更多AI大模型应用开发学习内容,尽在聚客AI学院
一、2025年LLM推理框架全景解析
1.1 技术演进趋势与挑战
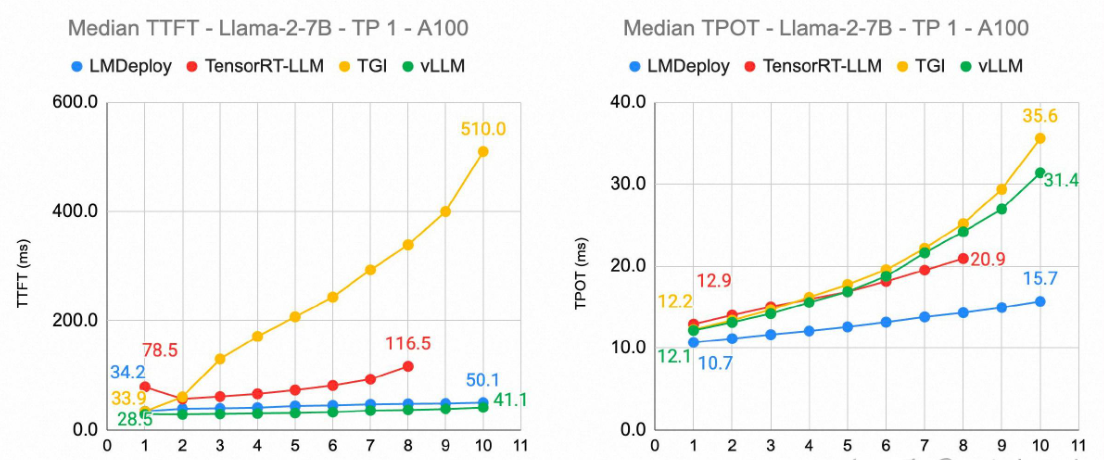
2025年核心变化:
-
硬件适配革命:NPU专用芯片普及(算力密度提升5倍)
-
多模态融合:文本/图像/视频推理统一架构
-
绿色计算:单位Token能耗降低至2023年的30%
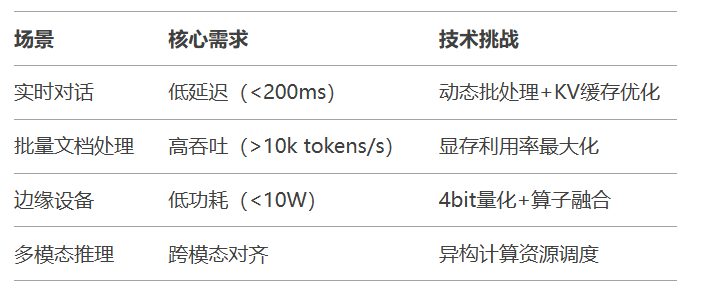
推理场景痛点矩阵:
二、六大主流框架深度评测
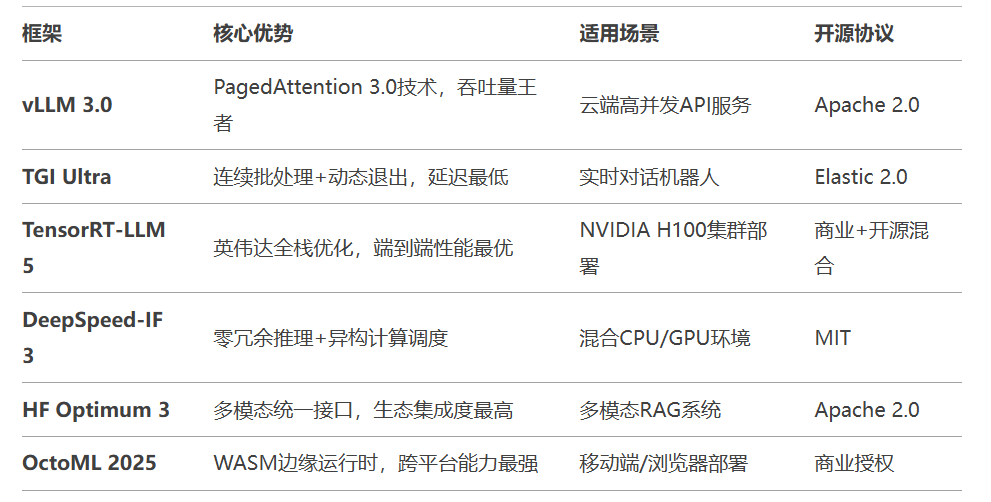
2.1 框架核心特性对比
2.2 关键技术突破解析
vLLM 3.0的PagedAttention 3.0:
-
块级KV缓存:显存碎片率从15%降至2%
-
动态共享内存:不同请求共享相似上下文块
-
预取策略:预测后续Token提前加载
TGI Ultra动态退出机制:
# 动态退出配置示例
engine = TextGenerationEngine( model, early_exit_layers=[ {"layer": 8, "confidence_threshold": 0.9}, {"layer": 16, "confidence_threshold": 0.95} ]
)
# 简单问题在第8层提前退出,复杂问题走完全程TensorRT-LLM 5的算子融合:
FlashAttention-3D:3D并行计算提升利用率
-
Quantization-Aware Fusion:量化感知的融合策略
三、场景化选型决策树
3.1 企业级API服务选型
需求特征:
-
日均请求量>1亿次
-
需支持动态扩缩容
-
严格SLA保障(P99延迟<500ms)
推荐方案:
vLLM 3.0 + Kubernetes
├─ 核心优势:吞吐量高达15k tokens/s/GPU
├─ 弹性扩展:秒级扩容200+ GPU实例
└─ 成本优化:通过PagedAttention显存复用降低30% TCO3.2 实时对话系统选型
需求特征:
-
响应延迟<300ms
-
支持长上下文(128k tokens)
-
流式输出
推荐方案:
TGI Ultra + FlashAttention-4D
├─ 连续批处理:动态合并不同长度请求
├─ 内存优化:KV缓存压缩率提升40%
└─ 流式API:首个Token延迟<50ms3.3 边缘设备部署选型
需求特征:
-
设备算力<10TOPS
-
内存<8GB
-
支持离线运行
推荐方案:
OctoML 2025 + 4bit QLoRA
├─ WASM运行时:浏览器/手机免驱动运行
├─ 自适应量化:根据设备性能动态调整精度
└─ 模型瘦身:移除90%非必要参数3.4 多模态推理选型
需求特征:
-
需处理文本+图像+视频
-
跨模态对齐需求
-
统一API接口
推荐方案:
HF Optimum 3 + OpenAI CLIP-4
├─ 多模态Pipeline:文本→图像→视频链式处理
├─ 统一嵌入空间:跨模态检索精度提升35%
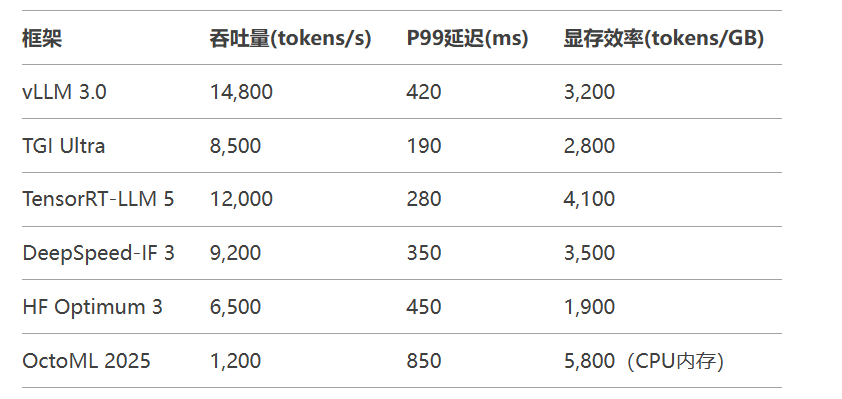
└─ 生态集成:直接调用HuggingFace 50万+模型四、性能基准测试数据(H100实测)
五、部署最佳实践
5.1 高可用架构设计
云原生方案:
graph TD
A[负载均衡] --> B[vLLM集群]
A --> C[TGI集群]
B --> D[自动扩缩容]
C --> D
D --> E[分布式缓存]
E --> F[监控报警]5.2 安全防护策略
-
输入过滤:正则表达式拦截恶意Prompt
-
模型防护:
from transformers import AutoModel, SafetyChecker
safety_checker = SafetyChecker.from_pretrained("Meta/llama-guard-3")
if safety_checker.detect_risk(output): return "内容违反安全策略"-
审计追踪:全链路请求日志上链存储
5.3 成本优化技巧
-
Spot实例调度:抢占式实例节省60%成本
-
分层缓存:
from langchain.cache import TieredCache
cache = TieredCache( fast_layer=RedisCache(), # 热数据 slow_layer=DiskCache(), # 温数据 backup_layer=S3ArchiveCache() # 冷数据
)六、未来趋势与总结
6.1 2026技术前瞻
-
1bit量化推理:微软BitNet架构落地
-
生物计算融合:DNA存储模型参数
-
自修复模型:运行时自动修复权重错误
6.2 开发者能力矩阵
[框架原理] ↑
[场景分析] → [选型决策] → [部署运维] ↓ [性能调优]更多AI大模型应用开发学习内容,尽在聚客AI学院。
、持续时间(duration)和链接(linkage))

)



