
🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏: 🏀深度学习_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
目录
1. 前言
2. 什么是对抗学习
3. 对抗学习
3.1 对抗攻击
3.1.1 FGSM
3.1.2 Iterative FGSM
3.2 对抗训练
4. 对抗攻击代码实现(FSGM)
4.1 网络模型
4.2 FSGM模块
4.3 Test模块
4.4 可视化图片
5. 对抗学习可以用在哪些方面
6. 总结
1. 前言
本系列文章,重点帮助大家理解机器学习中的各种学习包括多任务学习、联邦学习、对比学习等。
今天,猫猫来讲讲对抗学习,希望可以和大家一起打开对抗学习的大门!

2. 什么是对抗学习
机器学习这一技术自出现之始就以优异的性能应用于各个领域。近年来,随着机器学习的快速发展与广泛应用,这一领域更是得到前所未有的蓬勃发展。
目前, 机器学习在计算机视觉、语音识别、自然语言处理等复杂任务中取得了公认的成果,已经被广泛应用于自动驾驶、人脸识别等领域。随着机器学习技术遍地开花,逐渐深入人们的生活,其也被应用在许多例如安防、金融、医疗等对安全有严格要求的领域中,直接影响着人们的人身、财产和隐私的安危。
在一系列重大进展面前, 机器学习在越来越多的被应用到人类生活的方方面面,在这时人们也很容易忽视阳光背后的阴影。与很多实用性技术一样,机器学习作为一个复杂的计算机系统,同样面临着安全性的考验,同样会面临黑客攻击,也被发现存在着安全性问题,它们干扰机器学习系统输出正确结果,例如对抗样本(adversarial data)的存在。研究人员发现,一些精心设计的对抗样本可以使机器学习模型输出错误的结果。但是人类并不能发现这些样本,这就导致模型很容易受到我们无法预知的对抗攻击。如果攻击发生在很关键的领域(例如无人驾驶、指纹识别等),将造成很严重的后果。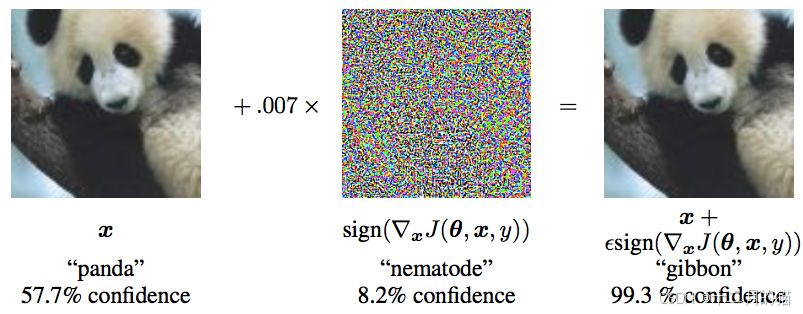
如上图所示,一张正常的大熊猫图片(左图)在被加入噪声后生成对抗样本(右图),会使得神经网络分类错误,并被神经网络认为是一张长臂猿图片,然而人类并不能察觉到这种变化。[1]
对抗样本是指:
将真实的样本添加扰动而合成的新样本,是由深度神经网络的输入的数据和人工精心设计好的噪声合成得到的,但它不会被人类视觉系统识别错误。然而在对抗数据面前,深度神经网络却是脆弱的,可以轻易迷惑深度神经网络。
由此可见,对抗攻击的危害很大,尤其是对于无人驾驶、医疗诊断、金融分析这些安全至关重要的领域。对抗样本无疑制约着机器学习技术的进一步应用,因此,提升神经网络的对抗鲁棒性(抵御对抗样本的能力)变得十分重要。
于是,机器学习中的对抗样本引起了研究人员的极大关注,他们也相应提出了一系列的对抗攻击(如何更有效的产生对抗样本)和对抗防御(针对对抗样本提供更有效的防御)的方法,这一领域称之为对抗学习。对抗学习是一个机器学习与计算机安全的交叉领域,旨在于在恶意环境下(比如在对抗样本的存在的环境下)给机器学习技术提供安全保障。
对抗学习:学习如何应对对抗攻击
学习如何应对对抗攻击:了解对抗攻击+完成对抗防御
3. 对抗学习
对抗学习的本质就是:让模型学会处理对抗攻击,提高模型的鲁棒性。而想要让模型学会处理对抗攻击就需要了解对抗攻击,因此需要学会生成对抗攻击,然后再根据对抗攻击的特点去完成对抗防御。
3.1 对抗攻击
根据不同的分类标准,对抗攻击(如何生成对抗样本)有着以下几种分类方式[3] ,从攻击环境或者按照攻击者具备的能力来说,可以分为:
白盒攻击(White-box attacks):白盒攻击假定攻击者可以完全了解他们正在攻击的神经网络模型的结构和参数,包括训练数据,模型结构,超参数情况,层的数目,激活函数,模型权重等。能在攻击时与模型有交互,并观察输入输出。
黑盒攻击(Black-box attacks):黑盒攻击假定攻击者不知道他们正在攻击的神经网络模型的结构和参数,能在攻击时与模型进行交互,只知道模型的输入输出。白盒攻击样本可以通过一些方法转换成黑盒攻击的方式。
灰盒攻击:介于黑盒攻击和白盒攻击之间,仅仅了解模型的一部分。(例如仅仅拿到模型的输出概率,或者只知道模型结构,但不知道参数)。
真实世界攻击(Real-world attacks):在真实的物理世界攻击。如将对抗样本打印出来,用手机拍照识别。
3.1.1 FGSM
如何生成对抗攻击呢?FGSM具体方法如下:
- FGSM(fast gradient sign method)是一种基于梯度生成对抗样本的算法,属于对抗攻击中的无目标攻击(即不要求对抗样本经过model预测指定的类别,只要与原样本预测的不一样即可)
- 我们在理解简单的dp网络结构的时候,在求损失函数最小值,我们会沿着梯度的反方向移动,使用减号,也就是所谓的梯度下降算法;而FGSM可以理解为梯度上升算法,也就是使用加号,使得损失函数最大化。先看下图效果,goodfellow等人通过对一个大熊猫照片加入一定的扰动(即噪音点),输入model之后就被判断为长臂猿。
FGSM 的步骤
- 选择损失函数: 选择一个损失函数LL,该函数衡量模型的预测与真实标签之间的差距。常用的损失函数是交叉熵损失。
- 计算梯度: 对输入样本xx计算损失函数相对于输入的梯度∇xL(x,y)∇xL(x,y),其中yy是真实标签。
- 生成对抗扰动: 使用梯度信息生成对抗扰动。扰动的公式为:
4. 生成对抗样本: 将扰动添加到原始样本中,得到对抗样本xadvxadv。
其中,sign(⋅)表示符号函数【即sign(-2),sign(-1.5)等都等于 -1;sign(3),sign(4.7)等都等于 1】,ϵ是一个小的正数,表示扰动的幅度(可以理解为学习率)。
FGSM 的特点
- 效率: FGSM 是一种非常快速和简单的攻击方法,因为它只需要计算一次梯度。
- 效果: 尽管简单,FGSM 能够有效地生成对抗样本,测试模型的鲁棒性。
- 局限性: FGSM 可能对一些防御方法不够有效,因为它的扰动是单一的,可能不足以击败更复杂的防御策略。
3.1.2 Iterative FGSM
原理: Iterative FGSM,也称为 Iterative Fast Gradient Sign Method,是 FGSM 的一种改进版本。它通过多次迭代的方式生成对抗样本,以增强对抗攻击的效果。

特点:
- 迭代过程: 通过多次迭代,每次对抗样本都稍微更新,从而生成更强的对抗样本。
- 效果提升: 迭代过程使得对抗样本的攻击效果通常比单次 FGSM 攻击要强。
3.2 对抗训练
理解对抗样本之后,也就不难理解各种相关概念了,比如“对抗攻击”,其实就是想办法造出更多的对抗样本,而“对抗防御”,就是想办法让模型能正确识别更多的对抗样本。
所谓对抗训练,则是属于对抗防御的一种,它构造了一些对抗样本加入到原数据集中,希望增强模型对对抗样本的鲁棒性;
对抗训练:想要在模型训练中提升模型的对抗防御能力,识别一些对抗样本
在对抗训练中,我们讲讲Min-Max训练方法:
总的来说,对抗训练可以统一写成如下格式:
其中 D代表训练集, x代表输入, y代表标签, 是模型参数,
是单个样本的 loss,
是对抗扰动,
是扰动空间。这个统一的格式首先由论文 Towards Deep Learning Models Resistant to Adversarial Attacks [4] 提出。
这个式子可以分步理解如下:
-
往属于 里边注入扰动
,
越大越好,也就是说尽可能让现有模型的预测出错;
-
当然
,其中
是一个常数;
-
每个样本都构造出对抗样本
之后,用
作为数据对去最小化loss来更新参数
(梯度下降);
-
反复交替执行 1、2、3 步。
核心思想:
1、生成对抗样本(可以用FSGM等算法)。
2、训练对抗样本逐步达到最好效果的对抗样本。
3、在每次生成更好对抗样本的同时,利用生成的对抗样本参与网络参数的训练,从而提高模型对对抗样本的识别程度。
4. 对抗攻击代码实现(FSGM)
4.1 网络模型
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
import numpy as np
import matplotlib.pyplot as plt# 这里的epsilon先设定为几个值,到时候后面可视化展示它的影响如何
epsilons = [0, .05, .1, .15, .2, .25, .3]
# 这个预训练的模型需要提前下载,放在如下url的指定位置,下载链接如上
pretrained_model = "data/lenet_mnist_model.pth"
use_cuda=True# 就是一个简单的模型结构
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x, dim=1)# 运行需要稍等,这里表示下载并加载数据集
test_loader = torch.utils.data.DataLoader(datasets.MNIST('../data', train=False, download=True, transform=transforms.Compose([transforms.ToTensor(),])),batch_size=1, shuffle=True)# 看看我们有没有配置GPU,没有就是使用cpu
print("CUDA Available: ",torch.cuda.is_available())
device = torch.device("cuda" if (use_cuda and torch.cuda.is_available()) else "cpu")# Initialize the network
model = Net().to(device)# 加载前面的预训练模型
model.load_state_dict(torch.load(pretrained_model, map_location='cpu'))# 设置为验证模式.
# 详解见这个博客 https://blog.csdn.net/qq_38410428/article/details/101102075
model.eval()代码解析
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
nn.Conv2d(1, 10, kernel_size=5):这是一个卷积层,输入通道数为1(通常是灰度图像),输出通道数为10(卷积核的个数),卷积核的大小为5x5。这个层会提取图像的局部特征。self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
nn.Conv2d(10, 20, kernel_size=5):第二个卷积层,输入通道数为10(上一层的输出通道数),输出通道数为20,卷积核大小仍为5x5。通过这一层,网络会学习更高级的特征。self.conv2_drop = nn.Dropout2d()
nn.Dropout2d():这是一个2D Dropout层,作用是随机丢弃部分特征图的通道,以此来减少过拟合。它通常在卷积层之后使用,可以提高网络的泛化能力。self.fc1 = nn.Linear(320, 50)
nn.Linear(320, 50):这是一个全连接层(线性层),输入特征的维度是320(一般是卷积层输出的展平后的特征数),输出特征的维度是50。全连接层用于将卷积层提取的特征映射到分类空间。self.fc2 = nn.Linear(50, 10)
nn.Linear(50, 10):第二个全连接层,将输入的50维特征映射到10个输出单位,通常用于分类任务的输出层。这里的10表示分类类别数,假设是一个10类的分类问题(如手写数字分类)。模型的整体结构:
该网络由两层卷积层和两层全连接层组成,整体结构如下:
- 卷积层1 (
conv1):从输入图像中提取特征,使用5x5的卷积核,输出10个特征图。- 卷积层2 (
conv2):对卷积层1的输出进行进一步特征提取,输出20个特征图。- Dropout层 (
conv2_drop):在卷积层2的输出上进行2D dropout操作,丢弃一部分特征图,防止过拟合。- 全连接层1 (
fc1):将卷积层的输出展平并输入到全连接层,输出50个特征。- 全连接层2 (
fc2):将50个特征映射到10个类别,输出最终的分类结果。注意点
- 展平:在输入全连接层之前,通常需要对卷积层的输出进行展平(flatten),将二维的特征图展平成一维向量。展平的维度通常是
(batch_size, 320),其中320是卷积层输出的特征数量(取决于输入图像大小和卷积层的配置)。- Dropout:Dropout层有助于减少过拟合,它会在训练过程中随机丢弃部分神经元,迫使网络在每次训练时使用不同的子网络,从而提高泛化能力。
代码解析
1.
x = F.relu(F.max_pool2d(self.conv1(x), 2))
self.conv1(x): 输入x经过第一个卷积层conv1。假设conv1是一个卷积层(nn.Conv2d),它会对输入x应用卷积操作,通常用于提取图像的局部特征。conv1的输出是一个新的张量,形状通常会比输入的x小(除非使用填充)。
F.max_pool2d(self.conv1(x), 2): 在卷积操作之后,执行最大池化操作(max_pool2d)。最大池化通常用于下采样,通过选择每个 2x2 区域中的最大值来减小特征图的空间维度。kernel_size=2表示池化窗口大小为 2x2。
F.relu(...): 对池化后的结果应用 ReLU 激活函数,增加网络的非线性性。ReLU 会把所有负值置为 0,保留正值。2.
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
self.conv2(x): 输入x经过第二个卷积层conv2,该操作会提取更高层次的特征。
self.conv2_drop(...): 这是一个额外的操作,通常是一个Dropout层,可能用于在训练过程中防止过拟合。它会随机将一部分神经元的输出设置为 0,减少网络对特定神经元的依赖。
F.max_pool2d(..., 2): 在卷积和 Dropout 操作后,执行 2x2 最大池化。
F.relu(...): 对池化后的结果应用 ReLU 激活函数。3.
x = x.view(-1, 320)
x.view(-1, 320): 这个操作将x张量重新调整形状。view(-1, 320)表示将x重塑为一个二维张量,其中-1表示自动计算批量大小(batch size),而320是每个样本的特征维度。这一步通常在将卷积层的输出连接到全连接层时执行。假设卷积和池化操作后,特征图的尺寸为(batch_size, channels, height, width),通过view将其展平成一个(batch_size, 320)的二维张量,以便输入到全连接层。4.
x = F.relu(self.fc1(x))
self.fc1(x): 这是第一个全连接层(fc1),将展平的特征图(x)映射到一个新的维度。假设fc1是一个nn.Linear层,例如fc1 = nn.Linear(320, 128),它会把输入的 320 维特征映射到 128 维。
F.relu(self.fc1(x)): 对fc1的输出应用 ReLU 激活函数,增加非线性性。5.
x = F.dropout(x, training=self.training)
F.dropout(x, training=self.training): 在训练时,执行 Dropout 操作。Dropout 是一种正则化方法,通过随机丢弃部分神经元的输出,防止网络对某些特征过拟合。self.training是 PyTorch 中的标志,指示模型是否处于训练模式。如果处于训练模式(self.training = True),则会应用 Dropout;如果处于评估模式(self.training = False),则不会应用。6.
x = self.fc2(x)
self.fc2(x): 这是第二个全连接层,将通过fc1输出的特征进一步映射到最终的分类空间。假设fc2 = nn.Linear(128, num_classes),则该层将输出一个大小为num_classes的向量,表示每个类别的得分。7.
return F.log_softmax(x, dim=1)
F.log_softmax(x, dim=1): 对fc2的输出应用 log-softmax 函数。Softmax 将原始的输出值转换为概率分布,而log_softmax则进一步对结果取对数,这在进行交叉熵损失时非常常见。dim=1表示 softmax 应该沿着类的维度(即每个样本的类别分数)进行计算。
4.2 FSGM模块
# FGSM attack code
def fgsm_attack(image, epsilon, data_grad):# 使用sign(符号)函数,将对x求了偏导的梯度进行符号化sign_data_grad = data_grad.sign()# 通过epsilon生成对抗样本perturbed_image = image + epsilon*sign_data_grad# 做一个剪裁的工作,将torch.clamp内部大于1的数值变为1,小于0的数值等于0,防止image越界perturbed_image = torch.clamp(perturbed_image, 0, 1)# 返回对抗样本return perturbed_image
4.3 Test模块
def test( model, device, test_loader, epsilon ):# 准确度计数器correct = 0# 对抗样本adv_examples = []# 循环所有测试集for data, target in test_loader:# Send the data and label to the devicedata, target = data.to(device), target.to(device)# Set requires_grad attribute of tensor. Important for Attackdata.requires_grad = True# Forward pass the data through the modeloutput = model(data)init_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability# If the initial prediction is wrong, dont bother attacking, just move onif init_pred.item() != target.item():continue# Calculate the lossloss = F.nll_loss(output, target)# Zero all existing gradientsmodel.zero_grad()# Calculate gradients of model in backward passloss.backward()# Collect datagraddata_grad = data.grad.data# Call FGSM Attackperturbed_data = fgsm_attack(data, epsilon, data_grad)# Re-classify the perturbed imageoutput = model(perturbed_data)# Check for successfinal_pred = output.max(1, keepdim=True)[1] # get the index of the max log-probabilityif final_pred.item() == target.item():correct += 1# 这里都是为后面的可视化做准备if (epsilon == 0) and (len(adv_examples) < 5):adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )else:# 这里都是为后面的可视化做准备if len(adv_examples) < 5:adv_ex = perturbed_data.squeeze().detach().cpu().numpy()adv_examples.append( (init_pred.item(), final_pred.item(), adv_ex) )# Calculate final accuracy for this epsilonfinal_acc = correct/float(len(test_loader))print("Epsilon: {}\tTest Accuracy = {} / {} = {}".format(epsilon, correct, len(test_loader), final_acc))# Return the accuracy and an adversarial examplereturn final_acc, adv_examples
- model.zero_grad(): PyTorch文档中提到,如果grad属性不为空,新计算出来的梯度值会直接加到旧值上面。 为什么不直接覆盖旧的结果呢?这是因为有些Tensor可能有多个输出,那么就需要调用多个backward。 叠加的处理方式使得backward不需要考虑之前有没有被计算过导数,只需要加上去就行了。我们的情况很简单,就一个输出,所以需要使用这条语句
- loss.backward():这条语句并不会更新参数,它只会求出各个中间变量的grad(梯度)值 ,当然也求出了损失函数关于x的偏导啦
- data_grad = data.grad.data:由于前面使用了loss.backward() ,所以data这个tensor的grad属性,自然就有值了,还是损失函数对于x的偏导值
4.4 可视化图片
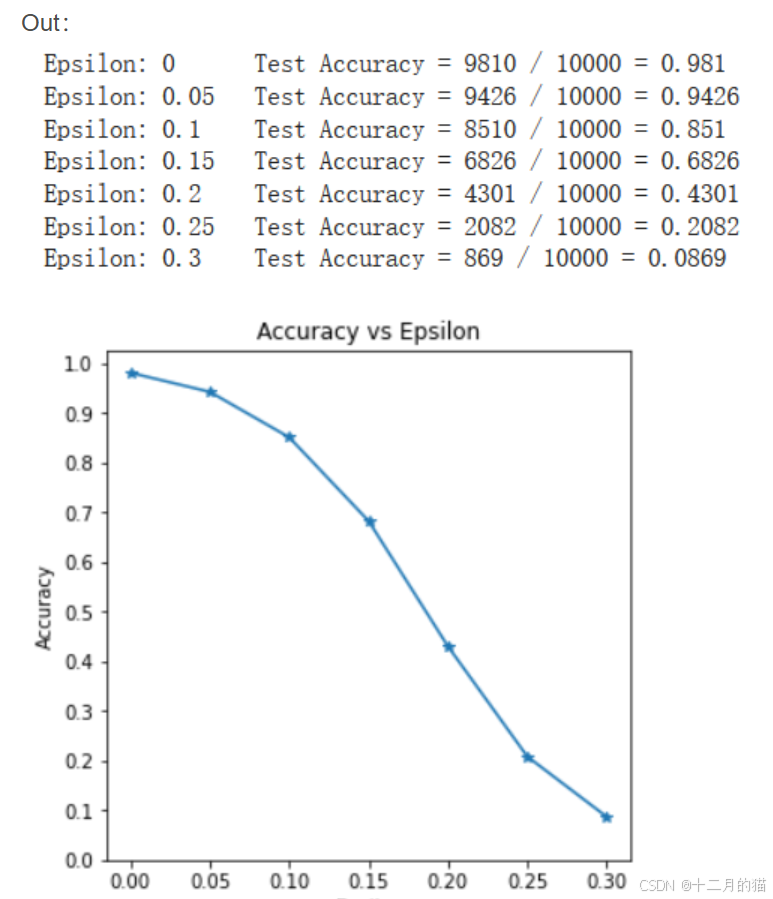
模型准确率变化:
accuracies = []
examples = []# Run test for each epsilon
for eps in epsilons:acc, ex = test(model, device, test_loader, eps)accuracies.append(acc)examples.append(ex)plt.figure(figsize=(5,5))
plt.plot(epsilons, accuracies, "*-")
plt.yticks(np.arange(0, 1.1, step=0.1))
plt.xticks(np.arange(0, .35, step=0.05))
plt.title("Accuracy vs Epsilon")
plt.xlabel("Epsilon")
plt.ylabel("Accuracy")
plt.show()
对抗样本展示:
# Plot several examples of adversarial samples at each epsilon
cnt = 0
plt.figure(figsize=(8,10))
for i in range(len(epsilons)):for j in range(len(examples[i])):cnt += 1plt.subplot(len(epsilons),len(examples[0]),cnt)plt.xticks([], [])plt.yticks([], [])if j == 0:plt.ylabel("Eps: {}".format(epsilons[i]), fontsize=14)orig,adv,ex = examples[i][j]plt.title("{} -> {}".format(orig, adv))plt.imshow(ex, cmap="gray")
plt.tight_layout()
plt.show()

5. 对抗学习可以用在哪些方面
通过将计算得到的扰动噪声加入原始图像,使得能够正确分类原始图像的分类器对加入扰动的图像产生错误分类。而这个扰动的幅度很小,人眼观察是不会错分的,但却能在测试或部署阶段,很容易的“欺骗”深度神经网络。
将深度神经网络应用到对安全有严格要求的环境中时,处理对抗样本造成的脆弱性就成为了一个重要的任务。此外,并不是某个机器学习(包括深度学习)算法单独具有对于对抗样本的脆弱性,而是机器学习的模型普遍都可能具有该缺陷,这种缺陷在对于安全性要求较高的行业中就显得尤为重要了。因此,对抗学习可以被广泛地运用在医疗、金融、安防和自动驾驶等行业。
01.图像识别
近年来的研究进一步发现,不仅是像素级别的扰动,真实世界中的扰动即便通过摄像机采集,也具有攻击性,这就使得对抗攻击更容易出现在我们生活的世界中。例如,对停车标志附加一些贴纸或涂鸦,它便被交通标志识别系统错误识别为限速标志。
△添加了黑白贴纸的停车标志可以被机器学习模型错误识别
02.人脸识别
真人戴上一副特制的眼镜,就被人脸识别系统错误识别为另一个人。如果这些对抗攻击方法被用来干扰自动驾驶、人脸识别等应用系统,后果将不堪设想。
△人物戴上特制眼镜被识别成其他人
03.目标检测
来自比利时鲁汶大学的研究者针对人物检测器进行了对抗攻击方面的研究,他们开发了一个 40cm×40cm 的对抗样本补丁。如果人类佩戴它,目标检测模型将无法再检测到该人类。如图所示,左侧没有携带对抗图像块的人可被准确识别出来,而右侧携带对抗图像块的人并未被检测出来。入侵者可以使用它在摄像头下隐身!
△携带对抗样本在目标检测模型下隐身
04.音频和文本识别
机器学习模型在进行语音识别过程中,如果此时的背景音乐是经过精心设计的,那么就有可能使识别结果错误,甚至按照攻击者的意图来输出结果。在文本处理任务中,也有着相似的问题,在文本段落中,增加一些特殊的词汇或标点,或者在不改变语义情况下调整个别句子,人类不易察觉,但模型却无法按照预期输出正确的结果。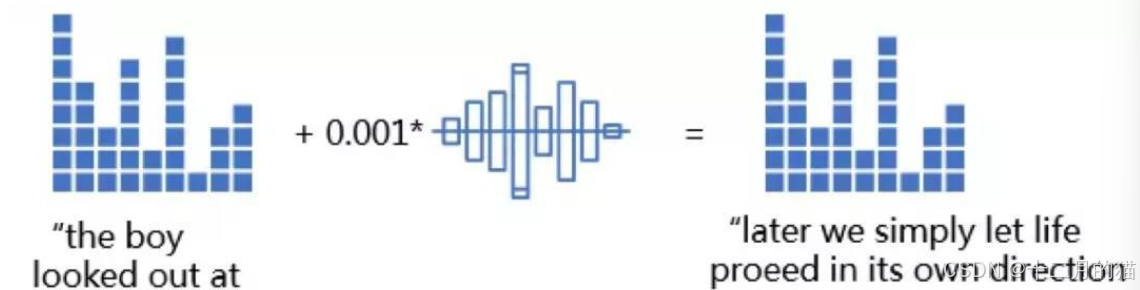
6. 总结
目前,对抗攻击中攻击与防御的方式也是“道高一尺,魔高一丈”,已经经过了许多轮的迭代,演变出了许多攻防方式。随着各种攻击方法的产生,提出的防御方法看似抵御了这些攻击,但是新出现的攻击却又不断躲避着这些防御方法。
至今,人们仍不完全清楚神经网络这个黑盒的本质特性。甚至有研究指出,神经网络完成的分类任务仅是靠辨别局部的颜色和纹理信息,这使得自然的对抗样本,即便不是人为加入的扰动,而是真实采集到的图像,也能够成功地欺骗神经网络。这也支持了许多研究者的观点,即神经网络只是学习了数据,而非知识,机器学习还无法像人一样学习。
这项难题的最终解决,或许依赖于对神经网络的透彻理解,以及对神经网络结构的改进。弄清楚神经网络内部的学习机制,并据此进行改进,或许才能真正解决目前神经网络对于对抗攻击的脆弱性。
因此对抗机器学习不仅是机器学习被更加广泛地被应用的一道门槛,也是促使人们研究如何解释机器学习模型的动力。
如果想要学习更多人工智能·深度学习的知识,大家可以点个关注并订阅,持续学习、天天进步
你的点赞就是我更新的动力,如果觉得对你有帮助,辛苦友友点个赞,收个藏呀~~~




领域常用数据集介绍)
