首先,先搞一个模板代码,方便后面的操作
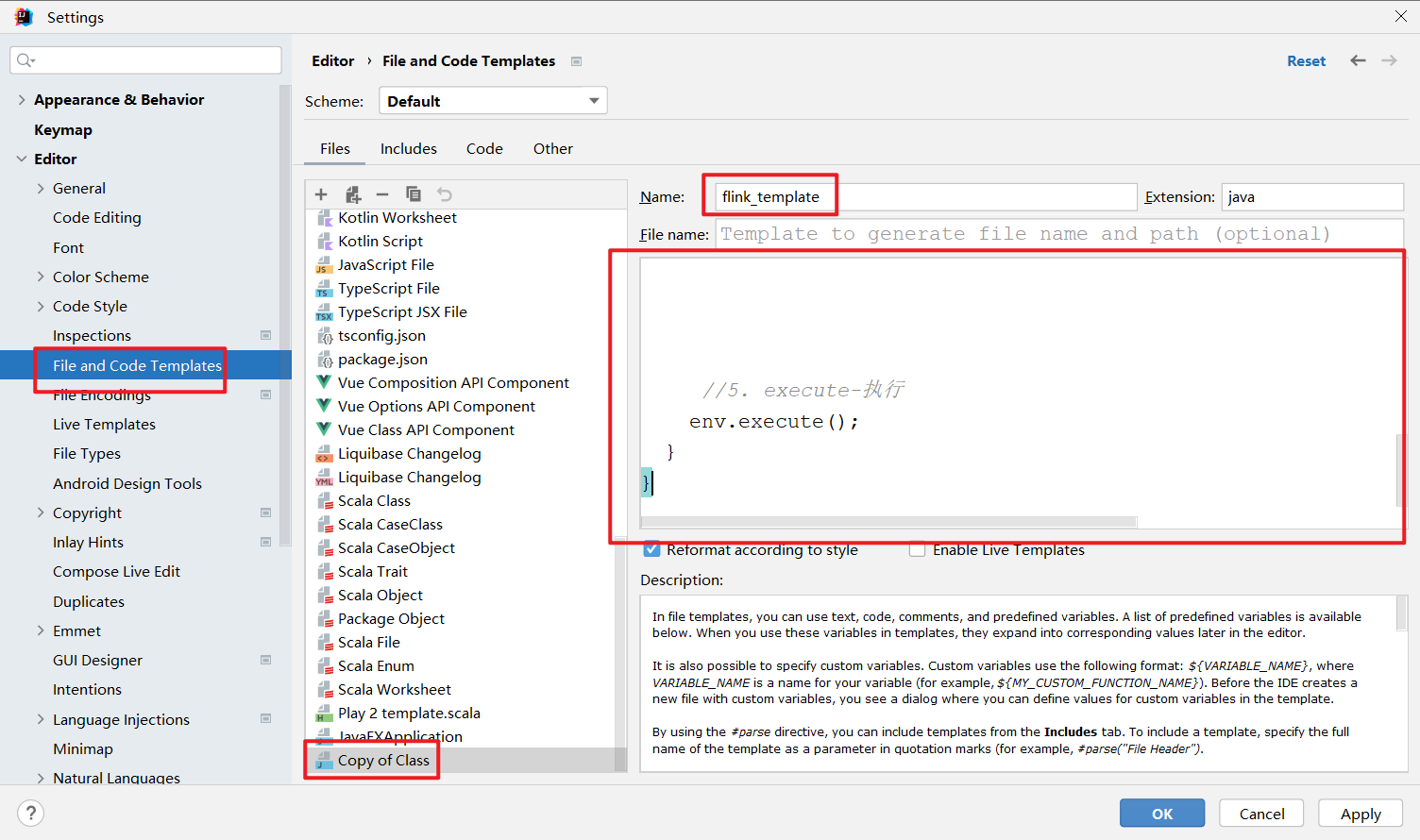
#if (${PACKAGE_NAME} && ${PACKAGE_NAME} != "")package ${PACKAGE_NAME};#end
#parse("File Header.java")
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**@基本功能:@program:${PROJECT_NAME}@author: 闫哥@create:${YEAR}-${MONTH}-${DAY} ${HOUR}:${MINUTE}:${SECOND}
**/
public class ${NAME} {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}map算子的使用
假如有如下数据:
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css将其转换为一个LogBean对象,并输出。
提示:读取本地文件,使用如下方式
DataStream<String> lines = env.readTextFile("./data/input/flatmap.log");
字段名可以定义为:
String ip; // 访问ipint userId; // 用户idlong timestamp; // 访问时间戳String method; // 访问方法String path; // 访问路径假如需要用到日期工具类,可以导入lang3包
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.12.0</version>
</dependency>package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.time.DateUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.text.SimpleDateFormat;
import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 09:10:30**/public class MapDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class LogBean{String ip; // 访问ipint userId; // 用户idlong timestamp; // 访问时间戳String method; // 访问方法String path; // 访问路径}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\a.log");//3. transformation-数据处理转换// 此处也可以将数据放入到tuple中,tuple可以支持到tuple25DataStream<LogBean> mapStream = fileStream.map(new MapFunction<String, LogBean>() {@Overridepublic LogBean map(String line) throws Exception {String[] arr = line.split(" ");String ip = arr[0];int userId = Integer.valueOf(arr[1]);String createTime = arr[2];// 如何将一个时间字符串变为时间戳// 17/05/2015:10:05:30/*SimpleDateFormat simpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");Date date = simpleDateFormat.parse(createTime);long timeStamp = date.getTime();*/// 要想使用这个common.lang3 下的工具类,需要导入包Date date = DateUtils.parseDate(createTime, "dd/MM/yyyy:HH:mm:ss");long timeStamp = date.getTime();String method = arr[3];String path = arr[4];LogBean logBean = new LogBean(ip, userId, timeStamp, method, path);return logBean;}});//4. sink-数据输出mapStream.print();//5. execute-执行env.execute();}
}第二个版本:
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.text.SimpleDateFormat;
import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 11:40:37**/
@Data
@AllArgsConstructor
class LogBean{private String ip; // 访问ipprivate int userId; // 用户idprivate long timestamp; // 访问时间戳private String method; // 访问方法private String path; // 访问路径
}
public class Demo04 {// 将数据转换为javaBeanpublic static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.readTextFile("datas/a.log");//3. transformation-数据处理转换SingleOutputStreamOperator<LogBean> map = streamSource.map(new MapFunction<String, LogBean>() {@Overridepublic LogBean map(String line) throws Exception {String[] arr = line.split("\\s+");//时间戳转换 17/05/2015:10:06:53String time = arr[2];SimpleDateFormat format = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");Date date = format.parse(time);long timeStamp = date.getTime();return new LogBean(arr[0],Integer.parseInt(arr[1]),timeStamp,arr[3],arr[4]);}});//4. sink-数据输出map.print();//5. execute-执行env.execute();}
}FlatMap算子的使用练习
将DataStream中的每一个元素转换为0...n个元素
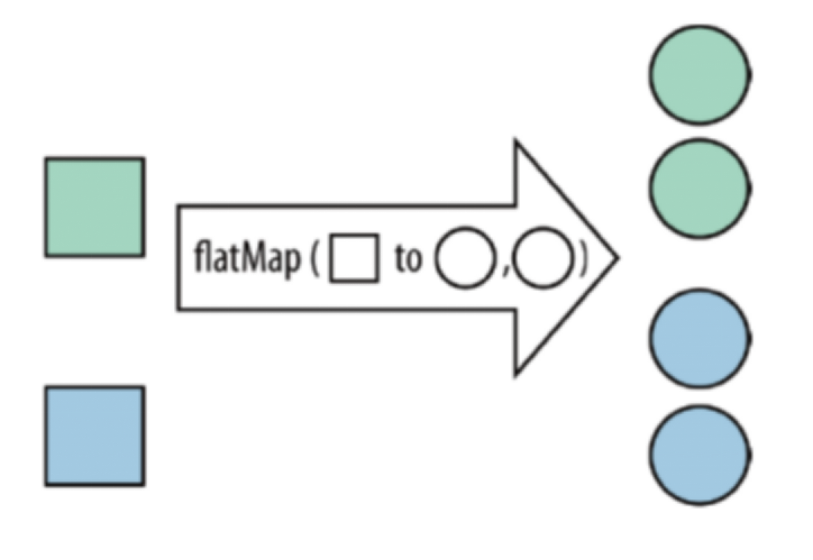
读取flatmap.log文件中的数据
如:
| 张三,苹果手机,联想电脑,华为平板 |
转换为
| 张三有苹果手机 张三有联想电脑 张三有华为平板 李四有… … … |
代码演示:
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 09:51:59**/
public class FlatMapDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\flatmap.log");//3. transformation-数据处理转换DataStream<String> flatMapStream = fileStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {//张三,苹果手机,联想电脑,华为平板String[] arr = line.split(",");String name = arr[0];for (int i = 1; i < arr.length; i++) {String goods = arr[i];collector.collect(name+"有"+goods);}}});//4. sink-数据输出flatMapStream.print();//5. execute-执行env.execute();}
}Filter的使用
读取第一题中 a.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.time.DateUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 09:10:30**/public class FilterDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class LogBean{String ip; // 访问ipint userId; // 用户idlong timestamp; // 访问时间戳String method; // 访问方法String path; // 访问路径}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\a.log");//3. transformation-数据处理转换// 读取第一题中 a.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志DataStream<String> filterStream = fileStream.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String line) throws Exception {String ip = line.split(" ")[0];return ip.equals("83.149.9.216");}});//4. sink-数据输出filterStream.print();//5. execute-执行env.execute();}
}随堂代码:
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.core.fs.FileSystem;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.text.SimpleDateFormat;
import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 11:40:37**/public class Demo06 {// 将数据转换为javaBeanpublic static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.readTextFile("datas/a.log");//3. transformation-数据处理转换//读取第一题中 a.log文件中的访问日志数据,过滤出来以下访问IP是83.149.9.216的访问日志streamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String line) throws Exception {String[] arr = line.split(" ");String ip = arr[0];return ip.equals("83.149.9.216");}}).writeAsText("datas/b.log", FileSystem.WriteMode.OVERWRITE).setParallelism(1);//4. sink-数据输出//5. execute-执行env.execute();}
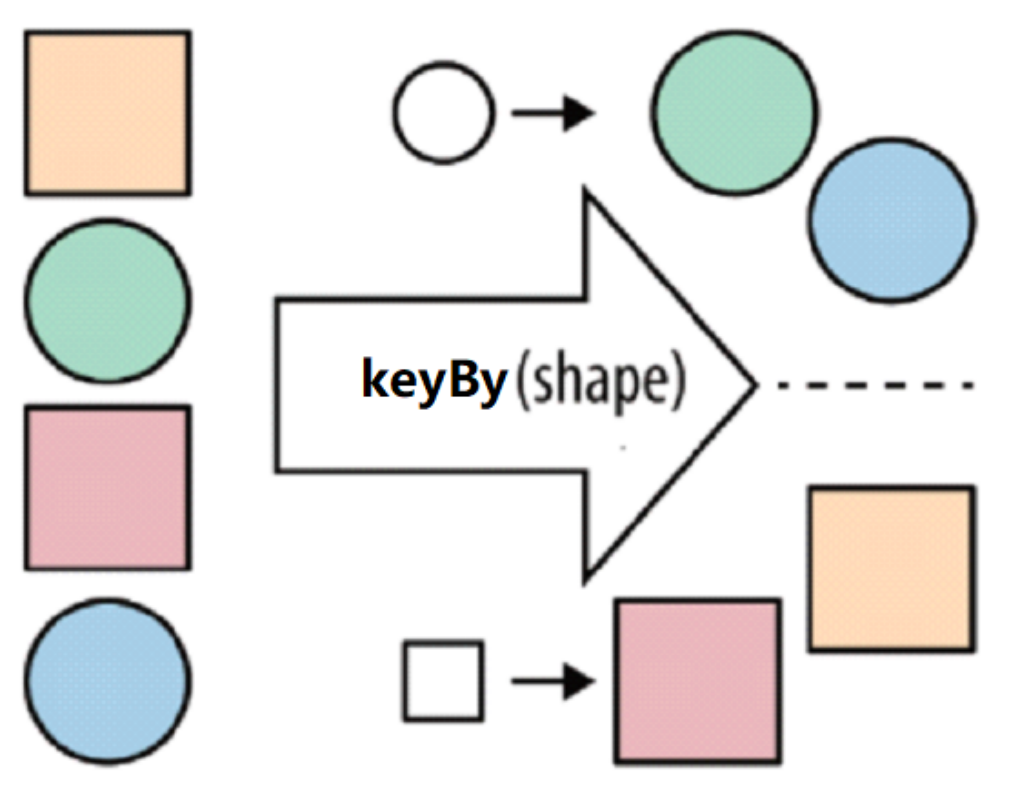
}KeyBy
流处理中没有groupBy,而是keyBy
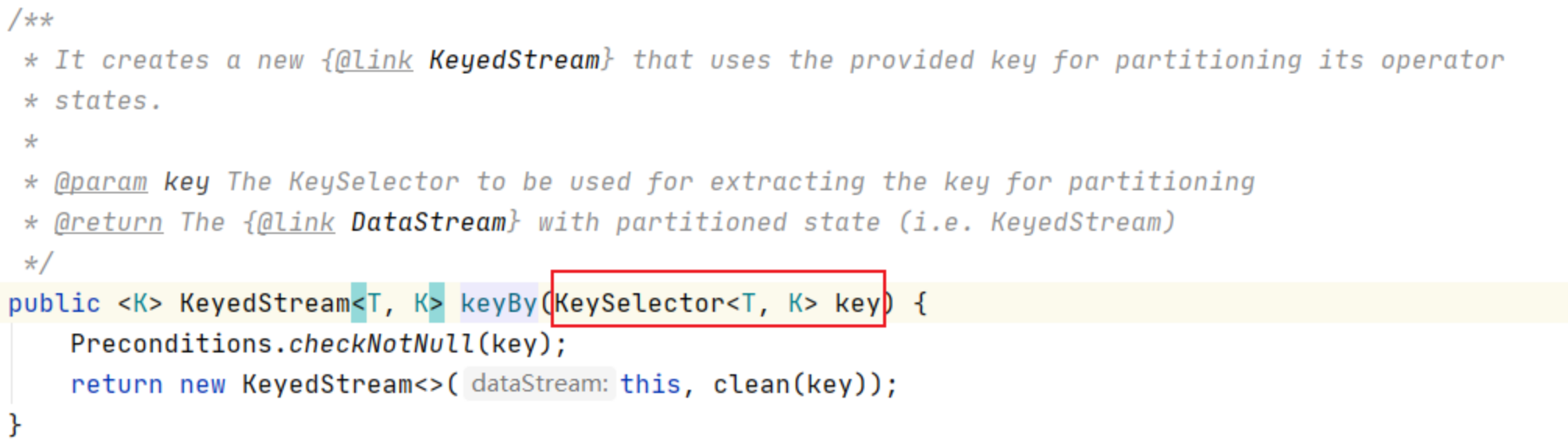
KeySelector对象可以支持元组类型,也可以支持POJO[Entry、JavaBean]
元组类型
单个字段keyBy
//用字段位置(已经被废弃)
wordAndOne.keyBy(0)//用字段表达式
wordAndOne.keyBy(v -> v.f0)多个字段keyBy
//用字段位置
wordAndOne.keyBy(0, 1);//用KeySelector
wordAndOne.keyBy(new KeySelector<Tuple2<String, Integer>, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> getKey(Tuple2<String, Integer> value) throws Exception {return Tuple2.of(value.f0, value.f1);}
});类似于sql中的group by
select sex,count(1) from student group by sex;
group by 后面也可以跟多个字段进行分组,同样 keyBy 也支持使用多个列进行分组POJO
public class PeopleCount {private String province;private String city;private Integer counts;public PeopleCount() {}//省略其他代码。。。
}单个字段keyBy
source.keyBy(a -> a.getProvince());多个字段keyBy
source.keyBy(new KeySelector<PeopleCount, Tuple2<String, String>>() {@Overridepublic Tuple2<String, String> getKey(PeopleCount value) throws Exception {return Tuple2.of(value.getProvince(), value.getCity());}
});练习:
假如有如下数据:
env.fromElements(Tuple2.of("篮球", 1),Tuple2.of("篮球", 2),Tuple2.of("篮球", 3),Tuple2.of("足球", 3),Tuple2.of("足球", 2),Tuple2.of("足球", 3));
求:篮球多少个,足球多少个?package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 10:07:05**/
public class KeyByDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<Tuple2<String,Integer>> dataStream = env.fromElements(Tuple2.of("篮球", 1),Tuple2.of("篮球", 2),Tuple2.of("篮球", 3),Tuple2.of("足球", 3),Tuple2.of("足球", 2),Tuple2.of("足球", 3));//3. transformation-数据处理转换/*KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> tuple2) throws Exception {return tuple2.f0;}});*/KeyedStream<Tuple2<String, Integer>, String> keyedStream = dataStream.keyBy(tuple -> tuple.f0);keyedStream.sum(1).print();//4. sink-数据输出//5. execute-执行env.execute();}
}package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 14:32:52**/
public class Demo07 {@Data@AllArgsConstructorstatic class Ball{private String ballName;private int num;}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出DataStreamSource<Tuple2<String, Integer>> tuple2DataStreamSource = env.fromElements(Tuple2.of("篮球", 1),Tuple2.of("篮球", 2),Tuple2.of("篮球", 3),Tuple2.of("足球", 3),Tuple2.of("足球", 2),Tuple2.of("足球", 3));// 这个写法已经废弃,0 代表的是按照元组的第一个元素进行分组,相同的组进入到相同的编号中KeyedStream<Tuple2<String, Integer>, Tuple> tuple2TupleKeyedStream = tuple2DataStreamSource.keyBy(0);tuple2TupleKeyedStream.print();// 这个写法是目前提倡的写法// 使用了lambda表达式,因为这个算子后面不需要写returns 所以看着比较简介tuple2DataStreamSource.keyBy(v -> v.f0).print();// 这个是原始写法,没有简化tuple2DataStreamSource.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});// 以上的写法是针对数据是二元组的格式,以下演示数据是pojoDataStreamSource<Ball> ballSource = env.fromElements(new Ball("篮球", 1),new Ball("篮球", 2),new Ball("篮球", 3),new Ball("足球", 3),new Ball("足球", 2),new Ball("足球", 3));ballSource.keyBy(ball -> ball.getBallName()).print();ballSource.keyBy(new KeySelector<Ball, String>() {@Overridepublic String getKey(Ball ball) throws Exception {return ball.getBallName();}});//5. execute-执行env.execute();}
}假如遇到如下错误:
Exception in thread "main" org.apache.flink.api.common.typeutils.CompositeType$InvalidFieldReferenceException: Cannot reference field by field expression on GenericType<com.bigdata.transformation.Ball>Field expressions are only supported on POJO types, tuples, and case classes. (See the Flink documentation on what is considered a POJO.)解决方案:
将实体类,不要写在一个.java 文件的里面,单独写成一个文件,并使用 public 修饰即可。
Reduce --sum的底层是reduce
可以对一个dataset 或者一个 group 来进行聚合计算,最终聚合成一个元素
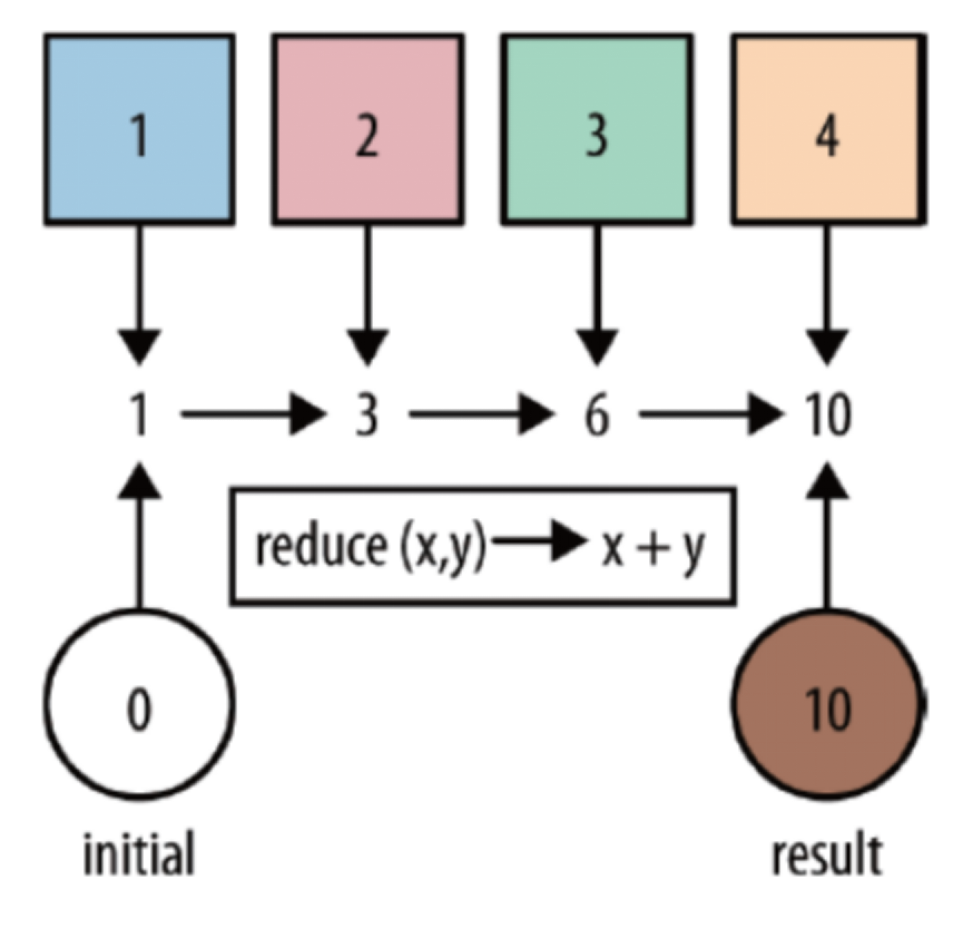
读取a.log日志,统计ip地址访问pv数量,使用reduce 操作聚合成一个最终结果
结果类似:
(86.149.9.216,1)
(10.0.0.1,7)
(83.149.9.216,6)
package com.bigdata.day03;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.lang3.time.DateUtils;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 09:10:30**/public class ReduceDemo {@Data@AllArgsConstructor@NoArgsConstructorstatic class LogBean{String ip; // 访问ipint userId; // 用户idlong timestamp; // 访问时间戳String method; // 访问方法String path; // 访问路径}public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> fileStream = env.readTextFile("F:\\BD230801\\FlinkDemo\\datas\\a.log");//3. transformation-数据处理转换// 此处也可以将数据放入到tuple中,tuple可以支持到tuple25DataStream<LogBean> mapStream = fileStream.map(new MapFunction<String, LogBean>() {@Overridepublic LogBean map(String line) throws Exception {String[] arr = line.split(" ");String ip = arr[0];int userId = Integer.valueOf(arr[1]);String createTime = arr[2];// 如何将一个时间字符串变为时间戳// 17/05/2015:10:05:30/*SimpleDateFormat simpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");Date date = simpleDateFormat.parse(createTime);long timeStamp = date.getTime();*/// 要想使用这个common.lang3 下的工具类,需要导入包Date date = DateUtils.parseDate(createTime, "dd/MM/yyyy:HH:mm:ss");long timeStamp = date.getTime();String method = arr[3];String path = arr[4];LogBean logBean = new LogBean(ip, userId, timeStamp, method, path);return logBean;}});DataStream<Tuple2<String, Integer>> mapStream2 = mapStream.map(new MapFunction<LogBean, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(LogBean logBean) throws Exception {return Tuple2.of(logBean.getIp(), 1);}});//4. sink-数据输出KeyedStream<Tuple2<String,Integer>, String> keyByStream = mapStream2.keyBy(tuple -> tuple.f0);// sum的底层是 reduce// keyByStream.sum(1).print();// [ ("10.0.0.1",1),("10.0.0.1",1),("10.0.0.1",1) ]keyByStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {// t1 => ("10.0.0.1",10)// t2 => ("10.0.0.1",1)return Tuple2.of(t1.f0, t1.f1 + t2.f1);}}).print();//5. execute-执行env.execute();}
}随堂笔记:
package com.bigdata.day02;import lombok.AllArgsConstructor;
import lombok.Data;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.text.SimpleDateFormat;
import java.util.Date;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 11:40:37**/public class Demo08 {// 将数据转换为javaBeanpublic static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> streamSource = env.readTextFile("datas/a.log");//3. transformation-数据处理转换KeyedStream<Tuple2<String, Integer>, String> keyBy = streamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {String[] arr = value.split(" ");return Tuple2.of(arr[0], 1);}}).keyBy(v -> v.f0);// 不使用reduce的情况,本质上sum的底层是agg,agg的底层是reduce//keyBy.sum(1).print();// 将相同的IP 已经放入到了同一个组中,接着就开始汇总了。keyBy.reduce(new ReduceFunction<Tuple2<String, Integer>>() {// 第一个v1 代表汇总过的二元组,第二个v2 ,代表 当前分组中的一个二元组@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> v1, Tuple2<String, Integer> v2) throws Exception {return Tuple2.of(v1.f0,v1.f1 + v2.f1);}}).print();// 简化版keyBy.reduce(( v1, v2) -> Tuple2.of(v1.f0,v1.f1 + v2.f1)).print();//5. execute-执行env.execute();}
}flatMap/map/filter/keyby/reduce综合练习
需求: 对流数据中的单词进行统计,排除敏感词TMD【腾讯美团滴滴】
此处用到了一个windows版本的软件 netcat,具体用法,先解压,然后在路径中输入cmd,来到黑窗口。
服务端的启动:
客户端就是双击 nc.exe 即可,里面无需写 nc 命令。
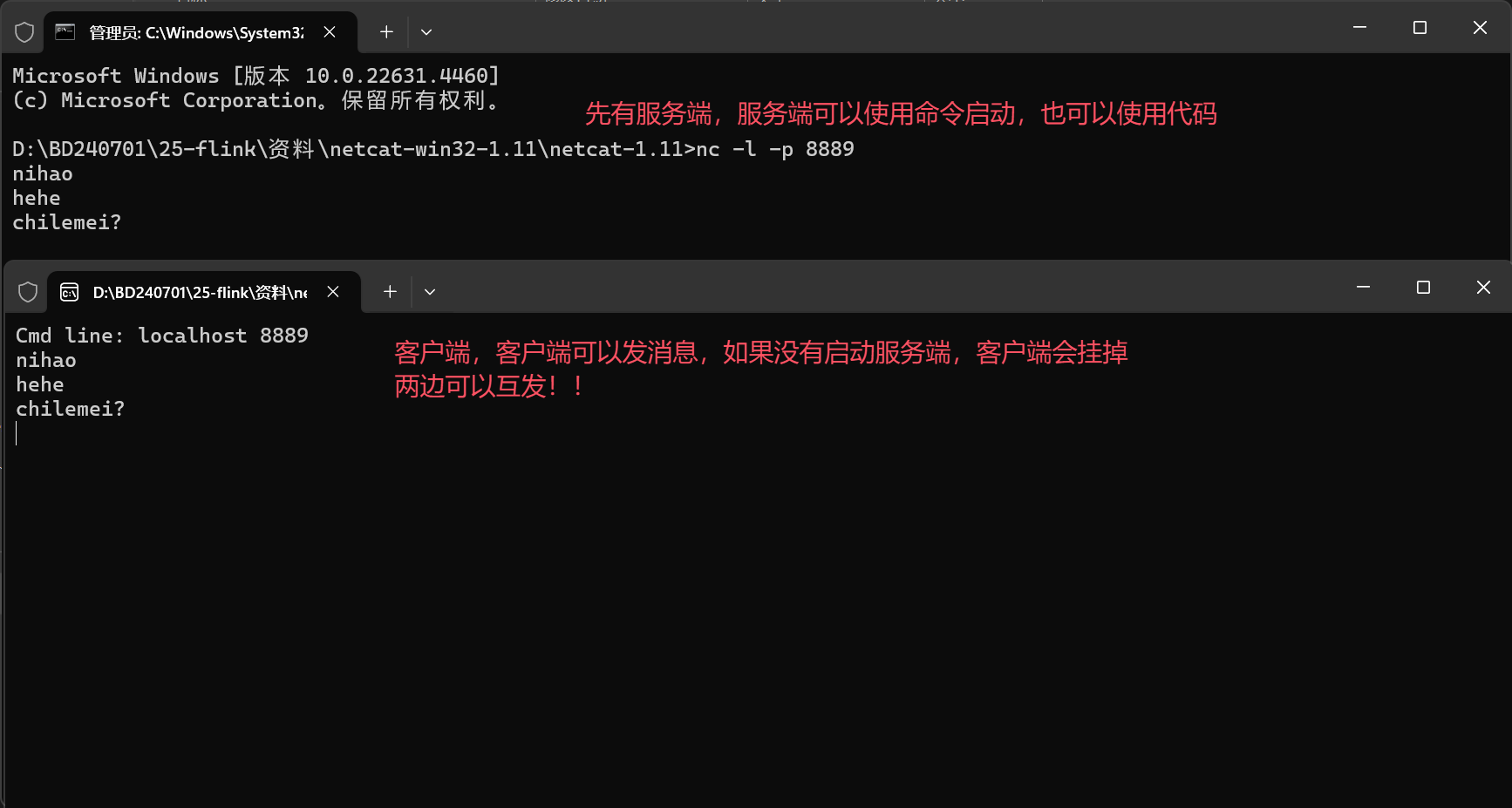
假如你想随时随地使用nc这个命令,需要配置环境变量。
官网地址:netcat 1.11 for Win32/Win64
Netcat介绍及安装使用_netcat安装-CSDN博客
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.planner.expressions.In;
import org.apache.flink.util.Collector;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 10:44:27**/
public class ZongHeDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStream<String> dataStreamSource = env.socketTextStream("localhost", 8889);dataStreamSource.filter(new FilterFunction<String>() {@Overridepublic boolean filter(String line) throws Exception {return !line.contains("TMD");}}).flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String line, Collector<String> collector) throws Exception {String[] arr = line.split(" ");for (String word : arr) {collector.collect(word);}}}).map(new MapFunction<String, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> map(String s) throws Exception {return Tuple2.of(s,1);}}).keyBy(v -> v.f0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> reduce(Tuple2<String, Integer> tuple2, Tuple2<String, Integer> t1) throws Exception {return Tuple2.of(tuple2.f0,tuple2.f1 + t1.f1);}}).print();//4. sink-数据输出//5. execute-执行env.execute();}
}随堂代码:
package com.bigdata.source;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.util.Collector;import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-11-22 09:54:28**/
class JdbcSource extends RichSourceFunction<String> {Connection connection;PreparedStatement statement;@Overridepublic void open(Configuration parameters) throws Exception {//使用jdbc//Class.forName("com.jdbc.cj.mysql.Driver");connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/zuoye", "root", "123456");statement = connection.prepareStatement("select word from fuck_words");}@Overridepublic void close() throws Exception {statement.close();connection.close();}@Overridepublic void run(SourceContext<String> ctx) throws Exception {ResultSet resultSet = statement.executeQuery();while(resultSet.next()){String word = resultSet.getString("word");ctx.collect(word);}}@Overridepublic void cancel() {}
}public class _07综合案例 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> dataStreamSource = env.socketTextStream("localhost", 8889);//3. transformation-数据处理转换DataStreamSource<String> jdbcSource = env.addSource(new JdbcSource());jdbcSource.print();ArrayList<String> words = new ArrayList<>();jdbcSource.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {words.add(value);return value;}}).print();// 此路不通,因为我们的代码不是顺序执行的,而且我们的算子还是并行运行的 words没有任何值,悬案!System.out.println(words);String[] arr = {"tmd","fuck"};// 此处的list 只能读取,不能修改和删除List<String> list = Arrays.asList(arr);dataStreamSource.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] arr = value.split("\\s+");for (String word : arr) {// 此处完全可以直接将 不要的单词过滤掉,也可以将来使用filter方法过滤out.collect(word);}}}).filter(new FilterFunction<String>() {@Overridepublic boolean filter(String value) throws Exception {return !list.contains(value);}}).map(new MapFunction<String, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String, Integer> map(String value) throws Exception {return new Tuple2<>(value,1);}}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}}).sum(1).print();//4. sink-数据输出//5. execute-执行env.execute();}
}union和connect-合并和连接
Union
union可以合并多个同类型的流
将多个DataStream 合并成一个DataStream
【注意】:union合并的DataStream的类型必须是一致的
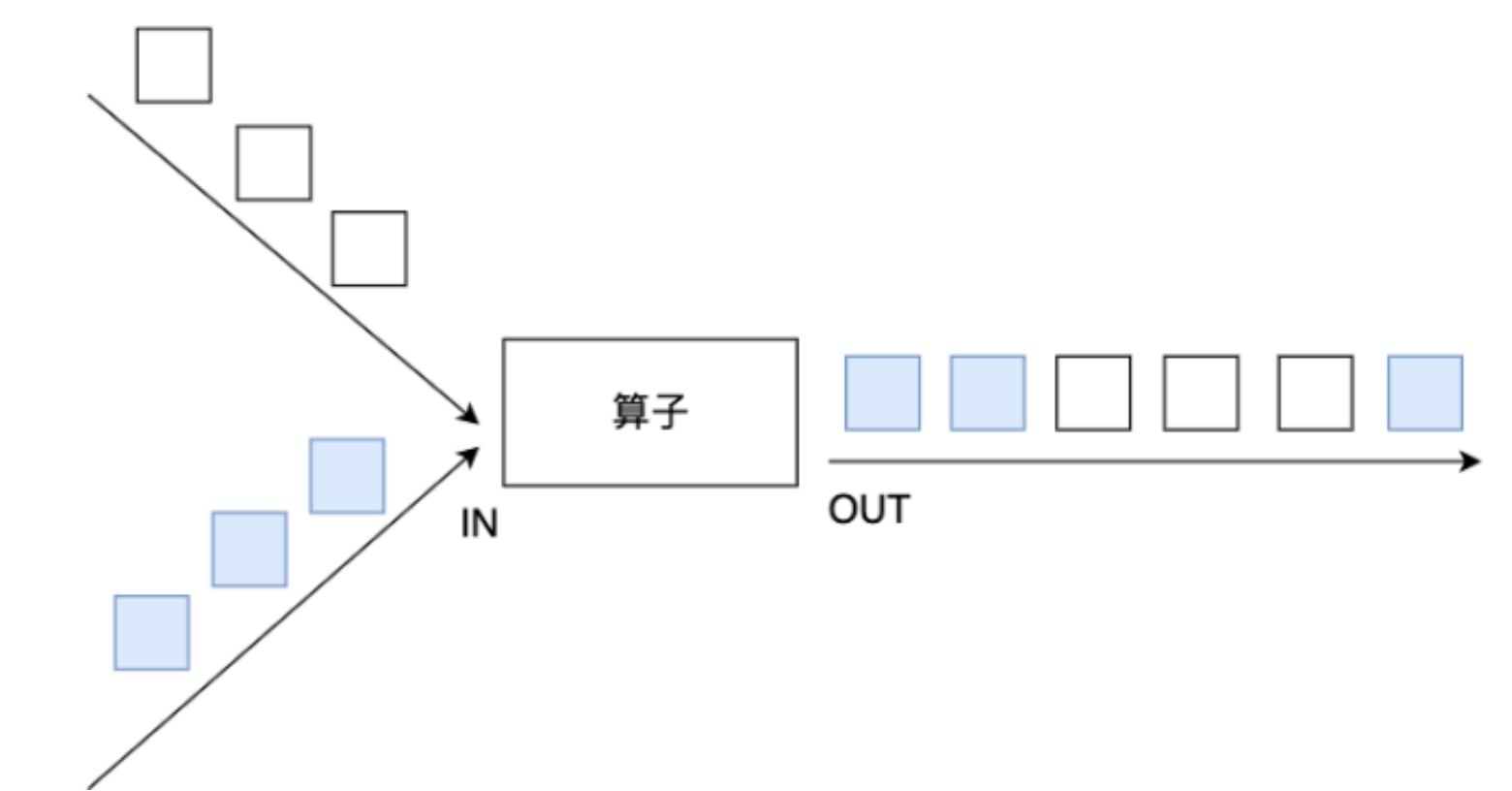
注意:union可以取并集,但是不会去重。
connect
connect可以连接2个不同类型的流(最后需要处理后再输出)
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化【一国两制】,两个流相互独立, 作为对比Union后是真的变成一个流了。
和union类似,但是connect只能连接两个流,两个流之间的数据类型可以不同,对两个流的数据可以分别应用不同的处理逻辑.
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 11:40:12**/
public class UnionConnectDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//2. source-加载数据DataStreamSource<String> stream1 = env.fromElements("hello", "nihao", "吃甘蔗的人");DataStreamSource<String> stream2 = env.fromElements("hello", "kong ni qi wa", "看电子书的人");DataStream<String> unionStream = stream1.union(stream2);unionStream.print();DataStream<Long> stream3 = env.fromSequence(1, 10);// stream1.union(stream3); 报错//3. transformation-数据处理转换ConnectedStreams<String, Long> connectStream = stream1.connect(stream3);// 此时你想使用这个流,需要各自重新处理// 处理完之后的数据类型必须相同DataStream<String> mapStream = connectStream.map(new CoMapFunction<String, Long, String>() {// string 类型的数据@Overridepublic String map1(String value) throws Exception {return value;}// 这个处理long 类型的数据@Overridepublic String map2(Long value) throws Exception {return Long.toString(value);}});//4. sink-数据输出mapStream.print();//5. execute-执行env.execute();}
}package com.bigdata.transforma;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.util.Collector;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-11-22 10:50:13**/
public class _08_两个流join {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);DataStreamSource<String> ds1 = env.fromElements("bigdata", "spark", "flink");DataStreamSource<String> ds2 = env.fromElements("python", "scala", "java");DataStream<String> ds3 = ds1.union(ds2);ds3.print();// 接着演示 connectDataStreamSource<Long> ds4 = env.fromSequence(1, 10);ConnectedStreams<String, Long> ds5 = ds1.connect(ds4);ds5.process(new CoProcessFunction<String, Long, String>() {@Overridepublic void processElement1(String value, CoProcessFunction<String, Long, String>.Context ctx, Collector<String> out) throws Exception {System.out.println("String流:"+value);out.collect(value);}@Overridepublic void processElement2(Long value, CoProcessFunction<String, Long, String>.Context ctx, Collector<String> out) throws Exception {System.out.println("Long流:"+value);out.collect(String.valueOf(value));}}).print("合并后的打印:");//2. source-加载数据//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}Side Outputs侧道输出(侧输出流) --可以分流
举例说明:对流中的数据按照奇数和偶数进行分流,并获取分流后的数据
package com.bigdata.day02;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-05-13 16:19:56**/
public class Demo11 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 侧道输出流DataStreamSource<Long> streamSource = env.fromSequence(0, 100);// 定义两个标签OutputTag<Long> tag_even = new OutputTag<Long>("偶数", TypeInformation.of(Long.class));OutputTag<Long> tag_odd = new OutputTag<Long>("奇数", TypeInformation.of(Long.class));//2. source-加载数据SingleOutputStreamOperator<Long> process = streamSource.process(new ProcessFunction<Long, Long>() {@Overridepublic void processElement(Long value, ProcessFunction<Long, Long>.Context ctx, Collector<Long> out) throws Exception {// value 代表每一个数据if (value % 2 == 0) {ctx.output(tag_even, value);} else {ctx.output(tag_odd, value);}}});// 从数据集中获取奇数的所有数据DataStream<Long> sideOutput = process.getSideOutput(tag_odd);sideOutput.print("奇数:");// 获取所有偶数数据DataStream<Long> sideOutput2 = process.getSideOutput(tag_even);sideOutput2.print("偶数:");//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}物理分区
Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置
1) Global Partitioner
该分区器会将所有的数据都发送到下游的某个算子实例(subtask id = 0)
2)Shuffle Partitioner
根据均匀分布随机划分元素
3) Broadcast Partitioner
发送到下游所有的算子实例,是将上游的所有数据,都给下游的每一个分区一份。
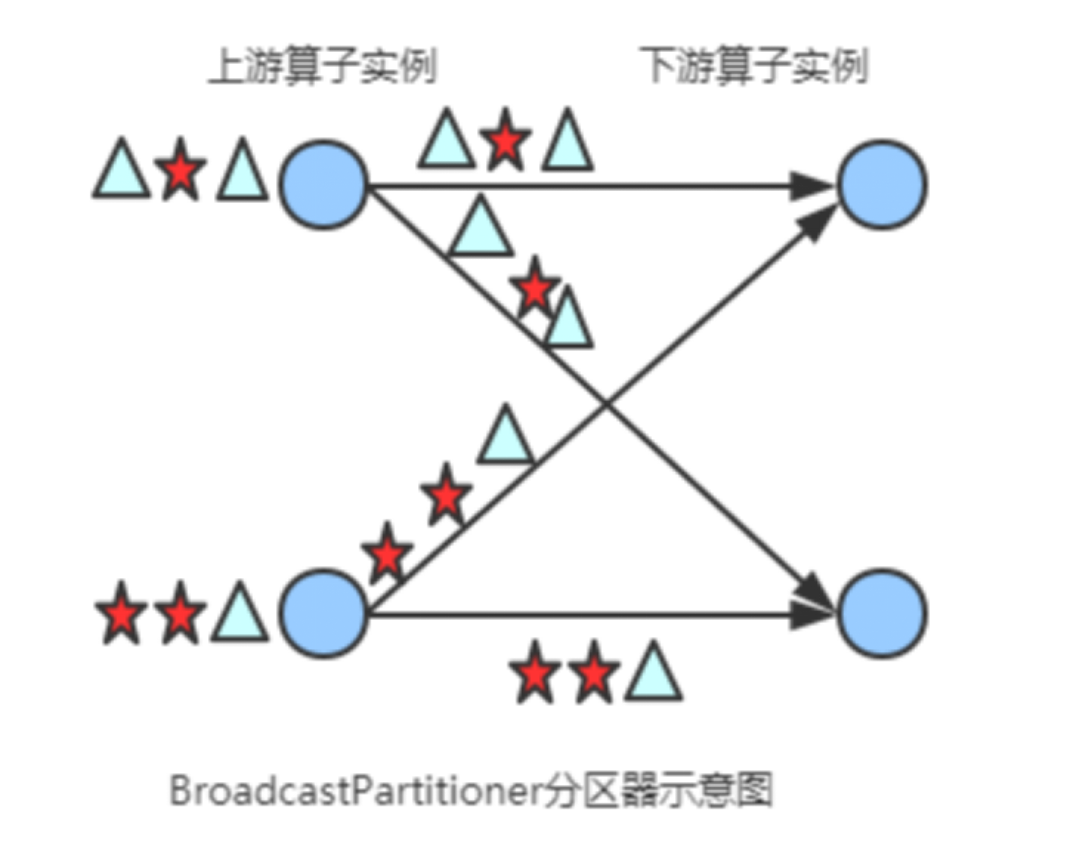
4)Rebalance Partitioner --重分区 【重点】
通过循环的方式依次发送到下游的task
数据倾斜: 某一个分区数据量过大。
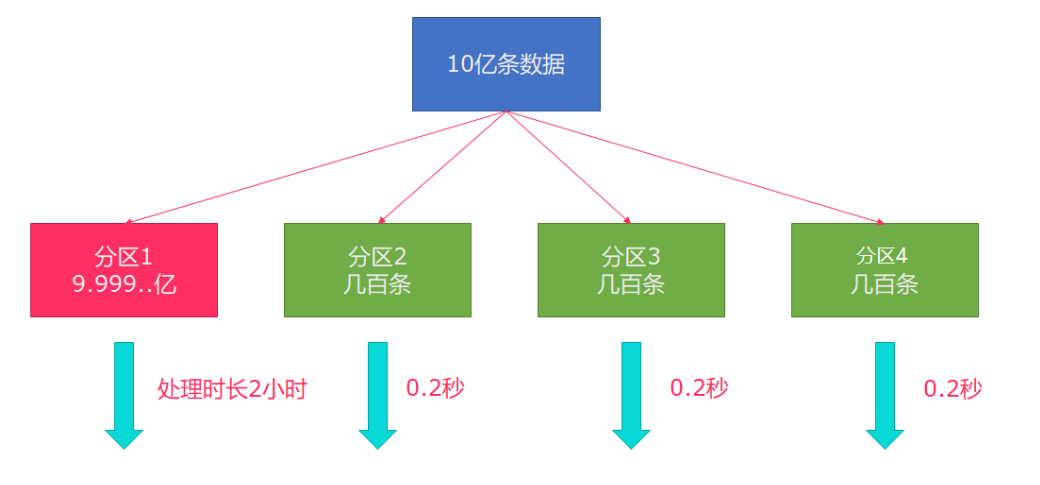
解决方案:可以对分区数据进行重分区rebalance。

源码截图:

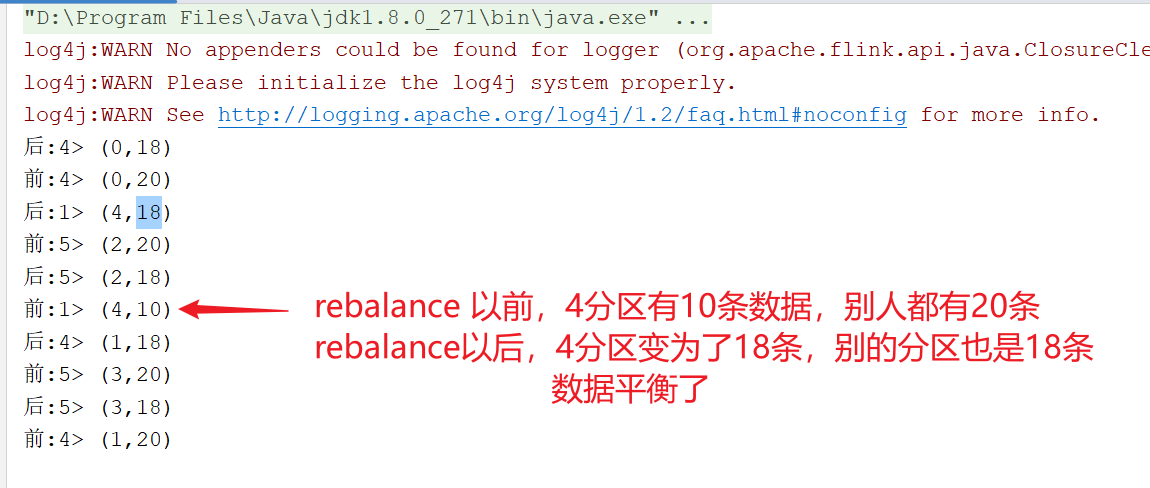
通过人为制造数据不平衡,然后通过方法让其平衡,可以通过观察每一个分区的总数来观察。
随堂代码,熟悉各个分区器的使用方法:
package com.bigdata.day03;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2023-11-21 14:11:59**/
public class PartitionerDemo {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);// 手动设置五个分区env.setParallelism(5);//2. source-加载数据DataStreamSource<Long> dataStream = env.fromSequence(0, 100);// 认为制造数据不均衡的情况/*** // [1,20],[21,40],[41,60],[61,80],[81,100]* // -->[11,20],[21,40],[41,60],[61,80],[81,100]* // 这个是由数据源所决定的,假如是一个socket ,就不会出现这个情况了。*/SingleOutputStreamOperator<Long> filterStream = dataStream.filter(new FilterFunction<Long>() {@Overridepublic boolean filter(Long aLong) throws Exception {return aLong > 10;}});filterStream.print("前");// 在一个流对象后面,调用rebalance ,会将流中的数据进行再平衡,得到一个新的流// DataStream<Long> rebalanceStream = filterStream.rebalance();// global 是将数据全部发送给一个分区// DataStream<Long> rebalanceStream = filterStream.global();// 将上游数据,随机发送给下游的分区// DataStream<Long> rebalanceStream = filterStream.shuffle();// 前面一个分区的数据,发送给后面一个分区//DataStream<Long> rebalanceStream = filterStream.forward();// 将前面分区的数据发送给后面的所有分区DataStream<Long> rebalanceStream = filterStream.broadcast();rebalanceStream.print("后");//3. transformation-数据处理转换//4. sink-数据输出//5. execute-执行env.execute();}
}如何查看每一个分区的数据量呢?
package com.bigdata.transforma;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-11-22 11:52:43**/
public class _10_物理分区策略 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(5);DataStreamSource<Long> streamSource = env.fromSequence(1, 100000);//DataStream<Long> ds = streamSource.global();// 此时打印,数据都在1 分区//ds.print();// shuffle 将数据随机均匀分布在不同的 分区上,或者任务上。//DataStream<Long> shuffle = streamSource.shuffle();// broadcast 将上游的每一个分区的数据发送给下有的所有分区//DataStream<Long> broadcast = streamSource.broadcast();// 将数据均匀的分发给下游的分区,如果遇到数据倾斜,直接就解决了//DataStream<Long> rebalance = streamSource.rebalance();// 上有的数据对应下游的数据,分区数必须是 1:1才行DataStream<Long> forward = streamSource.forward();// streamSource.rescale();//shuffle.print();// 虽然打印了,但是我不知道某个分区具体有多少数据,所以我想看到某个分区,以及这个分区的数据量forward.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {@Overridepublic Tuple2<Long, Integer> map(Long value) throws Exception {long partition = getRuntimeContext().getIndexOfThisSubtask();return Tuple2.of(partition,1);}}).keyBy(0).sum(1).print();//5. execute-执行env.execute();}
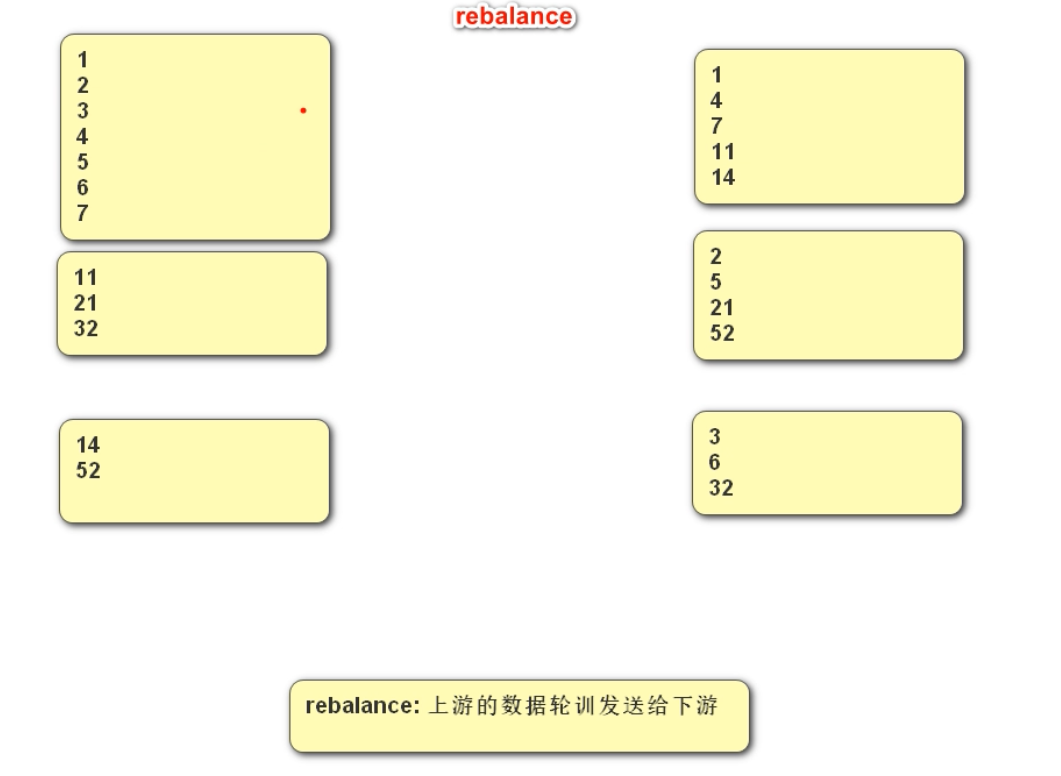
}Rebalance底层逻辑:
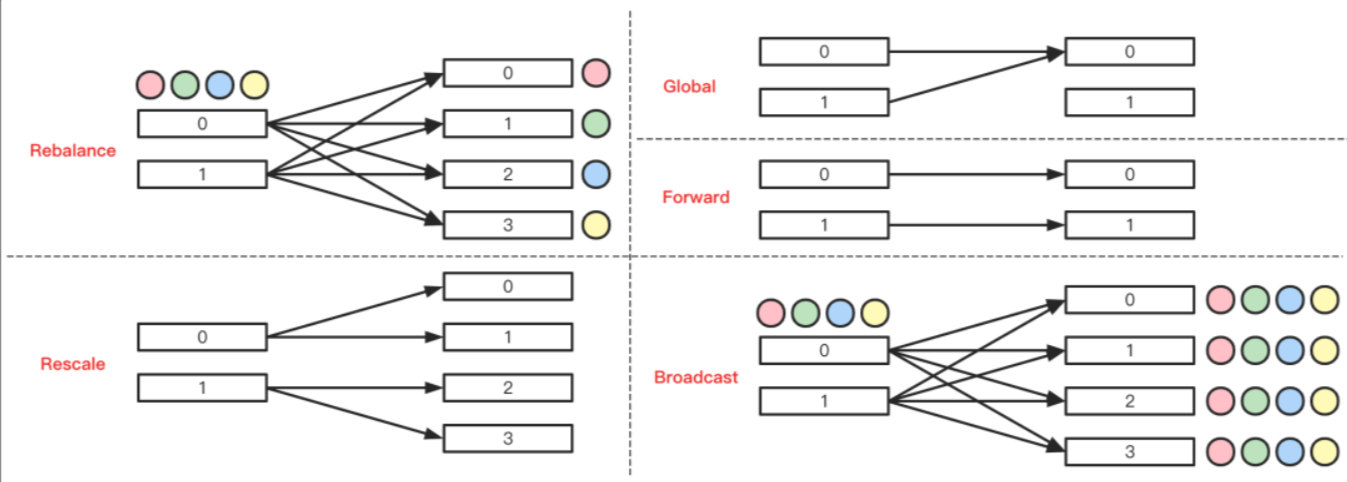
5) Forward Partitioner
发送到下游对应的第一个task,保证上下游算子并行度一致,即上有算子与下游算子是1:1的关系

在上下游的算子没有指定分区器的情况下,如果上下游的算子并行度一致,则使用ForwardPartitioner,否则使用RebalancePartitioner,对于ForwardPartitioner,必须保证上下游算子并行度一致,否则会抛出异常。
6)Custom(自定义) Partitioning
关于分区,很多技术都有分区:
1、hadoop 有分区
2、kafka 有分区
3、spark 有分区
4、hive 有分区
使用用户定义的Partitioner 为每个元素选择目标任务
以下代码是这几种情况的代码演示:
package com.bigdata.transforma;import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;/*** @基本功能:* @program:FlinkDemo* @author: 闫哥* @create:2024-11-22 14:15:50**/
class CustomPartitioner implements Partitioner<Long>{@Overridepublic int partition(Long key, int numPartitions) {System.out.println(numPartitions);if(key <10000){return 0;}return 1;}
}
public class _11_自定义分区规则 {public static void main(String[] args) throws Exception {//1. env-准备环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(2);DataStreamSource<Long> streamSource = env.fromSequence(1, 15000);DataStream<Long> dataStream = streamSource.partitionCustom(new CustomPartitioner(), new KeySelector<Long, Long>() {@Overridepublic Long getKey(Long value) throws Exception {return value;}});//dataStream.print();// 每一个分区的数据量有多少dataStream.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {@Overridepublic Tuple2<Long, Integer> map(Long value) throws Exception {long partition = getRuntimeContext().getIndexOfThisSubtask();return Tuple2.of(partition,1);}}).keyBy(0).sum(1).print("前:");DataStream<Long> rebalance = dataStream.rebalance();rebalance.map(new RichMapFunction<Long, Tuple2<Long,Integer>>() {@Overridepublic Tuple2<Long, Integer> map(Long value) throws Exception {long partition = getRuntimeContext().getIndexOfThisSubtask();return Tuple2.of(partition,1);}}).keyBy(0).sum(1).print("后:");//5. execute-执行env.execute();}
}
)




