数据加载与保存:
1. 加载数据的方法
通过选项加载:传入URL地址、用户名、密码和数据表名称等参数。
通过路径加载:传入加载数据的路径和类型,使用可选参数。
通过MySQL语句加载:直接导入MySQL语句来加载数据。
2. 保存数据的方法
通用方法:使用df.write方法保存数据。
设定格式和选项:指定保存的数据类型、选项和路径。
保存模式:使用mode方法设置保存模式(追加、错误、覆盖、忽略)。
数据源格式
默认数据源格式:Spark SQL的默认数据源格式,能够存储嵌套数据,方便执行所有操作。
JSON数据:Spark SQL可以自动检测JSON数据集的结构,并加载为DataFrame。
CSV数据:配置CSV文件的列表信息,读取CSV文件的第一行作为数据列信息。
MySQL数据:通过JDBC从关系型数据库读取数据,创建DataFrame,并可以将数据写回数据库。
具体操作步骤
1. 导入依赖
确保Spark和MySQL的版本号一致。
2. 读取数据
第一种方式:使用option参数传入URL、驱动、用户名、密码和表名。
第二种方式:在URL中融合用户名和密码,使用`options`参数。
第三种方式:使用spark.read.jdbc方法,传入JDBC路径、用户名和密码。
3. 写入数据
创建RDD并转换为DataFrame格式。
使用mode参数设置保存模式(追加、错误、覆盖、忽略)。
关闭Spark。
Spark-SQL连接Hive
1.把hive-site.xml core-site.xml 和 hdfs-site.xml拷贝到conf下
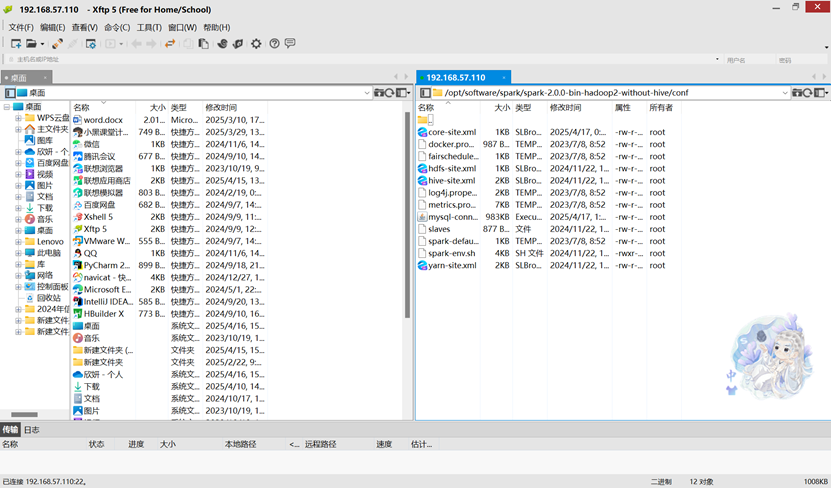
2.把 MySQL 的驱动 copy 到 jars/目录下
![]()
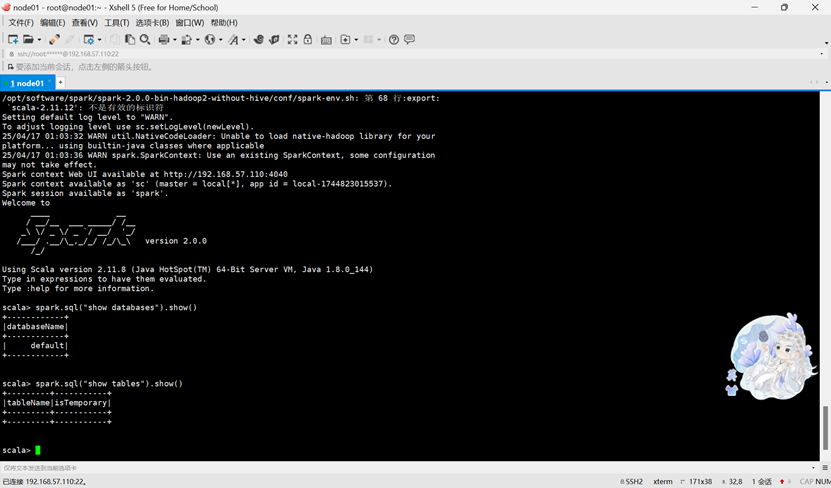
3.验证是否连接成功
spark.sql("show databases").show()
spark.sql("show tables").show()
4.运行Spark-SQL CLI
输入spark-sql
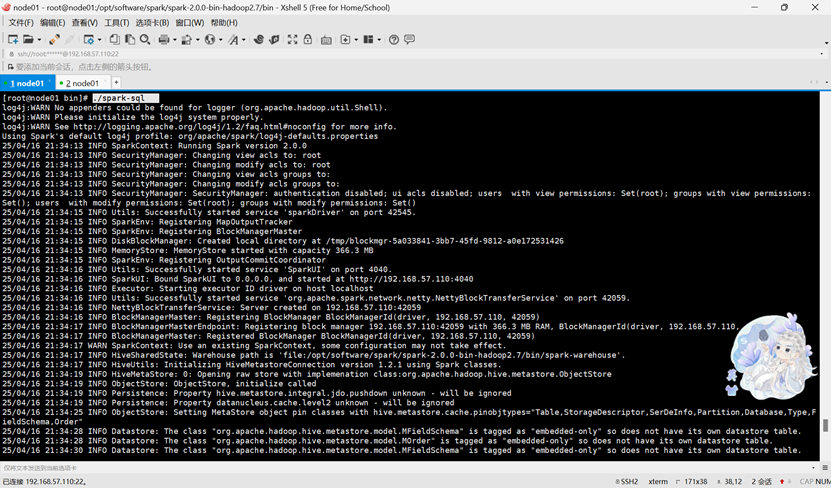
输入SHOW DATABASES;验证是否启动成功

)
库)

)