关键字大小写不敏感
查看表结构中的 desc = describe 描述
降序中的 desc = descend
1. 数据库的操作
1. 创建数据库
create database 数据库名;
为防止创建的数据库重复
CREATE DATABASE IF NOT EXISTS 数据库名;
手动设置数据库采用的字符集
character set 字符集名;charset 字符集名;char : unicode
String : utf8mb4(推荐使用 utf8mb4,完整支持 Unicode,包括表情符号)
utf8(残本,不支持emoji表情符号)
指定数据库字符集的校验规则
collate 排序规则;2. 查看数据库
show databases ;3. 选中要使用的数据库
use 数据库名;4. 删除数据库
drop database 数据库名;1. 常用数据类型
一、数值类型
1. 整数类型
| 类型 | 字节 | 有符号范围 | 无符号范围 |
|---|---|---|---|
| TINYINT | 1 | -128 ~ 127 | 0 ~ 255 |
| SMALLINT | 2 | -32,768 ~ 32,767 | 0 ~ 65,535 |
| MEDIUMINT | 3 | -8,388,608 ~ 8,388,607 | 0 ~ 16,777,215 |
| INT/INTEGER | 4 | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
| BIGINT | 8 | -2^63 ~ 2^63-1 | 0 ~ 2^64-1 |
2. 浮点数类型
| 类型 | 字节 | 说明 |
|---|---|---|
| FLOAT | 4 | 单精度浮点数,约7位精度 |
| DOUBLE | 8 | 双精度浮点数,约15位精度 |
3. 定点数类型
| 类型 | 说明 |
|---|---|
| DECIMAL(M,D) | 精确小数,M是总位数,D是小数位数 |
精度高,运算速度慢,占的空间大
二、字符串类型
1. 短文本
| 类型 | 最大长度 | 特点 |
|---|---|---|
| CHAR(n) | 255字符 | 固定长度,效率高 |
| VARCHAR(n) | 65,535字节 | 可变长度,节省空间 |
n 表示该类型最多存储多少个字符(不是字节),一个汉字算一个字符
2. 长文本
| 类型 | 最大长度 | 特点 |
|---|---|---|
| TINYTEXT | 255字节 | |
| TEXT | 65,535字节 | |
| MEDIUMTEXT | 16,777,215字节 | |
| LONGTEXT | 4GB |
3. 二进制数据
| 类型 | 说明 |
|---|---|
| BINARY(n) | 固定长度二进制字符串 |
| VARBINARY(n) | 可变长度二进制字符串 |
| BLOB | 二进制大对象 |
文本数据存储的都是字符,这些字符都可以在对应的码表上查到
二进制数据:在码表上查不到的如音乐,图片,视频
三、日期时间类型
| 数据类型 | 存储大小 | 格式 | 范围(最小值 ~ 最大值) |
|---|---|---|---|
| YEAR | 1字节 | YYYY | 1901 ~ 2155 |
| DATE | 3字节 | YYYY-MM-DD | 1000-01-01 ~ 9999-12-31 |
| TIME | 3字节 | HH:MM:SS | -838:59:59 ~ 838:59:59 |
| DATETIME | 5字节 | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP | 4字节 | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 UTC ~ 2038-01-19 03:14:07 UTC |
2. 表操作
1. 创建表
create table 表名(
列名 数据类型[约束条件],
列名 数据类型[约束条件],
...
);
2. 查看表结构
desc 表名;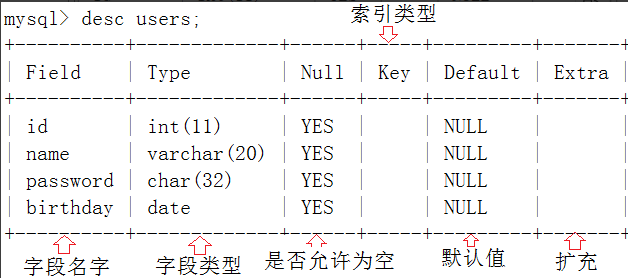
int(11) 是四个字节,此处(11)表示显示宽度,即显示这个int类型时,最多占据11个字符的宽度(和存储时的容量无关)。
3. 删除表
drop table 表名;删除表的同时,表中的数据也一并删除。
3. 表数据操作
1. 新增数据
值的个数和类型要和表结构匹配
1. 单行数据 + 全列插入(即在表中插入一行数据)
insert into 表名 values (值1,值2,值3...);insert into 表名 values (值1,值2,值3...),(值1,值2,值3...),(值1,值2,值3...),...;insert into 表名 (列1,列2,...) values (值1,值2,...);insert into 表名 (列1,列2,...) values (值1,值2,...),(值1,值2,...),...;2. 查询数据
mysql是一个“客户端 - 服务器”结构的程序
客户端在这里进行的操作,都会通过请求发送给服务器,服务器查询的结果也会通过响应返回给客户端(以临时表的形式)
SQL 查询的逻辑执行顺序:
FROM 子句 - 确定数据来源
JOIN 子句 - 连接相关表
WHERE - 行级过滤(此时不能使用SELECT中定义的别名)
GROUP BY - 数据分组
HAVING - 分组后过滤
SELECT - 计算列表达式并选择列
DISTINCT 关键字- 去重
ORDER BY - 排序(可以使用SELECT中定义的别名)
LIMIT /OFFSET- 结果集限制
SELECT [DISTINCT] 列1 [as 别名] , 列2 [as 别名], ...
FROM 表名
[WHERE 条件]
[GROUP BY 分组列]
[HAVING 分组条件]
[ORDER BY 排序列 [ASC|DESC]]
[LIMIT [偏移量,] 行数];1. 全列查询
select * from 表名;如果数据库当前这个表中的数据特别多,就可能会产生问题:
1. 读取硬盘,把硬盘的IO给跑满了,此时程序的其他部分想访问硬盘,就会非常慢。
2. 操作网络,也可能把网卡的带宽跑满,此时其他客户端想通过网络访问服务器,也会非常慢
这样的拥堵,就可能导致客户端无法顺利访问到数据库,进一步也就对整个服务器造成影响(相当于数据库服务器挂了)
2. 指定列查询
select 列1,列2,... from 表名;3. 表达式查询
是列与列之间的运算
select 表达式1,表达式2,... from 表名;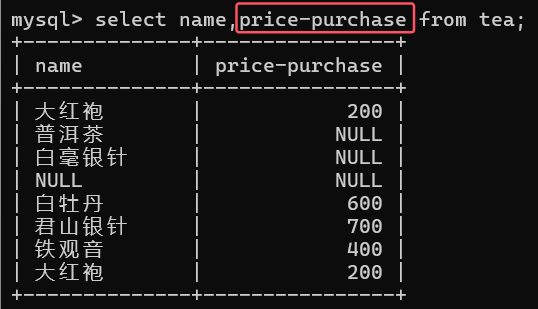
4. 去重:DISTINCT
select distinct 列1,列2... from 表名;5. 别名
列的别名不能在ORDER BY中直接使用(在某些MySQL版本中)
SELECT [DISTINCT] 列1 [[as] 别名] , 列2 [[as] 别名], ... FROM 表名;6. 排序:order by
select 列1,列2... from 表名order by 列名 [asc/desc],列名 [asc/desc]...;
3. 可以对多个字段进行排序,排序优先级随书写顺序
7. 条件查询:where
select 列名 from 表名 where 约束条件;| 运算符 | 描述 |
|---|---|
| = | 等于, NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于, NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| <> 或 != | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN a0 AND a1 | 范围匹配, [a0, a1] ,如果 a0 <= value <= a1 ,返回 TRUE(1) |
| IN(option,...) | 在指定值列表中,如果是 option 中的任意一个,返回 TRUE(1) |
| LIKE | 模糊匹配,% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
| IS NULL | 是空值 |
| IS NOT NULL | 不是空值 |
SELECT * FROM 表名 WHERE 列名 LIKE '模式';% 表示任意多个(包括 0 个)任意字符;
_ 表示任意一个字符
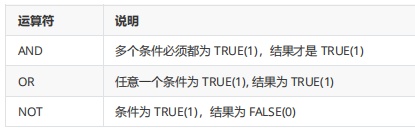
AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
8. 分页查询
始终结合 ORDER BY 使用分页,否则结果顺序不确定
select 列名 from 表名 limit 每页记录数 offset 偏移量;select 列名 from 表名 limit 偏移量, 每页记录数;当前页码(page)和每页大小(pageSize)
偏移量(offset) = (page - 1) * pageSize
每页记录数 = pageSize
3. 修改数据
UPDATE 表名
SET 列名1 = 值1, 列名2 = 值2, ...
[WHERE 条件]
[ORDER BY 列名]
[LIMIT 行数];
将名字为null改为信阳毛尖

怎样查看警告:
show warnings;
4. 删除数据
DELETE FROM 表名
[WHERE 条件]
[ORDER BY 列名]
[LIMIT 行数];delete from 表名;如果删除数据时不加任何约束条件,则将整个表中的数据全部删除,只留空表。
在修改和删除数据中,limit 行数; 表示共删除或修改几行。
4. 数据库约束
在创建表时使用
约束类型:NOT NULL - 指示某列不能存储 NULL 值。UNIQUE - 保证某列的每行必须有唯一的值。DEFAULT - 规定没有给列赋值时的默认值。PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。CHECK - 保证列中的值符合指定的条件。
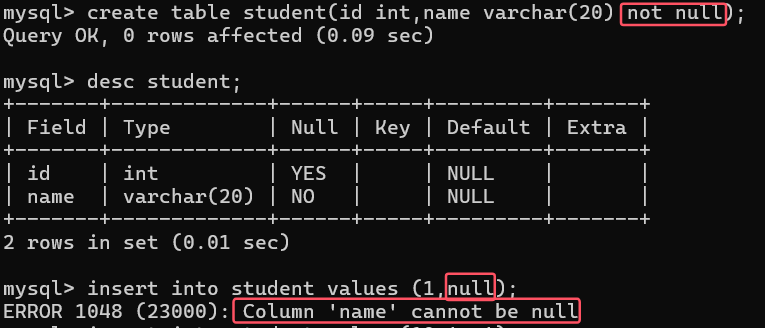
1. 非空约束 (NOT NULL)
作用:确保列不能包含NULL值
特点:
-
强制字段必须有值
-
可以在ALTER TABLE时添加或删除
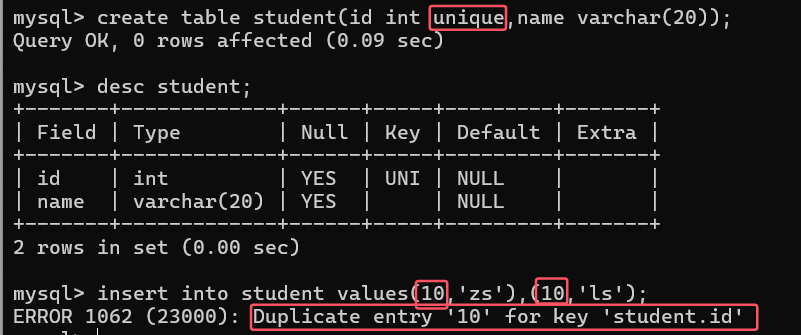
2. 唯一约束 (UNIQUE)
作用:确保列中的值唯一
特点:
-
允许NULL值(但只能有一个NULL)
-
一个表可以有多个唯一约束
-
自动创建非聚集索引
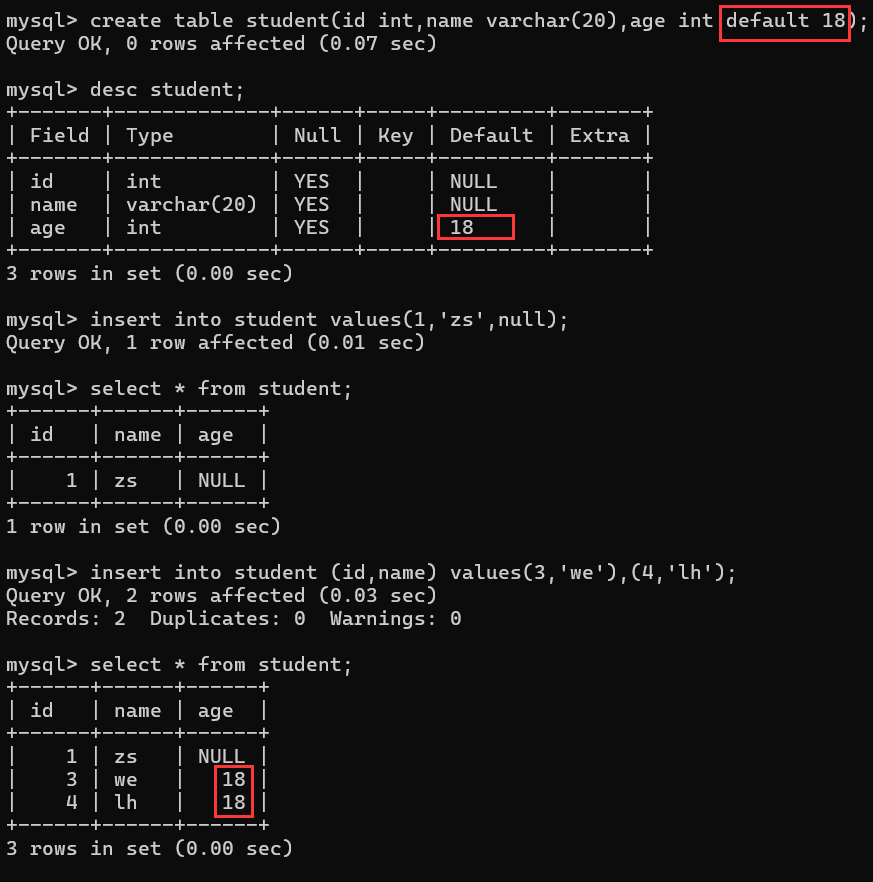
3. 默认约束 (DEFAULT)
作用:当插入数据未指定值时提供默认值,默认情况下为null.
特点:
-
可以是常量值或表达式
-
适用于INSERT和UPDATE操作
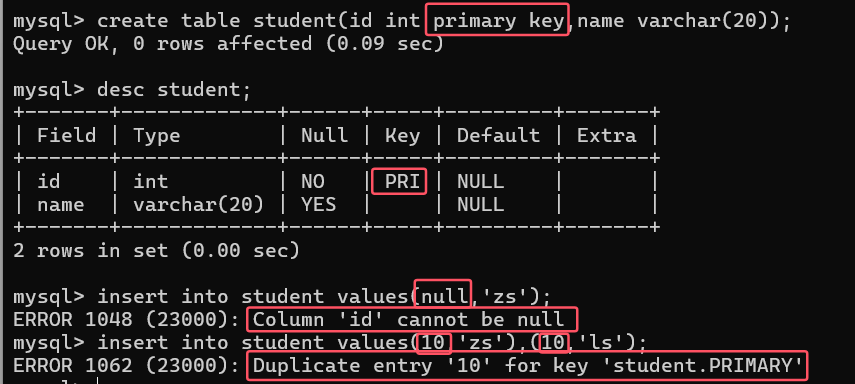
4. 主键约束 (PRIMARY KEY)
作用:唯一标识表中的每一行记录,确保实体完整性
特点:
-
不允许NULL值
-
不允许重复值
-
一个表只能有一个主键
-
自动创建聚集索引
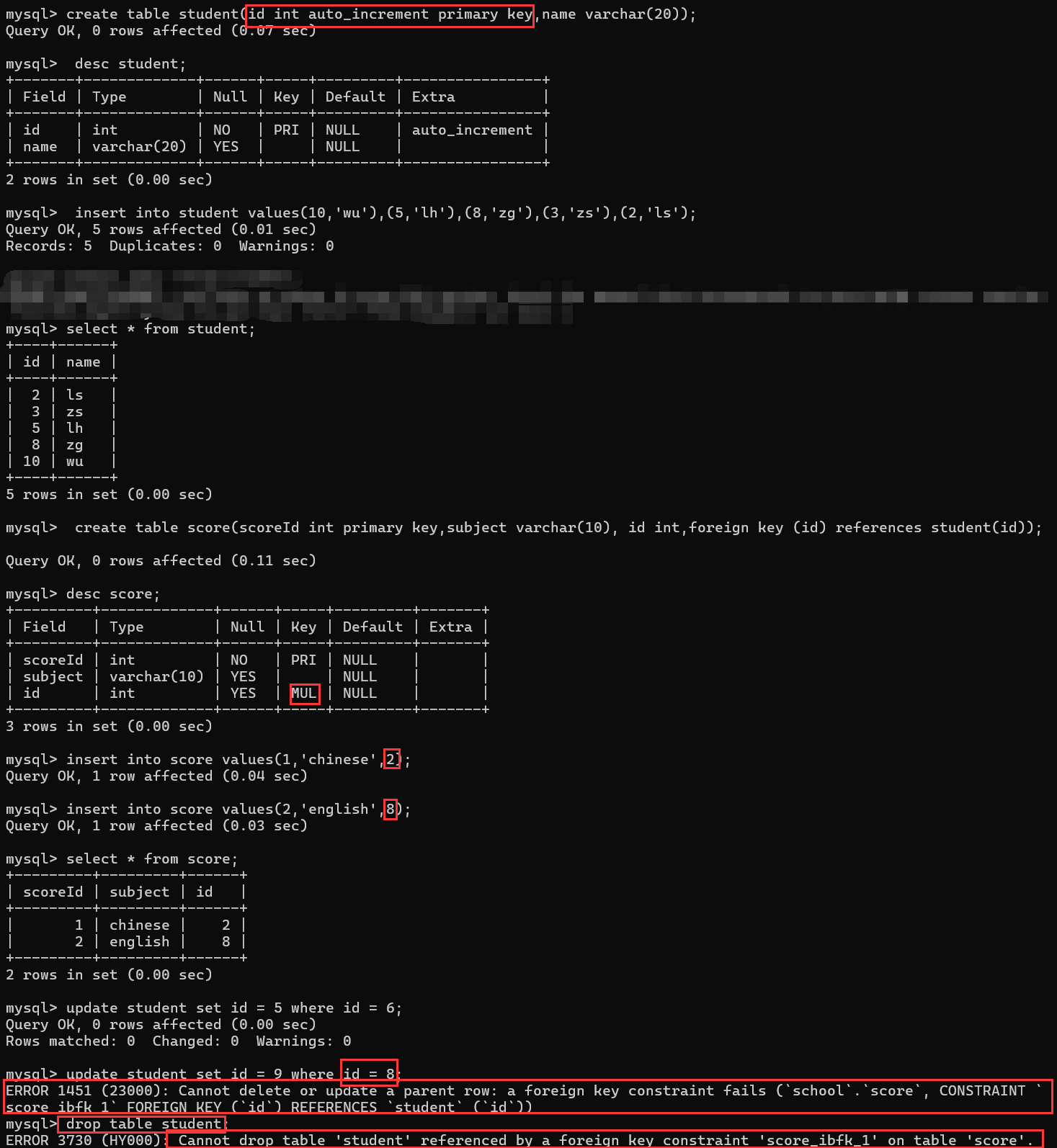
5. 外键约束 (FOREIGN KEY)
作用:维护表之间的引用完整性
特点:
-
确保一个表的值必须在另一个表中存在
-
可以定义级联操作
-
引用列必须是主键或唯一键
父表:约束别人的表
子表:被别人约束的表
CREATE TABLE 子表名 (列定义...,[CONSTRAINT 约束名] FOREIGN KEY (外键列) REFERENCES 主表名(主表列)[ON DELETE 参照动作][ON UPDATE 参照动作]
);
外键约束动作
当主表数据被删除或更新时,可以指定子表数据的处理方式:
| 动作 | 描述 |
|---|---|
RESTRICT | (默认)拒绝主表的删除或更新操作 |
CASCADE | 级联操作,主表删除/更新时,子表对应记录也删除/更新 |
SET NULL | 主表删除/更新时,子表对应外键列设为NULL(需允许NULL) |
NO ACTION | 类似RESTRICT |
SET DEFAULT | 设为默认值(MySQL目前不支持) |
针对父表的 删除/修改 操作,如果当前被 删除/修改 的值,已经被子表引用了,则无法进行此操作
外键约束要始终保持,子表中的数据在对应的父表的列中要存在。
如果父表不存在,子表添加元素时无参考依据
指定外键约束,时,父表中被关联的一列必须为主键或unique。
逻辑删除:
如果要删除与子表关联的父表元素,我们可以多设置一列进行条件约束。
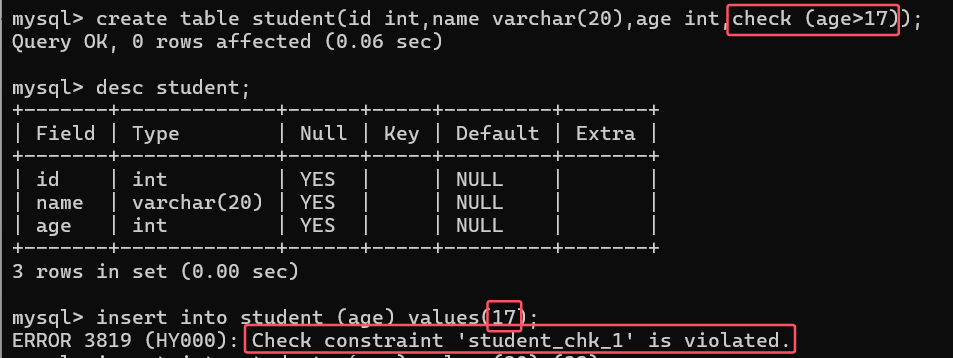
6. 检查约束 (CHECK)
作用:确保列值满足指定条件
特点:
-
MySQL 8.0.16+ 完全支持
-
可以引用多列
-
条件不满足时拒绝操作
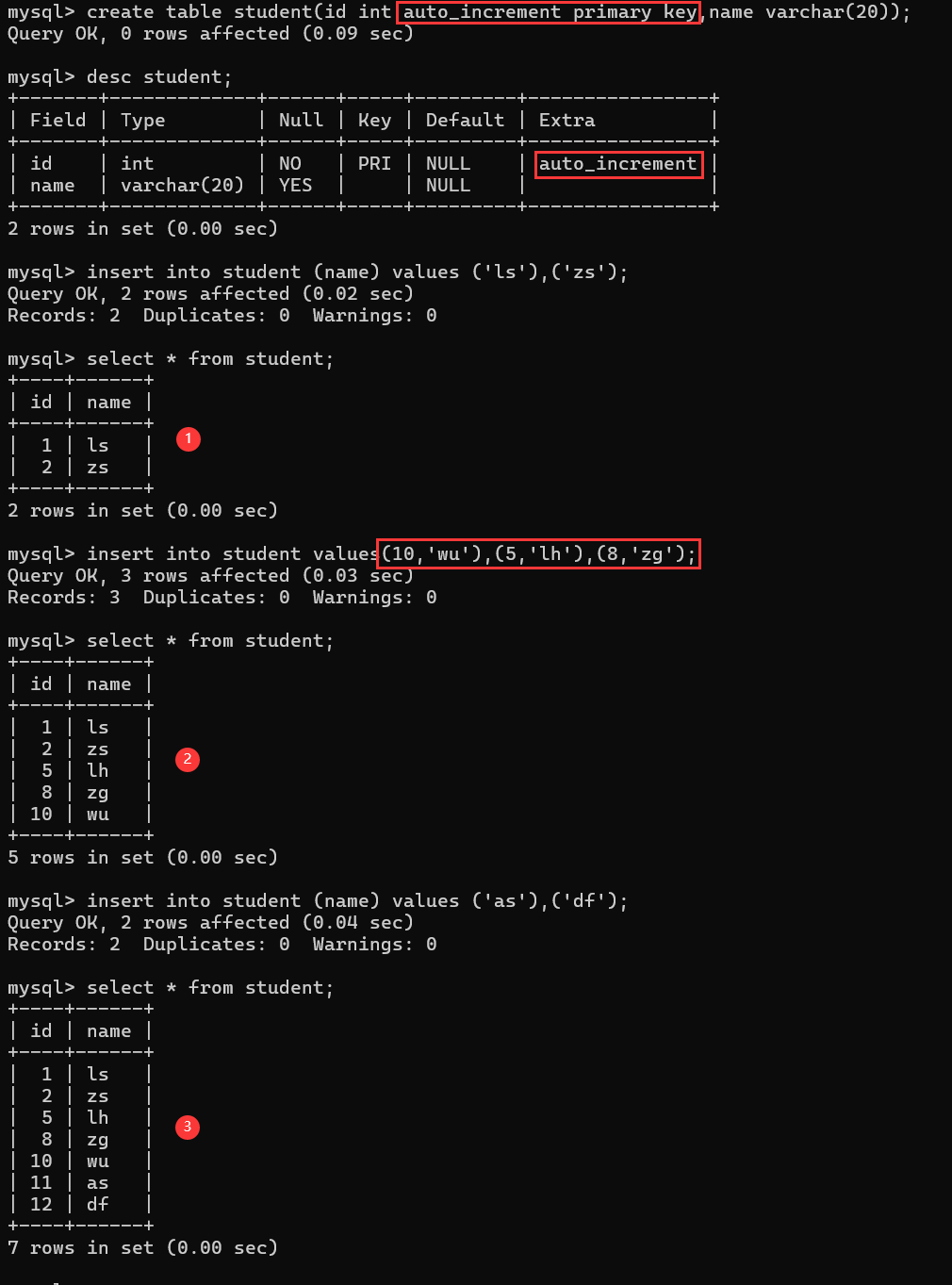
7. 自增约束 (AUTO_INCREMENT)
作用:自动为列生成唯一递增整数值(会自动排序),必须作用与键
特点:
-
通常用于主键
-
每张表只能有一个自增列
-
默认从1开始,每次增加1
-
支持整数类型(INT, SMALLINT, BIGINT等)
-
自增列不保证连续:删除记录后,自增值不会重用


——线程)



