
异常值(Outlier)全面指南 —— 检测、分析与处理
作者:Chris Albon(图源) 场景:数据清洗与特征工程必备技能
一、什么是异常值(Outlier)
定义
异常值(Outlier)是指那些在数据集中远离其他观测值的点,通常与数据的整体趋势明显不同,可能源于错误、噪声、特殊事件或极端情况。
二、异常值的影响与处理原则
| 处理原则 | 说明 | 优缺点 |
|---|---|---|
| Drop(删除) | 删除异常值 | 简单粗暴,易丢失重要信息 |
| Mark(标记) | 给异常值打标识 | 保留信息,利于后续分析 |
| Rescale(调整) | 对异常值做缩放或替代 | 数据完整性好,降低干扰 |
三、异常值检测方法(含公式)
1. 基于统计特征的检测
1.1 标准差法(Z-Score)
公式:
-
μ:均值
-
σ:标准差
-
判断条件:|Z| > 3 视为异常值
1.2 四分位距法(IQR)
公式:
判断条件:
X < Q1 − 1.5 × IQR 或 X > Q3 + 1.5 × IQR
2. 基于模型的检测
| 方法 | 说明 | 适用场景 |
|---|---|---|
| Isolation Forest | 随机切分 | 大数据集 |
| One-Class SVM | 边界学习 | 非线性数据 |
| DBSCAN | 密度聚类 | 空间型数据 |
| LOF | 局部离群因子 | 局部异常 |
四、异常值处理三种方式(Drop / Mark / Rescale)
1. Drop(删除)
示意图:
原始数据:[1, 2, 3, 1000, 4, 5]
删除异常值:[1, 2, 3, 4, 5]
代码示例(IQR法):
import pandas as pddf = pd.DataFrame({'value': [1, 2, 3, 1000, 4, 5]})Q1 = df['value'].quantile(0.25)
Q3 = df['value'].quantile(0.75)
IQR = Q3 - Q1df_clean = df[~((df['value'] < (Q1 - 1.5 * IQR)) | (df['value'] > (Q3 + 1.5 * IQR)))]
print(df_clean)
运行结果
value
0 1
1 2
2 3
4 4
5 52. Mark(打标)
示意图:
原始数据:[1, 2, 3, 1000, 4, 5]
标记数据:[1, 2, 3, 1000(异常), 4, 5]
代码示例(Z-Score法):
from scipy import stats
import numpy as np
import pandas as pddf = pd.DataFrame({'value': [1, 2, 3, 1000, 4, 5]})df['outlier'] = np.where(np.abs(stats.zscore(df['value'])) > 3, 1, 0)
print(df)
运行结果
value outlier
0 1 0
1 2 0
2 3 0
3 1000 0
4 4 0
5 5 0
3. Rescale(调整)
常见处理方式:
-
Winsorizing(极值化)
-
Log / sqrt 变换
-
Cap(上下限)
代码示例(上下限限制):
import pandas as pddf = pd.DataFrame({'value': [1, 2, 3, 1000, 4, 5]})Q1 = df['value'].quantile(0.25)
Q3 = df['value'].quantile(0.75)IQR = Q3 - Q1upper_limit = Q3 + 1.5 * IQR
lower_limit = Q1 - 1.5 * IQRdf['value'] = df['value'].clip(lower=lower_limit, upper=upper_limit)
print(df)
运行结果
value
0 1.0
1 2.0
2 3.0
3 8.5
4 4.0
5 5.0
五、不同策略的适用场景对比
| 策略 | 适合情况 | 优缺点 |
|---|---|---|
| Drop | 异常点确实是错误值 | 丢失数据 |
| Mark | 不确定是否干扰模型 | 数据保留 |
| Rescale | 保留所有数据 | 需要谨慎使用 |
六、完整案例演示(含可视化)
绘制数据分布
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pddf = pd.DataFrame({'value': [1, 2, 3, 1000, 4, 5]})sns.boxplot(x=df['value'])
plt.show()
运行结果
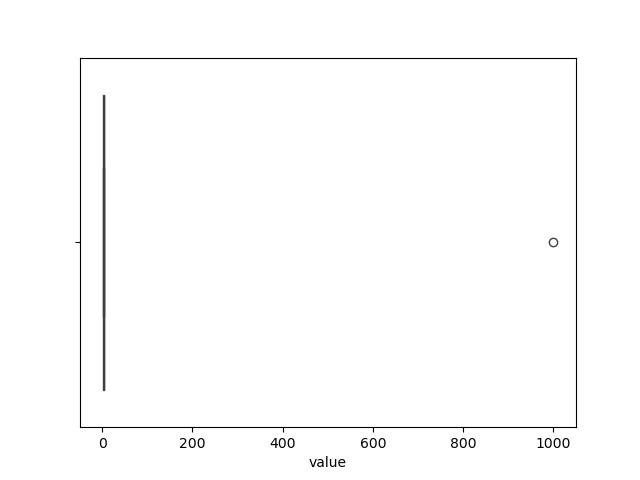
使用Isolation Forest检测异常值
from sklearn.ensemble import IsolationForest
import pandas as pddf = pd.DataFrame({'value': [1, 2, 3, 1000, 4, 5]})
iso = IsolationForest(contamination=0.1)
df['outlier'] = iso.fit_predict(df[['value']])
print(df)
运行结果
value outlier
0 1 1
1 2 1
2 3 1
3 1000 -1
4 4 1
5 5 1
七、总结
| 核心观点 | 说明 |
|---|---|
| 异常值检测 | 重要的特征工程步骤 |
| 三大处理策略 | Drop / Mark / Rescale 各有适用 |
| 推荐顺序 | 先检测 → 再判断 → 再处理 |
八、参考图示(构思)
异常值处理策略关系图
检测|-----------------| | |Drop Mark Rescale| | |丢弃数据 标记分析 调整保留


)



