1.概述
在大批量数据处理与实时计算领域,Apache Kafka已成为消息队列的事实标准。本文将完整记录从零开始搭建高可用Kafka集群,并配置EFAK监控平台的详细过程,涵盖规划、部署、优化到监控的全生命周期管理。通过本文,你将了解并掌握一套生产级别可用的Kafka集群部署和监控方案。
从 Kafka 2.8.0 开始,可以不再依赖zookeeper,尽管 Kafka 在新版本中减少了或移除了对 ZooKeeper 的依赖,但在完全移除之前,许多现有的部署仍然依赖于 ZooKeeper,所以kafka不依赖于zookeeper的版本不够成熟,或者说生产环境实战经验不够全面,有待踩坑~今天我们搭建的kafka集群还是依赖于zookeeper,但是本文不再详解讲述kafka和zookeeper相关概念和原理,不清楚的可查看我们之前总结的:
zookeeper:详解Zookeeper(铲屎官)在中间件的应用和在Spring Boot业务系统中实现分布式锁和注册中心的解决方案
kafka:kafka入门实战教程看这篇就够了
2.kafka集群
这里我们以半数原则选择3台机器搭建kafka集群,这也是很多常规业务系统生产环境的集群配置,我们知道kafka依赖于zookeeper,所以在部署kafka集群之前,得先部署好zookeeper服务,zookeeper是半数原则的典型中间件,所以zookeeper的集群强烈建议是单数台服务器搭建,因为3台机器和4台机器的高可用性是一样的,但是今天的主角是kafka集群,所以我们这里就使用单点的zookeeper服务了,我们准备的三台服务器如下:
10.10.0.10
10.10.0.14
10.10.0.22
kafka集群基础架构图:这里展示的是生产者向3台broker组成的kafka集群中某个3分区3副本的topic发送消息,该topic被多个消费者组同时订阅消费,一个消费者组由多个消费者组成

- Producer:消息生产者,就是向 Kafka broker 发消息的客户端
- Consumer:消息消费者,向 Kafka broker 取消息的客户端。
- Topic:**可以理解为一个队列,**生产者和消费者面向的都是一个 topic
- Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。kafka 只保证按一个 partition 中的顺序将消息发给consumer,不保证一个 topic 的整体(多个 partition 间)的顺序;
- Consumer Group(CG):消费者组,由多个 consumer 组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Replica:副本。一个 topic 的每个分区都有若干个副本,一个 Leader 和若干个Follower。
- Follower:每个分区多个副本中的“从”,实时从 Leader 中同步数据,保持和Leader 数据的同步。平时只有数据冗余备份的作用,但当Leader 发生故障时,某个 Follower 会成为新的 Leader。
在10.10.0.10上部署了zookeeper服务,不知道咋部署的,可以根据上面zookeeper使用教程总结链接自行跳转了解下。
话不多说,回到今天的主题kafka,其实在上面提到的kafka入门实战总结中,我们已经介绍过了kafka是如何安装部署的。这里基于集群模式再详解介绍一遍,其实集群模式和单点部署没多大区别,无外乎就是改改配置文件而已。
2.1 环境和安装包准备
Kafka 运行需要 Java 环境,确保安装了 JDK,当然了zookeeper服务的部署也是需要先安装JDK,你可以理解他们都是java服务,部署启动完成之后使用Java的命令jps就能查看到相关进程。
回归流程,环境准备好之后先去kafka官网下载安装包,官网地址:https://kafka.apache.org/downloads.html
下载安装包之后分别放到上面三台服务器上并解压:
tar -xzf kafka_2.13-2.8.0.tgz
cd kafka_2.13-2.8.0
查看解压后的kafka安装包:
bin config libs LICENSE NOTICE site-docs
重点关注下bin和config
查看bin:是一些shell脚本,这些脚本有启动或者停止kafka服务的,也有关于kafka生产者、消费者、主题操作的

查看config: 是一些关于服务的配置文件,有关于kafka服务的配置server.properties,也有关于生产者,消费者的配置

不知道你没有注意到在shell脚本和配置文件中都有zookeeper的身影,其实是kafka安装包内置了一个zookeeper服务,我们用如下命令启动zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties
但是我们上面是基于zookeeper的入门教程先单独安装了zookeeper服务,并没有使用内置启动这种方式,我的建议是单独安装,因为zookeeper并不只是为了服务于kafka,它还可以应用于很多场景,这里就不展开细说的,感兴趣的可以看上面的链接教程。
2.2 集群配置修改
启动kafka服务之前,需要先修改下每台服务器的kafka安装包的config路径下的配置文件server.properties:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/kafka/kafka/logs
#topic 在当前 broker 上的分区个数
num.partitions=1
#用来恢复和清理 data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个 topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大 1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 地址
zookeeper.connect=10.10.0.10:2181这里关于集群的配置重点关注3个就行了:
broker.id=0
这个是集群服务的唯一标识不能重复,这里是10.10.0.10broker的id是0,那10.10.0.14, 10.10.22的broker id分别是1,2
其次就是:
zookeeper.connect=10.10.0.10:2181
配置zookeeper地址,这是很重要的,kafka依赖于zookeeper,所以必须得配置正确
最后一个配置:
log.dirs=/kafka/kafka/logs
指定kafka数据存储的地方,方便我们快速找到并查看
2.3 启动并查看
万事俱备只欠东风,经过上面的准备工作之后,我就可以执行下面命令启动kafka服务了:
bin/kafka-server-start.sh -daemon config/server.properties
安装前面说的,启动之后我们可以使用jps命令查看是否启动成功:
10881 Jps
1607 Kafka
124219 QuorumPeerMain
当然也可以使用Linux命令ps -ef | grep kafka查看进程
如果有报错,就需要根据前面配置数据存储路径查看服务启动日志排查了
关闭服务也很简单,执行下面命令即可:
bin/kafka-server-stop.sh
这样一个3台服务的kafka集群就搭建起来了。
3.监控平台efak搭建
有了集群没有监控,就容易成为瞎子,可能集群服务出问题无法快速感知到,有了监控才能对集群的健康、压力、性能情况了然于胸,所以我们下面就来搭建下kafka监控平台efak。
首先也是一样的先去官网地址下载安装包上传到服务器之后并解压,eagle的官网地址:https://www.kafka-eagle.org/
tar -zxvf kafka-eagle-bin-2.0.8.tar.gz
修改解压后安装包文件夹conf下的system.properties,配置过多,我这里只展示需要修改的配置项,其他的默认即可:
# zookeeper连接信息
efak.zk.cluster.alias=cluster1
cluster1.zk.list=10.10.0.10:2181######################################
# kafka offset storage 存储
######################################
cluster1.efak.offset.storage=kafka# kafka mysql jdbc driver address 监控信息存储
######################################
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://10.10.0.10:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=root其他的配置无需修改。
接下来配置环境变量vi /etc/profile,添加如下配置
# kafkaEFAK
export KE_HOME=/opt/module/efak
export PATH=$PATH:$KE_HOME/bin
执行source /etc/profile使环境变量生效。
这时候还没不能启动监控平台,最后一步需要修改下3台kafka服务的启动脚本vi bin/kafka-server-start.sh:
修改如下参数值:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; thenexport KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -
XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -
XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -
XX:InitiatingHeapOccupancyPercent=70"export JMX_PORT="9999"#export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
这里kafka的调整了jvm参数和暴露远程监控端口JMX_PORT="9999",重点就是暴露远程监控端口,至于jvm参数看具体服务配置,改不改不影响这个监控平台的启动的。
修改完启动脚本之后,按照上面部署kafka的教程,先执行下关闭kafka服务命令,再逐个启动即可。
在kafka服务全部正常重启之后,就可以启动监控平台了,也很简单,执行下面命令即可:
bin/ke.sh start
控制台输出日志如下,表示启动成功:
访问地址:http://10.10.0.14:8048:
输入账号密码登陆成功之后,可以整体监控信息:
可以看到集群有3个broker,查看详情:
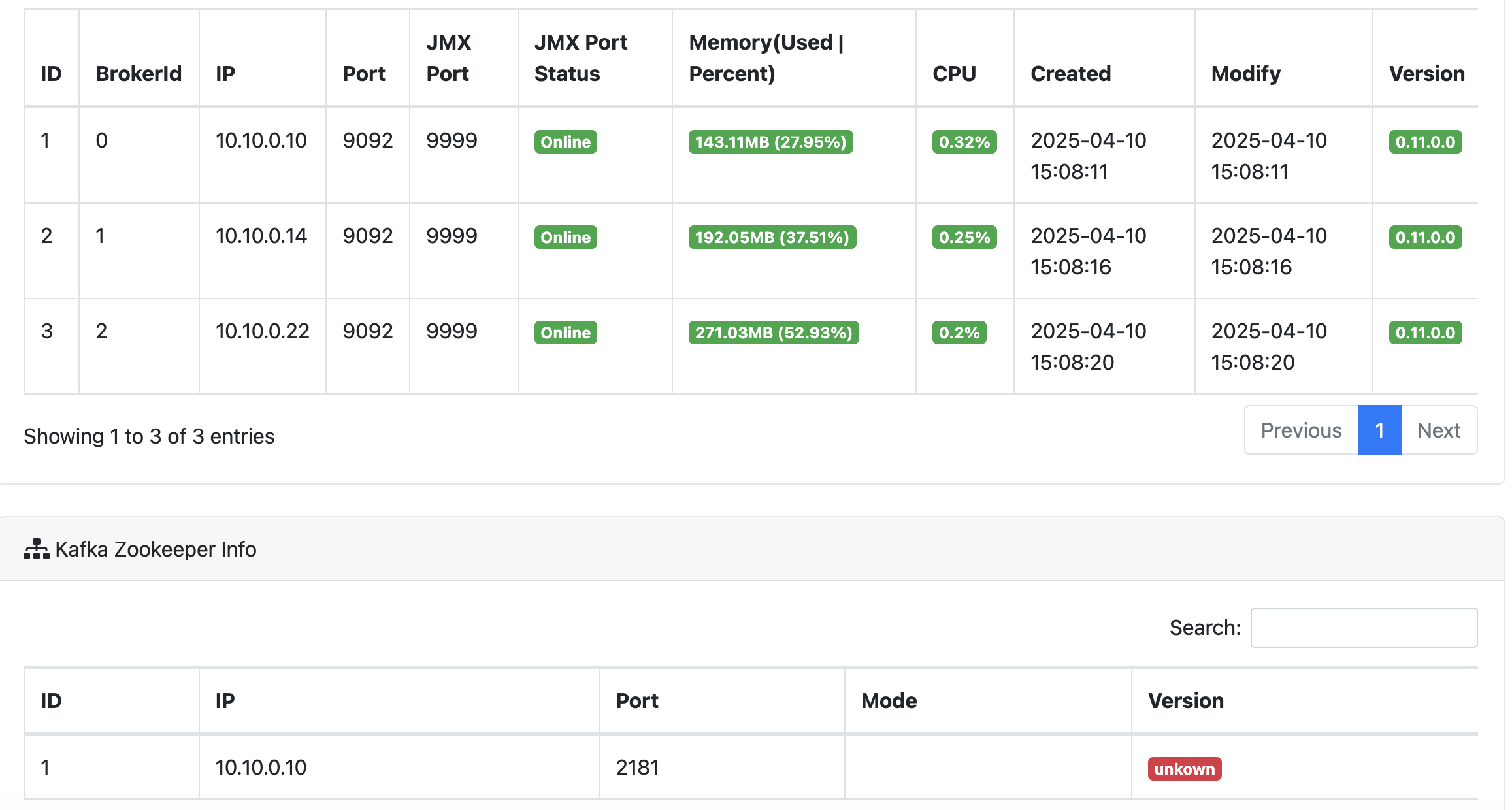
可以看到在监控平台上,集群信息、主题topic信息、消费者信息都一目了然。
4.Spring Boot整合kafka生产消费消息查看监控
这里就不详细展开Spring Boot如何整合kafka,直接根据上面的教程:kafka入门实战教程看这篇就够了
**生产消息:**核心逻辑如下,完整代码调转入门教程
for (int i = 0; i < 10; i++) {// 通过传入key计算分区producer.send(new ProducerRecord<String, String>("test_topic",Integer.toString(i), "val"+Integer.toString(i)));
}
执行之后查看监控:可以看到主题相关信息
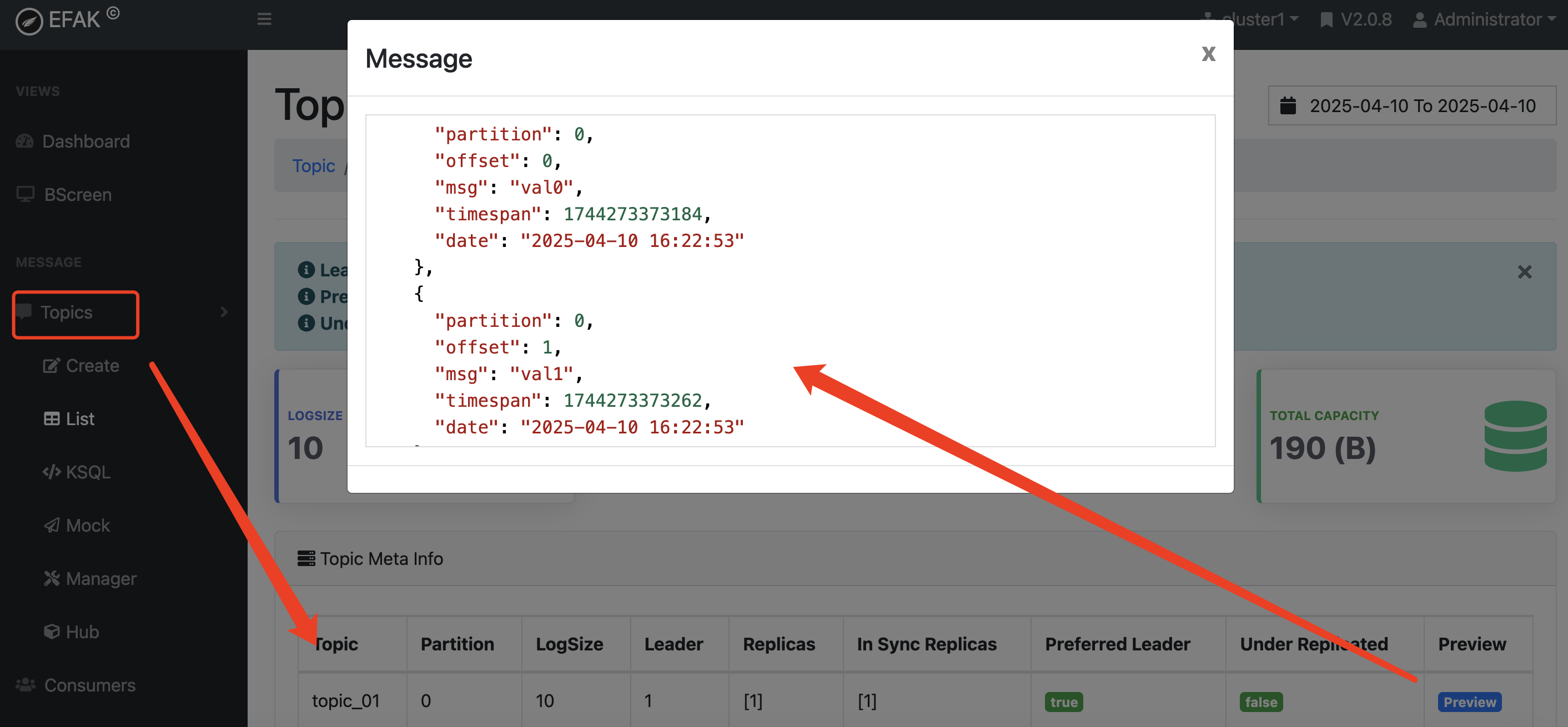
**消费消息:**核心逻辑如下,完整代码跳转入门教程:
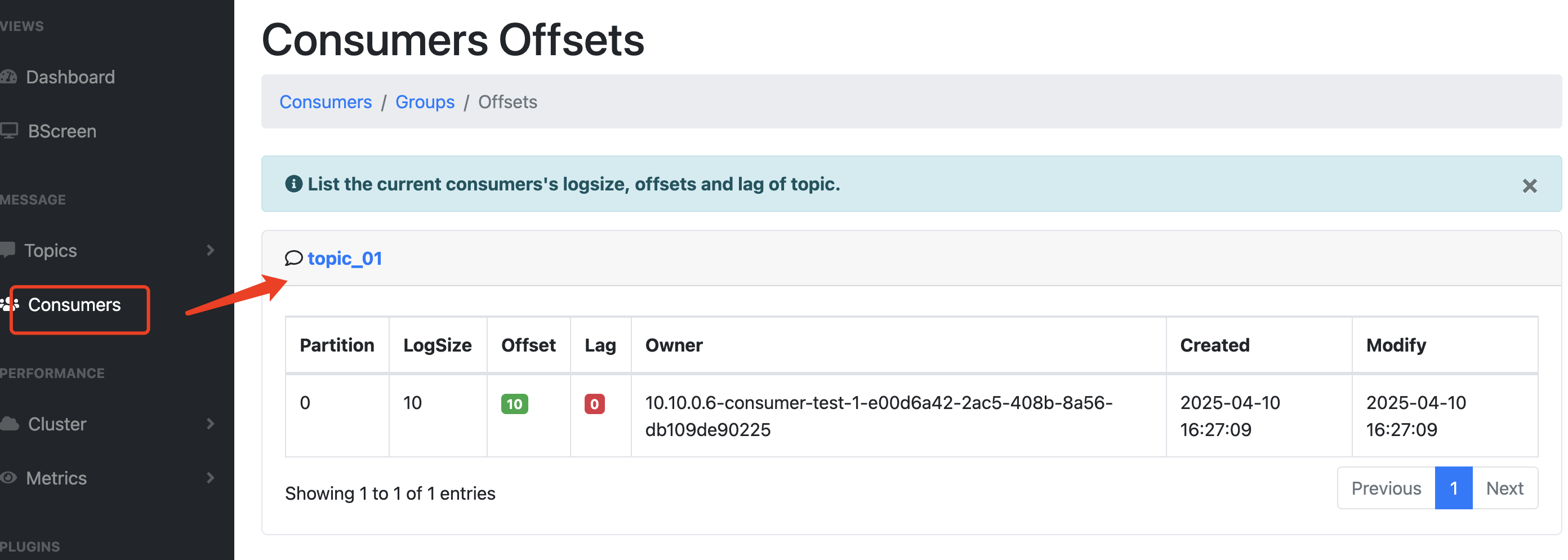
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);// 添加消费者订阅的主题topic,可以添加多个ArrayList<String> topics = new ArrayList<>();topics.add("topic_01");kafkaConsumer.subscribe(topics);// 拉取数据while (true) {// 每隔1s消费一批数据ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {// 打印数据System.out.println(consumerRecord);}}
监控平台信息展示:可以看到消费者的相关信息
5.总结
通过本文实践,我们完成了:高可用Kafka集群的标准化部署和Eagle监控平台的深度集成。






