下载tessdata各语言集合包.zip
找个盘下面解压缩,名字改成英文的
pom文件依赖
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.5.4</version></dependency>
java文件内容
package com.jht.demo.until;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;import java.io.File;public class OCRChineseExample {public static void main(String[] args) {// 初始化Tesseract实例ITesseract instance = new Tesseract();// 设置训练数据的路径(tessdata/configs/path)// instance.setDatapath("C:\\Program Files\\Tesseract-OCR\\tessdata");instance.setDatapath("E:\\tessdata\\tessdata");// 设置OCR的语言instance.setLanguage("chi_sim"); // 中文简体try {// 读取图片文件// String imgPath = "C:\\path\\to\\your\\image.png";String imgPath = "D:\\桌面\\1.png";String result = instance.doOCR(new File(imgPath));System.out.println(result);} catch (TesseractException e) {e.printStackTrace();}}}
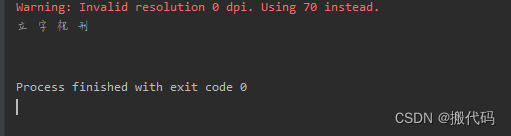
识别不太对说明训练的还是不到位呀,但是逻辑是正确的





