引言:百花齐放的推理利器
随着大型语言模型(LLMs)能力的飞速发展,它们在各行各业的应用也日益广泛。然而,如何高效地将这些强大的模型部署到实际应用中,成为了一个至关重要的问题。模型推理,作为将训练好的 LLM 应用于具体任务的关键环节,其性能直接影响着用户体验和应用成本。
在追求更低延迟、更高吞吐量和更灵活部署的道路上,涌现出了众多优秀的 LLM 推理框架。这些框架各有侧重,通过不同的技术手段,例如优化计算图、融合计算内核、支持模型量化、管理 KV 缓存以及实现高效的批处理等,来提升 LLM 的推理效率。
时至 2025 年,LLM 推理框架的生态已经呈现出百花齐放的态势。为了帮助读者更好地理解和选择适合自身需求的推理框架,本章将对当前主流的框架进行详细的分类和介绍,并通过实战对比,揭示它们在不同应用场景下的性能表现。

我们将主要围绕以下几个类别展开讨论:
- 高性能推理框架: 这类框架专注于极致的推理性能,通常采用先进的优化技术,旨在实现最低的延迟和最高的吞吐量,适用于对响应速度要求极高的在线服务和需要处理大量并发请求的场景。
- 本地部署与轻量化框架: 这类框架更注重在资源受限的环境中运行 LLM,例如个人电脑、边缘设备等。它们通常具有部署简单、资源占用低、轻量级等特点,方便用户在本地进行实验和部署。
- 灵活部署与多模型支持框架: 这类框架提供了高度的灵活性,能够支持多种不同的模型架构,并提供多种部署选项,方便用户根据实际需求进行选择和集成。
- 开发者友好型框架: 这类框架旨在降低 LLM 推理服务的开发门槛,提供易于使用的 API 和工具,帮助开发者快速构建和部署基于 LLM 的应用程序。
通过本章的学习,您将能够深入了解各种主流 LLM 推理框架的核心原理、特点优势、适用场景以及如何在实际项目中进行选择和应用。让我们一起探索这些强大的推理利器,为您的 LLM 应用提速!
1. 高性能推理框架
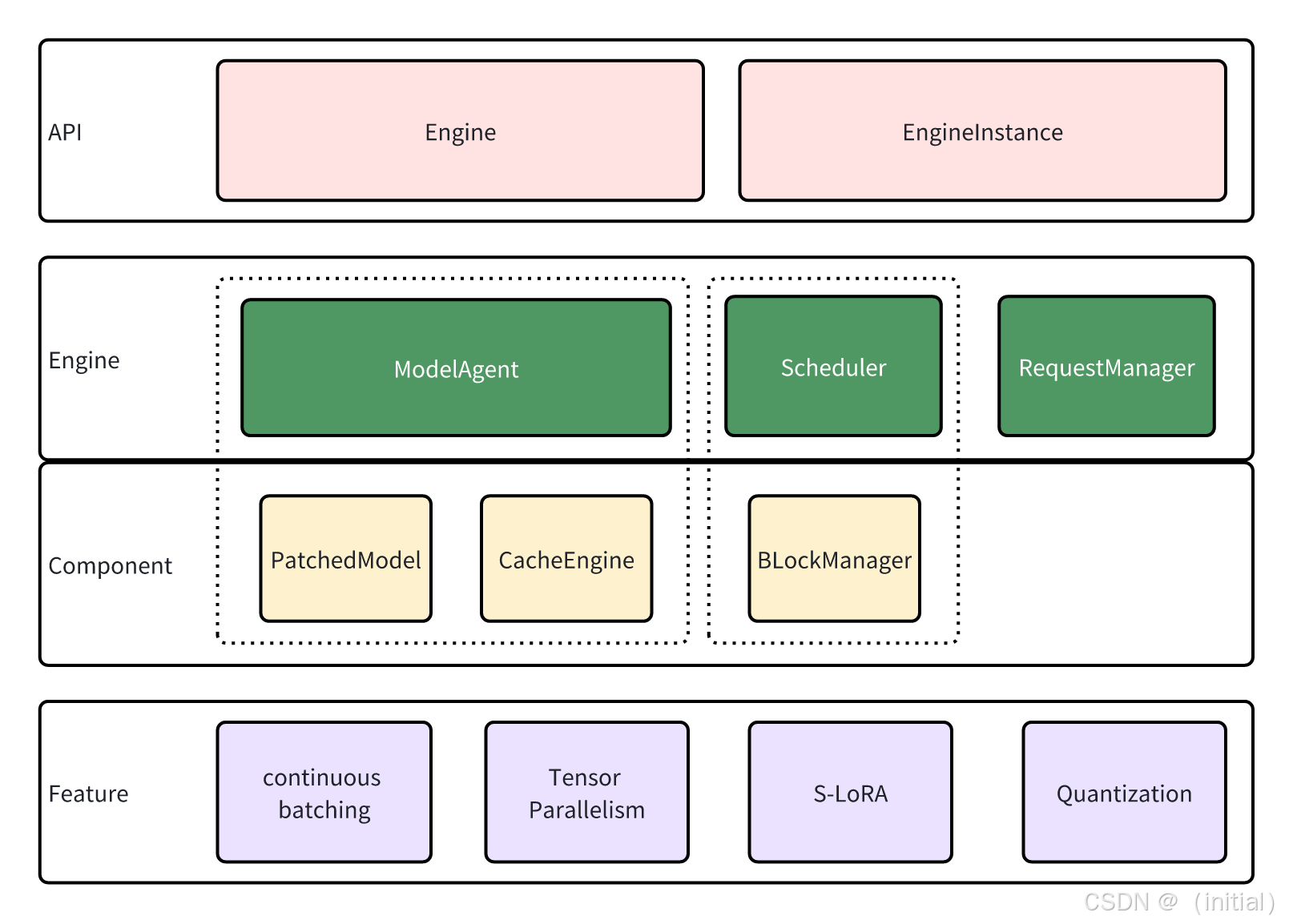
1.1 vLLM
-
架构与核心原理: vLLM 通过创新的 PagedAttention 技术,将每个序列的 KV 缓存分割成多个不连续的内存块(pages),从而避免了内存碎片化和冗余分配,极大地提升了内存使用效率,尤其是在处理长序列和多并发请求时。此外,vLLM 还采用了 Continuous Batching 技术,通过动态地将多个请求合并到一个批次中进行处理,显著提高了 GPU 的利用率和吞吐量。
-


-
相关图片搜索关键词: “vLLM PagedAttention”, “vLLM Continuous Batching”
-
特点与优势: 高吞吐量、低延迟、优秀的长序列支持(与第六章讨论的长文本推理挑战相关)、支持多种量化方法(例如 FP8,与第五章讨论的模型优化相关)、与 OpenAI API 兼容、与 Hugging Face Transformers 生态系统深度集成。
-
使用与代码示例:
# 运行此代码需要先安装 vLLM:pip install vllmfrom vllm import LLM, SamplingParams# 加载模型llm = LLM(model="mistralai/Mistral-7B-Instruct-v0.2")# 定义采样参数sampling_params = SamplingParams(max_tokens=50, top_p=0.9, temperature=0.8)# 输入提示列表prompts = ["Hello, what is your name?", "Tell me a joke."]# 进行推理outputs = llm.generate(prompts, sampling_params)# 打印输出for output in outputs:print(output.outputs[0].text)``` -
适用场景: 适用于需要处理大批量 Prompt 输入且对推理速度要求高的场景,例如金融分析、智能客服、大规模文档处理等企业级应用。
1.2 LMDeploy
- 架构特点: LMDeploy 以极致的 GPU 性能为目标,通过深度优化底层算子和调度策略,实现了超低的推理延迟和极高的吞吐量。它还深度应用了 FlashAttention 等技术来进一步提升性能。
- 核心优势: 完美契合企业级实时应用的需求,对国产 GPU 进行了深度适配,具备优秀的多模态处理能力。
- 适用场景: 适合国内企业和政府机构在特定国产硬件环境下部署,以及对实时性要求极高的应用场景。
1.3 TGI (Text Generation Inference)

- 企业级特性: TGI 是一个专为生产环境设计的文本生成服务,强调稳定性和高吞吐量,旨在成为构建可靠 LLM 服务的基石。它还考虑了 多租户 (Multi-tenancy) 和 安全 等关键的企业级需求。
- 核心优势: 本机支持 Hugging Face Transformers 模型,可以在多种硬件环境下进行高效推理。
- 适用场景: 适合在不需要为核心模型增加多个 adapter 的场景下,构建稳定可靠的文本生成服务。
1.4 TensorRT-LLM (基于 NVIDIA TensorRT) (NVIDIA)

- 架构与原理: TensorRT-LLM 是 NVIDIA 提供的高性能深度学习推理 SDK,构建于 TensorRT 之上,专门为大型语言模型 (LLMs) 推理进行了深度优化。它通过 图优化(例如,去除冗余节点、合并相邻操作,减少计算开销)、Kernel Fusion(将多个连续的小 kernel 融合成一个大的 kernel,减少 kernel 启动开销,例如垂直和水平的 kernel fusion)和 量化(降低模型权重和激活的精度,减少计算和存储需求,与第五章讨论的模型优化相关)等技术,显著提升推理速度并降低显存占用。TensorRT-LLM 针对 Transformer 架构进行了定制优化,例如高效的注意力机制实现(包括 FlashAttention 等)、更灵活和细粒度的量化支持(包括 INT4、INT8、FP16 等多种精度,以及 Weight/Activation 量化,支持 PTQ、QAT 等)、更好的多 GPU 和分布式推理支持,以及对长序列推理的优化(与第六章讨论的长文本推理挑战相关)。
- 安装配置: TensorRT-LLM 的安装通常需要依赖 CUDA 和 cuDNN,具体步骤可以参考 NVIDIA 官方文档。
-基本使用与性能调优实战: 使用 TensorRT-LLM 通常涉及将训练好的模型(例如 PyTorch 或 TensorFlow 模型)转换为 TensorRT engine 格式,然后使用 TensorRT-LLM 提供的 API 进行推理。性能调优需要根据具体的模型和硬件进行实验,例如选择合适的量化精度、调整 batch size 和使用合适的优化配置。 - 适用场景: 适用于 NVIDIA GPU 上的高性能推理,尤其是在需要极致速度和低延迟的场景。
1.5 SGLang


- 核心特点: SGLang 是一个高性能的推理 runtime,专注于深度优化语言生成流程。
- 核心优势: 内建强大的分布式部署能力,可以轻松应对复杂的应用场景。
- 适用场景: 适用于边缘计算、物联网和低负载场景,为无 GPU 环境下的基本推理需求提供可行方案。
2 本地部署与轻量化框架
2.1 Ollama

- 核心特点: Ollama 提供极简的本地 LLM 部署方案。
- 核心优势: 可以通过简单的命令一键加载模型,集成了用户友好的 Web 界面,支持 Windows、macOS 与 Linux 平台,内置超过 1700 款预训练模型,默认提供 int4 量化处理后的权重,大幅降低显存需求,使普通消费级硬件也能流畅运行。
- 适用场景: 个人用户进行快速原型验证和本地实验的最佳选择。
2.2 Llama.cpp

- 核心特点: Llama.cpp 是一个专注于 CPU 优化设计的框架,以轻量级著称。
- 核心优势: 资源占用极低,完美适用于边缘设备和资源受限的特殊环境。它基于 C++ 编写,专注于 CPU 优化,支持多种量化和优化技术,可以在 CPU 上高效运行 Llama 等模型。
- 适用场景: 边缘设备、嵌入式系统等资源受限的环境。
2.3 LocalAI

- 核心特点: LocalAI 专注于在本地运行 LLM。
- 核心优势: 将数据隐私和安全性置于首位,尤其适合对数据敏感度有极高要求的应用场景。它支持 CPU 和 GPU 推理。
- 适用场景: 个人用户和对数据隐私要求极高的场景。
2.4 KTransformers

- 核心特点: KTransformers 是 CPU 优化框架中的能效先锋。
- 核心优势: 专注于在资源极其有限的环境中实现低功耗和高效率的平衡。
- 适用场景: 资源极其有限且对功耗敏感的环境。
2.5 GPT4ALL

- 核心特点: GPT4ALL 配备图形用户界面 (GUI)。
- 核心优势: 操作极其简易直观,最大程度降低了 LLM 的使用门槛。
- 适用场景: 初学者快速入门和进行本地模型体验。
3. 灵活部署与多模型支持框架
3.1 XInference
- 核心特点: XInference 是一个开源框架。
- 核心优势: 提供与 OpenAI API 兼容的接口,具备高度的部署灵活性,并原生支持多种模型,能够灵活应对快速变化的应用需求。
- 适用场景: 需要快速切换或集成不同 LLM 的场景。
3.2 OpenLLM
- 核心特点: OpenLLM 是一个开源社区驱动的框架。
- 核心优势: 高度的灵活性和可定制性、广泛支持各种模型架构和混合部署模式。
- 适用场景: 需要深度定制化 LLM 部署的场景。
3.3 Hugging Face Transformers
- 核心优势: 拥有最为完善的生态系统,提供极其丰富的预训练模型资源,社区支持强大,广泛应用于学术研究和快速原型开发,部署方式也异常灵活,既可以通过 Pipelines 快速上手,也可以使用更底层的 API 进行定制化部署。此外,
accelerate库可以帮助在分布式环境下进行高效的推理。 - 使用与代码示例 (Pipeline):
# 运行此代码需要先安装 Transformers:pip install transformersfrom transformers import pipeline# 创建文本生成 pipeline,默认使用 CPUgenerator = pipeline('text-generation', model='gpt2')# 进行文本生成output = generator("Hello, I am a language model,", max_length=50, num_return_sequences=1)# 打印输出print(output[0]['generated_text'])``` * **适用场景:** 学术研究、快速原型开发以及需要灵活部署各种 Transformer 模型的场景。
3.4 LiteLLM
- 核心特点: LiteLLM 是轻量级适配层的代表。
- 核心优势: 提供统一的 API 接口,能够无缝支持多种 LLM(例如 OpenAI、Anthropic、Hugging Face 等),极大地简化了多模型集成和管理的复杂性。
- 适用场景: 需要集成和管理多个不同 LLM 提供商的模型的场景。
3.5 ONNX Runtime
- 核心优势: 具备良好的跨平台性,可以在多种操作系统和硬件上运行,并提供了一定的优化能力。
- 基本使用示例:
# 运行此代码需要先安装 torch 和 onnxruntime:pip install torch onnxruntimeimport torchfrom transformers import AutoTokenizer, AutoModelForCausalLMfrom onnxruntime import InferenceSession# 加载预训练模型和 tokenizermodel_name = "gpt2"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name)# 导出为 ONNX 格式onnx_path = "gpt2.onnx"dummy_input = tokenizer("Hello, world!", return_tensors="pt")torch.onnx.export(model,(dummy_input['input_ids'], dummy_input['attention_mask']),onnx_path,input_names=['input_ids', 'attention_mask'],output_names=['output'],dynamic_axes={'input_ids': {0: 'batch', 1: 'sequence'},'attention_mask': {0: 'batch', 1: 'sequence'},'output': {0: 'batch', 1: 'sequence'}})# 使用 ONNX Runtime 进行推理ort_session = InferenceSession(onnx_path)inputs = {ort_session.get_inputs()[0].name: dummy_input['input_ids'].numpy(),ort_session.get_inputs()[1].name: dummy_input['attention_mask'].numpy()}ort_outputs = ort_session.run(None, inputs)# 获取生成的 tokengenerated_tokens = torch.tensor(ort_outputs[0])# 解码 tokenoutput_text = tokenizer.decode(generated_tokens[0], skip_special_tokens=True)print(output_text)``` * **适用场景:** 需要在不同硬件平台上部署和运行 LLM 模型。
4. 开发者友好型框架
4.1 FastAPI
- 核心特点: FastAPI 是一个高性能的 Python Web 框架。
- 核心优势: 专为快速构建 LLM 推理 API 服务而设计,以其开发效率高和性能卓越而著称,支持异步操作和自动数据验证。
- 适用场景: 快速原型开发和构建生产级别的 LLM 推理 API 服务。
4.2 dify
- 核心特点: dify 是一个集成多种工具的开发框架。
- 核心优势: 为快速构建和部署基于 LLM 的应用提供了极大的便利,集成了 Prompt 管理、模型选择、数据源连接等功能。
- 适用场景: 应用开发者和快速原型设计。
4.3 Coze(扣子)
- 核心特点: Coze 是一个新一代 AI 应用开发平台。
- 核心优势: 无论是是否有编程基础,都可以在扣子上快速搭建基于大模型的各类 AI 应用,并将 AI 应用发布到各个社交平台、通讯软件,也可以通过 API 或 SDK 将 AI 应用集成到你的业务系统中。
- 适用场景: 无需或少量代码即可快速构建和部署 LLM 应用的场景。
5. 推理框架的核心原理对比分析
| 特性 | vLLM | LMDeploy | TGI | TensorRT-LLM (基于 NVIDIA TensorRT) | SGLang | Ollama | Llama.cpp | ONNX Runtime | Transformers Pipelines | FastAPI |
|---|---|---|---|---|---|---|---|---|---|---|
| 计算图优化 | 有限,侧重于动态执行图优化 | 较高,针对 Transformer 结构进行了深度优化,例如算子融合、内存优化等 | 基础,依赖底层框架的优化 | 强大,针对 LLM 进行了定制优化,包括层融合、算子重排等 | 有限 | 无 | 有限,主要依赖编译器优化,例如循环展开、指令级并行等 | 良好,能够对计算图进行优化,例如公共子表达式消除、死代码消除等 | 无,Pipeline 专注于易用性 | 无,Web 框架主要关注 API 构建 |
| Kernel Fusion | 有限,主要在 CUDA kernel 层面进行优化 | 较高,针对 Transformer 中常见的操作进行了 kernel 融合,例如 Multi-Head Attention 的融合等 | 基础,依赖底层框架的 kernel 实现 | 强大,针对 LLM 中常见的操作进行了高度优化的 kernel 融合 | 有限 | 无 | 有限,依赖底层库的 kernel 实现,针对 CPU 进行了优化过的 kernel 实现 | 良好,可以将多个操作映射到优化的硬件指令,例如使用特定硬件指令集优化计算 | 无,Pipeline 专注于易用性 | 无,Web 框架主要关注 API 构建 |
| 动态 Batching | 强大 (Continuous Batching,根据实际请求动态调整批次大小) | 良好,支持动态调整批次大小 | 良好,支持动态调整批次大小 | 良好,支持动态调整批次大小 | 强大,内建灵活的分布式批处理能力 | 基础 | 基础 | 良好,支持动态调整批次大小 | 基础,Pipeline 默认支持一定程度的批处理 | 良好,可以灵活控制批处理逻辑 |
| 量化支持 | 多种 (FP8 等) | 支持 INT4 (W4A16/W4A32)、FP16 等多种量化方式 | 支持 INT8、FP16 等多种量化方式 | 强大 (INT8、FP16、INT4 等多种精度,以及 Weight/Activation 量化,支持 PTQ、QAT 等) | 支持多种量化方式 (例如 INT8) | int4 默认 | 支持多种量化方式 (例如 INT4、INT8) | 支持多种量化方式 (例如 INT8、FP16、Dynamic Quantization) | 支持,可以通过参数配置 | 通常在模型部署时集成量化方案 |
| 长序列优化 | 强大 (PagedAttention,高效管理长序列的 KV 缓存) | 良好,针对长文本推理进行了优化,例如 FlashAttention 的应用 | 良好,支持处理较长序列 | 强大,针对 LLM 进行了专门优化,例如高效的注意力机制实现 | 良好,针对长文本生成流程进行了优化 | 良好,对长文本有一定支持 | 良好,通过各种优化技术支持长文本,例如 KV 缓存优化、注意力机制优化等 | 良好,对长文本有一定支持 | 有限 (受限于模型上下文长度) | 无 |
| KV 缓存优化 | 强大 (PagedAttention,避免内存碎片化) | 良好,对 KV 缓存进行了优化 | 良好,对 KV 缓存进行了管理 | 强大,针对 LLM 的 KV 缓存进行了高效管理和优化 | 良好,对 KV 缓存进行了优化 | 良好,对 KV 缓存进行了管理 | 良好,通过量化等方式减少 KV 缓存大小,并通过其他策略优化 KV 缓存的访问 | 良好,对 KV 缓存进行了管理 | 基础的 KV 缓存管理 | 无 |
| 硬件支持 | NVIDIA GPU (为主) | NVIDIA GPU、国产 GPU | 多种 GPU | NVIDIA GPU (专为 NVIDIA GPU 优化) | 多种 GPU/CPU | CPU/GPU | CPU (为主),部分支持 GPU | CPU/GPU/其他加速器 (通过 ONNX 导出) | CPU/GPU | CPU/GPU |
| 其他推理加速技术 | 支持 (例如通过集成其他库) | 支持 (例如 FlashAttention) | 支持 (例如通过集成其他库) | 支持 (例如 FlashAttention、Multi-Query Attention 等) | 支持 (例如通过集成其他库) | 有限 | 支持 (例如通过各种优化编译选项) | 支持 (例如通过优化器) | 支持 (例如模型蒸馏) | 支持 (例如通过集成加速库) |
6. 实操:针对不同场景选择合适的推理框架,并进行性能对比测试
-
场景一:构建一个简单的在线对话服务。
- 选择框架:vLLM 或 TGI,因为它们在延迟和吞吐量方面表现优秀。
- 测试工具:可以使用
locust、ApacheBench或k6等压力测试工具模拟并发用户请求。 - 测试指标:关注 平均延迟 (Average Latency)、第 95 百分位延迟 (P95 Latency)、第 99 百分位延迟 (P99 Latency)、每秒请求数 (Requests Per Second, RPS) 或 每秒处理的 token 数 (Tokens Per Second)。
- 对比:比较不同框架在相同模型、相同并发用户数和相同输入长度下的性能表现。
-
场景二:在本地 CPU 上运行一个轻量级模型。
- 选择框架:Ollama 或 Llama.cpp。
- 测试工具:可以使用 Python 的
time模块测量推理时间,使用系统监控工具(如top或任务管理器)查看 CPU 和内存占用率。更细致的内存分析可以使用memory_profiler等 Python 库。 - 测试指标:关注 生成固定长度文本所需的时间、CPU 利用率 和 内存占用率。
- 对比:比较不同框架在资源占用和推理速度上的差异。
-
场景三:构建一个可以灵活切换不同 LLM 提供商的应用程序。
- 选择框架:LiteLLM。
- 测试指标:主要关注代码的简洁性和切换不同模型 API 的便捷性,可以测量切换模型所需的代码行数和操作步骤。
在进行性能对比测试时,请务必保证测试环境的一致性(例如,相同的硬件、相同的操作系统、相同的模型版本),并进行多次测试取平均值,以获得更可靠的结果。同时,要根据实际的应用场景选择合适的测试指标。
7. 未来趋势展望
LLM 推理框架正处于快速发展和演进的阶段。我们可以预见以下一些未来趋势:
- 更智能的动态批处理: 框架将能够更智能地根据请求的特性和系统负载动态调整批次大小,以实现更高的资源利用率和更好的用户体验。
- 更广泛的硬件支持: 随着专用 AI 加速卡等新兴硬件的出现,推理框架将需要提供更好的支持和优化。
- 推理与训练的融合: 未来可能会出现更紧密的推理与训练框架集成,方便模型部署和持续优化。
- 端侧推理能力的增强: 随着移动设备和嵌入式设备的计算能力提升,轻量级推理框架将在端侧发挥越来越重要的作用。
- 更高级的量化和压缩技术: 为了进一步降低模型大小和提高推理速度,更先进的量化和压缩技术将被集成到推理框架中。
结论:选择最适合您的推理框架
本章详细介绍了 2025 年主流的 LLM 推理框架,它们各自拥有独特的优势和适用场景。在选择框架时,请务必考虑您的 性能需求、硬件环境、部署场景、团队经验、生态系统支持 以及 具体的功能需求。没有绝对的“最佳”答案,而是需要根据您的具体情况进行权衡。如果您追求极致的性能和低延迟,高性能推理框架如 vLLM 和 TensorRT 可能是您的首选。如果您需要在资源受限的环境中运行模型,本地部署框架如 Ollama 和 Llama.cpp 会更适合。如果您需要灵活地支持多种模型或快速构建应用,那么灵活部署和开发者友好型框架将是更好的选择。希望本章的内容能够帮助您更好地理解这些推理利器,并在您的 LLM 应用开发中做出明智的决策。






)