目录
1.前言
2.RNN
2.1RNN Cell
2.2RNN
3.例子
3.1 RNN Cell实现
3.2 RNN 实现
4.独热向量的缺点
5. LSTM
1.前言
全连接神经网络也叫做Dense神经网络,利用线性层对特征进行变换
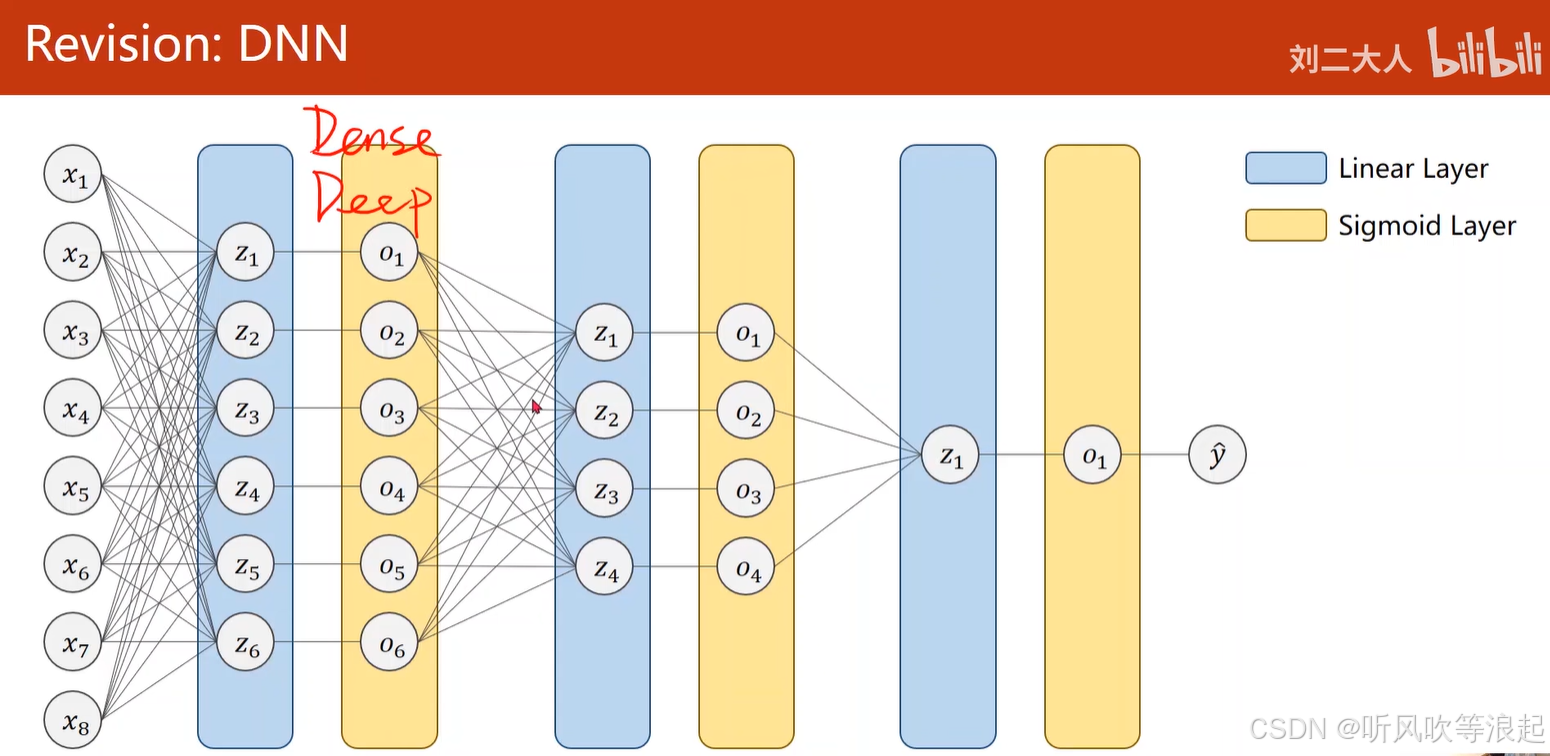
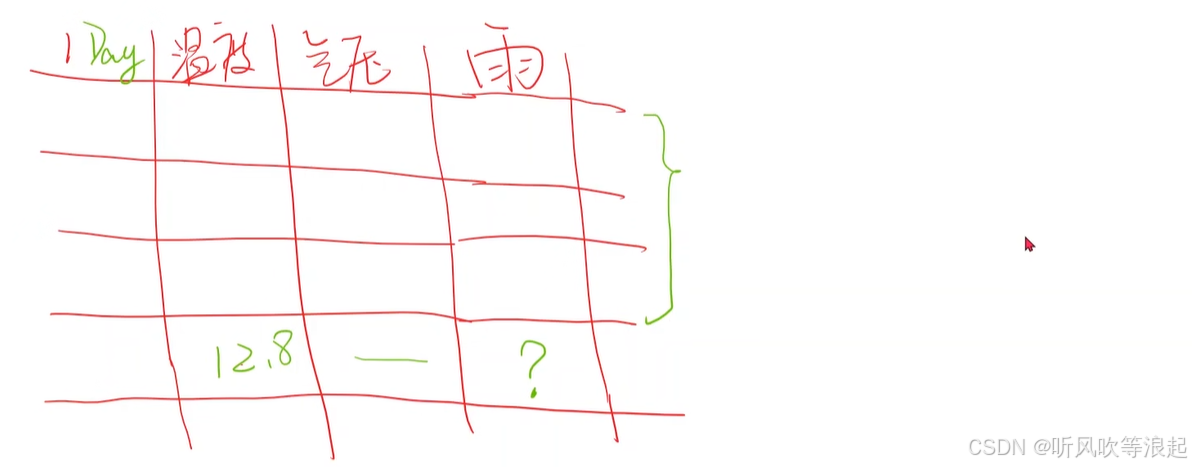
例如,如果想要做预测是否下雨的系统,传统的DNN都是利用当天的数据特征进行预测
但这样其实是没有用的,因为预测都是提前的,换句话说,我们需要利用前面的数据预测下一次的天气
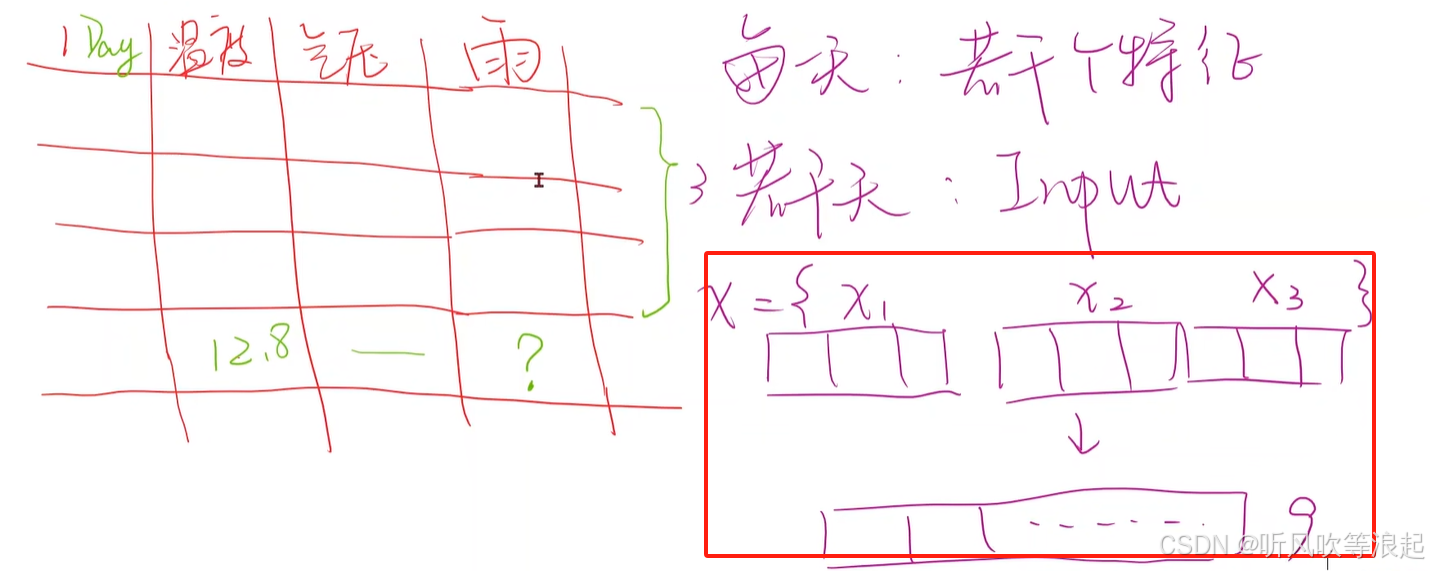
那么想要预测第四天的天气,需要前面三天的输入作为特征,假设每天都有三个特征的话,那么输入就是9个
如果说利用DNN网络的话,需要把三天的特征展平、拼接成9维度的
这样其实计算是很复杂的,因为DNN的网络参数非常多。因为CNN使用了权重共享
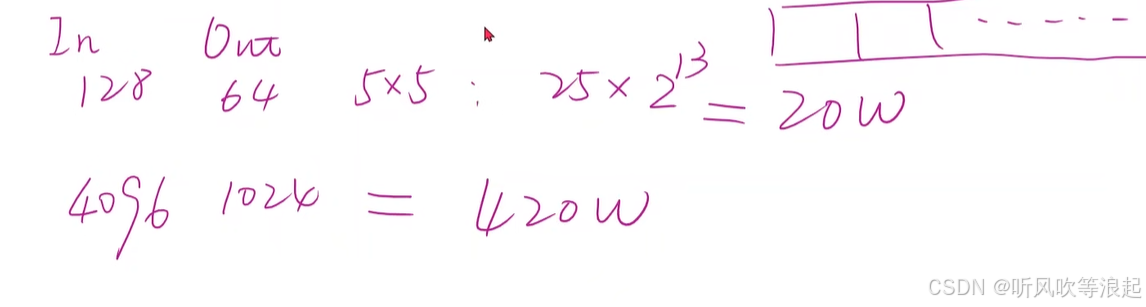
RNN专门用来处理这种带有序列的数据,使用了权重共享
2.RNN
序列数据,后面的数据是和前面的数据相关的,例如视频、自然语言
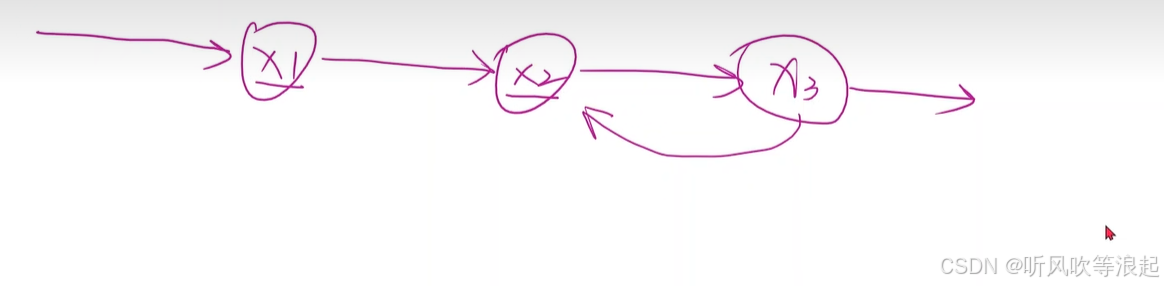
RNN专门用来处理这种时间序列的数据,使用了权重共享
2.1RNN Cell
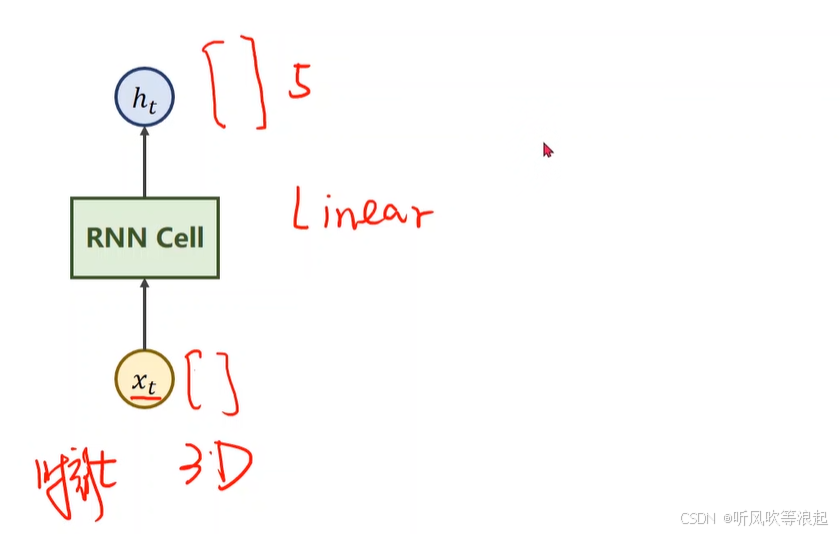
RNN Cell把一个维度映射到另一个维度,本质就是线性层
假如输入是三维的,输出是五维的,其实就是一个映射
RNN cell,每一个输入xi都是一个特征向量
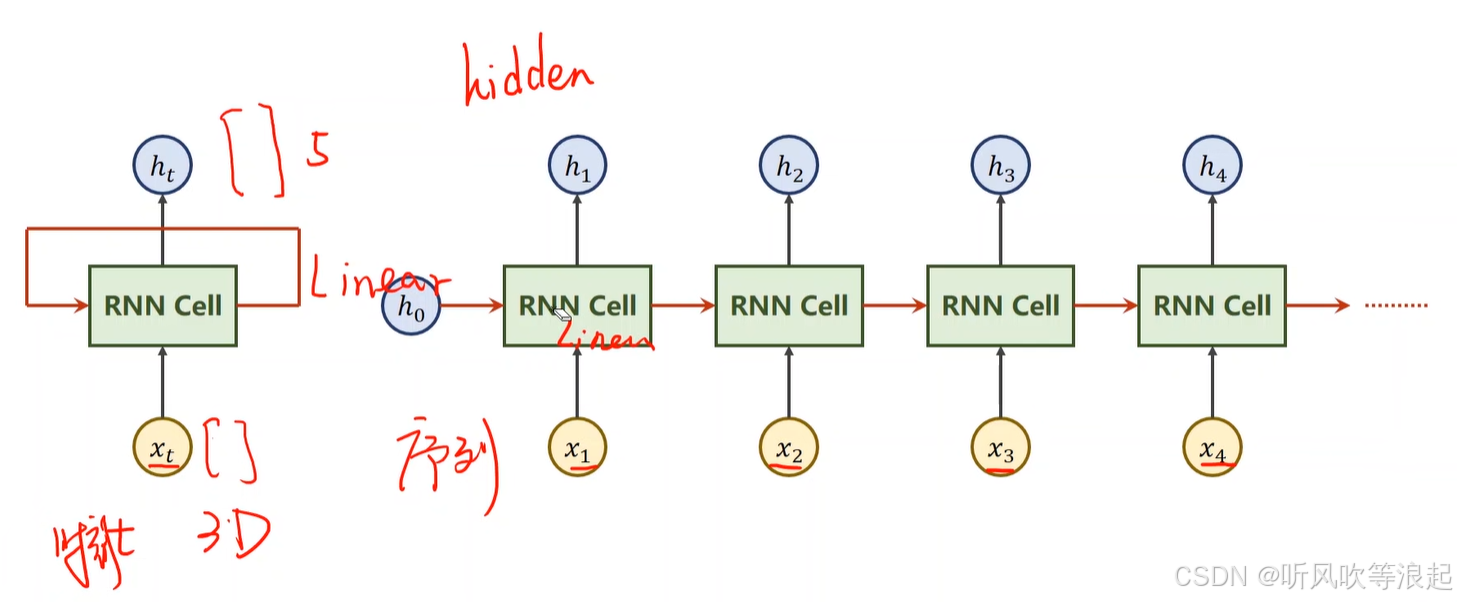
对于h1,x1是输入特征的向量,h0代表是先验知识(没有的话,设置和h1、h2一样的维度就行)
其输出的h1作为h2的先验知识,输入是x2的特征向量
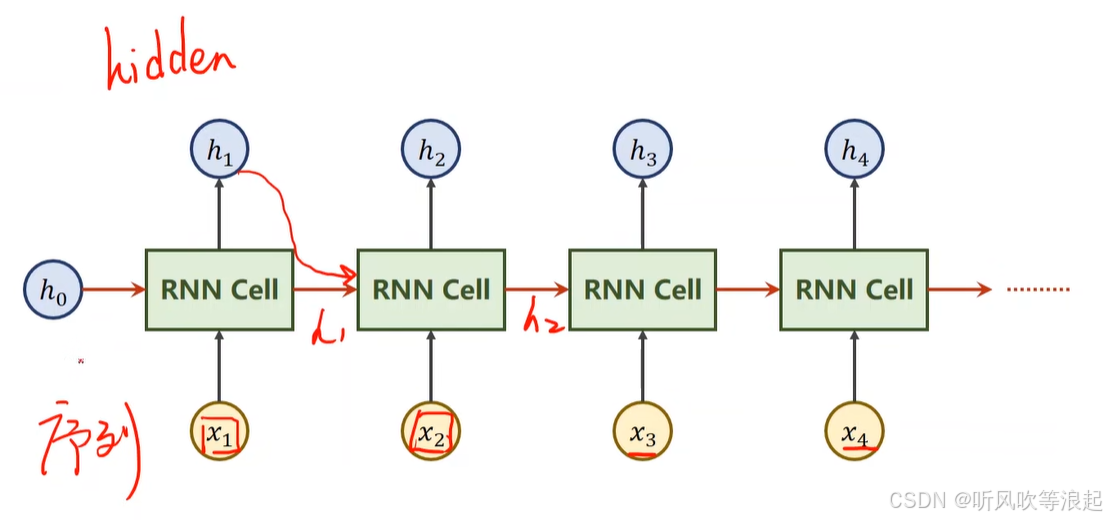
这里的RNN Cell是重复使用的,是同一层,只不过是循环计算,形成权重共享
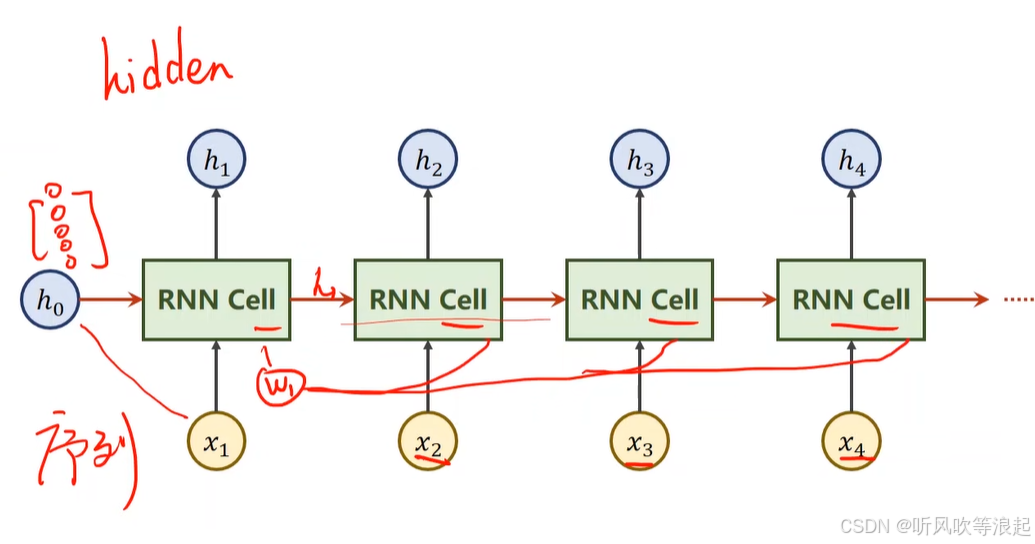
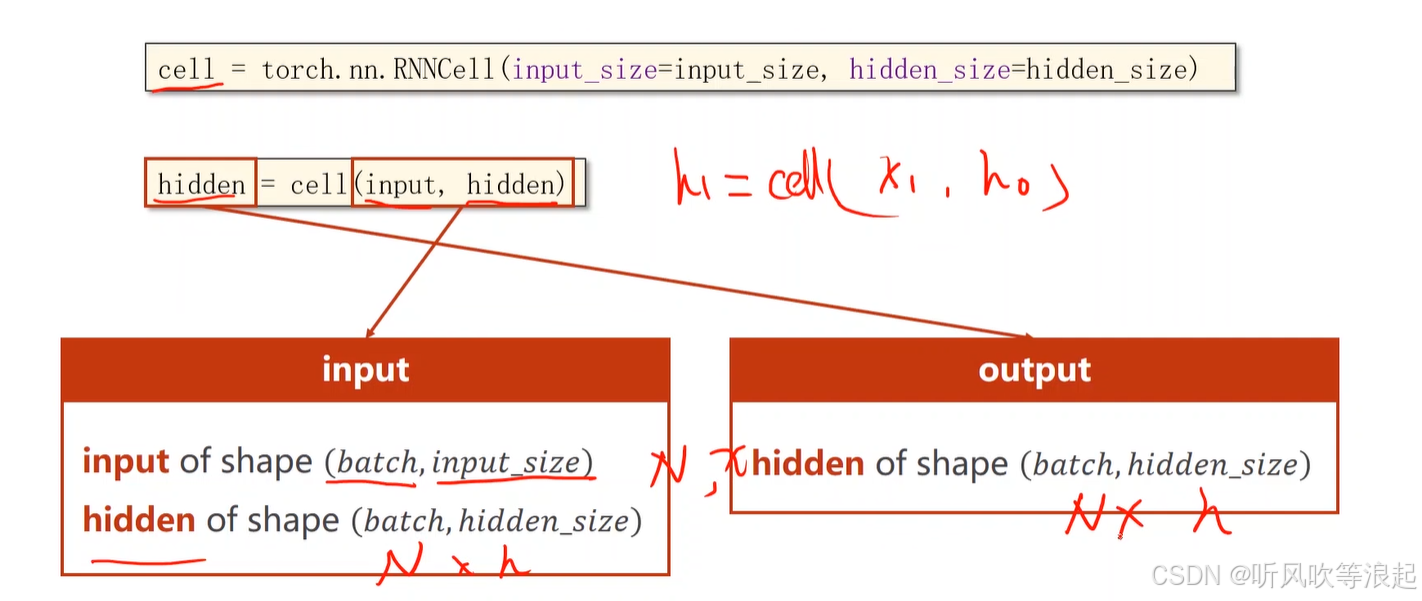
计算过程:
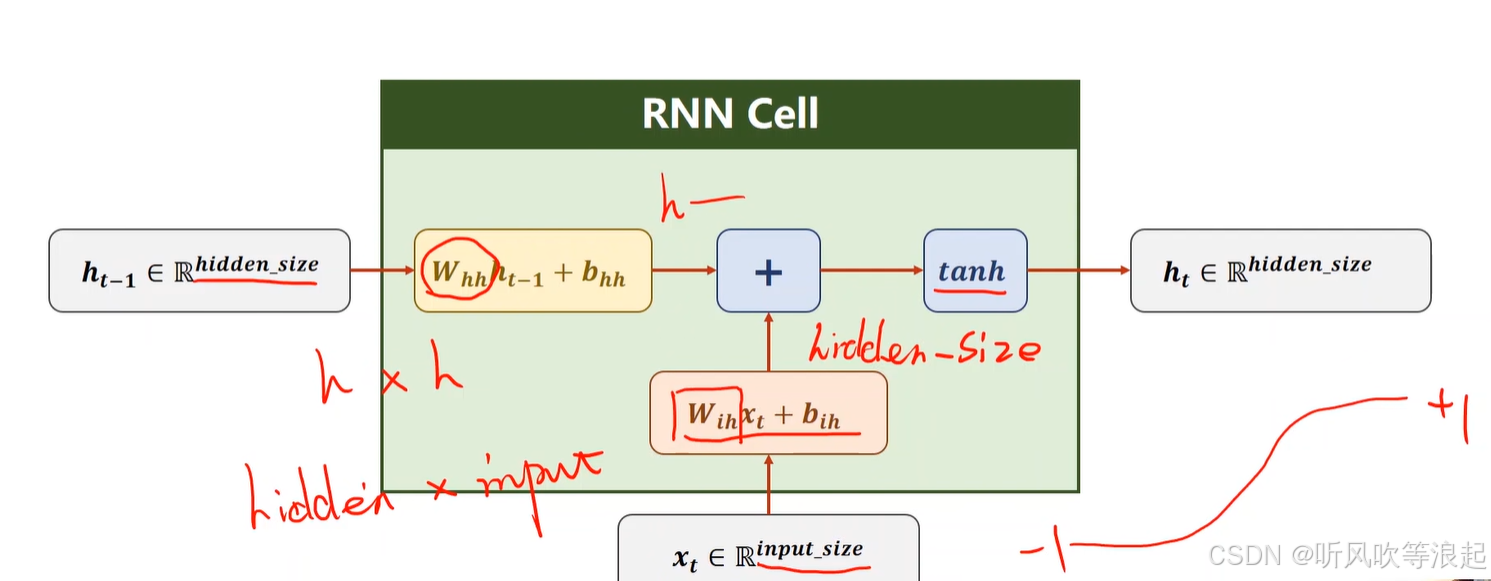
torch中计算:两个输入,一个是输入的特征向量,还一个是先验知识(当前时刻和上个时刻相关)
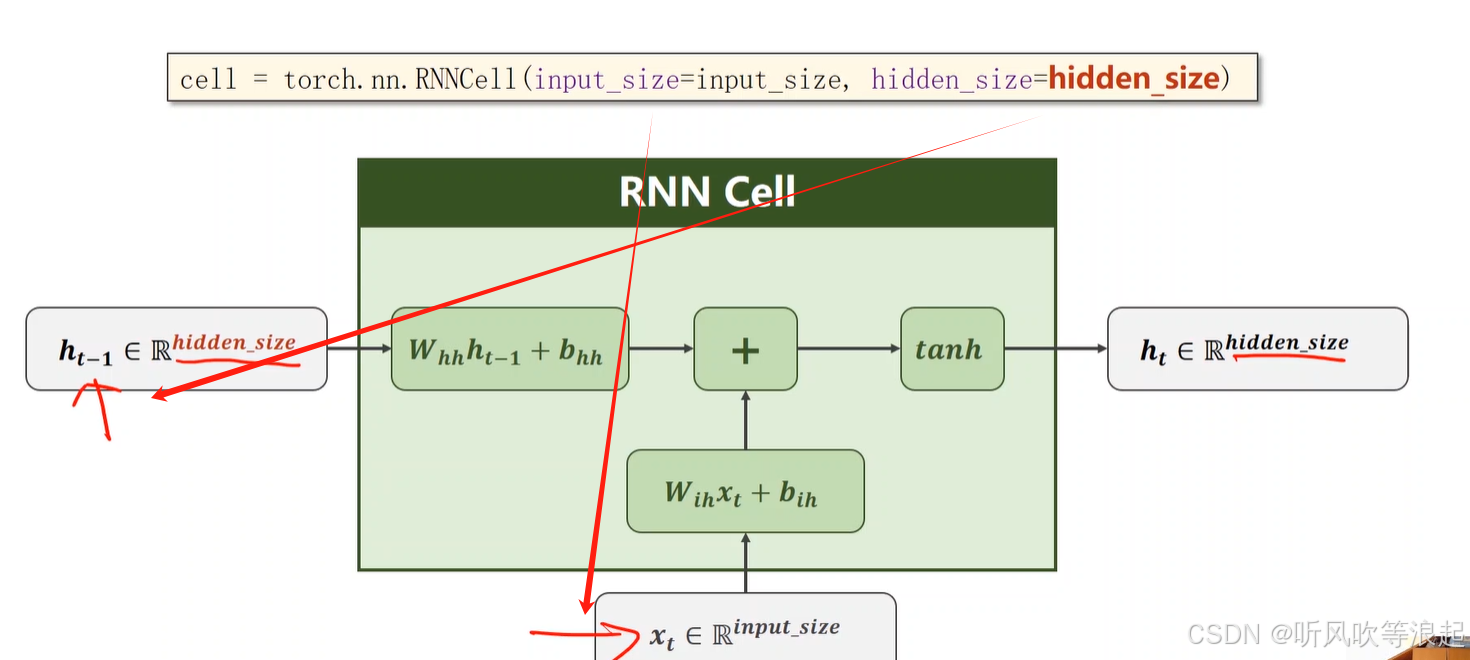
输出的维度和隐层的维度一样,因为输出是下一个序列的先验知识啊,或者说是下一个序列的隐层输入

实例:
import torchbatchSize = 1
seqLen = 3
inputSize = 4
hiddenSize = 2cell = torch.nn.RNNCell(input_size=inputSize,hidden_size=hiddenSize)dataset = torch.randn(seqLen,batchSize,inputSize)
hidden = torch.zeros(batchSize,hiddenSize)for idx,input in enumerate(dataset):print('='*20,idx,'='*20)print('input size:',input.shape) # input size: torch.Size([1, 4])hidden = cell(input,hidden)print('output size:',hidden.shape) # output size: torch.Size([1, 2])print(hidden) # tensor([[ 0.6926, -0.5587]], grad_fn=<TanhBackward0>)
==================== 0 ====================
input size: torch.Size([1, 4])
output size: torch.Size([1, 2])
tensor([[ 0.6926, -0.5587]], grad_fn=<TanhBackward0>)
==================== 1 ====================
input size: torch.Size([1, 4])
output size: torch.Size([1, 2])
tensor([[-0.5971, 0.5054]], grad_fn=<TanhBackward0>)
==================== 2 ====================
input size: torch.Size([1, 4])
output size: torch.Size([1, 2])
tensor([[0.3833, 0.1948]], grad_fn=<TanhBackward0>)2.2RNN
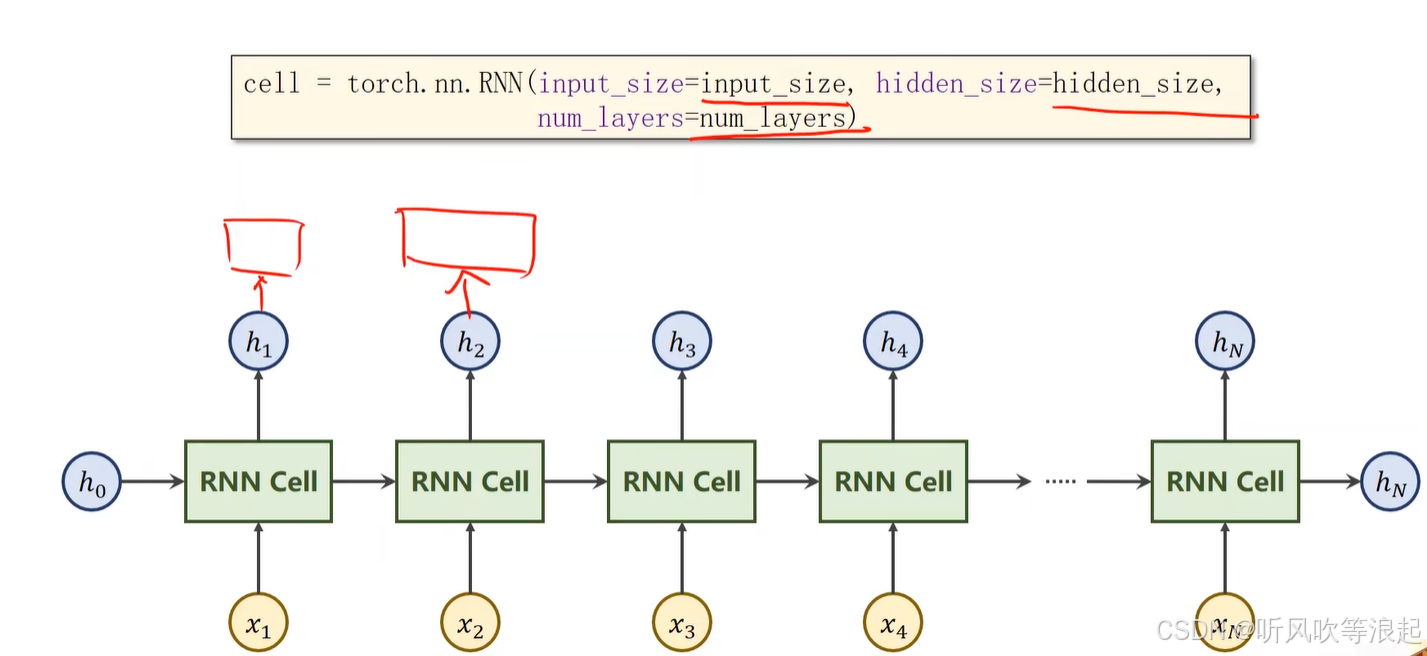
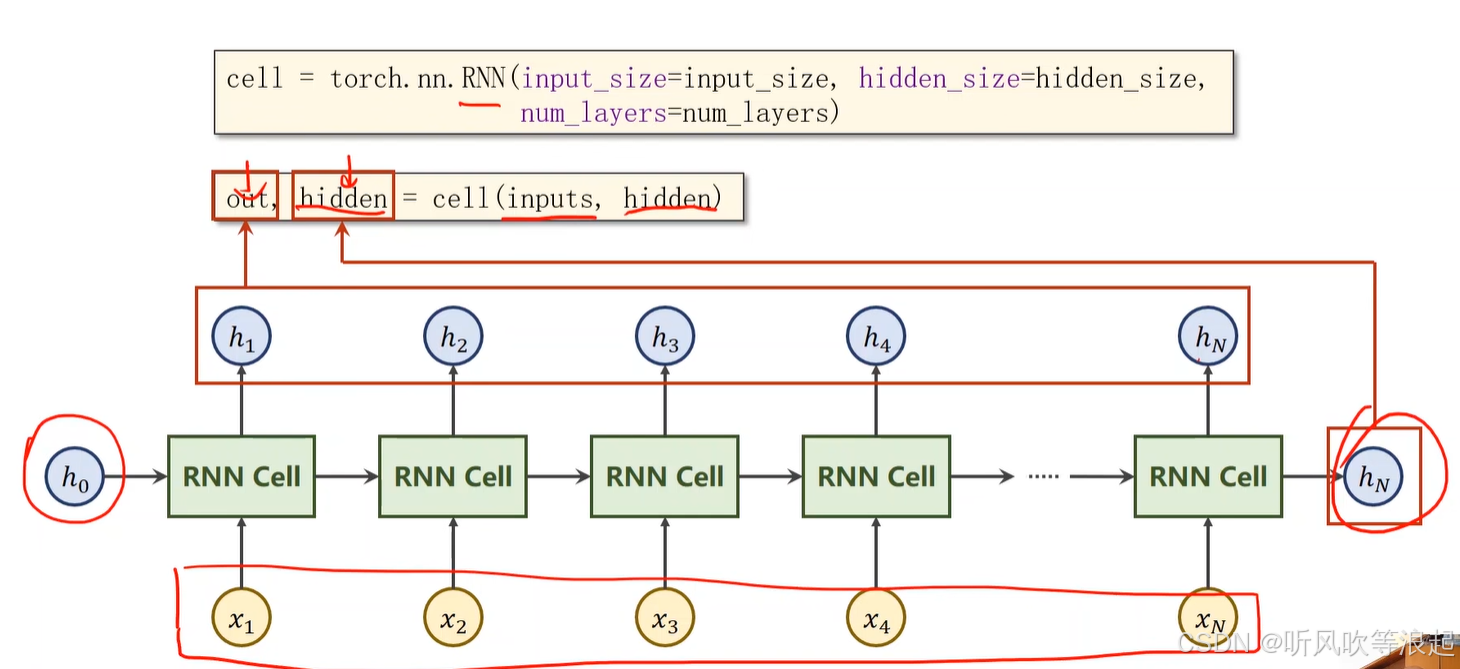
输出介绍:
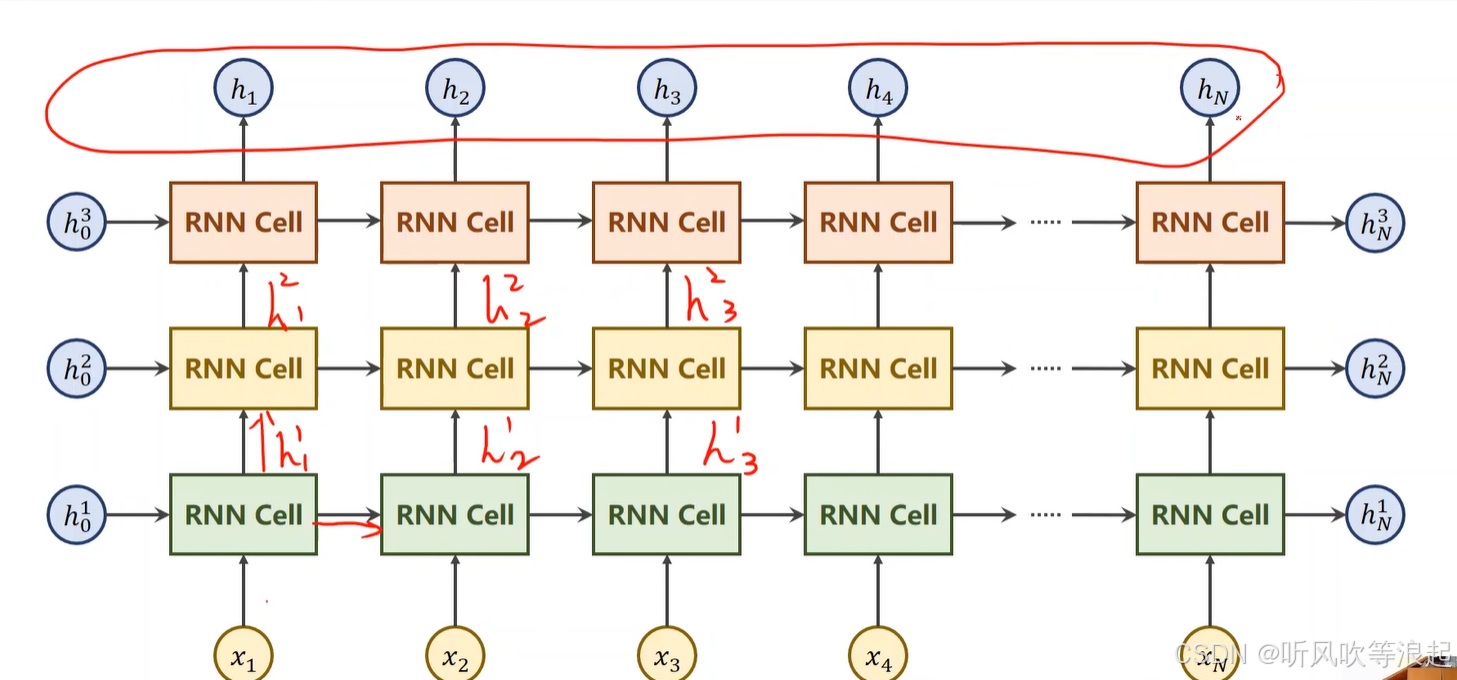
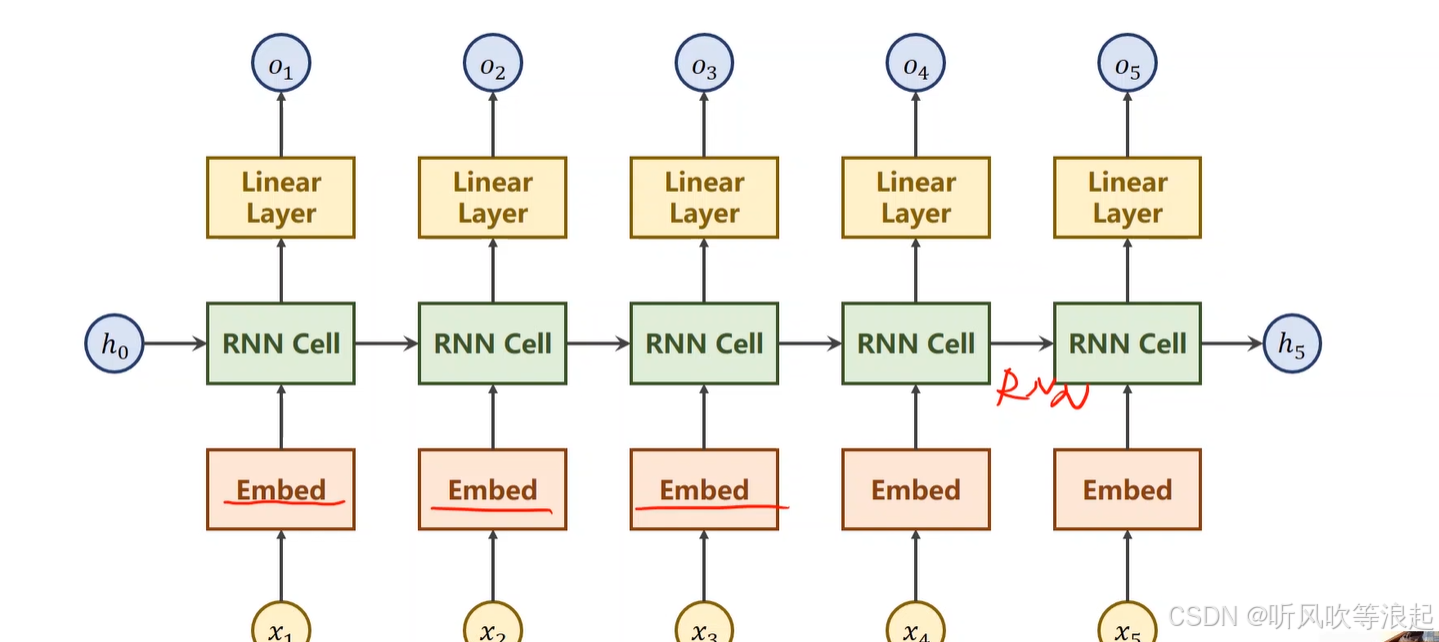
多层RNN
实例:
import torchbatchSize = 1
seqLen = 3
inputSize = 4
hiddenSize = 2
numLayers = 1cell = torch.nn.RNN(input_size=inputSize,hidden_size=hiddenSize,num_layers=numLayers)inputs = torch.randn(seqLen,batchSize,inputSize)
hidden = torch.zeros(numLayers,batchSize,hiddenSize)out,hidden = cell(inputs,hidden)print('output size:',out.shape) # output size: torch.Size([3, 1, 2])
print('output:',out)
'''
output: tensor([[[ 0.2475, 0.8597]],[[-0.2017, 0.4246]],[[ 0.1378, 0.8480]]], grad_fn=<StackBackward0>)
'''
print('hidden size:',hidden.shape) # hidden size: torch.Size([1, 1, 2])
print('hidden:',hidden) # hidden: tensor([[[0.1378, 0.8480]]], grad_fn=<StackBackward0>)
3.例子
把hello的序列变成ohlol的序列
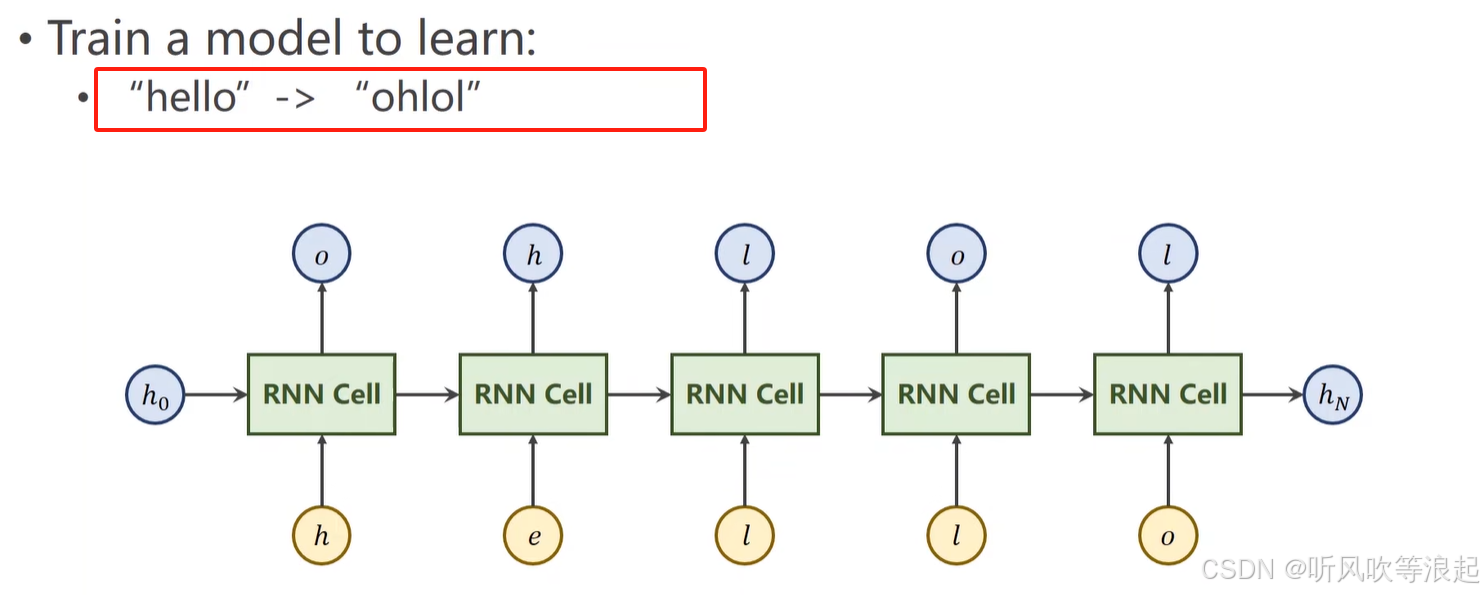
首先把字符向量化,首先进行词嵌入(编码),然后转为向量,向量的长度和字典一样
这个独热向量才能送到RNN里面
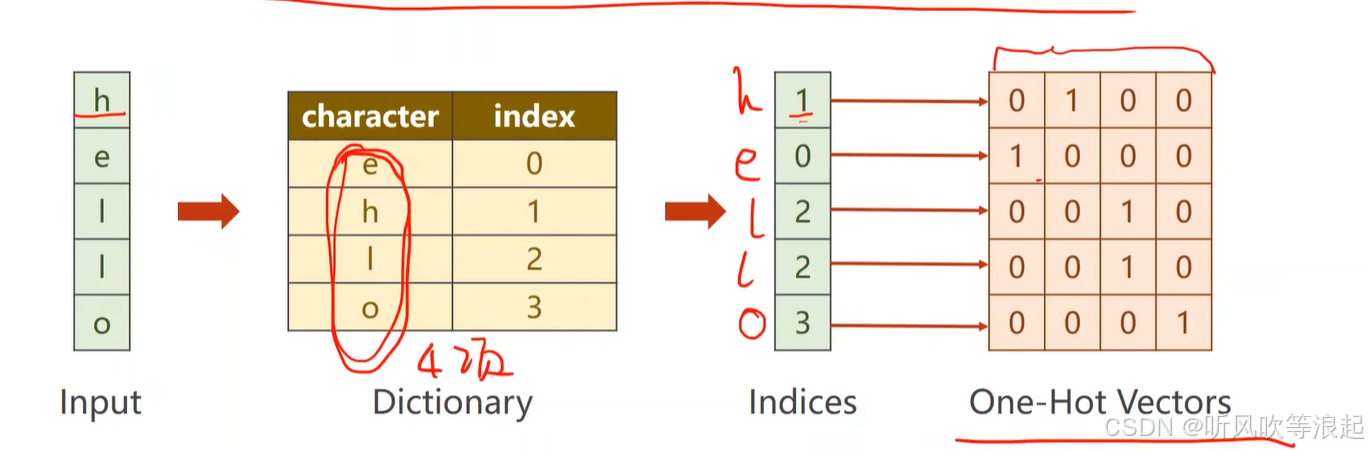
这里是5个序列,每个序列的输入size = 4
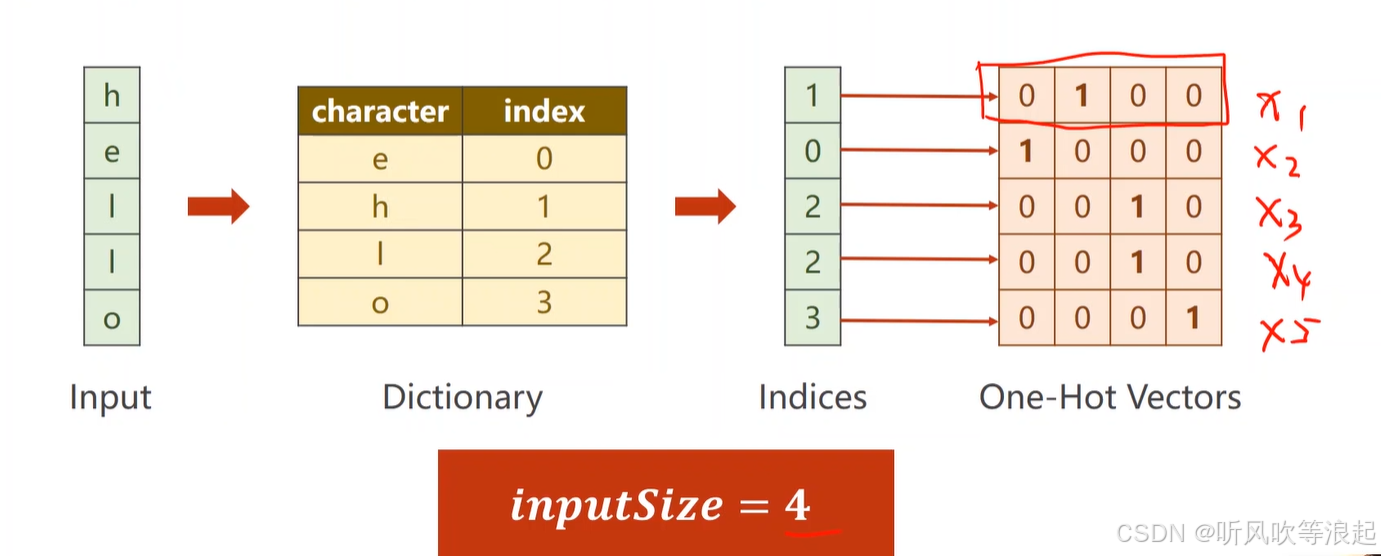
因此,对于网络,每个RNN Cell,输入size是4,输出是4的概率,经过softmax最大值就能知道这个cell的预测是h、e、l、o的哪一个
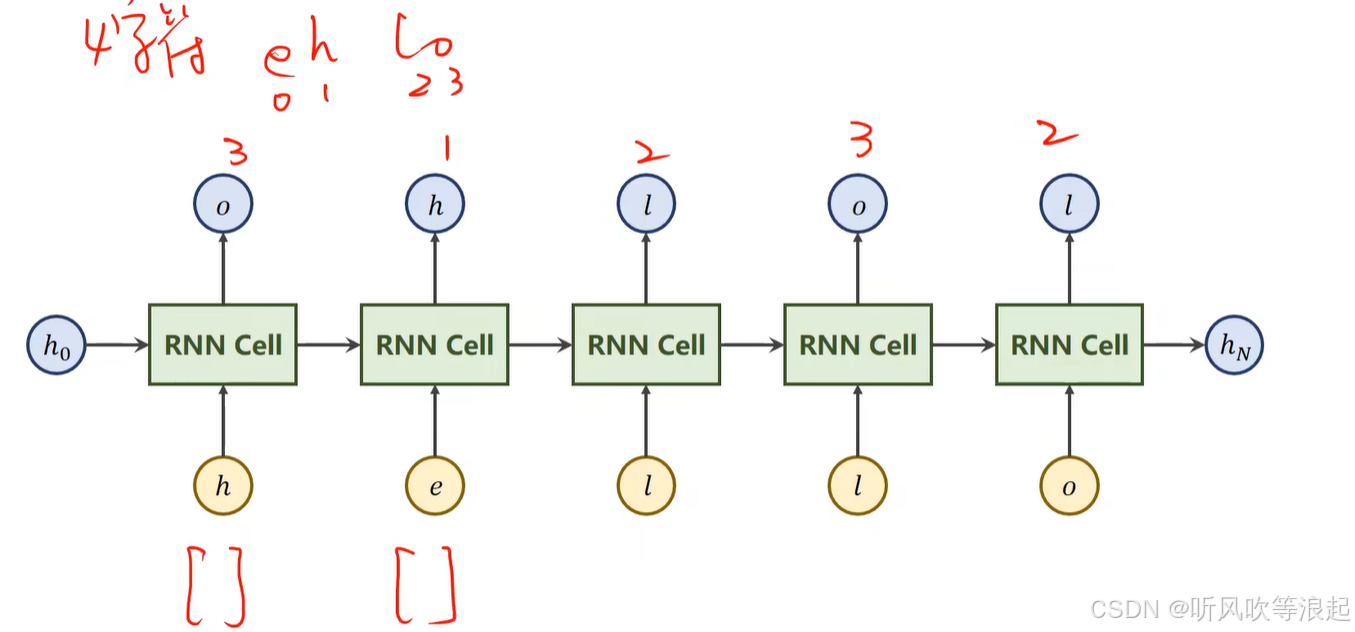
如下:
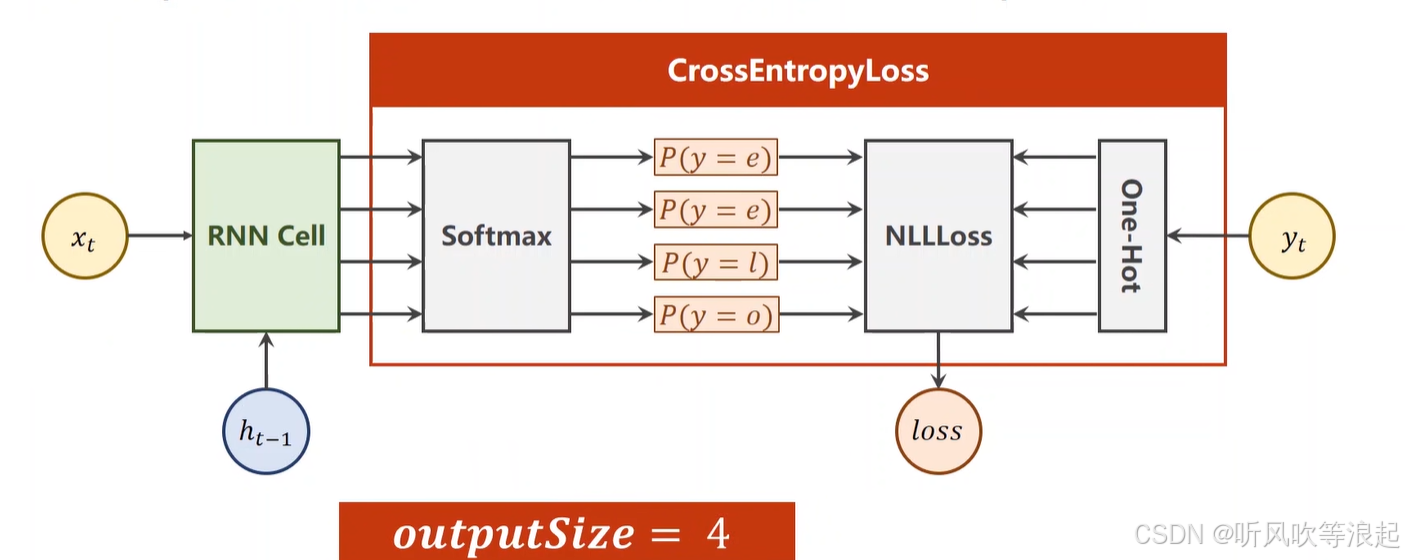
3.1 RNN Cell实现
完整代码:
import torchinput_size = 4
hidden_size = 4
batch_size = 1idx2char = ['e','h','l','o'] # 字典
x_data = [1,0,2,2,3] # h e l l o
y_data = [3,1,2,3,2] # o h l o lone_hot_lookup = [ # 独热向量查询[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1],
]x_one_hot = [one_hot_lookup[x] for x in x_data]
# [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]inputs = torch.Tensor(x_one_hot).view(-1,batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1,1)class Model(torch.nn. Module):def __init__(self, input_size, hidden_size, batch_size):super(Model, self).__init__()self.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnncell = torch.nn.RNNCell(input_size=self.input_size,hidden_size=self.hidden_size)def forward(self, input, hidden):hidden = self.rnncell(input, hidden)return hiddendef init_hidden(self):return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.1)for epoch in range(30):loss =0optimizer.zero_grad()hidden = net.init_hidden()print('Predicted string:', end='')for input, label in zip(inputs, labels):hidden = net(input, hidden)loss += criterion(hidden, label)_,idx= hidden.max(dim=1)print(idx2char[idx.item()], end="")loss.backward()optimizer.step()print(',Epoch[%d/15]loss=%.4f' %(epoch+1, loss.item()))
如下:
Predicted string:eeeee,Epoch[1/15]loss=8.2629
Predicted string:ehlle,Epoch[2/15]loss=6.8652
Predicted string:ellll,Epoch[3/15]loss=6.1394
Predicted string:lolll,Epoch[4/15]loss=5.5051
Predicted string:ohlll,Epoch[5/15]loss=4.7259
Predicted string:ohlll,Epoch[6/15]loss=4.0233
Predicted string:ohlol,Epoch[7/15]loss=3.5085
Predicted string:ohlol,Epoch[8/15]loss=3.1282
Predicted string:ohlol,Epoch[9/15]loss=2.8488
Predicted string:ohlol,Epoch[10/15]loss=2.6822
Predicted string:ohlol,Epoch[11/15]loss=2.5589
Predicted string:ohlol,Epoch[12/15]loss=2.4280
Predicted string:ohlol,Epoch[13/15]loss=2.2983
Predicted string:ohlol,Epoch[14/15]loss=2.1925
Predicted string:ohlol,Epoch[15/15]loss=2.1124
Predicted string:ohlol,Epoch[16/15]loss=2.0471
Predicted string:ohlol,Epoch[17/15]loss=1.9908
Predicted string:ohlol,Epoch[18/15]loss=1.9429
Predicted string:ohlol,Epoch[19/15]loss=1.9041
Predicted string:ohlol,Epoch[20/15]loss=1.8745
Predicted string:ohlol,Epoch[21/15]loss=1.8529
Predicted string:ohlol,Epoch[22/15]loss=1.8377
Predicted string:ohlol,Epoch[23/15]loss=1.8268
Predicted string:ohlol,Epoch[24/15]loss=1.8182
Predicted string:ohlol,Epoch[25/15]loss=1.8102
Predicted string:ohlol,Epoch[26/15]loss=1.8022
Predicted string:ohlol,Epoch[27/15]loss=1.7939
Predicted string:ohlol,Epoch[28/15]loss=1.7859
Predicted string:ohlol,Epoch[29/15]loss=1.7785
Predicted string:ohlol,Epoch[30/15]loss=1.77203.2 RNN 实现
代码如下:
import torchinput_size = 4
hidden_size = 4
batch_size = 1
num_layers = 1
seq_len = 5idx2char = ['e','h','l','o'] # 字典
x_data = [1,0,2,2,3] # h e l l o
y_data = [3,1,2,3,2] # o h l o lone_hot_lookup = [ # 独热向量查询[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1],
]x_one_hot = [one_hot_lookup[x] for x in x_data]
# [[0, 1, 0, 0], [1, 0, 0, 0], [0, 0, 1, 0], [0, 0, 1, 0], [0, 0, 0, 1]]inputs = torch.Tensor(x_one_hot).view(seq_len,batch_size,input_size)
labels = torch.LongTensor(y_data)class Model(torch.nn. Module):def __init__(self, input_size, hidden_size, batch_size,num_layers=1):super(Model, self).__init__()self.num_layers = num_layersself.batch_size = batch_sizeself.input_size = input_sizeself.hidden_size = hidden_sizeself.rnn = torch.nn.RNN(input_size=self.input_size,hidden_size=self.hidden_size,num_layers=self.num_layers)def forward(self, input):hidden = torch.zeros(self.num_layers,self.batch_size,self.hidden_size)out,_ = self.rnn(input,hidden)return out.view(-1,self.hidden_size)def init_hidden(self):return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size,num_layers)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.05)for epoch in range(30):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted:', ''.join([idx2char[x] for x in idx]),end='')print(',Epoch[%d/30]loss=%.4f' %(epoch+1, loss.item()))
如下:
Predicted: olohl,Epoch[1/30]loss=1.2335
Predicted: olool,Epoch[2/30]loss=1.1043
Predicted: ooool,Epoch[3/30]loss=1.0440
Predicted: ooool,Epoch[4/30]loss=1.0014
Predicted: ooool,Epoch[5/30]loss=0.9576
Predicted: ooool,Epoch[6/30]loss=0.9133
Predicted: ohool,Epoch[7/30]loss=0.8725
Predicted: ohlol,Epoch[8/30]loss=0.8374
Predicted: ohlol,Epoch[9/30]loss=0.8066
Predicted: ohlol,Epoch[10/30]loss=0.7778
Predicted: ohlol,Epoch[11/30]loss=0.7497
Predicted: ohlol,Epoch[12/30]loss=0.7225
Predicted: ohlol,Epoch[13/30]loss=0.6964
Predicted: ohlol,Epoch[14/30]loss=0.6715
Predicted: ohlol,Epoch[15/30]loss=0.6476
Predicted: ohlol,Epoch[16/30]loss=0.6243
Predicted: ohlol,Epoch[17/30]loss=0.6017
Predicted: ohlol,Epoch[18/30]loss=0.5799
Predicted: ohlol,Epoch[19/30]loss=0.5599
Predicted: ohlol,Epoch[20/30]loss=0.5422
Predicted: ohlol,Epoch[21/30]loss=0.5268
Predicted: ohlol,Epoch[22/30]loss=0.5130
Predicted: ohlol,Epoch[23/30]loss=0.5000
Predicted: ohlol,Epoch[24/30]loss=0.4879
Predicted: ohlol,Epoch[25/30]loss=0.4769
Predicted: ohlol,Epoch[26/30]loss=0.4674
Predicted: ohlol,Epoch[27/30]loss=0.4591
Predicted: ohlol,Epoch[28/30]loss=0.4515
Predicted: ohlol,Epoch[29/30]loss=0.4440
Predicted: ohlol,Epoch[30/30]loss=0.43674.独热向量的缺点
在词典映射的时候,维度会很高,例如上万维度。
而因为独热编码的特征,上万的维度里只有一个是有值的,造成稀疏。
编码都是硬编码,不是自己学习得到的

embedding:把高维的稀疏映射到低维的稠密空间里

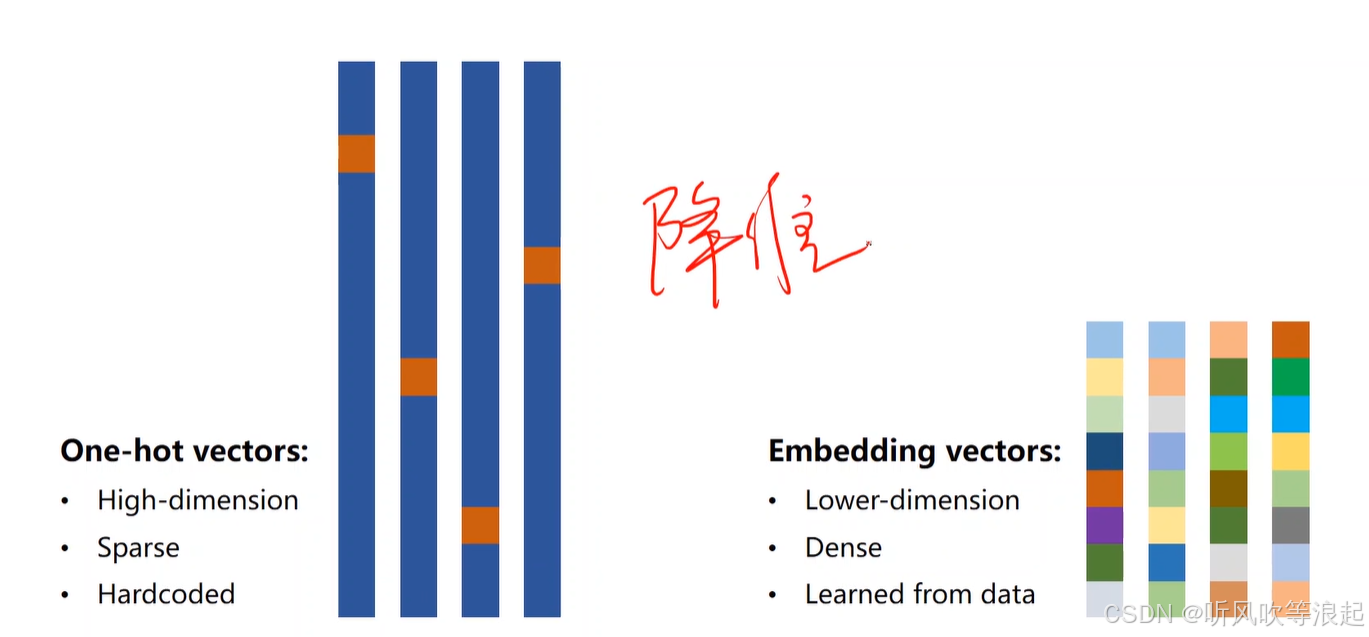
代码如下:
import torchnum_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
batch_size = 1
num_layers = 2
seq_len = 5idx2char = ['e','h','l','o'] # 字典
x_data = [[1,0,2,2,3]] # h e l l o
y_data = [3,1,2,3,2] # o h l o l# one_hot_lookup = [ # 独热向量查询
# [1,0,0,0],
# [0,1,0,0],
# [0,0,1,0],
# [0,0,0,1],
# ]inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)class Model(torch.nn. Module):def __init__(self):super(Model, self).__init__()self.emb = torch.nn.Embedding(input_size,embedding_size)self.rnn = torch.nn.RNN(input_size=embedding_size,hidden_size=hidden_size,num_layers=num_layers,batch_first=True)self.fc = torch.nn.Linear(hidden_size,num_class)def forward(self, x):hidden = torch.zeros(num_layers,x.size(0),hidden_size)x = self.emb(x)x,_ = self.rnn(x,hidden)x =self.fc(x)return x.view(-1,num_class)net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=0.05)for epoch in range(30):optimizer.zero_grad()outputs = net(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()_, idx = outputs.max(dim=1)idx = idx.data.numpy()print('Predicted:', ''.join([idx2char[x] for x in idx]),end='')print(',Epoch[%d/30]loss=%.4f' %(epoch+1, loss.item()))
如下:
Predicted: lolll,Epoch[1/30]loss=1.1871
Predicted: oolol,Epoch[2/30]loss=0.9232
Predicted: ohlol,Epoch[3/30]loss=0.7144
Predicted: ohlol,Epoch[4/30]loss=0.5330
Predicted: ohlol,Epoch[5/30]loss=0.3823
Predicted: ohlol,Epoch[6/30]loss=0.2578
Predicted: ohlol,Epoch[7/30]loss=0.1712
Predicted: ohlol,Epoch[8/30]loss=0.1120
Predicted: ohlol,Epoch[9/30]loss=0.0731
Predicted: ohlol,Epoch[10/30]loss=0.0490
Predicted: ohlol,Epoch[11/30]loss=0.0338
Predicted: ohlol,Epoch[12/30]loss=0.0238
Predicted: ohlol,Epoch[13/30]loss=0.0171
Predicted: ohlol,Epoch[14/30]loss=0.0125
Predicted: ohlol,Epoch[15/30]loss=0.0094
Predicted: ohlol,Epoch[16/30]loss=0.0072
Predicted: ohlol,Epoch[17/30]loss=0.0056
Predicted: ohlol,Epoch[18/30]loss=0.0045
Predicted: ohlol,Epoch[19/30]loss=0.0037
Predicted: ohlol,Epoch[20/30]loss=0.0031
Predicted: ohlol,Epoch[21/30]loss=0.0026
Predicted: ohlol,Epoch[22/30]loss=0.0022
Predicted: ohlol,Epoch[23/30]loss=0.0019
Predicted: ohlol,Epoch[24/30]loss=0.0017
Predicted: ohlol,Epoch[25/30]loss=0.0015
Predicted: ohlol,Epoch[26/30]loss=0.0014
Predicted: ohlol,Epoch[27/30]loss=0.0012
Predicted: ohlol,Epoch[28/30]loss=0.0011
Predicted: ohlol,Epoch[29/30]loss=0.0010
Predicted: ohlol,Epoch[30/30]loss=0.0009
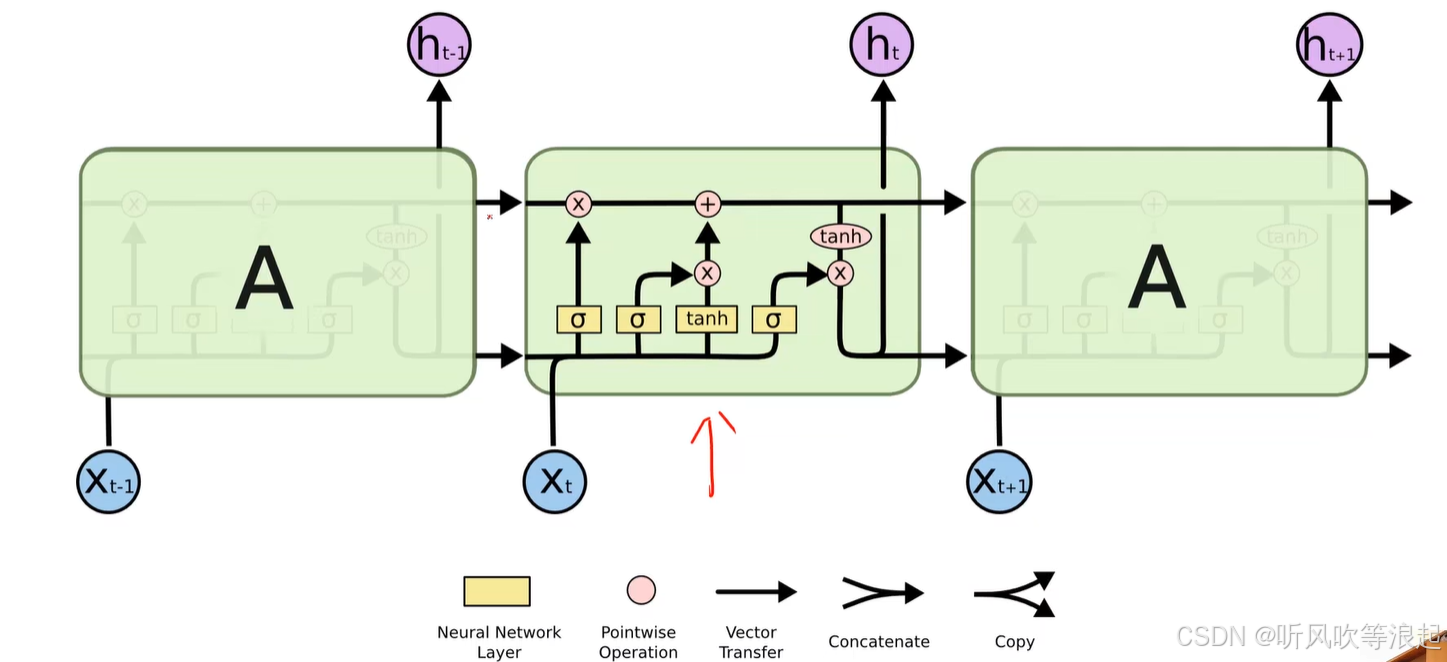
5. LSTM

)


