最近工作中接触消息队列比较多,前几周又看到kafka4.0发布,故写一篇博客对消息队列做一个复盘。
目录
- 消息队列对比
- 1. Apache Kafka 4.0
- 2. RabbitMQ
- 3. RocketMQ
- 4. ActiveMQ
- 5. Apache Pulsar
- 6. NSQ
- kafka4.0
- 鲜明的新特性
- Java 版本要求升级
- API 更新与精简
- 移除zk依赖
- 新消费者组协议
- 快速开始
- 环境搭建
- windows环境
- linux Docker环境
- 生产消费
- 命令行
- golang
- 配置参考
消息队列对比
下面给出一个详细的对比表,涵盖了当前业界较主流的几款消息队列(MQ):Apache Kafka(特别是4.0版本)、RabbitMQ、RocketMQ、ActiveMQ以及Apache Pulsar。
| 产品 | 架构/协调机制 | 吞吐量 | 延迟 | 扩展性 | 消息持久性 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| Kafka 4.0 | 全新KRaft模式(废弃ZooKeeper),自管理元数据 | 超高(百万级TPS) | ms级 | 极佳(水平扩展非常灵活) | 强(持久化日志存储,支持回溯) | 高吞吐、可扩展、高可用;新增队列语义支持点对点消费;历史消息回放丰富 | 较重的学习曲线;对低延时要求的场景可能稍欠,消息重复风险(需应用层去重) | 大数据实时流处理、日志采集、事件溯源、数据管道、流计算应用 |
| RabbitMQ | 基于AMQP协议,Erlang开发;采用Broker模式推模式消息传递 | 中等(万级TPS左右) | 超低(微秒级推送) | 一般(主要依赖垂直扩展) | 可配置持久化(消息确认后删除) | 安装部署简单、支持多种路由和协议、成熟稳定、低延迟;管理界面友好 | 吞吐量较Kafka低;大量消息积压时性能下降;Erlang生态门槛较高 | 企业级系统、异步任务处理、RPC、请求-响应、低延迟实时消息传递 |
| RocketMQ | 分布式架构:NameServer+Broker+Producer/Consumer | 高(十万级TPS左右) | ms级 | 很好(通过集群可实现水平扩展) | 强(写盘及副本机制确保不丢失) | 金融级稳定性、支持顺序消息和事务、消息堆积能力出色;在阿里内部经受多次考验 | 客户端语言主要是Java(及不成熟的C++);社区生态较Kafka稍逊 | 订单交易、金融系统、实时计费、业务削峰、对顺序性和事务性要求较高的场景 |
| ActiveMQ | 基于JMS规范,主备模式,传统Broker模式 | 较低(万级TPS) | ms级 | 较弱(扩展性有限) | 支持持久化 | 标准JMS实现,功能较全、协议多样、适应传统系统对接 | 性能和扩展性不如新一代MQ,版本更新缓慢,社区活跃度较低 | 小规模企业、传统内部系统、对JMS兼容性要求较高的场景 |
| Pulsar | 分层架构:Broker + BookKeeper(存储计算分离),ZooKeeper协同(元数据管理) | 高(十万级TPS) | ms级 | 极佳(支持多租户、跨数据中心) | 强(存储与计算分离,持久性高) | 支持多租户、跨地域容灾、灵活消费模式(独占、共享、failover、key_shared);扩展性好 | 较新,成熟度和生态尚在发展阶段;部署和运维配置较复杂 | 云原生应用、大型分布式系统、多租户环境、跨地域数据复制、需要存储计算分离的场景 |
| NSQ | 轻量级 Pub/Sub 架构:nsqd 处理消息,nsqlookupd 负责服务发现 | 高(适当调优下能支持数十万TPS) | 超低(通常毫秒级) | 良好(易于集群水平扩展) | 可选持久化(默认在内存,支持磁盘模式) | 简洁易用、部署成本低、延迟极低、原生 Go 语言实现,高并发性能出色 | 功能较简单,不支持复杂路由、事务;在超大数据持久存储和回放场景下不如 Kafka | 微服务通信、实时数据流、轻量级事件分发、IoT、日志处理、请求-响应场景 |
1. Apache Kafka 4.0
核心变化与架构: Kafka 4.0 的标志性更新在于彻底废弃了对 ZooKeeper 的依赖,通过引入 KRaft(Kafka Raft)模式实现自管理元数据。这一改变简化了集群部署与管理,大大降低了运维复杂度,同时增强了集群的扩展性和可用性。
优点:
- 高吞吐与可扩展性:得益于分布式日志(持久化顺序写)技术,单机可以达到百万级TPS,多节点扩展非常灵活。
- 历史数据回放:持久化存储允许对历史数据进行重放和追溯,适合日志收集和事件溯源。
- 新增队列语义:Kafka 4.0开始支持点对点消费模式(共享组),让消息消费更加灵活。
缺点:
- 对新手来说,新体系结构和协议变化可能带来一定学习曲线。
- 在一些对实时性要求极高的场景下(如金融交易中毫秒级响应),相比基于推模式的RabbitMQ可能稍逊。
消费隔离:
- Kafka 采用 消费者组(Consumer Group) 模型:
- 同一组内,每个分区的消息仅由一个消费者消费,实现负载均衡;
- 不同消费者组独立消费同一主题的所有消息(即多个应用可获取完整消息副本)。
消息确认机制:
- Kafka 借助 offset 提交 来确认消费:
- 消费者处理完消息后提交当前偏移量(可自动或手动提交);
- 消费者故障时,未提交的消息会被重新消费,实现“至少一次”传递;
- 配合幂等生产者和事务,可实现精确一次消费。
Go 语言消费者示例: 使用 segmentio/kafka-go 库:
package mainimport ("context""fmt""log""github.com/segmentio/kafka-go"
)func main() {r := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},Topic: "example-topic",GroupID: "example-group",})defer r.Close()for {m, err := r.ReadMessage(context.Background())if err != nil {log.Fatal("error reading message: ", err)}fmt.Printf("Received message at offset %d: %s\n", m.Offset, string(m.Value))// 消费确认由 offset 提交决定(此库默认自动提交,可改为手动)}
}
适用场景: 主要适合大数据实时流处理、日志采集、事件溯源、数据管道以及流式计算。
2. RabbitMQ
架构特性: RabbitMQ 是基于 AMQP 协议,由 Erlang 开发,擅长消息的推送(push)模式,且内建丰富的交换机(Exchange)类型和路由机制,适合复杂的消息传递逻辑。
优点:
- 低延迟:由于推模式和Erlang语言并发特性,在消息响应上可以达到微秒级,非常适合需要低延时的场景。
- 灵活路由:多种交换机类型支持复杂的消息路由和过滤规则,满足不同业务需求。
- 成熟稳定:广泛应用于企业系统,管理界面友好,功能和插件成熟。
缺点:
- 吞吐量相对Kafka和RocketMQ较低,不太适合海量数据传输。
- 在消息积压时,性能下降较为明显。
- Erlang语言的生态对二次开发的要求较高,团队需要具备相应经验。
消费隔离:
- RabbitMQ 通过 队列与交换机 实现:
- 点对点模式下,同一队列中消息只会被一个消费者消费;
- 发布/订阅模式中,通过不同队列(或者同一个队列多个绑定)实现多个消费者各自获得完整消息。
消息确认机制:
- 使用 ACK/NACK 机制:
- 消费者处理成功后发送 ACK 给 Broker;
- 处理失败或超时则发送 NACK,消息重新投递,确保可靠性。
Go 语言消费者示例: 使用 streadway/amqp 库:
package mainimport ("fmt""log""github.com/streadway/amqp"
)func main() {conn, err := amqp.Dial("amqp://guest:guest@localhost:5672/")if err != nil {log.Fatal(err)}defer conn.Close()ch, err := conn.Channel()if err != nil {log.Fatal(err)}defer ch.Close()msgs, err := ch.Consume("example-queue", // 队列名称"", // consumer tagfalse, // auto-ack,为 false 需手动确认false,false,false,nil,)if err != nil {log.Fatal(err)}forever := make(chan bool)go func() {for d := range msgs {fmt.Printf("Received message: %s\n", d.Body)// 消费确认d.Ack(false)}}()fmt.Println("Waiting for messages. To exit press CTRL+C")<-forever
}
适用场景: 适合中小型企业、企业内部集成、异步任务处理、复杂路由消息(如RPC、请求响应)以及对实时性要求极高的业务场景。
3. RocketMQ
架构特性: RocketMQ 由阿里巴巴推出,采用Java实现,并针对高可靠性与顺序消息传递进行了优化。其核心架构由NameServer、Broker、Producer和Consumer组成,支持分布式部署。
优点:
- 高稳定性:在电商和金融场景中已有广泛验证,能够保证消息绝对不丢失。
- 高吞吐与顺序保证:支持十万级TPS,同时针对顺序消息和事务消息有特殊优化。
- 易于掌控:Java源码公开,便于二次开发和定制。
缺点:
- 客户端语言支持较为有限,主要集中在Java及部分C++实现。
- 社区生态和国际影响力略逊于Kafka。
消费隔离:
- 采用 消费者组(Consumer Group) 模型:
- 同一组内,消息在多个消费者间分配;
- 不同组独立消费同一主题下的全部消息,实现应用级隔离。
消息确认机制:
- 通过 回执确认:
- 消费者成功处理后,向 Broker 返回确认;
- 若未确认,Broker 根据重试策略重新投递消息。
Go 语言消费者示例: 使用 rocketmq-client-go/v2 库:
package mainimport ("context""fmt""log""github.com/apache/rocketmq-client-go/v2""github.com/apache/rocketmq-client-go/v2/consumer""github.com/apache/rocketmq-client-go/v2/primitive"
)func main() {c, err := rocketmq.NewPushConsumer(consumer.WithGroupName("testGroup"),consumer.WithNamesrvAddr([]string{"127.0.0.1:9876"}),)if err != nil {log.Fatalf("could not create consumer: %v", err)}err = c.Subscribe("example-topic", consumer.MessageSelector{}, func(ctx context.Context, msgs ...*primitive.MessageExt) (consumer.ConsumeResult, error) {for _, msg := range msgs {fmt.Printf("Received message: ID=%s, Body=%s\n", msg.MsgId, string(msg.Body))}// 处理成功返回确认return consumer.ConsumeSuccess, nil})if err != nil {log.Fatalf("subscribe error: %v", err)}err = c.Start()if err != nil {log.Fatalf("start consumer error: %v", err)}defer c.Shutdown()select {} // 阻塞等待
}
适用场景: 特别适用于金融、电商、订单交易系统以及对消息顺序和事务要求极高的场景;同时适合大规模消息堆积和削峰场景。
4. ActiveMQ
架构特性: ActiveMQ 基于JMS规范实现,支持多种消息模型(点对点和发布订阅),是较早期的开源消息中间件。
优点:
- 功能完备:实现了JMS标准,支持多种消息协议,兼容性好。
- 成熟稳定:广泛应用于传统企业系统中,适合作为内部消息传递通道。
缺点:
- 吞吐量和扩展性较差,不适合大规模数据处理。
- 社区更新缓慢,新功能和性能优化明显不足。
消费隔离:
- ActiveMQ 支持 队列(Point-to-Point) 和 主题(Publish/Subscribe) 模式:
- 队列模式中,消息只由一个消费者接收;
- 主题模式中,每个订阅者(Subscriber)都能收到消息,实现消费隔离。
消息确认机制:
- 支持多种 JMS 确认模式:
- AUTO_ACKNOWLEDGE(自动确认)、CLIENT_ACKNOWLEDGE(客户端确认)、或 SESSION_TRANSACTED(事务处理)
- 根据需求选择适当的模式,保证消息可靠传递或事务性一致性。
Go 语言消费者示例(基于 STOMP 协议): 使用 go-stomp/stomp 库:
package mainimport ("fmt""log""github.com/go-stomp/stomp"
)func main() {conn, err := stomp.Dial("tcp", "localhost:61613")if err != nil {log.Fatal(err)}defer conn.Disconnect()sub, err := conn.Subscribe("/queue/example.queue", stomp.AckAuto)if err != nil {log.Fatal(err)}defer sub.Unsubscribe()for {msg := <-sub.Cif msg.Err != nil {log.Fatal(msg.Err)}fmt.Printf("Received message: %s\n", string(msg.Body))}
}
适用场景: 适合小型或传统企业内部系统、与JMS兼容性要求较高的场景,对于消息量和吞吐要求不高的应用依然是个不错的选择。
5. Apache Pulsar
架构特性: Pulsar 采用分层架构设计,核心由Broker、BookKeeper(专用存储引擎)和ZooKeeper(元数据管理)组成,实现了存储与计算分离。支持多租户与跨数据中心部署。
优点:
- 灵活性与扩展性:天然支持多租户,集群水平扩展容易,适合大规模云原生应用。
- 高可用与跨区域支持:内置跨数据中心容灾机制,能满足复杂分布式部署需求。
- 多样化消费模式:支持独占、共享、故障转移和Key共享消费模式,灵活应对不同业务需求。
缺点:
- 由于相对较新,成熟度和部分生态支持尚不及Kafka;运维和部署配置较为复杂。
消费隔离:
- Pulsar 通过 订阅(Subscription) 机制实现消费隔离:
- 每个订阅就像一个独立的消费组,不同订阅可以独立消费同一主题的全部消息。
- 提供多种订阅类型(Exclusive、Shared、Failover、Key_Shared),以满足顺序性、负载均衡及容灾需求。
消息确认机制:
- 消费者在处理消息后需要显式 发送 ACK:
- 同时支持单条确认和累积确认,保证至少一次传递;
- 未确认的消息会在规定时间内重新投递。
Go 语言消费者示例: 使用 pulsar-client-go 库:
package mainimport ("context""fmt""log""github.com/apache/pulsar-client-go/pulsar"
)func main() {client, err := pulsar.NewClient(pulsar.ClientOptions{URL: "pulsar://localhost:6650",})if err != nil {log.Fatal(err)}defer client.Close()consumer, err := client.Subscribe(pulsar.ConsumerOptions{Topic: "example-topic",SubscriptionName: "example-subscription",Type: pulsar.Exclusive, // 或 Shared、Failover、KeyShared})if err != nil {log.Fatal(err)}defer consumer.Close()for {msg, err := consumer.Receive(context.Background())if err != nil {log.Fatal(err)}fmt.Printf("Received message [ID=%v]: '%s'\n", msg.ID(), string(msg.Payload()))consumer.Ack(msg)}
}
适用场景: 适合于云原生、大规模分布式、多租户应用、跨数据中心容灾场景以及对存储与计算分离有明确需求的系统。
6. NSQ
架构特性: NSQ 是由 Go 语言开发的实时分布式消息中间件,采用去中心化的架构设计。核心由 nsqd(消息处理)与 nsqlookupd(服务发现)组成,不依赖像 ZooKeeper 这样的协调组件,支持原生的 Pub/Sub 模型。通过 HTTP API 与轻量组件组合,实现简洁、高性能、低延迟的消息传递。
优点:
- 部署简单:无外部依赖,单一可执行文件即可运行,便于集群扩展和维护。
- 低延迟高性能:基于 Go 的并发能力,微秒级延迟,单节点即可支撑高并发消息流。
- 架构解耦性好:通过
nsqlookupd实现服务发现,无中心协调器,天然高可用。 - 接口友好:内建 Web UI 和 HTTP API,开发调试体验良好。
- 原生 Go 支持:Go 项目集成自然,生态偏 Go 场景友好。
缺点:
- 功能较轻:不支持事务、延迟队列、顺序消息等高级特性。
- 持久化能力有限:虽然支持磁盘落盘,但缺乏 Kafka 等级的日志存储与历史重放能力。
- 消费管理弱:无 offset 管理,幂等和消费追踪需业务方补齐。
- 生态较小:相较于 Kafka、RabbitMQ 社区活跃度较低,语言支持主要集中于 Go 与 Python。
消费隔离:
- NSQ 采用 Channel 概念 实现消费隔离:
- 一个 Topic 可以有多个 Channel,每个 Channel 相当于一个独立的消费订阅;
- 同一 Channel 内的多个消费者会自动进行负载均衡,而不同 Channel 则各自收到完整的消息副本。
消息确认机制:
- NSQ 采用 ACK 机制:
- 消费者成功处理后发送 ACK;
- 如果超时未确认,NSQ 会重新投递消息,确保可靠消费。
Go 语言消费者示例: 使用 nsqio/go-nsq 库:
package mainimport ("fmt""log""github.com/nsqio/go-nsq"
)type ConsumerHandler struct{}func (h *ConsumerHandler) HandleMessage(m *nsq.Message) error {fmt.Printf("Received NSQ message: %s\n", string(m.Body))return nil // 返回 nil 即确认消息处理成功
}func main() {config := nsq.NewConfig()consumer, err := nsq.NewConsumer("example_topic", "example_channel", config)if err != nil {log.Fatal(err)}consumer.AddHandler(&ConsumerHandler{})// 连接 nsqlookupd 进行服务发现if err := consumer.ConnectToNSQLookupd("127.0.0.1:4161"); err != nil {log.Fatal(err)}select {} // 阻塞等待
}
适用场景:
适用于微服务架构、实时日志/监控系统、IoT 消息传递、请求-响应异步通信、快速原型/初创项目等。特别适合 Go 项目中需要高并发、低延迟、部署轻便的消息队列方案。
kafka4.0

我们将目光回到kafka4.0!这是一个重要里程碑,官方称这是第一个完全无需 Apache ZooKeeper 运行的重大版本。
Apache Kafka 4.0 是一个重要的里程碑,标志着第一个完全无需 Apache ZooKeeper® 运行的重大版本。通过默认运行在 KRaft 模式下,Kafka 简化了部署和管理,消除了维护单独的 ZooKeeper 集群的复杂性。这一变化显著降低了运营开销,增强了可伸缩性,并简化了管理任务。
Kafka 的主要版本,如 4.0 版本,移除了至少 12 个月前已弃用的 API,以简化平台,并鼓励采用新功能。值得注意的是,在 Kafka 4.0 中,Kafka 客户端和 Kafka Streams 需要 Java 11,而 Kafka 代理、Connect 和工具现在则需要 Java 17。
发布说明:https://archive.apache.org/dist/kafka/4.0.0/RELEASE_NOTES.html
官方文档:https://kafka.apache.org/documentation.html#upgrade_4_0_0
官方下载连接:https://kafka.apache.org/downloads
我们在官方下载二进制包并且解压,会发现以往繁重的zk配置消失了!
鲜明的新特性
Java 版本要求升级
随着 Kafka 4.0 的发布,其对 Java 版本的要求也相应提高,Kafka 客户端和 Kafka Streams 需要 Java 11,而 Kafka 代理、Connect 和相关工具则需要 Java 17。这一升级举措具有多方面的重要意义:
-
性能优化:较新的 Java 版本在性能方面有了显著提升,包括更快的 JIT 编译器、优化的垃圾回收机制等。这将直接反映在 Kafka 的运行效率上,提高消息处理速度和系统响应能力。
-
安全增强:新版本的 Java 修复了众多安全漏洞,并引入了更强大的安全特性。升级到指定的 Java 版本,能够确保 Kafka 系统在日益复杂的网络安全环境中具备更高的安全性,保护数据的完整性和保密性。
-
功能扩展:Java 11 和 17 引入了许多新特性和 API,如 HttpClient、Switch 表达式增强等。这些新特性为 Kafka 的开发和扩展提供了更多可能性,有助于构建更现代化、功能更强大的应用程序。
对于使用 Kafka 的项目团队而言,这一变化提醒他们在升级 Kafka 版本时,务必同步检查和更新 Java 运行环境,以确保系统的兼容性和稳定性。同时,这也是推动团队技术栈升级,拥抱现代化开发工具和实践的良好契机。
在 Kafka 4.0 版本中,用于开发和运行消息生产与消费的客户端库(包括 Kafka Streams 作为流处理库)要求运行环境至少使用 Java 11;而 Kafka 的服务器端组件(也就是 Kafka 代理,即 broker)、用于数据集成的 Kafka Connect 框架以及其它附带的管理和工具程序,则需要在更高版本的 Java(Java 17)上运行。这反映了 Kafka 4.0 在不同组件上对 Java 功能和性能优化的不同需求。
-
Kafka 客户端
- 定义: Kafka 客户端是指开发者在应用程序中使用的库,这些库使得应用程序能够连接到 Kafka 集群,实现消息的生产(Producer)和消费(Consumer)。
- 作用: 客户端负责与 Kafka 服务器通信,发送和接收消息,是应用程序与 Kafka 集群交互的接口。
- Java 要求: Kafka 客户端库(如 Java 的 KafkaProducer 和 KafkaConsumer)需要在 Java 11 环境下运行。
-
Kafka Streams
- 定义: Kafka Streams 是构建在 Kafka 客户端之上的一个高层次流处理库,用于开发实时、分布式的流处理应用程序。
- 作用: 它简化了流数据的处理、转换、聚合等操作,使开发者能够更轻松地构建复杂的实时处理管道。
- Java 要求: 同样需要 Java 11 环境,这与 Kafka 客户端保持一致。
-
Kafka 代理(Broker)
- 定义: Kafka 代理是 Kafka 集群中的服务器组件,负责存储主题、分区数据,并提供数据发布、订阅和持久化功能。
- 作用: 它是 Kafka 集群的核心,负责接收消息、写入日志、管理数据副本、协调集群内部的各种操作等。
- Java 要求: Kafka 代理需要在 Java 17 环境下运行,说明新版代理利用了 Java 17 的新特性和性能改进,以实现更高的稳定性和吞吐量。
-
Kafka Connect
- 定义: Kafka Connect 是一个用于将外部系统(例如数据库、文件系统、搜索引擎等)与 Kafka 集群无缝集成的框架。
- 作用: 它提供了数据的导入和导出功能,使得数据能够在 Kafka 与其他系统之间流动,简化了数据集成工作。
- Java 要求: Kafka Connect 及相关工具也需要在 Java 17 环境下运行,可能是因为这些工具需要更高的性能和更现代的 JVM 特性来支持大规模数据交换和管理任务。
API 更新与精简
为了保持平台的简洁性和可持续发展,Kafka 4.0 删除了至少 12 个月前被废弃的 API。
KIP-724: 移除对消息格式 v0 和 v1 的支持:消息格式 v0 和 v1 在 Apache Kafka 3.0 中被弃用。它们已在 4.0 版本中移除。
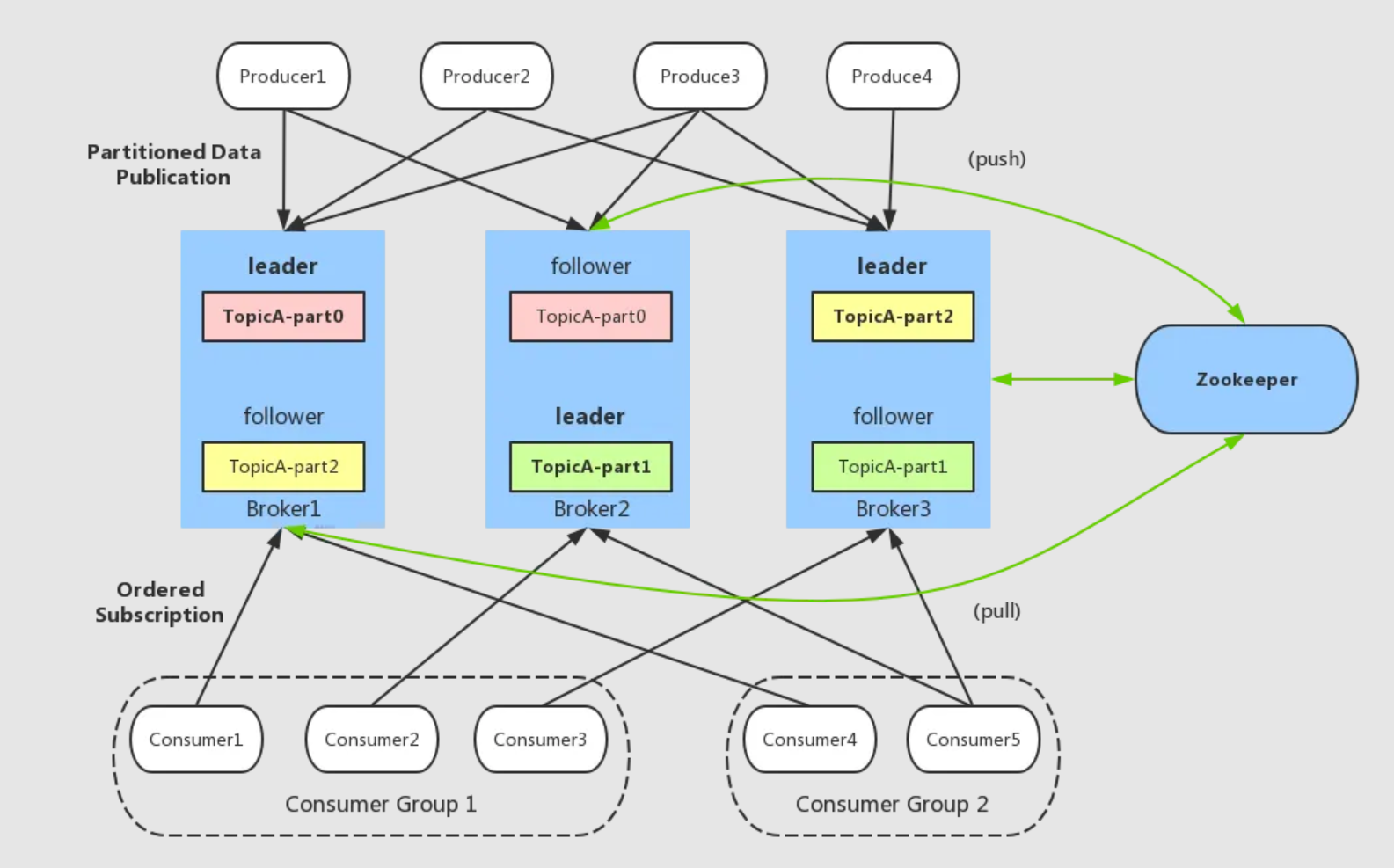
移除zk依赖
在 Kafka 3.x 及更早版本中,ZooKeeper(ZK)是元数据管理的核心组件,负责 Broker 注册、Topic 分区分配、控制器选举等关键任务,如图所示。
这种设计存在显著问题:
- 运维复杂度高 :需独立维护 ZK 集群,占用额外资源且增加故障点。
- 性能瓶颈明显 :元数据操作依赖 ZK 的原子广播协议(ZAB),大规模集群(如万级分区)下元数据同步延迟可达秒级。
- 扩展性受限 :ZK 的写性能随节点数增加而下降,限制 Kafka 集群规模。
Apache Kafka Raft(KRaft)是在 KIP-500 中引入的共识协议,用于移除 Apache Kafka 对 ZooKeeper 进行元数据管理的依赖。这通过将元数据管理的责任集中在 Kafka 本身,而不是在两个不同的系统(ZooKeeper 和 Kafka)之间分割,从而大大简化了 Kafka 的架构。
KRaft 模式利用 Kafka 中的新法定多数控制器服务,取代了之前的控制器,并使用基于事件的 Raft 共识协议的变体。
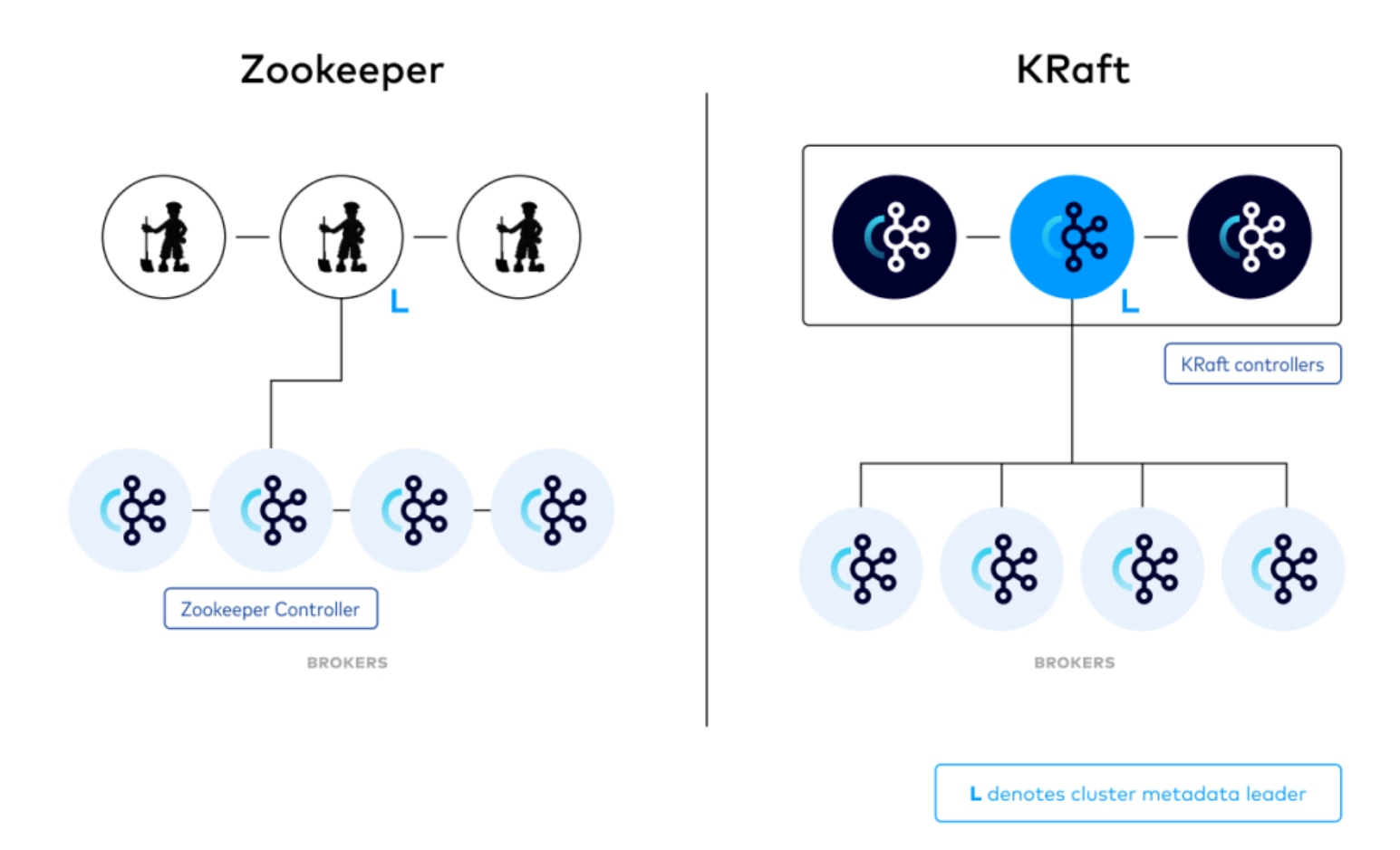
Kafka 4.0 默认启用 KRaft 模式 (Kafka Raft),完全摒弃 ZK 依赖。其核心原理如下:
- 元数据自管理 :基于 Raft 共识算法,将元数据存储于内置的 __cluster_metadata 主题中,由 Controller 节点(通过选举产生)统一管理。
- 日志复制机制 :所有 Broker 作为 Raft 协议的 Follower,实时复制 Controller 的元数据日志,确保强一致性。
- 快照与恢复 :定期生成元数据快照,避免日志无限增长,故障恢复时间从 ZK 时代的分钟级优化至秒级。
新消费者组协议
传统上,Kafka 主要采用发布-订阅模式,消费者组模式下,分区需与消费者一一绑定,如下图所示。
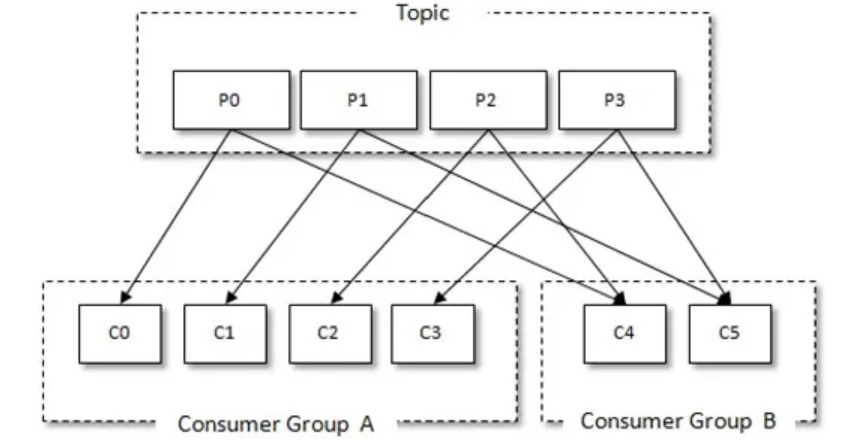
无法实现多消费者协同处理同一分区消息,消费者数量不能超过分区数量——最多为一对一。

在大规模数据处理场景中,消费者组的重平衡操作一直是影响系统性能和用户体验的关键环节。Kafka 4.0 通过引入新的消费者组协议(KIP-848),对这一核心功能进行了深度优化。传统上,当消费者组内的成员发生变化(如消费者实例的加入或退出)时,整个组会触发重平衡过程,以重新分配分区的消费任务。然而,这一过程往往会导致短暂的停机时间和延迟增加,尤其是在消费者组规模较大或分区数量较多的情况下。 新的消费者组协议将重平衡逻辑从客户端转移到了服务器端,从根本上解决了上述问题。
Apache Kafka 通过下一代消费者重平衡协议的通用可用性,告别了 “停止世界” 的重平衡。它提高了消费者组的稳定性和性能,同时简化了客户端。新的协议在服务器端默认启用。消费者必须通过设置 group.protocol=consumer 来选择加入。
在某些特定场景下,如点对点的消息传递、任务分配等,传统的队列语义更具优势。
Kafka 4.0 通过引入“队列”功能, 共享组(Share Group) , 允许多消费者同时处理同一分区消息,实现点对点消费模式 。
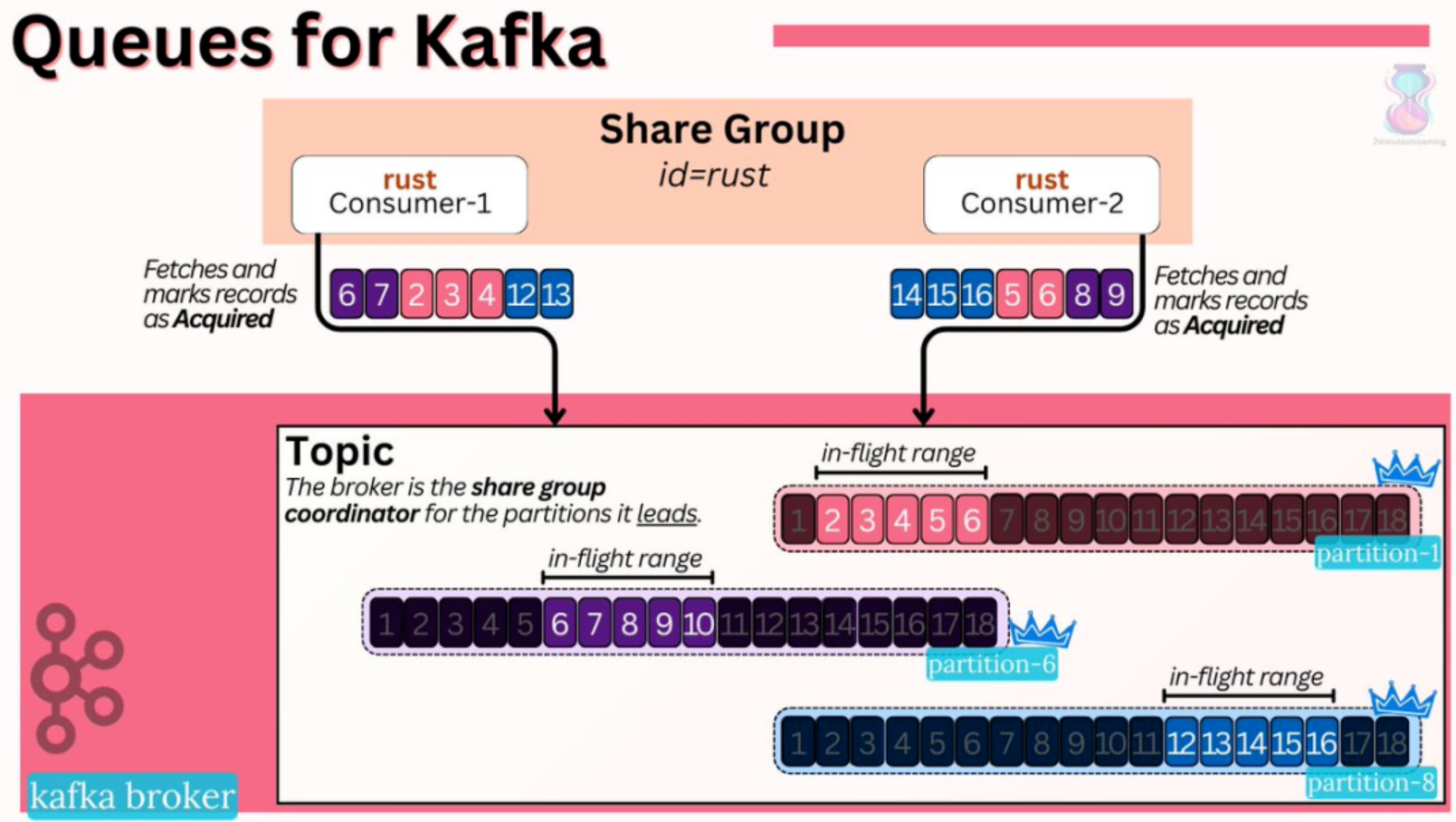
Kafka 4.0 通过 共享组 实现队列语义,关键技术包括:
- 多消费者协同消费 :同一分区的消息可由多个消费者并行处理,突破分区数限制。
- 记录级锁机制 :每条消息被消费时加锁(TTL 控制),防止重复处理。
- ACK/NACK 语义 :支持逐条确认(Exactly-Once)或重试(At-Least-Once)。
主要特点:
- 支持传统队列场景 :适用于需要保证消息严格顺序且仅由一个消费者处理的场景。
- 提升资源利用率 :共享组机制使得多个消费者能够动态地共享分区资源,提高了系统资源的利用率和整体吞吐量。
- 简化架构设计 :开发者无需在 Kafka 与其他专门的队列系统之间进行复杂的集成和数据迁移。(因为之前kafka是通过偏移量offset提交的,而不是ack/nack)
快速开始
环境搭建
windows环境
在本地,我们可以下载tgz包然后解压,kafka在bin目录下面开辟了windows子目录,提供了对windows环境的支持,
修改配置文件server.properties就可以通过启动脚本启动了:
.\bin\windows\kafka-server-start.bat .\config\server.properties
有时候会报错:
'wmic' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
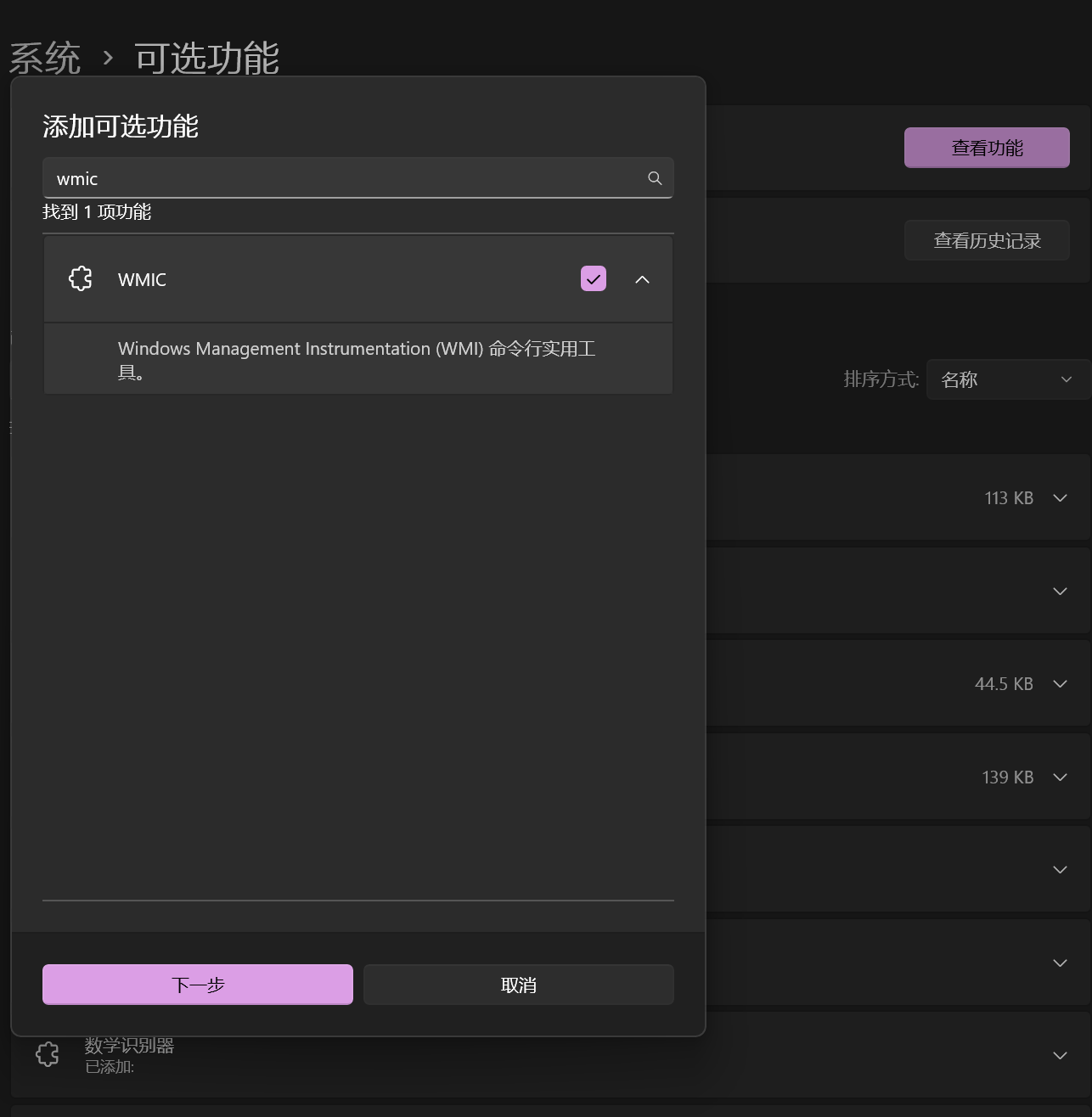
WMIC(Windows Management Instrumentation Command-line),是 Windows 系统中的一种命令行界面工具,用于通过 Windows 管理规范(WMI)获取系统和网络信息、管理 Windows 操作系统和设备。微软已于 2016 年在 Windows Server 中弃用了 WMIC;于 2021 年在 Windows 10 系统中弃用了 WMIC。
2024年微软再度禁用了 Windows 11 中内置的 WMIC 管理工具,并宣布将在 Windows 11 的下个版本中正式“砍掉”这款应用。
我们需要首先去设置->可选功能->查看功能搜索wmic重新下载:
然后重新启动:
PS H:\kafka\kafka_2.13-4.0.0> .\bin\windows\kafka-server-start.bat .\config\server.properties
DEPRECATED: A Log4j 1.x configuration file has been detected, which is no longer recommended.
To use a Log4j 2.x configuration, please see https://logging.apache.org/log4j/2.x/migrate-from-log4j1.html#Log4j2ConfigurationFormat for details about Log4j configuration file migration.
You can also use the H:\kafka\kafka_2.13-4.0.0/config/tool-log4j2.yaml file as a starting point. Make sure to remove the Log4j 1.x configuration after completing the migration.
'java' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
出现这个命令代表我们本机没有java环境,由于kafka依赖java17,我们去官网下载:https://www.oracle.com/java/technologies/javase/jdk17-archive-downloads.html
然后配置环境变量,并添加path:
变量名:JAVA_HOME
变量值:安装位置%JAVA_HOME%\bin
能正常输入如下内容即代表安装完成,

除此之外,这是因为 Kafka 在使用 KRaft 模式时,需要在日志目录中存在 meta.properties 文件来存储集群元数据(如 cluster.id 和 broker.id),如果该文件缺失,Kafka 将无法启动。默认配置的日志目录会导致无法启动,因此我们修改配置文件:
log.dirs=H:/kafka/kafka_2.13-4.0.0/tmp
然后生成一个唯一的集群 ID(可能会输出log4j的错误,不是kafka的错误,我们直接忽略):
.\bin\windows\kafka-storage.bat random-uuid
然后,使用生成的 UUID 格式化存储目录
.\bin\windows\kafka-storage.bat format --standalone -t <your-uuid> -c .\config\server.properties
然后再次启动:
linux Docker环境
我们可以看到windows下环境搭建非常复杂,docker可以将复杂的环境与开发工作解耦,官方提供的docker镜像有两种:
基于JVM的镜像(Using JVM Based Apache Kafka Docker Image):
docker pull apache/kafka:4.0.0
docker run -p 9092:9092 apache/kafka:4.0.0
基于GraalVM的镜像(Using GraalVM Based Native Apache Kafka Docker Image)
docker pull apache/kafka-native:4.0.0
docker run -p 9092:9092 apache/kafka-native:4.0.0
从体积上看,基于GraalVM的镜像明显小很多,可以按照python和go直观对比,第一种相当于基于python解释器把代码也要放进去,第二种相当于源码编译好后就放了一个可执行文件和配置文件。
GraalVM 本质上是一个支持 Java 的运行时(基于 OpenJDK),但它内置了一个更强大的 JIT 编译器(Graal Compiler)。它可以把 Java 应用编译成一个 不依赖 JVM 的原生可执行文件,启动速度非常快,内存占用更小。原理是 提前编译(AOT),在编译阶段就静态分析代码,连类加载器、GC、反射等都做了裁剪或替换。
GraalVM 支持在一个进程中运行和互操作以下语言:
- Java / Kotlin / Scala 等 JVM 语言
- JavaScript / TypeScript
- Python(实验性)
- Ruby(实验性)
- R、LLVM-based languages(如 C/C++ via Sulong)
编译后的影响:
-
启动速度:kafka-native 镜像由于是原生可执行文件,启动速度更快,适合对启动时间敏感的场景。
-
资源占用:原生镜像在运行时的内存占用通常更小,适合资源受限的环境。
-
兼容性:由于 kafka-native 是通过 GraalVM 编译的,可能在某些特性上与标准 JVM 版本存在差异,需注意兼容性问题。
生产消费
命令行
执行如下命令就可以创建一个名为mytest的topic:
// windows
bin/windows/kafka-topics.bat --create --topic mytest --bootstrap-server localhost:9092// linux
bin/kafka-topics.sh --create --topic mytest --bootstrap-server localhost:9092

查看topic详细信息:
$ bin/kafka-topics.sh --describe --topic mytest --bootstrap-server localhost:9092
Topic: quickstart-events TopicId: NPmZHyhbR9y00wMglMH2sg PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: quickstart-events Partition: 0 Leader: 0 Replicas: 0 Isr: 0

生产消息:
$ bin/kafka-console-producer.sh --topic mytest --bootstrap-server localhost:9092
>hello
>world

消费消息:
$ bin/kafka-console-consumer.sh --topic mytest --from-beginning --bootstrap-server localhost:9092
This is my first event
This is my second event

golang
现在去golang package网站搜kafka,人气较高的有两个:
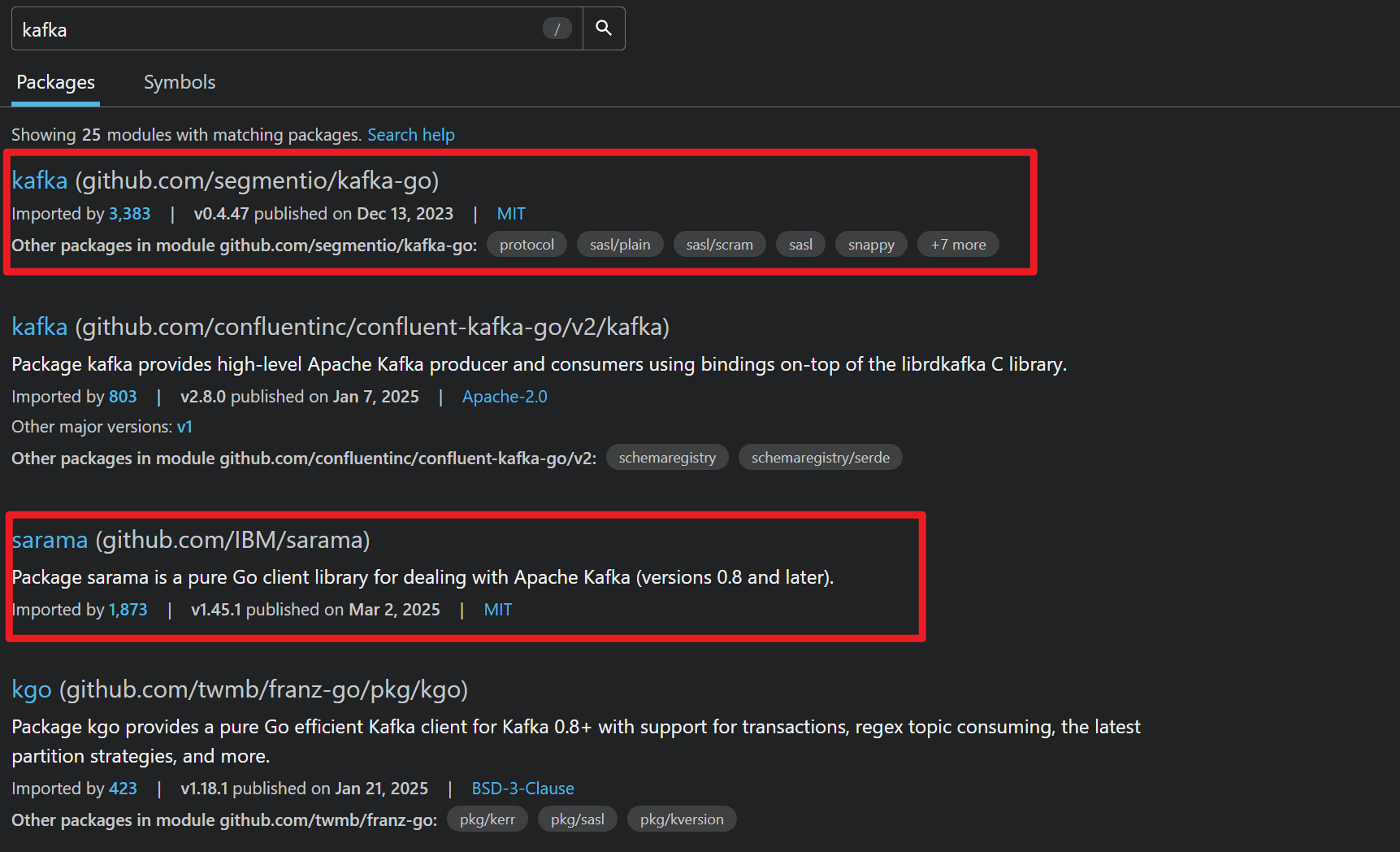
对比下两个库:
| 特性 | Sarama(IBM 维护) | kafka-go(Segment 维护) |
|---|---|---|
| Kafka 版本支持 | 支持 Kafka 0.8+,但对 Kafka 4.0 的支持未明确,存在兼容性风险 | 官方测试支持 Kafka 0.10.1.0 至 2.7.1,尚未明确支持 Kafka 4.0 |
| 分区感知能力 | 存在分区变更后需重启客户端的问题 | 支持自动感知分区变化,具备自动重试和重连机制 |
| 维护状态 | 由 IBM 接手维护,活跃度一般,文档相对较少 | 维护活跃,文档完善,易于学习和使用 |
性能与资源占用
| 特性 | Sarama | kafka-go |
|---|---|---|
| 同步写性能 | 异步模式性能较好,但同步模式性能较差,存在内存占用高的问题 | 异步写性能优异,适合高吞吐场景;同步写性能较差 |
| 内存管理 | 使用指针传递,导致频繁的垃圾回收和较高的内存使用 | 内存管理更高效,资源占用较低 |
功能特性
| 特性 | Sarama | kafka-go |
|---|---|---|
| API 设计 | 提供低级 API,使用复杂,缺乏对 Go 上下文(context)的支持 | 提供高级和低级 API,支持 Go 上下文,易于集成 |
| 消费者组支持 | 支持消费者组,但在多个 Topic 订阅时可能存在部分分区无法消费的问题 | 支持消费者组,具备自动重试和重连机制,稳定性更高 |
| Mock 测试支持 | 提供 Mock 测试包,便于单元测试 | 不提供 Mock 测试包,需自行搭建测试环境 |
社区与生态
| 特性 | Sarama | kafka-go |
|---|---|---|
| 社区活跃度 | 社区活跃度一般,文档相对较少 | 社区活跃,文档完善,易于学习和使用 |
| 生态支持 | 与其他 Go 项目集成较为复杂 | 易于与 Go 项目集成,适合快速开发 |
-
推荐使用 kafka-go:如果您追求简洁的 API、良好的性能和更高的稳定性,尤其是在需要自动感知分区变化和支持 Go 上下文的场景下,kafka-go 是更合适的选择。
-
谨慎使用 Sarama:尽管 Sarama 在异步高并发操作方面表现良好,但存在分区感知能力差、内存管理不佳等问题,且对 Kafka 4.0 的兼容性未明确,建议在特定需求下谨慎使用。
-
关注 Confluent-Kafka-go:如果您需要完全兼容 Kafka 的所有特性,并且可以接受引入 C++ 库带来的编译复杂度,Confluent-Kafka-go 是一个值得考虑的选择。
这里直接扑上Kafka-go官网的看法:
我们在 Segment 广泛依赖 Go 和 Kafka。不幸的是,在撰写本文时,Kafka 的 Go 客户端库的状态并不理想。可用的选项包括:
-
sarama:虽然是目前最受欢迎的,但使用起来非常困难。它文档不足,API 暴露了 Kafka 协议中的底层概念,而且不支持 Go 的新特性,如 context。它还将所有值都作为指针传递,导致大量的动态内存分配、更频繁的垃圾回收以及更高的内存使用。
-
confluent-kafka-go:这是一个基于 librdkafka 的 cgo 封装,因此它在所有使用该包的 Go 代码中都引入了对 C 库的依赖。它的文档比 sarama 好得多,但仍然不支持 Go 的 context。
-
goka:是一个较新的 Kafka Go 客户端,专注于特定的使用模式。它为将 Kafka 用作服务之间消息总线(而不是事件顺序日志)提供了抽象,但这并不是我们在 Segment 使用 Kafka 的典型方式。该包还依赖 sarama 处理所有与 Kafka 的交互。
这就是 kafka-go 的用武之地。它提供了用于与 Kafka 交互的高级和低级 API,模仿了 Go 标准库的概念并实现了其接口,使其易于使用并能与现有软件集成。
不管怎么说,我们先下载下来看看:github.com/segmentio/kafka-go,kafka-go提供了低级api和高级api,所谓低级/高级指的是:
低级 API
特点:
- 直接控制:开发者需要直接管理与 Kafka 的连接、分区、偏移量等细节。
- 灵活性高:适用于需要精细控制 Kafka 行为的场景,例如手动管理偏移量、特定的分区消费策略等。
使用示例:
以下是使用低级 API 通过 kafka.Conn 发送消息的示例:
package mainimport ("context""log""time""github.com/segmentio/kafka-go"
)func main() {topic := "my-topic"partition := 0// 连接到 Kafka 的指定分区的 leaderconn, err := kafka.DialLeader(context.Background(), "tcp", "localhost:9092", topic, partition)if err != nil {log.Fatal("failed to dial leader:", err)}defer conn.Close()// 设置写入超时时间conn.SetWriteDeadline(time.Now().Add(10 * time.Second))// 发送消息_, err = conn.WriteMessages(kafka.Message{Value: []byte("Hello Kafka")},kafka.Message{Value: []byte("Another Message")},)if err != nil {log.Fatal("failed to write messages:", err)}
}
高级 API
特点:
- 简化操作:封装了常用的读写操作,内部自动处理连接、分区、偏移量等细节。
- 易于使用:适合大多数常规的 Kafka 使用场景,开发者无需关注底层实现。
使用示例:
以下是使用高级 API 的生产者和消费者示例:
生产者:
package mainimport ("context""log""time""github.com/segmentio/kafka-go"
)func main() {// 初始化一个 writer,指定 Kafka 地址和主题writer := kafka.NewWriter(kafka.WriterConfig{Brokers: []string{"localhost:9092"},Topic: "my-topic",Balancer: &kafka.LeastBytes{},})defer writer.Close()// 创建消息msg := kafka.Message{Key: []byte("Key-A"),Value: []byte("Hello Kafka"),}// 发送消息err := writer.WriteMessages(context.Background(), msg)if err != nil {log.Fatal("failed to write messages:", err)}log.Println("Message is written")
}
消费者:
package mainimport ("context""log""github.com/segmentio/kafka-go"
)func main() {// 初始化一个 reader,指定 Kafka 地址、主题和消费者组reader := kafka.NewReader(kafka.ReaderConfig{Brokers: []string{"localhost:9092"},GroupID: "my-group",Topic: "my-topic",MinBytes: 10e3, // 10KBMaxBytes: 10e6, // 10MB})defer reader.Close()for {// 读取消息msg, err := reader.ReadMessage(context.Background())if err != nil {log.Fatal("failed to read message:", err)}log.Printf("Message at offset %d: %s = %s\n", msg.Offset, string(msg.Key), string(msg.Value))}
}
这次我们采用镜像方式启动kafka,首先打开dockerhub页面搜索kafka,可以看到除了镜像外还有k8s charts文件:
我们采取官方镜像:
Apache Kafka 支持通过环境变量覆盖一系列代理配置。环境变量必须以 KAFKA_ 开头,并且在代理配置中的任何点(.)应在相应的环境变量中用下划线(_)表示。例如,要设置主题的默认分区数 num.partitions,需要设置环境变量 KAFKA_NUM_PARTITIONS。
例如,要在 KRaft 结合模式下运行 Kafka(意味着处理客户端请求的代理和处理集群协调的控制器都运行在同一容器中),并且将默认的主题分区数设置为 3,而不是默认的 1,我们需要指定 KAFKA_NUM_PARTITIONS,并添加其他必需的配置:
docker run -d \--name broker \-e KAFKA_NODE_ID=1 \-e KAFKA_PROCESS_ROLES=broker,controller \-e KAFKA_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \-e KAFKA_CONTROLLER_LISTENER_NAMES=CONTROLLER \-e KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT \-e KAFKA_CONTROLLER_QUORUM_VOTERS=1@localhost:9093 \-e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 \-e KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1 \-e KAFKA_TRANSACTION_STATE_LOG_MIN_ISR=1 \-e KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS=0 \-e KAFKA_NUM_PARTITIONS=3 \apache/kafka:latest
在命令行中指定这么多环境变量会变得很麻烦。更简单的方法是使用 Docker Compose 来指定和管理 Kafka 容器。
services:broker:image: apache/kafka:latestcontainer_name: brokerenvironment:KAFKA_NODE_ID: 1KAFKA_PROCESS_ROLES: broker,controllerKAFKA_LISTENERS: PLAINTEXT://:9092,CONTROLLER://:9093KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://10.128.145.159:9092KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLERKAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXTKAFKA_CONTROLLER_QUORUM_VOTERS: 1@localhost:9093KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0KAFKA_NUM_PARTITIONS: 3ports:- 9092:9092networks:- kafka-netnetworks:kafka-net:driver: bridge
启动docker:
docker-compose down
docker-compose up -d
进入镜像并初始化:
docker exec --workdir /opt/kafka/bin/ -it broker sh
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic mytest
开启一个生产者:
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic mytest
验证是否可以收到信息:
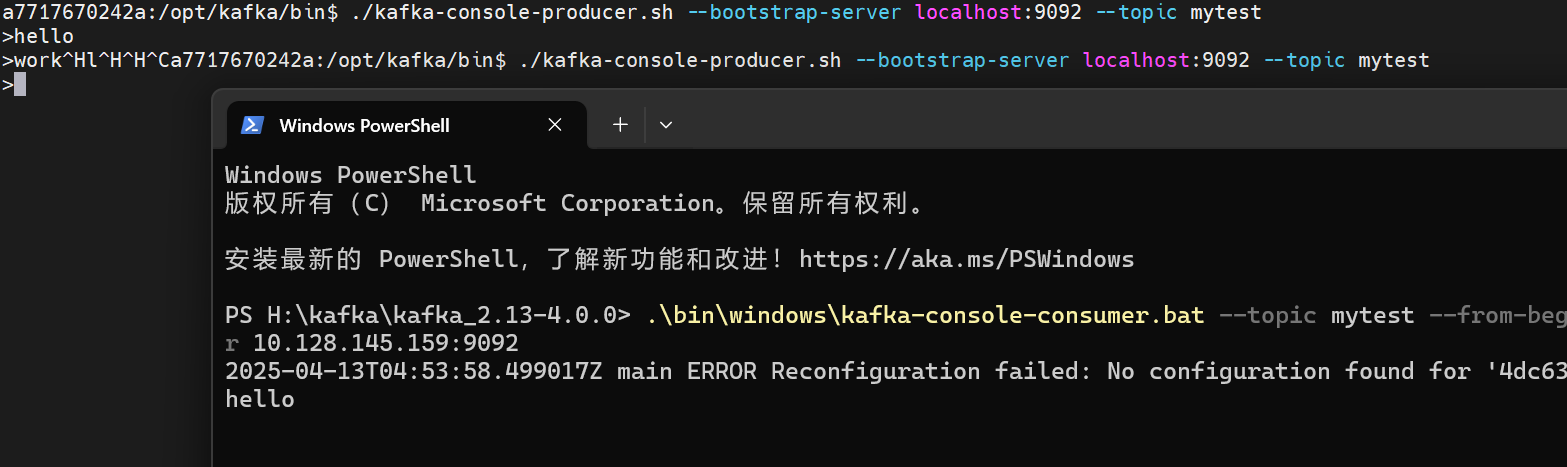
然后我们以go高级api为例:
package mainimport ("context""github.com/segmentio/kafka-go""log"
)var (brokers = []string{"10.128.145.159:9092",}groupId = "generalzy"topic = "mytest"
)func main() {// 初始化一个 reader,指定 Kafka 地址、主题和消费者组reader := kafka.NewReader(kafka.ReaderConfig{Brokers: brokers,GroupID: groupId,Topic: topic,MinBytes: 10e3, // 10KBMaxBytes: 10e6, // 10MB})defer reader.Close()for {// 读取消息msg, err := reader.ReadMessage(context.Background())if err != nil {log.Fatal("failed to read message:", err)}log.Printf("Message at offset %d: %s = %s\n", msg.Offset, string(msg.Key), string(msg.Value))}
}
最后遗憾收场:
2025/04/13 13:04:05 failed to read message:fetching message: EOF
看样子kafka-go的协议暂未支持kafka4.0。
配置参考
https://kafka.apache.org/documentation.html#brokerconfigs

)




