本文以MySQL作为业务数据库、以Redis作为缓存数据库为例展开,分析数据库与缓存数据一致性解决方案。
纯理论分析,有啥理解不对的请帮忙指出,谢谢。另外没太懂延迟双删是用在哪个环节,感觉分析完了延迟双删用不上
Cache Aside,旁路缓存
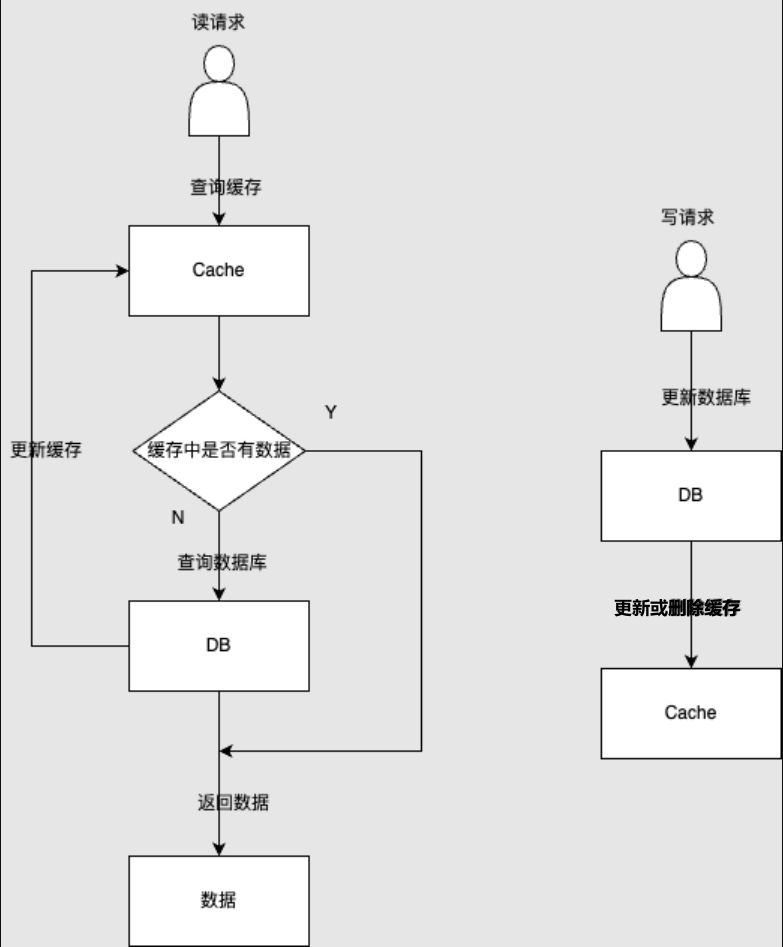
注意,关于写操作,有四种方式,数据库与缓存操作的先后、缓存具体操作方式组合:
- 先更新数据库,再更新缓存
- 先更新缓存,再更新数据库(该方法在涉及调用MySQL数据库函数的操作时就不能用了,因为得先更新MySQL才能获取到更新后的数据,所以该方法并不是很理想)
- 先更新数据库,再删除缓存
- 先删除缓存,再更新数据库
方案零:先实现旁路缓存再说
数据库与缓存一致性解决方案将基于旁路缓存展开。则有如下伪代码实现:
读操作
func get(oid):data = nullcache_key = "cache:" + oidcache_data = redis.get(cache_key)if exist(cache_data):data = deserialize(cache_data)else:data = orm_framework.entity.get(oid)redis.set(cache_key, data)return data
写操作
写操作接下来分析三种方式(先更新缓存,后更新数据的方式二在上节被直接否定了,原因见上节)
方式一:先更新数据库,再更新缓存
func update1(data):orm_framework.entity.update(data)# 方式一,查询更新之后的数据,然后更新缓存data = orm_framework.entity.get(data.oid)cache_key = "cache:" + data.oidredis.set(cache_key, data)return data
方式三:先更新数据库,再删除缓存
func update2(data):orm_framework.entity.update(data)# 直接让缓存失效,例如删除缓存,由读线程重建缓存cache_key = "cache:" + data.oidredis.delete(cache_key)return data
方式四:先删除缓存,再更新数据库
func update2(data):# 直接让缓存失效,例如删除缓存,由读线程重建缓存cache_key = "cache:" + data.oidredis.delete(cache_key)orm_framework.entity.update(data)return data
第零版方案仅仅实现旁路缓存,但各种一致性操作并没有做控制,接下来对第零版方案进行分析。
方案零分析
数据库与缓存数据一致性问题本质上是并发问题在数据一致性上的体现,所以需要站在可见性、原子性、有序性之上来分析和解决该问题。
可见性、原子性、有序性
可见性:需要保证MySQL与Redis两者数据的一致性,在这个场景中,MySQL与Redis自身不会出现可见性问题,服务端线程执行上面的读写操作时不会共享有关变量,无需考虑可见性问题。
原子性:读写操作各自都不是原子性的。分析如下:
读操作
- 假设一开始MySQL与Redis数据一致
- 若读命中缓存,则直接回返回数据,这是单步缓存读,有原子性
- 若没有命中缓存,则会尝试重建缓存,要先从MySQL中读取数据,然后再更新Redis,读MySQL与写Redis这两步操作并非原子性,其他操作可以介于两者中间
写操作(方式一)
- 假设一开始MySQL与Redis数据一致
- 更新MySQL与查询MySQL可以是一个事务,这两步操作具有原子性
- 更新Redis单步操作具有原子性
- 但是这两个系列操作之间不具有原子性,可以插入其他操作
写操作(方式三)
- 与第一种同理,也不具备原子性。
写操作(方式四)
- 与第一种同理,也不具备原子性。
总结,读写操作分别都会操作MySQL和Redis,但由于MySQL与Redis之间没有事务,所以读写操作各自不可能具有原子性。只要不具有原子性的操作在并发时就可能会因为执行顺序导致并发问题。
顺序性
由于读写操作均不具备原子性,必须考虑并发时命令执行顺序导致的问题。读操作命中缓存时不会存在顺序性问题,但读操作重建缓存部分,以及写操作本身,会存在顺序性导致的并发问题,下面针对这两个系列的操作进行分析,由于导致的问题太多,并发情况复杂,这里针对并发读、并发写、并发读写各自举出一个例子来说明并发问题。
并发问题分析
读操作,并发读
读操作重建缓存部分核心步骤就是查询MySQL和更新Redis两个原子性操作。
# MySQL事务,原子性操作
data = orm_framework.entity.get(oid)
# Redis命令,原子性操作
redis.set(cache_key, data)
考虑并发读问题,A线程查询MySQL,B线程查询MySQL,若此时B获得的数据比A更新,接下来B线程更新Redis,最后A线程更新Redis,这时结果就是新的缓存被旧数据覆盖,造成写覆盖问题,导致数据不一致。。
总结一下问题,就是多个线程并发重建缓存,有可能会出现新数据缓存被旧数据覆盖的情况。
另外,这里本身不太合适让所有线程都可以重建缓存,一是多余的缓冲重建是浪费资源,二是所有读线程参与缓存重建意味着都要查询MySQL,这就容易导致缓存击穿问题(当然这里也有缓存穿透问题,但与一致性问题相关不大,可以在现有流程扩充功能即可,本文讨论缓存穿透问题)。
写操作,并发写
方式一
方式一写操作核心流程就是更新、查MySQL和更新Redis两个原子性操作。
# MySQL事务,原子性操作
orm_framework.entity.update(data)
data = orm_framework.entity.get(data.oid)
# Redis命令,原子性操作
redis.set(cache_key, data)
与读操作同理,考虑写并发情况,同样会出现写覆盖问题,A线程先更新MySQL数据,B线程再更新MySQL数据,随后B线程更新缓存,最后A线程更新缓存,这时新缓存数据被旧数据覆盖,出现写覆盖问题,导致数据不一致。
方式二
方式二写操作核心流程就是更新MySQL和删除Redis两个原子性操作。
# MySQL事务,原子性操作,记为write1操作
orm_framework.entity.update(data)
# Redis命令,原子性操作,记为write2操作
redis.delete(cache_key)
使用删除策略的一个好处就是不会出现写覆盖问题,就是因为是删除缓存操作,A线程先更新MySQL数据,B线程再更新MySQL数据,然后B线程删除缓存,最后A线程删除缓存,这种情况完全没有问题。也就是说,写并发下,采用删除的方式不会有顺序问题,这时删除的优势,不过读写并发就会有一定问题,这个问题后续讨论。
方式三
方式二写操作核心流程就是删除Redis和更新MySQL两个原子性操作。
# Redis命令,原子性操作,记为write2操作
redis.delete(cache_key)
# MySQL事务,原子性操作,记为write1操作
orm_framework.entity.update(data)
方式三与方式二同理,在写并发下没有写覆盖问题,但读写并发会有问题,这个问题后续讨论。
读写并发
方式一写操作本身写并发就有写覆盖问题,考虑读写并发就更复杂且有更多问题,这里不再展开。
方式二写操作与方式三写操作没有写覆盖问题,读写并发时,由于读并发有写覆盖问题,写操作无论采用方式二和方式三都会有并发问题。
总结
以上,分别分析了并发读、并发写、并发读写的情况,可以得出结论,读操作中有两个原子操作,MySQL一个、Redis一个,由于顺序不能保证,导致并发问题,写操作中同理也是两个原子操作,方式一本身就存在并发问题,方式二、三本身没有,但是整体上看,读写并发时,读一定有问题,读可能有问题,并发读写一定有问题
方案一:分布式锁
并发本身是用来解决CPU等资源利用率的问题,那么解决并发带来的问题最通用的方案解决并发本身,就是加锁,只让一个线程操作,那么可以采用分布式锁尝试解决一致性问题。
读操作
func get(oid):data = nullcache_key = "cache:" + oidcache_data = redis.get(cache_key)if exist(cache_data):data = deserialize(cache_data)else:# 双检锁# 加锁,保证重建缓存的顺序性# 双检,保证不会重复重建缓存以及重复查询MySQL,防止缓存击穿# 这里重建缓存时也可以新开一个子线程重建缓存,主线程直接返回旧数据,这里由主线程负责重建缓存,更快一些,不过要注意把分布式锁传给子线程由子线程解锁# 另外,这里也可以采用两把锁,一把读锁,一把写锁,读操作用读锁,下文的写操作用写锁,这里就是单纯的一把分布式锁控制lock_key = "lock:" + oidsucc = redis.setnx(lock_key, ttl)while !succ:succ = redis.setnx(lock_key)cache_data = redis.get(cache_key)if exist(cache_data):data = deserialize(cache_data)else:data = orm_framework.entity.get(oid)redis.set(cache_key, data)redis.delete(lock_key)return data
- 读操作命中缓存直接返回
- 读操作重建缓存使用分布式锁,操作时对于同一条数据只会有一个线程进行重建,且采用双检锁防止重复重建及缓存击穿,因为不再并发就不会由写覆盖问题,重建缓存之外的读线程在获取分布式锁处阻塞自旋
写操作,方式一
func update1(data):lock_key = "lock:" + oidsucc = redis.setnx(lock_key, ttl)while !succ:succ = redis.setnx(lock_key)orm_framework.entity.update(data)# 查询更新之后的数据,然后更新缓存data = orm_framework.entity.get(data.oid)cache_key = "cache:" + data.oidredis.set(cache_key, data)redis.delete(lock_key)return data
- 写操作采用分布式锁(与重建缓存是一把分布式锁),对于同一条数据的更新,只会有一个线程进行MySQL更新和Redis更新,不会出现写覆盖问题
读操作+读操作方式一分析
- 读写操作使用同一个分布式锁,则读操作重建缓存与写操作两者也是有序的,能保证重建缓存时一定重建的是最新的缓存,重建完缓存之后,被阻塞的读操作自然也能从缓存中读到最新数据
- 若MySQL与Redis不宕机,且后端线程不意外崩溃,当写操作更新完数据之后到写操作更新缓存之前这一段时间内,MySQL与Redis会不一致,当然这一点可以优化,当前仅仅采用了一个分布式锁,如果采用读写锁,只要读缓存加读锁,重建缓存也加读锁,写操作整个加写锁,这样使用读写锁机制能保证这一小段时间不会有读操作能读到数据(读写锁可以基于Redis及Lua脚本实现,两个分布式锁加一定的逻辑)
- 若MySQL与Redis不宕机,后端线程在执行写操作时,执行完更新MySQL事务并提交后直接宕机,Redis没有更新,这时会出现不一致情况,当然后面只要重建缓存,则一定是最新的数据
- 整体上,读操作+写操作方式一构成了一个无限趋近于强一致性的最终一致性解决方案
写操作,方式三
先更新数据库,再删除缓存
func update1(data):lock_key = "lock:" + oidsucc = redis.setnx(lock_key, ttl)while !succ:succ = redis.setnx(lock_key)orm_framework.entity.update(data)# 删除缓存cache_key = "cache:" + data.oidredis.delete(cache_key)redis.delete(lock_key)return data
- 前文已分析过,读的两个删除缓存方案在并发读时没有写覆盖问题,方式一有写覆盖问题使用分布式锁可以保证一致性,则没有写覆盖问题的方式三自然可以
- 同样的是,这里也存在写操作更新完数据库后,在删除缓存之前,会导致读操作读取旧缓存数据的情况,等到缓存被删除后,读操作被阻塞,然后有且仅有一个读线程重建最新的缓存,也能达成最终一致性,同样的是这一点能采用读写锁优化
- 同样的是,若MySQL与Redis不宕机,后端线程在执行写操作时,执行完更新MySQL事务并提交后直接宕机,Redis缓存没有删除,这时会出现不一致情况,当然后面只要重建缓存,则一定是最新的数据
- 整体上,读操作+写操作方式二构成了一个无限趋近于强一致性的最终一致性解决方案
写操作,方式四
先删除缓存,再更新数据库
func update1(data):lock_key = "lock:" + oidsucc = redis.setnx(lock_key, ttl)while !succ:succ = redis.setnx(lock_key)# 删除缓存cache_key = "cache:" + data.oidredis.delete(cache_key)orm_framework.entity.update(data)redis.delete(lock_key)return data
- 同理,前文已分析过,读的两个删除缓存方案在并发读时没有写覆盖问题,方式一有写覆盖问题使用分布式锁可以保证一致性,则没有写覆盖问题的方式四自然可以
- 不同的是,这里不会因为写操作数据库事务提交后,后端线程意外崩溃导致MySQL与Redis数据不一致,也没有事务提交后到删除缓存前的这一段数据不一致时间,一切因为先删除缓存,使得所有读操作被阻塞自旋,由于写线程持有分布式锁,没有一个读线程可以重建缓存,不会读到旧数据,等到更新完MySQL后写操作释放锁,才会重建缓存,再之后大量读操作才能读最新的数据。
- 读操作+写操作方式四是一个强一致性方案
总结:采用读操作+写操作方式四(先删除缓存再更新数据库)的方式可以实现一个数据库与缓存数据强一致性解决方案。
??? 注意
既然采用删除缓存的写操作没有覆盖更新问题,那么写操作采用的分布式锁可否去掉?不可以,举个例子,上文所述,采用删除缓存的写操作虽然在写并发下没有更新覆盖问题,但整个读写并发是有问题的,通过加分布式锁,能保证读操作重建缓存时一定读到的是最新的MySQL数据,且更新缓存之前不会有其他操作,所以能保持一致,若要去掉写操作的分布式锁,会出现这样的情况,读线程查询MySQL,写线程更新MySQL,写线程删除Redis,读线程更新Redis,就缓存上了旧数据
方案一是一个成熟的并发场景下数据库和缓存强一致性解决方案了,不过当处于高并发场景时,可能还需要很多权衡和改造来满足大量请求。
方案二:高并发解决方案
当处于高并发场景时,只有一个优化准则,一致性换可用性,数据一致一定能保证功能能正确执行,但是高并发场景的可用性就比较差。 可以参考CAP与BASE定理分析。
下面在方案一的基础上基于一致性换可用性的思路来给出高并发方案。
读操作优化
方案一读操作在高并发场景下会存在哪些问题?
- 缓存击穿、缓存穿透、缓存雪崩不再分析,误解锁锁续约不再分析,根据对应方案进行改造即可。
- 读操作最大的问题是重建缓存时,除重建缓存的线程之外,其余线程均会空转自旋在获取分布式锁这一步,极大影响高并发读。
怎么解决方案一非重建缓存线程自旋问题?
- 方法一,直接返回空数据,这种在大多数情况下都不合适,用户体验上,页面数据旧一些也比没数据强,用缓存的目的就在于少访问数据库但是把数据返回
- 方法二,缓存逻辑过期,缓存不设置ttl,但额外设置一个
cache:ttl:id的key记录缓存的过期时间,这样读操作获取不到锁就返回旧数据即可
func get(oid):data = nullcache_key = "cache:" + oidcache_ttl_key = "cache:ttl:" + oidcache_data = redis.get(cache_key)cache_ttl = redis.get(cache_ttl_key)if exist(cache_data):data = deserialize(cache_data)if !(exist(cache_ttl) and cache_ttl > current_timestamp():# 双检锁# 加锁,保证重建缓存的顺序性# 双检,保证不会重复重建缓存以及重复查询MySQL,防止缓存击穿# 这里重建缓存时也可以新开一个子线程重建缓存,主线程直接返回旧数据,这里由主线程负责重建缓存,更快一些,不过要注意把分布式锁传给子线程由子线程解锁lock_key = "lock:" + oidsucc = redis.setnx(lock_key, ttl)# 获取锁失败,直接返回旧数据if !succ:return datacache_data = redis.get(cache_key)cache_ttl = redis.get(cache_ttl_key)if exist(cache_data) and exist(cache_ttl) and cache_ttl > current_timestamp()):data = deserialize(cache_data)else:data = orm_framework.entity.get(oid)redis.set(cache_key, data)redis.set(cache_ttl, current_timestamp() + 30)redis.delete(lock_key)return data
写操作优化
缓存本质上是用来加速读操作的,写操作本身并发程度会受限于MySQL数据库,所以写操作这里可以优化但优化程度是有限的。
由于写操作中缓存不再具有ttl而是改为cache:ttl:id替代,所以写操作这里更新缓存时需要也更新cache:ttl:id。
写操作方式一(先更新MySQL,再更新Redis):这时需要更新cache:id和cache:ttl:id。
写操作方式二(先更新MySQL,再删除Redis):这时需要更新cache:id和更新cache:ttl:id,通过将当前时间写入cache:ttl:id表示已过期。
写操作方式三(先删除Redis,再更新MySQL):同写操作方式二。
经过上述改造,写操作便可以与读操作协作了。
到目前为止,牺牲读操作非重建缓存线程读缓存这一部分的一致性,提高了并发读性能,由于重建缓存依然采用分布式锁机制度,所以可以保证在下一次重建缓存完毕后,一定能达成最终一致性状态。这时也算是一个差不多的最终一致性方案了。
还能考虑再优化一点吗?接下来尝试去掉写操作的分布式锁。
方案三
在方案二基础上,尝试去掉写操作的分布式锁,原本重建缓存一定可以重建最新数据,但现在要牺牲重建缓存时的一致性。
方案一中写操作的分布锁用来保证读操作重建缓存与写操作两者有序,以及通过先删除的方式阻塞读操作,不过方案二中已经牺牲读缓存这部分的一致性了,那么重建缓存与写操作两者间的一致性能否牺牲以换取高并发可用,就是将写操作的分布式锁去掉呢?
首先,从写并发开始分析,前文所述,写操作方式一是存在写覆盖问题的,该方案顺序问题太复杂,一要考虑并发写覆盖,二要考虑重建缓存与写并发间的并发问题,该方式不太合适(并发问题情况太多不再一一分析)。
写操作采用更新方式就不能去掉分布式锁吗?可以,同样也是牺牲数据一致性换取可用性,问题在于,本身更新方式会造成写覆盖问题,然后读操作与写操作也会出现并发问题,相对于删除方案,性能相差不大,但对一致性多了一个写覆盖问题的损害。
其次,写操作方式二和写操作方式三本身不存在写覆盖问题,不过由于要配合读操作,在方案二中采用逻辑过期方案,那么这时不能删除缓存,而是更新cache:ttl:id,若去掉分布式锁,更新cache:ttl:id,就会出现写覆盖问题,不过巧的是,写操作更新cache:ttl:id是把当前时间写入表示缓存过期,模拟一下写覆盖场景,线程A更新MySQL,线程B更新MySQL,线程B更新cache:id,更新cache:ttl:id为t2,线程A更新cache:id,更新cache:ttl:id为t1,若t1和t2是从后端线程获取的时间,则t1 < t2 <=当前时间,不影响缓存过期判定,若采用lua脚本t1与t2从redis节点获取时间,则t2 < t1 < 当前时间,当然,这一切实在所有机器时间一致的情况下。总之,尽管cache:ttl:id更新会存在写覆盖的情况,但是完全不影响缓存过期判断,所以写操作去掉分布式锁,同时也能与读操作的优化相配合。既然写操作方式二和写操作方式三并发写本身没有问题,则接下来分别分析这两种写操作与重建缓存间的并发关系。
最后,分析一下读操作方式三、读操作方式四与重建缓存间的并发关系。在方案一中,写操作方式三与写操作方式四的区别在于写操作方式四优于方式三两点:
- 方式四通过先删除缓存和分布式锁的手段,保证不会出现方式三中更新MySQL后到删除Redis前的一段不一致时期
- 方式四通过优先删除缓存的方式,保证不会出现方式三中更新MySQL后后端线程意外崩溃,导致Redis与MySQL不一致
现在若去掉写线程的分布式锁,则方式四仅剩第2个优点了。另外,在并发写的执行序列下,方式三与方式四差不多,但由于前面说的优点,下面以方式四为例进行分析。
def update4(data):cache_ttl_key = "cache:ttl:" + data.oidredis.set(cache_ttl_key, current_timestamp())orm_framework.entity.update(data)return data
整体来看,读操作命中缓存直接返回,未命中也没获取到锁返回旧数据,未命中获取到锁重建缓存,但是重建缓存不一定是最新的,写操作,先删除缓存,再更新数据库,写操作不再有分布式锁。
至此,高并发场景下数据库与缓存一致性方案大体完成。还有一个问题,尽管牺牲了一致性,以换取可用性,但根据CAP和BASE,至少应当追求最终一致性,那么当前方案能否达成最终一致性?
首先,方案三牺牲了两部分一致性,第一部分是允许重建缓存时获取不到锁的线程直接返回旧数据,不过这部分最终还是要读缓存的,只要缓存与数据库之后一致,这部分无需担心,第二部分是牺牲了重建缓存时缓存与数据库的一致性,这部分是唯一要分析的点。
分析:重建缓存过程中读写并发时什么时候会造成不一致?
- 首先由于写并发是缓存失效方案,写并发之间本身没有问题
- 重建缓存的读线程与写线程之间有问题,重建缓存的线程会加分布式锁,同一时间只会有一个,所以要分析的实际上是一读多写的数据库和缓存一致性问题。
有六个写线程并发,update和delete,右边是真实的并发操作序列。

真正的并发写操作序列可以归纳为:...+ 若干delete操作+若干update操作+若干update操作+...,update和delete轮番操作,但两次操作的时间间隔和delete段与update段的操作次数都不相同

下图中,中间是写操作序列,左右两边分别列出读操作重建缓存的操作情况,注意,重建缓存同一时刻只会有一个线程在操作,这里是画出了不同的序列交叉情况。
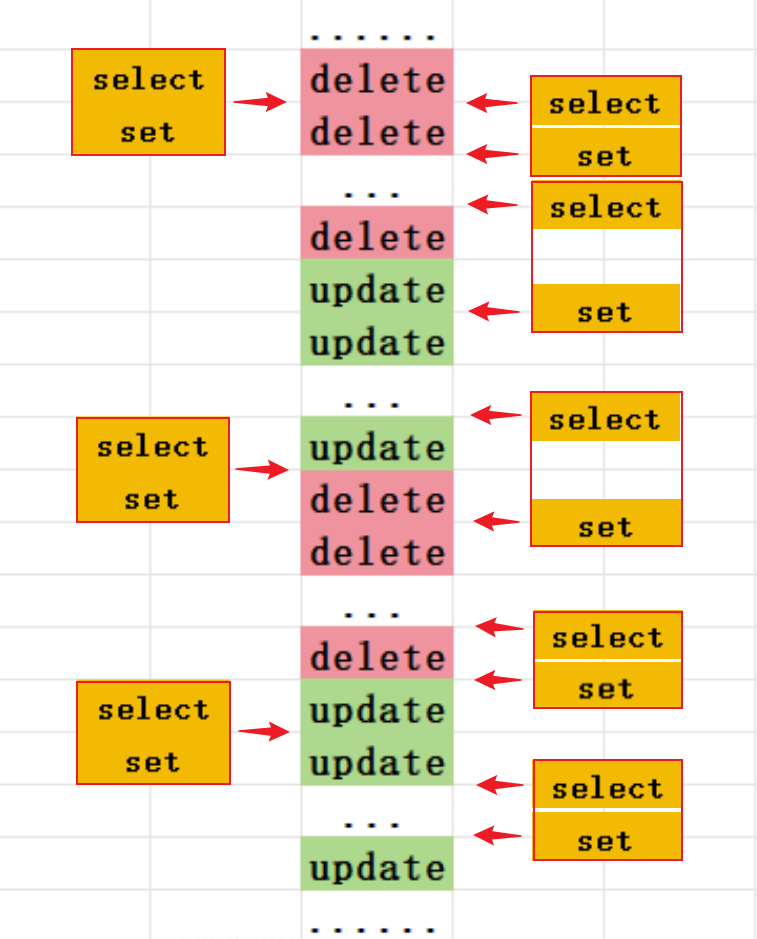
- 显然,重建缓存操作的select和set之间没有写操作,在这一步就一定能达成数据一致性
- 若select与set之间都是delete操作,那么也能达成数据一致性
- 若select与set之间但凡有一个update操作,都会导致重建完缓存之后数据不一致,当然,在下一次重建缓存时就会把本次的数据更新缓存,但是下一次重建缓存也可能会有下一次的数据不一致。
结论:当前方案会使数据从一致到不一致再到一致,即达到最终一致性,其中数据从一致到不一致是当前方案做出的牺牲,从不一致到一致快速恢复却取决于具体操作序列,可能比较长,可能很短,并不稳定。不过可以做一个优化,上述可以得出结论,下次重建缓存距离本次更新越近,则本次更新的数据就能越快写到缓存,故此时可以考虑在写方案四的基础上在最后再进行一个缓存删除操作,即双删,以降低缓存重建间隔。
def update4(data):cache_ttl_key = "cache:ttl:" + data.oidredis.set(cache_ttl_key, current_timestamp())orm_framework.entity.update(data)redis.set(cache_ttl_key, current_timestamp())return data
值得说明的是,而且这个操作对某些特殊情形十分有帮助。
本方案中如果数据从一致变成不一致,那么操作序列一定是这样的:
情形一
select
update
...
update
delete
...
delete
set
情形二
select
delete
...
delete
update
...
updateset
情形三
...
select
update
...
updateset
考虑先delete然后update的情况,若以上三种情形发生之后不再有写操作,或者很久之后才会有写操作,那么这时得等到下一次写操作过来才能重建缓存,或者等缓存失效才能重建缓存,所以给写操作最后加一次删除缓存是为了解决某次写操作后数据不一致但无法快速重建缓存的场景。
总结一下,在方案二基础上,去掉写操作分布式锁,改为双删形式,第一删防止写操作提交MySQL事务后线程崩溃,无法快速重建缓存,第二删,防止某写操作造成不一致后,长时间没有写操作导致长期无法重建缓存。整体可以达成一个最终一致性方案。
方案四
在方案三的基础上,引入canal,由于方案三本身就是最终一致性方案,读操作不再使用分布式锁操作,主要是为了保证写操作更新MySQL时能尽可能快的重建缓存。那么可以考虑使用canal取代写操作自身缓存失效的这么一个操作,或者做一个双保险,保留写操作缓存失效操作,同时启用canal做一个兜底,因为canal顺序解析日志,也是顺序更新缓存,可以明确地只要消费完canal的消息,就可以达成最终一致性,这个程度比方案三稍微快一下。
总结
方案一,分布式锁:强一致性方案,不适用于高并发场景
方案二,缓存逻辑过期+分布式锁:最终一致性方案,不能保证接口数据能返回最新的,但能保证MySQL与Redis保持强一致
方案三,缓存逻辑过期+双删:整体最终一致性
方案四,缓存逻辑过期+双删或canal:能更稳定达到最终一致性的方案
库)


)
