一: SQL 优化
1.1 插入数据
1.1.1 批量插入
单条 INSERT 语句执行时,需经历语法解析、事务提交、磁盘 I/O 等多个步骤。批量插入将多条数据合并为一条 SQL,能够减少网络通信和事务开销。
-- 单条插入(低效)
INSERT INTO tb_user (name, age) VALUES ('张三', 25);
INSERT INTO tb_user (name, age) VALUES ('李四', 30);-- 批量插入(高效)
INSERT INTO tb_user (name, age) VALUES ('张三', 25),('李四', 30);
一次插入语句插入的数据建议控制在 500~1000 ,避免单条 SQL 过大导致内存溢出或锁竞争,如果数据量太大可通过分批次提交(如每 1000 条提交一次)平衡性能与资源消耗。
1.1.2 手动提交事务
默认情况下,每条 INSERT 语句会自动提交事务,频繁提交事务会导致事务日志频繁刷盘,增加 I / O 压力。
START TRANSACTION; -- 开启事务
INSERT INTO tb_user (name, age) VALUES ('张三', 25);
INSERT INTO tb_user (name, age) VALUES ('李四', 30);
COMMIT; -- 手动提交事务
此时事务日志刷盘次数从 N 次(N 为插入条数)降低为 1 次,适用于高并发写入场景。
1.1.3 主键顺序插入
InnoDB 表的数据按主键顺序组织为 B+ 树结构。顺序插入主键值可减少页分裂和碎片,提升写入效率。所以如果没有业务强需求,建议使用 BIGINT 自增主键,分布式场景可使用雪花算法生成有序主键。
1.1.4 大批量插入场景的优化
适用于一次性插入数十万甚至百万级数据的场景,比如在历史数据迁移场景下可以使用。核心方法是使用 LOAD DATA INFILE 指令直接加载数据文件,绕过 SQL 解析和事务机制。
- 首先启动本地文件加载开关:
# 客户端连接时添加参数 --local-infile
mysql --local-infile -u root -p# 在 MySQL 会话中开启全局开关
SET GLOBAL local_infile = 1;
- 接着准备一下数据文件 xxx.csv,文件格式如下:
张三,25
李四,30
- 执行 LOAD 指令
LOAD DATA LOCAL INFILE '/path/to/data.csv' INTO TABLE tb_user
FIELDS TERMINATED BY ',' -- 字段分隔符
LINES TERMINATED BY '\n' -- 行分隔符
(name, age); -- 目标表字段
1.2 主键优化
在 InnoDB 存储引擎中,数据按主键顺序物理存储,聚集索引的叶子节点直接包含行数据,所有二级索引的叶子节点存储主键值。如果主键是无序的就需要付出一些代价:页分裂与页合并。
页分裂:新数据插入时,目标页已满且主键值不连续,InnoDB 将当前页分裂为两页,重新分配数据并调整 B+ 树结构,这会增加磁盘 I/O 操作,还会导致数据页碎片化,降低查询效率,举个例子:假设页1已满(主键10, 20, 30),插入主键15(无序),此时就会发生页分裂:
分裂前:页1 [10,20,30]
分裂后:页1 [10,15], 页2 [20,30]
页合并:删除记录后,如果页的空间利用率低于 MERGE_THRESHOLD(默认50%),InnoDB 会尝试与相邻页合并以优化空间。
| 原则 | 说明 | 推荐方案 | 注意事项 |
|---|---|---|---|
| 优先使用短主键 | 主键长度直接影响索引树层级和存储空间。更短的主键可减少二级索引体积,提升查询效率。 | 自增主键、雪花算法 ID | 避免使用 UUID(16字节)或长字符串,因其占用空间大且无序。 |
| 保证顺序插入 | 主键值按顺序递增写入,避免页分裂和磁盘碎片,显著提升写入性能。 | AUTO_INCREMENT 自增主键 | 分布式场景可用雪花算法,避免因主键无序导致的性能下降。 |
| 禁止修改主键 | 修改主键需同步更新所有二级索引中的旧主键值,导致高并发下锁竞争和大量 I/O 开销。 | 业务设计时隔离主键与业务逻辑字段 | 若必须修改主键,建议通过新增记录实现,而非直接逻辑删除或者新增。 |
1.3 oder by 优化
在 MySQL 中,ORDER BY 的排序操作通过以下两种方式实现:
- Using filesort:通过排序缓冲区进行额外排序,效率较低。
- Using index:直接利用索引的有序性返回结果,无需额外排序,效率高。
所以我们可以通过为排序字段建立合适的索引来优化 oder by 排序的执行效率,但是要注意:如果 order by 字段全部使用升序排序或者降序排序就都会走索引,但是如果一个字段升序排序,另一个字段降序排序,此时就都不会走索引,当排序字段方向不一致时,需创建指定方向的联合索引。
-- 示例:创建支持混合排序的索引
CREATE INDEX idx_age_asc_phone_desc ON tb_user(age ASC, phone DESC);
-- 有效查询
EXPLAIN SELECT age, phone FROM tb_user ORDER BY age ASC, phone DESC;
-- 无效查询(索引方向不匹配)
EXPLAIN SELECT age, phone FROM tb_user ORDER BY age DESC, phone ASC;
所以我们可以通过添加索引的方式对 oder by 进行优化,多字段排序的适合也要遵循最左前缀法则,尽量使用覆盖索引避免回表查询,
1.4 group by 优化
同样的,group by 也可以通过索引来提高执行效率,在分组操作时,索引的使用也是满足最左前缀法则的
1.5 limit 优化
使用 LIMIT 进行深度分页时如 LIMIT 9,000,000, 10,MySQL 需要先扫描并排序前 9,000,010 条数据,最后实际上只返回最后 10 条,前 9,000,000 条都会被丢弃,即使有索引也需要完整遍历索引树完成排序,造成大量的 I / O 和 CPU 资源浪费,优化的核心思路是通过覆盖索引避免回表查询,减少需要处理的数据量。
1.6 count 优化
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count() 的时候会直接返回这个数,效率很高,而 InnoDB 在执行 count() 时,需要把数据一行一行地从引擎里面读出来,然后累计计数。优化的核心思路是自己计数,如创建 key-value 表存储在内存或硬盘,或者是用 redis
-
count(字段):没有 not null 约束的话,InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为 null,不为 null,计数累加;有 not
null 约束的话,InnoDB 引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加 -
count(主键):InnoDB引擎会遍历整张表,把每行的主键 id 值都取出来,返回给服务层,服务层拿到主键后,直接按行进行累加,因为主键不可能为空
-
count(1):InnoDB 引擎遍历整张表,但不取值。服务层对于返回的每一层,放一个数字 1 进去,直接按行进行累加
-
count(*):InnoDB 引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加
按效率排序:count(字段) < count(主键) < count(1) < count(*),所以尽量使用 count(*)
1.7 update 优化
对于 update 的优化,要避免行锁升级为表锁,因为 InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,如果你的索引失效了,在全表扫描时为避免逐行加锁的资源消耗,行锁会自动升级为表级锁。
-- 案例1:使用主键索引(行锁),这句由于 id 有主键索引,所以只会锁这一行;
UPDATE user SET balance = 100 WHERE id = 5; -- 仅锁定 id=5 的行-- 案例2:使用无索引字段(表锁),这句由于 name 没有索引,所以会把整张表都锁住进行数据更新,解决方法是给 name 字段添加索引
UPDATE user SET balance = 200 WHERE phone = '13800138000'; -- 锁定整个表
二: 视图
视图本身并不存储任何物理数据,而是通过保存一个预先编写的 SELECT 查询语句,在每次访问视图时动态执行该查询并实时生成结果集。
-- 创建视图,create or replace 表示创建或者替换视图,如果视图已经存在就替换,不存在就新建,view 后面的 stu_v_1 是视图名称,as 后面跟着的是视图的逻辑,接着把数据存入虚拟表 stu_v_1 中
create or replace view stu_v_1 as select id, name from student where id <= 10;-- 查询视图
show create view stu_v_1;
select * from stu_v_1;-- 修改视图
create or replace view stu_v_1 as select id, name, no from student where id <= 10;
alter view stu_v_1 as select id, name from student where id <= 10;-- 删除视图
drop view if exists stu_v_1;/* */
2.1 检查选项
WITH CHECK OPTION 是视图定义中的关键子句,用于强制约束通过视图修改的数据必须符合视图的查询条件,为了确定检查的范围,mysql 提供了两个选项:CASCADED 和 LOCAL,默认值为 CASCADED。
CREATE VIEW active_users AS
SELECT * FROM users WHERE status = 1
WITH CHECK OPTION; -- 因为此时视图查询的是 status = 1 的数据,所以此时禁止插入 status≠1 的数据
| 对比项 | CASCADED(级联检查) | LOCAL(本地检查) |
|---|---|---|
| 触发条件 | 当前视图或任何依赖视图定义了 WITH CASCADED CHECK OPTION | 当前视图定义了 WITH LOCAL CHECK OPTION |
| 检查范围 | 当前视图及其所有上游视图的查询条件(无论上游是否定义检查选项) | 仅检查当前视图和显式定义检查选项的依赖视图 |
| 行为特点 | 严格模式:强制所有层级条件必须满足 | 宽松模式:仅验证有明确约束的层级 |
| 适用场景 | 需要确保数据在所有视图层级中都合法(例如多层视图嵌套时,要求所有层级条件同时生效) | 允许部分层级条件不强制检查(例如仅确保当前视图条件合法,不追溯未定义检查的依赖视图) |
2.2 视图更新
视图需要满足以下所有条件才能执行 INSERT / UPDATE / DELETE 操作:
- 不使用聚合函数
- 不使用集合操作 UNION 或者 UNION ALL
- 不使用 GROUP BY 或 HAVING 子句
- 不使用去重 DISTINCT
视图的作用:
| 作用类型 | 描述 | 实现价值 |
|---|---|---|
| 简化复杂性 | 将高频或复杂的查询逻辑封装为视图,用户可直接操作视图而无需重复编写完整查询条件。 | 提升开发效率,避免代码冗余,降低使用门槛。 |
| 权限控制 | 通过视图限制用户只能访问特定行或列(如 WHERE status=1),弥补数据库原生行列权限的不足。 | 实现行级或列级数据权限隔离,保障敏感数据安全性。 |
| 结构解耦 | 视图作为逻辑层抽象,屏蔽底层表结构变化(如字段重命名、表拆分),仅需维护视图定义一致性。 | 降低表结构变更对上层应用的影响,增强系统可维护性。 |
-- 1.为了保证数据库表的安全性,开发人员在操作tb_user表时,只能看到的用户的基本字段,屏蔽手机号和邮箱两个字段。
create view tb user view as select id,name,profession, age,gender,status,createtime from tb_user;
select *from tb user view;-- 2.查询每个学生所选修的课程(三张表联查),这个功能在很多的业务中都有使用到,为了简化操作,定义一个视图。
create view tb_stu_course_view
select s.name student_name, s.no student_no, c.name course_name
from student s, stuent_course sc, course c
where s.id = sc.studentid and sc.courseid = c.id;-- 以后每次只需要进行查询视图即可
select * from tb_stu_course_view;
三:存储过程
存储过程是事先经过编译并存储在数据库中的一段 SQL语句的集合,调用存储过程可以简化应用开发人员的很多工作,存储过程完全在数据库服务器内存中运行,与应用层代码解耦,这对于提高数据处理的效率是有好处的。
| 特点 | 描述 | 核心价值 |
|---|---|---|
| 模块化封装与逻辑复用 | 将复杂业务逻辑封装为独立模块,支持多次调用,避免代码冗余。 | 提升开发效率,增强代码可维护性。 |
| 参数化交互与数据返回 | 支持输入参数、输出参数及返回值,实现灵活的业务逻辑控制与结果传递。 | 适应动态业务需求,增强程序灵活性。 |
| 批量执行与性能优化 | 通过单次调用执行多条 SQL 语句,减少应用层与数据库层的网络交互次数。 | 降低网络延迟,提升高并发场景执行效率。 |
-- 存储过程基本语法
-- 创建
-- 创建一个名为 p1 的存储过程,() 表示无输入参数。
-- BEGIN ... END 包裹存储过程的主体逻辑,相当于代码块的大括号 {}。
create procedure p1()
beginselect count(*)from student;
end;-- 调用
call p1();-- 查看数据库 itcast 中所有存储过程和函数的元信息。
select * from information_schema.ROUTINES where ROUTINE_SCHEMA = 'itcast';
show create procedure p1;-- 删除
drop procedure if exists p1;
3.1 变量
3.1.1 系统变量
系统变量是 MySQL 服务器提供的一组预定义变量,这些变量控制着 MySQL 服务器的行为和配置。与用户自定义的变量不同,系统变量由 MySQL 本身定义并维护,且它们的作用范围可以分为两类:全局变量 GLOBAL 和会话变量 SESSION 。这两种变量的主要区别在于它们的作用范围和生命周期。
全局变量影响MySQL服务器的整个实例,适用于所有用户和会话。更改全局变量后,所有新创建的会话都将使用更新后的值,但已存在的会话将继续使用它们各自的会话变量值,直到下次连接时使用新的全局值。而会话变量仅影响当前用户会话。它们在会话开始时初始化,直到会话结束才会消失。一旦会话结束,所有会话变量的设置将被丢弃。
-- 查看系统变量
-- 检索当前会话的所有系统变量
show session variables;
show session variables like 'auto%';-- 检索整个服务器实例的所有系统变量
show glabal variables ;
SELECT @@global.autocommit; -- 查看全局的 autocommit 变量值
SELECT @@session.autocommit; -- 查看当前会话的 autocommit 变量值-- 临时启用当前会话的自动提交
set session autocommit = 1;insert intto course(id, name) values (6, 'ES');-- 设置全局的自动提交为关闭
set global auto commit = 0;
3.1.2 用户自定义变量
用户定义变量:用户可以在 MySQL 会话中根据自己的需求随意定义的变量,在用的时候通过“@变量名”使用就可以。这些变量的作用域仅限于当前数据库连接,并且在连接结束时自动销毁。
用户定义变量不需要预先声明或初始化,当第一次使用时,如果该变量没有已经赋值,则返回的结果为 NULL。用户定义变量可以存储任何类型的数据,包括字符串、数字、日期等。对于相同的变量名,后续的赋值操作会覆盖前一个值。
-- 变量:用户变量
-- 赋值
set @myname = 'itcast';
-- 这种 := 方式保守一点
set @myage := 10;select @mycolor := 'red';
select count(*) into @mycount from tb_user;-- 输出为 NULL,因为没有提取赋值,但是可以直接使用
select @abc;
3.1.3 局部变量
局部变量是 MySQL 中在特定代码块(如存储过程、函数或触发器)内定义的变量,其作用域仅限于定义它的代码块。与用户定义变量不同,局部变量需要显式声明,并且只能在声明它的 BEGIN … END 块中使用。
BEGINDECLARE a INT;BEGINDECLARE b INT; -- 只能在内部块中访问DECLARE c INT; -- 只能在内部块中访问-- 从 student 表查询总记录数(COUNT(*)),并将结果存入局部变量 c。SELECT COUNT(*) INTO c FROM student;SET a = 10; -- 可以访问外部块的变量 aEND;SET b := 20; -- 错误!无法访问内部块的变量 b
END;
3.2 if 判断
create procedure p3()
begindeclare score int default 58;declare result varchar(10);-- 如果 score ≥ 85,将 result 赋值为 '优秀'if score >= 85 thenset result :='优秀';elseif score >= 60 thenset result :='及格';elseset result :='不及格';end if;select result;
end;
3.3 参数 (in, out, inout)
| 类型 | 含义 | 备注 |
|---|---|---|
| IN | 该类参数作为输入,也就是需要调用时传入值 | 默认 |
| OUT | 该类参数作为输出,也就是该参数可以作为返回值 | |
| INOUT | 既可以作为输入参数,也可以作为输出参数 |
-- 根据传入(in)参数score,判定当前分数对应的分数等级,并返回(out)
-- score >= 85分,等级为优秀。
-- score >= 60分 且 score < 85分,等级为及格
-- score < 60分,等级为不及格。
create procedure p3(in score int, out result varchar(10))
beginif score >= 85 thenset result :='优秀';elseif score >= 60 thenset result :='及格';elseset result :='不及格';end if;select result;
end;-- 将传入的200分制的分数,进行换算,换算成百分制,然后返回分数 --> inout
create procedure p5(inout score double)
beginset score := score * 0.5;
end;set @score = 198;
call p5(score);
select @score;
3.4 case
-- case
-- 根据传入的月份,判定月份所属的季节(要求采用case结构)
-- 1-3月份,为第一季度
-- 4-6月份,为第二季度
-- 7-9月份,为第三季度
-- 10-12月份,为第四季度create procedure p6(in month int)
begin declare result varchar(10);case when month >= 1 and month <= 3 thenset result := '第一季度';when month >= 4 and month <= 6 thenset result := '第二季度';when month >= 7 and month <= 9 thenset result := ' 第三季度';when month >= 10 and month <= 12 thenset result := '第四季度';elseset result := '非法参数';end case;select concat('你输入的月份为:', month, ',所属季度为:', result);
end;
3.5 循环
3.5.1 while
-- while计算从1累加到 n 的值,n 为传入的参数值。
-- A.定义局部变量,记录累加之后的值;
-- B.每循环一次,就会对 n 进行减1,如果 n 减到0,则退出循环-- 定义一个输入参数 n 类型为整数 INT
create procedure p7(in n int)
begindeclare total int default 0;while n>0 doset total := total + nset n:=n-1;end while;select total;
end;
call p7( n: 100);
3.5.2 repeat
repeat 就相当于 do while,先进行循环一次再判断,满足条件则退出
-- while计算从1累加到 n 的值,n 为传入的参数值。
-- A.定义局部变量,记录累加之后的值;
-- B.每循环一次,就会对 n 进行减1,如果 n 减到0,则退出循环create procedure p8(innint)
begindeclare total int default 0;repeatset total := total + n;set n := n - 1;until n <= 0end repeat;select total;
end;call p8( n: 10);
call p8( n: 100);
3.6 游标 - cursor
游标是数据库编程中用于逐行处理查询结果集的一种机制,类似于程序中的“指针”或“迭代器”。它允许开发者在存储过程或函数中,对 SQL 查询返回的多行数据进行逐行操作,实现复杂业务逻辑。
-- 创建名为 p11 的存储过程,接收一个输入参数 uage(整数类型)
create procedure p11(in uage int)
begin -- 声明变量:用于临时存储游标获取的数据declare uname varchar(100); -- 存储用户姓名declare upro varchar(100); -- 存储用户专业-- 声明游标 u_cursor:关联查询语句,获取年龄<=uage的用户姓名和专业declare u_cursor cursor for select name, profession from tb_user where age <= uage; -- 查询条件:年龄小于等于输入参数-- 删除已存在的表 tb_user_pro(避免重复数据)drop table if exists tb_user_pro;-- 创建新表 tb_user_pro,用于存储处理结果create table if not exists tb_user_pro(id int primary key auto_increment, -- 自增主键name varchar(100), -- 用户姓名字段profession varchar(100) -- 专业字段);-- 打开游标:执行关联的查询语句,加载结果集到内存open u_cursor;-- 开启无限循环(⚠️ 存在问题:未设置退出条件,会导致死循环,这里我为了方便就这样写了)while true do-- 从游标中获取下一行数据,存入变量 uname 和 uprofetch u_cursor into uname, upro;-- 将获取的数据插入新表 tb_user_pro-- NULL 表示 id 自增,无需手动赋值insert into tb_user_pro values(null, uname, upro);end while;-- 关闭游标(⚠️ 实际因死循环永远不会执行到这里)close u_cursor;
end;
3.7 存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。存储函数用的较少,能够使用存储函数的地方都可以用存储过程替换。
create function fun1(n int) -- 创建一个名为 fun1 的函数,接受一个整数参数 n
returns int deterministic -- 指定函数返回一个整数,并声明其为确定性函数
begin -- 函数体开始declare total int default 0; -- 声明一个整数变量 total,并将其初始化为 0while n > 0 do -- 当 n 大于 0 时进入循环set total := total + n; -- 将 n 加到 total 中set n := n - 1; -- 将 n 的值减 1end while; -- 循环结束return total; -- 返回计算得出的总和 total
end; -- 函数体结束
四:触发器
触发器是数据库中的一种自动化回调机制,当指定的事件(如增删改)发生在数据库表上时,触发器会自动执行预定义的 SQL 逻辑。它类似于编程中的“事件监听器”,用于在数据变更时强制执行业务规则、数据校验或日志记录。现在触发器还只支持行级触发,不支持语句级触发。
| 触发器类型 | NEW 和 OLD |
|---|---|
| insert 型触发器 | NEW 表示将要或已经新增的数据 |
| update 型触发器 | OLD 表示修改之前的数据,NEW 表示将要或已经修改后的数据 |
| delete 型触发器 | OLD 表示将要或已经删除的数据 |
-- 插入数据触发器
create trigger tb_user_insert_trigger -- 创建一个名为 tb_user_insert_trigger 的触发器after insert on tb_user for each row -- 触发器类型为插入后触发,针对 tb_user 表的每一行begin insert into user_logs(id, operation, operate_time, operate_id, operate_params) values -- 向 user_logs 表插入一条日志记录(null, 'insert', now(), new.id, concat('插入的数据内容为:id=', new.id, ',name=', new.name, ', phone=', new.phone, ', email=', new.email, ', profession=', new.profession)); -- 插入的值包括操作类型、当前时间、插入的用户 ID 和相关数据内容
end; -- 结束触发器定义-- 查看触发器
show triggers; -- 显示当前数据库中所有的触发器-- 删除触发器
drop trigger tb_user_insert_trigger; -- 删除已创建的 tb_user_insert_trigger 触发器-- 插入数据到 tb_user
insert into tb_user(id, name, phone, email, profession, age, gender, status, createtime) values -- 向 tb_user 表插入一条新数据
(25, '二皇子', '1880901212', 'erhuangzi@163.com', '软件工程', 23, '1', '1', now()); -- 插入的具体数据,包括当前时间-- 修改数据触发器
create trigger tb_user_update_trigger -- 创建一个名为 tb_user_update_trigger 的触发器after update on tb_user for each row -- 触发器类型为更新后触发,针对 tb_user 表的每一行begin insert into user_logs(id, operation, operate_time, operate_id, operate_params) values -- 向 user_logs 表插入一条日志记录(null, 'update', now(), new.id, -- 插入的值包括操作类型、当前时间、被更新用户的 IDconcat('更新之前的数据:id=', old.id, ',name=', old.name, ', phone=', old.phone, ', email=', old.email, ', profession=', old.profession, -- 使用 OLD 关键字记录更新之前的数据'更新之后的数据:id=', new.id, ',name=', new.name, ', phone=', new.phone, ', email=', new.email, ', profession=', new.profession)); -- 使用 NEW 关键字记录更新后的数据
end; -- 结束触发器定义update tb_user set age = 32 where id = 23; -- 更新 tb_user 表中 id 为 23 的用户的年龄为 32,触发更新触发器
update tb_user set age = 32 where id <= 5; -- 更新 tb_user 表中 id 小于等于 5 的用户的年龄为 32,触发器为行级触发器,因此此语句会触发 5 次create trigger tb_user_delete_trigger -- 创建一个名为 tb_user_delete_trigger 的触发器after delete on tb_user for each row -- 触发器类型为删除后触发,针对 tb_user 表的每一行begin insert into user_logs(id, operation, operate_time, operate_id, operate_params) values -- 向 user_logs 表插入一条日志记录(null, 'delete', now(), old.id, -- 插入的值包括操作类型、当前时间、被删除用户的 IDconcat('删除之前的数据:id=', old.id, ',name=', old.name, ', phone=', old.phone, ', email=', old.email, ', profession=', old.profession)); -- 使用 OLD 关键字记录删除之前的数据
end; -- 结束触发器定义delete from tb_user where id = 26; -- 删除 tb_user 表中 id 为 26 的用户,触发删除触发器
五:锁
在数据库中,锁是协调多个用户或线程并发访问共享资源的核心机制。MySQL 的锁机制旨在解决数据并发访问时的一致性和有效性问题,同时避免因资源争用导致的冲突,确保数据的完整性和事务的隔离性。MySQL 按照锁的粒度划分,MySQL 中的锁分为一下三类:
- 全局锁:锁定数据库中的所有表。
- 表级锁:每次操作锁住整张表。
- 行级锁:每次操作锁住对应的行数据。
5.1 全局锁
全局锁是 MySQL 中一种锁定整个数据库的机制。当对数据库实例加全局锁后,所有表将进入 只读模式,此时任何写操作和事务都会被阻塞。
-- 使用全局锁:
flush tables with read lock
-- 释放全局锁:
unlock tables
我们要清楚一点,全局锁的重量级是非常大的,它的典型的使用场景是做全库的逻辑备份,对所有的表进行锁定,从而获取一致性视图,保证数据的完整性。
5.2 表级锁
顾名思义,表级锁就是每次操作锁住整张表,对于表级锁一般分为一下三种:
- 表锁
- 元数据锁
- 意向锁
5.2.1 表锁
表级锁是 MySQL 中一种锁定整张表的机制。当对某张表加锁后,其他会话对该表的访问将受到限制,具体限制范围取决于锁的类型,看看这个锁是读锁还是写锁。
| 锁类型 | 别名 | 功能描述 |
|---|---|---|
| 读锁(共享锁) | READ LOCK | 读锁不会阻塞其他客户端的读,但是会阻塞写。 |
| 写锁(排他锁) | WRITE LOCK | 写锁既会阻塞其他客户端的读,又会阻塞其他客户端的写。 |
//表级别的共享锁,也就是读锁;
//允许当前会话读取被锁定的表,但阻止其他会话对这些表进行写操作。
lock tebles t_student read;//表级锁的独占锁,也是写锁;
//允许当前会话对表进行读写操作,但阻止其他会话对这些表进行任何操作(读或写)。
lock tables t_stuent write;// 释放所有锁,会话退出,也会释放所有锁
unlock tables
5.2.2 元数据锁
元数据锁简称为 MDL ,元数据锁由 MySQL 自动加锁和释放,无需手动干预,它用于操作表中的元数据,如表名、列定义、索引、存储引擎等,确保在并发操作中,表结构的变更不会与数据操作冲突,避免因表结构变动导致的数据不一致的问题。
| 锁类型 | 相关操作 | 功能描述 |
|---|---|---|
| MDL 读锁 | 对一张表进行 CRUD 操作时,加的是 MDL 读锁; | 允许事务读取元数据,阻止其他事务修改表结构,但允许多个读锁共享。 |
| MDL 写锁 | 对一张表做结构变更操作的时候,加的是 MDL 写锁; | 排他锁,禁止其他事务读取或写入数据,确保表结构改变期间无并发操作干扰。 |
5.2.3 意向锁
意向锁 是 InnoDB 引擎引入的一种 表级锁,用于快速判断表中是否存在行级锁,从而避免加表锁时逐行检查锁状态的性能问题,意向锁有以下两种类型:
- 意向共享锁:表示事务打算对表中的某些行加共享锁(S锁)。
- 意向排他锁:表示事务打算对表中的某些行加排他锁(X锁)。
为什么要有意向锁呢?当需要加表级锁时,必须确保表中没有行级锁冲突,若没有意向锁,加表锁前需要扫描全表,检查每行是否有行锁,这在大表中效率极低。通过意向锁,我们加表锁时,只需检查表级意向锁的存在,无需逐行扫描。
5.3 行级锁
行级锁是 InnoDB 存储引擎中实现的一种锁机制,其锁定粒度最小,针对表中的单行或相邻行数据进行锁定,并发性能最高,适用于高并发事务场景。它通过精细控制数据行的访问,平衡了数据一致性与并发效率。
| 锁类型 | 作用范围 | 解决的核心问题 | 支持的隔离级别 |
|---|---|---|---|
| 行锁 | 锁定单行记录 | 防止数据被并发修改 | 读取已提交、可重复读 |
| 间隙锁 | 锁定索引记录的间隙(不包含记录本身) | 防止幻读 | 可重复读 |
| 临键锁 | 锁定行记录 + 前序间隙 | 同时防止修改和幻读 | 可重复读 |
5.3.1 行锁
行锁是 InnoDB 存储引擎中针对单行数据的锁机制,通过锁定表中的某一行记录,控制并发事务对数据的访问。行锁分为两种:
- 共享锁(S 锁):允许读,禁止写。
- 排他锁(X 锁):禁止读写,完全独占。
| SQL | 行锁类型 | 说明 |
|---|---|---|
| insert, update, delete … | 排他锁 | 自动加锁 |
| select | 无锁 | 默认不加锁,读取快照数据(MVCC 机制)。 |
| select … lock in share mode | 共享锁 | 手动加锁,需要手动在 select 之后加上 lock in share mode |
| select … for update | 排他锁 | 手动加锁,需要手动在 select 之后加上 for update |
行锁基于索引生效:如果查询条件使用了索引,InnoDB 只会锁定符合条件的行。
-- 示例:使用索引字段(如 id)加锁
SELECT * FROM users WHERE id = 1 FOR UPDATE; -- 仅锁定 id=1 的行
无索引导致锁升级:如果查询条件未使用索引,InnoDB 会退化为表级锁去锁定所有行。
-- 示例:未使用索引字段(如 name 无索引)
SELECT * FROM users WHERE name = 'Alice' FOR UPDATE; -- 锁定全表!
5.3.2 间隙锁
间隙锁是 InnoDB 在可重复读 隔离级别下引入的一种锁机制,用于锁定两个索引值之间的间隙(不包含记录本身),这样做的目的是防止其他事务在间隙内插入新数据,举个例子:
| id | name |
|---|---|
| 3 | 路飞 |
| 5 | 骑隆 |
| 6 | 乌索普 |
此时索引值的间隙为:
- (-∞, 3)
- (3, 5)
- (5, 6)
- (6, +∞)
事务 A 已经对间隙 (3, 5) 加锁,其他事务无法在此区间插入新数据(如 id=4),从而确保事务 A 多次读取同一范围时,结果一致,这样就不会出现幻读了。间隙锁之间是兼容的,多个事务可以同时对同一间隙加间隙锁,无论是共享间隙锁还是排他间隙锁,并且间隙锁与行锁不冲突,两者可共存。
5.3.3 临键锁
临键锁是 InnoDB 在可重复读隔离级别下使用的核心锁机制,通过行锁 + 间隙锁的组合,同时锁定一个范围和记录本身,彻底解决幻读问题,举个例子:
| id | name |
|---|---|
| 1 | 路飞 |
| 3 | 赛隆 |
| 5 | 乌索普 |
| 6 | 山治 |
临键锁 (3, 5]:
- 间隙锁:锁定 (3, 5) 的间隙,此时禁止插入 id=4。
- 行锁:锁定 id=5 的记录,此时禁止修改或删除 id=5 的行。
| 查询类型 | 场景 | 锁机制 |
|---|---|---|
| 唯一索引的等值查询(值不存在) | 查询 id=4(表中不存在该记录)。 | 锁优化:退化为间隙锁,锁定 (3, 5) 的间隙,阻止插入 id=4。 |
| 普通索引的等值查询 | 对普通索引列 age=20 查询,索引值为 [18, 20, 22]。 | 1. 锁定 age=20 的行锁及前序间隙 (18, 20)。 2. 向后遍历发现 age=22 不满足条件,退化为间隙锁 (20, 22)。 |
| 范围查询(唯一索引) | 查询 id < 5。 | 1. 找到第一个不满足条件的记录 id=5。 2. 锁定范围 (3 到 id=5 的范围)。 |
多个事务可同时持有同一间隙的间隙锁,X 型临键锁:与其他事务的 X/S 型行锁冲突。S 型临键锁:仅与 X 型行锁冲突。
六:InnoDB 引擎
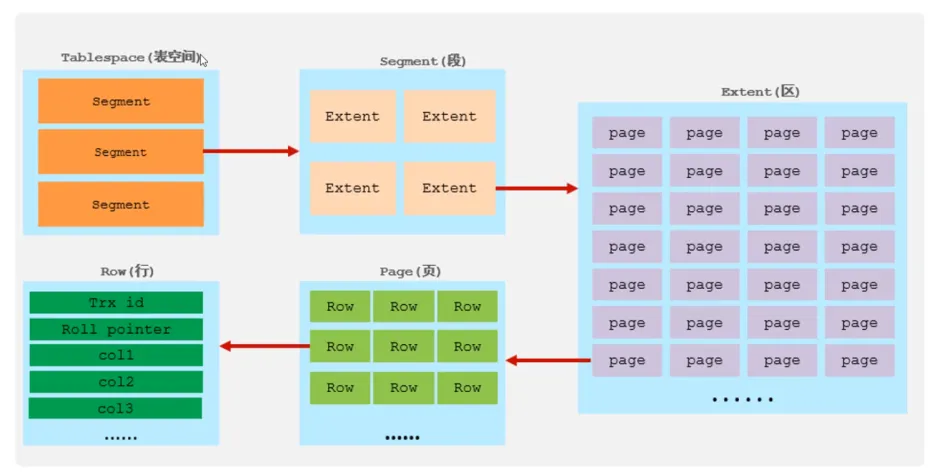
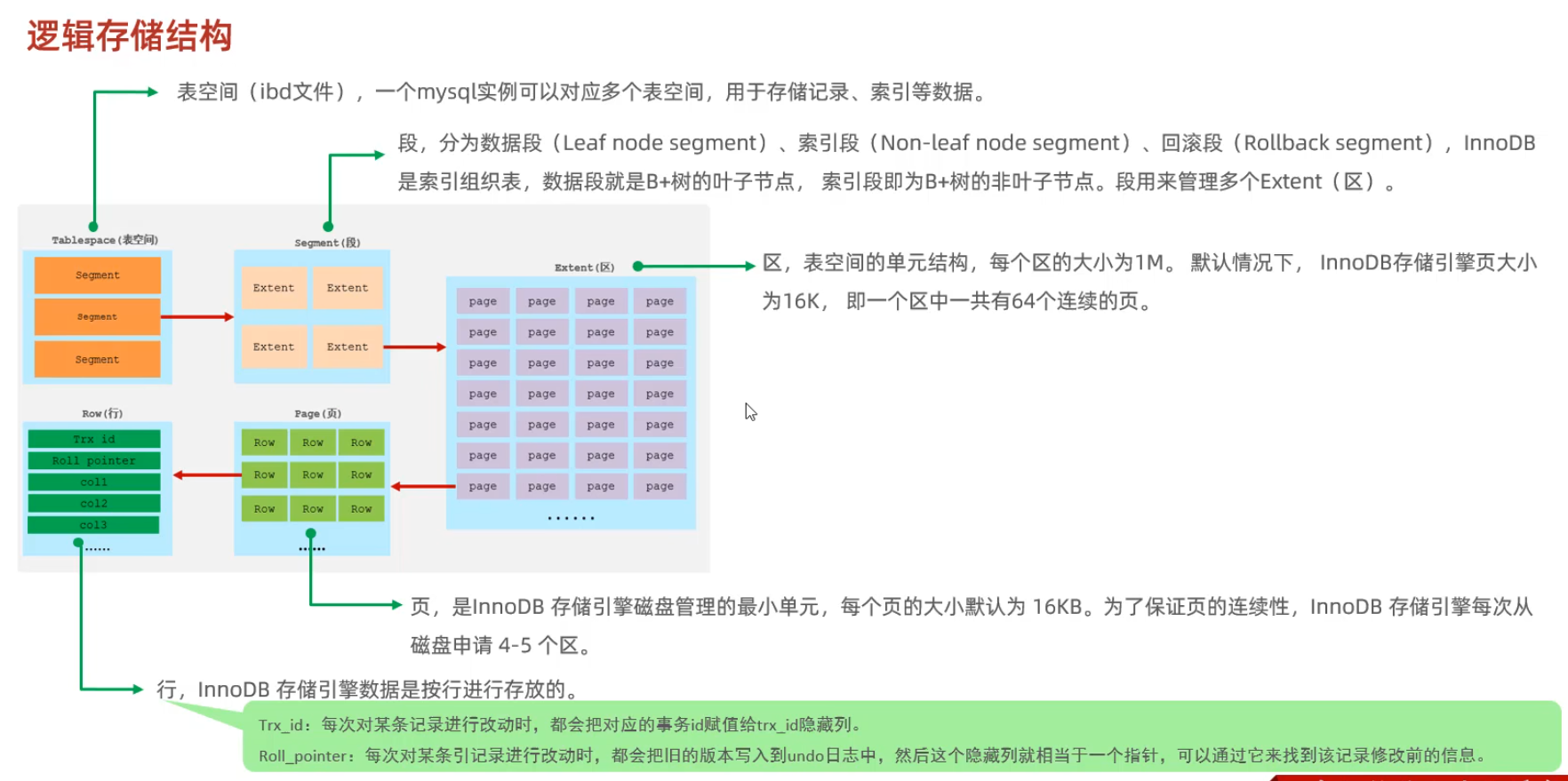
6.1 逻辑存储结构
InnoDB 的逻辑存储结构从宏观到微观分为 表空间 → 段 → 区 → 页 → 行,每一层设计都服务于高效的数据管理、事务支持和并发控制。
一个表空间有多个段空间,而一个段空间又有多个区空间,一个区空间的大小为 1 M,一个区空间有 64 个连续的页,一个页空间的大小为 16 kb,最后一个页中有多个行数据。





:touch)