文章目录
- 一、MySQL 多线程复制的背景
- 二、MySQL 5.5 主从复制
- 1、原理
- 2、部署主从复制
- 2.1、主节点安装配置MySQL 5.5
- 2.2、从节点安装配置MySQL 5.5
- 3、检查主从库 `server_id` 和 `log_bin` 配置
- 4、创建主从复制用户
- 5、获取主库的二进制日志文件和位置
- 6、配置从库连接主库参数并启动从库复制进程
- 7、验证主从复制
- 7.1、查看主库从库数据
- 7.2、主库创建表并插入数据
- 7.3、从库执行查询操作
- 8、MySQL 5.5 单线程体现
- 三、MySQL 5.6 基于 schema(库级别) 的并行复制
- 1、原理
- 2、存在的问题
- 3、部署主从复制
- 3.1、主节点安装配置 MySQL 5.6
- 3.2、从节点安装配置 MySQL 5.6
- 4、检查主从库`server_id`、`log_bin`、 `slave_parallel_workers`
- 5、创建主从复制用户
- 6、获取主库的二进制日志文件和位置
- 7、配置从库连接主库参数并启动从库复制进程
- 8、验证主从复制
- 8.1、查看主库从库数据
- 8.2、主库创建表并插入数据
- 8.3、从库执行查询操作
- 9、主节点单库多表 sysbench 写压测 从节点测试延迟
- 9.1、安装 sysbench 压测工具
- 9.2、创建测试数据库
- 9.3、使用 `sysbench` 准备测试数据
- 9.4、运行写操作测试
- 9.5、从库采集延迟时间
- 9.6、事务处理速度(TPS,Transactions Per Second)和查询处理速度(QPS,Queries Per Second)
- 9.7、清除测试数据
- 10、主节点多库多表 sysbench 写压测 从节点测试延迟
- 10.1、创建测试数据库
- 10.2、使用 `sysbench` 准备测试数据
- 10.3、运行写操作测试
- 10.4、从库采集延迟时间
- 四、MySQL 5.7 基于组提交的并行复制
- 1、原理
- 2、部署主从复制
- 2.1、主节点安装配置 MySQL 5.7
- 2.2、从节点安装配置 MySQL 5.7
- 3、检查主从库`server_id`、`log_bin`、 `slave_parallel_workers`、`slave-parallel-type`
- 4、创建主从复制用户
- 5、获取主库的二进制日志文件和位置
- 6、配置从库连接主库参数并启动从库复制进程
- 7、验证主从复制
- 7.1、查看主库从库数据
- 7.2、主库创建表并插入数据
- 7.3、从库执行查询操作
- 8、主节点单库多表 sysbench 写压测 从节点测试延迟
- 8.1、安装 sysbench 压测工具
- 8.2、创建测试数据库
- 8.3、使用 `sysbench` 准备测试数据
- 8.4、运行写操作测试
- 8.5、从库采集延迟时间
- 8.6、事务处理速度(TPS,Transactions Per Second)和查询处理速度(QPS,Queries Per Second)
- 8.7、清除测试数据
- 五、MySQL 8.0 基于 WriteSet 的并行复制
- 1、概述
- 2、核心原理
- Master 端
- Slave 端
- 3、MySQL 8.0 相关参数
- 3.1、binlog_transaction_dependency_tracking
- 3.2、transaction_write_set_extraction
- 3.3、binlog_transaction_dependency_history_size
- 4、WriteSet 依赖检测条件
- 5、基于 COMMIT_ORDER,WRITESET_SESSION,WRITESET 方案的压测
- 6、开启并行复制
- 6.1、主库
- 6.2、从库
一、MySQL 多线程复制的背景
MySQL 的主从复制延迟一直是受开发者最为关注的问题之一,MySQL 从 5.6 版本开始追加了并行复制功能,目的就是为了改善复制延迟问题,并行复制称为enhanced multi-threaded slave(简称MTS)。
- MySQL 的复制是基于 binlog 的。
- MySQL 复制包括两部分,从库中有两个线程:IO 线程和 SQL 线程。
- IO 线程主要是用于拉取接收 Master 传递过来的 binlog,并将其写入到 relay log.
- SQL 线程主要负责解析 relay log,并应用到 slave 中。
- IO 和 SQL 线程都是单线程的,然而master却是多线程的,所以难免会有延迟,为了解决这个问题,多线程应运而生了。
- IO 没必要多线程,因为 IO 线程并不是瓶颈。
- SQL 多线程,目前最新的5.6,5.7,8.0 都是在 SQL 线程上实现了多线程,来提升 slave 的并发度,减少复制延迟。
二、MySQL 5.5 主从复制
1、原理
- master 节点上的binlogdump 线程,在slave 与其正常连接的情况下,将binlog 发送到slave 上。
- slave 节点的I/O Thread ,通过读取master 节点binlog 日志名称以及偏移量信息将其拷贝到本地relay log 日志文件。
- slave 节点的SQL Thread,该线程读取relay log 日志信息,将在master 节点上提交的事务在本地回放,达到与主库数据保持一致的目的。

2、部署主从复制
| 主库 | 192.168.112.10 |
|---|---|
| 从库 | 192.168.112.20 |
| MySQL版本 | 5.5.62 |
2.1、主节点安装配置MySQL 5.5
cd /usr/local
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.5.62-linux-glibc2.12-x86_64.tar.gz
tar -zxvf mysql-5.5.62-linux-glibc2.12-x86_64.tar.gz
ln -s mysql-5.5.62-linux-glibc2.12-x86_64 mysql
groupadd mysql
useradd -r -g mysql mysql
cd /usr/local/mysql
chown -R mysql:mysql .
mkdir -p /usr/local/mysql/data
chown -R mysql:mysql /usr/local/mysql/data
./scripts/mysql_install_db --user=mysql --datadir=/usr/local/mysql/data
cat > /etc/my.cnf << EOF
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysqld.pid
user = mysql
port = 3306
# 二进制日志配置
server-id = 1
log-bin = mysql-bin
binlog-format = row
expire_logs_days = 10# 主从复制配置
log-slave-updates = 1
read-only = 0
EOF
cat > /etc/systemd/system/mysqld.service << EOF
[Unit]
Description=MySQL 5.5 Database Server
After=network.target[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
echo 'export PATH="/usr/local/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
mysqladmin -uroot password '123'
2.2、从节点安装配置MySQL 5.5
cd /usr/local
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.5.62-linux-glibc2.12-x86_64.tar.gz
tar -zxvf mysql-5.5.62-linux-glibc2.12-x86_64.tar.gz
ln -s mysql-5.5.62-linux-glibc2.12-x86_64 mysql
groupadd mysql
useradd -r -g mysql mysql
cd /usr/local/mysql
chown -R mysql:mysql .
mkdir -p /usr/local/mysql/data
chown -R mysql:mysql /usr/local/mysql/data
./scripts/mysql_install_db --user=mysql --datadir=/usr/local/mysql/data
cat > /etc/my.cnf << EOF
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysqld.pid
user = mysql
port = 3306
# 主从复制配置
server-id = 2
relay-log = mysql-relay-bin
log-bin = mysql-bin
read-only = 1
EOF
cat > /etc/systemd/system/mysqld.service << EOF
[Unit]
Description=MySQL 5.5 Database Server
After=network.target[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
echo 'export PATH="/usr/local/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
mysqladmin -uroot password '123'
select version();
mysql -V
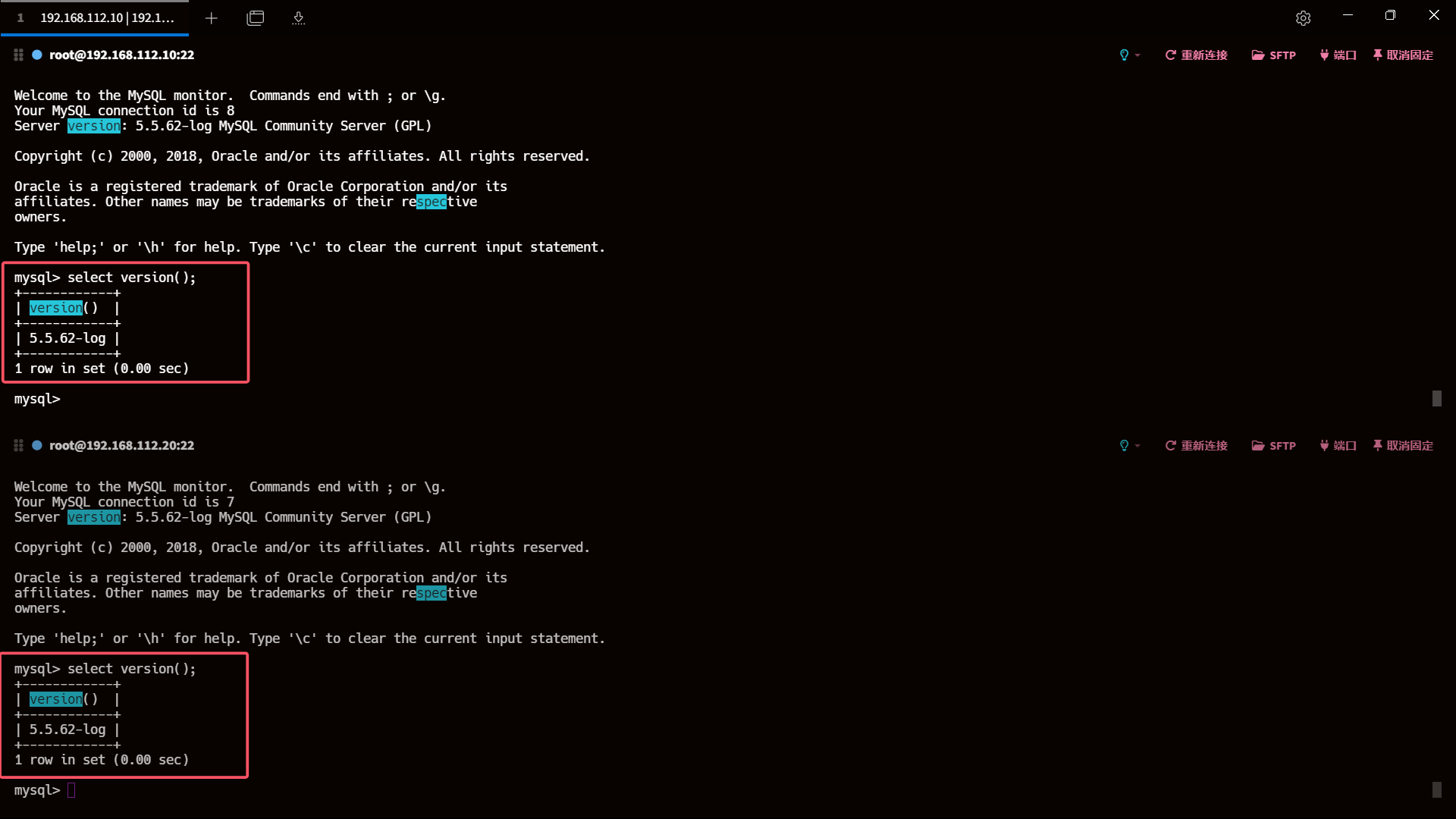
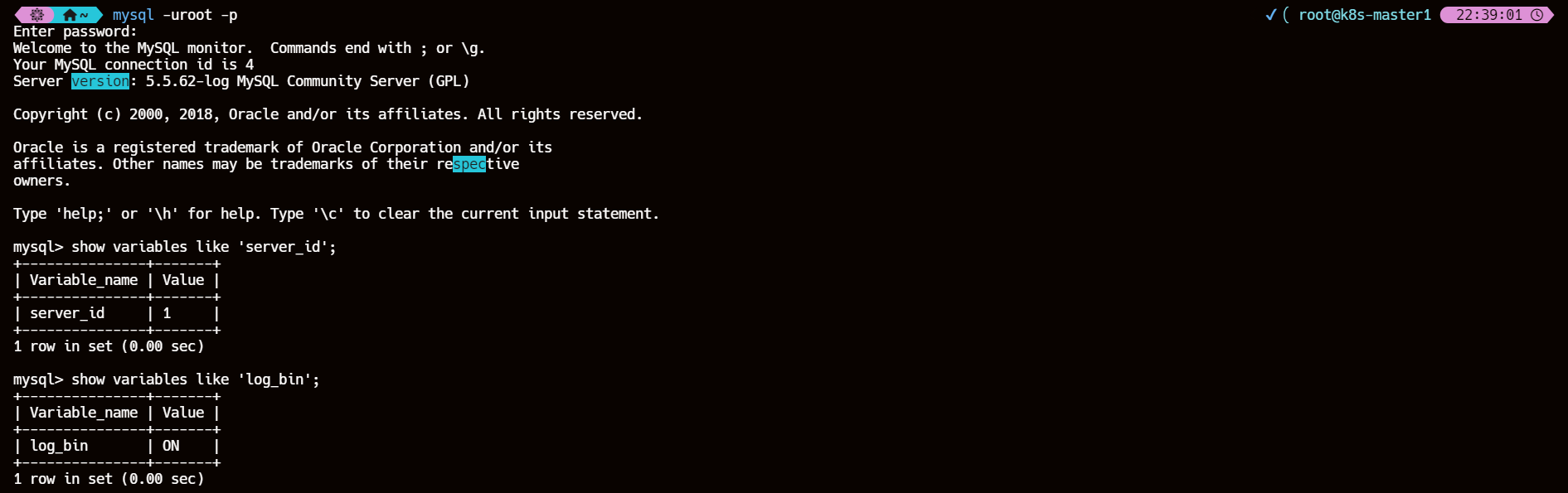
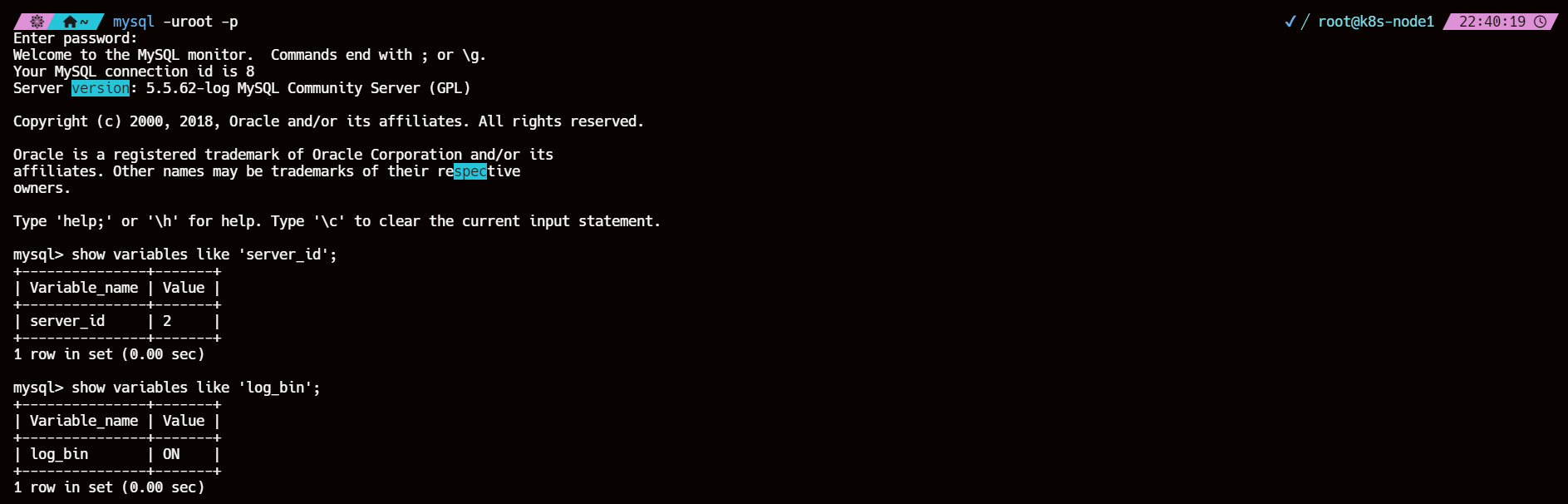
3、检查主从库 server_id 和 log_bin 配置
show variables like 'server_id';
show variables like 'log_bin';
| 主库 |
|---|
 |
| 从库 |
 |
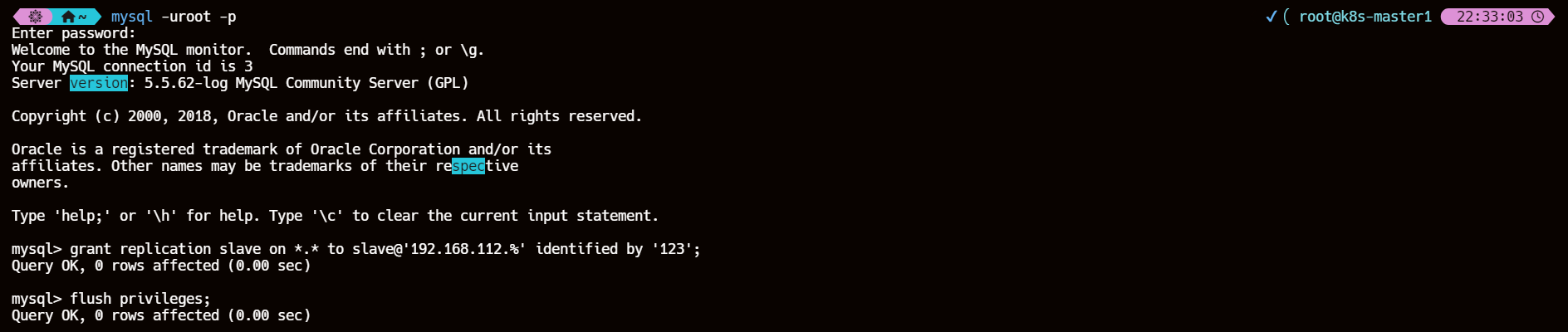
4、创建主从复制用户
主库
#登录数据库
mysql -uroot -p123#创建slave用户
grant replication slave on *.* to slave@'192.168.112.%' identified by '123';flush privileges;
grant replication slave on *.*: 授予replication slave权限,允许用户从主库复制数据。*.*表示所有数据库和所有表。to slave@'192.168.112.%': 指定用户名为slave,允许从192.168.112.%子网内的任何IP地址连接到主库。identified by '123': 设置用户的密码为123。
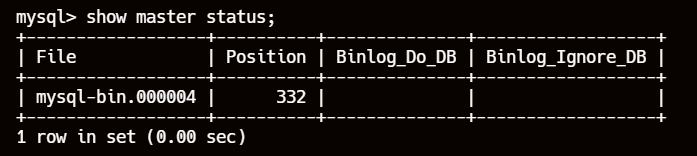
5、获取主库的二进制日志文件和位置
# 记录下 File 和 Position 的值
show master status;
6、配置从库连接主库参数并启动从库复制进程
change master to
master_host='192.168.112.10',
master_user='slave',
master_password='123',
master_log_file='mysql-bin.000004',
master_log_pos=332;start slave;
show slave status\G;
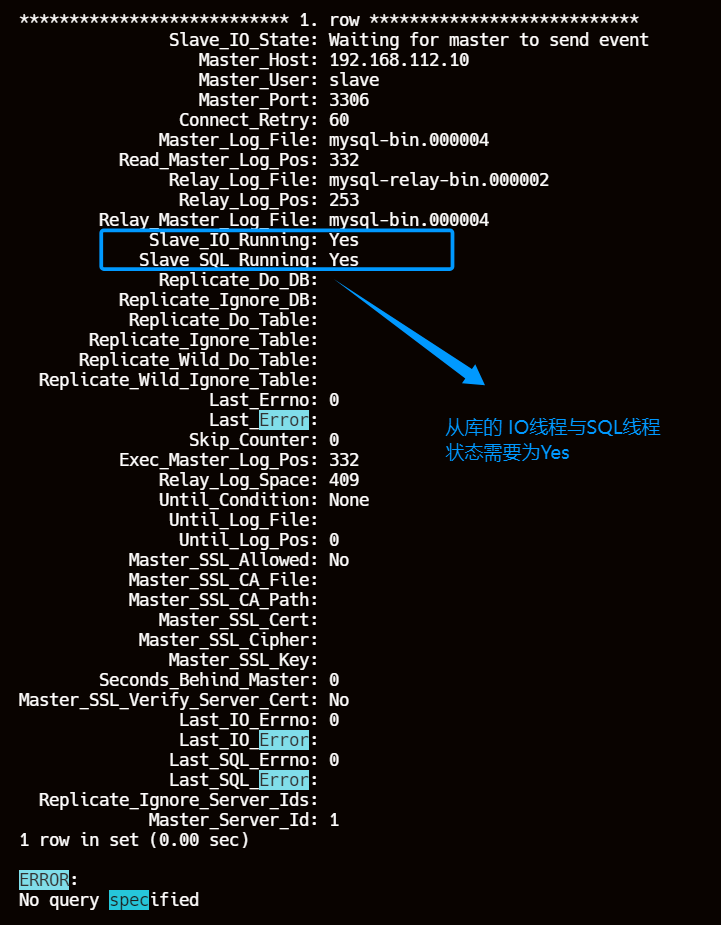
7、验证主从复制
7.1、查看主库从库数据
目前数据一致
show databases;use test ; show tables;
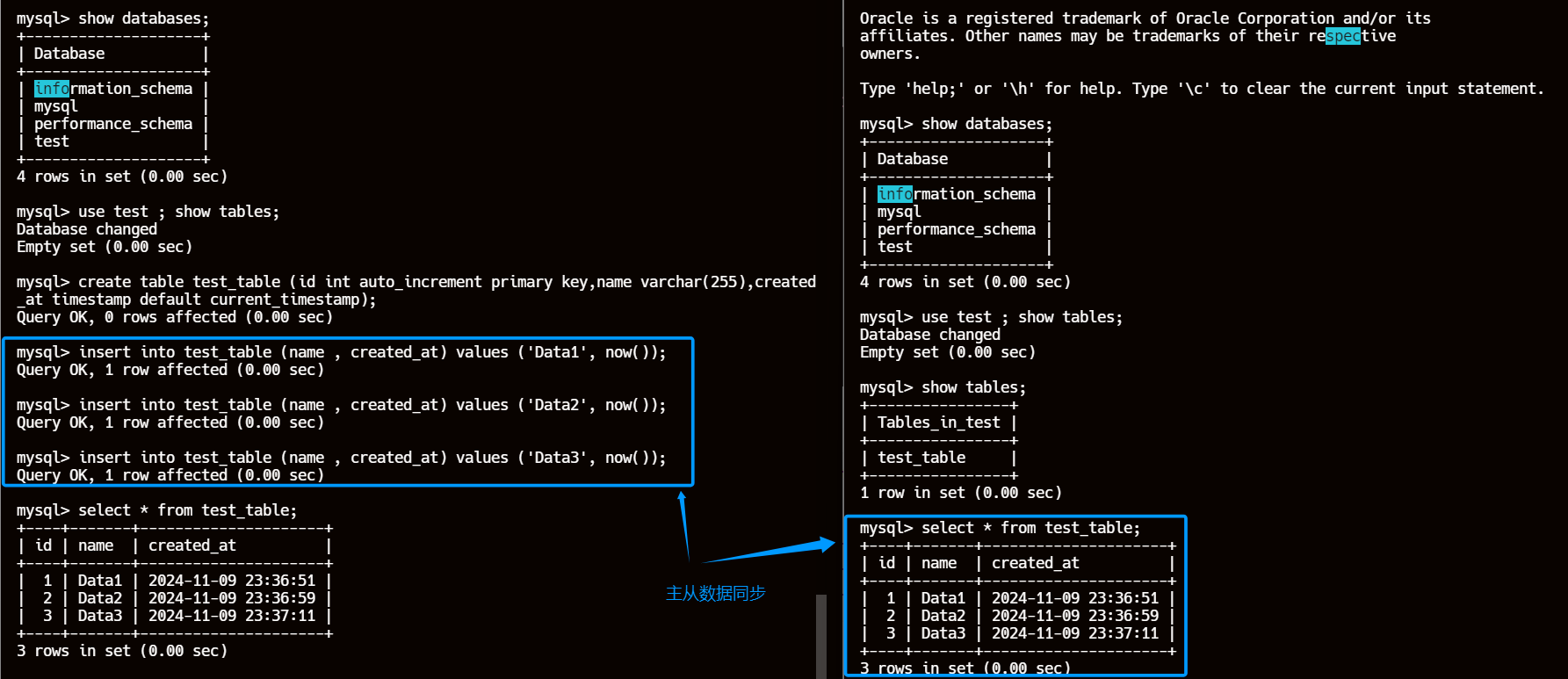
7.2、主库创建表并插入数据
create table test_table (id int auto_increment primary key,name varchar(255),created_at timestamp default current_timestamp);insert into test_table (name , created_at) values ('Data1', now());
insert into test_table (name , created_at) values ('Data2', now());
insert into test_table (name , created_at) values ('Data3', now());
7.3、从库执行查询操作
show tables;select * from test_table;
8、MySQL 5.5 单线程体现
# 从库
show processlist;

这里有两个系统用户线程:
Id 1是IO线程,负责从主库读取二进制日志并写入从库的中继日志。Id 2是SQL线程,负责从中继日志中读取事件并应用到从库。
三、MySQL 5.6 基于 schema(库级别) 的并行复制
如果在MySQL 5.6 版本开启并行复制功能(slave_parallel_workers > 0),那么SQL 线程就变为了coordinator 线程。但是其并行只是基于schema的,也就是基于库的。如果用户的MySQL数据库实例中存在多个schema且schema下表数量较少,对于从服务器复制的速度的确可以有比较大的帮助。
1、原理
通过配置参数 slave_parallel_workers = n 开启并行复制,原来的单个SQL线程的功能被拆分成了两个部分:一个 Coordinator 线程和多个 Worker 线程。
coordinator线程主要负责两部分内容:
- 若判断可以并行执行,那么选择worker线程执行事务的二进制日志
- 若判断不可以并行执行,如该操作是DDL,或者是事务跨schema操作,则等待所有的worker线程执行完成之后再执行当前的日志。
这意味着coordinator 线程并不是仅将日志发送给worker 线程,自己也可以回放日志,但是所有可以并行的操作交付由worker 线程完成。
Worker线程作用:
WorkThread线程负责实际应用中继日志中的事务。每个WorkThread线程负责处理特定数据库(Schema)的事务。- 可以通过配置参数
slave_parallel_workers来设置WorkThread线程的数量。默认值为0,表示不启用并行复制。

2、存在的问题
基于schema级别的并行复制存在一个问题,schema级别的并行复制效果并不高,如果用户实例有很少的库和较多的表,那么并行回放效果会很差,甚至性能会比原来的单线程更差,但是日常维护中其实单个实例的的事务处理相对集中在一个 DB 上。因此单库多表是比多库多表更为常见的一种情形。
这种并行复制的模式,只有在实例中有多个 DB,且 DB 的事务都相对繁忙的情况下才会有较高的并行度。
3、部署主从复制
3.1、主节点安装配置 MySQL 5.6
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz
tar xzvf mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz
mkdir /application
mv mysql-5.6.40-linux-glibc2.12-x86_64 /application/mysql-5.6.40
ln -s /application/mysql-5.6.40/ /application/mysql
cd /application/mysql/support-files/
\cp my-default.cnf /etc/my.cnf
cp mysql.server /etc/init.d/mysqld
cd /application/mysql/scripts
useradd mysql -s /sbin/nologin -M
yum -y install autoconf
./mysql_install_db --user=mysql --basedir=/application/mysql --data=/application/mysql/data
echo 'export PATH="/application/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
sed -i 's#/usr/local#/application#g' /etc/init.d/mysqld /application/mysql/bin/mysqld_safe
sed -i '/^# basedir = /a\basedir = /application/mysql/' /etc/my.cnf
sed -i '/^# datadir = /a\datadir = /application/mysql/data/' /etc/my.cnf
cat >> /usr/lib/systemd/system/mysqld.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=https://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/application/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
EOF
cat >> /etc/my.cnf << EOF
# 主从复制配置
server-id = 1
log-bin = mysql-bin
binlog-format = ROW
expire_logs_days = 10# 其他配置
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
mysqladmin -uroot password '123'
3.2、从节点安装配置 MySQL 5.6
wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz
tar xzvf mysql-5.6.40-linux-glibc2.12-x86_64.tar.gz
mkdir /application
mv mysql-5.6.40-linux-glibc2.12-x86_64 /application/mysql-5.6.40
ln -s /application/mysql-5.6.40/ /application/mysql
cd /application/mysql/support-files/
\cp my-default.cnf /etc/my.cnf
cp mysql.server /etc/init.d/mysqld
cd /application/mysql/scripts
useradd mysql -s /sbin/nologin -M
yum -y install autoconf
./mysql_install_db --user=mysql --basedir=/application/mysql --data=/application/mysql/data
echo 'export PATH="/application/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
sed -i 's#/usr/local#/application#g' /etc/init.d/mysqld /application/mysql/bin/mysqld_safe
sed -i '/^# basedir = /a\basedir = /application/mysql/' /etc/my.cnf
sed -i '/^# datadir = /a\datadir = /application/mysql/data/' /etc/my.cnf
cat >> /usr/lib/systemd/system/mysqld.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=https://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/application/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
EOF
cat >> /etc/my.cnf << EOF
# 主从复制配置
server-id = 2
relay-log = mysql-relay-bin
log-bin = mysql-bin
read-only = 1# 并行复制配置
slave_parallel_workers = 4
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
mysqladmin -uroot password '123'
mysql -V
select version();
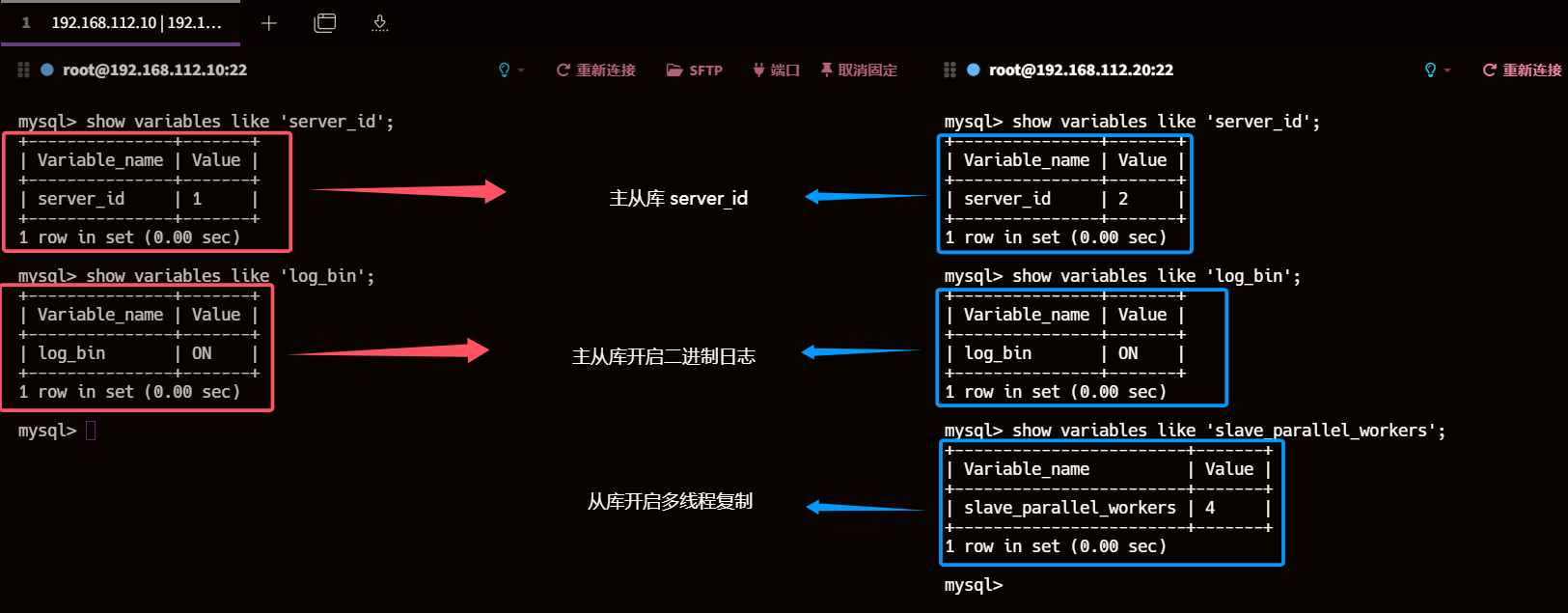
4、检查主从库server_id、log_bin、 slave_parallel_workers
show variables like 'server_id';show variables like 'log_bin';show variables like 'slave_parallel_workers';show processlist;

5、创建主从复制用户
主库
#创建slave用户
grant replication slave on *.* to slave@'192.168.112.%' identified by '123';flush privileges;

6、获取主库的二进制日志文件和位置
# 记录下 File 和 Position 的值
show master status;

7、配置从库连接主库参数并启动从库复制进程
change master to
master_host='192.168.112.10',
master_user='slave',
master_password='123',
master_log_file='mysql-bin.000001',
master_log_pos=552;start slave;
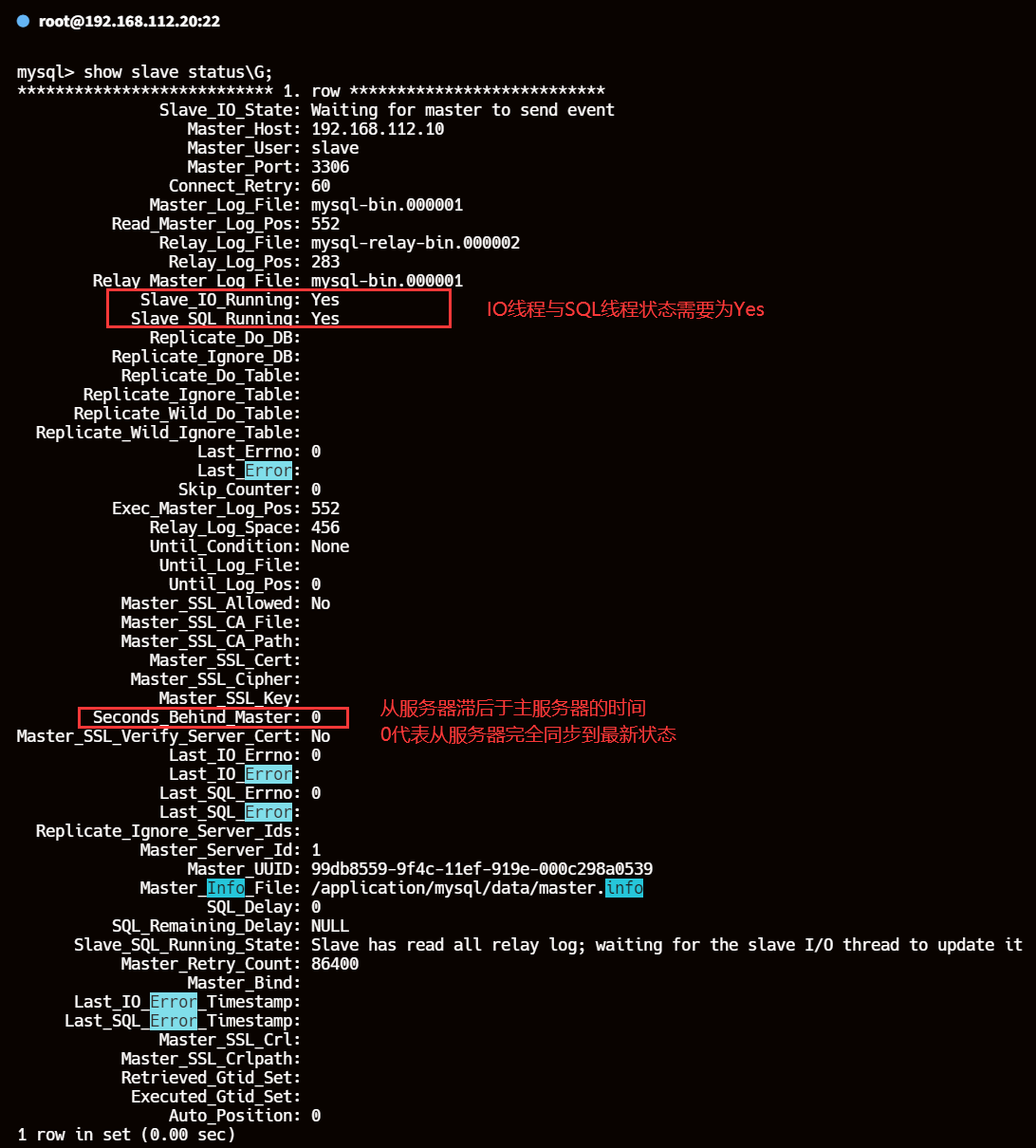
show slave status\G;
8、验证主从复制
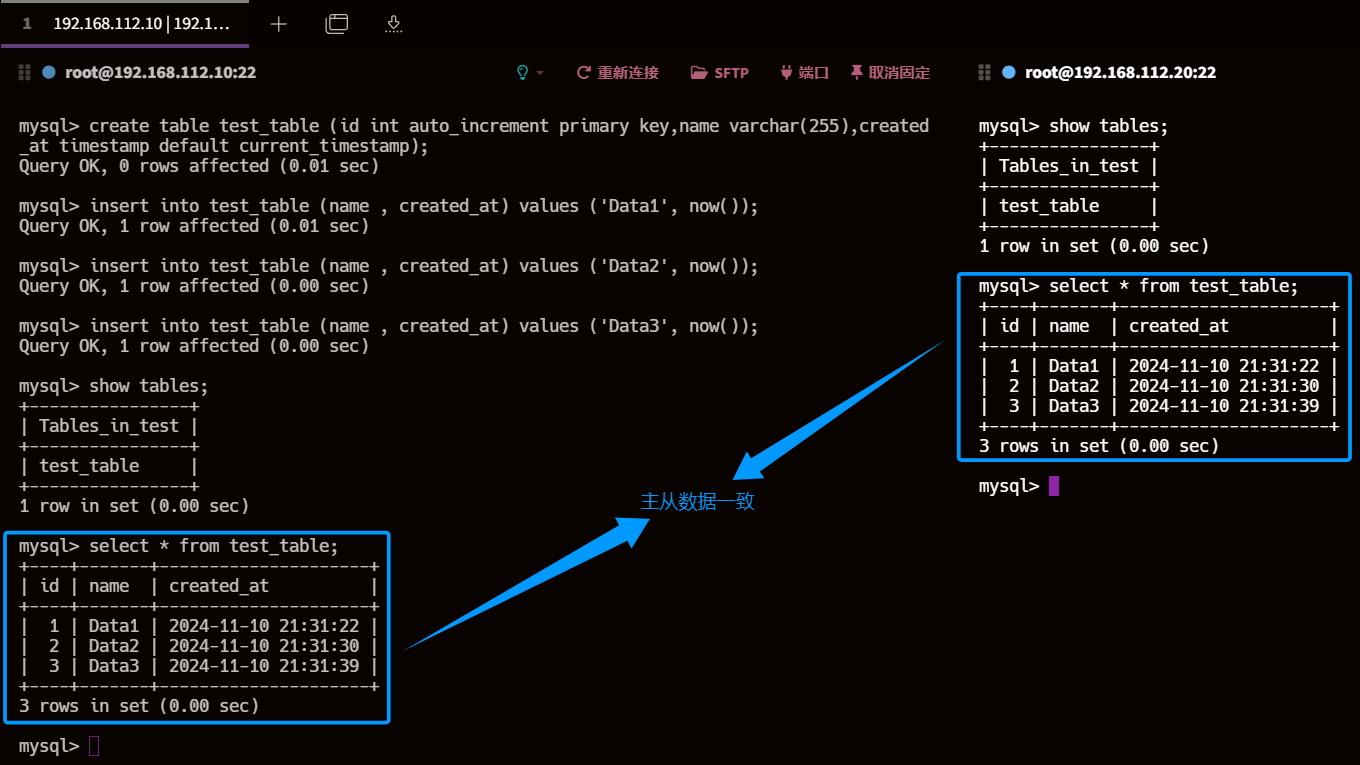
8.1、查看主库从库数据
目前数据一致
show databases;use test ; show tables;

8.2、主库创建表并插入数据
create table test_table (id int auto_increment primary key,name varchar(255),created_at timestamp default current_timestamp);insert into test_table (name , created_at) values ('Data1', now());
insert into test_table (name , created_at) values ('Data2', now());
insert into test_table (name , created_at) values ('Data3', now());
8.3、从库执行查询操作
show tables;select * from test_table;
9、主节点单库多表 sysbench 写压测 从节点测试延迟
9.1、安装 sysbench 压测工具
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bashyum -y install sysbenchsysbench --version
9.2、创建测试数据库
# 主节点
create database tssysbench;
9.3、使用 sysbench 准备测试数据
sysbench /usr/share/sysbench/oltp_write_only.lua \
--mysql-host=192.168.112.10 --mysql-port=3306 \
--mysql-user=root --mysql-password='123' \
--mysql-db=tssysbench --db-driver=mysql \
--tables=20 --table-size=10000 --report-interval=10 \
--threads=64 --time=200 \
prepare
- /usr/share/sysbench/ 目录下有OLTP 基准测试的脚本文件,我们使用的是写测试模拟并发写入情况
- –mysql-host=192.168.112.10 --mysql-port=3306 \ --mysql-user=root --mysql-password=‘123’ \ 数据库的用户和密码等信息
- –mysql-db=tssysbench --tables=20 --table_size=10000:这一串的意思,就是说在tssysbench这个库里,构造20个测试表,每个测试表里构造1万条测试数据,测试表的名字会是类似于sbtest1,sbtest2这个样子的
- –db-driver=mysql:代表数据库驱动
- –time=200:这个就是说连续访问200秒
- –threads=64:这个就是说用64个线程模拟并发访问
- –report-interval=10:这个就是说每隔10秒输出一下压测情况
- 最后有一个prepare,意思是参照这个命令的设置去构造出来我们需要的数据库里的数据,他会自动创建20个测试表,每个表里创建1万条测试数据。一共20w条数据
9.4、运行写操作测试
sysbench /usr/share/sysbench/oltp_write_only.lua \
--mysql-host=192.168.112.10 --mysql-port=3306 \
--mysql-user=root --mysql-password='123' \
--mysql-db=tssysbench --db-driver=mysql \
--tables=20 --table-size=10000 --report-interval=10 \
--threads=64 --time=200 \
run
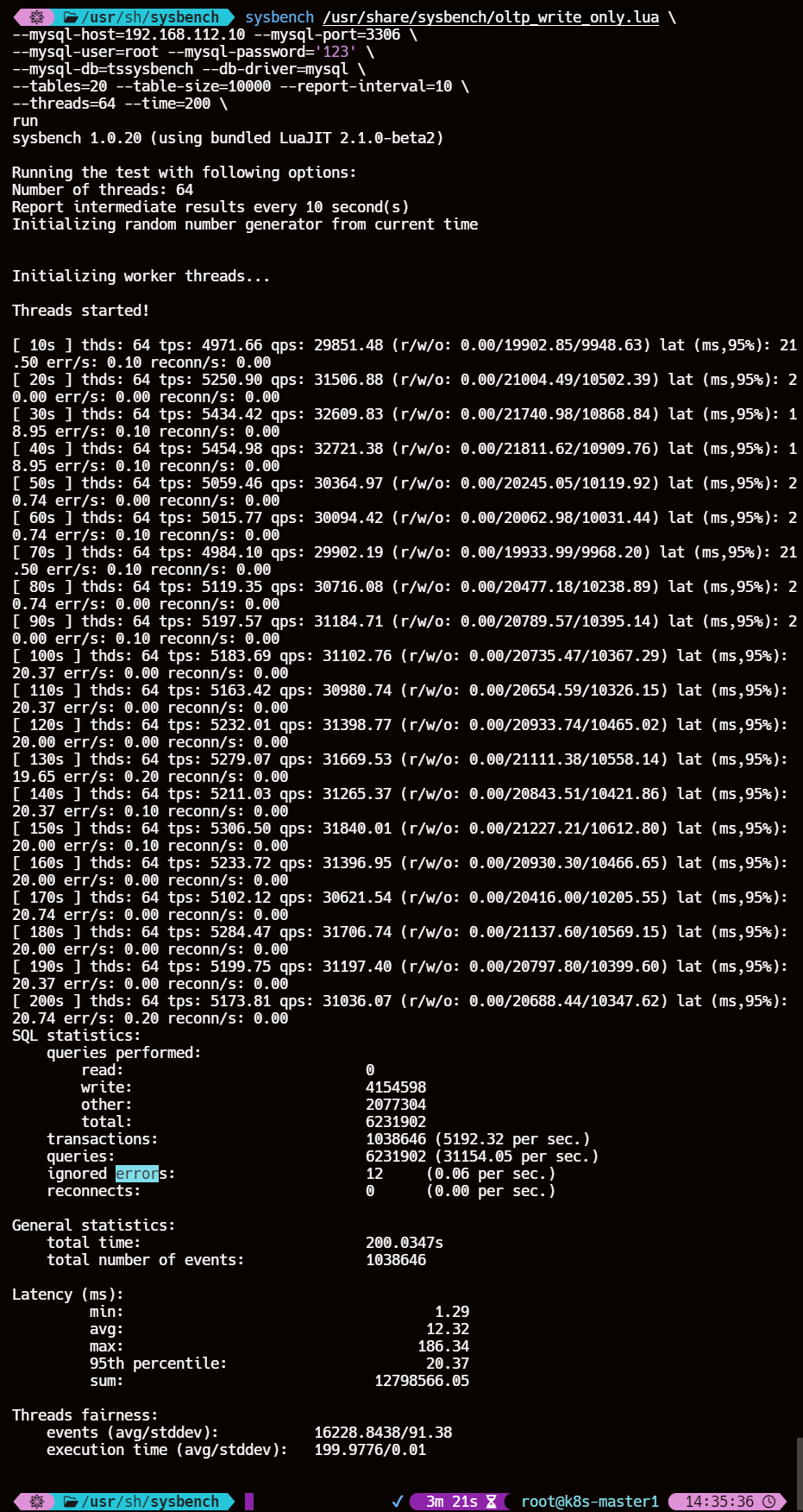
每10s压测情况报告(取第一个10s做参数详解):
- thds: 64,这个意思就是有64个线程在压测
- tps: 4971.66,这个意思就是每秒执行了4971.66个事务
- qps: 29851.48,意思是每秒执行了29851.48个请求
- (r/w/o: 0.00/17826.55/8911.43) ,意思是每秒29851.48个请求中有19902.85个写请求、9948.63个其他请求,是对QPS进行了rwo拆解
- lat (ms,95%):21.50,意思是95%的请求延迟都在21.50ms以下
- err/s: 0.00 reconn/s: 0.00 ,意思是每秒有0.1个请求是失败的,发生了0次网络重连
结果参数详解:
- SQL statistics: SQL统计信息
- read:0, 0次读操作
- write:4154598, 4154598次写操作
- other:2077304, 2077304次其他操作
- total:6231902,6231902次总操作数
- transactions:1038646 (5192.32 per sec),在整个测试过程中,完成了 1,038,646 个事务,平均每秒完成 5192.32 个事务(tps)。
- queries:6231902 (31154.05 per sec.),在整个测试过程中,执行了 6,231,902 次查询,平均每秒执行 31,154.05 次查询(qps)。
- ignored errors:12 (0.06 per sec),在整个测试过程中,忽略了 12 个错误,平均每秒忽略 0.06 个错误
- reconnects:0(0.00 per sec.) ,在整个测试过程中,没有发生任何重连,平均每秒重连次数为 0。
- General statistics: 总体统计信息
- total time:200.0347s,测试总用时200.0347 秒
- total number of events:1038646,在测试期间发生的总事件数1038646,即完成的事务数。
- Latency (ms):延迟统计信息
- min: 1.29 最小延迟1.29 毫秒
- avg: 12.32 平均延迟12.32 毫秒
- max: 186.34 最大延迟 186.34 毫秒
- 95th percentile: 20.37 95% 的事件的响应时间不超过 20.37 毫秒
- sum: 12798566.05 所有事件的总延迟事件为 12798566.05 毫秒
- Threads fairness: 线程公平性
- events (avg/stddev): 16228.8438/91.38 每个线程平均完成的事件数及其标准偏差。平均每个线程完成了 16,228.8438 个事件,标准偏差为 91.38
- execution time (avg/stddev): 199.9776/0.01 每个线程平均执行的时间及其标准偏差。平均每个线程执行了 199.9776 秒,标准偏差为 0.01
9.5、从库采集延迟时间
collect_delay.sh
#!/bin/bash# 从库连接信息
SLAVE_MYSQL_USER="root"
SLAVE_MYSQL_PASSWORD="123"# 采集次数
COLLECT_COUNT=10# 记录延迟时间的数组
DELAY_TIMES=()for ((i=1; i<=COLLECT_COUNT; i++)); doecho "Collecting delay $i..."# 获取从库的延迟时间DELAY=$(mysql -u $SLAVE_MYSQL_USER -p$SLAVE_MYSQL_PASSWORD -e "SHOW SLAVE STATUS\G;" | grep Seconds_Behind_Master | awk '{print $2}')DELAY_TIMES+=($DELAY)# 等待一段时间sleep 20
done# 计算平均延迟时间
AVERAGE_DELAY=$(echo "${DELAY_TIMES[@]}" | tr ' ' '+' | bc -l)
AVERAGE_DELAY=$(echo "$AVERAGE_DELAY / $COLLECT_COUNT" | bc -l)echo "Average delay for replication: $AVERAGE_DELAY seconds"
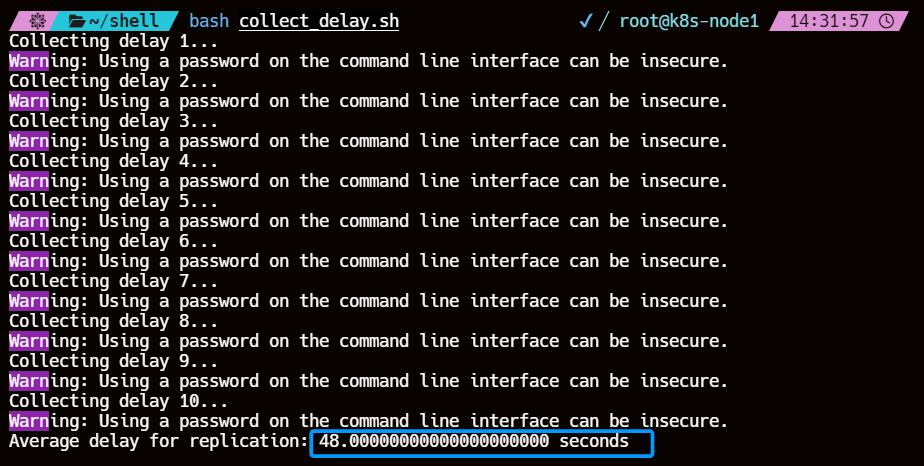
这里对从库主从复制延迟的参数是采集
Seconds_Behind_Master的值,压测200s内同时对从库进行延迟数据的采集,10s一次最后取值为10次平均值最终延迟为48.0s
9.6、事务处理速度(TPS,Transactions Per Second)和查询处理速度(QPS,Queries Per Second)
| 场景 | 单库多表 |
|---|---|
| 数据量 | 20w |
| 线程数 | 64 |
| 压测时间 | 200s |
| 事务数 | 1,038,646 |
| TPS | 5,192.32 事务/秒 |
| QPS | 3,1154.05 查询/秒 |
| 主从复制延迟 | 48.0s |
9.7、清除测试数据
run 改为 cleanup 即可
sysbench /usr/share/sysbench/oltp_write_only.lua \
--mysql-host=192.168.112.10 --mysql-port=3306 \
--mysql-user=root --mysql-password='123' \
--mysql-db=tssysbench --db-driver=mysql \
--tables=20 --table-size=10000 --report-interval=10 \
--threads=64 --time=200 \
cleanup
10、主节点多库多表 sysbench 写压测 从节点测试延迟
因为我目前不知道 sysbench 是否有多库多表压测的特性,所以采用 parallel 并行执行 sysbench 写压测。观测从节点延迟。还是20w条数据
10.1、创建测试数据库
10个数据库,每个数据库10张表,每张表2000条数据,64线程模拟并发,持续时间200s
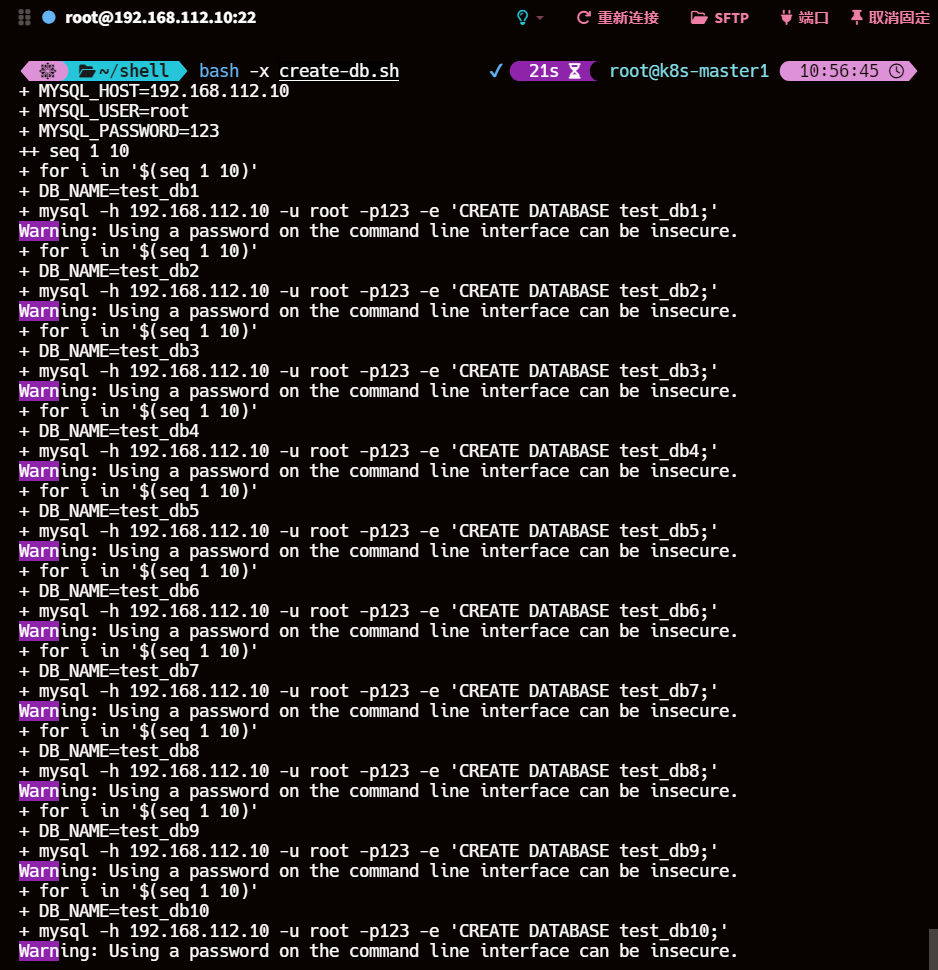
create-db.sh
#!/bin/bash# 主库连接信息
MYSQL_HOST="192.168.112.10"
MYSQL_USER="root"
MYSQL_PASSWORD="123"# 创建10个数据库
for i in $(seq 1 10); doDB_NAME="test_db$i"mysql -h $MYSQL_HOST -u $MYSQL_USER -p$MYSQL_PASSWORD -e "CREATE DATABASE $DB_NAME;"
done
10.2、使用 sysbench 准备测试数据
sysbench-pre.sh
#!/bin/bash# 主库连接信息
MYSQL_HOST="192.168.112.10"
MYSQL_USER="root"
MYSQL_PASSWORD="123"for i in $(seq 1 10); doDB_NAME="test_db$i"# 准备测试数据sysbench /usr/share/sysbench/oltp_write_only.lua \--mysql-host=$MYSQL_HOST --mysql-port=3306 \--mysql-user=$MYSQL_USER --mysql-password=$MYSQL_PASSWORD \--mysql-db=$DB_NAME --db-driver=mysql \--tables=10 --table-size=2000 --report-interval=10 \--threads=64 --time=200 \prepare
done
10.3、运行写操作测试
sysbench-run.sh
#!/bin/bash# 主库连接信息
MYSQL_HOST="192.168.112.10"
MYSQL_USER="root"
MYSQL_PASSWORD="123"# 使用 parallel 运行 sysbench 测试
seq 1 10 | parallel --no-notice -j 8 'DB_NAME=test_db{}sysbench /usr/share/sysbench/oltp_write_only.lua \--mysql-host='$MYSQL_HOST' --mysql-port=3306 \--mysql-user='$MYSQL_USER' --mysql-password='$MYSQL_PASSWORD' \--mysql-db=$DB_NAME --db-driver=mysql \--tables=10 --table-size=2000 --report-interval=10 \--threads=8 --time=200 \run
'
10.4、从库采集延迟时间
collect_delay.sh
#!/bin/bash# 从库连接信息
SLAVE_MYSQL_USER="root"
SLAVE_MYSQL_PASSWORD="123"# 采集次数
COLLECT_COUNT=10# 记录延迟时间的数组
DELAY_TIMES=()for ((i=1; i<=COLLECT_COUNT; i++)); doecho "Collecting delay $i..."# 获取从库的延迟时间DELAY=$(mysql -u $SLAVE_MYSQL_USER -p$SLAVE_MYSQL_PASSWORD -e "SHOW SLAVE STATUS\G;" | grep Seconds_Behind_Master | awk '{print $2}')DELAY_TIMES+=($DELAY)# 等待一段时间sleep 20
done# 计算平均延迟时间
AVERAGE_DELAY=$(echo "${DELAY_TIMES[@]}" | tr ' ' '+' | bc -l)
AVERAGE_DELAY=$(echo "$AVERAGE_DELAY / $COLLECT_COUNT" | bc -l)echo "Average delay for replication: $AVERAGE_DELAY seconds"
针对MySQL 5.6 版本 多库多表的性能测试就先这样吧
从执行结果看使用 parallel 执行 sysbench 多库是串行而非并行所以控制不了变量
四、MySQL 5.7 基于组提交的并行复制
MySQL5.7中slave服务器的回放与master是一致的,即master服务器上是怎么并行执行的,那么slave上就怎样进行并行回放。不再有库的并行复制限制。
1、原理
通过对事务进行分组,优化减少了生成二进制日志所需的操作数。当事务同时提交时,它们将在单个操作中写入到二进制日志中。如果事务能同时提交成功,那么它们就不会共享任何锁,这意味着它们没有冲突,因此可以在Slave上并行执行。所以通过在二进制日志中添加组提交信息,实现Slave可以并行地安全地运行事务。
Group Commit技术在MySQL5.6中是为了解决事务提交的时候需要fsync导致并发性不够而引入的。简单来说,就是由于事务提交时必须将Binlog写入到磁盘上而调用fsync,这是一个代价比较高的操作,事务并发提交的情况下,每个事务各自获取日志锁并进行fsync会导致事务实际上以串行的方式写入Binlog文件,这样就大大降低了事务提交的并发程度。
Group Commit技术将事务的提交阶段分成了Flush、Sync、Commit三个阶段,每个阶段维护一个队列,并且由该队列中第一个线程负责执行该步骤,这样实际上就达到了一次可以将一批事务的Binlog fsync到磁盘的目的,这样的一批同时提交的事务称为同一个Group的事务

Group Commit虽然是属于并行提交的技术,但是解决了从服务器上事务并行回放的一个难题——即如何判断哪些事务可以并行回放。如果一批事务是同时Commit的,那么这些事务必然不会有互斥的持有锁,也不会有执行上的相互依赖,因此这些事务必然可以并行的回放。
为了标记事务所属的组,MySQL5.7版本在产生Binlog日志时会有两个特殊的值记录在 Binlog Event 中,last_committed 和 sequence_number,其中 last_committed指的是该事务提交时,上一个事务提交的编号,sequence_number是事务提交的序列号,在一个Binlog文件内单调递增。如果两个事务的last_committed值一致,这两个事务就是在一个组内提交的。

为了兼容MySQL5.6基于库的并行复制,5.7引入了新的变量slave-parallel-type,其可以配置的值有:DATABASE(默认值,基于库的并行复制方式)、LOGICAL_CLOCK(基于组提交的并行复制方式)。
2、部署主从复制
因为变量 slave-parallel-type 的参数设置中 database 实际上就是 MySQL 5.6 版本的多线程复制
所以这个 MySQL 5.7 版本就采用 logical_clock
2.1、主节点安装配置 MySQL 5.7
cd /usr/local
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.35-linux-glibc2.12-x86_64.tar.gz
tar -zxvf mysql-5.7.35-linux-glibc2.12-x86_64.tar.gz
ln -s mysql-5.7.35-linux-glibc2.12-x86_64 mysql
groupadd mysql
useradd -r -g mysql mysql
cd /usr/local/mysql
chown -R mysql:mysql .
mkdir -p /usr/local/mysql/data
chown -R mysql:mysql /usr/local/mysql/data
./bin/mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data
cat > /etc/my.cnf << EOF
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysqld.pid
user = mysql
port = 3306
# 二进制日志配置
server-id = 1
log-bin = mysql-bin
binlog-format = row
expire_logs_days = 10
gtid-mode = ON
enforce-gtid-consistency=ON
# 主从复制配置
log-slave-updates = 1
read-only = 0
EOF
cat > /etc/systemd/system/mysqld.service << EOF
[Unit]
Description=MySQL 5.7 Database Server
After=network.target[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
echo 'export PATH="/usr/local/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
======================================================================================
> 使用临时密码登录MySQL,修改 root 密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123';
FLUSH PRIVILEGES;
EXIT;
临时密码

2.2、从节点安装配置 MySQL 5.7
cd /usr/local
wget https://cdn.mysql.com/archives/mysql-5.7/mysql-5.7.35-linux-glibc2.12-x86_64.tar.gz
tar -zxvf mysql-5.7.35-linux-glibc2.12-x86_64.tar.gz
ln -s mysql-5.7.35-linux-glibc2.12-x86_64 mysql
groupadd mysql
useradd -r -g mysql mysql
cd /usr/local/mysql
chown -R mysql:mysql .
mkdir -p /usr/local/mysql/data
chown -R mysql:mysql /usr/local/mysql/data
./bin/mysqld --initialize --user=mysql --datadir=/usr/local/mysql/data
cat > /etc/my.cnf << EOF
[mysqld]
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
socket = /tmp/mysql.sock
pid-file = /usr/local/mysql/data/mysqld.pid
user = mysql
port = 3306
# 二进制日志配置
server-id = 2
log-bin = mysql-bin
binlog-format = row
expire_logs_days=10# 主从复制配置
relay-log=mysql-relay-bin
log-slave-updates=ON
gtid-mode=ON
enforce-gtid-consistency=ON
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=4
slave_preserve_commit_order=on
read-only = 0
EOF
cat > /etc/systemd/system/mysqld.service << EOF
[Unit]
Description=MySQL 5.7 Database Server
After=network.target[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
Restart=on-failure[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload && systemctl start mysqld && systemctl enable mysqld
echo 'export PATH="/usr/local/mysql/bin:$PATH"' >> /etc/profile.d/mysql.sh
source /etc/profile
======================================================================================
> 使用临时密码登录MySQL,修改 root 密码
ALTER USER 'root'@'localhost' IDENTIFIED BY '123';
FLUSH PRIVILEGES;
EXIT;
临时密码

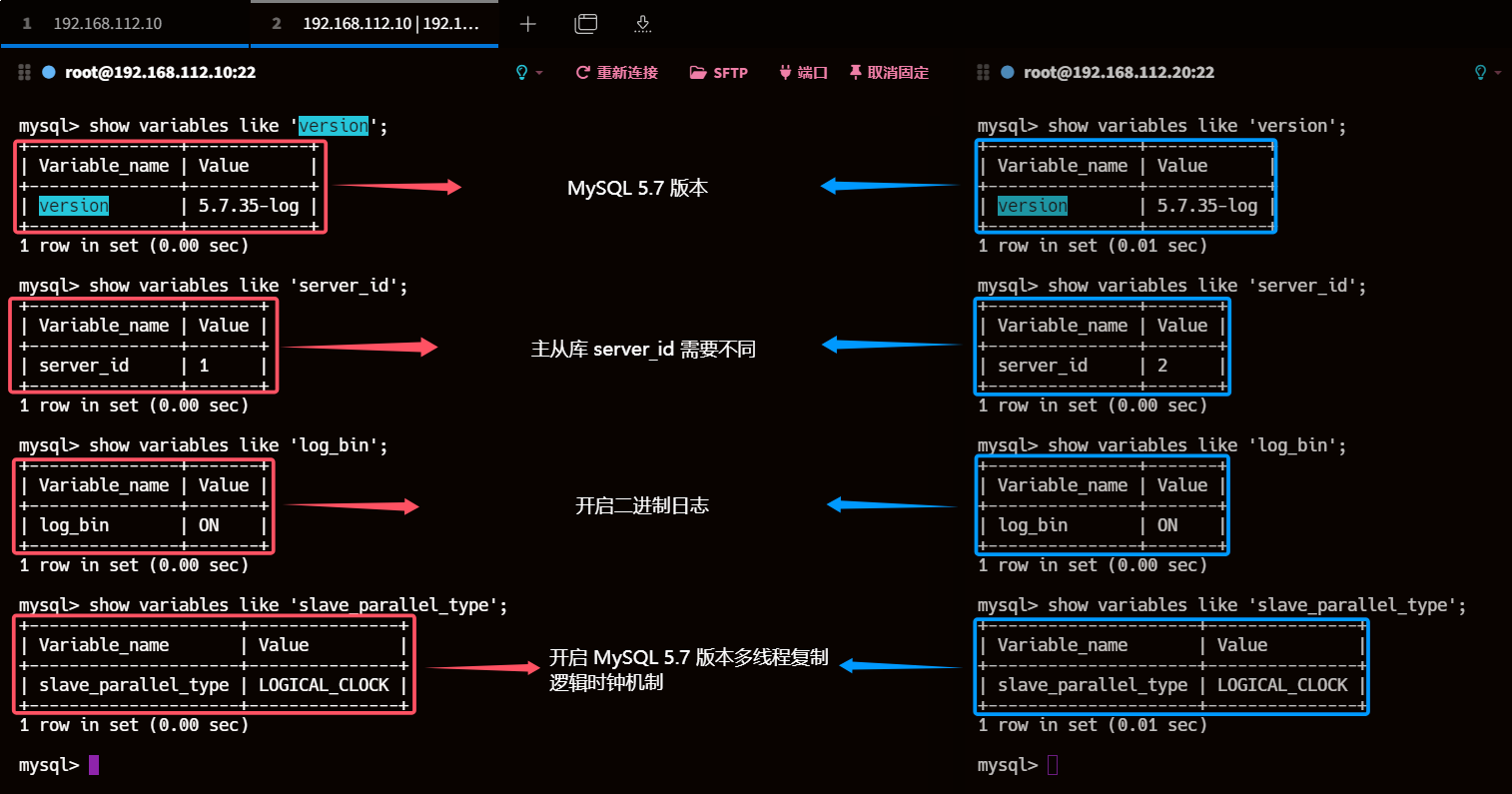
3、检查主从库server_id、log_bin、 slave_parallel_workers、slave-parallel-type
show variables like 'version';show variables like 'server_id';show variables like 'log_bin';show variables like 'slave_parallel_type';
4、创建主从复制用户
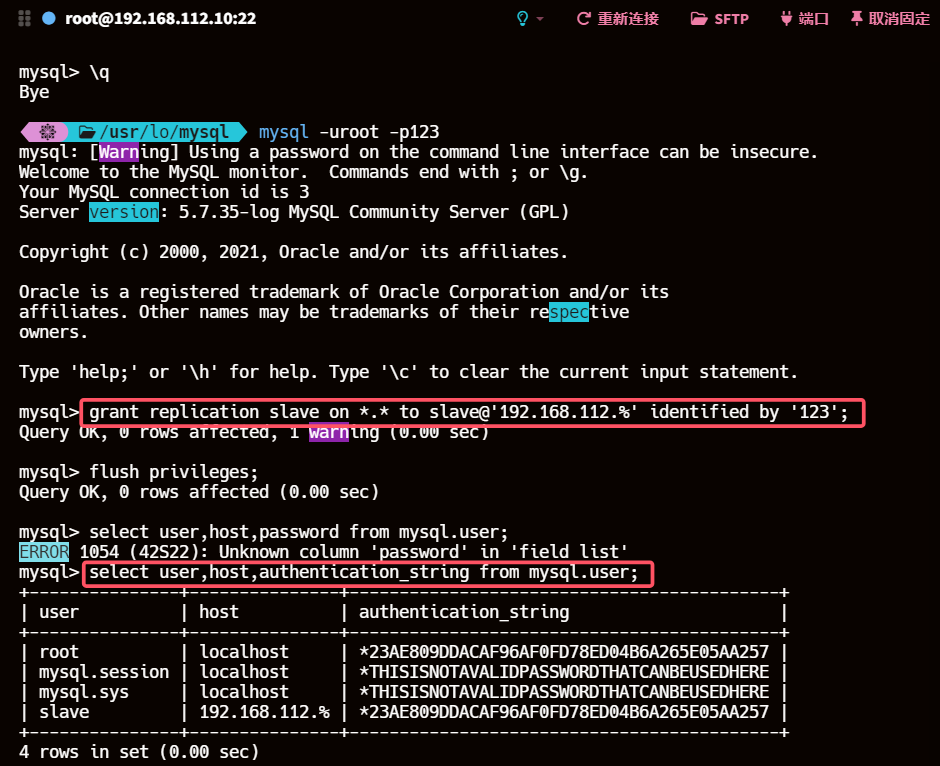
主库
#登录数据库
mysql -uroot -p123#创建slave用户
grant replication slave on *.* to slave@'192.168.112.%' identified by '123';flush privileges;select user,host,authentication_string from mysql.user;
grant replication slave on *.*: 授予replication slave权限,允许用户从主库复制数据。*.*表示所有数据库和所有表。to slave@'192.168.112.%': 指定用户名为slave,允许从192.168.112.%子网内的任何IP地址连接到主库。identified by '123': 设置用户的密码为123。
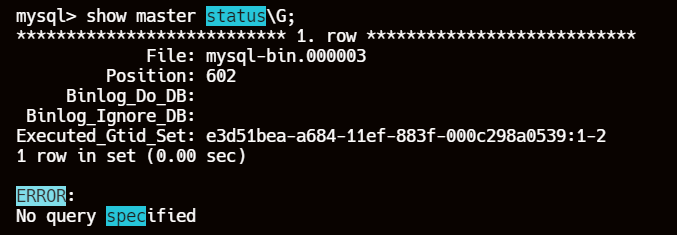
5、获取主库的二进制日志文件和位置
# 记录下 File 和 Position 的值
show master status;
6、配置从库连接主库参数并启动从库复制进程
change master to
master_host='192.168.112.10',
master_user='slave',
master_password='123',
master_log_file='mysql-bin.000003',
master_log_pos=602;start slave;
show slave status\G;
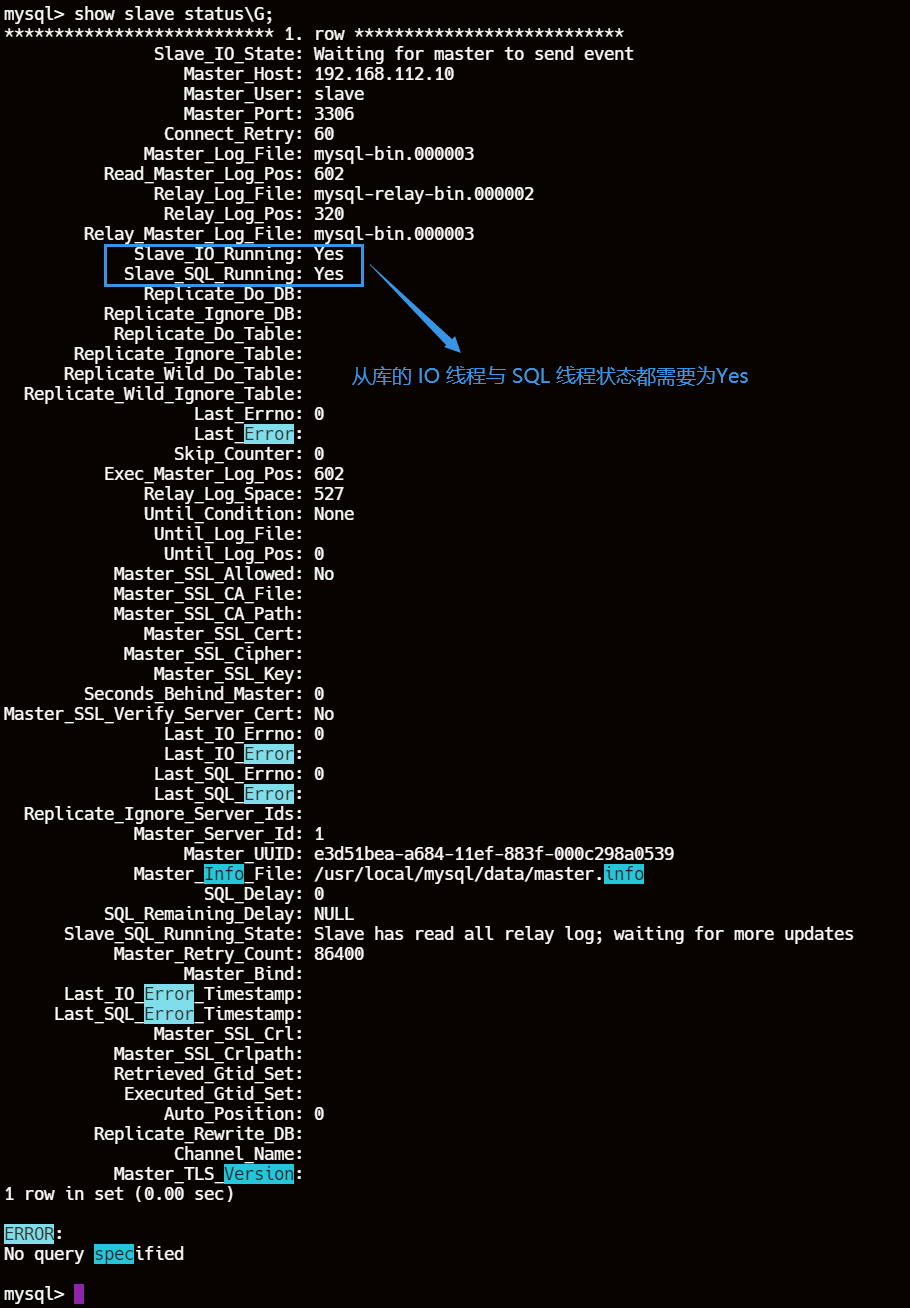
7、验证主从复制
7.1、查看主库从库数据
目前数据一致
show databases;# 主库
create database test;use test;
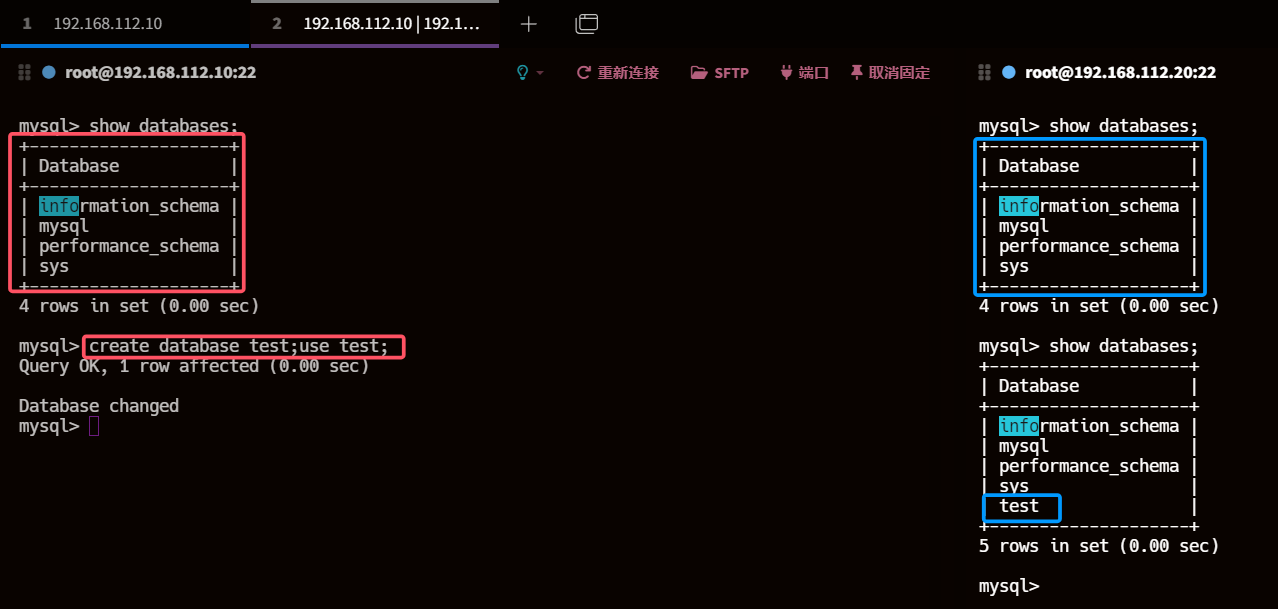
7.2、主库创建表并插入数据
create table test_table (id int auto_increment primary key,name varchar(255),created_at timestamp default current_timestamp);insert into test_table (name , created_at) values ('Data1', now());
insert into test_table (name , created_at) values ('Data2', now());
insert into test_table (name , created_at) values ('Data3', now());
7.3、从库执行查询操作
use test;show tables;select * from test_table;
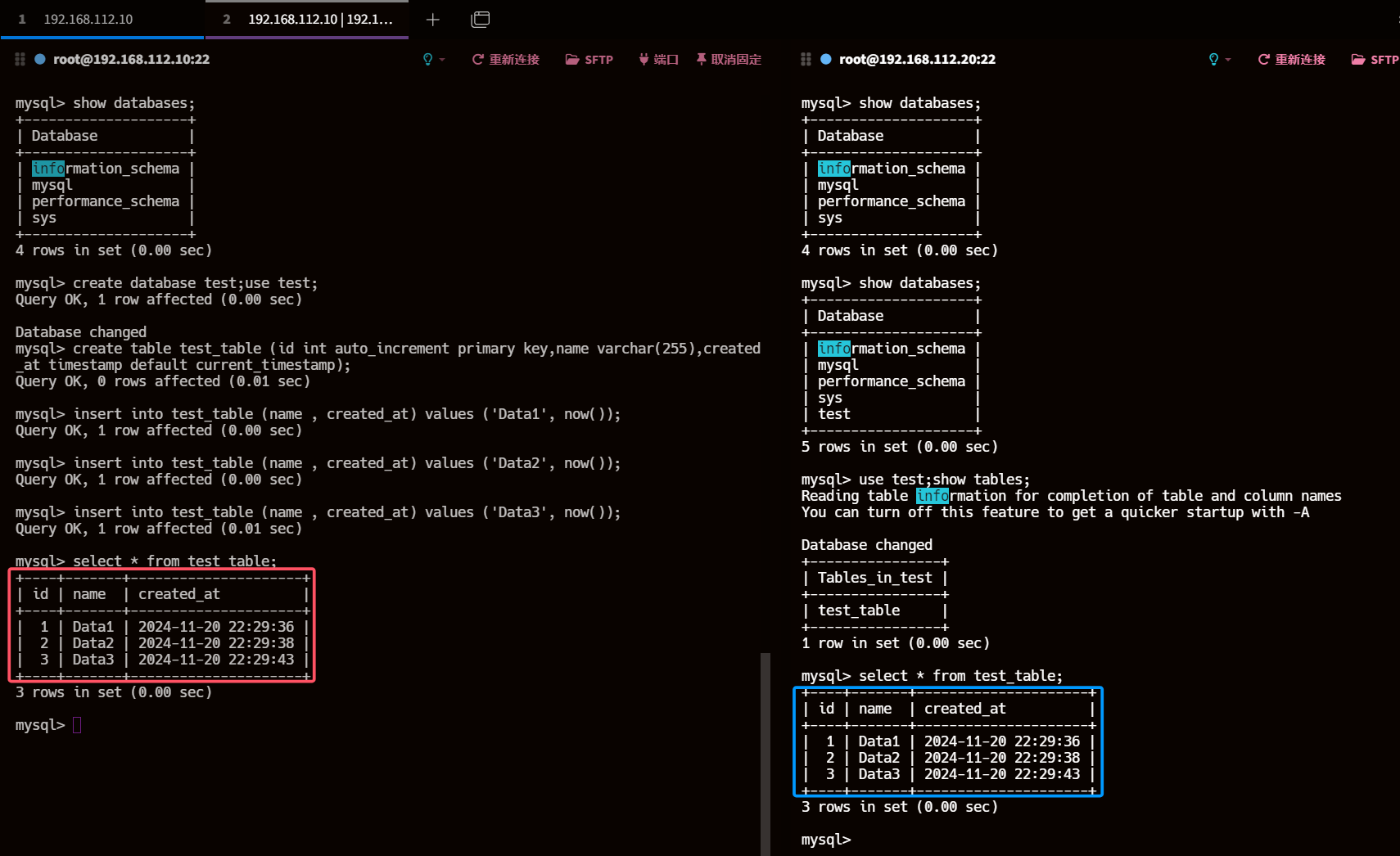
8、主节点单库多表 sysbench 写压测 从节点测试延迟
8.1、安装 sysbench 压测工具
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | sudo bashyum -y install sysbenchsysbench --version
8.2、创建测试数据库
# 主节点
create database tssysbench;
8.3、使用 sysbench 准备测试数据
与MySQL 5.6 版本的单库多表写压测一样的数据形成对照
sysbench /usr/share/sysbench/oltp_write_only.lua \
--mysql-host=192.168.112.10 --mysql-port=3306 \
--mysql-user=root --mysql-password='123' \
--mysql-db=tssysbench --db-driver=mysql \
--tables=20 --table-size=10000 --report-interval=10 \
--threads=64 --time=200 \
prepare
- /usr/share/sysbench/ 目录下有OLTP 基准测试的脚本文件,我们使用的是写测试模拟并发写入情况
- –mysql-host=192.168.112.10 --mysql-port=3306 \ --mysql-user=root --mysql-password=‘123’ \ 数据库的用户和密码等信息
- –mysql-db=tssysbench --tables=20 --table_size=10000:这一串的意思,就是说在tssysbench这个库里,构造20个测试表,每个测试表里构造1万条测试数据,测试表的名字会是类似于sbtest1,sbtest2这个样子的
- –db-driver=mysql:代表数据库驱动
- –time=200:这个就是说连续访问200秒
- –threads=64:这个就是说用64个线程模拟并发访问
- –report-interval=10:这个就是说每隔10秒输出一下压测情况
- 最后有一个prepare,意思是参照这个命令的设置去构造出来我们需要的数据库里的数据,他会自动创建20个测试表,每个表里创建1万条测试数据。一共20w条数据
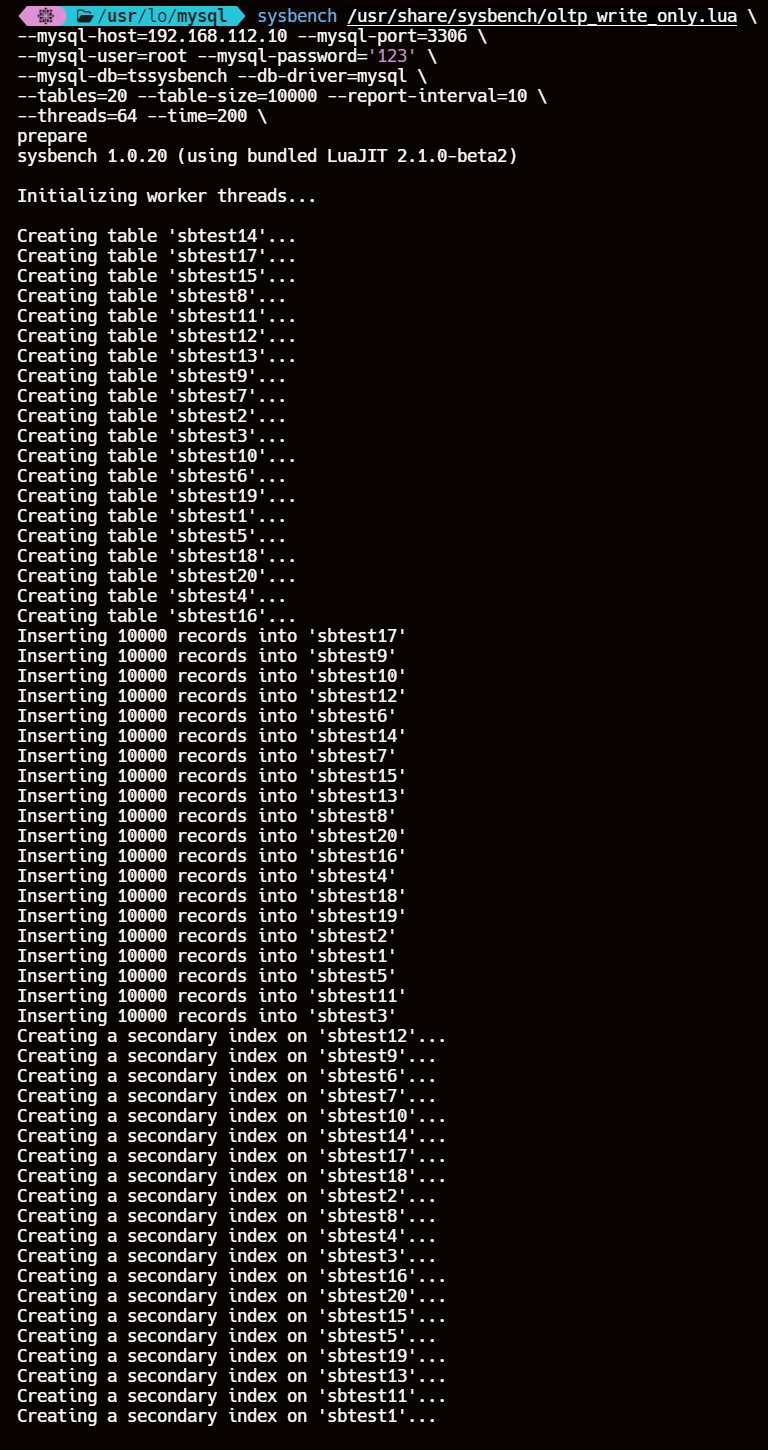
8.4、运行写操作测试
sysbench /usr/share/sysbench/oltp_write_only.lua \--mysql-host=192.168.112.10 --mysql-port=3306 \--mysql-user=root --mysql-password='123' \--mysql-db=tssysbench --db-driver=mysql \--tables=20 --table-size=10000 --report-interval=10 \--threads=64 --time=200 \run
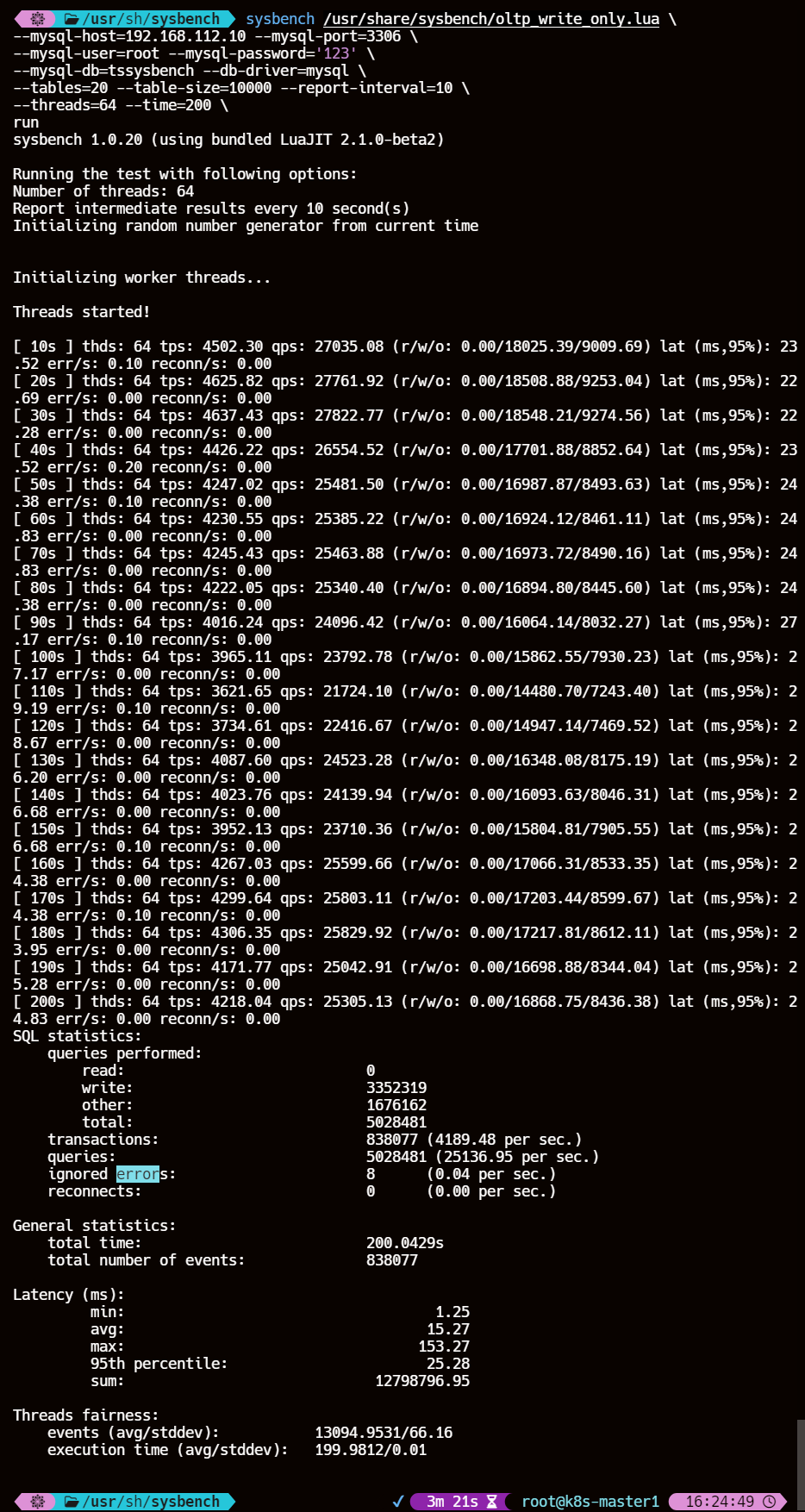
每10s压测情况报告(取第一个10s做参数详解):
- thds: 64,这个意思就是有64个线程在压测
- tps: 4502.30,这个意思就是每秒执行了4502.30个事务
- qps: 27035.08,意思是每秒执行了27035.08个请求
- (r/w/o: 0.00/18025.39/9009.69) ,意思是每秒27035.08个请求中有18025.39个写请求、9009.69个其他请求,是对QPS进行了rwo拆解
- lat (ms,95%):23.52,意思是95%的请求延迟都在23.52ms以下
- err/s: 0.10 reconn/s: 0.00 ,意思是每秒有0.1个请求是失败的,发生了0次网络重连
结果参数详解:
- SQL statistics: SQL统计信息
- read:0, 0次读操作
- write:3352319, 3352319次写操作
- other:1676162,1676162次其他操作
- total:5028481,5028481次总操作数
- transactions:838077 (4189.48 per sec),在整个测试过程中,完成了 838,077 个事务,平均每秒完成 4,189.48 个事务(tps)。
- queries:5028481 (25136.95 per sec.),在整个测试过程中,执行了 5,028,481 次查询,平均每秒执行 25,136.95 次查询(qps)。
- ignored errors:8(0.04 per sec),在整个测试过程中,忽略了 8 个错误,平均每秒忽略 0.04 个错误
- reconnects:0(0.00 per sec.) ,在整个测试过程中,没有发生任何重连,平均每秒重连次数为 0。
- General statistics: 总体统计信息
- total time:200.0429s,测试总用时200.0429 秒
- total number of events:838077,在测试期间发生的总事件数838,077,即完成的事务数。
- Latency (ms):延迟统计信息
- min: 1.25 最小延迟1.25 毫秒
- avg: 15.27 平均延迟15.27 毫秒
- max: 153.27 最大延迟 153.27 毫秒
- 95th percentile: 25.28 95% 的事件的响应时间不超过 25.28 毫秒
- sum: 12798796.95 所有事件的总延迟事件为 12798796.95 毫秒
- Threads fairness: 线程公平性
- events (avg/stddev): 13094.9531/66.16 每个线程平均完成的事件数及其标准偏差。平均每个线程完成了 13,094.9531 个事件,标准偏差为 66.16
- execution time (avg/stddev): 199.9812/0.01 每个线程平均执行的时间及其标准偏差。平均每个线程执行了 199.9812 秒,标准偏差为 0.01
8.5、从库采集延迟时间
collect_delay.sh
#!/bin/bash# 从库连接信息
SLAVE_MYSQL_USER="root"
SLAVE_MYSQL_PASSWORD="123"# 采集次数
COLLECT_COUNT=10# 记录延迟时间的数组
DELAY_TIMES=()for ((i=1; i<=COLLECT_COUNT; i++)); doecho "Collecting delay $i..."# 获取从库的延迟时间DELAY=$(mysql -u $SLAVE_MYSQL_USER -p$SLAVE_MYSQL_PASSWORD -e "SHOW SLAVE STATUS\G;" | grep Seconds_Behind_Master | awk '{print $2}')DELAY_TIMES+=($DELAY)# 等待一段时间sleep 20
done# 计算平均延迟时间
AVERAGE_DELAY=$(echo "${DELAY_TIMES[@]}" | tr ' ' '+' | bc -l)
AVERAGE_DELAY=$(echo "$AVERAGE_DELAY / $COLLECT_COUNT" | bc -l)echo "Average delay for replication: $AVERAGE_DELAY seconds"
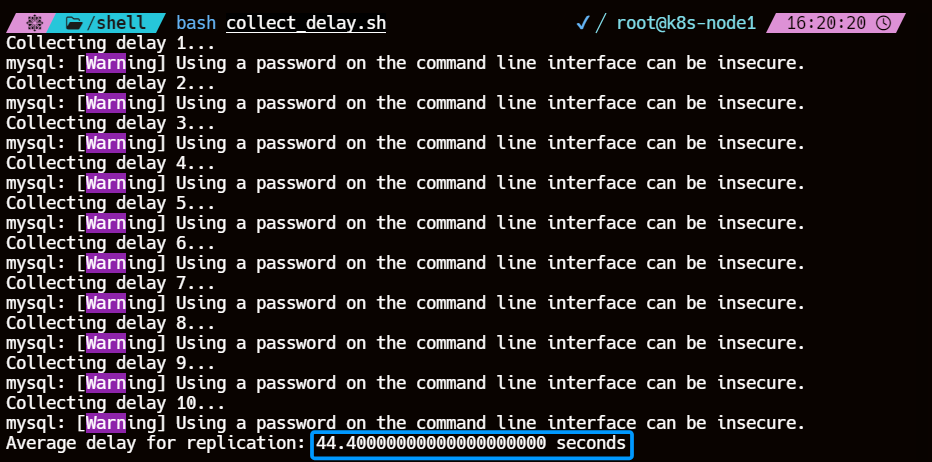
这里对从库主从复制延迟的参数是采集
Seconds_Behind_Master的值,压测200s内同时对从库进行延迟数据的采集,10s一次最后取值为10次平均值最终延迟为44.4s
8.6、事务处理速度(TPS,Transactions Per Second)和查询处理速度(QPS,Queries Per Second)
| 场景 | 单库多表 |
|---|---|
| 数据量 | 20w |
| 线程数 | 64 |
| 压测时间 | 200s |
| 事务数 | 838077 |
| TPS | 4,189.48 事务/秒 |
| QPS | 25,136.95 查询/秒 |
| 主从复制延迟 | 44.4s |
。。。同样的 sysbench 写压测参数,单库多表,20张表、每张表10000条数据、并发线程数64、持续压测时间200s
至少相对 MySQL 5.6 版本,MySQL 5.7 版本的主从复制延迟时间是优化了的
8.7、清除测试数据
run 改为 cleanup 即可
sysbench /usr/share/sysbench/oltp_write_only.lua \
--mysql-host=192.168.112.10 --mysql-port=3306 \
--mysql-user=root --mysql-password='123' \
--mysql-db=tssysbench --db-driver=mysql \
--tables=20 --table-size=10000 --report-interval=10 \
--threads=64 --time=200 \
cleanup
五、MySQL 8.0 基于 WriteSet 的并行复制
1、概述
基于组提交 LOGICAL_CLOCK 多线程复制机制在每组提交事务足够多,即业务量足够大时表现较好。但很多实际业务中,虽然事务没有 Lock Interval 重叠,但这些事务操作的往往是不同的数据行,也不会有锁冲突,是可以并行执行的,但 LOGICAL_CLOCK 的实现无法使这部分事务得到并行重放。为了解决这个问题,MySQL 在 5.7.22 版本推出了基于WriteSet的并行复制。简单来说,WriteSet并行复制的思想是:不同事务的记录不重叠,则都可在从库上并行重放。可以看到并行的力度从组提交细化为记录级。
MySQL8.0 是基于write-set的并行复制,write-set由binlog-transaction-dependency-tracking参数进行控制。MySQL 会有一个集合变量来存储事务修改的记录信息(主键哈希值),所有已经提交的事务所修改的主键值经过 hash 后都会与那个变量的集合进行对比,来判断改行是否与其冲突,并以此来确定依赖关系,没有冲突即可并行。这样的粒度,就到了 row 级别了,此时并行的粒度更加精细,并行的速度会更快。
2、核心原理
Master 端
-
WriteSet 的生成:
-
当事务提交时,MySQL 会计算该事务修改的所有行的 WriteSet。WriteSet 是一个哈希集合,包含了所有被修改的行的唯一标识符(通常是主键或唯一键的哈希值)。
-
WriteSet=hash(index_name | db_name | db_name_length | table_name | table_name_length | value | value_length)
-
-
-
WriteSet 的存储:
- MySQL 维护一个哈希表来存储 WriteSet 和其对应的 sequence number。
- 每个事务提交时,会检查哈希表中是否存在相同的 WriteSet。
-
last_committed 的更新:
- 无冲突:如果哈希表中不存在相同的 WriteSet,说明当前事务与之前的事务没有冲突。此时,WriteSet 插入哈希表,并且当前事务的
last_committed值保持不变,与前一个事务的last_committed值相同。 - 有冲突:如果哈希表中存在相同的 WriteSet,说明当前事务与之前的事务有冲突。此时,更新哈希表中对应 WriteSet 的
sequence_number,并将当前事务的last_committed值更新为新的sequence_number。
- 无冲突:如果哈希表中不存在相同的 WriteSet,说明当前事务与之前的事务没有冲突。此时,WriteSet 插入哈希表,并且当前事务的
Slave 端
- 并行执行
- 在从库上,复制调度器会检查事务的
last_committed值。 - 如果两个事务的
last_committed值相同,说明它们可以并行执行。 - 如果两个事务的
last_committed值不同,说明它们有冲突,必须按顺序执行。
- 在从库上,复制调度器会检查事务的
3、MySQL 8.0 相关参数
在MySQL 8.0中,引入了参数binlog_transaction_dependency_tracking用于控制如何决定事务的依赖关系。
3.1、binlog_transaction_dependency_tracking
该值有三个选项:
- COMMIT_ORDERE:表示继续使用5.7中的基于组提交的方式决定事务的依赖关系(默认值);
- WRITESET:表示使用写集合来决定事务的依赖关系;
- WRITESET_SESSION:表示使用WriteSet来决定事务的依赖关系,但是同一个Session内的事务不会有相同的last_committed值(同一个会话中的事务不能并行执行)。
3.2、transaction_write_set_extraction
指定事务写集合的哈希算法,可设置的值有:
- OFF
- MURMUR32
- XXHASH64(默认值)。
对于 Group Replication,该参数必须设置为 XXHASH64。
注意,若要将 binlog_transaction_dependency_tracking 设置为 WRITESET 或 WRITESET_SESSION,则该参数不能设置为 OFF。
3.3、binlog_transaction_dependency_history_size
m_writeset_history 的上限,默认 25000。
一般来说,binlog_transaction_dependency_history_size 越大,m_writeset_history 能存储的行的信息就越多。在不出现行冲突的情况下,m_writeset_history_start 也会越小。相应地,新事务的 last_committed 也会越小,在从库重放的并发度也会越高。
4、WriteSet 依赖检测条件
WriteSet是基于主键的冲突检测(binlog_transaction_depandency_tracking = COMMIT_ORDERE|WRITESET|WRITESET_SESSION,修改的row的主键或非空唯一键没有冲突,即可并行)。
在开启了WRITESET或WRITESET_SESSION后,MySQL按以下的方式标识并记录事务的更新:
- 如果事务当前更新的行有主键,则将HASH(DB名、TABLE名、KEY名称、KEY_VALUE1、KEY_VALUE2……)加入到当前事务的vector write_set中。
- 如果事务当前更新的行有非空的唯一键,同样将HASH(DB名、TABLE名、KEY名、KEY_VALUE1)……加入到当前事务的write_set中。
- 如果事务更新的行有外键约束且不为空,则将该外键信息与VALUE的HASH加到当前事务的 write_set中。
- 如果事务当前更新的表的主键是其它某个表的外键,则设置当前事务has_related_foreign_key = true。
- 如果事务更新了某一行且没有任何数据被加入到write_set中,则标记当前事务 has_missing_key = true。在执行冲突检测的时候,先会检查has_related_foreign_key和has_missing_key , 如果为true,则退到COMMIT_ORDER模式;否则,会依照事务的write_set中的HASH值与已提交的事务的write_set进行比对。如果没有冲突,则当前事务与最后一个已提交的事务共享相同的last_commited,否则将从全局已提交的write_set中删除那个冲突的事务之前提交的所有write_set,并退化到COMMIT_ORDER计算last_committed。
- 在每一次计算完事务的last_committed值以后,需要去检测当前全局已经提交的事务的write_set是否已经超过了binlog_transaction_dependency_history_size设置的值,如果超过,则清空已提交事务的全局write_set。
从检测条件上看,该特性依赖于主键和唯一索引,如果事务涉及的表中没有主键且没有唯一非空索引,那么将无法从此特性中获得性能的提升。除此之外,还需要将Binlog格式设置为Row格式。
5、基于 COMMIT_ORDER,WRITESET_SESSION,WRITESET 方案的压测
MySQL 官方有对 COMMIT_ORDER,WRITESET_SESSION,WRITESET 这三种方案的压测测试
我这里就不测试了
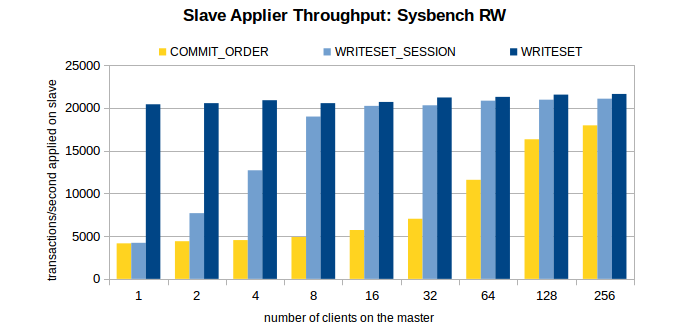
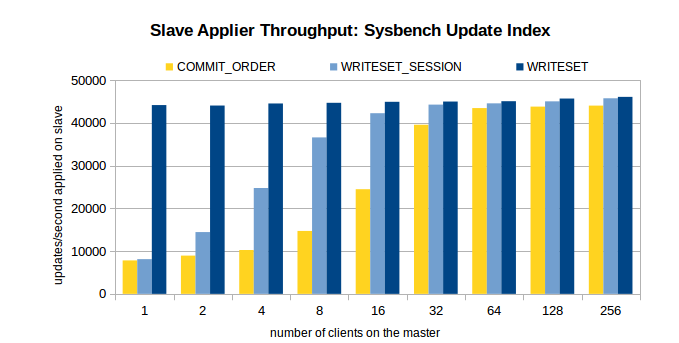
主库环境:16 核,SSD,1个数据库,16 张表,共 800w 条数据。
压测场景:OLTP Read/Write, Update Indexed Column 和 Write-only。
压测方案:在关闭复制的情况下,在不同的线程数下,注入 100w 个事务。开启复制,观察不同线程数下,不同方案的从库重放速度。
三个场景下的压测结果如图所示。
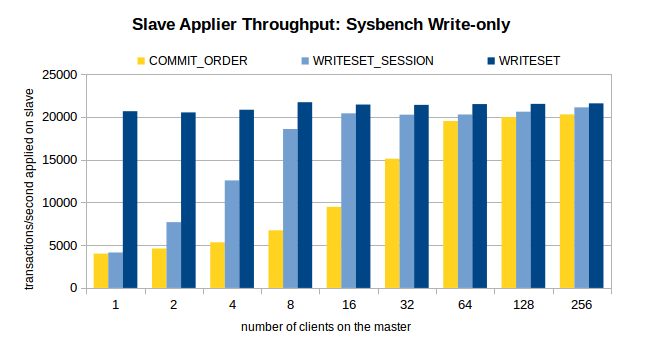
结论
1、对于 COMMIT_ORDER 方案,主库并发度越高,从库的重放速度越快。
2、对于 WRITESET 方案,主库的并发线程数对其几乎没有影响。甚至,单线程下 WRITESET 的重放速度都超过了 256 线程下的COMMIT_ORDER。
3、与 COMMIT_ORDER 一样,WRITESET_SESSION 也依赖于主库并发。只不过,在主库并发线程数较低(4 线程、8 线程)的情况下,WRITESET_SESSION 也能实现较高的吞吐量。
6、开启并行复制
修改过 my.cnf 配置文件中的参数都需要重载重启 MySQL 才能生效
6.1、主库
binlog_transaction_dependency_tracking = WRITESET
transaction_write_set_extraction = XXHASH64
binlog_transaction_dependency_history_size = 25000
binlog_format = ROW
- binlog_transaction_dependency_tracking:
COMMIT_ORDER:基于提交顺序的依赖关系。这意味着事务的依赖关系是根据它们在主库上提交的顺序来确定的。WRITESET:基于写集的依赖关系。这意味着事务的依赖关系是根据它们修改的数据行来确定的。WRITESET_SESSION:基于会话的写集依赖关系。这是WRITESET的一种更细粒度的变体,它不仅考虑事务修改的数据行,还考虑会话内的事务依赖关系。
- transaction_write_set_extraction = XXHASH64:选择用于计算 WriteSet 的哈希算法。
OFF:不计算 WriteSet。XXHASH64:使用 XXHash64 算法。这是一种快速且分布均匀的哈希算法。MURMUR32:使用 MurmurHash32 算法。这也是一种快速的哈希算法,但比 XXHash64 稍慢。
- binlog_transaction_dependency_history_size:设置 WriteSet 历史记录的最大大小。
- 可以根据实际情况调整。较大的值可以提供更多的历史记录,但会占用更多内存。较小的值可能会导致历史记录过早被清除,影响依赖关系的准确性。
- binlog_format:设置二进制日志的格式。
STATEMENT:基于语句的复制。二进制日志记录的是 SQL 语句本身。ROW:基于行的复制。二进制日志记录的是每行数据的变化。(基于 WRITESET 的并行复制方案,只在 binlog 格式为 ROW 的情况下才生效。)MIXED:混合模式。MySQL 自动选择STATEMENT或ROW模式,以确保复制的正确性。
6.2、从库
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 16
slave_preserve_commit_order = ON
- slave_parallel_type:设置从库并行复制的类型。该参数有以下取值:
- DATABASE:基于库级别的并行复制。MySQL 8.0.27 之前的默认值。
- LOGICAL_CLOCK:基于组提交的并行复制。
- slave_parallel_workers:设置 Worker 线程的数量。
- 开启了多线程复制,原来的 SQL 线程将演变为 1 个 Coordinator 线程和多个 Worker 线程。
- slave_preserve_commit_order:
- 事务在从库上的提交顺序是否与主库保持一致,建议开启。



)
