DayDreamer:用于物理机器人学习的世界模型
Philipp Wu* Alejandro Escontrela* Danijar Hafner* Ken Goldberg Pieter Abbeel 加州大学伯克利分校 *贡献相同
摘要:为了在复杂环境中完成任务,机器人需要从经验中学习。深度强化学习是机器人学习的一种常见方法,但它需要大量的试错来学习,限制了其在物理世界中的部署。因此,许多机器人学习的进步依赖于模拟器。然而,在模拟器中学习无法捕捉现实世界的复杂性,容易受到模拟器不准确的影响,而且产生的行为无法适应世界的变化。最近的Dreamer算法通过在学习到的世界模型中进行规划,仅需少量交互即可学习,在视频游戏中超越了纯强化学习。通过学习世界模型来预测潜在动作的结果,可以在想象中进行规划,减少在现实环境中所需的试错次数。然而,尚不清楚Dreamer是否能够促进物理机器人的更快学习。在本文中,我们将Dreamer应用于4个机器人,直接在现实世界中在线学习,无需任何模拟器。Dreamer训练一个四足机器人从零开始,在没有重置的情况下,仅用1小时就能翻滚、站立和行走。然后我们推动机器人,发现Dreamer在10分钟内适应,能够抵抗干扰或快速翻滚并重新站立。在两个不同的机械臂上,Dreamer直接从相机图像和稀疏奖励中学习拾取和放置多个物体,接近人类表现。在一个轮式机器人上,Dreamer仅从相机图像中学习导航到目标位置,自动解决机器人方向的模糊性。在所有实验中使用相同的超参数,我们发现Dreamer能够在现实世界中进行在线学习,这为现实世界中的机器人学习建立了一个强大的基准。我们发布了基础设施,以便将来将世界模型应用于机器人学习。视频可在项目网站上找到:Redirecting…
图1:为了研究Dreamer在样本高效机器人学习中的适用性,我们将该算法应用于4个机器人,直接在现实世界中从零开始学习机器人运动、操作和导航任务,无需模拟器。这些任务评估了多种挑战,包括连续和离散动作、密集和稀疏奖励、本体感知和相机输入,以及多种输入模态的传感器融合。在所有实验中成功使用相同的超参数,Dreamer为现实世界中的机器人学习建立了一个强大的基准。
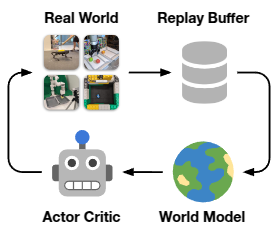
图2:Dreamer遵循一个简单的流程,在没有模拟器的情况下在机器人硬件上进行在线学习。当前学习到的策略在机器人上收集经验。这些经验被添加到重放缓冲区。世界模型通过监督学习在重放缓冲区的离策略序列上进行训练。演员批评家算法从世界模型的潜在空间中想象的轨迹中优化神经网络策略。我们并行化数据收集和神经网络学习,以便在机器人移动时继续学习步骤,并实现低延迟动作计算。

在现实世界中教授机器人解决复杂任务是机器人研究的一个基础性问题。深度强化学习(RL)提供了一种流行的机器人学习方法,使机器人能够通过试错随时间改进其行为。然而,当前的算法需要与环境进行过多的交互才能学习成功的行为,这使得它们在许多现实世界任务中不切实际。最近,现代世界模型在模拟领域和视频游戏中展示了数据高效学习的巨大潜力(Hafner等,2019;2020)。从过去的经验中学习世界模型使机器人能够想象潜在动作的未来结果,减少在现实环境中学习成功行为所需的试错次数。
尽管学习准确的世界模型具有挑战性,但它们为机器人学习提供了引人注目的特性。通过预测未来结果,世界模型允许在仅进行少量现实世界交互的情况下进行规划和行为学习(Gal等,2016;Ebert等,2018)。此外,世界模型总结了关于环境的一般动态知识,一旦学会,就可以用于多种下游任务(Sekar等,2020)。世界模型还学习融合多种传感器模态的表示,并将它们整合到潜在状态中,从而无需手动状态估计。最后,世界模型能够很好地从可用的离线数据中泛化(Yu等,2021),这可以进一步加速现实世界中的学习。
尽管世界模型前景广阔,但为现实世界学习准确的世界模型是一个巨大的开放性挑战。在本文中,我们利用Dreamer世界模型的最新进展,用于训练各种机器人,采用最直接和基础的问题设置:在没有模拟器或演示的情况下,在现实世界中进行在线强化学习。如图2所示,Dreamer从过去经验的重放缓冲区中学习世界模型,从世界模型的潜在空间中想象的轨迹中学习行为,并不断与环境交互以探索和改进其行为。我们的目标是推动直接在现实世界中进行机器人学习的极限,并提供一个稳健的平台,以促进未来工作开发世界模型对机器人学习的好处。本文的主要贡献总结如下:
-
机器人上的Dreamer:我们将Dreamer应用于4个机器人,证明了在没有引入新算法的情况下直接在现实世界中成功学习。任务涵盖了多种挑战,包括不同的动作空间、感官模态和奖励结构。
-
1小时内行走:我们从零开始在现实世界中教授四足机器人,在1小时内翻滚、站立和行走。之后,我们发现机器人在10分钟内适应被推动,学习抵抗推动或快速翻滚并重新站立。
-
视觉拾取和放置:我们训练机械臂从稀疏奖励中拾取和放置物体,这需要从像素中定位物体并融合图像与本体感知输入。学习到的行为超越了无模型智能体,并接近人类表现。
-
开源:我们公开发布了所有实验的软件基础设施,支持不同的动作空间和感官模态,为未来在现实世界中将世界模型应用于机器人学习提供了灵活的平台。
2 方法
我们利用Dreamer算法(Hafner等,2019;2020)在没有模拟器的情况下在物理机器人上进行在线学习。本节总结了通用算法以及机器人实验所需的训练架构和传感器融合的细节。图2展示了方法的概述。Dreamer从过去经验的重放缓冲区中学习世界模型,使用演员批评家算法从学习到的模型预测的轨迹中学习行为,并在环境中部署其行为以不断扩展重放缓冲区。我们分离学习更新和数据收集以满足延迟要求,并实现快速训练而无需等待环境。在我们的实现中,一个学习线程持续训练世界模型和演员批评家行为,同时一个演员线程并行计算环境交互的动作。
世界模型学习:世界模型是一个深度神经网络,用于学习预测环境动态,如图3(左)所示。
图3:神经网络训练我们利用梦想家算法(Hafner等,2019; 2020)在现实世界中进行快速的机器人学习。 Dreamer由两个神经网络组件组成。左:世界模型遵循了一个深卡尔曼滤波器的结构,该滤波器是在重播缓冲区中绘制的子序列中训练的。编码器将所有感官模式融合到离散编码中。解码器重建来自编码的输入,提供丰富的学习信号并实现人类对模型预测的检查。训练了一个经常性状态空间模型(RSSM),以预测给定的动作的未来代码,而无需观察中间输入。右:世界模型可以使用较大的批量大小从紧凑的潜在空间中想象中的推出进行大规模并行策略优化,而无需重建感觉输入。 Dreamer从想象中的推出和学习的奖励函数训练政策网络和价值网络
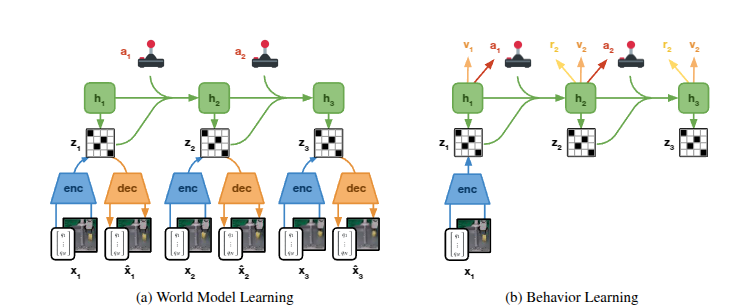
由于感官输入可能是大型图像,我们预测未来的表示而不是未来的输入。这减少了累积误差,并允许使用大批次进行大规模并行训练。因此,世界模型可以被视为机器人从空白开始并随着其在现实世界中探索而不断改进模型的快速环境模拟器。世界模型基于递归状态空间模型(RSSM;Hafner等,2018),包括四个组件: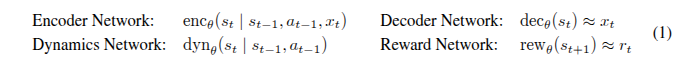
物理机器人通常配备有不同模态的多种传感器,例如本体感知关节读数、力传感器以及高维输入,如RGB和深度相机图像。编码器网络将所有感官输入xt融合到随机表示zt中。动态模型使用其递归状态ht学习预测随机表示的序列。解码器重建感官输入,以提供丰富的信号用于学习表示,并使人类能够检查模型预测,但在从潜在轨迹中学习行为时不需要。在我们的实验中,机器人需要通过与现实世界的交互来发现任务奖励,奖励网络学习预测这些奖励。也可以使用手动指定的奖励作为解码感官输入的函数。我们通过随机反向传播(Kingma和Welling,2013;Rezende等,2014)联合优化世界模型的所有组件。
演员批评家学习:虽然世界模型代表了与任务无关的动态知识,但演员批评家算法学习特定于当前任务的行为。如图3(右)所示,我们从世界模型的潜在空间中预测的轨迹中学习行为,无需解码观测。这允许使用典型批次大小为16K在单个GPU上进行大规模并行行为学习,类似于专用的现代模拟器(Makoviychuk等,2021)。演员批评家算法包括两个神经网络:
演员网络的作用是学习在每个潜在模型状态st下成功动作at的分布,以最大化未来预测任务奖励的总和。批评家网络通过时序差分学习(Sutton和Barto,2018)学习预测未来任务奖励的总和。这很重要,因为它允许算法考虑超出H = 16步规划范围的奖励,以学习长期策略。给定一个模型状态的预测轨迹,批评家被训练来回归轨迹的回报。一个简单的选择是将回报计算为N个中间奖励的总和加上下一个状态的批评家预测。为了避免为N选择任意值,我们计算λ-回报,其平均所有N ∈ [1, H − 1],计算如下:
![]()
虽然批评家网络被训练来回归λ-回报,但演员网络被训练来最大化它们。计算策略梯度以优化演员时有多种梯度估计器可用,例如Reinforce(Williams,1992)和重参数化技巧(Kingma和Welling,2013;Rezende等,2014),它们直接通过可微分的动态网络反向传播回报梯度(Henaff等,2019)。按照Hafner等(2020)的做法,我们为连续控制任务选择重参数化梯度,为具有离散动作的任务选择Reinforce梯度。除了最大化回报外,演员还被激励保持高熵,以防止塌陷到确定性策略,并在整个训练过程中保持一定的探索:
![]()
我们使用Adam优化器(Kingma和Ba,2014)优化演员和批评家。为了计算λ-回报,我们使用文献中常见的慢速更新的批评家网络副本(Mnih等,2015;Lillicrap等,2015)。演员和批评家的梯度不影响世界模型,因为这将导致不正确且过于乐观的模型预测。超参数列在附录D中。与Hafner等(2020)相比,没有训练频率超参数,因为分离的学习者与数据收集并行优化神经网络,不限制速率。
3 实验
我们在4个机器人上评估Dreamer,每个机器人都有不同的任务,并将其性能与适当的算法和人类基线进行比较。这些实验代表了常见的机器人任务,如运动、操作和导航。这些任务提出了多种挑战,包括连续和离散动作、密集和稀疏奖励、本体感知和图像观测以及传感器融合。学习到的世界模型具有多种特性,使其非常适合机器人学习。实验的目标是评估最近学习到的世界模型的成功是否能够实现直接在现实世界中的样本高效机器人学习。具体来说,我们旨在回答以下研究问题:
-
Dreamer是否能够直接在现实世界中进行机器人学习,无需模拟器?
-
Dreamer是否能够在各种机器人平台、感官模态和动作空间中成功?
-
Dreamer的数据效率与以前的强化学习算法相比如何?
3.1 A1四足机器人行走

这个高维连续控制任务需要训练一个四足机器人从背部翻滚、站立并以固定目标速度向前行走。以前的四足机器人运动工作需要在模拟器中进行广泛的训练,使用领域随机化,使用恢复控制器以避免不安全状态,或者将动作空间定义为参数化轨迹生成器,从而限制了运动的空间。相比之下,我们在端到端强化学习设置中直接在机器人上进行训练,无需模拟器或重置。我们使用的Unitree A1机器人由12个直接驱动电机组成。电机通过连续动作控制,这些动作代表由硬件上的PD控制器实现的电机角度。输入包括电机角度、方向和角速度。为了保护电机,我们通过巴特沃斯滤波器过滤掉高频电机命令。由于空间限制,当机器人到达可用训练区域的末端时,我们会手动干预,而不修改机器人所处的关节配置或方向。
奖励函数是五个项的总和。一个直立奖励从基座框架向上向量计算,站立姿势的项从髋关节、肩关节和膝关节的角度计算,向前速度项从投影的向前速度和总速度计算。每个项在其前面的项至少满足0.7时才激活,否则设置为0:
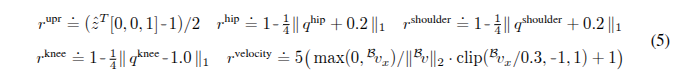
如图4所示,经过一小时的训练,Dreamer学会了始终如一地将机器人从背部翻滚、站立并向前行走。在训练的前5分钟内,机器人设法翻滚并站在脚上。20分钟后,它学会了如何站立。大约经过1小时的训练,机器人学会了跳跃步态以目标速度向前行走。在成功完成这项任务后,我们通过反复用大棒将机器人击倒来测试算法的鲁棒性,如图8所示。在额外的10分钟在线学习后,机器人适应并抵抗推动或快速翻滚并重新站立。相比之下,SAC很快学会了翻滚,但在给定的小数据预算下未能站立或行走。
3.2 UR5多物体视觉拾取和放置
图5:UR5多对象视觉挑选并放置此任务需要学习从第三人称摄像头图像找到三个球对象,抓住它们,然后将其移入另一个垃圾箱。手臂可以在垃圾箱内外移动,并给予稀疏的奖励,以抓住球并将其放入相对的垃圾箱中。环境要求世界模型在现实世界中学习多对象动态,而稀疏奖励结构为政策优化带来了挑战。梦想家克服了视觉本地化的挑战和在此任务上稀疏奖励visual localization and sparse rewards,在自动操作的几个小时内学习成功的策略

在仓库和物流环境中,拾取和放置任务需要机器人操作臂将物品从一个容器运输到另一个容器。图5展示了该任务的成功拾取和放置周期。由于稀疏奖励、需要从像素中推断物体位置以及多个移动物体的复杂动态,该任务具有挑战性。感官输入包括本体感知读数(关节角度、夹持器位置、末端执行器笛卡尔位置)和场景的第三方RGB图像。成功抓取3个物体中的一个(通过部分夹持器闭合检测)会获得+1奖励,在同一容器中释放物体给予-1奖励,将其放置在另一个容器中给予+10奖励。我们以2Hz的频率控制Universal Robotics的高性能UR5机器人。动作为离散的,用于沿X、Y和Z轴以增量方式移动末端执行器以及切换夹持器状态。只有在抓住物体时才允许沿Z轴移动,夹持器在到达正确容器上方时自动打开。我们通过让3名演示者用操纵杆控制UR5来估计人类表现。
Dreamer在8小时内达到平均每分钟2.5个物体的拾取率。机器人最初在学习中挣扎,因为奖励信号非常稀疏,但在2小时的训练后逐渐开始改进。机器人首先学会定位物体并在靠近物体时切换夹持器。随着时间的推移,抓取变得精确,机器人学会将物体从角落推出。图5展示了Dreamer与Rainbow DQN、PPO和人类基线的比较。Rainbow DQN和PPO仅学习短视行为,即抓取并立即在同一容器中放下物体。相比之下,Dreamer在8小时后接近人类表现。我们假设Rainbow DQN和PPO失败是因为它们需要更多的经验,而这在现实世界中收集是不切实际的。
3.3 XArm视觉拾取和放置

虽然UR5机器人是一个高性能的工业机器人,但XArm是一个可访问的低成本7自由度操作臂,我们大约以0.5Hz的频率控制它。与第3.2节类似,任务需要定位和抓取一个软物体并将其从一个容器移动到另一个容器,如图6所示。由于容器没有倾斜,我们用绳子将物体连接到夹持器上。这使得物体不太可能卡在角落,但以更复杂的动态为代价。稀疏奖励、离散动作空间和观测空间与UR5设置匹配,除了添加深度图像观测。
Dreamer学习了一个策略,使XArm在10小时内达到平均每分钟3.1个物体的拾取率,这与该任务的人类表现相当。图6显示Dreamer在10小时内解决了任务,而Rainbow算法,一个顶级的无模型算法,用于从像素进行离散控制,未能学习。有趣的是,我们观察到Dreamer有时学会使用绳子将物体从角落拉出,然后再抓取它,展示了多模态行为。此外,我们观察到当照明条件发生剧烈变化(例如日出时的尖锐阴影)时,性能最初会崩溃,但Dreamer在额外训练几个小时后适应了变化条件,并超过了其先前的性能,如附录A所述。
3.4 Sphero导航

我们在一个视觉导航任务中评估Dreamer,该任务要求操纵一个轮式机器人到达固定目标位置,仅以RGB图像作为输入。我们使用Sphero Ollie机器人,一个圆柱形机器人,具有两个可控电机,我们通过连续扭矩命令以2Hz的频率进行控制。由于机器人对称且只有图像观测可用,它必须从观测的历史中推断航向方向。机器人获得负L2距离的密集奖励。由于目标固定,在100个环境步骤后,我们结束剧集,并通过一系列高功率随机电机动作随机化机器人的位置。
在2小时内,Dreamer学会了快速且一致地导航到目标,并在剧集的剩余时间内保持在目标附近。如图7所示,Dreamer实现了平均距离目标0.15,以区域大小为单位,并在时间步长上平均。我们发现DrQv2,一个专门用于从像素进行连续控制的无模型算法,实现了类似的性能。这一结果与Yarats等(2021)的模拟实验相匹配,表明这两种算法在从图像进行连续控制任务时表现相似。
4 相关工作
现有的机器人学习工作通常利用大量模拟经验进行领域和动态随机化,然后部署到现实世界(Rusu等,2016;Peng等,2018;OpenAI等,2018;Lee等,2020;Irpan等,2020;Rudin等,2021;Kumar等,2021;Siekmann等,2021;Smith等,2021;Escontrela等,2022;Miki等,2022),利用机器人队列收集经验数据集(Kalashnikov等,2018;Levine等,2018;Dasari等,2019;Kalashnikov等,2021;Ebert等,2021),或依赖外部信息,如人类专家演示或任务先验,以实现样本高效学习(Xie等,2019;Schoettler等,2019;James等,2021;Shah和Levine,2022;Bohez等,2022;Sivakumar等,2022)。然而,设计模拟任务和收集专家演示是耗时的。此外,这些方法中的许多需要专门的算法来利用离线经验、演示或模拟器的不准确性。相比之下,我们的实验表明,通过世界模型,直接从物理世界中的奖励进行端到端学习对于多种任务是可行的。
从零开始直接在物理世界中进行端到端学习的工作相对较少。Visual Foresight(Finn等,2016;Finn和Levine,2017;Ebert等,2018)通过在线规划学习视频预测模型以解决现实世界任务,但限于短期任务,并且需要在规划过程中生成图像,这在计算上是昂贵的。相比之下,我们学习潜在动态,从而在紧凑的潜在空间中高效地进行策略优化,并使用大批次。Yang等(2019;2022)通过预测脚放置并利用领域特定的控制器实现四足运动。SOLAR(Zhang等,2019)从图像中学习潜在动态模型,并展示了机器人臂的到达和推动。Nagabandi等(2019)通过从状态观测中学习的动态模型进行规划,以学习灵巧操作策略。相比之下,我们的实验表明,在4个具有挑战性的机器人任务中成功学习,涵盖了广泛的挑战和感官模态,使用单一的学习算法和超参数设置。
5 讨论
我们将Dreamer应用于物理机器人学习,发现现代世界模型能够实现样本高效的机器人学习,涵盖从零开始在现实世界中的多种任务,无需模拟器。我们还发现这种方法具有通用性,可以解决机器人运动、操作和导航任务,无需更改超参数。Dreamer在1小时内教会了一个四足机器人从背部翻滚、站立和行走,这以前需要在模拟器中进行广泛训练,然后转移到现实世界,或使用参数化轨迹生成器和给定的重置策略。我们还展示了在两个机器人臂上从像素和稀疏奖励中学习拾取和放置物体的能力,耗时8-10小时。
局限性:尽管Dreamer显示出有希望的结果,但硬件上的长时间学习会增加机器人的磨损,可能需要人工干预或维修。此外,需要进行更多工作来通过更长时间的训练来探索Dreamer和我们基线的极限。最后,我们认为通过结合快速现实世界学习和模拟器的好处来解决更具挑战性的任务,是一个具有影响力的未来研究方向。
附录 A:适应性
现实世界中的机器人学习面临环境条件变化和动态变化的实际挑战。我们发现Dreamer能够在不更改学习算法的情况下适应当前环境条件。这表明Dreamer在持续学习设置中有应用前景(Parisi等,2019)。关于四足机器人对外部干扰的适应性,请参见第3.1节和图8。
XArm位于大窗户附近,能够在照明条件变化的情况下适应并保持性能。XArm的实验在日落后进行,以在整个训练过程中保持恒定的照明条件。图A.1显示了XArm的学习曲线。
图A.1:左两个图像是Dreamer消耗的原始观察结果。最左边的图像是XARM在训练时看到的图像观察。下一个图像显示在日出期间的观察。尽管像素空间差异很大,但XARM仍能够在大约5小时内恢复,然后超过原始性能。
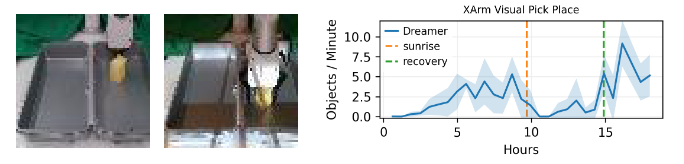
如预期一样,XArm的性能在日出时下降。然而,XArm能够在大约5小时内适应照明条件的变化,并恢复原始性能,这比从零开始训练要快。仔细检查这些时间的图像观测(如图A.1所示),发现机器人接收到的观测图像上有强烈的光线覆盖整个场景,这与原始训练观测图像有很大不同。
附录 B:想象

图B.1:为了内省策略,我们可以在Dreamer的潜在空间中展开轨迹,然后解码图像以可视化演员网络的意图。每一行是一个想象的轨迹,显示每第二个帧。顶部:UR5环境中的潜在轨迹展开。多个物体引入了更多的视觉复杂性,网络需要对其进行建模。注意第二条轨迹,其中静态的橙色球变成了绿色球。底部:XArm环境中的潜在轨迹展开。
附录 C:详细相关工作
强化学习用于运动
一种常见的方法是通过领域和动态随机化在大量模拟数据上训练RL智能体(Peng等,2018;Lee等,2020;Rudin等,2021;Siekmann等,2021;Escontrela等,2022;Miki等,2022;Kumar等,2021;Rusu等,2016;Bohez等,2022),然后冻结学习到的策略并部署到现实世界。Smith等(2021)探索了在模拟器中预训练策略,并使用现实世界数据进行微调。Yang等(2019)研究了使用多步损失学习动态模型,并使用模型预测控制来完成指定任务。Yang等(2022)在现实世界中训练运动策略,但需要在模拟器中训练的恢复控制器以避免不安全状态。相比之下,我们不使用模拟器或重置策略,直接在物理机器人上进行训练。
强化学习用于操作
学习有望使机器人操作臂在开放的现实世界环境中解决接触丰富的任务。一类方法试图通过机器人队列来扩展经验收集(Kalashnikov等,2018;2021;Ebert等,2021;Dasari等,2019;Levine等,2018)。相比之下,我们只利用一个机器人,但通过使用学习到的世界模型并行化智能体的经验。另一种常见的方法是利用专家演示或其他任务先验(Pinto和Gupta,2015;Ha和Song,2021;Xie等,2019;Schoettler等,2019;Sivakumar等,2022)。James和Davison(2021);James等(2021)利用少量演示来提高Q学习的样本效率,通过关注场景中的重要方面。其他方法,如运动,首先利用模拟器,然后转移到现实世界(Tzeng等,2015;Akkaya等,2019;OpenAI等,2018;Irpan等,2020)。
基于模型的强化学习
由于其比无模型方法更高的样本效率,基于模型的强化学习是现实世界机器人学习的一个有前景的方法(Deisenroth等,2013)。基于模型的方法首先学习一个动态模型,然后可以用于规划动作(Nagabandi等,2019;Hafner等,2018;Chua等,2018;Nagabandi等,2017),或作为模拟器来学习策略网络,如Dreamer(Hafner等,2019;2020)。一种方法是学习一个动作条件的视频预测模型(Finn和Levine,2017;Ebert等,2018;Finn等,2016)。这种方法的一个缺点是需要直接预测高维观测,这可能计算效率低下且容易漂移。Dreamer在潜在空间中学习动态模型,从而允许更高效的轨迹展开,并避免依赖高质量的视觉重建来制定策略。另一条研究线提出学习潜在动态模型,而无需重建输入(Deng等,2021;Okada和Taniguchi,2021;Bharadhwaj等,2022;Paster等,2021),我们认为这是支持复杂环境中移动视点的一个有前景的方向。
:3D机房大屏全景解析)





)