
目录
1. 图的概念
2. 图的术语
3. 图的存储结构
邻接矩阵
邻接表
4. 图的遍历
深度优先遍历(DFS)
广度优先遍历(BFS)
5. 生成树和最小生成树(Prim/Kruskal)
普里姆算法(加点法)
克鲁斯卡尔算法(加边法)
6. 最短路径
Dijkstra算法
Floyd算法
1. 图的概念
● 图的定义:图G(Graph)由两个集合V(Vertex)和E(Edge)组成,记为G=(V,E)。
V是顶点的有限集合,记为V(G)。
E是连接V中两个不同顶点(顶点对)的边的有限集合,记为E(G)。
2. 图的术语
● 无向图:无向边用圆括号括起来,例如(i, j)表示一条无向边。称i, j互为邻接点。
● 有向图:有向图用尖括号括起来,例如<i, j>表示一条有向边。称i为起点,j为终点。并称j是i的出边邻接点,i是j的入边邻接点。
● 图中的逻辑关系表现为邻接
● 无向图中,顶点所关联的边的数目称为该顶点的度
● 有向图中,以顶点i为终点的入边的数目,称为该顶点的入度
以顶点i为起点的出边的数目,称为该顶点的出度。
● 所有顶点的度的和 = 边数x2 (对无向图有向图都成立)
● n个顶点的完全无向图中有n(n-1)/2条边
n个顶点的完全有向图中有n(n-1)条边
● 当一个图接近完全图时,称为稠密图
当一个图含有较少的边数时,称为稀疏图
● 子图:点集和边集都被包含
● 路径:从顶点i到顶点j的一条路径是一个顶点序列
● 路径长度:一条路径上经过的边的数目
● 简单路径:一条路径除起点和终点可以相同外,其余顶点均不相同
● 回路/环:一条路径起点和终点相同
● 简单回路/简单环:起点和终点相同的简单路径
● 连通:若顶点i到顶点j有路径,则i和j连通
● 无向图:
若图中任意两个顶点都连通,称为连通图,否则称为非连通图
无向图中的极大连通子图称为连通分量
● 有向图:
若图中任意两个顶点都连通,称为强连通图
有向图中极大强连通子图称为强连通分量
● 权:与边相关的数值
● 带权图/网:边上带权的图
3. 图的存储结构
邻接矩阵
1. 如果G是不带权图,则:

2. 如果G是带权图,则:

邻接矩阵的特点:
- 邻接矩阵适合存储稠密图
- 确定任意两个顶点之间是否有边相连的时间为O(1)
- 无向图的邻接矩阵对称。
- 对于无向图,邻接矩阵的第i行(或第i列)的非零非∞元素的个数就是顶点i的度。
- 对于有向图,邻接矩阵的第i行非零非∞元素的个数是顶点i的出度。
- 邻接矩阵的第i列非零非∞元素的个数是顶点i的入度。
邻接表
将每个顶点的所有出边构成一个列表

对于边数目较少的稀疏图,邻接表比邻接矩阵要节省空间。
邻接表的特点:
- 邻接表不唯一(每个顶点出边列表中次序任意)
- 对于稀疏图,邻接表比邻接矩阵更节省空间
- 对于无向图,顶点i对应的单链表的边结点数是顶点i的度
- 对于有向图,顶点i对应的单链表的边结点个数是顶点i的出度。
- 确定任意两个顶点间是否有边相连的时间为O(m) m为最大顶点出度
逆邻接表:存储每个顶点的入边,不存储出边
4. 图的遍历
将图中的顶点按任意顺序排列起来,编号最小的顶点为起始点
- 为了避免同一个顶点被重复访问,必须记住访问过的顶点。为此,可设置一个访问标志数组visited,初始时所有元素置为0,当顶点i访问过时,该数组元素visited[i]置为1。
- 根据遍历方式的不同,图的遍历方法有两种:
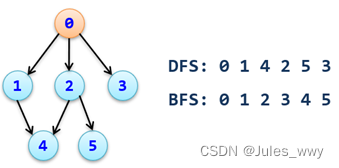
深度优先遍历(DFS)
- 从图中某个起始点v出发进行深度优先搜索—DFS(v) ,首先访问初始顶点v。
- 然后选择一个与顶点v邻接且没被访问过的顶点w为初始顶点,再从w出发进行深度优先搜索—DFS(w),直到图中与当前顶点v邻接的所有顶点都被访问过为止。
广度优先遍历(BFS)
- 首先访问起始点v。
- 接着访问顶点v的所有未被访问过的邻接点v1、v2、…、vt。
- 然后再按照v1、v2、…、vt的次序,访问每一个顶点的所有未被访问过的邻接点。
- 依次类推,直到图中所有和初始点v有路径相通的顶点或者图中所有已访问顶点的邻接点都被访问过为止。
- 相邻顶点:先访问先处理——队列
5. 生成树和最小生成树(Prim/Kruskal)
● 连通图的生成树是包含全部顶点的一个极小连通子图。(含有n个顶点n-1条边,多一条边则构成回路,少一条边则不连通)
● 由深度优先遍历得到的生成树称为深度优先生成树。
由广度优先遍历得到的生成树称为广度优先生成树。
无论哪种生成树,都是由相应遍历中首次搜索的边构成的。


● 连通图:仅需调用遍历过程(DFS或BFS)一次,从图中任一顶点出发,便可以遍历图中的各个顶点。遍历中搜索边<v,w>时,若顶点w首次访问(该边也是首次搜索到),则该边是一条树边,所有树边构成一棵生成树。
● 非连通图:需对每个连通分量调用一次遍历过程,所有连通分量对应的生成树构成整个非连通图的生成森林。
● 生成树的代价:在无向连通网中,生成树上各边的权值之和
● 最小生成树:在无向连通网中,代价最小的生成树
推荐视频:【最小生成树(Kruskal(克鲁斯卡尔)和Prim(普里姆))算法动画演示】 https://www.bilibili.com/video/BV1Eb41177d1/
普里姆算法(加点法)
普里姆(Prim)算法是一种构造性算法。
每次选择已选顶点集合和未选顶点集合连接边中权值最小的边。
Prim算法时间复杂度为O(n2),n为图的顶点数
Prim特别适合于稠密图求最小生成树
克鲁斯卡尔算法(加边法)
在n个顶点的图中,将所有边的权值从小到大排序,每次取权值最小的边,加边后判断是否形成回路,如果形成回路就丢弃这条边并继续。直到图中包含n-1条边停止。
克鲁斯卡尔算法由于与n无关,所以克鲁斯卡尔算法特别适合于稀疏图求最小生成树。
6. 最短路径
采用广度优先遍历可以求最短路径
对于非带权图,最短路径就是边数最少的。对于带权图,最短路径就是边上权值之和最小的。
Dijkstra算法
求图中某一顶点到其余顶点的最短路径(称为单源最短路径)
推荐视频:https://www.youtube.com/watch?v=bZkzH5x0SKU
按路径长度递增的次序产生最短路径的算法。
Dijkstra算法不适合含负权的图求最短路
步骤:
1. 初始化4个数组
visited_nodes:[] //初始为空
unvisited_nodes:[A,B,C,D,…] //图中所有结点
shortest_distance:[0,∞,∞,∞,…] //除了起点设为0,其余都是无穷
previous_node:[-1,-1,-1,-1,…] //全部设置为-1,或全为空None
2. 从起点开始遍历
每次遍历步骤:
- 将该点i从unvisited_nodes中删除,加入visited_nodes中
- 找出点i所有出边邻接点
- 计算到每个邻接点的距离:距离d = shortest distance[i] + 边<i,j>权值
- 如果距离d>=shortest_distance[j],则不更新数组
- 如果距离d<shortest_distance[j],就更新距离shortest_distance[j]=d
- 并更新previous_node[j] = i
直到unvisited_nodes数组为空,停止遍历
就得到了完整的shortest_distance和previous_node
3. 得到结果
- 从起点到点j的最短长度为shortest_distance[j]
- 从起点到点j最短路径,从previous_nodes[j]开始找,通过回溯找到先前的每一个结点,连起来就是路径。
例子:

Floyd算法
求图中每一对顶点之间的最短路径(称为多源最短路径)
步骤:
1. 初始化两个矩阵
A矩阵用于存储最短路径长度值。

path用来存储路径

2. 考虑每一个结点k
k行和k列及主对角线不用比较,保持原值
如果A[i][j] > A[i][k] + A[k][j]
更新A[i][j] = A[i][k] + A[k][j]
path[i][j] = 路径到j的前一结点(不一定是k)
3. 所有结点考虑完后得到的A和path就是结果
A[i][j]就是i到j的最短长度
最短路径用回溯法,例如path[i][j]=k, path[i][k]=w, path[i][w]=i,则路径为iwkj
例子:



)

)



