在 PyTorch 中,池化层(Pooling Layer)是卷积神经网络(CNN)中的重要组成部分,主要用于降维(减少计算量)和特征提取(增强平移不变性)。PyTorch 提供了多种池化操作,包括最大池化、平均池化、自适应池化等。以下是详细说明:
1. 最大池化(Max Pooling)
作用:提取局部区域的最大值,保留最显著的特征。
常用场景:图像分类、目标检测等。
(1) 二维最大池化(nn.MaxPool2d)
import torch.nn as nn# 定义一个 2x2 的最大池化层,步长 stride=2
max_pool = nn.MaxPool2d(kernel_size=2, # 池化窗口大小(可以是 int 或 tuple,如 (2,2))stride=2, # 步长(默认等于 kernel_size)padding=0, # 填充(默认 0)dilation=1, # 空洞池化(默认 1)return_indices=False # 是否返回最大值的位置(用于 MaxUnpool2d)
)# 输入张量 (batch_size=1, channels=1, height=4, width=4)
x = torch.tensor([[[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
]], dtype=torch.float32).unsqueeze(0) # shape: [1, 1, 4, 4]output = max_pool(x)
print(output)输出:
tensor([[[[ 6., 8.],[14., 16.]]]])计算过程:
-
池化窗口
2x2,步长2,无填充。 -
输出尺寸计算:

(2) 一维最大池化(nn.MaxPool1d)
适用于时序数据(如 NLP、语音):
max_pool_1d = nn.MaxPool1d(kernel_size=2, stride=2)
x = torch.tensor([[[1, 2, 3, 4, 5, 6]]], dtype=torch.float32) # shape: [1, 1, 6]
output = max_pool_1d(x) # shape: [1, 1, 3]
print(output) # tensor([[[2., 4., 6.]]])
2. 平均池化(Average Pooling)
作用:计算局部区域的平均值,适用于平滑特征。
常用场景:图像分类、语义分割等。
(1) 二维平均池化(nn.AvgPool2d)
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
x = torch.tensor([[[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]
]], dtype=torch.float32).unsqueeze(0) # shape: [1, 1, 4, 4]output = avg_pool(x)
print(output)输出:
tensor([[[[ 3.5, 5.5],[11.5, 13.5]]]])计算过程:
-
每个
2x2窗口取平均值: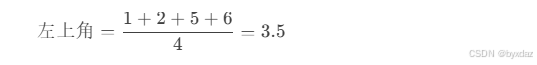
(2) 全局平均池化(Global Average Pooling, nn.AdaptiveAvgPool2d)
常用于 CNN 最后一层,代替全连接层:
global_avg_pool = nn.AdaptiveAvgPool2d((1, 1)) # 输出固定为 1x1
x = torch.randn(1, 3, 32, 32) # 假设输入是 32x32 的 RGB 图像
output = global_avg_pool(x) # shape: [1, 3, 1, 1]
3. 其他池化操作
(1) 自适应池化(Adaptive Pooling)
作用:自动调整输出尺寸,适用于输入尺寸不固定的情况。
# 自适应最大池化,输出尺寸固定为 3x3
adaptive_max_pool = nn.AdaptiveMaxPool2d((3, 3))
x = torch.randn(1, 3, 128, 128) # 任意输入尺寸
output = adaptive_max_pool(x) # shape: [1, 3, 3, 3](2) 分数池化(Fractional Pooling)
PyTorch 不直接支持,但可通过 nn.functional.interpolate 实现类似效果。
4. 池化层 vs 卷积层
| 特性 | 池化层 (Pooling) | 卷积层 (Convolution) |
|---|---|---|
| 作用 | 降维、增强平移不变性 | 特征提取 |
| 可学习参数 | 无 | 有(权重和偏置) |
| 计算方式 | 取最大值/平均值 | 线性变换 + 非线性激活 |
| 输出尺寸 | 通常比输入小 | 可能比输入大(带 padding) |
5. 池化层的典型应用
class CNN(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)self.pool1 = nn.MaxPool2d(2, 2) # 降维 2 倍self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)self.pool2 = nn.AdaptiveAvgPool2d((1, 1)) # 全局平均池化def forward(self, x):x = F.relu(self.conv1(x))x = self.pool1(x) # [B, 16, H/2, W/2]x = F.relu(self.conv2(x))x = self.pool2(x) # [B, 32, 1, 1]return x
6. 总结
-
最大池化(
MaxPool2d):提取最显著特征,适用于分类任务。 -
平均池化(
AvgPool2d):平滑特征,适用于回归或语义分割。 -
自适应池化(
AdaptiveAvgPool2d):适用于输入尺寸不固定的情况。 -
全局平均池化(GAP):常用于 CNN 最后一层,减少参数量。





