
教程总体简介:要求 目标 1.1 项目演示 学习目标 1.1 图像识别背景 1.2 什么是目标检测 1.2.1 目标检测定义 1.2.1.1 物体 1.3 目标检测应用场景 1.3.1 行业 1.3.2 应用类别 1.4 开发环境搭建 目标检测概述 3.1 目标检测任务描述 3.1.4 目标定位的简单实现 项目实现 4.9 Web Server + TensorFlow Serving Client 4.9.1 环境安装 4.9.1 Web Server 4.10 服务器部署+小程序 4.10.2 小程序 目标检测算法原理 3.2 R-CNN 3.2.1 目标检测-Overfeat模型 3.2.7 问题? 3.3 SPPNet 3.5 Faster R-CNN 3.5.2 RPN原理 3.5.4 效果对比 3.6 YOLO(You only look once) 3.6.1 YOLO 这些候选框与我们前面R-CNN系列算法中有哪些不同? 3.6.2 单元格(grid cell) 3.6.3 非最大抑制(NMS) 3.6.4 训练 3.7 SSD(Single Shot MultiBox Detector) 3.7.1 SSD 问题:SSD中的多个Detector & classifier有什么作用? 3.7.2 训练与测试流程 3.8 TensorFlowSSD接口 3.8.1 接口文件 数据集处理 2.2 目标数据集标记 2.3 数据集格式转换 2.3.2 TFRecords文件 2.3.3 案例:VOC2007数据集转换 2.4 slim库介绍 2.4.2 导入以及API介绍 4.1 项目结构介绍 4.1.2 项目代码训练架构设计 4.2 数据模块接口 4.2.1 功能需求 4.2.3 商品数据模块代码编写 4.4 预处理 4.4.2 数据增强 4.5 多GPU训练 4.5.1 训练步骤以及设备部署需求 4.5.2 运行过程与代码编写 主函数训练逻辑 一、选择设备初始配置初始部署设备信息 Create global_step. 选择全局步长变量所在的设备 获取类 获取网络参数 初始化网络 获取形状 获取default anchors 默认只返回一个样本 进行数据的批处理以及获取到队列当中(获取多个数据) 要获取批处理:[image, gclasses, glocalisations, gscores] 单列表? Tensor 列表 重叠的列表进行转换成单列表 r包含着多个样本 计算所有GPU / CPU设备的平均损失和每个变量的梯度总和 获取训练的OP以及摘要OP pre-trained模型路径. 开始训练 4.6 测试
完整笔记资料代码:https://gitee.com/yinuo112/AI/tree/master/深度学习/嘿马深度学习目标检测教程/note.md
感兴趣的小伙伴可以自取哦~
全套教程部分目录:


部分文件图片:

商品目标检测要求、目标
要求
- 有机器学习基础
- 有深度学习基础,如神经网络结构、优化过程
- 知道常见神经网络模型,如CNN(AlexNet、GoogleNet)
- 了解并使用过TensorFlow框架做过图像识别
目标
- 掌握图像检测项目的开发流程
- 掌握模型原理、训练、多GPU徐老年工具的使用
- 掌握TensorFlow Serving模型的部署以及客户端使用
- 学完可以从事图像识别、TensorFlow工程师方面的开发工作
1.1 项目演示
学习目标
-
目标
-
了解项目的演示结果
-
应用
-
无
1.1.1 项目演示
项目已经部署上线,Web端+小程序端演示
1.1.2 项目结构
1.1.3 项目安排
-
第一阶段:算法模型
-
RCNN以及相关算法
- YOLO与SSD
-
算法接口介绍
-
第二阶段:数据集处理
-
数据集标记格式
-
数据集存储与读取
-
第三阶段:项目实现
-
数据接口实现
- 模型接口实现
- 训练、设备部署逻辑实现
- 测试接口
- TensorFlow serving部署模型
- Web server+TensorFlow serving Client
- 小程序
1.1 图像识别背景
学习目标
-
目标
-
了解图像识别的三大任务
-
图像识别的两种模式
-
应用
-
无
1.1.1 图像识别三大任务
-
目标识别:或者说分类,定性目标,确定目标是什么(图a)
-
目标检测:定位目标,确定目标是什么以及位置(图b)
-
目标分割:像素级的对前景与背景进行分类,将背景剔除(图c,图d)
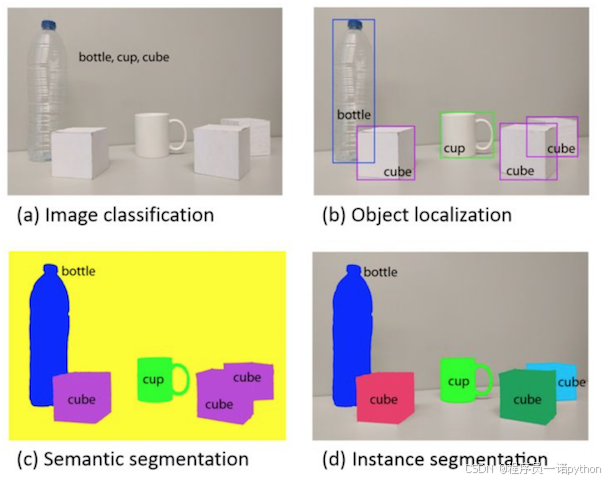
目标检测:技术成熟并且使用更多的场景
目标分割:适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
1.1.2 图像识别的发展
- 通用场景
谷歌、微软、Facebook、百度、阿里巴巴在内的科技巨头都花费了大量的人力财力做研究,搭建了很多图像识别的平台。
-
垂直场景
-
医疗领域:医疗影像的检测
- 林木产业:木板树种检测识别
垂直应用场景里的行业特质挖掘和经验积累往往会被忽视,所以在垂直领域的行业中大量的公司正在开发相当多的图像应用。
1.2 什么是目标检测
学习目标
-
目标
-
知道目标检测的定义
-
了解目标检测的技术发展历史
-
应用
-
无
1.2.1 目标检测定义
识别图片中有哪些物体以及物体的位置(坐标位置)

1.2.1.1 物体
即图像中存在的物体对象,但是能检测哪些物体会受到人为设定限制。
目标检测中能检测出来的物体取决于当前任务(数据集)需要检测的物体有哪些。假设我们的目标检测模型定位是检测动物(牛、羊、猪、狗、猫五种结果),那么模型对任何一张图片输出结果不会输出鸭子、书籍等其它类型结果。
1.2.1.2 位置
目标检测的位置信息一般由两种格式(以图片左上角为原点(0,0)):
-
极坐标表示:(xmin, ymin, xmax, ymax)
-
xmin,ymin:x,y坐标的最小值
-
xmin,ymin:x,y坐标的最大值
-
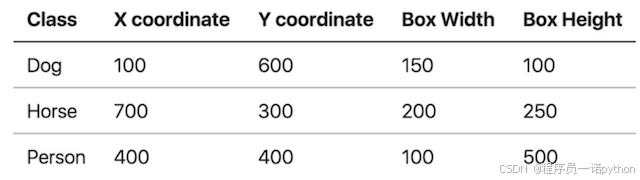
中心点坐标:(x_center, y_center, w, h)
-
x_center, y_center:目标检测框的中心点坐标
- w,h:目标检测框的宽、高
假设这个图像是1000x800,所有这些坐标都是构建在像素层面上:

中心点坐标结果如下:
1.2.2 目标检测的技术发展历史
-
传统目标检测方法(候选区域+手工特征提取+分类器)
-
HOG+SVM、DPM
-
region proposal+CNN提取分类的目标检测框架
-
(R-CNN, SPP-NET, Fast R-CNN, Faster R-CNN)
-
端到端(End-to-End)的目标检测框架
-
YOLO、SSD
1.3 目标检测应用场景
学习目标
-
目标
-
了解目标检测的行业应用场景
-
应用
-
无
1.3.1 行业
-
公安行业的应用
-
公安行业用户的迫切需求是在海量的视频信息中,发现犯罪嫌疑人的线索。人工智能在视频内容的特征提取、内容理解方面有着天然的优势。可实时分析视频内容,检测运动对象,识别人、车属性信息,并通过网络传递到后端人工智能的中心数据库进行存储。
-
农作物的应用
-
农业中农作物表面的病虫害识别也需要用到目标检测技术

-
医疗影像检测
-
人工智能在医学中的应用目前是一个热门的话题,医学影像图像中病变部位检测和识别对于诊断的自动化,提供优质的治疗具有重要的意义。
-
电商行业的应用
-
电商行业中充满无数的商品,利用检测功能查询相关商品,快速找到用户需要的商品类型或者品牌类别,从而提高电商领域的用户满意度
1.3.2 应用类别
- 道路检测

-
动物检测
-
商品检测
-
车牌检测
-
菜品检测

- 车型检测
1.4 开发环境搭建
学习目标
-
目标
-
无
-
应用
-
开发环境搭建
1.4.1 安装
1.4.1.1 虚拟环境安装
- 1、现在虚拟环境管理工具, 环境隔离(python3版本))
pip3 install virtualenv
- 2、配置参数
export WORKON_HOME=$HOME/virtualenv
source /usr/local/bin/virtualenvwrapper.sh
- 3、新建虚拟环境
mkvirtualenv + -p /user/bin/python(python版本所在位置) + test(虚拟环境名称)
- 4、进入虚拟环境
workon test
1.4.1.2 安装环境包
- 环境包:
pip install -r requirements.txt
requirements.txt文件当中包含所有要安装的库。
- TensorFlow版本
关于TensorFlow:
上一种方式当中,TensorFlow默认安装的是非GPU版本(1.8版本),如果要安装GPU版本,参考一下资料中提供的如下文件中的安装过程

目标检测概述
了解目标检测基本概念
掌握开发环境的搭建
3.1 目标检测任务描述
学习目标
-
目标
-
了解目标检测算法分类
- 知道目标检测的常见指标IoU
-
了解目标定位的简单实现方式
-
应用
-
无
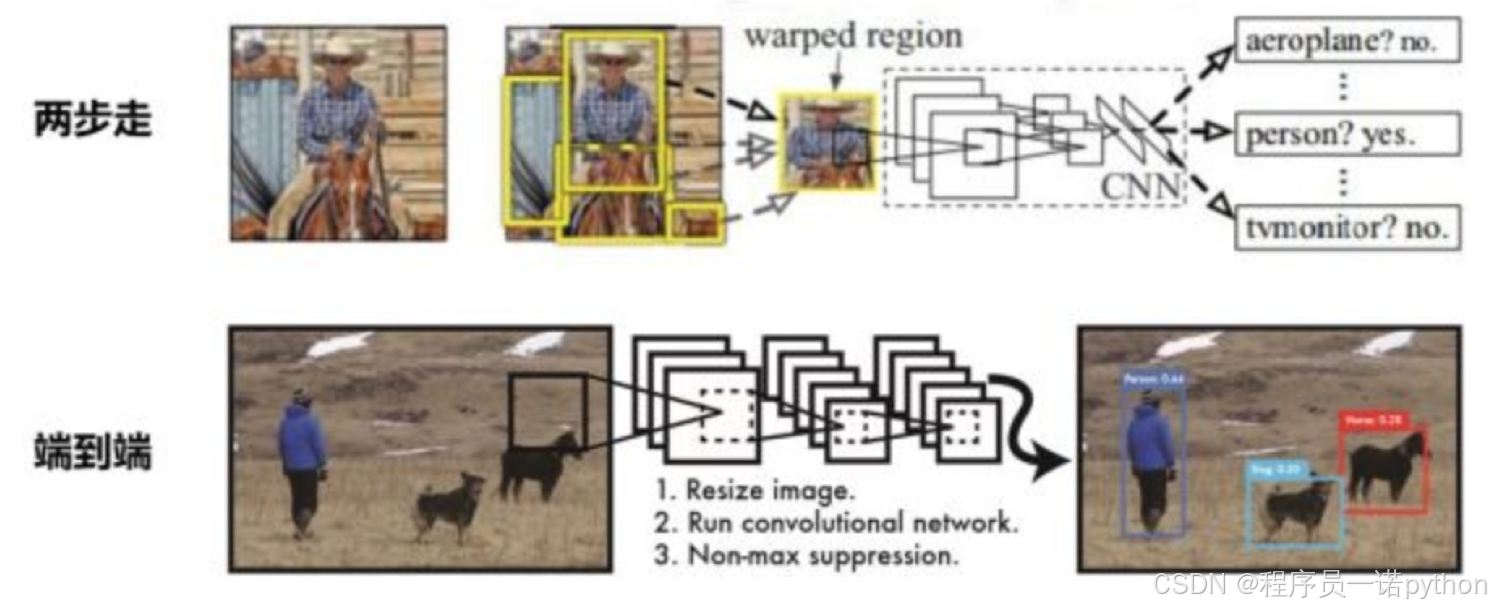
3.1.1 目标检测算法分类
-
两步走的目标检测:先进行区域推荐,而后进行目标分类
-
代表:R-CNN、SPP-net、Fast R-CNN、Faster R-CNN
-
端到端的目标检测:采用一个网络一步到位
-
代表:YOLO、SSD
3.1.2 目标检测的任务
3.1.2.1 分类原理回顾
先来回归下分类的原理,这是一个常见的CNN组成图,输入一张图片,经过其中卷积、激活、池化相关层,最后加入全连接层达到分类概率的效果
- 分类的损失与优化
在训练的时候需要计算每个样本的损失,那么CNN做分类的时候使用softmax函数计算结果,损失为交叉熵损失
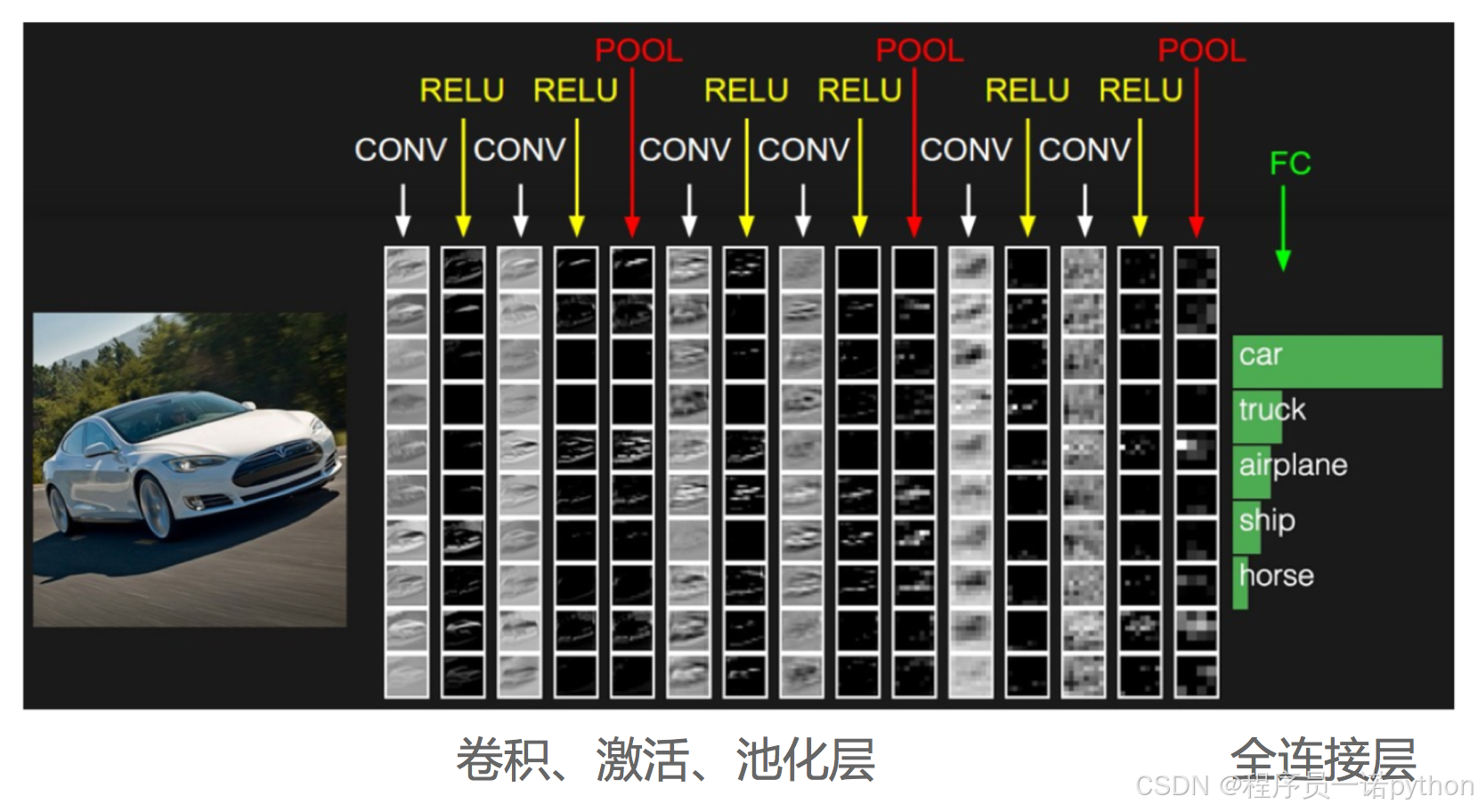
- 常见CNN模型
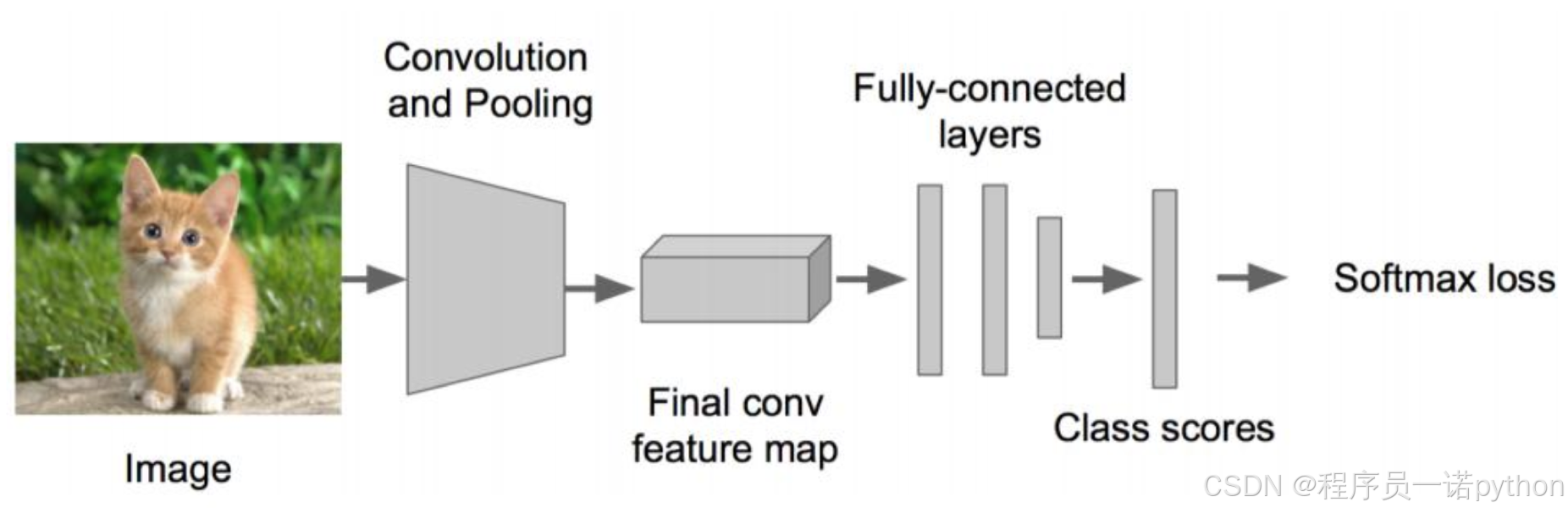
对于目标检测来说不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息,所以从分类到检测,如下图标记了过程:
- 分类

- 分类+定位(只有一个对象的时候)

- 目标检测
3.1.2.2 检测的任务
-
分类:
-
N个类别
- 输入:图片
- 输出:类别标签
- 评估指标:Accuracy

-
定位:
-
N个类别
- 输入:图片
- 输出:物体的位置坐标
- 主要评估指标:IOU
其中我们得出来的(x,y,w,h)有一个专业的名词,叫做bounding box(bbox).
3.1.2.3 两种Bounding box名称
在目标检测当中,对bbox主要由两种类别。
- Ground-truth bounding box:图片当中真实标记的框
- Predicted bounding box:预测的时候标记的框
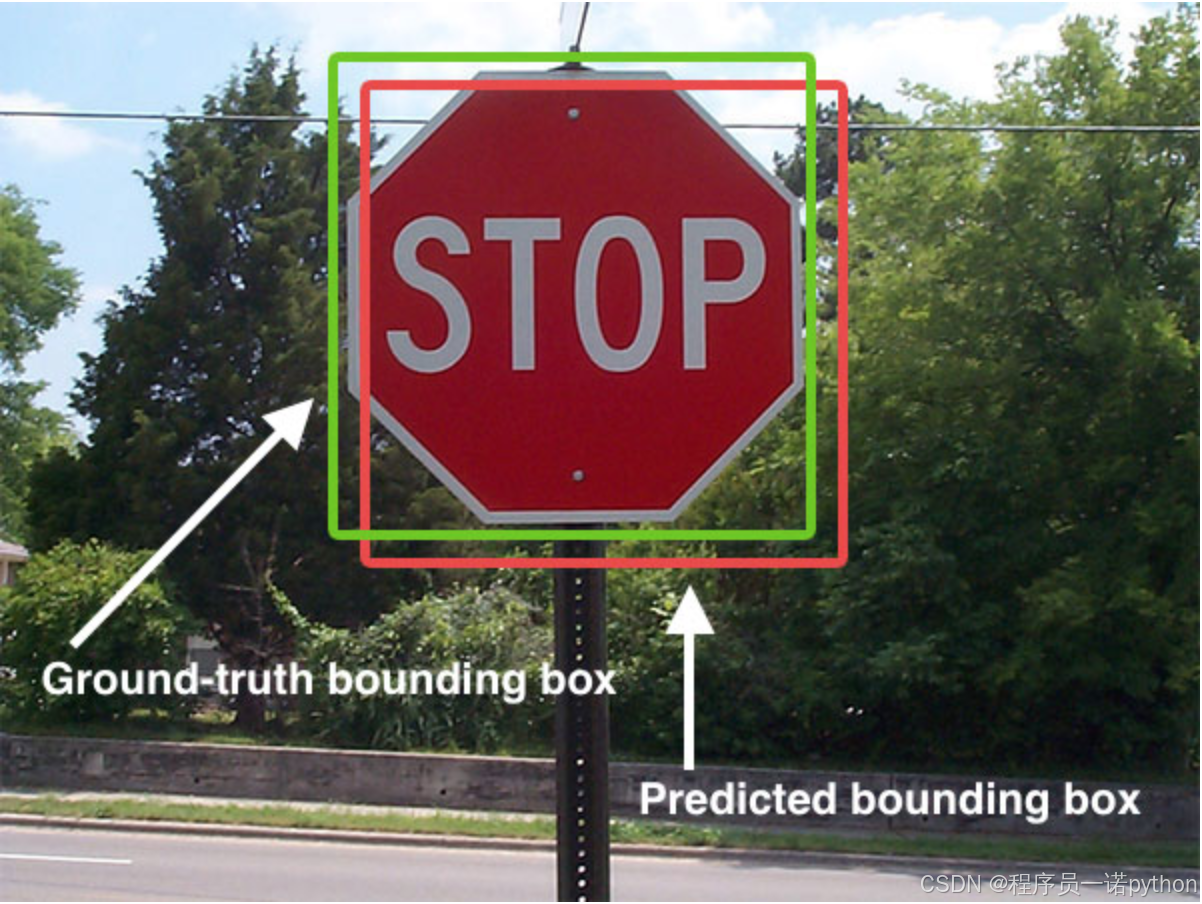
一般在目标检测当中,我们预测的框有可能很多个,真实框GT也有很多个。
3.1.2.4 检测的评价指标
| 任务 | description | 输入 | 输出 | 评价标准 |
|---|---|---|---|---|
| Detection and Localization (检测和定位) | 在输入图片中找出存在的物体类别和位置(可能存在多种物体) | 图片(image ) | 类别标签(categories)和 位置(bbox(x,y,w,h)) | IoU (Intersection over Union) mAP (Mean Average Precision) |
-
IoU(交并比)
-
两个区域的重叠程度overlap:侯选区域和标定区域的IoU值
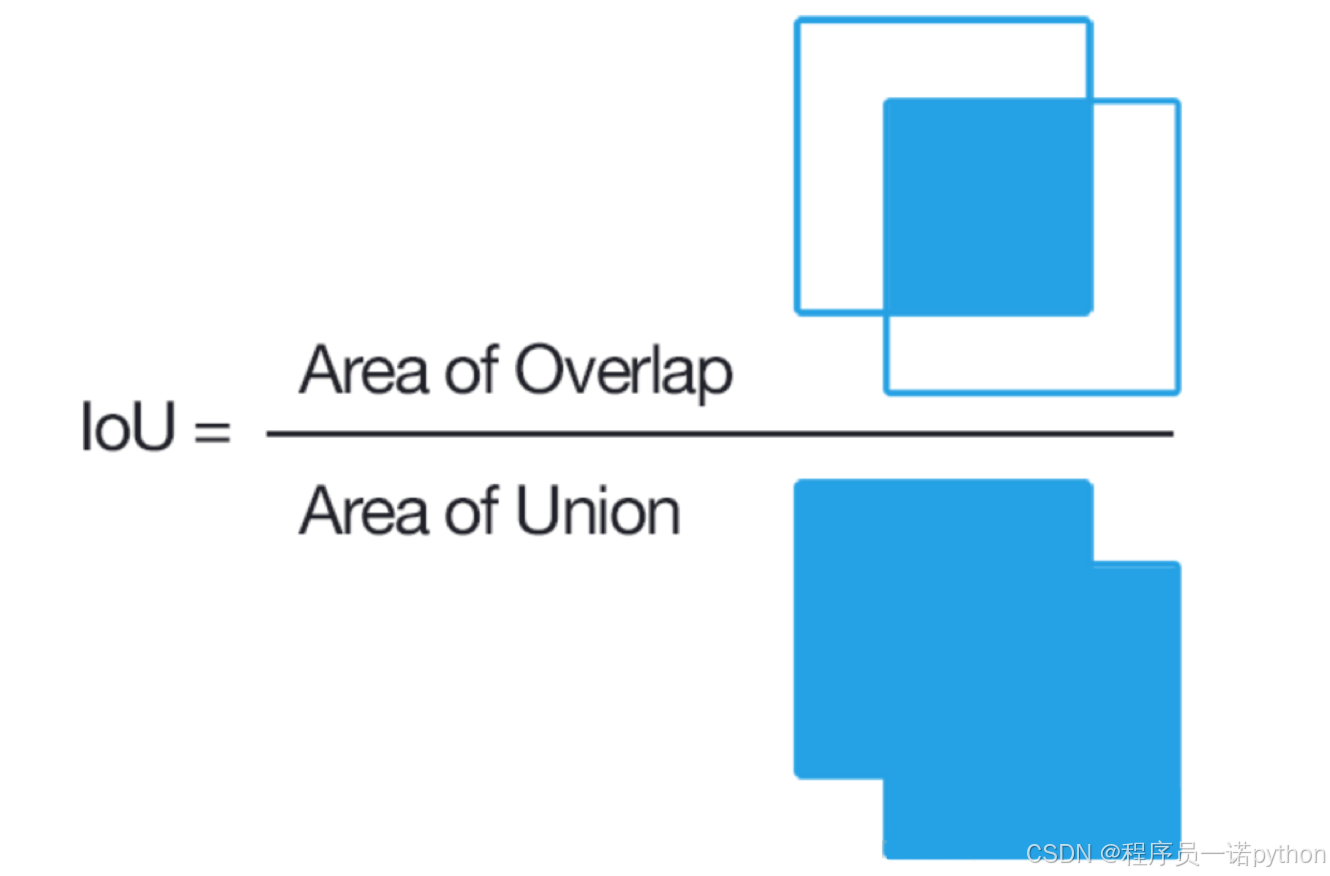
3.1.4 目标定位的简单实现
在分类的时候我们直接输出各个类别的概率,如果再加上定位的话,我们可以考虑在网络的最后输出加上位置信息。
3.1.4.1 回归位置
增加一个全连接层,即为FC1、FC2
-
FC1:作为类别的输出
-
FC2:作为这个物体位置数值的输出
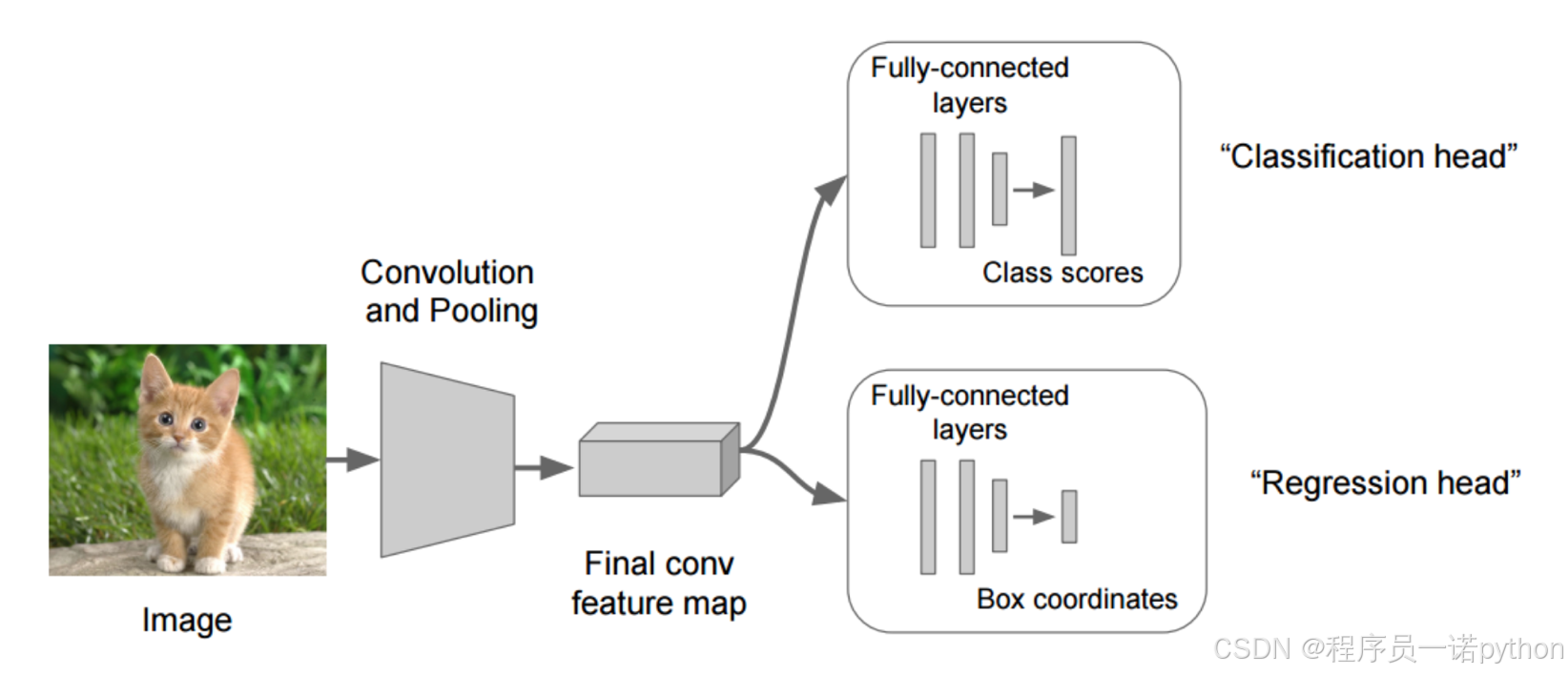
假设有10个类别,输出[p1,p2,p3,...,p10],然后输出这一个对象的四个位置信息[x,y,w,h]。同理知道要网络输出什么,如果衡量整个网络的损失
- 对于分类的概率,还是使用交叉熵损失
- 位置信息具体的数值,可使用MSE均方误差损失(L2损失)
如下图所示
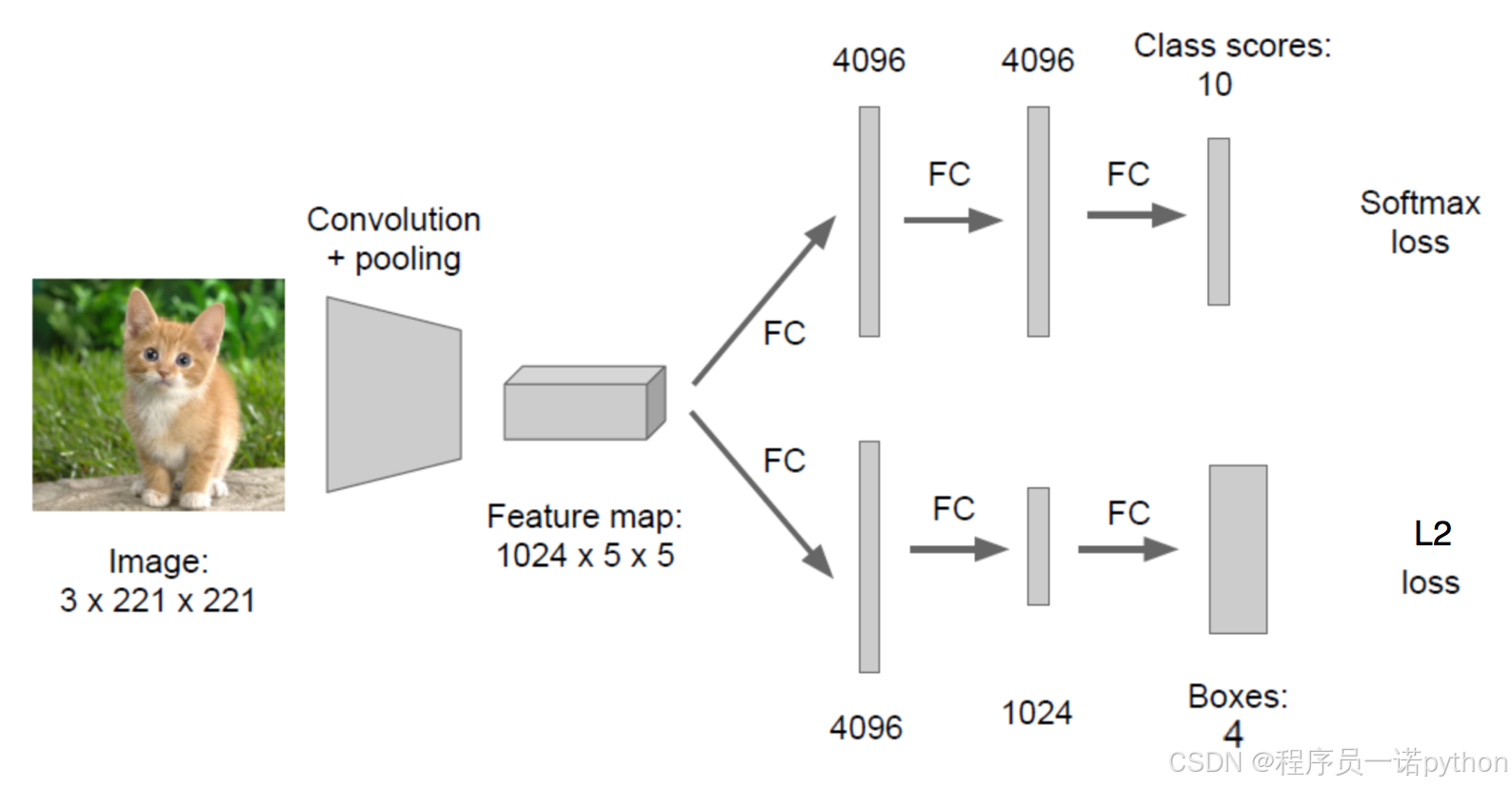
3.1.4.2 位置数值的处理
对于输出的位置信息是四个比较大的像素大小值,在回归的时候不适合。目前统一的做法是,每个位置除以图片本身像素大小。
假设以中心坐标方式,那么x = x/x_image,y/y_image, w/x_image,h/y_image,也就是这几个点最后都变成了0~1之间的值。
3.1.5 总结
- 掌握目标检测的算法分类
- 掌握分类,分类与定位,目标检测的区别
- 掌握分类与定位的简单方法、损失衡量

-1)



