写在开始:
1️⃣ 本文仅用作个人java日常开发记录学习使用,如果涉及版权或者其他问题,及时联系小编修改或者下架,多谢
2️⃣本文简单介绍LiteFlow是什么,为什么用它,以及如何用的介绍,还有LiteFlow的代码以及设计模式应用分析,如果有兴趣还是希望大家自行去官网看看,一起学习学习;
1 [WHAT]什么是LiteFlow
LiteFlowX 规则引擎官方网址:https://liteflow.yomahub.com
在每个公司的系统中,总有一些拥有复杂业务逻辑的系统,这些系统承载着核心业务逻辑,几乎每个需求都和这些核心业务有关,这些核心业务业务逻辑冗长,涉及内部逻辑运算,缓存操作,持久化操作,外部资源调取,内部其他系统RPC调用等等。时间一长,项目几经易手,维护的成本得就会越来越高。各种硬代码判断,分支条件越来越多。代码的抽象,复用率也越来越低,各个模块之间的耦合度很高。一小段逻辑的变动,会影响到其他模块,需要进行完整回归测试来验证。如要灵活改变业务流程的顺序,则要进行代码大改动进行抽象,重新写方法。实时热变更业务流程,几乎很难实现
如何打破僵局?LiteFlow为解耦逻辑而生,为编排而生,在使用LiteFlow之后,你会发现打造一个低耦合,灵活的系统会变得易如反掌
1.1 特性
- 基于组件:编排的最小粒度为组件,复杂业务的解耦利器,为所有组件提供统一化的编写方式。
- 规则轻量 : 基于EL规则文件来编排复杂逻辑,多种格式支持,规则语法简单易学。可实现任意复杂编排。
- 多配置源 :规则可储存在任意地方,除了框架支持的外,用户还可自定义扩展。
- 平滑热刷 : 可在应用运行时进行热刷新规则,并且整个过程是平滑的。
- 支持脚本 :支持Groovy和多种QL语言的逻辑编写,可实现热变更逻辑。
- 稳定高效 : 能稳定运行在生产环境,成为应用编排的核心驱动引擎,性能卓越。
LiteFlow简介: https://liteflow.cc/pages/5816c5/
2 [WHY] LiteFlow优势和使用场景
LiteFlow的设计原则基于工作台模式
工作台模式
n个工人按照一定顺序围着一张工作台,按顺序各自生产零件,生产的零件最终能组装成一个机器,每个工人只需要完成自己手中零件的生产,而无需知道其他工人生产的内容。每一个工人生产所需要的资源都从工作台上拿取,如果工作台上有生产所必须的资源,则就进行生产,若是没有,就等到有这个资源。每个工人所做好的零件,也都放在工作台上。
这个模式有几个好处:
每个工人无需和其他工人进行沟通。工人只需要关心自己的工作内容和工作台上的资源。这样就做到了每个工人之间的解耦和无差异性。
即便是工人之间调换位置,工人的工作内容和关心的资源没有任何变化。这样就保证了每个工人的稳定性。
如果是指派某个工人去其他的工作台,工人的工作内容和需要的资源依旧没有任何变化,这样就做到了工人的可复用性。
因为每个工人不需要和其他工人沟通,所以可以在生产任务进行时进行实时工位更改:替换,插入,撤掉一些工人,这样生产任务也能实时地被更改。这样就保证了整个生产任务的灵活性。
这个模式映射到LiteFlow框架里,工人就是组件,工人坐的顺序就是流程配置,工作台就是上下文,资源就是参数,最终组装的这个机器就是这个业务。正因为有这些特性,所以LiteFlow能做到统一解耦的组件和灵活的装配
2.1 优势
- 解耦复杂逻辑 :复杂逻辑的重构,你只需按照业务边界来拆分成小组件。LiteFlow为你的系统提供了统一化的组件标准。每个组件尽量保证职责单一性。
- 任意编排 :当你的业务变成了一个个小组件时,你就可以进行任意编排。无论是多么复杂的结构,通过编写简单而又强大的EL规则文本即可让你的组件快速组成一条业务链。
- 即时调整你的业务 :LiteFlow赋予你的系统即时调整业务的能力,即时改变规则,既能够热刷新你整个的业务链。并且过程是完全平滑的。甚至于你可以通过定义脚本组件来改变业务逻辑。
- 灵活的脚本语言的支持 :LiteFlow支持多种脚本语言,你可以定义自己的脚本语言节点,来和Java组件进行混编。结合热刷新,线上业务不用发布秒改逻辑。
复杂流程假设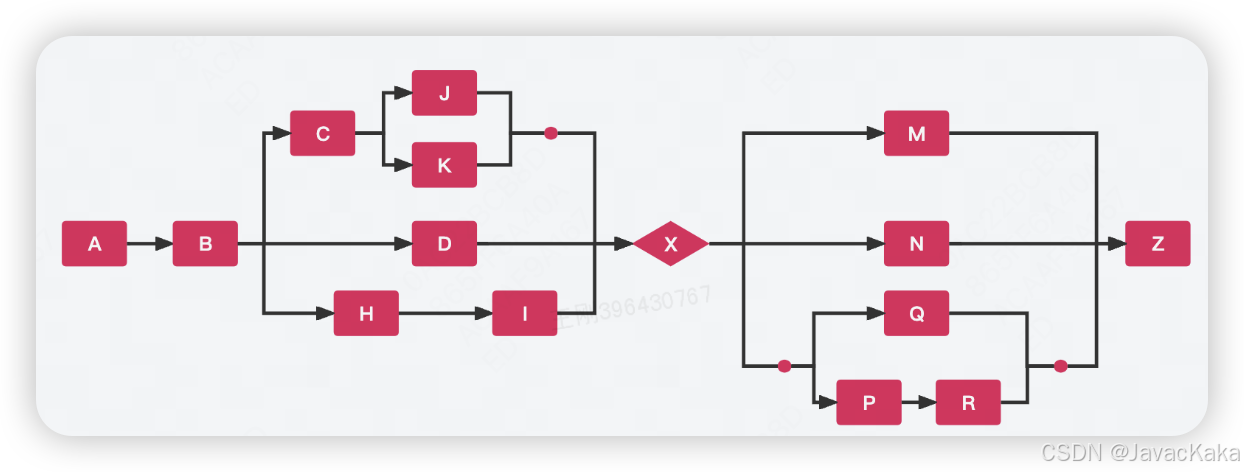
2.2 不适用场景
- 以角色驱动为主的流程轮转。类似于审批流这种。
- 多系统之间的流程编排。LiteFlow是一个规则引擎,侧重于逻辑编排,跨系统之间属于RPC调用,参数很难统一化,很难落地实施。
小结 : 主要区别于流程引擎,不适用于跨系统和角色驱动流程; ListFlow更像是无状态流程编排
3 LiteFlow核心组件介绍
图就暂时忽略了;可以参考链接 https://liteflow.cc/ 查阅架构图哈
4 【HOW】LiteFlow使用
4.1 组件定义
4.1.1 定义普通组件
普通组件是LiteFlow里执行业务的最小单元,分为继承式和声明式两种形态,其中继承式推荐绝大多数应用,而声明式的组件可以继承你自己业务的类,来完成需要抽象的场景。
// 继承方式
@LiteflowComponent(id = "a", name = "组件名A")
public class ACmp extends NodeComponent {@Overridepublic void process() {//do your business}//更多覆盖的方法请参照官方文档
}
// 声明方式
@LiteflowComponent(id = "a", name = "组件名A")
@LiteflowCmpDefine
public class ACmp{@LiteflowMethod(LiteFlowMethodEnum.PROCESS)public void process(NodeComponent bindCmp) {//do your business}//更多覆盖的方法请参照官方文档
}
4.1.2 定义排他组件
选择组件相当于排他网关,根据选择组件里返回的结果来路由到其他的组件/链路/表达式在LiteFlow里,定义一个选择组件也相当简单。
// 继承
@Component("e")
public class ESwitchCmp extends NodeSwitchComponent {@Overridepublic String processSwitch() throws Exception {return "d";}//更多覆盖的方法请参照官方文档
}// 声明
@Component("e")
@LiteflowSwitchCmpDefine
public class ESwitchCmp{@LiteflowMethod(LiteFlowMethodEnum.PROCESS_SWITCH)public String processSwitch(NodeComponent bindCmp) throws Exception {return "g";}//更多覆盖的方法请参照官方文档
}
4.1.3 定义条件组件
条件组件相当于排他网关的另一个变种,结果只有真或者假,根据真假结果来路由到其他的组件/链路/表达式。
在LiteFlow里,定义一个条件组件也相当简单。
//
@Component("e")
public class ESwitchCmp extends NodeIfComponent {@Overridepublic boolean processIf() throws Exception {return true;}//更多覆盖的方法请参照官方文档
}//
@Component("e")
@LiteflowIfCmpDefine
public class EIfCmp{@LiteflowMethod(LiteFlowMethodEnum.PROCESS_IF)public boolean processIf(NodeComponent bindCmp) throws Exception {return true;}//更多覆盖的方法请参照官方文档
}
4.2 规则DSL介绍
LiteFlow拥有很简单的DSL规则引擎,只需要掌握简单的几个关键字即可编排出极为复杂的结构。
LiteFlow的DSL底层用的是EL表达式引擎,在此基础上进行封装成为了DSL规则表达式语法。
根据不同的场景,一共分为4种表达式类型。所有的语法关键字加一起只有15个关键字,可以搭配出超乎想象的复杂流程。
// 串行 THEN 举例 a->b->c->d依次执行
<flow><chain name="chain1">THEN(a, b, c, d);</chain>
</flow>
// 并行 WHEN 举例 a执行后,bcd并行执行
<flow><chain name="chain1">THEN(a,WHEN(b, c, d));</chain>
</flow>
// 选择SWITCH 举例 以下表达式代表经过选择组件a的执行后,路由到b,c,d中的一个组件
<flow><chain name="chain1">SWITCH(a).to(b, c, d);</chain>
</flow>
5 【EXAMPLE】实践的思考
具体案例暂时没分享;
LiteFlow 还拥有自己的IDEA插件LiteFlowX,通过该插件能支持规则文件的智能提示、语法高亮、组件与规则文件之间的跳转及LiteFlow工具箱等功能,强烈建议大家安装下
安装好LiteFlowX插件后,我们代码中所定义的组件和规则文件都会显示特定的图标;
当我们编辑规则文件时,会提示我们已经定义好的组件,并支持从规则文件中跳转到组件;
还支持从右侧打开工具箱,快捷查看组件和规则文件。
6 思考:他山之石
简单粗看了一下LiteFlow的相关源代码,代码风格清晰,注释清晰,从中确实可以看到一些优秀设计的点,可以引入自己项目中,包括但不限于架构思想(战略层)和设计模式(战术层)
6.1 数据隔离
使用ThreadLocal进行线程隔离,数据总线(Dbus)维护上下文SlotMap,保证线程之间数据互不干扰
数据隔离机制分析:DataBus类实现:
使用ConcurrentHashMap<Integer, Slot> SLOTS来存储Slot对象。
使用ConcurrentLinkedQueue QUEUE来管理可用的Slot索引。Slot分配机制:
offerSlotByClass和offerSlotByBean方法用于创建新的Slot。
offerIndex方法从QUEUE中获取可用的索引,并将新创建的Slot存储到SLOTS中。线程隔离实现:
每个线程执行流程时,会获得一个唯一的Slot索引。
线程使用这个索引来访问和操作自己的Slot,不会干扰其他线程的数据。优势:
高并发性能:使用ConcurrentHashMap和ConcurrentLinkedQueue提高了并发性能。
动态扩容:当QUEUE为空时,DataBus会自动扩容,增加可用的Slot数量。
灵活性:支持通过Class和Bean两种方式创建Slot,适应不同的使用场景。
资源管理:提供了Slot的分配和释放机制,有效管理资源。
线程安全:通过索引机制和并发集合,确保了多线程环境下的数据隔离。可改善点:
内存占用:当并发量大时,可能会占用较多内存。可以考虑实现一种更高效的内存管理策略。
扩容策略:当前扩容策略是固定的(增加75%)。可以考虑实现一种更灵活的扩容策略,根据实际使用情况动态调整。
错误处理:当Slot分配失败时,直接返回-1。可以考虑提供更详细的错误信息或异常处理机制。
监控和统计:可以添加更多的监控指标,如Slot使用率、平均占用时间等,以便于系统调优。
清理机制:可以考虑添加一个定期清理未释放Slot的机制,防止长时间运行导致的资源泄露。总结:
LiteFlow的数据隔离机制通过DataBus和Slot的组合使用,实现了高效的线程隔离。这种设计在保证线程安全的同时,也提供了良好的性能和灵活性。整体上这是一个设计良好的数据隔离方案。
6.2 数据总线
DataBus类虽然没有直接使用传统的策略模式,但它的设计思想与策略模式有相似之处:
DataBus作为一个全局的上下文管理器,负责Slot的分配和管理。
不同的Slot创建策略(offerSlotByClass和offerSlotByBean)可以看作是不同的"策略"。
offerIndex方法可以看作是策略的执行方法。代码分析:
offerSlotByClass和offerSlotByBean方法提供了两种不同的Slot创建策略。
offerIndex方法实现了Slot的分配逻辑,包括动态扩容。
使用ConcurrentHashMap和ConcurrentLinkedQueue来管理Slot和可用索引。优势:
灵活性:支持多种Slot创建方式,可以根据需求选择合适的策略。
高并发支持:使用并发集合类,提高了多线程环境下的性能。
动态扩容:自动扩容机制确保了系统可以处理大量并发请求。
资源管理:提供了Slot的分配和释放机制,有效管理系统资源。
解耦:将Slot的创建和管理逻辑与业务逻辑分离。可改善点:
策略抽象:可以考虑将Slot创建策略抽象为接口,使策略的选择更加灵活。
配置化:可以通过配置文件来选择Slot创建策略,增加系统的可配置性。
性能优化:考虑使用更高效的数据结构或算法来管理Slot,特别是在高并发场景下。
监控和统计:添加更多的监控指标,如Slot使用率、分配时间等,以便于系统调优。
错误处理:增强错误处理机制,提供更详细的错误信息和异常处理。
清理机制:实现定期清理未释放Slot的机制,防止资源泄露。部分思考点:
引入Strategy接口:定义一个SlotCreationStrategy接口,让不同的Slot创建方式实现这个接口。
使用工厂模式:创建一个SlotFactory,根据不同的策略创建Slot。
增加监控:实现一个SlotMonitor类,用于监控Slot的使用情况。
扩容策略:实现一个更智能的扩容策略,根据系统负载动态调整。
增加缓存机制:对频繁使用的Slot实现缓存,提高性能。总结:
LiteFlow的DataBus实现了一个灵活且高效的数据隔离机制。虽然没有直接使用传统的策略模式,但其设计思想与策略模式相似,提供了良好的扩展性和灵活性。
6.3 设计模式的应用
1-抽象工厂(parse实现)
抽象产品:FlowParser接口
public interface FlowParser { void parseMain(List<String> pathList) throws Exception;
void parse(List<String> contentList) throws Exception; }具体产品:BaseJsonFlowParser, BaseXmlFlowParser, BaseYmlFlowParser
这些类继承自FlowParser,实现了特定格式的解析逻辑。抽象工厂:FlowParserFactory接口
public interface FlowParserFactory {
BaseJsonFlowParser createJsonELParser(String path);
BaseXmlFlowParser createXmlELParser(String path);
BaseYmlFlowParser createYmlELParser(String path);
}具体工厂:LocalParserFactory和ClassParserFactory
这些类实现了FlowParserFactory接口,负责创建具体的解析器实例。工厂提供者:FlowParserProvider
public class FlowParserProvider {
private static final FlowParserFactory LOCAL_PARSER_FACTORY = new LocalParserFactory();
private static final FlowParserFactory CLASS_PARSER_FACTORY = new ClassParserFactory();
public static FlowParser lookup(String path) throws Exception { // 实现逻辑 } }优势:
清晰的接口定义:FlowParserFactory接口明确定义了创建不同类型解析器的方法。
高度的灵活性:支持多种配置格式(JSON, XML, YAML)和来源(本地文件,类配置)。
良好的可扩展性:易于添加新的解析器类型,只需实现相应的工厂方法。
强大的解耦:使用工厂方法模式,将解析器的创建与使用分离。
统一的访问点:通过FlowParserProvider提供了一个统一的入口来获取适当的解析器。
类型安全:每种解析器类型都有专门的创建方法,减少了类型转换错误。改善点:
泛型使用:可以考虑在FlowParserFactory接口中使用泛型,以提供更好的类型安全性。
public interface FlowParserFactory { <T extends FlowParser> T createParser(String path, Class<T> parserType); }配置驱动:可以将解析器类型和对应的工厂方法配置化,减少硬编码。
private static final Map<String, BiFunction<FlowParserFactory, String, FlowParser>> PARSER_CREATORS = new HashMap<>(); static { PARSER_CREATORS.put("json", FlowParserFactory::createJsonELParser); PARSER_CREATORS.put("xml", FlowParserFactory::createXmlELParser); PARSER_CREATORS.put("yml", FlowParserFactory::createYmlELParser); }错误处理增强:在FlowParserProvider中添加更详细的错误处理和日志记录。
try { // 解析器查找逻辑 } catch (Exception e) { LOG.error("Failed to create parser for path: {}", path, e); throw new ParserCreationException("Unable to create parser", e); }懒加载:考虑使用懒加载方式创建解析器,以提高性能。
private static class LazyHolder { static final FlowParserFactory INSTANCE = new LocalParserFactory(); } public static FlowParserFactory getInstance() { return LazyHolder.INSTANCE; }单元测试友好:提供更多的钩子或接口,便于单元测试和模拟不同的解析场景。
public interface TestableFlowParserFactory extends FlowParserFactory { void setMockParser(FlowParser mockParser); }性能优化:考虑缓存常用的解析器实例,避免重复创建。
private static final Map<String, FlowParser> parserCache = new ConcurrentHashMap<>();总结:
LiteFlow的解析器实现采用了标准的抽象工厂模式,通过FlowParserFactory接口和具体实现类提供了创建不同类型解析器的灵活机制。FlowParserProvider作为中心控制点,管理不同类型的解析器创建。这种设计提供了excellent的灵活性、可扩展性和可维护性。
2-策略
策略模式分析:
抽象策略:NodeExecutor
public abstract class NodeExecutor { public void execute(NodeComponent instance) throws Exception { ... } protected void retry(NodeComponent instance, int currentRetryCount) throws Exception { ... } }具体策略:
可以有NodeExecutor的子类来实现不同的执行策略。策略的使用:
NodeExecutor类定义了执行节点的通用逻辑,包括重试机制。具体的执行策略可以通过继承NodeExecutor并重写retry方法来实现。实现分析:
通用执行逻辑:
execute方法定义了节点执行的通用流程,包括重试逻辑。
可定制的重试策略:
retry方法是protected的,允许子类重写以实现自定义的重试逻辑。异常处理:
execute方法包含了对不同类型异常的处理逻辑,特别是对ChainEndException的特殊处理。重试次数和异常类型的配置:
通过NodeComponent的getRetryCount和getRetryForExceptions方法获取重试配置。优点:
灵活性:允许不同的节点执行器实现不同的执行策略。
可扩展性:易于添加新的执行策略,只需创建NodeExecutor的新子类。
可配置性:重试次数和异常类型可以根据需要进行配置。
统一的错误处理:在基类中统一处理了异常,简化了子类的实现。改善点:
策略选择机制:
可以添加一个工厂类或注册机制,用于在运行时选择适当的NodeExecutor实现。
public class NodeExecutorFactory { private Map<String, NodeExecutor> executors = new HashMap<>(); public void registerExecutor(String type, NodeExecutor executor) { executors.put(type, executor); } public NodeExecutor getExecutor(String type) { return executors.get(type); } }参数化策略:
可以将重试逻辑的参数(如重试间隔)作为策略的一部分,而不是硬编码在NodeComponent中。
public abstract class NodeExecutor { protected int retryInterval; public NodeExecutor(int retryInterval) { this.retryInterval = retryInterval; } // ... 其他方法 ... }上下文对象:
引入一个上下文对象,包含执行过程中需要的所有信息,使策略更加灵活。
public class ExecutionContext { private NodeComponent instance; private int retryCount; private List<Class<? extends Exception>> retryForExceptions; // ... getters and setters ... } public abstract class NodeExecutor { public void execute(ExecutionContext context) throws Exception { // ... 使用context中的信息执行 ... } }日志增强:
可以在基类中添加更详细的日志记录,以便于调试和监控。性能优化:
考虑使用缓存机制来存储已创建的NodeExecutor实例,避免频繁创建对象。总结:
LiteFlow中的NodeExecutor类策略模式的基本实现。通过允许子类重写特定方法,来定制节点的执行策略。通过一些改进,如添加策略选择机制、参数化策略、引入上下文对象等,可以进一步增强其灵活性和可用性
3-模版
XmlFlowELParser类继承自BaseXmlFlowParser,并实现了parseOneChain方法。这是模板模式的典型应用,其中BaseXmlFlowParser定义了算法的骨架,而XmlFlowELParser提供了具体的实现。LiteFlow中模板模式的实现:模板方法(在BaseXmlFlowParser中):
@Override public void parse(List<String> contentList) throws Exception { // ... 前置处理逻辑 ... ParserHelper.parseNodeDocument(documentList); ParserHelper.parseChainDocument(documentList, CHAIN_NAME_SET, this::parseOneChain); }
这个方法定义了解析流程的骨架。抽象方法(在BaseXmlFlowParser中):
public abstract void parseOneChain(Element chain);
这是一个抽象方法,子类必须实现它来提供具体的解析逻辑。具体实现(在XmlFlowELParser中):
@Override public void parseOneChain(Element e) { ParserHelper.parseOneChainEl(e); }
XmlFlowELParser类提供了parseOneChain方法的具体实现
4-建造者
LiteFlowChainELBuilder类是一个典型的建造者模式实现。它提供了一系列方法来设置Chain的各个属性,最后通过build()方法完成Chain的构建。这种实现允许用户以流式接口的方式创建复杂的Chain对象。LiteFlow中的建造者模式:建造者类:LiteFlowChainELBuilder
public class LiteFlowChainELBuilder { private Chain chain; private Executable route; private final List<Condition> conditionList; // 构造方法和其他成员... }建造方法:
public LiteFlowChainELBuilder setChainId(String chainId) { ... } public LiteFlowChainELBuilder setRoute(String routeEl) { ... } public LiteFlowChainELBuilder setEL(String elStr) { ... } public LiteFlowChainELBuilder setNamespace(String nameSpace) { ... } public LiteFlowChainELBuilder setThreadPoolExecutorClass(String threadPoolExecutorClass) { ... }构建方法:
public void build() { this.chain.setRouteItem(this.route); this.chain.setConditionList(this.conditionList); FlowBus.addChain(this.chain); }静态创建方法:
public static LiteFlowChainELBuilder createChain() { return new LiteFlowChainELBuilder(); }
写在最后 : 码字不易,如果认为不错或者对您有帮忙,希望读者动动小手,点赞或者关注哈,多谢




