SpringBoot Druid Mysql多数据源整合
- 一、背景
- 二、配置结果
- 2.1 SpringBoot java 类配置
- 2.1.1 启动类配置
- 2.1.2 java Config配置
- 2.2 SpringBoot yml 配置
- 三、mybatis插件配置
- 3.1 PageHelper的yml配置
- 3.2 mybatis设置自定义字段默认值
- 四、配置解释
一、背景
-
公司项目需要连接另外一个数据库来处理数据
-
处理方法其实很多,如下所示:
- 给这个数据库单独跑一个服务,用来查询数据
- 直接将该数据库表同步到本地服务数据库
- 在本地服务中直接配置多数据源用来查询数据
-
其实每种方法都有自己的利弊,由于各种原因还是选择了方法3,配置多数据源进行查询
-
SpringBoot版本 2.3.12.RELEASE
-
Druid版本
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.22</version>
</dependency>
- 其他mysql,mybatis都是正常配置
二、配置结果
2.1 SpringBoot java 类配置
2.1.1 启动类配置
@SpringBootApplication(exclude = {DruidDataSourceAutoConfigure.class})
@ServletComponentScan
@EnableCaching
public class TestApplication {public static void main(String[] args) {SpringApplication.run(TestApplication.class, args);}}
- 其中使用@SpringBootApplication(exclude = {DruidDataSourceAutoConfigure.class})的原因见1
2.1.2 java Config配置
- 需要建立3个java类,DruidAutoConfiguration.java,DruidConfigTestOne.java,DruidConfigTestTwo.java
- DruidAutoConfiguration作用见2
- DruidConfigTestOne作用见3
- DruidConfigTestTwo作用见4
@Configuration
@ConditionalOnClass(DruidDataSource.class)
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
@EnableConfigurationProperties(DruidStatProperties.class)
@Import({DruidSpringAopConfiguration.class,DruidStatViewServletConfiguration.class,DruidWebStatFilterConfiguration.class,DruidFilterConfiguration.class})
public class DruidAutoConfiguration {
}
@Configuration
@MapperScan(basePackages = DruidConfigTestOne.PACKAGE, sqlSessionTemplateRef = "testOneSqlSessionTemplate")
public class DruidConfigTestOne {/*** mapper 所在包* 这个地方需要注意xml文件要在resources目录com/test/one/mapper下,mapper java类在com.test.one.mapper包下,这样就不需要配置xml文件所在位置,否则需要在sqlSessionFactory上面新增mapperLocation的配置* bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:/com/test/one/mapper/*.xml"));*/protected static final String PACKAGE = "com.test.one.mapper";/*** 配置自定义数据源,一定要切记,在SpringBoot启动类上去掉DruidDataSourceAutoConfigure.class** @return javax.sql.DataSource* @author liulin* @date 2025/4/11 16:49*/@Bean("testOneDataSource")@ConfigurationProperties(prefix = "spring.datasource.druid.test-one")@Primarypublic DataSource testOneDataSource(){return DruidDataSourceBuilder.create().build();}/*** 创建并配置一个SqlSessionFactory实例* 该方法使用Spring框架的@Bean注解,表明该方法会返回一个SqlSessionFactory对象,该对象将被Spring容器管理** @param dataSource 数据源,通过该参数指定SqlSessionFactory将要使用的数据库连接* @return SqlSessionFactory 一个配置好的SqlSessionFactory实例,用于创建SqlSession* @throws Exception 如果创建过程中出现错误,将抛出异常*/@Bean(name = "testOneSqlSessionFactory")@Primarypublic SqlSessionFactory sqlSessionFactory(@Qualifier("testOneDataSource") DataSource dataSource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(dataSource);return bean.getObject();}/*** 创建一个数据源事务管理器* <p/>* 该方法定义了一个Spring的@Bean注解,用于创建一个DataSourceTransactionManager实例* 这个实例用于管理与数据源相关的事务这个方法被标记为@Primary,意味着在相同类型* 的多个Bean存在时,Spring会默认选择这个Bean** @param dataSource 数据源实例,用于事务管理器的构造* @return DataSourceTransactionManager实例,用于管理数据库事务*/@Bean(name = "testOneTransactionManager")@Primarypublic DataSourceTransactionManager transactionManager(@Qualifier("testOneDataSource") DataSource dataSource) {return new DataSourceTransactionManager(dataSource);}/*** 创建并配置一个SqlSessionTemplate实例* 该实例用于执行SQL操作,利用Spring框架的依赖注入功能进行管理** @param sqlSessionFactory 用于创建SqlSessionTemplate的工厂,通过资格器@Qualifier指定特定的工厂* @return 返回配置好的SqlSessionTemplate实例,用于执行数据库操作* @throws Exception 如果实例化过程中遇到任何问题,则抛出异常*/@Bean(name = "testOneSqlSessionTemplate")@Primarypublic SqlSessionTemplate sqlSessionTemplate(@Qualifier("testOneSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {return new SqlSessionTemplate(sqlSessionFactory);}
}
@Configuration
@MapperScan(basePackages = DruidConfigTestTwo.PACKAGE, sqlSessionTemplateRef = "testTwoSqlSessionTemplate")
public class DruidConfigTestTwo {/*** mapper 所在包*/protected static final String PACKAGE = "com.test.two.mapper";/*** 配置自定义数据源,一定要切记,在SpringBoot启动类上去掉DruidDataSourceAutoConfigure.class** @return javax.sql.DataSource* @author liulin* @date 2025/4/11 16:49*/@Bean("testTwoDataSource")@ConfigurationProperties(prefix = "spring.datasource.druid.test-two")public DataSource testTwoDataSource(){return DruidDataSourceBuilder.create().build();}/*** 创建并配置一个SqlSessionFactory实例* 该方法使用Spring框架的@Bean注解,表明该方法会返回一个SqlSessionFactory对象,该对象将被Spring容器管理** @param dataSource 数据源,通过该参数指定SqlSessionFactory将要使用的数据库连接* @return SqlSessionFactory 一个配置好的SqlSessionFactory实例,用于创建SqlSession* @throws Exception 如果创建过程中出现错误,将抛出异常*/@Bean(name = "testTwoSqlSessionFactory")public SqlSessionFactory sqlSessionFactory(@Qualifier("testTwoDataSource") DataSource dataSource) throws Exception {SqlSessionFactoryBean bean = new SqlSessionFactoryBean();bean.setDataSource(dataSource);return bean.getObject();}/*** 创建一个数据源事务管理器* <p/>* 该方法定义了一个Spring的@Bean注解,用于创建一个DataSourceTransactionManager实例* 这个实例用于管理与数据源相关的事务这个方法被标记为@Primary,意味着在相同类型* 的多个Bean存在时,Spring会默认选择这个Bean** @param dataSource 数据源实例,用于事务管理器的构造* @return DataSourceTransactionManager实例,用于管理数据库事务*/@Bean(name = "testTwoTransactionManager")public DataSourceTransactionManager transactionManager(@Qualifier("testTwoDataSource") DataSource dataSource) {return new DataSourceTransactionManager(dataSource);}/*** 创建并配置一个SqlSessionTemplate实例* 该实例用于执行SQL操作,利用Spring框架的依赖注入功能进行管理** @param sqlSessionFactory 用于创建SqlSessionTemplate的工厂,通过资格器@Qualifier指定特定的工厂* @return 返回配置好的SqlSessionTemplate实例,用于执行数据库操作* @throws Exception 如果实例化过程中遇到任何问题,则抛出异常*/@Bean(name = "testTwoSqlSessionTemplate")public SqlSessionTemplate sqlSessionTemplate(@Qualifier("testTwoSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {return new SqlSessionTemplate(sqlSessionFactory);}
}
2.2 SpringBoot yml 配置
- yml 配置原因见5
spring:datasource:# 这个配置可要可不要,意义不大type: com.alibaba.druid.pool.DruidDataSourcedruid:# Spring监控aop-patterns: com.test.one.service.*,com.test.two.service.*# 监控配置web-stat-filter:# 是否启用StatFilter默认值trueenabled: true# 添加过滤规则url-pattern: /*# 忽略过滤的格式exclusions: /druid/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico# 关闭session监控session-stat-enable: false# Druid内置提供了一个StatViewServlet用于展示Druid的统计信息stat-view-servlet:# 是否启用StatViewServlet默认值trueenabled: true# 访问路径为/druid时,跳转到StatViewServleturl-pattern: /druid/*# 是否能够重置数据reset-enable: false# 需要账号密码才能访问控制台,默认为rootlogin-username: testlogin-password: test# IP白名单allow:# IP黑名单(共同存在时,deny优先于allow)deny:test-one:url: jdbc:mysql://127.0.0.1:3306/test_one?useSSL=false&characterEncoding=utf8&useTimezone=true&serverTimezone=GMT%2B8username: rootpassword: '123456'driver-class-name: com.mysql.cj.jdbc.Driver# 初始化时建立物理连接的个数initial-size: 5# 连接池的最小空闲数量min-idle: 5# 连接池最大连接数量max-active: 200# 获取连接时最大等待时间,单位毫秒max-wait: 60000# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。test-while-idle: true# 既作为检测的间隔时间又作为testWhileIdel执行的依据time-between-eviction-runs-millis: 60000# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)min-evictable-idle-time-millis: 30000# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)validation-query: select 1# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-borrow: false# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-return: false# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。pool-prepared-statements: false# 置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、Slf4j:日志记录、waLL: 防御sqL注入filters: stat,wall,slf4j# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100max-pool-prepared-statement-per-connection-size: -1# 合并多个DruidDataSource的监控数据use-global-data-source-stat: true# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000test-two:url: jdbc:mysql://127.0.0.1:3306/test_two?useSSL=false&characterEncoding=utf8&useTimezone=true&serverTimezone=GMT%2B8username: rootpassword: '123456'driver-class-name: com.mysql.cj.jdbc.Driver# 初始化时建立物理连接的个数initial-size: 5# 连接池的最小空闲数量min-idle: 5# 连接池最大连接数量max-active: 200# 获取连接时最大等待时间,单位毫秒max-wait: 60000# 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。test-while-idle: true# 既作为检测的间隔时间又作为testWhileIdel执行的依据time-between-eviction-runs-millis: 60000# 销毁线程时检测当前连接的最后活动时间和当前时间差大于该值时,关闭当前连接(配置连接在池中的最小生存时间)min-evictable-idle-time-millis: 30000# 用来检测数据库连接是否有效的sql 必须是一个查询语句(oracle中为 select 1 from dual)validation-query: select 1# 申请连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-borrow: false# 归还连接时会执行validationQuery检测连接是否有效,开启会降低性能,默认为truetest-on-return: false# 是否缓存preparedStatement, 也就是PSCache,PSCache对支持游标的数据库性能提升巨大,比如说oracle,在mysql下建议关闭。pool-prepared-statements: false# 置监控统计拦截的filters,去掉后监控界面sql无法统计,stat: 监控统计、Slf4j:日志记录、waLL: 防御sqL注入filters: stat,wall,slf4j# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100max-pool-prepared-statement-per-connection-size: -1# 合并多个DruidDataSource的监控数据use-global-data-source-stat: true# 通过connectProperties属性来打开mergeSql功能;慢SQL记录connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
三、mybatis插件配置
3.1 PageHelper的yml配置
- yml配置原因见6
#分页插件配置
pagehelper:helper-dialect: mysqlreasonable: truesupport-methods-arguments: trueparams: count=countSql
3.2 mybatis设置自定义字段默认值
- 需要2个java类,MyBatisInterceptorConfig.java,SetMySqlValueAutoConfiguration.java
- MyBatisInterceptorConfig见原因7
- SetMySqlValueAutoConfiguration见原因8
@Slf4j
@SuppressWarnings("unchecked")
@Intercepts({ @Signature(type = Executor.class, method = "update", args = { MappedStatement.class, Object.class }) })
public class MyBatisInterceptorConfig implements Interceptor {@Overridepublic Object intercept(Invocation invocation) throws Throwable {MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];// 获取 SQL 命令SqlCommandType sqlCommandType = mappedStatement.getSqlCommandType();// 获取参数Object parameter = invocation.getArgs()[1];// 如果不存在参数,直接返回if (parameter == null) {return invocation.proceed();}// 如果是批量插入一般是List类型,包装在ParamMap中if (parameter instanceof MapperMethod.ParamMap) {MapperMethod.ParamMap<Object> paramMap = (MapperMethod.ParamMap<Object>) parameter;for (Map.Entry<String, Object> entry : paramMap.entrySet()) {Object paramValue = entry.getValue();if (paramValue instanceof List) {List<Object> list = (List<Object>) paramValue;for (Object value : list) {// 设置对应数据值setFieldValues(value, sqlCommandType);}break;}}} else {setFieldValues(parameter, sqlCommandType);}return invocation.proceed();}/*** 设置字段对应值** @param parameter 实体信息* @param sqlCommandType sql类型* @author liulin* @date 2024-04-22 16:32:39**/private void setFieldValues(Object parameter, SqlCommandType sqlCommandType) throws IllegalAccessException, InvocationTargetException {// 获取私有成员变量Method[] declaredMethods = parameter.getClass().getDeclaredMethods();for (Method method : declaredMethods) {if (SqlCommandType.INSERT.equals(sqlCommandType)) {String name = method.getName();switch (name) {case "setUpdateUser":case "setCreateUser":method.invoke(parameter, getCurrentUserId());break;case "setCreateTime":case "setUpdateTime":method.invoke(parameter, new Date());break;case "setUpdateUserType":case "setCreateUserType":method.invoke(parameter, getCurrentUserType());break;default:break;}} else if (SqlCommandType.UPDATE.equals(sqlCommandType)) {String name = method.getName();switch (name) {case "setUpdateUser":method.invoke(parameter, getCurrentUserId());break;case "setUpdateTime":method.invoke(parameter, new Date());break;case "setUpdateUserType":method.invoke(parameter, getCurrentUserType());break;default:break;}}}}/*** 获取当前用户类型** @return int* @author liulin* @date 2024-11-14 15:05:55**/private Integer getCurrentUserType() {Authentication authentication = SecurityContextHolder.getContext().getAuthentication();if (authentication == null) {return null;}Object principal = authentication.getPrincipal();if (principal instanceof CarfiSessionUser) {return 1;}return null;}/*** 获取当前用户id** @return String* @author liulin* @date 2024-04-22 13:42:37**/private String getCurrentUserId() {Authentication authentication = SecurityContextHolder.getContext().getAuthentication();if (authentication == null) {return null;}Object principal = authentication.getPrincipal();if (principal instanceof CarfiSessionUser) {return CarfiUserUtils.getSysUser().getUserId();}return null;}@Overridepublic Object plugin(Object target) {return Plugin.wrap(target, this);}@Overridepublic void setProperties(Properties properties) {// comment explaining why the method is empty}
}
@Configuration
@ConditionalOnBean({SqlSessionFactory.class})
@AutoConfigureAfter({MybatisAutoConfiguration.class})
@Lazy(false)
public class SetMySqlValueAutoConfiguration implements InitializingBean {@Resourceprivate List<SqlSessionFactory> sqlSessionFactoryList;@Overridepublic void afterPropertiesSet() throws Exception {MyBatisInterceptorConfig interceptor = new MyBatisInterceptorConfig();for (SqlSessionFactory sqlSessionFactory : this.sqlSessionFactoryList) {org.apache.ibatis.session.Configuration configuration = sqlSessionFactory.getConfiguration();if (!this.containsInterceptor(configuration, interceptor)) {configuration.addInterceptor(interceptor);}}}private boolean containsInterceptor(org.apache.ibatis.session.Configuration configuration, Interceptor interceptor) {try {return configuration.getInterceptors().contains(interceptor);} catch (Exception var4) {return false;}}
}
四、配置解释
DruidDataSourceAutoConfigure
- 为什么要在启动类上排除DruidDataSourceAutoConfigure,是因为这个配置类com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure是下面这个样子
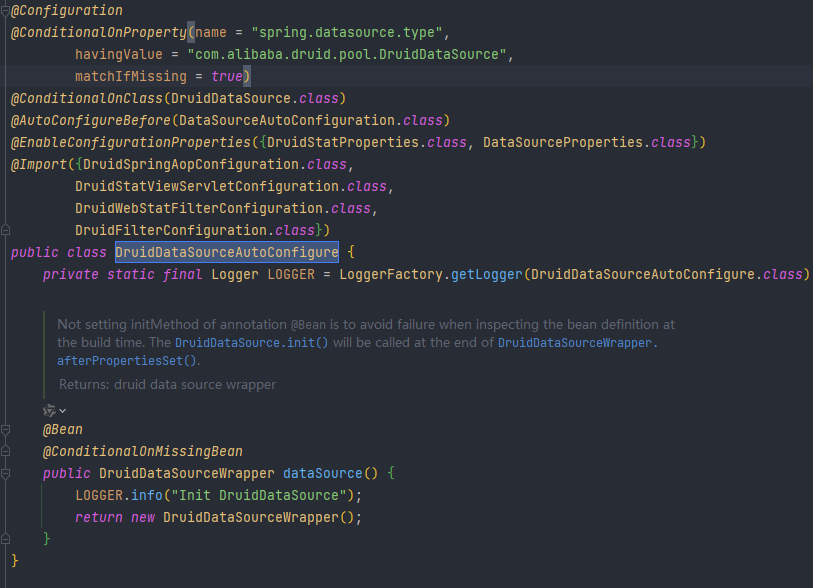
- 它自动装配了一堆druid的默认配置,包括数据源,监控界面,druid AOP切面等等类,其中DataSourceProperties导致spring.datasource下面必须要有默认数据库配置,否则就会报错,所以其实这里可以弄一个主数据源放上去,当然意义不是很大。
- 为什么要在启动类上排除DruidDataSourceAutoConfigure,是因为这个配置类com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure是下面这个样子
DruidAutoConfiguration
- 因为我排除了DruidDataSourceAutoConfigure,所以必须要把监控界面,druid AOP切面等等重新引入,否则druid的监控界面就没法正常使用了,druid监控界面进入路径: http://127.0.0.1:8080/login.html
DruidConfigTestOne
- 这个就很简单咯,就是配置数据源,sqlSessionFactory,事务管理器等一堆和数据配置有关的,@Primary保证是主数据源加载
DruidConfigTestTwo
- 和DruidConfigTestOne作用一致,就是副数据源
Druid 的 yml配置
- yml为什么可以像我上面这么配置,其实主要还是看DruidDataSourceAutoConfigure,他里面@EnableConfigurationProperties,@Import都可以点进去,可以看里面的字段属性,实际与yml的配置相关
PageHelper的yml配置
- 这个主要见PageHelperAutoConfiguration.java,com.github.pagehelper.autoconfigure.PageHelperAutoConfiguration
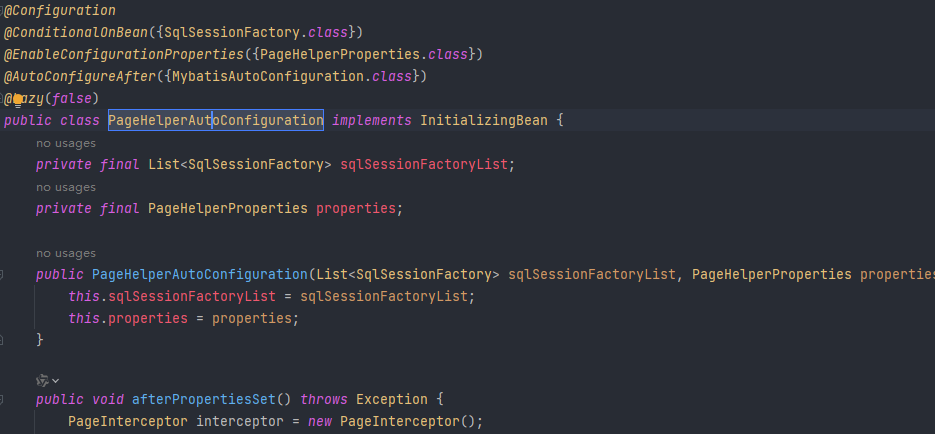
- 可以看到实现了InitializingBean,并且在afterPropertiesSet方法中设置了拦截器PageInterceptor,com.github.pagehelper.PageInterceptor
- 这个主要见PageHelperAutoConfiguration.java,com.github.pagehelper.autoconfigure.PageHelperAutoConfiguration
MyBatisInterceptorConfig
- 这个没啥好说的,就是在新增,更新时自动注入一些自定义字段值
SetMySqlValueAutoConfiguration
- 这个是因为MybatisAutoConfiguration.java类,org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration中的sqlSessionFactory被我自定义的sqlSessionFactory干扰了导致无法实现mybatis的拦截器注入,所以我就仿照PageHelperAutoConfiguration实现了一次自动注入,这样mybatis的自定义拦截器就不会因为自定义sqlSessionFactory而失效了。MybatisAutoConfiguration的sqlSessionFactory是下面这样的
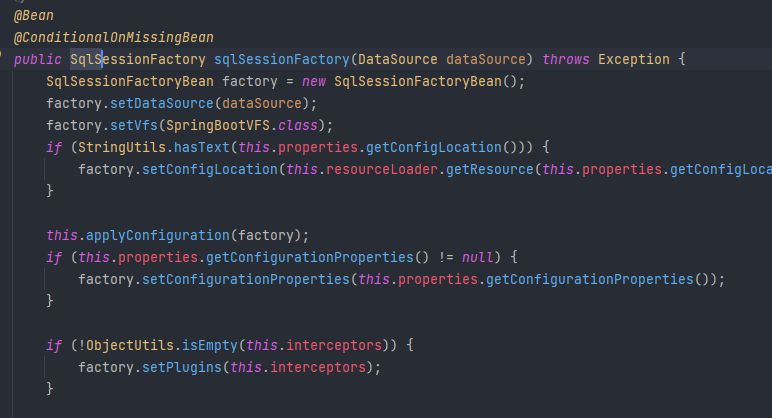
- 这个是因为MybatisAutoConfiguration.java类,org.mybatis.spring.boot.autoconfigure.MybatisAutoConfiguration中的sqlSessionFactory被我自定义的sqlSessionFactory干扰了导致无法实现mybatis的拦截器注入,所以我就仿照PageHelperAutoConfiguration实现了一次自动注入,这样mybatis的自定义拦截器就不会因为自定义sqlSessionFactory而失效了。MybatisAutoConfiguration的sqlSessionFactory是下面这样的





)
