目录
一、Create(创建)
1、全列插入和指定列插入
2、多行数据插入
3、插入冲突时更新
(1)duplicate
(2)replace into(替换)
二、 Retrieve(读取)
1、select列
(1)全列查询
(2)指定列查询
(3)查询字段为表达式
(4)为查询结果指定别名
(5)结果去重
2、where条件
3、 查询结果排序
4、筛选分页结果
三、Update(更新)
四、Delete(删除)
五、插入查询结构
六、聚合函数
七、group by使用
一、Create(创建)
##语法:
INSERT [ INTO ] table_name[( column [, column ] ...)]VALUES (value_list) [, (value_list)] ...value_list: value , [, value ] ...
1、全列插入和指定列插入
全列插入时不需要指定插入的列,直接写values
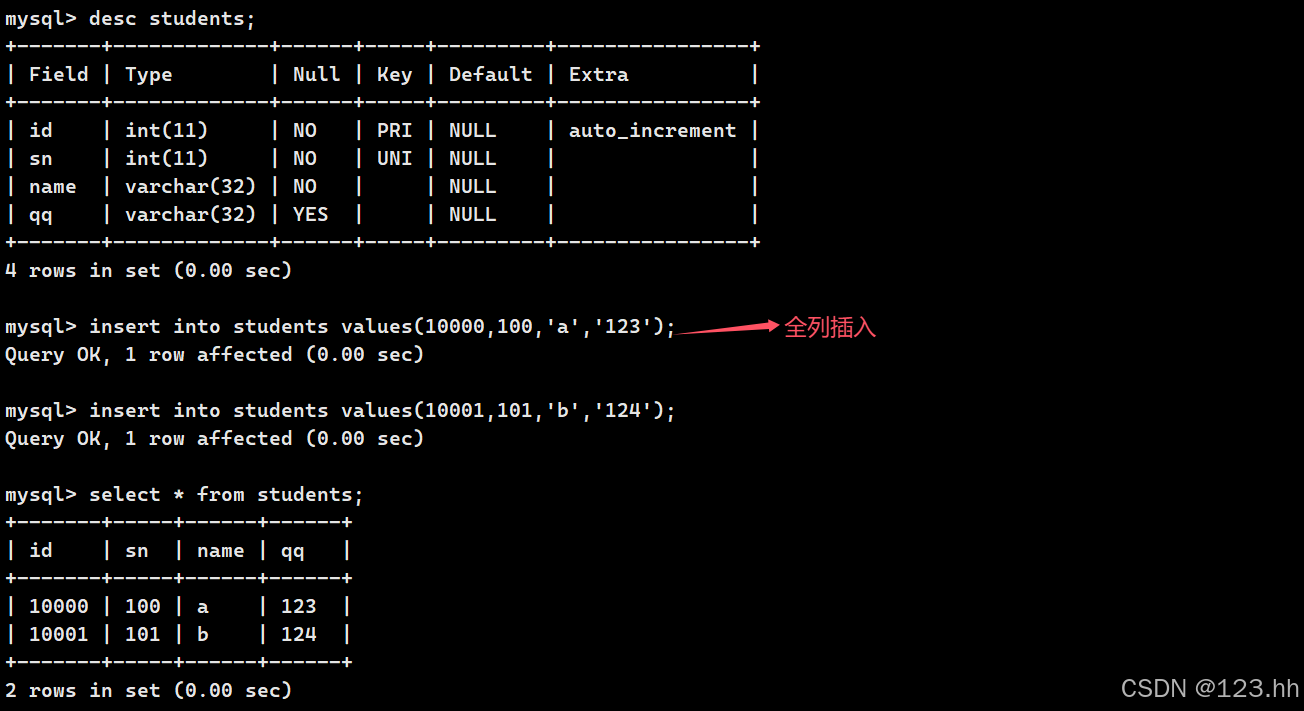
指定列插入需要指定插入的列和每一列对应的values
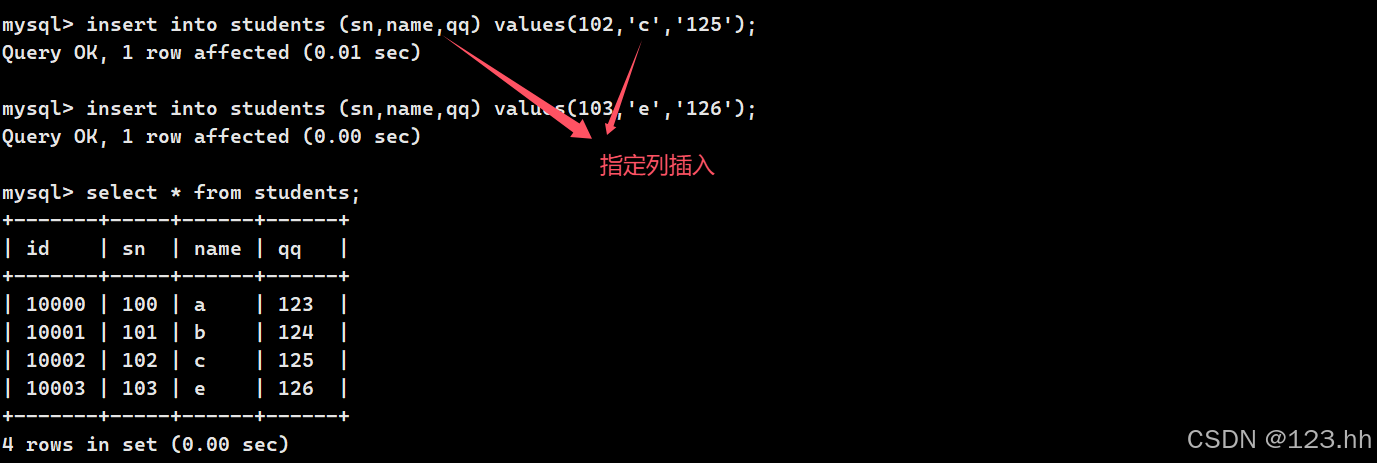
2、多行数据插入
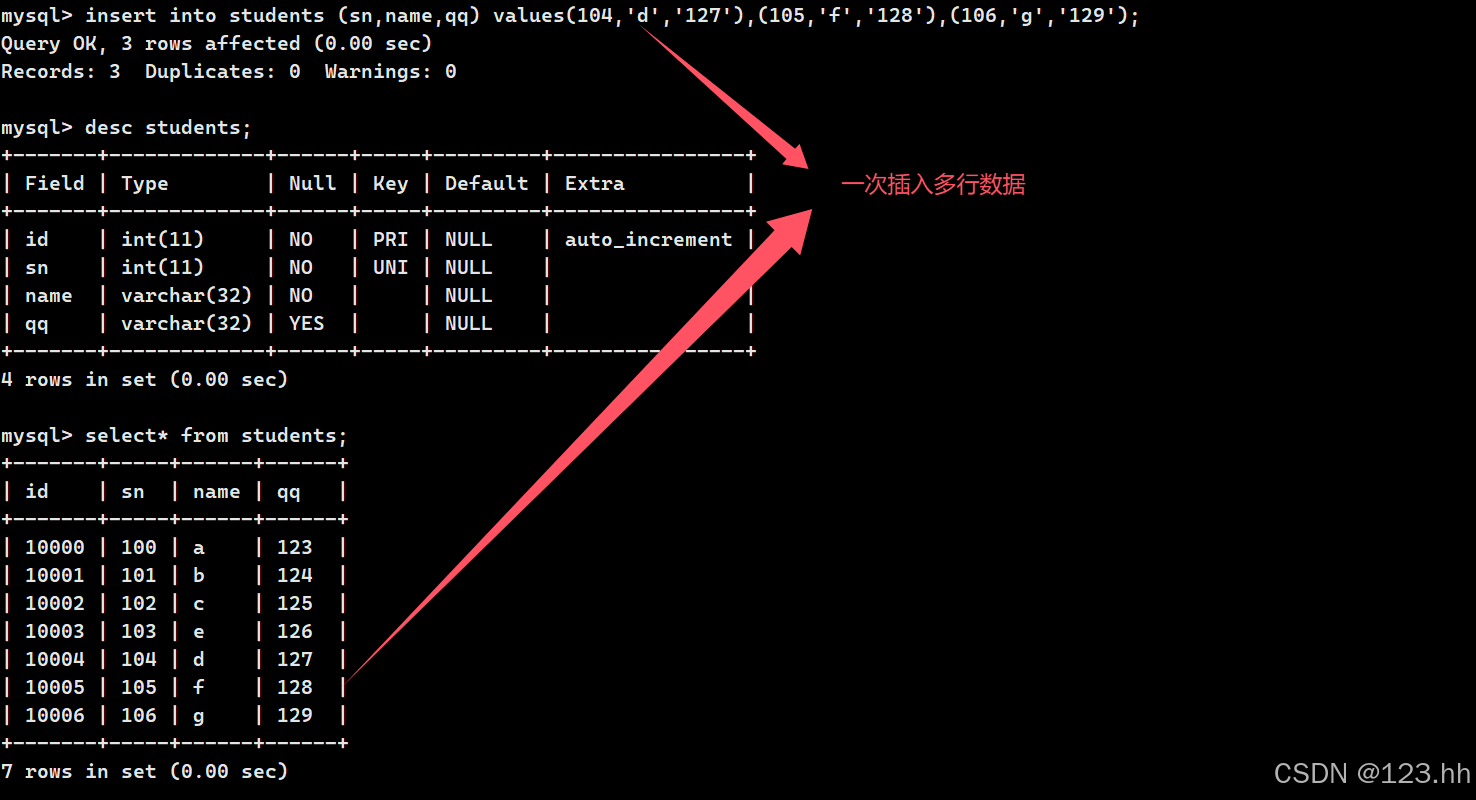
插入时可以一次性插入多行数据,并且可以全列或者指定列插入
3、插入冲突时更新
当插入一行数据时,可能和表中存在数据的主键或者唯一键冲突,此时就插入不成功;但是若想成功插入这个数据,就要使用特定的语句:
(1)duplicate
INSERT ... ON DUPLICATE KEY UPDATEcolumn = value [, column = value ] ...
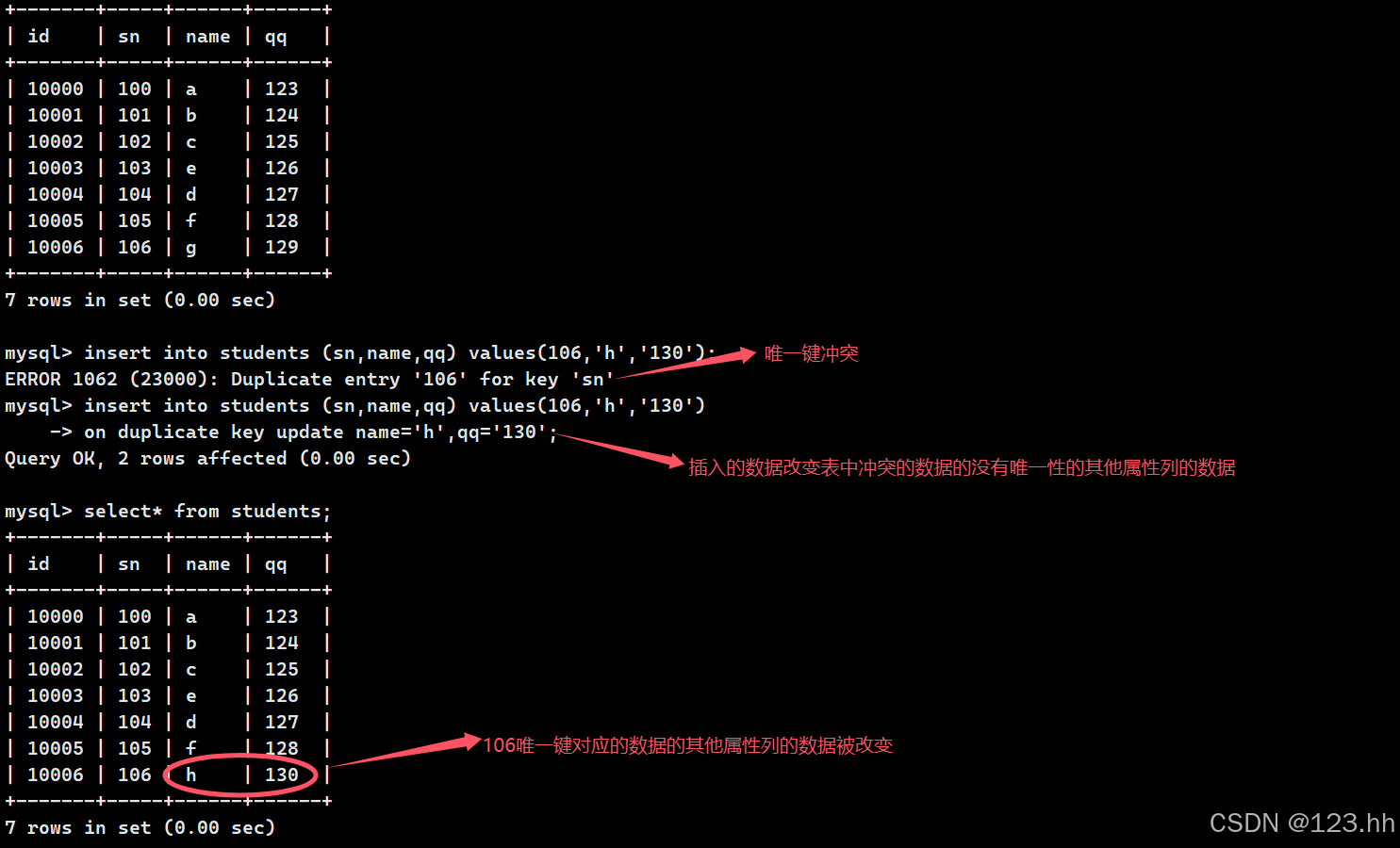

select row_count();查看被影响的行数

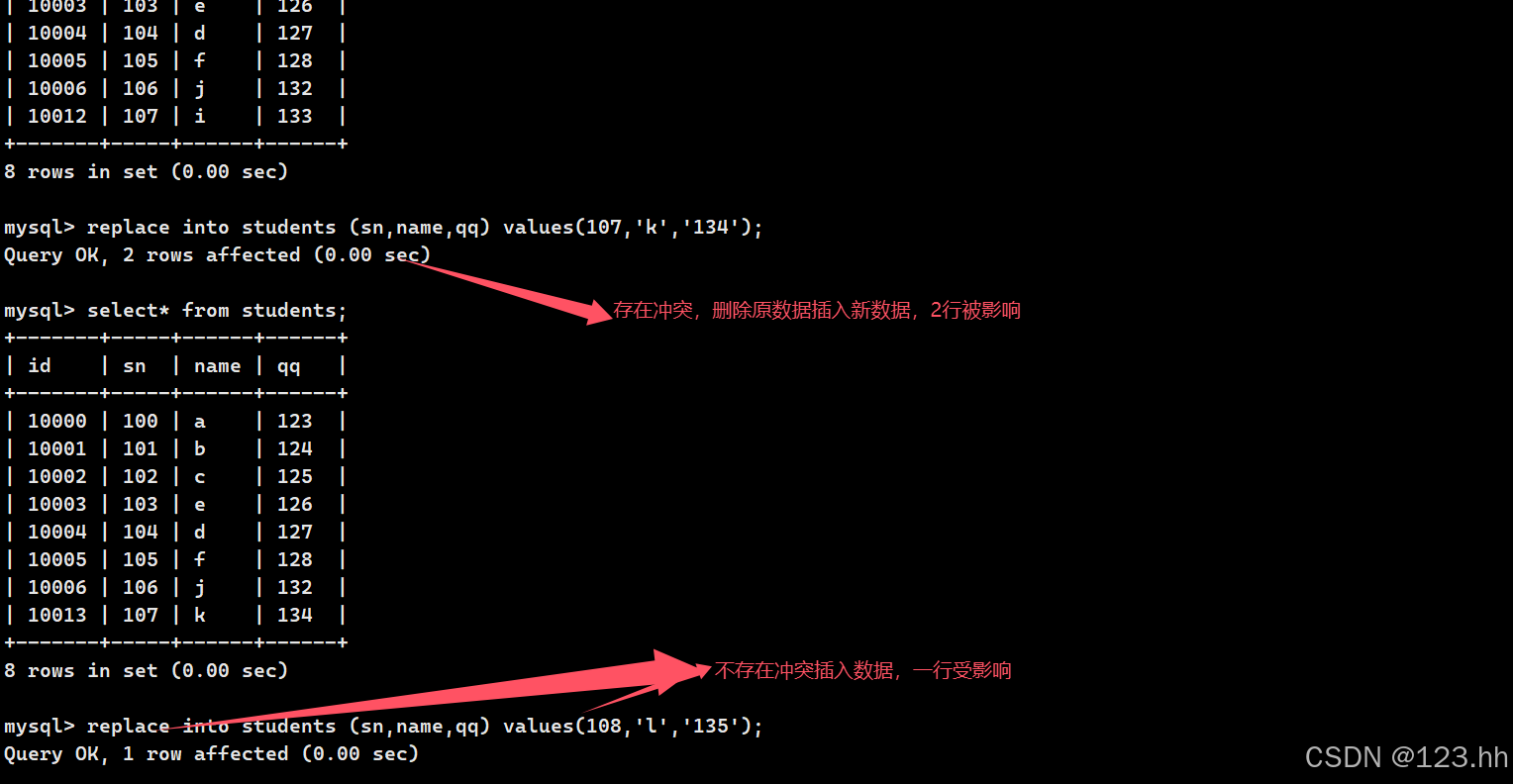
(2)replace into(替换)
插入数据时有冲突也可以使用replace替换,语法就是将插入时的insert改为replace

二、 Retrieve(读取)
##语法:
SELECT[DISTINCT] {* | {column [, column] ...}[FROM table_name][WHERE ...][ORDER BY column [ASC | DESC], ...]LIMIT ...
1、select列
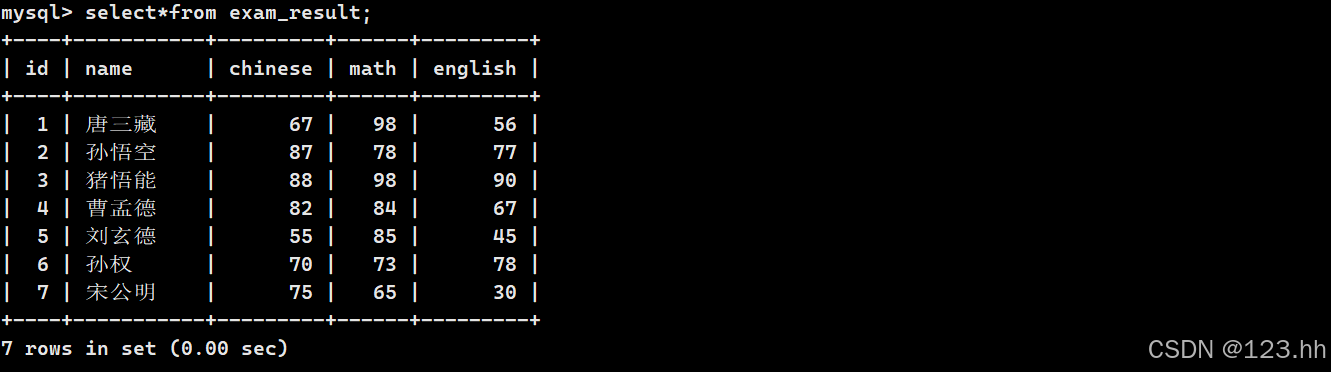
(1)全列查询
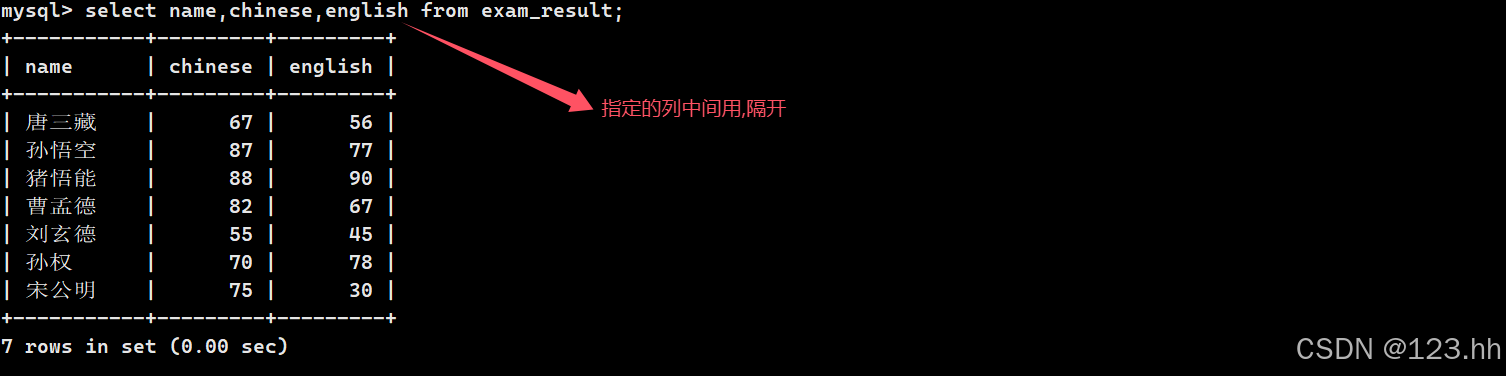
(2)指定列查询
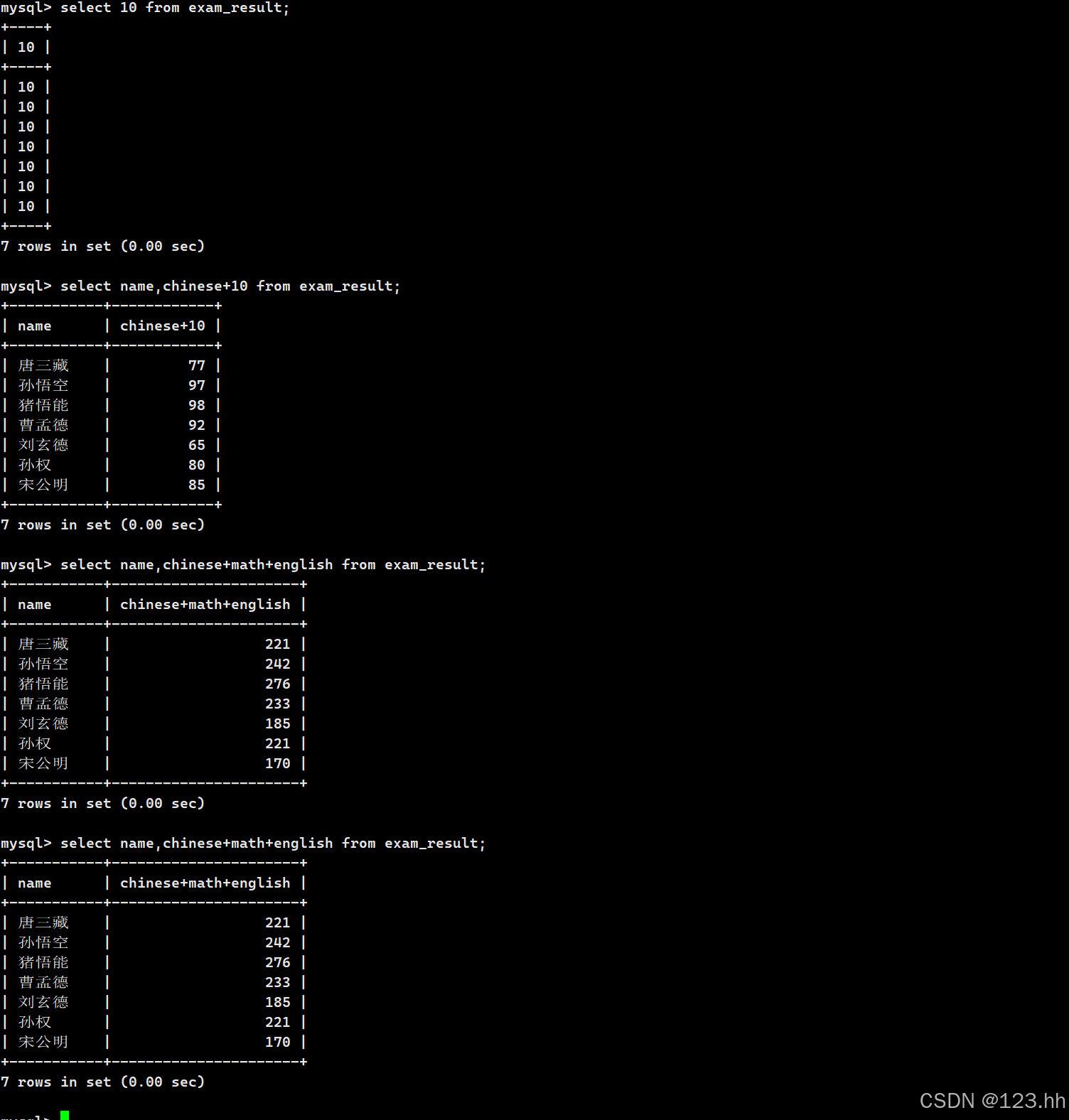
(3)查询字段为表达式
select后面跟的内容可以是表达式,查询完毕之后在表中可以显示这个表达式的结果
(4)为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;//as可以省略
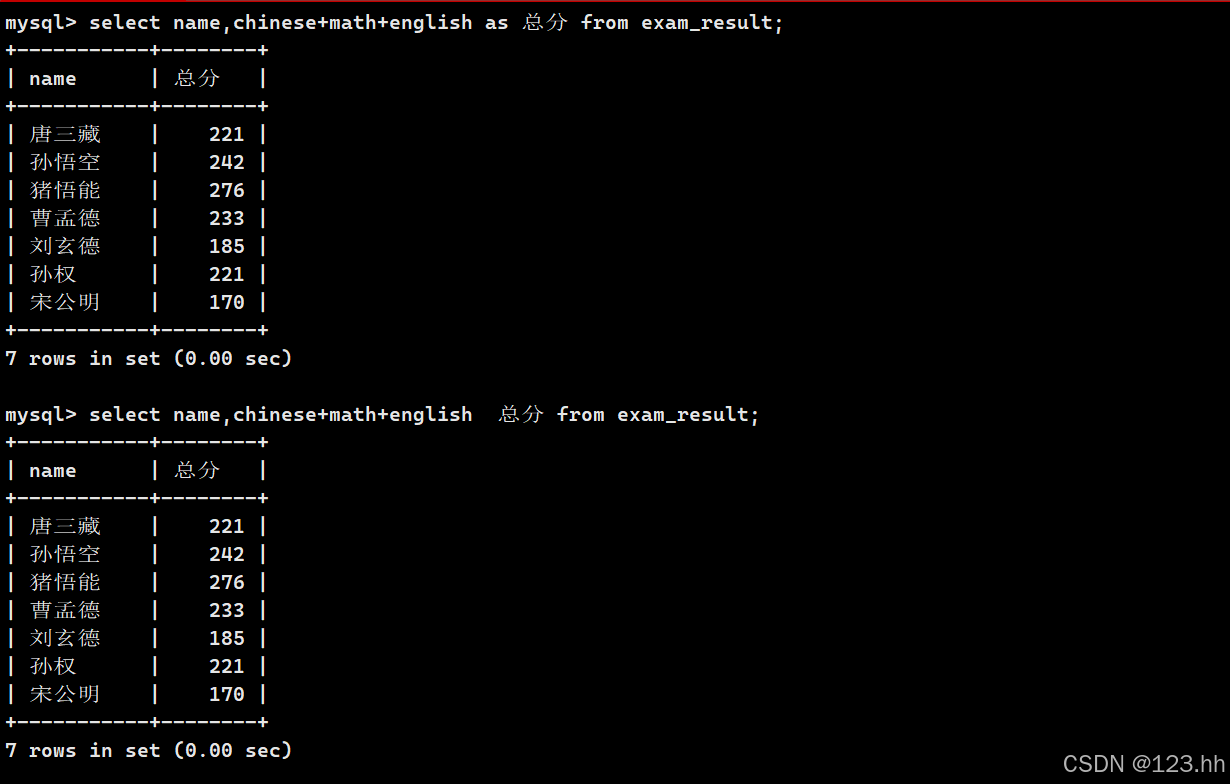
(5)结果去重
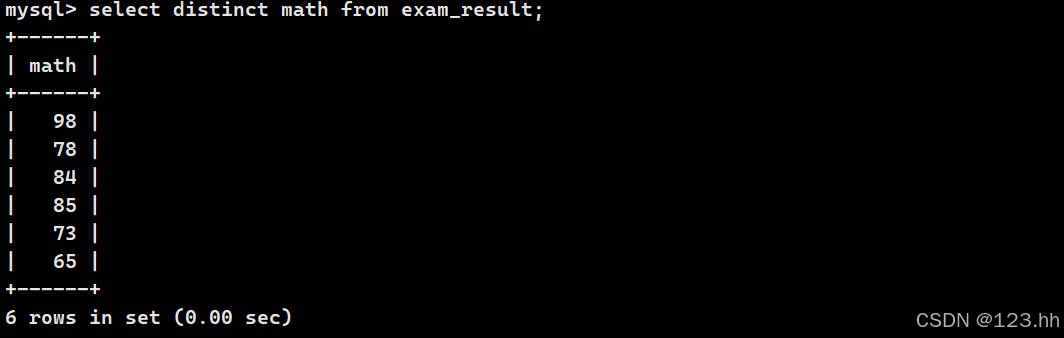
select后面加上distinct
2、where条件
where后面可接的比较运算符和逻辑运算符
比较运算符

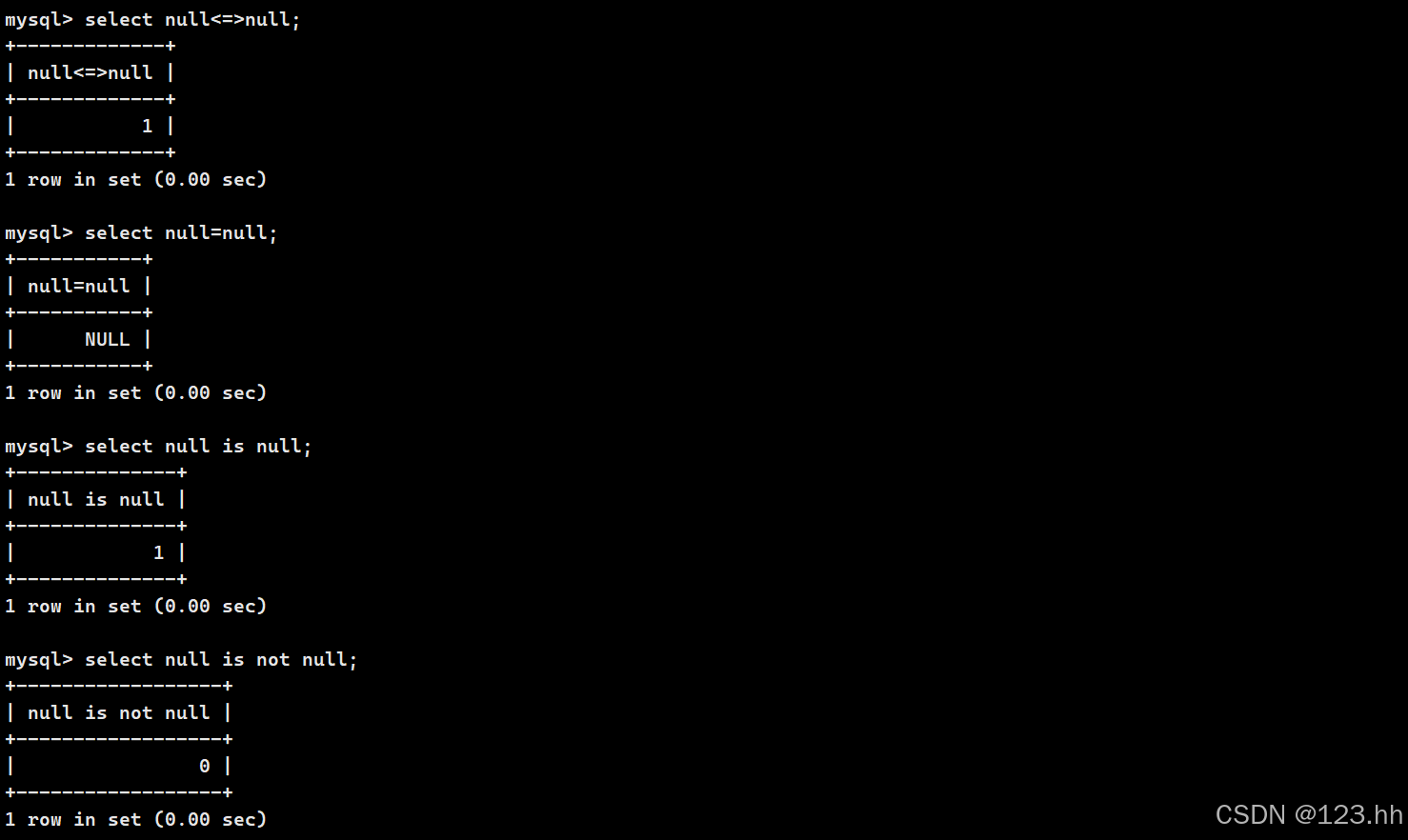
null安全不安全说的就是null能不能参与比较,只需要记住使用null进行判断时就用<=>、is null、is not null 就行了
逻辑运算符

使用where的案例
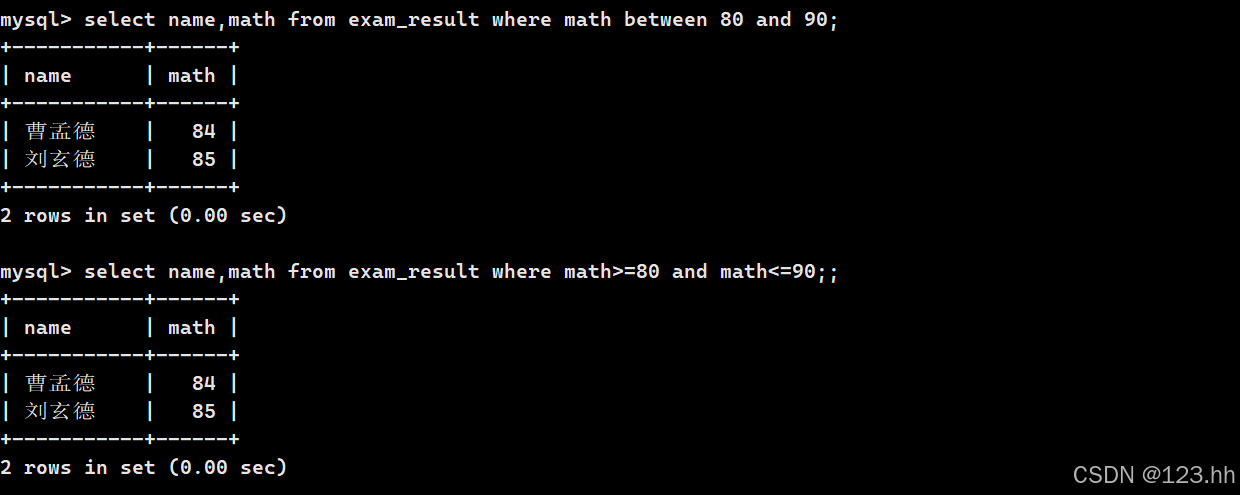
使用and逻辑运算符
in就是对或者or的简写
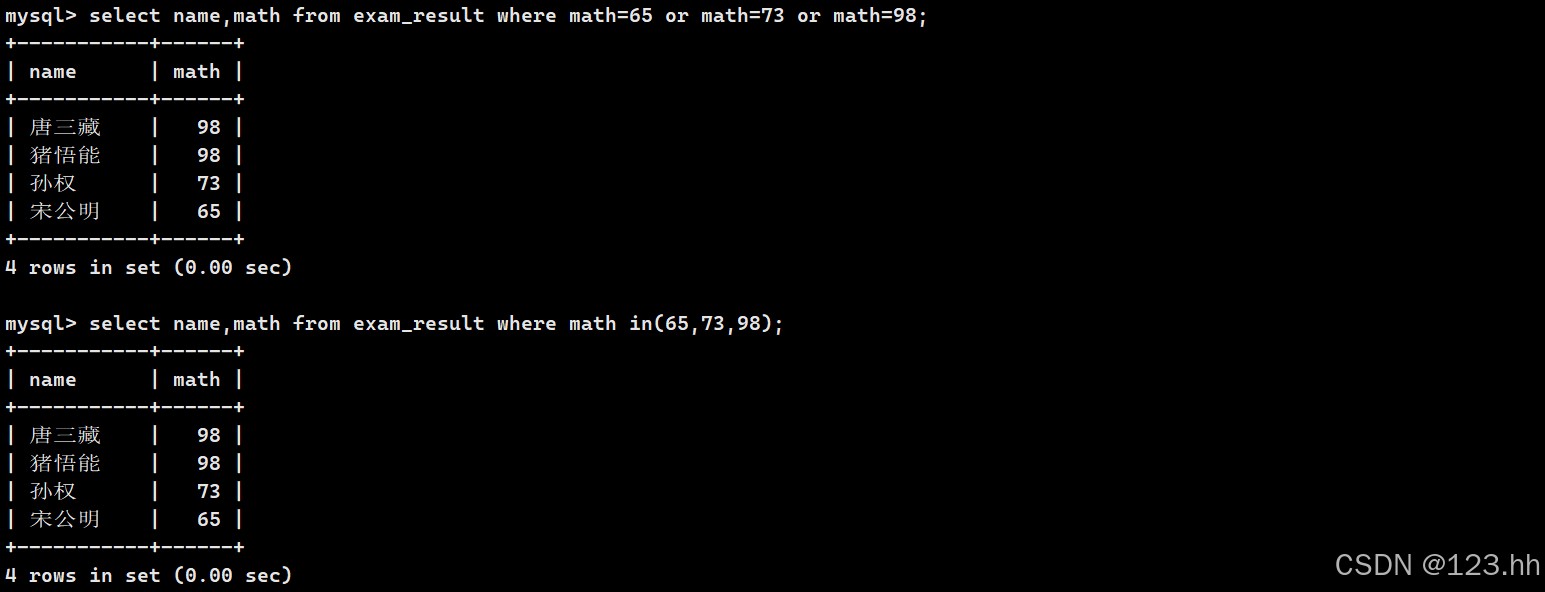
like模糊匹配
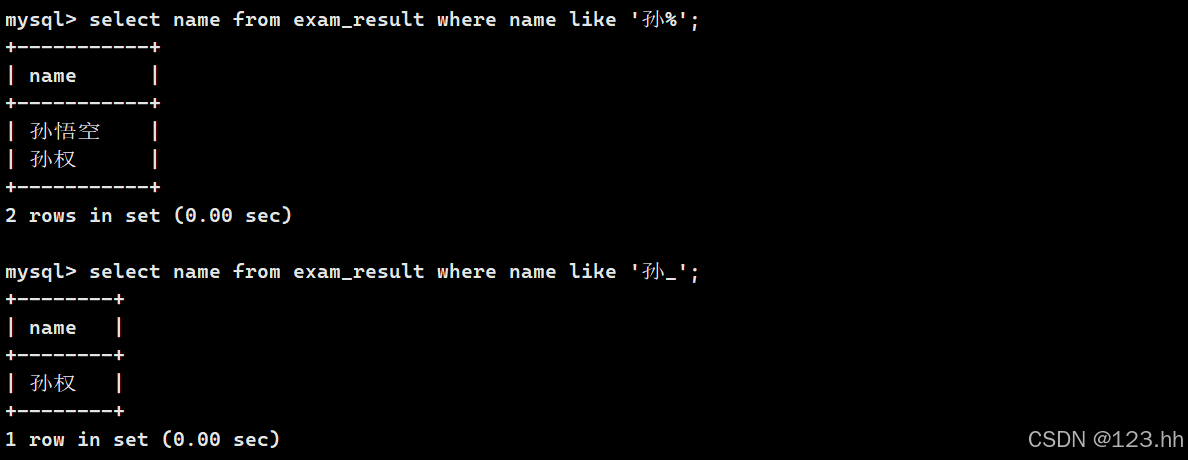
查询总分大于200的姓名
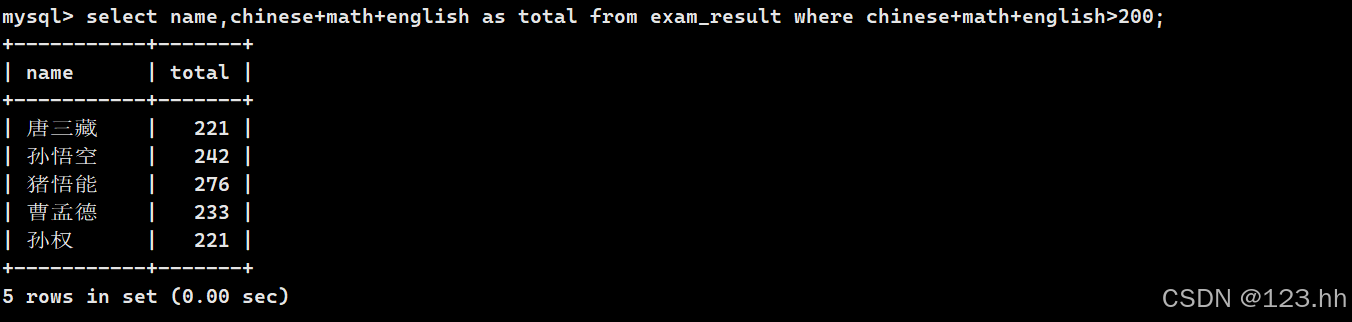
这个写法行吗? (查询时语句的顺序问题-1)
先确定从哪里找,在看条件是怎么找,最后再是找的具体内容
所以total是第三步出来的,但是where是第二部。
查询姓孙的,或者语文成绩大于数学成绩并且英语成绩小于80的
若是条件过多可以用()括起来为一部分的条件

3、 查询结果排序
语法:
-- ASC 为升序(从小到大)-- DESC 为降序(从大到小)-- 默认为 ASCSELECT ... FROM table_name [WHERE ...]ORDER BY column [ASC|DESC], [...];最好手动写是升序还是降序,即显示写asc或者desc
null默认是最小,升序时出现在最上面,降序时出现在最下面
几个案例:
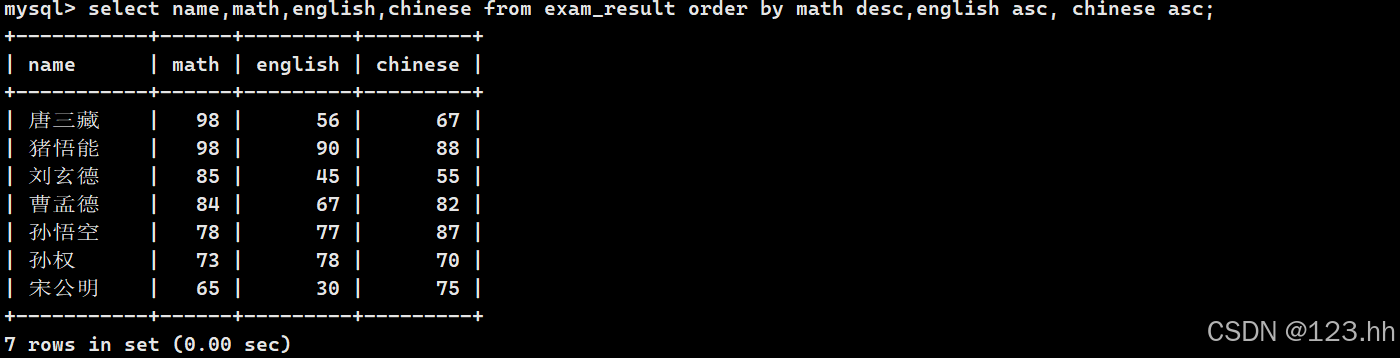
1、查询成绩,按照数学降序,英语升序,语文升序的顺序(即数学降序之后,若是有相同再去按照英语升序的排列;同理语文升序排序就是排的数学和英语成绩都相同的数据)
多个排出现时中间用逗号隔开
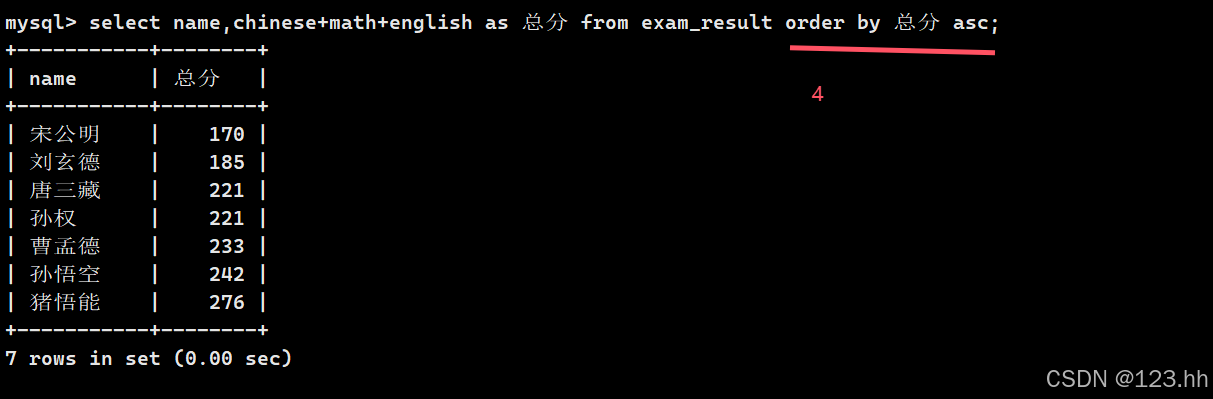
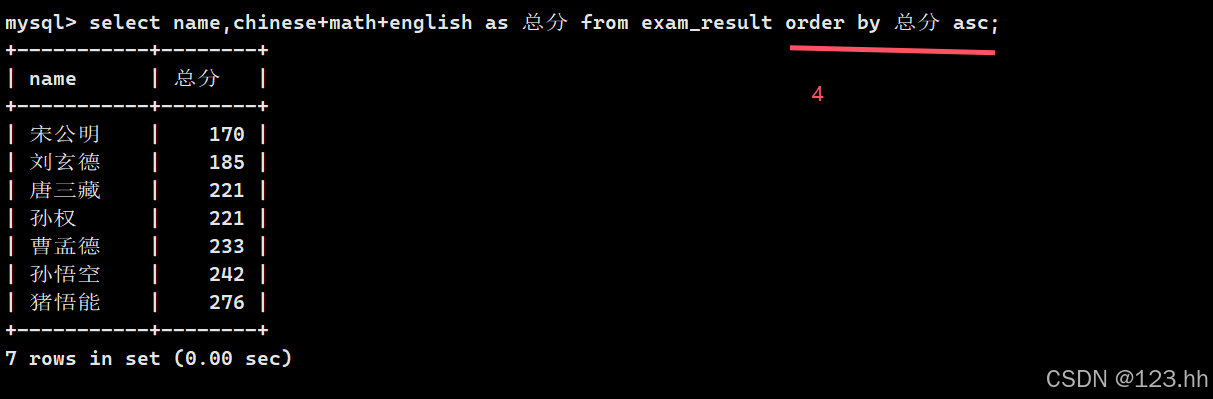
2、查询总分并且按照升序排序
这里需要注意的是,排序按照哪种顺序是第四步,第一步是先从哪里找,第二步是看查询条件where,第三步是看查找什么,最后是对查找的数据进行排序;(查找时语句顺序-2)
所以这里可以使用 总分 来排序;
这样也是合乎情理的,因为先排序在查找会有浪费,因为排序了我们不需要的数据;
3、查询姓孙或者姓曹的姓名和数学成绩并且按照数学成绩降序排序
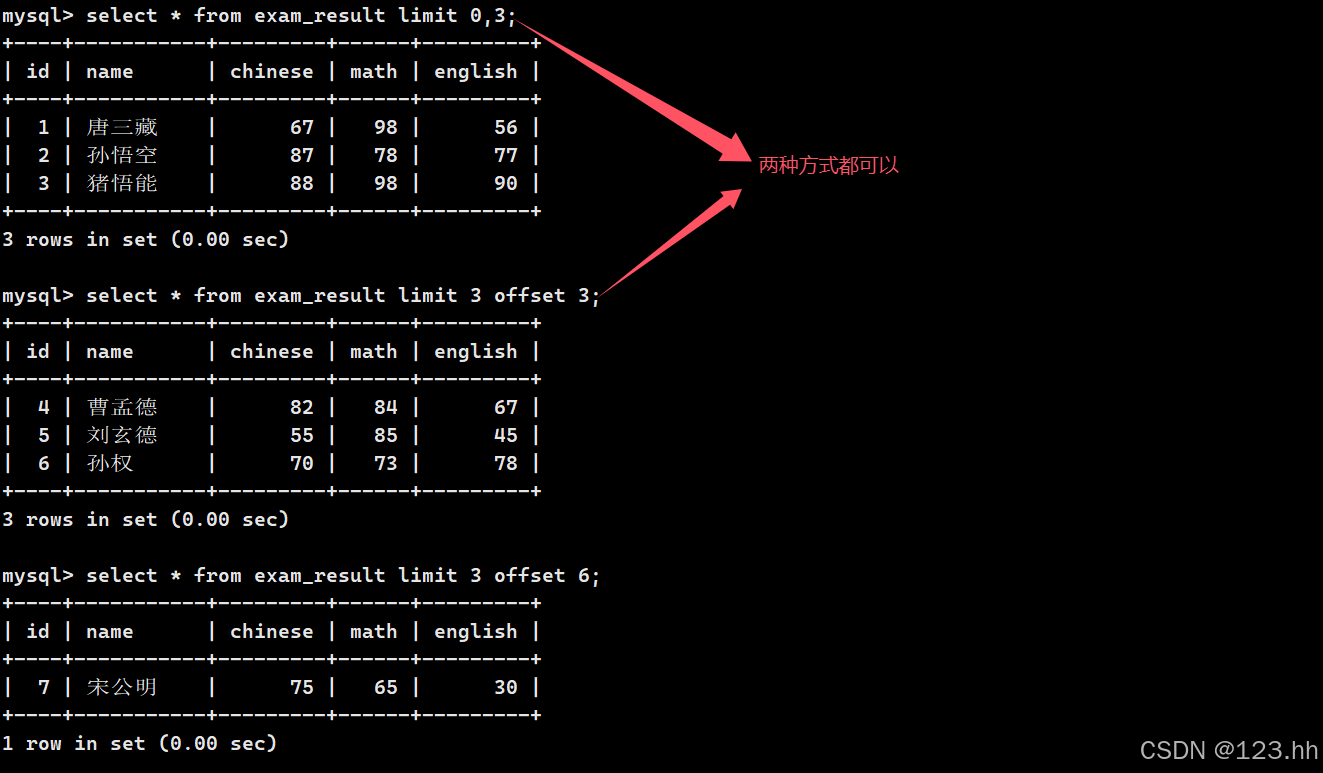
4、筛选分页结果
语法:
-- 起始下标为 0-- 从 s 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n-- 从 0 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
指定查询几行:
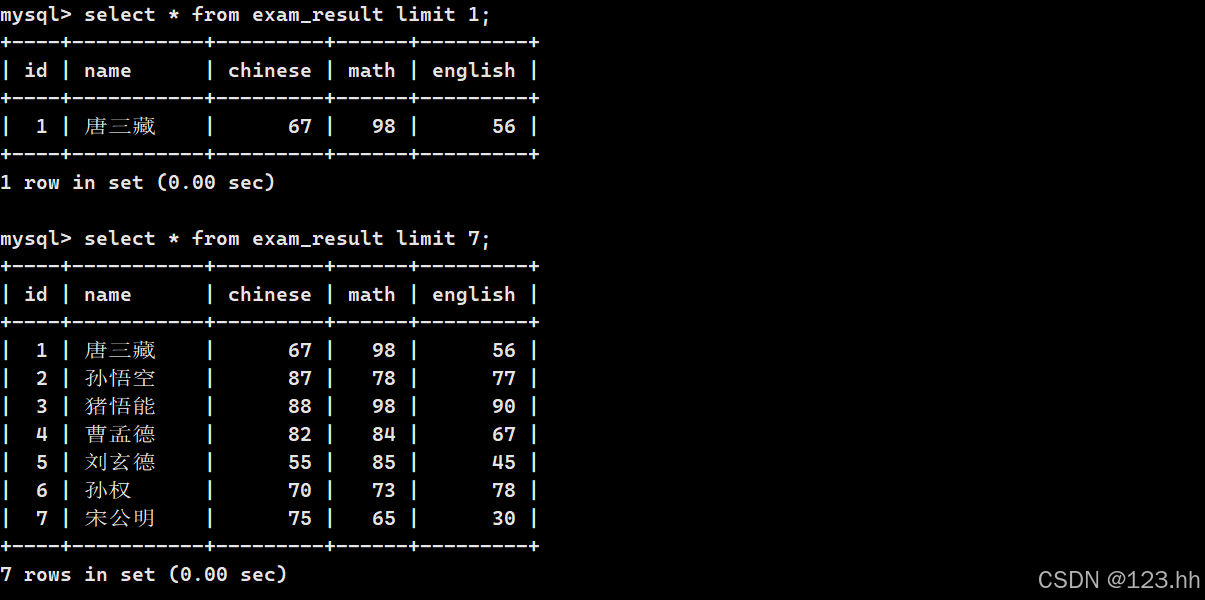
指定从哪页开查询,并且查询几行
三、Update(更新)
语法 :
UPDATE table_name SET column = expr [, column = expr ...][WHERE ...] [ORDER BY ...] [LIMIT ...]
##举例:

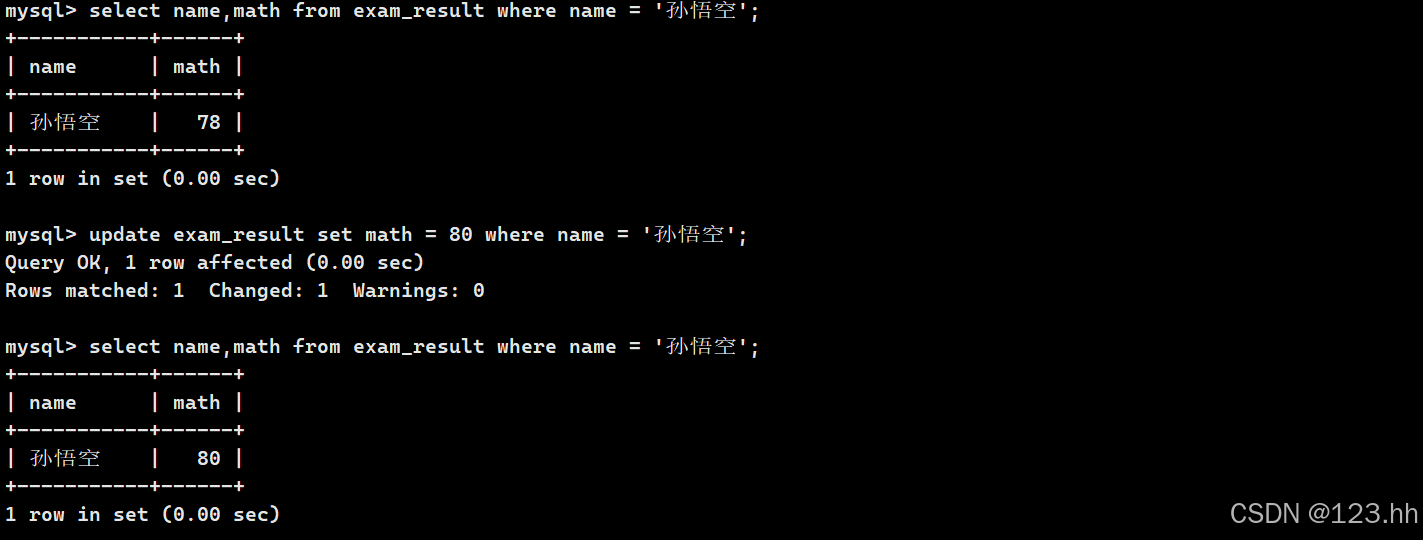
1、将孙悟空同学的数学成绩改为80分
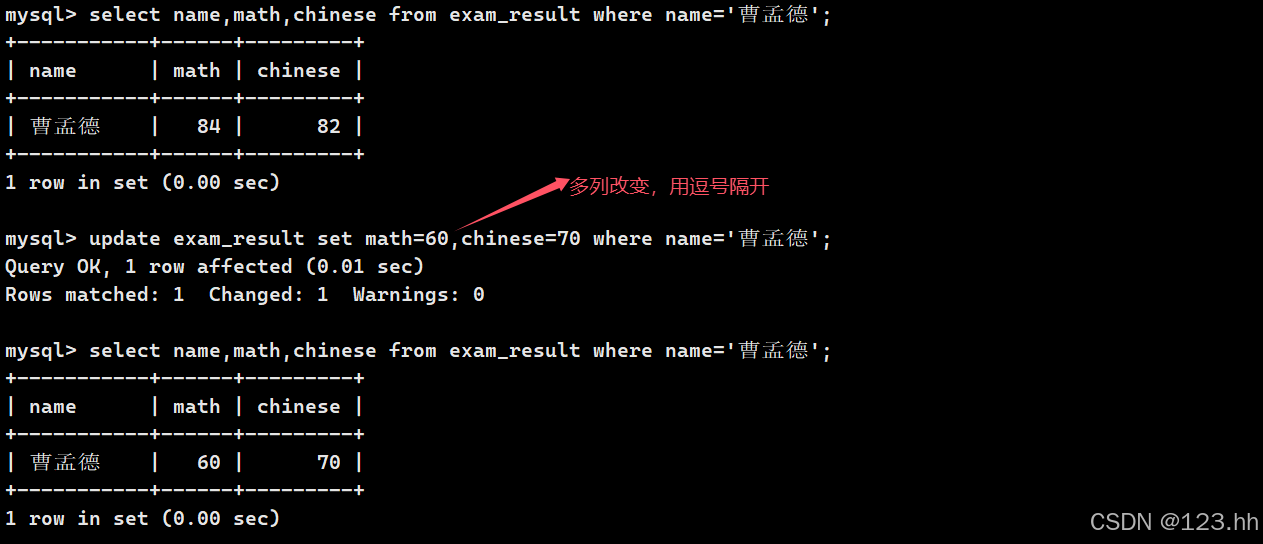
2、将曹孟德同学数学成绩改为60,语文成绩改为70
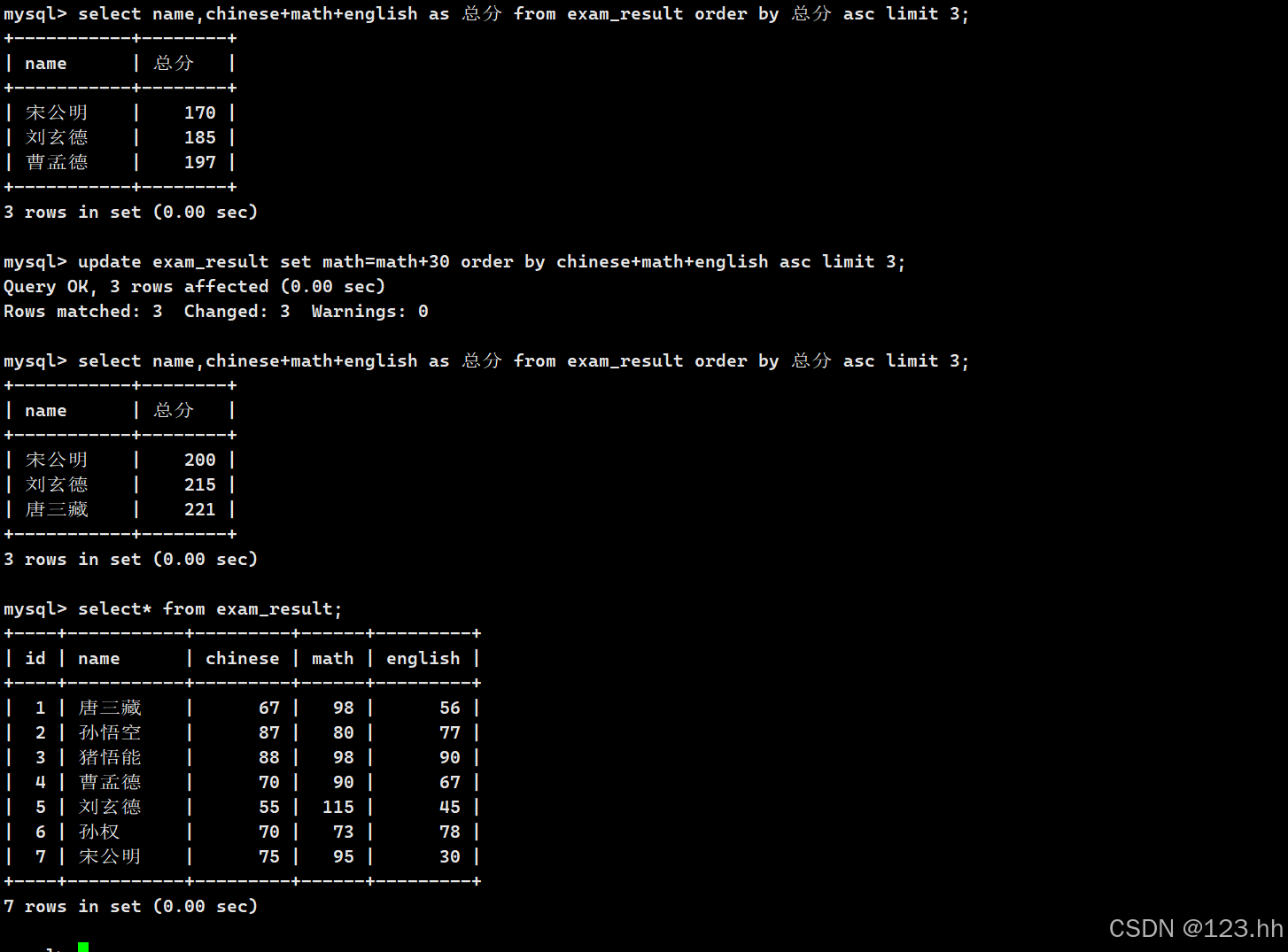
3、将总成绩倒数前3的数学成绩加30分
注意:update是最后更新的(因为更新要先按照条件找出更新的是哪些,即使是orderby或者limit也是更新的范围条件,所以更新顺序在最后);MySQL不支持math+=30,只能写math=math+30;
4、将所有同学的语文成绩改为原来的两倍

四、Delete(删除)
语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
##举例:
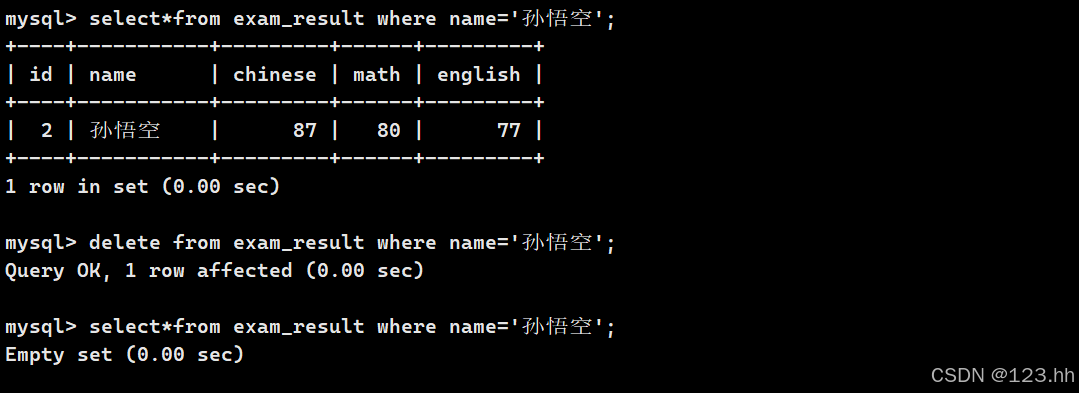
1、删除孙悟空的成绩
注意:delete也是在最后执行的,原因和update一样
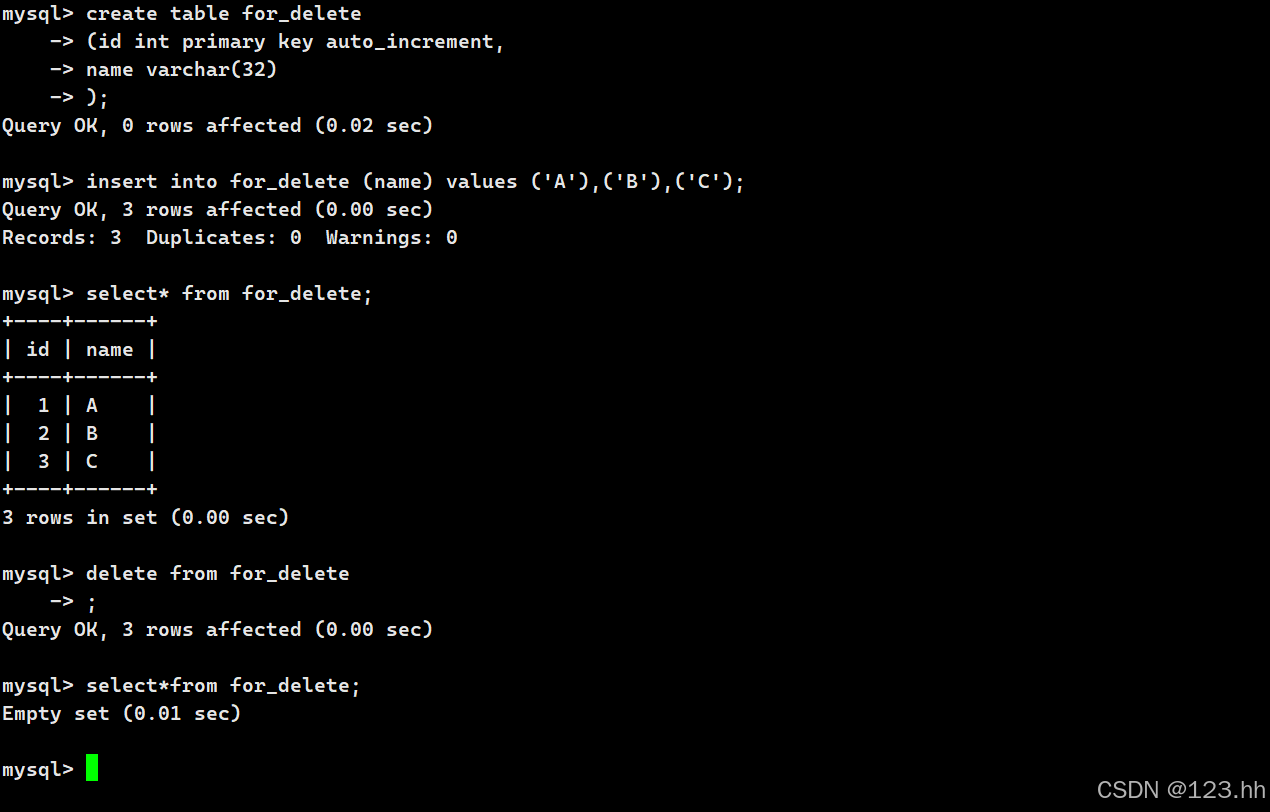
2、删除整张表数据
(1)delete from table_name;删除整张表数据;删除之后查看创建表内容时,有anto_increment内容

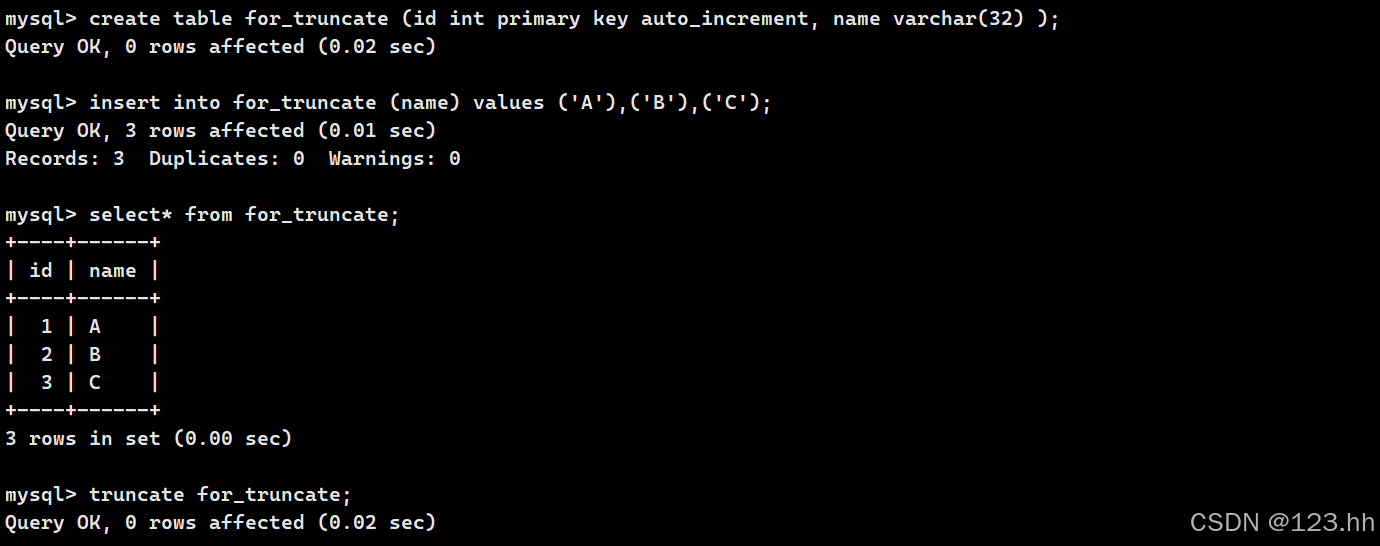
(2)truncate截断表

五、插入查询结构
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...
也就是插入表中的数据可以是select查询到的数据
案例:去除表中重复数据,将无重复数据放入新表中,再将新表重命名为原表的名称完成去重

表重命名操作直接使用RENAME TABLE old_table_name TO new_table_name; 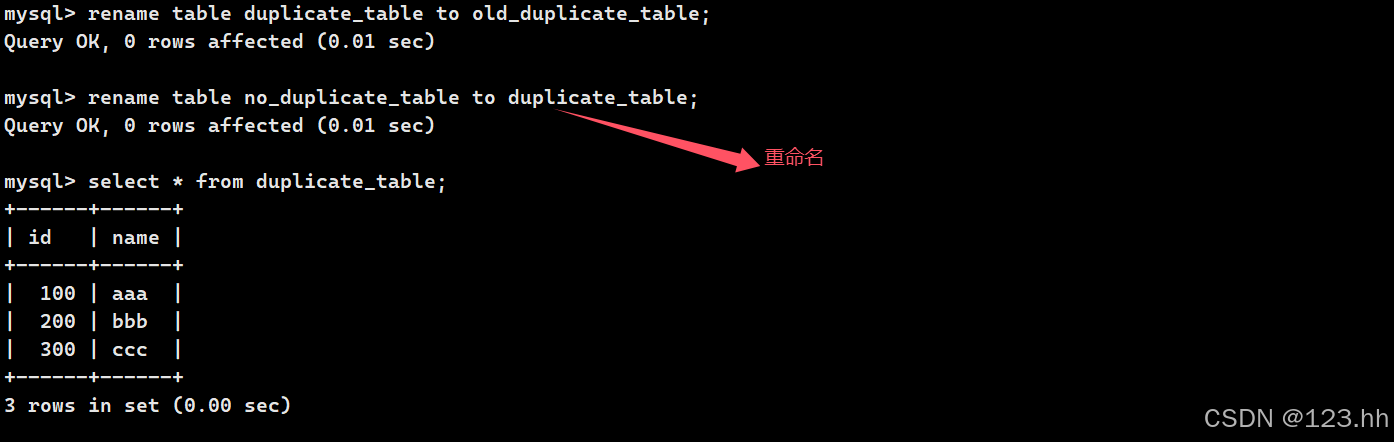
六、聚合函数

示例:
1、统计考试的有多少人?
用count(*) 不受null影响
用表达式作统计 count(1)

2、统计本次考试不同数学成绩的个数
意味着要进行去重
disdinct放在列名前面才能进行去重约束,而不是放在聚合函数前面
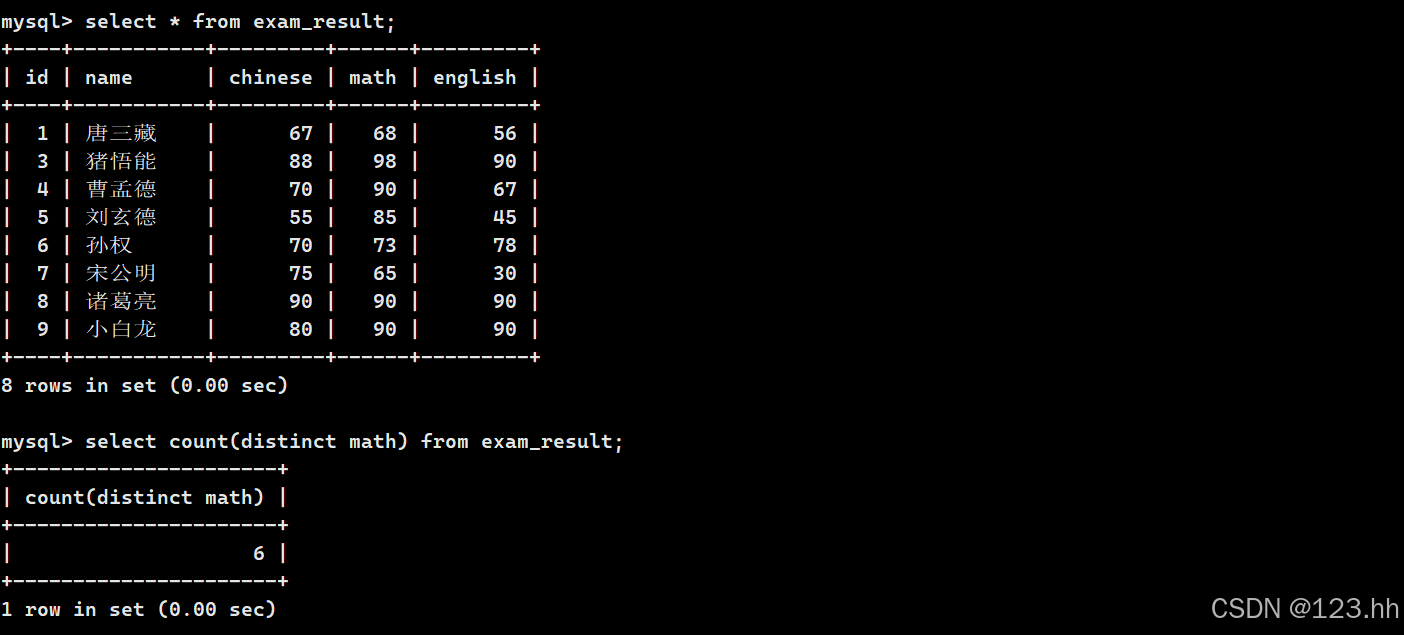
3、统计数学成绩总分
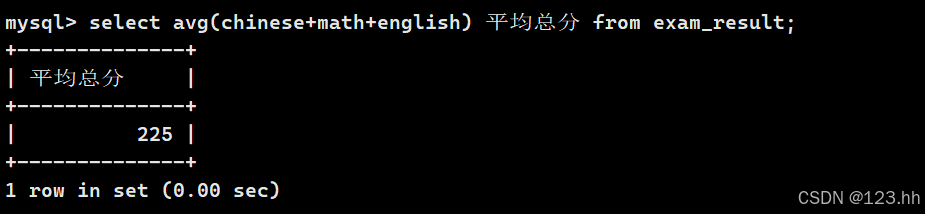
 4、统计平均总分
4、统计平均总分
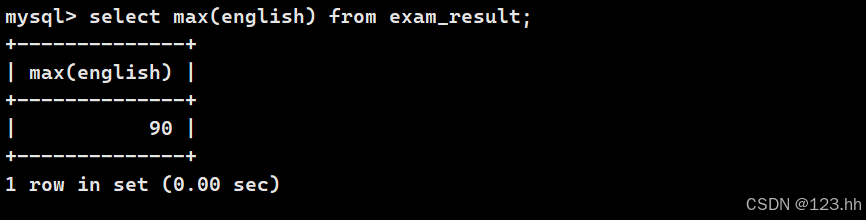
5、返回英语最高分
 6、返回数学成绩大于70分的数学最低分
6、返回数学成绩大于70分的数学最低分

七、group by使用
select column1, column2, .. from table group by column;
聚合函数使用是必须能聚合,也就是说有相同的部分,使用group by通过对某一列的值的不同分组,将不同的值及其相关的数据分到一个组,相当于创建了一个逻辑子表,这个表的一列的值都相同(这一列就是之前分组的列)
因为这个列名是作为分组依据的,很多行记录的这一列属性的值都相同,这一列有被聚合的能力,所以使用聚合函数时这个列名可以写在select后面
示例:
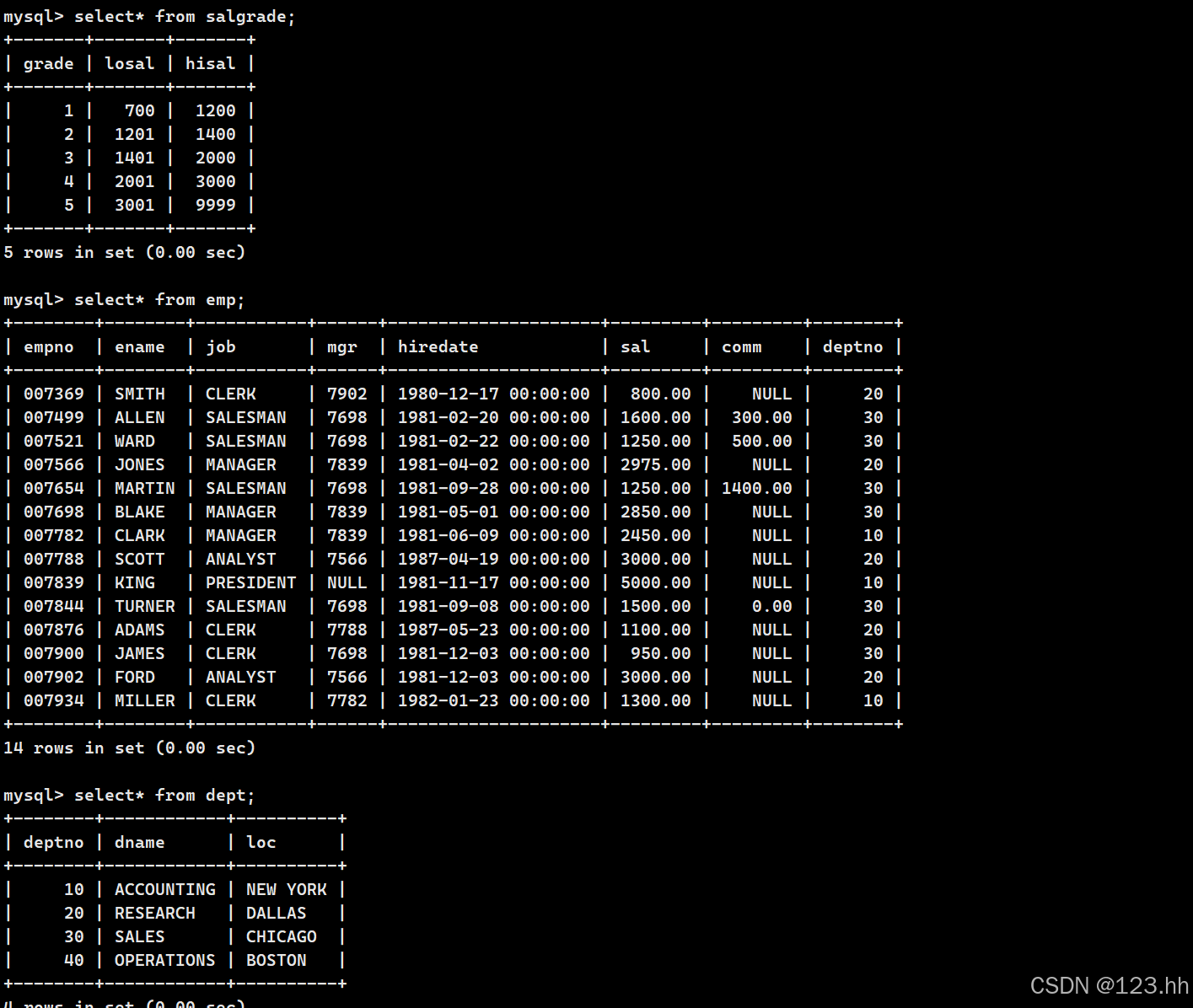
1、显示每个部门的最高工资和最低工资
将相同部门的先分组,再去使用聚合函数,此时deptno可以和聚合函数一起显示,因为deptno是作为分组依据的列,一个部门可以被许多员工共有
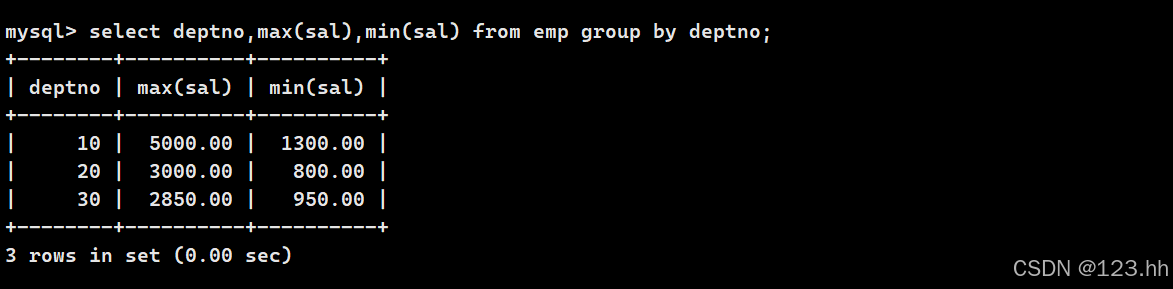
若是要加上姓名的话不行,因为ename 没有被聚合的能力,每个人的名字很多不同

2、显示每个部分每种岗位的平均工资和最低工资
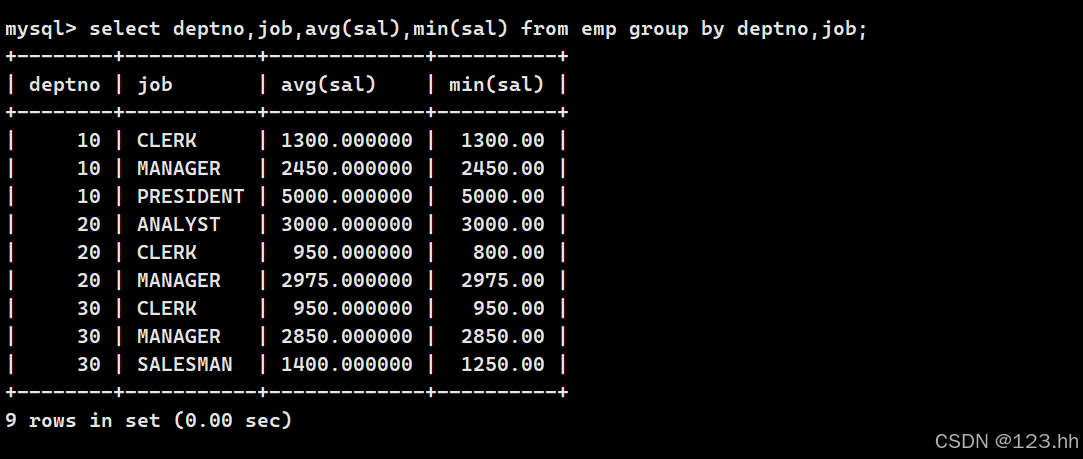
3、显示平均工资低于两千的部门以及它的平均工资
使用having进行条件筛选,having经常和group by一起使用

having和where很像,但是是有本质区别的





