安利免费开源的声音克隆、文本转语音整合包软件、一键本地安装!
大家好,我是星哥,今天给大家介绍两款声音克隆、文本转语音的软件,一个是ChatTTS和Spark-TTS,并且都有一键安装包,让你无需复杂的配置,就能在本地轻松体验声音的魅力。

ChatTTS是什么?
ChatTTS是专为对话场景设计的语音生成模型,特别适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。它支持中文和英文,通过使用大约100,000小时的中文和英文数据进行训练,ChatTTS在语音合成中表现出高质量和自然度。
开源地址: https://github.com/2noise/ChatTTS
安装ChatTTS
安装ChatTTS有3种方式,第1种是Docker compose安装ChatTTS-ui(推荐)、第2种是安装一键安装包(推荐)、第3种本地安装方式、
本地部署ChatTTS
系统环境介绍
以下都安装这个系统来介绍
系统:Windows11专业版
CPU: 英特尔I7-13700KF
内存: 32G
硬盘:1T nvme SSD +4T 机械
显卡:RTX 4070 Ti
python版本:Python 3.13.2
系统要安装Docker和Docker compose
Docker compose安装ChatTTS-ui(推荐)
开源地址:https://github.com/jianchang512/ChatTTS-ui
1.拉取项目仓库
在任意路径下克隆项目,例如:
git clone https://github.com/jianchang512/ChatTTS-ui.git chat-tts-ui
2.启动 Runner
进入到项目目录:
cd chat-tts-ui
启动容器并查看初始化日志:
gpu版本
docker compose -f docker-compose.gpu.yaml up -d cpu版本
docker compose -f docker-compose.cpu.yaml up -ddocker compose logs -f --no-log-prefix
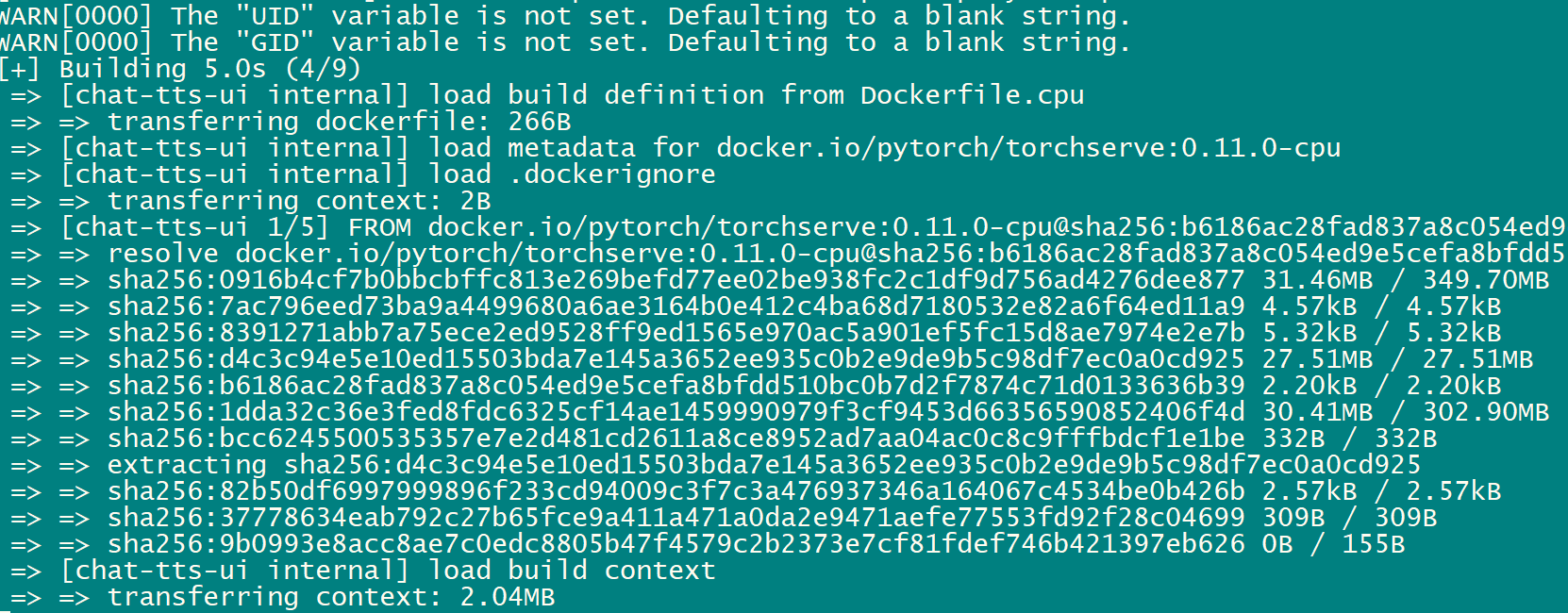
稍等一段时间,使用命令docker ps查看,如下则表示安装成功。
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7cce18cbbe8d chat-tts-ui-chat-tts-ui "/usr/local/bin/dock…" 7 minutes ago Up 2 minutes 7070-7071/tcp, 8080-8082/tcp, 0.0.0.0:9966->9966/tcp, :::9966->9966/tcp chat-tts-ui
3.访问 ChatTTS WebUI
启动:['0.0.0.0', '9966'],也即,访问部署设备的 IP:9966 即可,例如:
- 本机:
http://127.0.0.1:9966 - 服务器:
http://192.168.1.100:9966
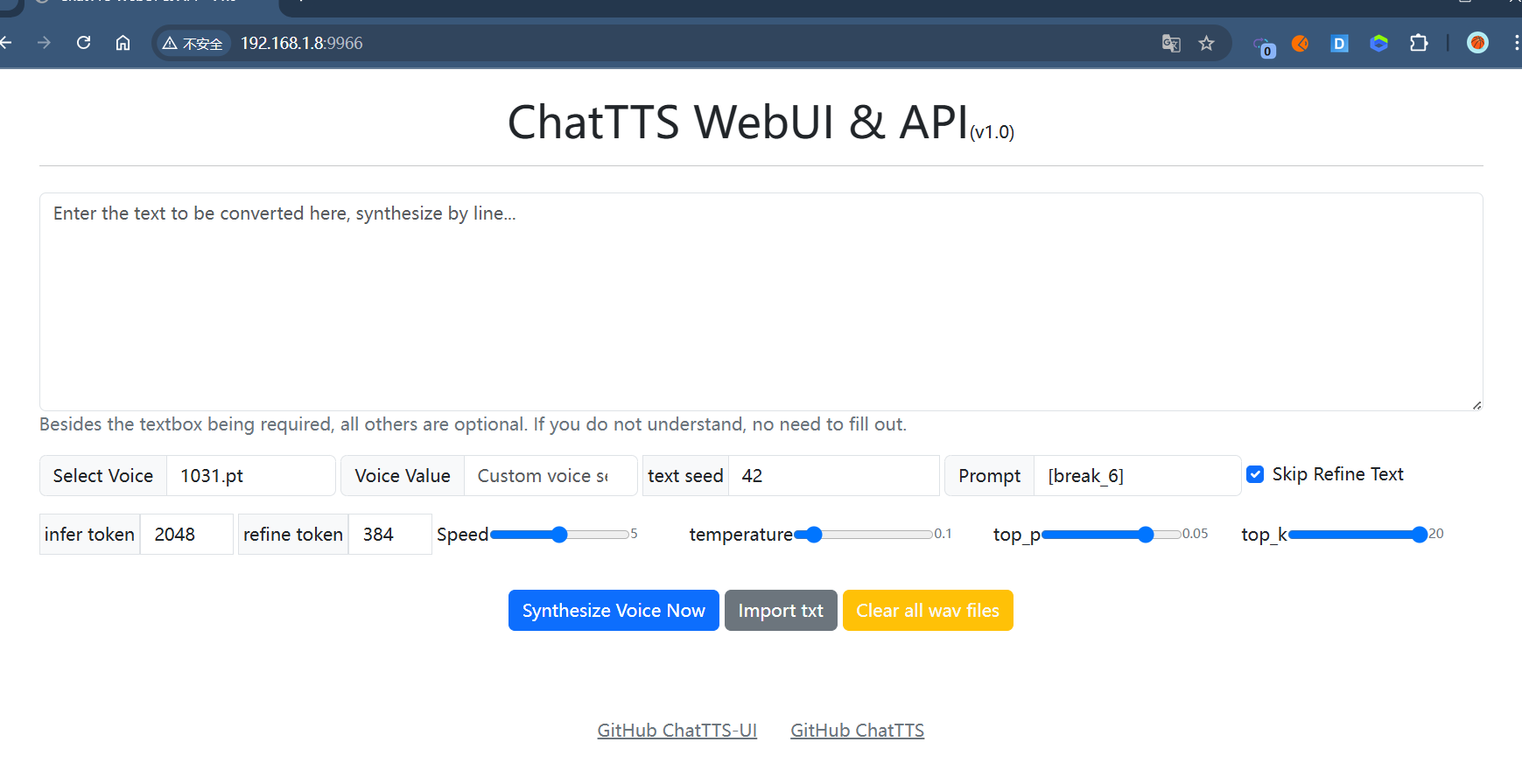
4.生成语言
随便输入一段莎士比亚的《哈姆雷特》生存还是毁灭
莎士比亚
活着还是去死?这真是一个值得思虑的问题。
去忍受那狂暴的命运无情的摧残,还是挺身去反抗那无边的烦恼,把它扫一个干净。去死,去睡就结束了?如果睡眠能结束我们心灵的创伤和肉体所承受的千百样痛苦,那真是生存求之不得的天大的好事。
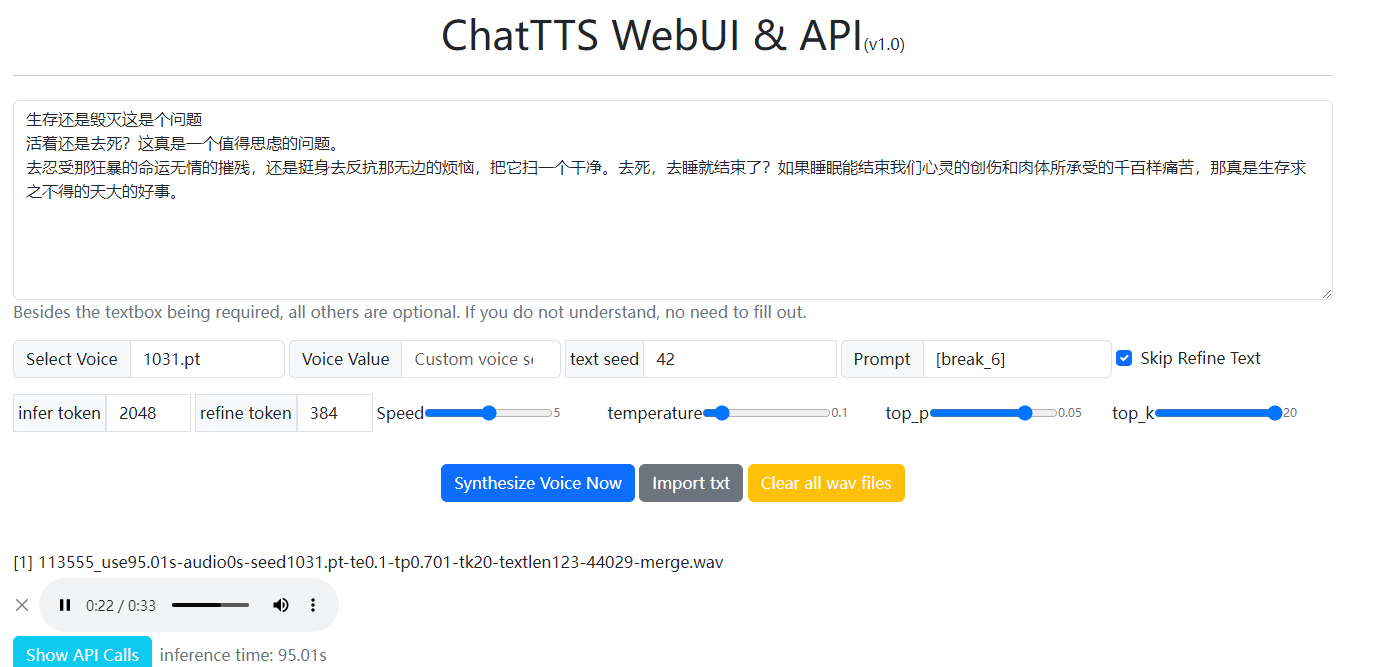
可以调试好可以下载语音。
Windows预打包版(推荐)
从 Releases中下载压缩包,解压后双击 app.exe 即可使用
某些安全软件可能报毒,请退出或使用源码部署
英伟达显卡大于4G显存,并安装了CUDA11.8+后,将启用GPU加速
ChatTTS-UI整合包下载
文件大小: 3.69G
pan点baidu点com/s/1Hnqzm8ZdDKYX0dbvGmW38g?pwd=khds (浏览器中)
提取码: khds
由于平台不让放链接,“星哥玩云”gzh,回复“TTS安装包”获得ChatTTS和Spark-TTS的一键安装包
本地安装(不推荐)
1.安装Python 和 git环境
需要安装python和git软件
python需要 3.9+ 版本,比如我选择python 3.10.2
安装下git环境,这个就不详细将。
2.克隆 ChatTTS-Ui
3.解压后在根目录下输入CMD进入终端,然后依次执行下面的安装命令:
python -m venv venv
.\venv\scripts\activate
pip install -r requirements.txt
4.如果不需要CUDA加速,执行
pip install torch==2.1.2 torchaudio==2.1.2
如果需要CUDA加速,执行
pip install torch==2.1.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
5.启动
最后执行 python app.py 启动,将自动打开浏览器窗口,默认地址 http://127.0.0.1:9966
(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)
6.下载modelscope下载模型
源码部署启动后,会先从 modelscope下载模型,但modelscope缺少spk_stat.pt,会报错,【点击下载 spk_stat.pt】
下载后将该文件复制到 项目目录/models/pzc163/chatTTS/asset/ 文件夹内
注意 modelscope 仅允许中国大陆ip下载模型,如果遇到 proxy 类错误,请关闭代理。
如果你希望从 huggingface.co 下载模型,请打开 app.py 查看大约第50行-60行的注释。如果需要GPU加速,必须是英伟达显卡,并且安装 cuda版本的torch
# 默认从 modelscope 下载模型,如果想从huggingface下载模型,请将以下3行注释掉CHATTTS_DIR = snapshot_download('pzc163/chatTTS',cache_dir=MODEL_DIR)
chat = ChatTTS.Chat()
chat.load_models(source="local",local_path=CHATTTS_DIR)# 如果希望从 huggingface.co下载模型,将以下注释删掉。将上方3行内容注释掉#os.environ['HF_HUB_CACHE']=MODEL_DIR
#os.environ['HF_ASSETS_CACHE']=MODEL_DIR
#chat = ChatTTS.Chat()
#chat.load_models()
Spark-TTS是什么
Spark-TTS 是最近备受瞩目的一个语音克隆开源项目,由香港科技大学、西北工业大学、上海交通大学等多所高校联合研发。经过本地测试,其效果与 F5-TTS 不相上下。
Spark-TTS 支持中英文语音克隆,安装部署过程并不复杂。本文将详细介绍如何安装部署,并进行修改,使其兼容 F5-TTS 的 API 接口,从而可以直接在 pyVideoTrans 软件的 F5-TTS 配音渠道中使用。
Spark-TTS的项目地址
- 项目官网:https://sparkaudio.github.io/spark-tts/
- Github仓库:https://github.com/SparkAudio/Spark-TTS
- HuggingFace模型库:https://huggingface.co/SparkAudio/Spark-TTS-0.5B
Spark-TTS的主要功能
- 零样本文本到语音转换:Spark-TTS 能在没有特定语音数据的情况下,复现说话人的声音,实现零样本语音克隆。
- 多语言支持:Spark-TTS 支持中英双语,可实现跨语言语音合成。用户可以用一种语言输入文本,生成另一种语言的语音输出,满足多语言场景下的语音合成需求。
- 可控语音生成:用户可以通过调整参数(如性别、音调、语速、音色等)来定制虚拟说话者的声音,生成符合特定需求的语音内容。
- 高效简洁的语音合成:基于 Qwen2.5 架构,Spark-TTS 无需额外的生成模型(如流匹配模型),直接从 LLM 预测的编码中重建音频,提高了语音合成的效率。
- 虚拟说话者创建:用户可以创建完全由自己定义的虚拟说话者,通过参数调整使其具有独特的语音风格,适用于虚拟主播、有声读物等场景。
- 语音克隆与风格迁移:Spark-TTS 支持从少量语音样本中提取风格特征,将其迁移到合成语音中,实现个性化语音风格的复制和迁移。
Spark-TTS的应用场景
- 语音助手开发:Spark-TTS 可以用于开发个性化的语音助手,通过调整音色、语速和语调等参数,生成自然流畅的语音输出,为用户提供更加人性化和个性化的交互体验。
- 多语言内容创作:工具支持中英双语,能实现跨语言语音合成,适合需要在不同语言版本之间保持一致语音风格的内容创作者,例如制作多语言的有声读物、广告或教育材料。
- 智能客服与信息播报:Spark-TTS 可以将文字信息转化为自然语音,用于智能客服系统,提供24小时不间断的服务,或者在公共交通、机场、医院等公共场所进行信息播报。
- 语音克隆与虚拟角色配音:Spark-TTS 支持零样本语音克隆,能快速复制特定说话人的声音风格,适用于虚拟角色配音、动画制作或虚拟主播等领域。
安装Spark-TTS
Spark-TTS整合安装包
由于迅雷限速下载还需要几个小时,等下载好了,再发链接

由于平台不让放链接,可以关注“星哥玩云”公众号,回复“TTS安装包”获得ChatTTS和Spark-TTS的一键安装包
1. 下载Spark-TTS源码
推荐有一定操作基础的这样安装
首先,在非系统盘创建一个由英文或数字组成的文件夹,例如 D:/spark。之所以要求使用英文、数字且非系统盘,是为了尽量避免可能出现的中文、权限等方面的错误。
然后,访问 Spark-TTS 官方代码仓库:https://github.com/SparkAudio/Spark-TTS
如下图所示,点击下载源码的 ZIP 包:
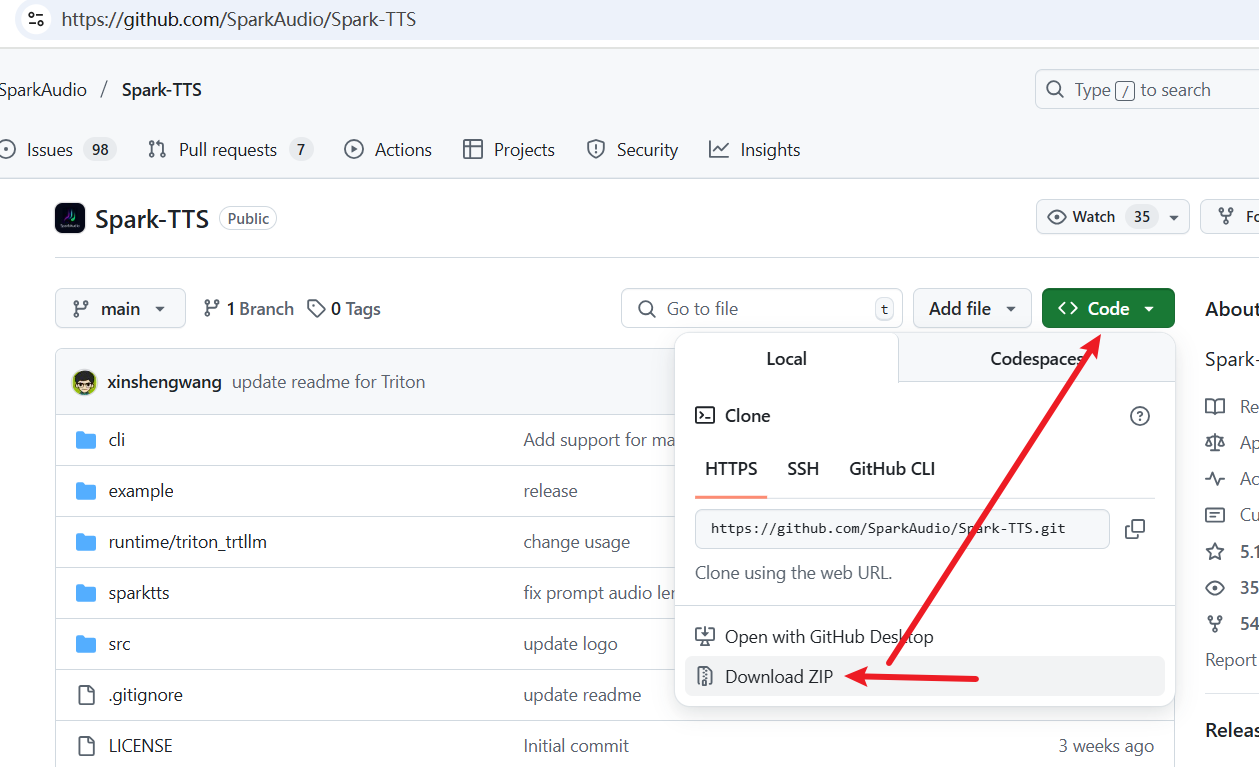
下载完成后解压,将所有文件和文件夹复制到 D:/spark 文件夹中。复制后的目录结构应如下图所示:
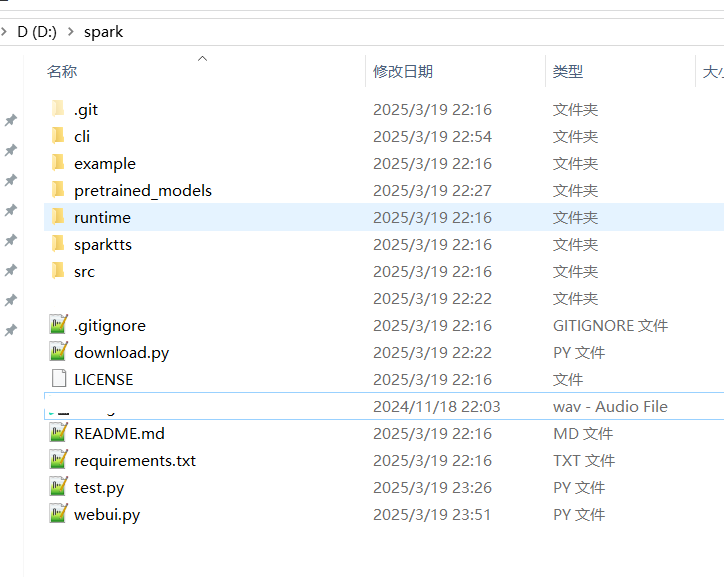
2. 创建虚拟环境并安装依赖
创建虚拟环境
在该文件夹地址栏输入 cmd 并回车,在弹出的黑色终端窗口中执行以下命令:
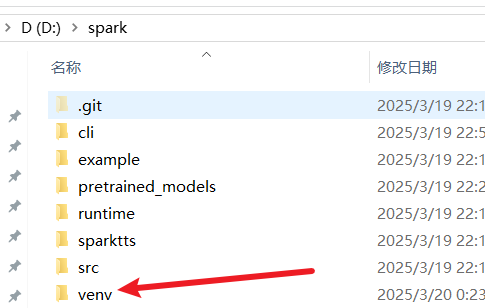
python -m venv venv
执行后,D:/spark 目录下会多出一个 venv 文件夹:
注意: 如果在执行时提示
python 不是内部或外部命令,说明没有安装 Python 或没有将其添加到系统环境变量中,请参考相关文章安装 Python。
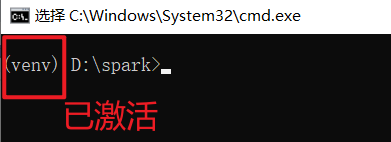
接下来,执行 venv\scripts\activate 激活虚拟环境。激活后,终端行首会出现 (venv) 字样,表示激活成功。后续所有命令都需要在此环境下执行,每次执行前请检查是否已激活。
安装依赖
在已激活的虚拟环境中,继续在终端中执行以下命令,安装所有依赖:
pip install -r requirements.txt或者:
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
3. 下载模型
开源 AI 项目所需的模型通常托管在 Hugging Face (huggingface.co) 上。由于该网站在国内已被屏蔽,因此需要科学上网才能下载模型。请确保已配置好科学上网环境,并设置了系统代理。
在当前目录 D:/spark 下创建一个名为 down.txt 的文本文件,将以下代码复制粘贴到文件中并保存:
from huggingface_hub import snapshot_download
snapshot_download("SparkAudio/Spark-TTS-0.5B", local_dir="pretrained_models/Spark-TTS-0.5B")
print('下载完成')
然后,在已激活虚拟环境的终端窗口中执行以下命令:
python down.txt
注意检查命令行前是否存在 (venv):
等待终端提示下载完成。
如果输出类似以下信息,说明网络连接错误,可能是科学上网环境配置不正确:
Returning existing local_dir `pretrained_models\Spark-TTS-0.5B` as remote repo cannot be accessed in `snapshot_download` ((MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /api/models/SparkAudio/Spark-TTS-0.5B/revision/main (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x000001BC4C8A4430>, 'Connection to huggingface.co timed out. (connect timeout=None)'))"), '(Request ID: aa61d1fb-ffc7-4479-9a99-2258c1bc0aee)')).

4. 启动 Web 界面
模型下载完成后,就可以启动并打开 Web 界面了。
在已激活虚拟环境的终端中执行以下命令:
python webui.py
等待出现如下信息时,表示启动完成:
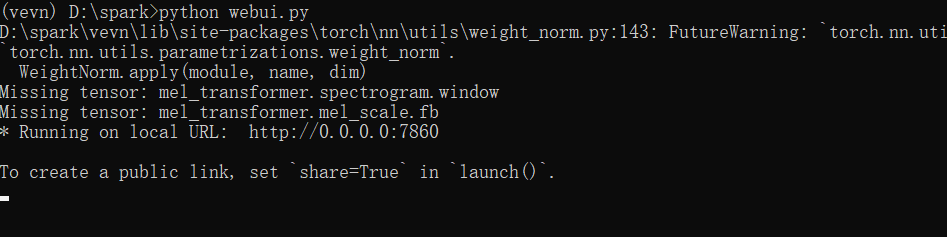
此时,可以在浏览器中打开地址 http://127.0.0.1:7860,Web 界面如下图所示:
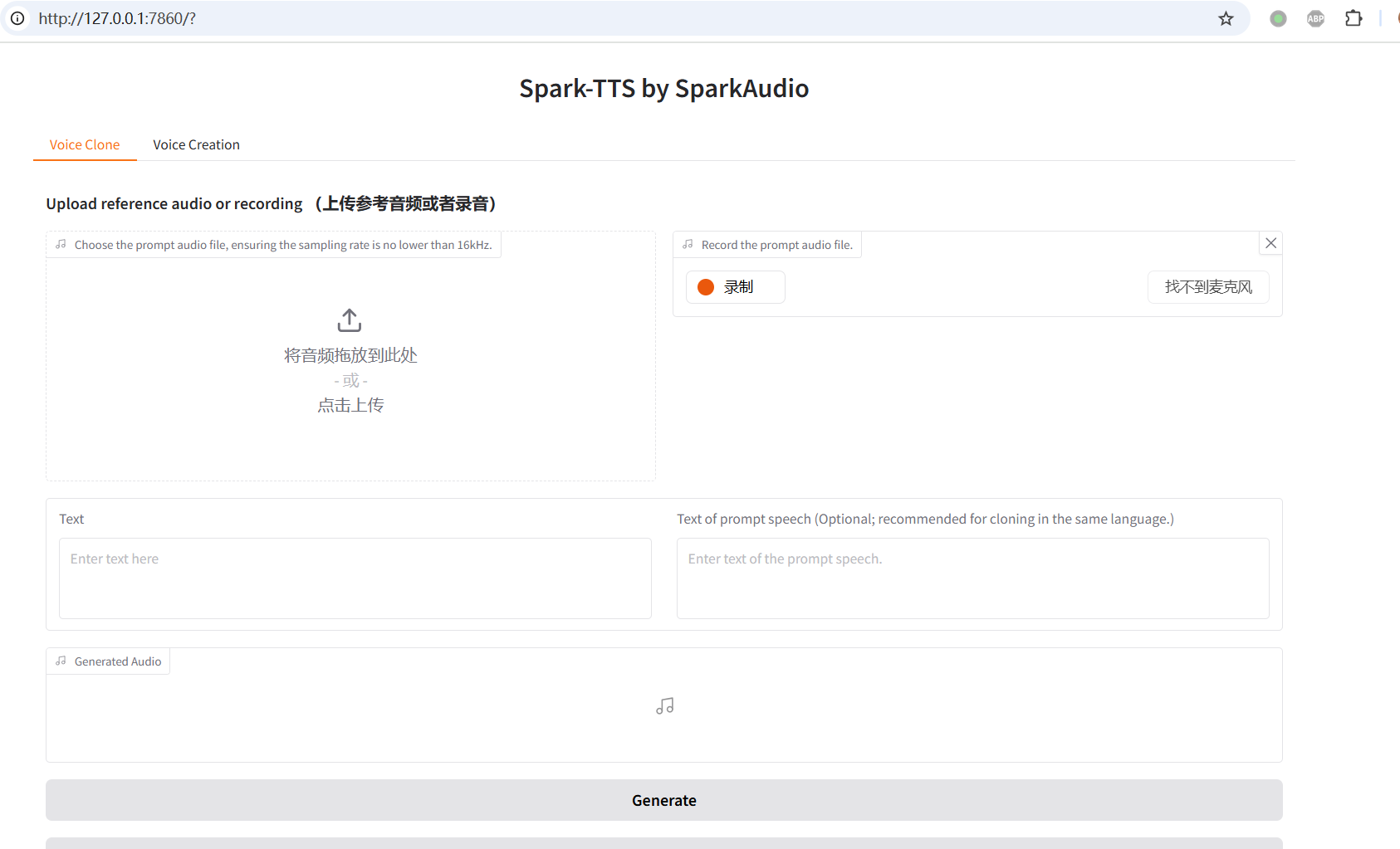
5. 语音克隆测试
如下图所示,选择一个你想要克隆音色的音频文件(时长 3-10 秒,发音清晰,背景干净)。
然后在右侧 Text of prompt speech 中输入该音频对应的文本内容,左侧输入你希望生成的语音文本,最后点击底部的 Generate 按钮开始执行。
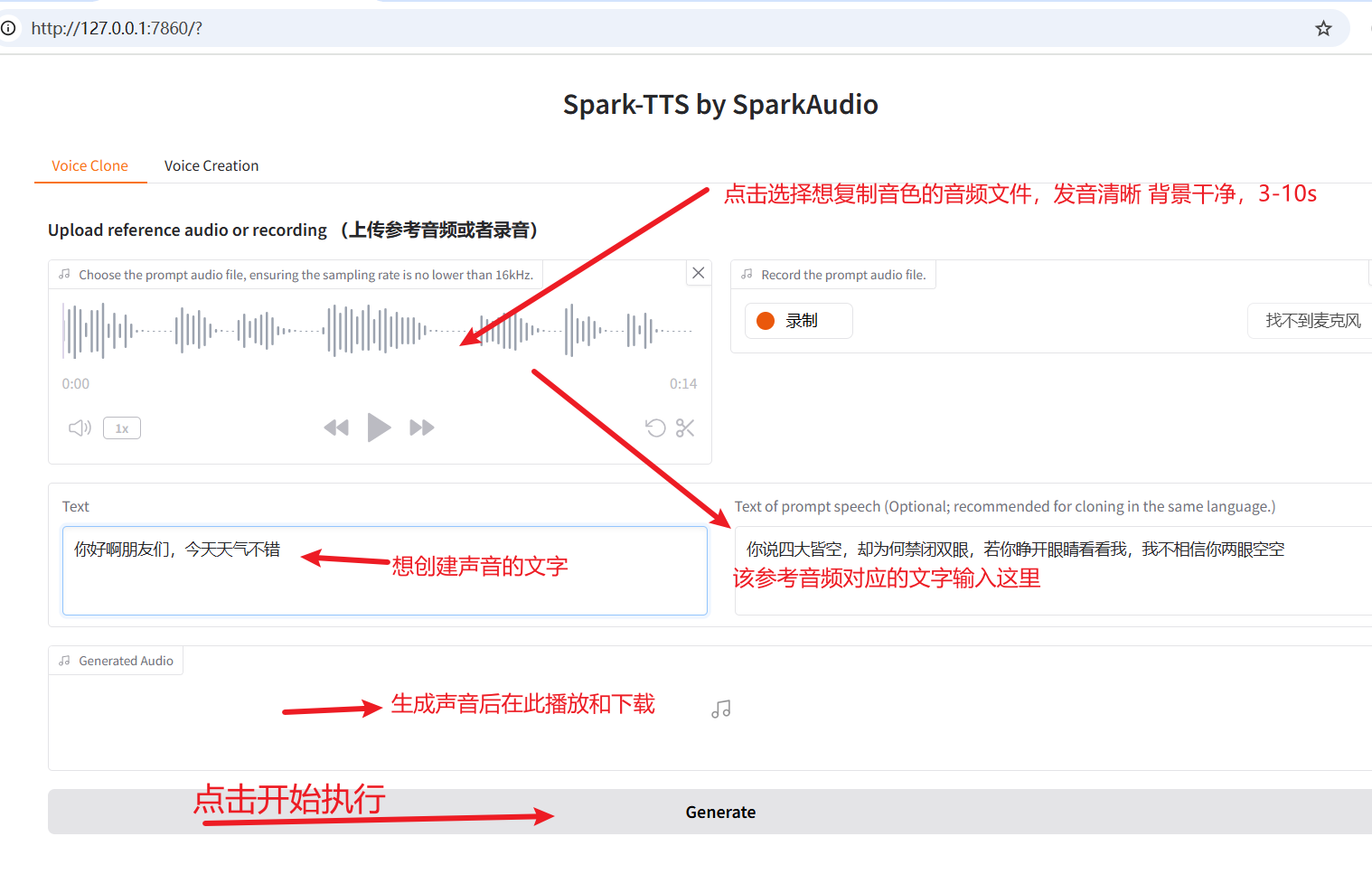
执行完成后,如下图所示。
6. 在 pyVideotrans 软件中使用
Spark-TTS 与 F5-TTS 非常相似,只需进行简单修改,就可以直接在 pyVideotrans 的 F5-TTS 配音渠道中使用 Spark-TTS。
打开 webui.py 文件,在大约第 135 行的上方粘贴以下代码:
def basic_tts(gen_text_input, ref_text_input, ref_audio_input,remove_silence=None,speed_slider=None):"""Gradio callback to clone voice using text and optional prompt speech.- text: The input text to be synthesised.- prompt_text: Additional textual info for the prompt (optional).- prompt_wav_upload/prompt_wav_record: Audio files used as reference."""prompt_speech = ref_audio_inputprompt_text_clean = None if len(ref_text_input) < 2 else ref_text_inputaudio_output_path = run_tts(gen_text_input,model,prompt_text=prompt_text_clean,prompt_speech=prompt_speech)return audio_output_path,prompt_text_clean
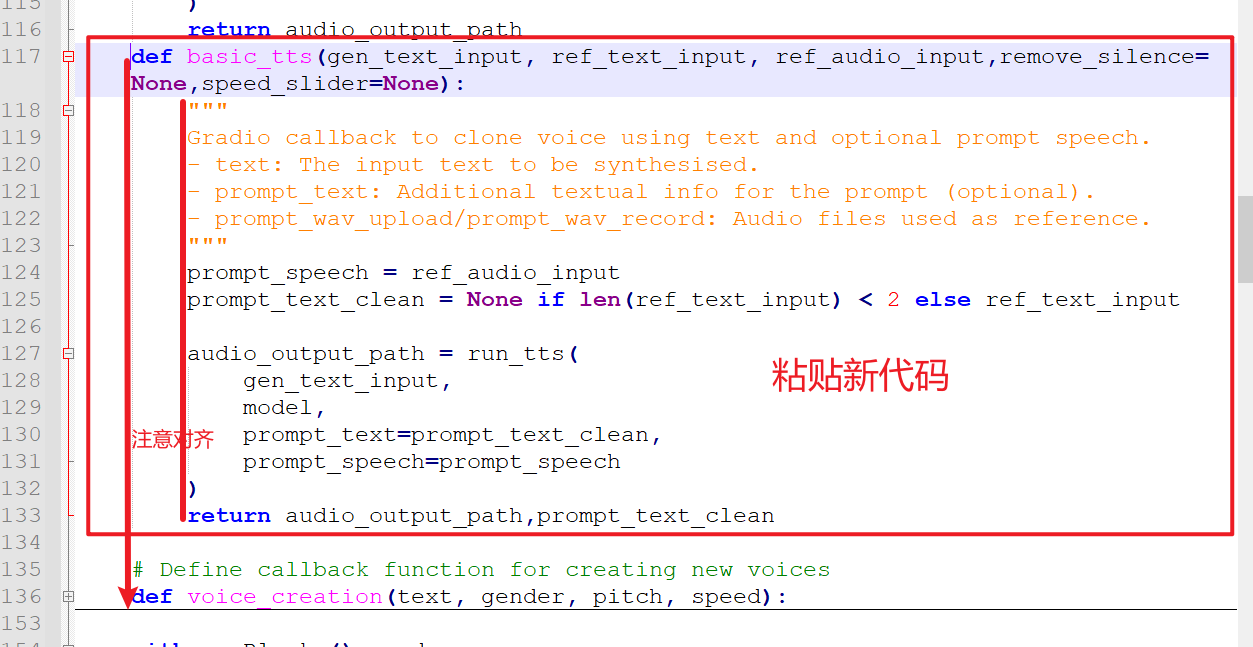
特别注意: Python 代码使用空格进行缩进对齐,否则代码会报错。为避免出错,建议不要使用记事本打开 webui.py 文件,而是使用专业的代码编辑器,例如 Notepad++ 或 VSCode 等免费工具。
然后,找到大约第 190 行的 generate_buttom_clone = gr.Button("Generate") 代码。 在其上方粘贴以下代码,同样必须注意对齐:
generate_buttom_clone2 = gr.Button("Generate2",visible=False)
generate_buttom_clone2.click(basic_tts,inputs=[text_input,prompt_text_input,prompt_wav_upload,text_input,text_input],outputs=[audio_output,prompt_text_input],api_name="basic_tts")
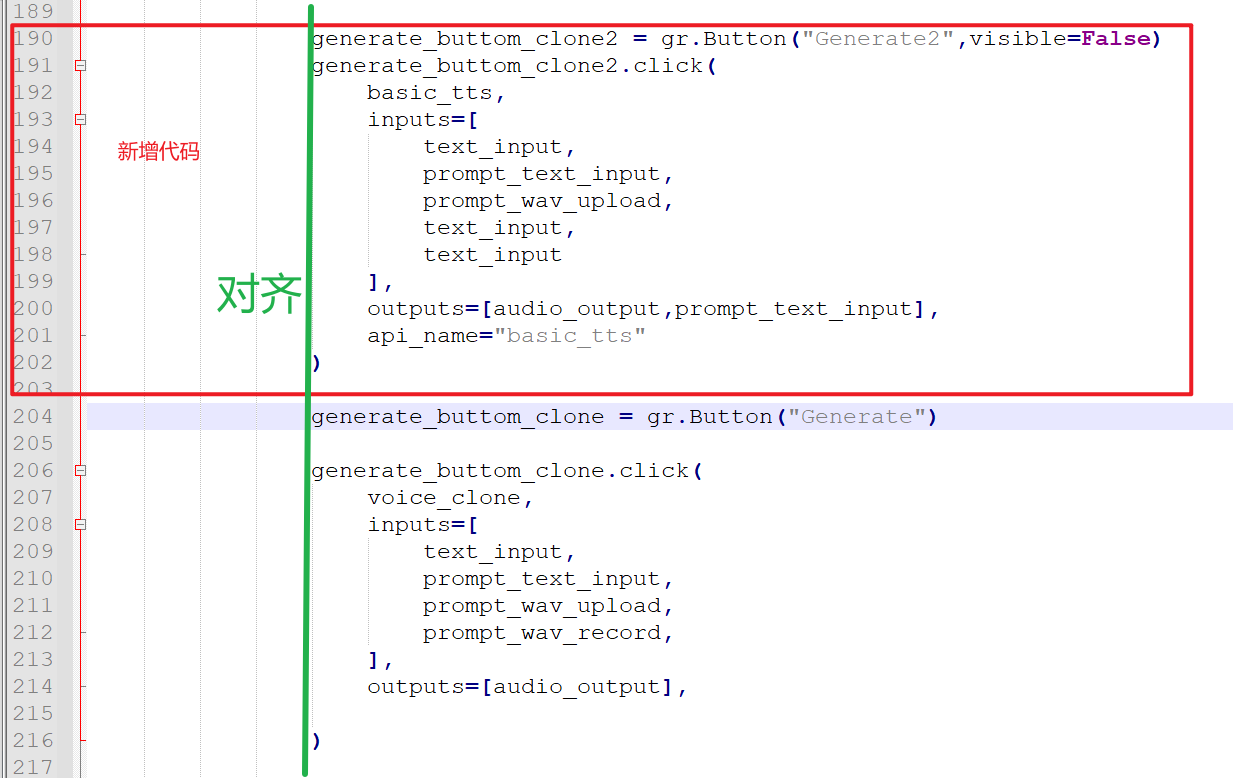
保存文件后,重新启动 webui.py:
python webui.py
- 将地址
http://127.0.0.1:7860填写到 pyVideotrans 软件的 “菜单” -> “TTS 设置” -> “F5-TTS” 的 API 地址中,即可开始使用。参考音频的位置和填写方式与 F5-TTS 的使用方法一致。
结束
ChatTTS和Spark-TTS都是非常优秀的免费开源声音克隆、文本转语音软件。 感兴趣的小伙伴可以试试。
写文不易,如果你都看到了这里,请点个赞和在看,分享给更多的朋友;也别忘了关注星哥玩云!这里有满满的干货分享,还有轻松有趣的技术交流~点个赞、分享给身边的小伙伴,一起成长,一起玩转技术世界吧! 😊




