假如你正在设计和开发一个分布式服务系统,系统中存在一批能够独立运行的服务,而在部署上也采用了集群模式以防止出现单点故障。所谓集群,就是指将多个服务实例集中在一起,对外提供同一业务功能,也就是任意请求都可以由集群中的某一个服务实例进行响应。如下图所示:

那么问题就来了,就像上图中所展示的,你的一次请求到底应该是由哪个服务实例来响应最为合适呢?这就是今天我们要讨论的话题。这个话题看上去很简单,实际上却有点复杂,涉及到服务请求的路由机制。在分布式系统中,负载均衡(Load Balance)是最常见的一种路由机制,接下来我们就来展开一下。
所谓负载均衡,简单讲就是将请求分摊到多个操作单元上进行执行。负载均衡建立在现有网络结构之上,它提供了一种廉价、有效、透明的方法扩展服务器的带宽、增加吞吐量、加强网络数据处理能力,以及提高网络的灵活性。下图展示了负载均衡的基本结构,可以看到来自客户端的请求通过中间的负载均衡器将被分发到各个服务实例,根据分发策略的不同将产生不同的分发结果。
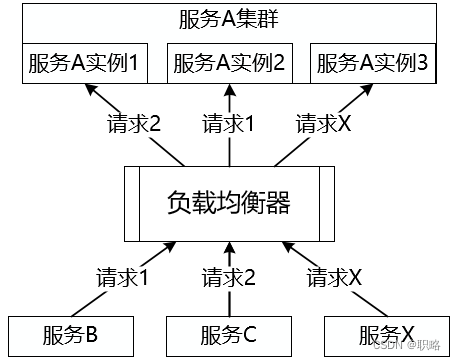
针对上图,我们先来考虑一个基础性的问题,即负载均衡器想要实现请求分发的前提是什么?显然,负载均衡器需要掌握当前各个服务实例的运行时状态,也就是说需要持有当前的服务实例列表信息,如下所示:

接下来我们来详细讨论具体的分发策略。首当其冲我们要明确的是一个问题是:请求是由谁来分发?针对这点就可以分成两大类负载均衡器,即服务器端负载均衡和客户端负载均衡,它们的核心区别就是服务实例地址列表所存放的位置。
我们先来看服务器端负载均衡,它的结构如下图所示:

显然,在这种负载均衡架构下,在客户端与服务实例之间存在一个独立的负载均衡服务器,然后这台负载均衡服务器负责将接收到的各个请求转发到运行中的某个服务实例上。提供服务器端负载均衡的工具有很多,例如常见的Apache、Nginx、HAProxy等都实现了基于HTTP协议或TCP协议的负载均衡模块。
基于服务器端的负载均衡机制实现比较简单,只需要在客户端与各个服务实例之间架设集中式的负载均衡器即可。负载均衡器与各个服务实例之间需要实现服务诊断以及状态监控,通过动态获取各个服务实例的运行时信息来决定负载均衡的目标服务。如果负载均衡器检测到某个服务实例已经不可用时就会自动移除该服务实例,正如上图中所示的“服务A实例2”那样。
通过上述分析,可以看到负载均衡器运行在一台独立的服务器上并充当代理(Proxy)的作用。所有的请求都需要通过负载均衡器的转发才能实现服务调用,这可能会是一个问题,因为当服务请求量越来越大时,负载均衡器将会成为系统的瓶颈。同时,一旦负载均衡器自身发生失败,整个服务的调用过程都将发生失败。因此,分布式架构中,为了避免集中式负载均衡所带来的这种问题,客户端负载均衡同样也是一种常用的方式。
客户端本身同样可以实现负载均衡。所谓客户端负载均衡,简单的说就是在客户端程序内部保存着各个服务实例信息,然后自己设定一个调度算法,在向服务器发起请求的时候,先执行调度算法计算出目标服务实例的地址。客户端负载均衡的表现形式如下图所示:

客户端负载均衡应用广泛,例如目前主流的微服务架构实现框架Spring Cloud、Dubbo等都内置了完整的客户端负载均衡模块。而像老牌的分布式缓存Memcache同样也是这一负载均衡策略的典型应用。
相比较而言,客户端负载均衡机制的主要优势就是不会出现集中式负载均衡所产生的瓶颈问题,因为每个客户端都有自己的负载均衡器,单个负载均衡器的失效也不会造成严重的后果。另一方面,由于所有的服务实例运行时信息都需要在多个负载均衡器之间进行传递,会在一定程度上加重网络流量负载。
通过前面内容的介绍,我们已经明确了“请求由谁来分发?”这个核心问题,同时也引出了一个新的概念,即用于执行负载均衡的调度算法,这就是我们要讨论的第二个问题,即“请求分发到哪去?”。
无论是使用服务器端负载均衡还是客户端负载均衡,运行时的分发策略决定了负载均衡的效果。分发策略在软件负载均衡中的实现形式为一组调度算法,通常称为负载均衡算法。负载均衡算法可以分成两大类,即静态负载均衡算法和动态负载均衡算法,它们之间的区别在于是否依赖于当前服务的运行时状态,这些状态信息通常包括服务过去一段时间的平均调用时延和所承接的连接数等。
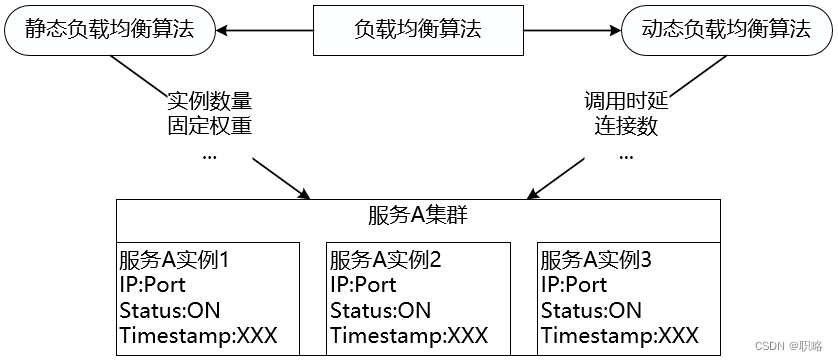
我们先来看静态负载均衡算法,这类算法中具有代表性的是各种随机(Random)和轮询(Round Robin)算法。
所谓随机算法,顾名思义,就是在集群中采用随机算法进行负载均衡,其特点是负载均衡的结果相对比较平均。随机算法实现也比较简单,使用JDK自带的Random工具类就可以用来指定服务实例的地址。例如,下图中来自客户端的9个请求分别被分发到了3个服务实例,分发的策略是随机选择一个服务实例,而不是一个固定的规则:

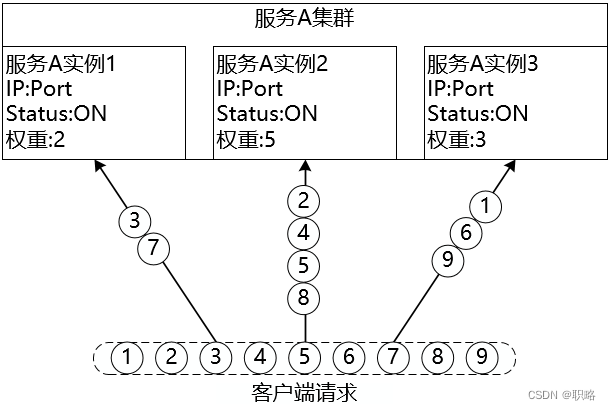
随机算法的一种改进是加权随机(Weight Random)算法,在集群中可能存在部分性能较优的服务器,为了使这些服务器响应更多请求,就可以通过加权随机算法提升这些服务器的权重,例如下图中实例2的权重设置的最大,所以对应的处理的请求数可能也就最多:
讲完随机算法,我们来看轮询算法。轮循算法的一般实现流程为顺序循环遍历服务实例列表,到达上限之后重新归零,继续顺序循环直到指定某一个服务实例。例如,在下图中第一个请求被分发到实例1,第二个请求被分发到实例2,第三个请求被分发到实例3,然后第四个请求再次被分发到了实例1,以此类推。当然,轮询的时候也可以为每个实例添加权重构成加权轮询算法。

事实上,所有涉及到权重的静态算法都可以转变为动态算法,因为权重可以在运行过程中动态更新。例如动态轮询算法中权重值会基于对各个服务器的持续监控并不断更新。另外,基于服务器的实时性能分配请求是常见的动态策略。典型的动态算法包括最少连接数算法、服务调用时延算法等。
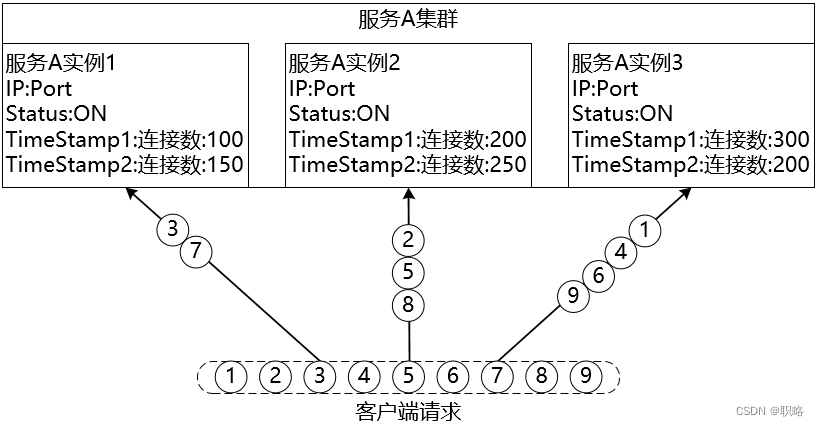
最少连接数(Least Connection)算法对传入的请求根据每台服务器当前所打开的连接数来分配,连接数最少的服务实例会优先响应请求。当执行分发策略时,会根据在某一个特定的时间点下服务实例的最新连接数来判断是否执行客户端请求。而在下一个时间点时,服务实例的连接数一般都会发生相应的变化,对应的请求处理也会做相应的调整,如下图所示:
与最少连接数类似,服务调用时延(Service Invoke Delay)算法的判断依据是服务实例的调用时延,根据服务调用和平均时延的差值动态调整权重。如下所示:

在现实中,有时候我们也会使用源地址哈希(Source IP Hash)算法,该算法实现请求IP粘滞(Sticky)连接,尽可能让客户端总是向同一服务实例发起调用服务。显然,这是一种有状态机制,我们也可以把它归为动态负载均衡算法,效果如下:

我们也可以进一步来梳理一下主流微服务框架中所采用的负载均衡算法。在Spring Cloud中所实现的核心负载均衡算法包括随机、轮询、加权响应时间、并发量最小优先等,而Dubbo中则提供了随机、轮询、最少活跃调用数和一致性哈希等算法。可以看到,这两个框架中都实现了我们介绍的一些主流算法,但也根据框架自身的特点提供了一些比较有特色的策略。当然,这两个框架也都提供了开发入口供开发人员实现自定义的负载均衡算法。
最后,我们通过如下所示的一张思维导图来总结今天的内容:


关于广义线性回归工具的补充内容)
)


)
