NLP算法工程师面试题
- 讲一下transformer
Transformer是一种用于自然语言处理和机器翻译的神经网络模型。它引入了自注意力机制,能够捕捉输入序列中的长距离依赖关系。Transformer由编码器和解码器组成,每个模块都由多个层堆叠而成。编码器用于将输入序列映射到一系列连续表示,解码器则将这些表示转化为输出序列。
- transformer怎么调优
Transformer的调优可以包括以下几个方面:
- 调整模型架构:可以尝试增加或减少编码器和解码器层的数量,调整隐藏单元的维度等。
- 学习率调度:使用学习率调度策略,如逐渐减小学习率、使用预热步骤等。
- 正则化:使用Dropout、权重衰减等正则化技术,防止过拟合。
- 批量大小和训练迭代次数:调整批量大小和训练迭代次数,以获得更好的训练效果。
- 初始化策略:选择合适的参数初始化方法,如Xavier初始化、高斯初始化等。
- 梯度裁剪:为了防止梯度爆炸,可以对梯度进行裁剪,限制梯度的最大范数。
- 讲一下CRF,公式是什么
条件随机场(CRF)是一种用于序列标注任务的统计模型。CRF可以建模输入序列和输出序列之间的依赖关系。其公式如下: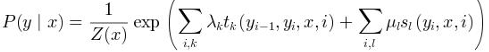 其中,P(yx)是给定输入序列×的条件下输出序列y的概率,Z(x)是归一化因子,入k和uI是特征函数的权重,tk和sI是特征函数,y_i和y_i1分别表示输出序列的第i个和第(1)个标签,N是输出序列的长度,K是标签的数量。
其中,P(yx)是给定输入序列×的条件下输出序列y的概率,Z(x)是归一化因子,入k和uI是特征函数的权重,tk和sI是特征函数,y_i和y_i1分别表示输出序列的第i个和第(1)个标签,N是输出序列的长度,K是标签的数量。
- 讲讲word2vec和word embedding区别
Word2Vec是一种用于将单词表示为连续向量的技术,它通过学习上下文信息来为每个单词生成固定维度的向量表示。Word2Vec基于分布式假设,即将上下文相似的单词嵌入到相似的向量空间中。Word2Vec有两种模型:Skip-gram和CBOW(Continuous Bag-of-Nords)。Word embedding是指将单词映射到低维度的向量空间的一般术语。Word2Vec是一种用于生成word embedding的具体方法的技术。Word2Vec通过训练一个神经网络模型,从大规模文本语料中学习单词的分布式表示。区别在于,Word2Vec是一种具体的算法,它是生成word embedding的一种方法。而word embedding是指将单词映射到低维度向量空间的技术,可以使用不同的方法来实现,而不限于Word2Vec。Word2Vec是基于上下文信息的分布式表示方法之一,而word embedding是一个更广泛的概念,涵盖了多种生成单词向量表示的方法,如GloVe、FastText等
- gpt3和gpt2的区别






