一、系统级性能分析工具perf原理
1. perf 的基本概念
内核集成:perf 直接集成在 Linux 内核源码中,能够深度访问硬件和操作系统层面的性能数据,具有低开销、高精度的特点。
事件采样原理:通过定期采样系统事件(如 CPU 周期、指令执行、缓存访问等),统计热点代码和资源消耗,帮助定位性能瓶颈。
2. 系统级性能优化的两个阶段
(1) 性能剖析(Performance Profiling, PP)
目标:识别系统的瓶颈,如 CPU 利用率过高、内存泄漏、I/O 延迟等。
方法:通过 perf 收集硬件事件(如 CPU 周期)、软件事件(如上下文切换)和追踪点(TracePoint)数据,生成性能报告。
输出:确定程序中耗时最多的函数(热点代码)、资源争用情况等。
(2) 代码优化
目标:基于剖析结果,针对性优化代码或调整系统配置。
常见手段:
优化算法复杂度;
减少锁竞争或使用无锁数据结构;
改善缓存局部性;
调整内存分配策略等。
3. perf 的核心技术支撑
perf 依赖以下三类技术收集性能数据:
(1) PMU(Performance Monitoring Unit)
硬件支持:PMU 是 CPU 内置的硬件单元,用于监控处理器级事件。
监控事件:
CPU 周期(cycles)、指令数(instructions);
缓存命中/失效(cache-misses, cache-references);
分支预测失败(branch-misses)等。
优势:直接访问硬件计数器,精度高、开销极低。
(2) TracePoint
内核静态探针:TracePoint 是 Linux 内核中预定义的静态跟踪点,用于记录特定事件的发生。
监控事件:
系统调用(syscalls)、调度事件(sched_switch);
文件 I/O(ext4 文件系统操作)、网络包处理等。
优势:提供细粒度的内核行为追踪,适用于分析系统调用和内核态性能问题。
(3) 内核计数器
软件统计:内核通过计数器记录系统事件的发生次数。
监控事件:
上下文切换(context-switches)、缺页异常(page-faults);
进程创建(process-fork)等。
优势:适用于统计类性能分析,如系统负载分布。
4. perf 的典型使用场景
(1) CPU 瓶颈分析
命令示例:
perf record -g -e cycles ./my_program # 记录程序的 CPU 周期事件 perf report # 生成热点函数报告输出:显示消耗最多 CPU 周期的函数及其调用栈。
(2) 缓存效率分析
命令示例:
perf stat -e cache-references,cache-misses ./my_program输出:统计缓存命中率,帮助优化内存访问模式。
(3) 内核行为追踪
命令示例:
perf trace -e syscalls:sys_enter_openat # 追踪文件打开操作输出:记录所有
openat系统调用的参数和频率。
5. perf 的优势与对比
优势:
低开销:基于事件采样而非全量记录,对系统影响小;
多功能性:支持硬件事件、内核事件、用户态程序分析;
深度集成:直接利用内核基础设施,无需额外插桩。
对比其他工具:
gprof:仅支持用户态函数耗时统计,无内核级支持;
Valgrind:功能强大但开销极高,适合内存调试而非性能分析。
二、安装性能分析工具perf与perf list命令
1.安装性能分析工具perf
sudo apt-get update
sudo apt-get install linux-tools-generic linux-cloud-tools-generic我这里已经安装过了:

执行perf命令如下,证明已经成功安装perf性能分析工具了。

查看当前perf所支持的性能事件列表如下(有软件也有硬件的):

除此之外还有常用的命令如下:
perf list:查看当前系统支持的性能事件perf bench:针对系统性能进行摸底perf test:针对系统进行健全性能测试perf stat:对全局性能进行统计perf top:针对实时查看当前系统进程函数占用率情况perf probe:自定义动态事件
【perf list sw】

命令作用
perf list sw用于列出系统中 软件模拟的性能事件。其中:
perf list基础功能是展示系统预定义的性能事件;sw是过滤条件,用于筛选出类型为[Software event](软件事件)的条目,这些事件由内核通过软件层面统计生成,而非硬件计数器直接采集。输出含义
输出结果为符合条件的性能事件列表,格式为
事件名称 [事件类型],具体含义:
- 事件名称:
- 如
alignment-faults(内存对齐错误次数)、context-switches OR cs(上下文切换次数,OR表示别名)、cpu-clock(CPU 活动时间)等,是性能分析的具体观测对象,反映系统软件层面的行为(如进程调度、内存管理等)。- 事件类型:
[Software event]:表示该事件由内核通过软件模拟统计(例如上下文切换、内存页错误等,无需硬件计数器支持);- 图中少量
[Tool event]属于输出异常(正常sw过滤应仅含Software event),可能是系统版本或工具特性导致,[Tool event]与perf工具自身功能相关(如时间统计),一般不归类于常规软件事件。
【perf list cache】

命令作用
perf list cache用于列出系统中与 缓存(Cache)相关的预定义性能事件,这些事件可用于分析 CPU 缓存(如一级数据缓存、指令缓存、TLB 等)的访问、命中 / 缺失情况,帮助定位缓存相关的性能瓶颈。输出含义
输出内容为缓存相关的性能事件列表,格式为 事件名称,具体解释:
- 事件分类:
- 以
cpu:开头,表明这些事件与 CPU 缓存相关,基于硬件计数器统计。- 常见事件示例:
L1-dcache-loads OR cpu/L1-dcache-loads/:
- 表示 CPU 一级数据缓存(L1 Data Cache)的加载次数,用于统计从 L1 数据缓存中读取数据的操作数量。
L1-dcache-load-misses OR cpu/L1-dcache-load-misses/:
- 表示 CPU 一级数据缓存加载缺失次数,即读取数据时在 L1 数据缓存中未命中,需从更高层级缓存或内存获取的次数。
L1-icache-loads OR cpu/L1-icache-loads/:
- 表示 CPU 一级指令缓存(L1 Instruction Cache)的加载次数,统计从 L1 指令缓存中读取指令的操作数量。
dTLB-loads OR cpu/dTLB-loads/:
- 表示数据转换查找缓冲(Data Translation Lookaside Buffer, dTLB)的加载次数,用于统计数据地址转换时 TLB 的访问情况。
branch-loads OR cpu/branch-loads/:
- 表示分支指令缓存的加载次数,统计分支指令相关的缓存访问操作。
这些事件可通过
perf stat -e 事件名等命令结合具体工具(如perf statperf record),深入分析程序运行时的缓存使用效率。
三、使用perf采集数据信息/perf stat|top
1.perf stat全局性能统计如下:

命令作用
perf stat ls用于运行ls命令(列出当前目录文件),同时收集并展示该命令执行过程中的性能计数器统计信息,帮助分析程序对 CPU、内存等资源的使用情况。输出内容详解
1. 命令执行结果
FlameGraph grpc linux-5.6.18 linux-5.6.18.tar.gz mosquitto-2.0.15 snap tmp work workflow zvfs这是
ls命令的正常输出,显示当前目录下的文件和文件夹。2. 性能计数器统计(
Performance counter stats for 'ls')
1.66 msec task-clock:
- 含义:任务(即
ls命令)占用的 CPU 时间,单位为毫秒。- 关联计算:
CPUs utilized = task-clock / time elapsed,用于计算 CPU 利用率(本例中通过后续0.583 CPUs utilized体现)。2 context-switches:
- 含义:
ls执行过程中发生的上下文切换次数,反映进程在运行中被调度器暂停 / 恢复的频率。0 cpu-migrations:
- 含义:CPU 迁移次数,即进程在不同 CPU 核心间迁移的次数(本例未发生迁移)。
103 page-faults:
- 含义:缺页异常次数,即访问的内存页面不在物理内存中,需从磁盘加载的次数。
3,073,664 cycles:
- 含义:CPU 消耗的周期数,反映指令执行的硬件耗时(结合
1.856 GHz可辅助分析频率影响)。0 stalled-cycles-frontend:
- 含义:前端停滞周期数,指 CPU 指令获取或解码阶段的停滞情况(本例无停滞)。
0 instructions:
- 含义:执行的指令数量。
0.00 insn per cycle表示每周期执行指令数为 0(可能因统计范围或事件未完全计数导致)。0 branches:
- 含义:分支指令数量,统计程序中条件跳转等分支操作的次数。
0 branch-misses:
- 含义:分支预测错误次数,若分支指令预测错误,会导致流水线刷新,影响性能(本例未统计到,提示
<not counted>)。3. 时间统计
0.002841599 seconds time elapsed:
- 含义:从命令开始到结束的总耗时(墙钟时间)。
0.001439000 seconds user:
- 含义:
ls在用户态执行的时间。0.001439000 seconds sys:
- 含义:
ls在内核态(系统调用)执行的时间。4. 统计提示
Some events weren't counted. Try disabling the NMI watchdog...
- 含义:部分事件(如
branch-misses)未成功计数,提示通过关闭 NMI 看门狗(修改/proc/sys/kernel/nmi_watchdog)尝试解决统计问题。
2.perf top指定性能事件,消耗最多的函数或指令
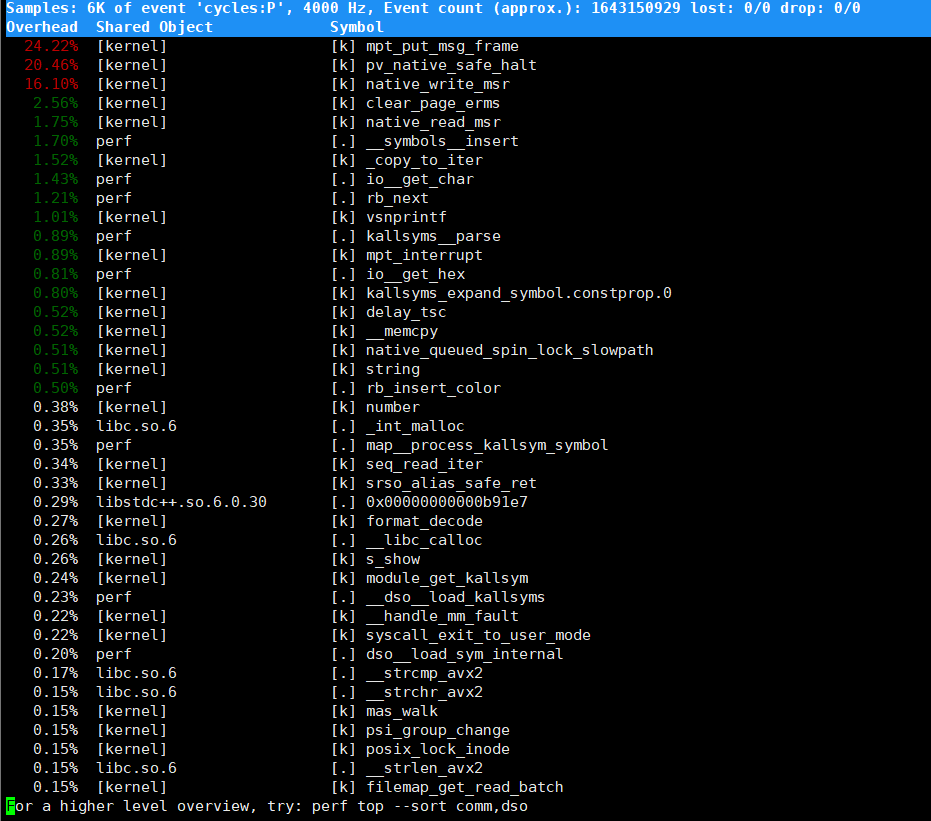
perf top命令作用
perf top是 Linux 性能分析工具perf的子命令,主要用于实时分析系统中各函数在特定性能事件(如 CPU 周期、缓存命中 / 缺失等)上的 “热度”。它通过采样统计,快速定位消耗资源最多的函数(包括应用程序函数、内核函数、动态链接库函数等),帮助开发者或运维人员识别系统性能瓶颈,例如哪些内核函数占用过多 CPU 周期、哪些应用函数存在效率问题等。
结合输出的详细分析(以图中内容为例)
输出表格包含四列,每列含义及对应图中内容分析如下:
1. 第一列:符号引发的性能事件比例
- 含义:表示该函数在性能事件(默认是 CPU 周期)中占用的比例,反映函数对性能事件的 “贡献度”,比例越高,说明该函数越消耗资源。
- 图中示例:
24.22%:表示mpt_put_msg_frame函数占用了约 24.22% 的 CPU 周期,是当前采样中最 “热” 的函数。20.46%:pv_native_safe_halt函数占用 20.46% 的 CPU 周期,也是主要的资源消耗点。2. 第二列:符号所在的 BSO(Binary/Symbol Object)
- 含义:标识函数所属的二进制对象,可能是内核、动态链接库、应用程序或内核模块等。
- 图中示例:
[kernel]:表示函数属于内核(如mpt_put_msg_framepv_native_safe_halt等)。perf:表示函数属于perf工具本身(如io_get_charrb_next等)。libc.so.6:表示函数属于 C 标准库(如_int_malloc_libc_calloc等)。3. 第三列:BSO 的类型
- 含义:
[k]:表示符号属于内核空间(内核代码或内核模块)。[.]:表示符号属于用户空间的 ELF 文件(如应用程序、动态链接库)。- 图中示例:
[k]:如mpt_put_msg_framepv_native_safe_halt等内核函数。[.]:如io_get_char(属于perf工具的用户态函数)。4. 第四列:符号名称或地址
- 含义:
- 若能解析为函数名,直接显示函数名(如
mpt_put_msg_frame_int_malloc);- 若无法解析(如匿名函数、代码地址),则显示地址(如
0x00000000000b91e7)。- 图中示例:
mpt_put_msg_frame:内核中可解析的函数名。0x00000000000b91e7:无法解析为函数名,仅显示地址的符号。
总结
通过
perf top的输出,可快速定位系统中资源消耗最大的函数。例如图中内核函数mpt_put_msg_frame和pv_native_safe_halt占据较高比例,若系统存在 CPU 利用率过高的问题,就可优先分析这些函数的逻辑是否存在优化空间。
3.perf record
perf record 精确到函数级别(混合显示汇编语言和代码),就是我们运行此工具命令之后,将其数据保存到 perf.data 中,我们也可以通过 perf report 进行分析。
perf record 工具命令常用选项:
-e-->record 指定 PMU 事件(--filter event 事件过滤器)
-a--> 获取所有 CPU 事件
-p--> 获取指定 PID 进程的事件
-o--> 指定获取保存数据的文件名称
-g--> 能够使函数调用图功能
-C--> 获取指定 CPU 事件
【具体案例】
testfork.c
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>int main() {int i;for (i = 0; i < 5; i++) {pid_t pid = fork();if (pid == 0) { // 子进程int j;for (j = 0; j < 100000; j++) {int x = j * j; // 模拟计算}return 0;} else if (pid > 0) { // 父进程wait(NULL); // 等待子进程结束} else {perror("fork");return 1;}}return 0;
}编译采集:

接着执行命令 perf report --call-graph none

四、采集perf数据信息生成火焰图
- 火焰图(flame graph)是性能分析的利器,通过它可以快速定位性能瓶颈点。
- perf 命令(performance 的缩写)是 Linux 系统原生提供的性能分析工具,会返回 CPU 正在执行的函数名以及调用栈(stack)。
使用步骤
1.下载FlameGraph包
curl -O http://example.com/FlameGraph.zip 
2.生成perf.unfold文件
perf script -i perf.data &> perf.unfold

如果中间出现权限问题
Permission denied,可以使用chmod u+x 增加执行权限。
3.生成perf.folded文件
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded

下面这两行命令和上面两行命令功能相同,也可以生成需要的perf.folded
perf script > perf.script
./FlameGraph/stackcollapse-perf.pl perf.script > perf.folded
4.生成perf.svg文件
./FlameGraph/flamegraph.pl perf.folded > perf.svg

5.打开火焰图

https://github.com/0voice



:ls)
