常用命令
oracle
数据连接
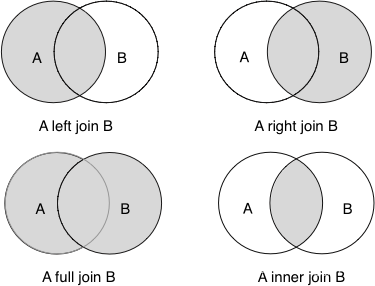
窗口函数over()
窗口函数over()函数常用的有两个属性partition by和order by,partition by类似于group by,我们通常将group by叫做分组,而partition by称作分区,分组返回通常是一行,partition by返回的是多行。
窗口函数主要和统计函数,排名函数,错行的函数联合使用。
例:
select t.*,
(t.score-avg(t.score) over( partition by t.subject_id)) as gaps
from test_student_score t
select t.*, rank() over(order by t.score desc) as ranks
from test_student_score t
where t.subject_id = 3;
排序函数ROW_NUMBER、RANK、DENSE_RANK
(1) row_number():连续’排序,如:1 2 3 4
(2) rank(): 跳跃 排序,如:1 2 2 4
(3) dense_rank():密集排序,如:1 2 2 3
时间函数
时间格式(无大小写区分)
Year:
yy two digits 两位年 显示值:07
yyy three digits 三位年 显示值:007
yyyy four digits 四位年 显示值:2007
Month:
mm number 两位月 显示值:11
mon abbreviated 字符集表示 显示值:11月,若是英文版,显示nov
month spelled out 字符集表示 显示值:11月,若是英文版,显示november
Day:
dd number 当月第几天 显示值:02
ddd number 当年第几天 显示值:02
dy abbreviated 当周第几天简写 显示值:星期五,若是英文版,显示fri
day spelled out 当周第几天全写 显示值:星期五,若是英文版,显示friday
ddspth spelled out, ordinal twelfth
Hour:
hh two digits 12小时进制 显示值:01
hh24 two digits 24小时进制 显示值:13
Minute:
mi two digits 60进制 显示值:45
Second:
ss two digits 60进制 显示值:25
其它
Q digit 季度 显示值:4
WW digit 当年第几周 显示值:44
W digit 当月第几周 显示值:1
24小时格式下时间范围为: 0:00:00 - 23:59:59…
12小时格式下时间范围为: 1:00:00 - 12:59:59 …
获取当前日期和时间的函数:sysdate systimestamp
日期和字符转换函数用法
TO_CHAR(datetime, ‘format’)
TO_DATE(character, ‘format’)
TO_TIMESTAMP(character, ‘format’)
TO_TIMESTAMP_TZ(character, ‘format’)
select to_char(sysdate,‘yyyy-mm-dd hh24:mi:ss’) as nowTime from dual; //日期转化为字符串
1)add_months(date,int):输入date数据和需要增加的月份数(整数),返回增加若干月份数后date数据。
SELECT ADD_MONTHS(SYSDATE, 1) FROM dual;
2)last_day(date):返回当前日期在该月份的最后一天的日期
SELECT LAST_DAY(SYSDATE) from dual;# 假设今天为2021-04-21,那么执行返回的时间日期为2021-04-30
3)months_between(date1,date2):返回两个日期的月份差,存在小数。
-- 返回值刚好为1,因为都是两个月份的02相减。
-- 提示:如果不相等则有很多小数。这时候使用floor进行向下取整或round进行向上取整
SELECT MONTHS_BETWEEN(to_date('2021-05-02','yyyy-mm-dd'), to_date('2021-04-02','yyyy-mm-dd')) as month from dual;
4)加减时间
-- 当前时间减去10分钟,同理换成year(年)、month(月)、day(日)、hour(时)、second(秒)
select sysdate,sysdate - interval '10' minute from dual;
-- 也可以换成加10分钟。
select sysdate,sysdate + interval '10' minute from dual;
5)求时间为星期几或者几月份或多少年
select to_char(sysdate,'D') from dual; --这周的第几天;每周的第一天为星期天,星期一为第二天
--某天星期几 同样可以求多少年(year)多少月(month)
select to_char(to_date('2021-04-08','yyyy-mm-dd'),'day') from dual; --20210408为星期四
--输出英文。某天星期几 同样可以求多少年多少月
select to_char(to_date('2021-04-08','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = AMERICAN') from dual;
6)求两个日期之间的月份
-- 求两个日期之间的月份(如果日期存在差值,则会有很长的小数,使用floor函数可以向下取整。)
-- 结果0,不满一个月
SELECT floor(MONTHS_BETWEEN(to_date('2021-05-01','yyyy-mm-dd'), to_date('2021-04-02','yyyy-mm-dd'))) as month from dual;
-- 求两个日期之间的月份(如果日期存在差值,则会有很长的小数,使用round函数可以四舍五入。)
-- 结果1,过了一半就算一个月。根据需求选择
SELECT ROUND(MONTHS_BETWEEN(to_date('2021-05-01','yyyy-mm-dd'), to_date('2021-04-02','yyyy-mm-dd')),0) as month from dual;
-- 扩展
-- 求人员的年龄
-- 月份相减计算年龄(推荐)
SELECT TRUNC(MONTHS_BETWEEN(to_date('2021-04-01','yyyy-mm-dd'), to_date('1997-04-02','yyyy-mm-dd'))/12,0) as age from dual;
select * from t1 sample(10)--抽取10%的样本
Oracle 三种分页方法(rownum、offset和fetch、row_number() over())
rownum
rownum用于表示返回行的序号
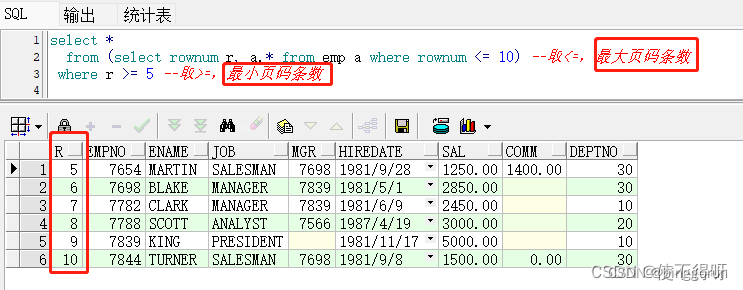
查询emp表中的前10条记录,然后在这10条记录中取出第5到第10条记录作为结果返回。使用rownum进行分页查询的优点是简单易懂,缺点是在查询大量数据时性能较差。
offset和fetch
oracle 12C及以上版本才能使用。
select rownum r, a.*from emp aorder by empno offset 4 rows fetch next 5 rows only;--对emp表按empno列进行排序,然后取出从第5条记录开始的5条记录作为返回
row_number() over()
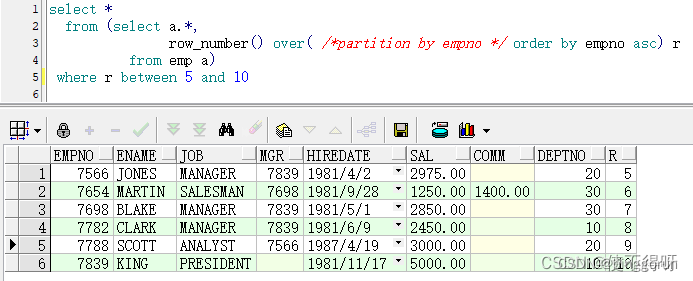
对emp表按照empno列进行排序,然后取出第5到第10条记录作为结果返回。
通配符
%:匹配包含零个或更多字符的任意字符串;
_(下划线):匹配任何单个字符;
[ ]:指定范围 ,([a-f]) 或集合 ([abcdef]) 中的任何单个字符;
[^]:不属于指定范围。
LIKE ‘M[^C]%’ 将搜索以字母 M 开头,并且第二个字母不是 c 的所有名称(如MacFeather)
转义字符
mysql中保持和linux或某些编程语言中一致,使用反斜杠“\”来解决,Oracle中则稍显麻烦。
在字符串拼接时遇到关键字可用quote(q)方法来搞定,但在where条件的like匹配中,就需要使用escape来搞定
对特殊字符进行变换,只要将单引号[‘]转换成两个单引号[’']就可以了
正则表达式
使用了 ‘正则表达式’ 替代了老的 ‘百分比 %’ 和 ‘通配符 _’
(1) regexp_like : 同 like 功能相似(模糊 ‘匹配’)
(2) regexp_instr : 同 instr 功能相似(返回字符所在 ‘下标’)
(3) regexp_substr : 同 substr 功能相似(‘截取’ 字符串)
(4) regexp_replace: 同 replace 功能相似( ‘替换’ 字符串)
其他常用函数
返回第一个非空表达式
COALESCE
COALESCE ( expression,value1,value2……,valuen)
主流数据库系统都支持COALESCE()函数,这个函数主要用来进行空值处理,返回第一个非空值。
COALESCE()函数可以用来完成几乎所有的空值处理,不过在很多数据库系统中都提供了它的简化版,这些简化版中只接受两个变量,其参数格式如下:
MYSQL: IFNULL(expression,value)
MSSQLServer: ISNULL(expression,value)
Oracle: NVL(expression,value)
Oracle:NVL2(x,value1,value2)如果x非空,返回value1,否则返回value2
这几个函数的功能和COALESCE(expression,value)是等价的。
NULLIF(ex1,ex2)函数:如果ex1与ex2相等则返回Null,不相等返回第一个表达式的值;
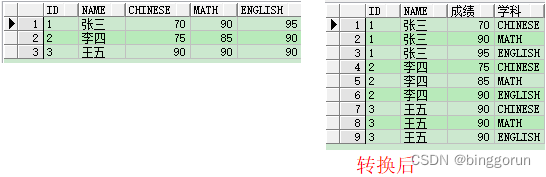
行转列、列转行
pivot:行转列
Oracle 11g之后可用
PIVOT(任意聚合函数 FOR 列名 IN(类型)),其中,【聚合函数】聚合的字段,是需要转化为列值的字段;【列名】是需要转化为列标识的字段,【类型】即是需要的结果展示,【类型】中可以指定别名; IN中还可以指定子查询。
with t_test as(select 1 id, '张三' name, 70 score, 'CHINESE' subject from dual union allselect 1 id, '张三' name, 90 score, 'MATH' subject from dual union allselect 1 id, '张三' name, 95 score, 'ENGLISH' subject from dual union allselect 2 id, '李四' name, 75 score, 'CHINESE' subject from dual union allselect 2 id, '李四' name, 85 score, 'MATH' subject from dual union allselect 2 id, '李四' name, 90 score, 'ENGLISH' subject from dual union allselect 3 id, '王五' name, 90 score, 'CHINESE' subject from dual union allselect 3 id, '王五' name, 90 score, 'MATH' subject from dual union allselect 3 id, '王五' name, 90 score, 'ENGLISH' subject from dual
)
select *from t_test-- 表别名无效!pivot (sum(score) -- 聚合函数for subject in('CHINESE' as 语文, 'MATH' as 数学, 'ENGLISH' as 英语))-- where id in (1, 2, 3)order by id;
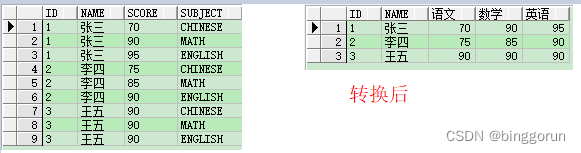
unpivot:列转行
UNPIVOT(自定义列名1【列的值】 FOR 自定义列名2【列名】 IN(【列名】)):其中,【列的值】字段,是将我们的值字段转为行数据中的【自定义列名1】;【列名】是将我们的列标题字段转为行数据中的【自定义列名2】,【列名】即是转为行的列名。
with t_test as (select 1 id, '张三' name, 70 chinese , 90 math , 95 english from dual union allselect 2 id, '李四' name, 75 chinese , 85 math , 90 english from dual union allselect 3 id, '王五' name, 90 chinese , 90 math , 90 english from dual
)
select id,name,score 成绩, -- 新增列subject 学科 -- 新增列from t_test -- 表别名无效!unpivot(score for subject in(chinese, math, english))
-- where id in (1, 2, 3)order by id;
字符串拼接
concat ,||
MySQL的concat函数可以连接一个或者多个字符串,只要其中一个是NULL,那么将返回NULL;
Oracle 的concat函数只能连接两个字符串,只要有一个字符串不是NULL,就不会返回NULL;
-- 多行转字符串
select concat(id,username) str from app_user
select id||username str from app_user--字符串转多列
实际上就是拆分字符串的问题,可以使用 substr、instr、regexp_substr函数方式
concat_ws()函数,有分隔符的字符串连接
mysql> select concat_ws(‘,’,‘11’,‘22’,‘33’);
group_concat()可用来行转列, Oracle没有这样的函数
group_concat([DISTINCT] 要连接的字段[Order BY ASC/DESC 排序字段] [Separator ‘分隔符’])
mysql> select id,group_concat(name) from aa group by id;
±-----±-------------------+
| id | group_concat(name) |
±-----±-------------------+
| 1 | 10,20,20 |
| 2 | 20 |
| 3 | 200,500 |
±-----±-------------------+
wm_concat
oracle独有,功能类似MySQL的group_concat
--wm_concat函数
--wm_concat(列名),该函数可以把列值以","号分隔起来,并显示成一行
select wm_concat(name) name from test;
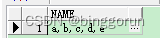
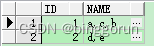
select id,wm_concat(name) name from test group by id;
LISTAGG
Oracle11.2新增,可以用于字符串聚集,实现对列值的拼接,不仅可作为一个普通函数使用,也可作为分析函数。
在每个分组内,LISTAGG根据order by子句对列值进行排序,将排序后的结果拼接起来。
listagg 函数有两个参数:
1、 要合并的列名
2、 自定义连接符号
☆LISTAGG 函数既是分析函数,也是聚合函数
所以,它有两种用法:
1、分析函数,如: row_number()、rank()、dense_rank() 等,用法相似
listagg(合并字段, 连接符) within group(order by 合并的字段的排序) over(partition by 分组字段)
2、聚合函数,如:sum()、count()、avg()等,用法相似
listagg(合并字段, 连接符) within group(order by 合并字段排序) --后面跟 group by 语句
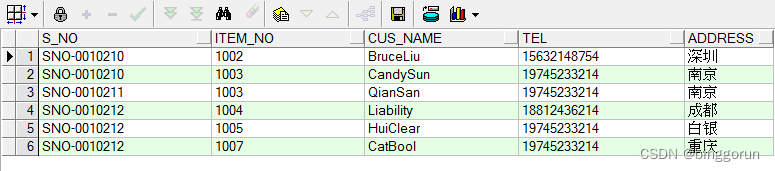
LISTAGG 分析函数用法
SELECT T.S_NO,LISTAGG(T.ITEM_NO, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) ITEM_NO,LISTAGG(T.CUS_NAME, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) CUS_NAME,LISTAGG(T.TEL, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) TEL,LISTAGG(T.ADDRESS, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) ADDRESSFROM test TGROUP BY T.S_NO;

LISTAGG 聚合函数用法
SELECT T.S_NO,LISTAGG(T.ITEM_NO, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) ITEM_NO,LISTAGG(T.CUS_NAME, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) CUS_NAME,LISTAGG(T.TEL, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) TEL,LISTAGG(T.ADDRESS, '/') WITHIN GROUP(ORDER BY T.S_NO, T.ITEM_NO) OVER(PARTITION BY T.S_NO) ADDRESSFROM test T;

去除空格
LTRIM(X[,TRIM_STR]):把X的左边截去trim_str字符串,缺省截去空格
RTRIM(X[,TRIM_STR]):把X的右边截去trim_str字符串,缺省截去空格
TRIM([TRIM_STR FROM]X):把X的两边截去trim_str字符串,缺省截去空格
截取函数
SUBSTR(X,start[,length]):返回X的字串,从start处开始,截取length个字符,缺省length,默认到结尾
取整
CEIL(X):大于或等于X的最小值(上取整)
FLOOR(X):小于或等于X的最大值(下取整)
ROUND(X[,Y]):X在第Y位四舍五入
ABS(X):X的绝对值
SQRT(X):X的平方根
TRUNC(X[,Y]):X在第Y位截断(TRUNC(3.456,2)=3.45)
LOG(X,Y):X为底Y的对数
转换函数
TO_CHAR(d|n[,fmt])
把日期和数字转换为制定格式的字符串。Fmt是格式化字符串
SELECT TO_CHAR(SYSDATE,'YYYY"年"MM"月"DD"日" HH24:MI:SS')"date" FROM dual;

TO_DATE(X,[,fmt])
把一个字符串以fmt格式转换成一个日期类型
TO_NUMBER(X,[,fmt])
把一个字符串以fmt格式转换为一个数字
其他
INSTR(X,STR[,START][,N):从X中查找str,可以指定从start开始,也可以指定从n开始,返回str的位置
mysql
postgres
hive


)



