# 添加网格线plt.grid(True)# 保存图像plt.savefig(output_file)logging.info(f"图表已保存到: {output_file}")def main():# 定义输入输出路径csv_paths = ['run/train1/exp/results.csv', # 替换为实际的 CSV 文件路径'run/train/exp3/results.csv','run/refine_train1/exp/results.csv','run/refine_train/exp14/results.csv']output_file = 'mAP_05_comparison_curve.png' # 输出图像文件名# 目标列名column_name = 'metrics/mAP50(B)' # 替换为目标列名# 加载数据并提取目标列data_list = []labels = ['Model-1', 'Model-2', 'Model-3', 'Model-4'] # 每个模型的标签colors = ['red', 'green', 'blue', 'orange'] # 每个模型的颜色for i, csv_path in enumerate(csv_paths):data = load_data(csv_path)mAP_05_data = extract_column(data, column_name)data_list.append(mAP_05_data)logging.info(f"成功提取数据: {labels[i]}")# 绘制并保存图表plot_curves(data_list, labels, colors, output_file)if __name__ == "__main__":main()
2.2.1 效果
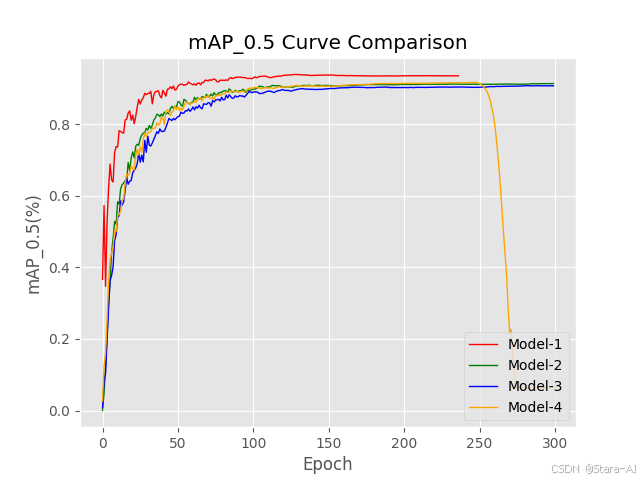
注:可以修改自己想要的列,分别指定文件路径,获取指定列名,绘制曲线
3. 数据分析与模型优化的意义
目标检测模型的训练过程本质上是一个优化问题,通过不断调整模型参数以最小化损失函数并最大化性能指标。results.csv 文件中的数据记录了这一动态过程的关键信息,为研究人员提供了深入分析模型行为的重要依据。
-
收敛速度分析
损失曲线(如train/box_loss和val/box_loss)的变化趋势能够直观反映模型的收敛速度。快速收敛通常表明模型在训练初期已经掌握了数据的基本特征,而缓慢收敛可能暗示模型复杂度不足或学习率设置不当。通过对多文件数据的对比,可以评估不同算法或超参数配置对收敛速度的影响。 -
最终精度评估
验证集上的性能指标(如metrics/mAP_0.5和metrics/mAP_0.5:0.95)是衡量模型最终精度的核心标准。mAP@0.5 更注重宽松条件下的检测能力,适合评估模型在实际应用中的表现;而 mAP@0.5:0.95 则反映了模型在高精度要求下的综合性能。通过绘制这些指标的变化曲线,可以清晰地观察模型在训练后期的性能提升情况。 -
改进效果验证
当引入新的算法或优化策略时,借助多文件数据对比功能,可以直观展示改进前后的性能差异。例如,通过比较两个模型的 mAP 曲线,可以验证新策略是否有效提升了模型的检测能力。这种定量分析方法为学术论文中的实验结果提供了强有力的支撑。 -
过拟合与欠拟合检测
训练集和验证集的损失值变化曲线可以帮助识别模型是否存在过拟合或欠拟合问题。如果训练损失持续下降而验证损失开始上升,则表明模型可能出现了过拟合;反之,如果两者均较高且下降缓慢,则可能存在欠拟合。结合精准率和召回率的变化,可以进一步判断模型在不同阶段的表现。

)
报错)



