基于数据打通的“全链路”营销是当下的“时髦”,应用它的前提是什么?
深度营销和运营的关键数据如何获得?
如何利用数据进行更精准的营销投放?
如何利用数据优化投放的效果?
如何促进消费者的转化,以及激活留存的客户,并不断提高他们的忠诚度?
应该采用什么样的数据战略?
宋星老师在《数据赋能:数字化营销与运营实战》中给出了以上问题的答案,最近正在读这本书,所以项采用框架拆解方式进行记录,一来通过梳理读书笔记倒逼自己提升对数字化营销的认知,二来分享给需要的小伙伴们,供相互学习交流使用。
本书围绕数据为企业数字化营销和业务增长赋能的两大主线——数据驱动和数据分析展开介绍,同时辅以近几年在中国企业界实际应用的真实案例进行生动讲解。
主要涉及的内容有:数据的来源、获取与接入,数字化流量运营,数据驱动的品牌、效果广告投放,流量效果的数据分析,异常流量与作弊识别,利用数据进行流量的宏观和微观转化,私域流量与消费者深度运营。
流量效果的数据分析
流量失效,满盘皆输。流量效果的数据分析是数字化营销与运营最重要的部分之一。
目录
流量渠道的效果分析与优化的工作内容
流量渠道的数据采集
细分渠道的评估与分析
整合渠道效果评估和归因分析
流量渠道分析的总结案例
异常流量的作弊识别
线上推广对线下转化效果的评估
一、流量渠道的效果分析与优化的工作内容
分析流量的效果,主要是分析对象是流量渠道,也常被称为流量源头。
包括内容如下:
第一对流量进行标记,以确保所有流量都是可识别的,且符合不重不漏的原则。
第二在流量进行准确标记的基础上,对流量渠道的直接表现进行衡量。所谓直接表现,是指各个流量渠道所能直接带来的营销推广的可计量效果。
第三是在对流量渠道的直接表现进行衡量之后,我们还需要对流量渠道的绩效表现做更深入的衡量。
二、流量渠道的数据采集
收集前端+后端数据。
准确地对流量渠道进行辨识,分析的颗粒度越小越好。
追踪流量背后的用户行为,追踪的用户行为越全面越好。
流量标记的 Link Tag 方法
Link Tag 是在流量源头(如各种广告)的链出链接上(链接的URL上)加上的尾部参数,这个参数就像附着在链接(Link)后面的标签(Tag)一样,因此得名。这些参数并不会影响链接的跳转,但能标明这个链接所属的流量源。
utm 是 Urchin Traffic Monitor 的缩写,Google 分析的前身
Utm_source 指广告所处的位置,如 bilibili, toutiao
Utm_medium 是广告的具体形式,如图文 tuwen,短视频 shortvideo
Utm_content 指展示类广告的具体创意内容
Utm_campaign 指投放广告的营销活动的名称
Utm_term 用来标记投放引擎所标记的关键词
DCM 或秒针这类工具提供的是营销前端广告投放的数据(广告本身曝光和点击),谷歌分析提供的则是营销后端的数据(触点平台的访问流量数据)。
搜索竞价排名流量使用流量标记
搜索引擎对用户搜索词进行了加密 - 用utm_term 这个字段用于关键词广告。
利用宏替换为搜索引擎竞价排名广告添加 Link Tag,尾部加{keyword},添加的是自己投放的关键词而非用户搜索的关键词。
信息流广告用 Link Tag 做标记
信息流广告的策略是”人群定向+创意+文案+着陆页“的不同策略的组合。
Utm_source 信息流媒体 bilibili, toutiao
Utm_medium 人群定向
Utm_content 创意
Utm_campaign 信息流(feedads)
Utm_term 文案
例子:
Utm_source=neteasenews 网易新闻
Utm_medium=tier1city-takeout 一线城市|订餐
Utm_content=luhan 鹿晗
Utm_campaign=infostream 信息流
Utm_term=4 四号创意
App 的推广来源问题
问题:App的推广来源信息在流量进入应用市场后被剪断
方法一:Server to Server 传输信息
Server to Server 的传输信息是指媒体把点击广告的用户信息,连同这个广告的信息,一起发给做App推广的广告主,一旦广告主获得了点击广告的用户的设备ID或其他识别信息,就会将其与新安装并使用App的用户的设备ID或其他识别信息做匹配。
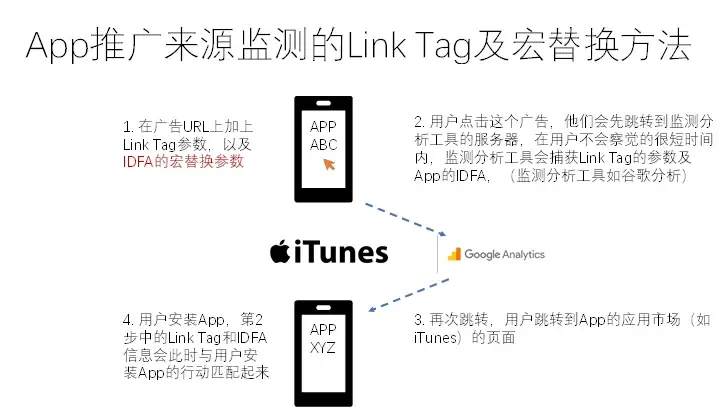
方法二:Link Tag 宏替换
需要广告商(或媒体)与第三方监测服务商进行合作。
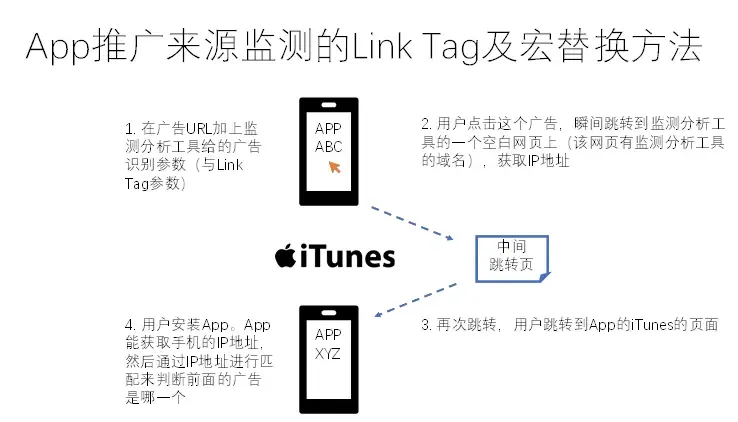
方法三:IP地址对应法
方法四:预置推广渠道
把推广渠道固定在App安装包中,如果有3个推广渠道,就做3个不同的App安装包,并确保每个推广渠道都有写着自己渠道信息的App上线。
流量标记不能实现的地方
Link Tag 能够发挥作用的前提有两个:
可以对流量源头的链出URL进行改动(添加尾部参数)论坛或聊天工具分享的URL,搜索引擎。
流量的落地环节必须能够添加监测脚本代码或者SDK在自己的淘宝店铺,微信后台等平台无法添加监测代码。
三、细分渠道的评估与分析
流量渠道的衡量指标
我们往往用两类指标来分析流量渠道的价值。
第一类:流量的多少及质量,包括流量数量、跳出率、停留时间、与网站或者App的互动程度等。第二类:流量的产出,即单纯地看这个流量产生了多少销售转化或者你期望这些流量背后的用户去完成的某件具体事情-下载,成为粉丝、推荐给他的好友等。我们还会将流量的产出与流程的成本结合起来计算流量的ROI(ROAS)。第三类:每个渠道背后的用户的忠诚度。
流量渠道的产出分析
ROAS (Return on Advertising Spending)广告回报比或者广告费用效果比。
流量渠道的质量分析
质量的意思可能很宽泛,除了ROAS作为流量质量指针,还包含交互度(停留时间,访问深度,流量大小)。
衡量流量质量的标准指标与 Engagement
衡量流量质量的标准指标是三件套,跳出率,停留时间(Time on Site)及 PageViews per
Session(PV/V)
Engagement并不是一个标准度量,可以被理解为是一系列体现交互程度度量的综合。
跳出率(Bounce Rate)
跳出率是一个复合度量。
跳出率 = 流量中对网站无意义的Session/流量总的Session x 100%
为了简单实现,无意义的Session被定义为:只访问了网站一个页面的Session。
访问长度与访问深度
访问长度:停留时间/Session总数量
访问深度:PageView/Session
网站用户行为分析工具记录的访问时间比访问者访问网络的实际时间略短,因为最后一个页面的实际浏览时间总是会被忽略不计。
Engagement Index 和 Engagement Rate
建立索引表Engagement Index,包含各类Engagement赋予具体的分数(Points),然后计算总分数 Engagement Rate = Engagement Index/Session
流量质量与产出的结合分析
考虑ROAS,过于结果导向。考虑流量质量,过于过程导向。Engagement ROAS 分析法
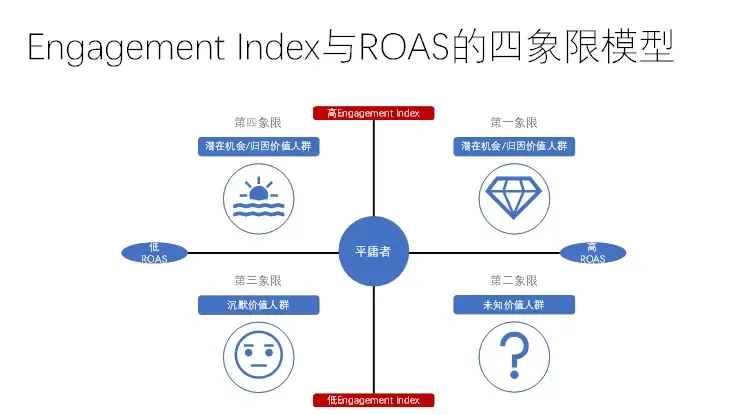
高兴趣低变现 - 第四象限
低兴趣高变现 - 第二象限
不适用于单页推广,PV/V 小于等于1,跳出率高达 95%/99%。除非有用户刷新页面。
四、整合渠道效果评估和归因分析
归因:一个名词之下的多个理解
归因的英文是 Attribution,描述的内容是变成一个转化(尤其是一个购买行为)是由哪些营销推广带来的结果。
理想状态下的归因
回溯在一个人完成转化或购买之前,所有影响他做出转化或购买的外部因素,如互联网广告、电梯广告、朋友的推荐、一篇软文、商场外的广告牌,它是全部归因。
全面归因的障碍:线下追踪与个人隐私保护。
现实中的归因
线上全域归因,通过一个人的各种行为来间接地推断各种营销对他的施加影响。
线上局部归因,通过一个人的部分行为来间接地推断部分营销对他的施加影响。
线上全域归因可以实现吗?
不太可能实现。接近能实现的机构是运营商,但运营商客户有限、隐私保护限制和不知道用户在 App 行为。
线上局部归因
单触点归因(Single Touchpoint Attribution, STA)
单触点归因(Single Touchpoint Attribution, STA)是指归因分析只焦距在某个具体触点上的引流情况和用户行为,从而判断这个触点上发生的转化是受了哪些引流推广的影响而发生的。
多触点归因(Multiple Touchpoint Attribution, MTA)
单ID归因 - 你在App上、网站上、小程序上用的ID是相同的,那么你在这些触点上的单触点归因就可以相互串联起来,形成多个触点上的归因。
多ID归因 - 多个触点上的归因通过同一个用户不同ID的打通进行串联。
单触点归因:流量覆盖问题
在计算转化来源时,默认都只会认为用户在之后点击的搜索引擎竞价排名广告或者你的其他广告才对这个转化具有效力,而用户最初的那次广告点击行为被覆盖了。
一个转化背后所有可能的努力
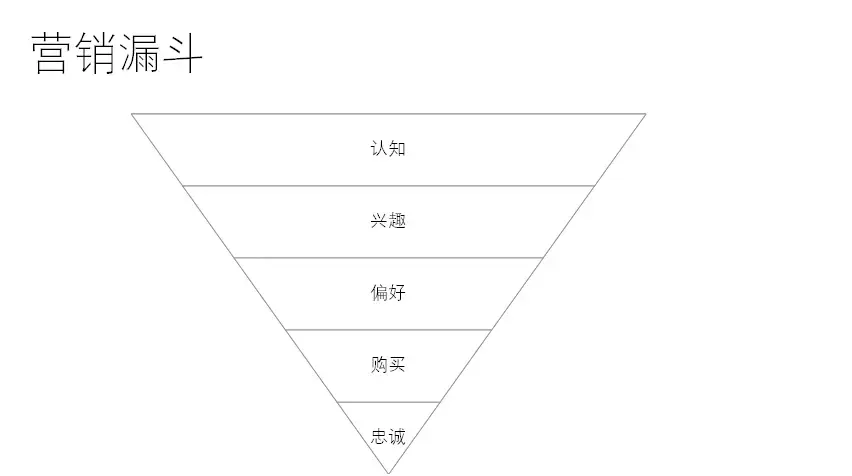
营销漏斗的存在,是购买者由浅入深地品牌或产品交互的过程中的必然。我们在营销漏斗的上部(营销的早期)的认知阶段的投入往往无法换取直接的转化,但为后面的在转化打下基础。
归因中的助攻和进球
整个营销的链路常常被称为消费者旅程。(Customer Journey)
我们在分析一个流量渠道的价值时,如果只单纯地分析它的进球数据,那么很有可能会误伤其他善于助攻的渠道,从而有可能(甚至相当程度地)影响转化率。
归因:一个实际的助攻案例
某电商网站由 1.3% 的辅助转化,但只有 0.32% 的直接转化(较低)。对更适合做品牌推广的该电商网站而言,这已经非常不错了。
曝光归因和点击归因
计入转化前历经的所有广告为曝光归因(View Attribution)
计入必须点击相应的页面叫作点击归因(Click Attribution)
支持点击归因的工具主要是网站用户行为分析工具,如谷歌分析、Adobe Analytics
支持曝光归因的工具主要是广告监播和效果分析工具,如 Double Click Campaign Manager,Admonitor。
作者更青睐点击归因。因为点击归因是消费者兴趣的展现,代表着某种确定性的心理变化,而曝光归因夸大了流量渠道的助攻价值,因为很多流量渠道并没有给消费者带来心理上的变化。
归因的时效性
对于归因,我们必须限定一个时间,因为无限回溯的助攻不符合常理。
更详细的归因关系 —— 归因路径
在研究流量渠道之间的助攻时,我们也关系谁给谁提供了助攻,因为这有助于我们指定新的流量渠道策略。
归因模型
首次互动归因模型(First Touch Attribution)
模型就是把营销全部功劳全部分配给第一次为网站带来访客的流量渠道。所有归因都是基于单个触点,因此自然会高估单个流量渠道的影响力。
这样会过分强调驱动用户认知的、位于转化漏斗最顶端的流量渠道。
适用于在新品牌或者新产品的推广上,以衡量广告的用户最初的影响,因为最初的影响对新品牌或者新产品更加重要。

线索转化互动归因模型(Lead Conversion Touch Attribution)
模型是指如果转化中有销售线索,那么回溯带来销售线索的那个流量渠道,并且把所有的转化功劳都划分给这个流量渠道。
过分强调了营销活动在整个用户转化过程中的作用。只用在需要获取业务线索的业态上,如To B 行业、教育行业、金融行业。

末次互动归因模型(Last Touch Attribution)
最容易测量的归因模型,也是各个工具计算转化的默认模型。

末次非直接流量互动归因模型(Last Non-direct Touch Attribution)
排除了直接流量因为一直接流量具体是哪个渠道带来的原因不明,二直接流量体现了公司的品牌力。
线性归因模型
将权重划分给用户转化过程中的每个触点,优点是简单,缺点是无法正确衡量各个流量渠道的不同影响。
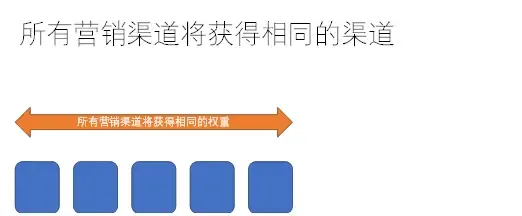
间衰减归因模型
把功劳划分给最接近转化的触点,触点越接近转化,对转化的影响力越大。

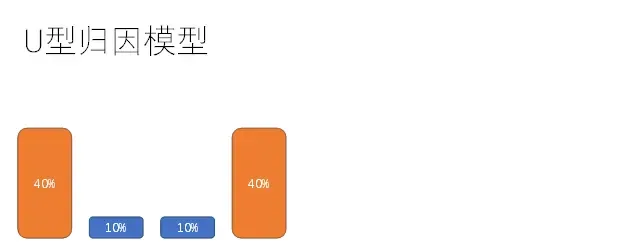
U型归因模型
谷歌也称其为基于位置的归因模型,它强调两个关键触点的重要性:第一次把新用户带来的首次互动流量渠道和最后转化的流量渠道。问题是它是机械的,或许中间渠道做了更大的贡献。
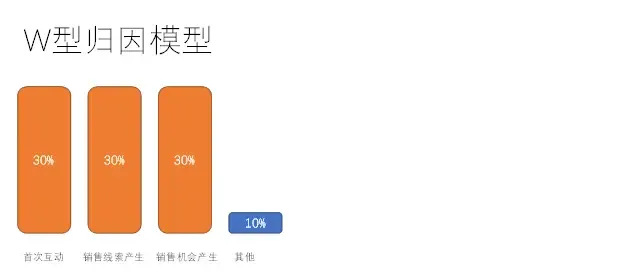
W型归因模型
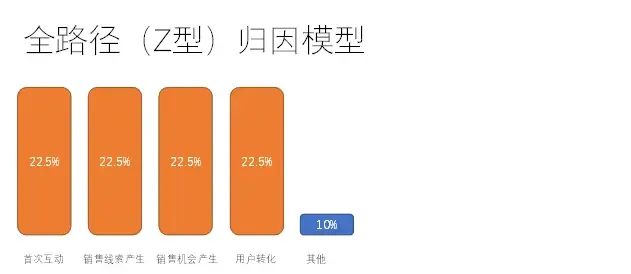
全路径(Z型)归因模型
只适用于为已有销售机会服务的营销组织。
自定义归因模型与智能归因模型
是需要数据科学家针对你的购物流程建立的自定义或算法模型,该模型能够最佳匹配用户转化的过程。
该模型在建立、维护和使用上都最困难和最耗时的归因模型,但它能够最精确地评估各流量渠道对用户过程的影响效果。
流量渠道分析的总结案例
一般而言,在行业内除非强调是归因转化率,或者归因收入、归因ROAS等,否则都默认是末次交互转化率。
分析原则:
原则一:细分。打开 Display 黑箱查看其内部的诸多广告就是细分。
原则二:从大处着手。在细分后,查看流量多的流量渠道,因为这些流量渠道的花费大。当然。如果可能,那么你可以径直查看花费大的流量渠道表现。
原则三:进行 Engagement-ROAS 分析,发现有提升机会的流量渠道。
原则四:对 ROAS 表现不好的流量渠道,进行归因助攻分析。
异常流量的作弊识别
异常流量与作弊流量本身毫无价值, 对营销与运营毫无效果。
由于品牌类营销缺乏短期的,明确的,可量化的结果,因此品牌类营销领域成为流量作弊的“重灾区”。
反作弊的价值不在于杜绝作弊,而在于增加作弊的成本,使作弊的收益小于正常营销或运营的收益,甚至使作弊的成本大于作弊的收益。
流量作弊情况严重吗?
如果作弊之后的获利空间(利差空间)更大,那么效果作弊也是完全可能存在的。
搜索营销的作弊情况较少, 目的是打击竞争对手,让竞争对手更多地浪费营销费用。
展示类广告的作弊情况较多,主要是 Banner 广告。视频前的贴片广告作弊较少。
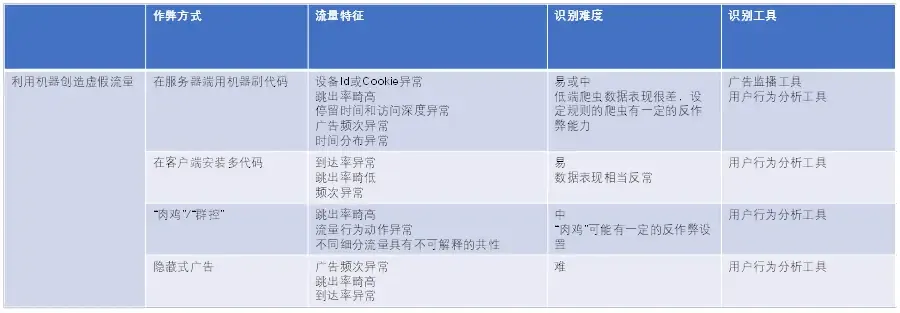
常见的作弊方法
利用伪装(Cloaking)
同一个页面,对机器展示一个内容,对真实的人展示另外一个内容。
利用机器创造虚假流量
利用机器创造的虚假流量被称为Bot流量,添加一些让流量计数增加的代码而创造的。
隐藏式广告在页面中嵌入1像素x1像素的透明GIF图像。
“肉鸡” 是终端设备被黑客远程控制,但这些流量具有非常趋同的行为特征。
“群控” 是控制自己的终端设备,多用 PC 模拟手机,只能是安卓,苹果需要靠买终端设备。
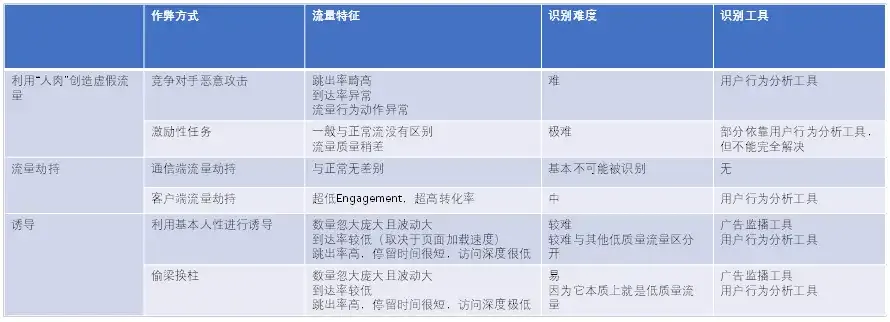
利用 “人肉” 创造虚假流量
人工刷量往往不仅刷流量,还必须刷很多广告主追求的效果数据。
也存在于搜索引擎竞价排名的恶意点击。
激励性任务。
流量劫持
将A渠道的流量修改为B渠道,从而将本来属于A渠道的转化功劳记在B渠道上。
一是在互联网较为底层的数据传输上进行修改。
二是在受众的客户端进行流量劫持。
作弊流量的流量特征
利用机器创造虚假流量
其他
识别作弊流量
技术方法与逻辑方法相结合
技术方法
黑名单库 -> 特征库 -> 监督机器学习
逻辑方法:通过不合理常识的数据识别作弊流量
广告端
点击率过大(视频前贴片 0.1%,信息流1%,搜索引擎竞价10%)
点击频次高(超过1.1)
曝光频次(超过10)
设备ID或者IP分布(部分号段挤占大量展示和点击)
落地端(流量进入企业的私域触点之后的环节)
跳出率太高 - 95%(流量的价值很低)
跳出率太低 - 5% (很难在正常的流量中产生)
Engagement Index 与 ROAS 不匹配
与正常情况不相符的转化率
访问长度和深度的矛盾(短时间内,有较大的访问页数)
大量符合一定规律的注册电话号码(如连号的号段)或者注册用户名与邮箱
流量数量和 Engagement Index 的矛盾
逻辑方法:通过不合理的 Engagement Index 识别作弊流量
线上推广对线下转化效果的评估
难点:线上推广触达的受众和线下的购买者之间很难实现类似于数字世界中的ID匹配,于是线上推广与线下之间的联系实际在屋里层面上被中断了。
追踪购买意向
让潜在客户主动留下电话号码
为每个广告分配不同的电话号码
在访客进入网站时分配访客ID
追踪线上推广带来的线下销售
创造唯一推广渠道的产品
优惠券
购物调研
区隔对比:通过在不同地域进行选择性的投放,以与没有投放的区域进行比较。

数据体系构建👇
DAMA:CDGP 考试重点及知识点分解
DAMA:数据治理 CDGA/CDGP 认证考试备考经验分享
DAMA 数据管理知识体系指南:第一章 数据管理
DAMA 数据管理知识体系指南:第三章 数据治理
DAMA 数据管理知识体系指南:第五章 数据模型与设计
DAMA 数据管理知识体系指南:第七章 数据安全
DAMA 数据管理知识体系指南:第十章 参考数据与主数据
《数据赋能:一本书讲透数字化营销与运营》 — 从正确的数据观开始
更多精彩👇



——Lifecycle生命周期感知)


