
🌈 个人主页:十二月的猫-CSDN博客
🔥 系列专栏: 🏀《深度学习理论直觉三十讲》_十二月的猫的博客-CSDN博客💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光
目录
1. 前言
2. 语义分割在计算机视觉中
3. 语义分割的应用
4. 理解卷积、最大池化和转置卷积
4.1 卷积运算
4.2 最大池化操作
4.3 上采样操作
4.4 转置卷积
4.5 总结
5. UNET网络
6. 总结
1. 前言
计算机视觉是一门跨学科的科学领域,研究如何让计算机从数字图像或视频中获得高水平的理解。从工程的角度来看,它寻求自动化人类视觉系统可以完成的任务。
深度学习使得计算机视觉领域在过去几年中飞速发展。在这篇文章中,我想讨论计算机视觉中的一项特定任务,即语义分割 。尽管研究人员已经想出了许多方法来解决这个问题,但我将讨论一种特殊的架构,即 UNET ,它使用完全卷积网络模型来完成这项任务。
此外这篇博客的目的还在于提供一些关于卷积网络中常用操作和术语的直观见解,以便于理解图像。 其中包括卷积、最大池化、感受野、上采样、转置卷积、跳过连接等。

2. 语义分割在计算机视觉中
计算机对图像的理解有多种粒度级别。对于每个级别,计算机视觉领域都定义了一个问题。从粗粒度到更细粒度的理解,可以分为计算机视觉中的不同任务:1、图像分类;2、带定位的分类;3、物体检测;4、语义分割;5、实例分割。
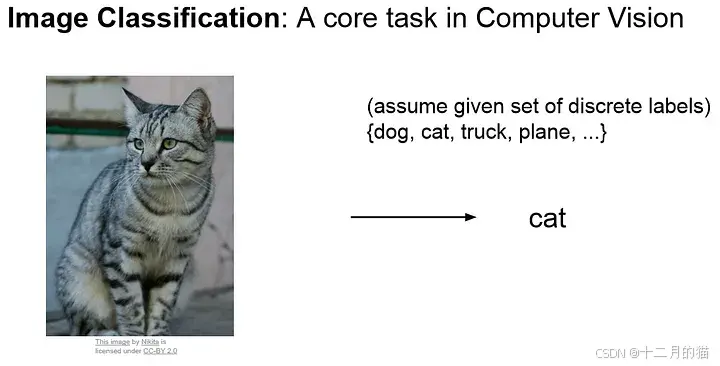
a. 图像分类:
计算机视觉中最基本的构建块是图像分类问题,给定一张图像,我们希望计算机输出一个离散标签,即图像中的主要对象。在图像分类中,我们假设图像中只有一个(而不是多个)对象。
在我的另一篇文章中:【深度学习的骨架与脉搏】卷积神经网络模型(呕心沥血版)_alexnet卷积神经网络具体的卷积和池化过程-CSDN博客我说到卷积神经网络CNN的一个特性就是 保留局部不变性(无论物体在图片的哪个位置,对于CNN来说学习到的东西都是一样的)。但是在定位问题中这个特性反倒变为了阻碍。
b. 带定位的分类:
在定位中,除了离散标签,我们还希望计算能够确定图像中物体的确切位置。这种定位通常使用边界框来实现,边界框可以通过一些与图像边界相关的数值参数来识别。即使在这种情况下,也假设每个图像只有一个物体。

c. 目标检测:
目标检测将定位扩展到下一个级别,现在图像不再局限于只有一个对象,而是可以包含多个对象。任务是对图像中的所有对象进行分类和定位。在这里,定位再次使用边界框的概念来完成。

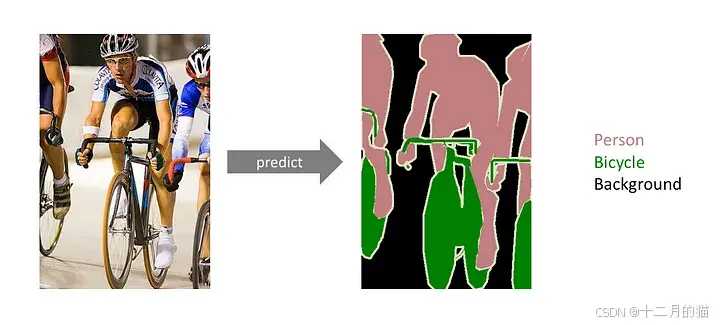
d. 语义分割:
语义图像分割的目标是将图像中的每个像素标记为所表示内容的相应类别 。由于我们要对图像中的每个像素进行预测,因此这项任务通常称为密集预测 。请注意,与之前的任务不同,语义分割的预期输出不仅仅是标签和边界框参数。输出本身是高分辨率图像(通常与输入图像大小相同),其中每个像素被归类为特定类别。因此,它是像素级图像分类。
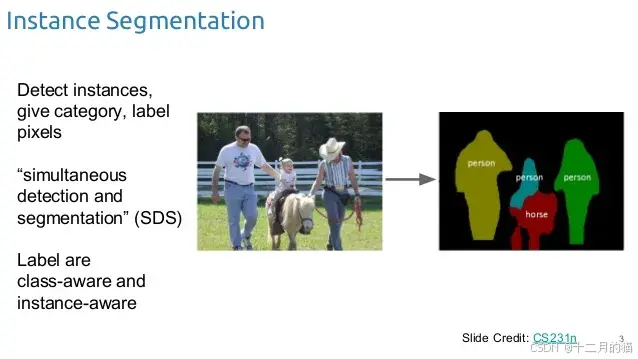
e. 实例分割:
实例分割比语义分割领先一步,在像素级分类之外,我们期望计算机分别对每个类的实例进行分类。例如,上图中有 3 个人,严格来说是“人”类的 3 个实例。这 3 个实例被分别分类(使用不同的颜色)。但语义分割不会区分特定类的实例。
特别地:实例分割是语义分割的进一步细粒度分割
3. 语义分割的应用
如果你想知道语义分割是否有用,你的疑问是合理的。然而,事实证明,Vision 中的许多复杂任务都需要对图像进行这种细粒度的理解。例如:
a. Autonomous vehicles 自动驾驶汽车
自动驾驶是一项复杂的机器人任务,需要在不断变化的环境中进行感知、规划和执行。这项任务还需要以最高的精度执行,因为安全至关重要。语义分割提供有关道路上可用空间的信息,以及检测车道标记和交通标志。

b. 生物医学图像诊断
机器可以增强放射科医生的分析能力,大大减少运行诊断测试所需的时间。
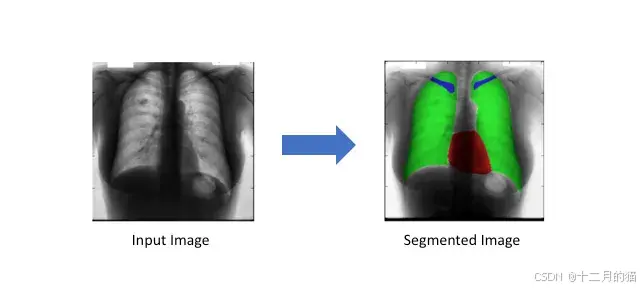
c. 地理传感
语义分割问题也可以视为分类问题,其中每个像素被归类为一系列对象类别中的一个。因此,卫星图像的土地使用地图绘制有一个用例。土地覆盖信息对于各种应用都很重要,例如监测森林砍伐和城市化区域。为了识别卫星图像上每个像素的土地覆盖类型(例如城市、农业、水域等),土地覆盖分类可以看作是一项多类语义分割任务。道路和建筑物检测也是交通管理、城市规划和道路监测的重要研究课题。

4. 理解卷积、最大池化和转置卷积
在深入研究 UNET 模型之前,了解卷积网络中通常使用的不同操作非常重要。请深入理解卷积、最大池化和转置卷积的作用。
4.1 卷积运算
卷积运算有两个输入:
- 输入的3维向量(图片一般是RGB输入的3D向量)。
- 一组f个(f也就通道数)过滤器(也叫卷积核或特征提取器),每个过滤器的大小为k*k(通常为3或5),其深度默认是3(和输入的维度是相同,因为图片一般是3D向量)。
卷积运算的输出:
- 一个大小为 (nout x nout x f) 的 3D 体积(也称为输出图像或特征图),也可以说是f个大小为(nout x nout)的输出图像。(每一个卷积核会提取输出图像中的一部分特征)

卷积可视化如下:
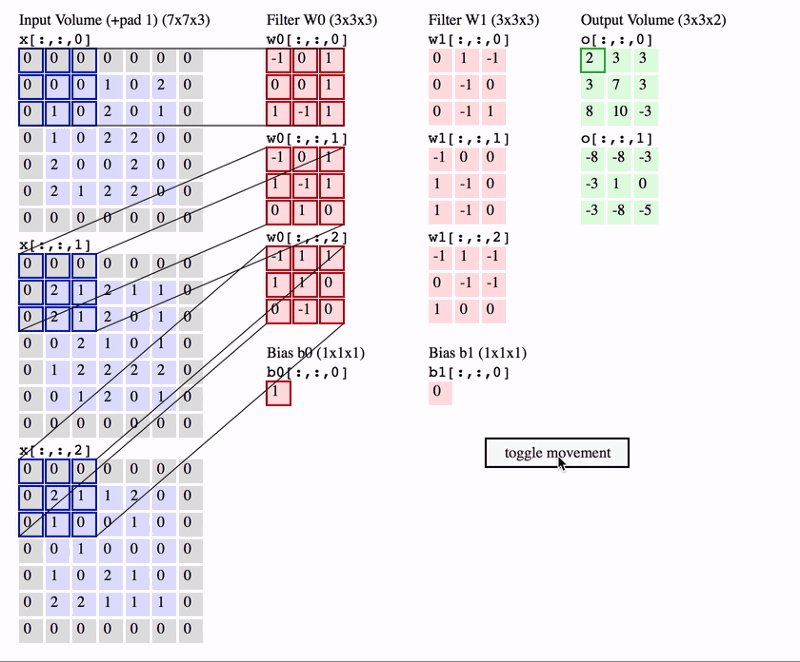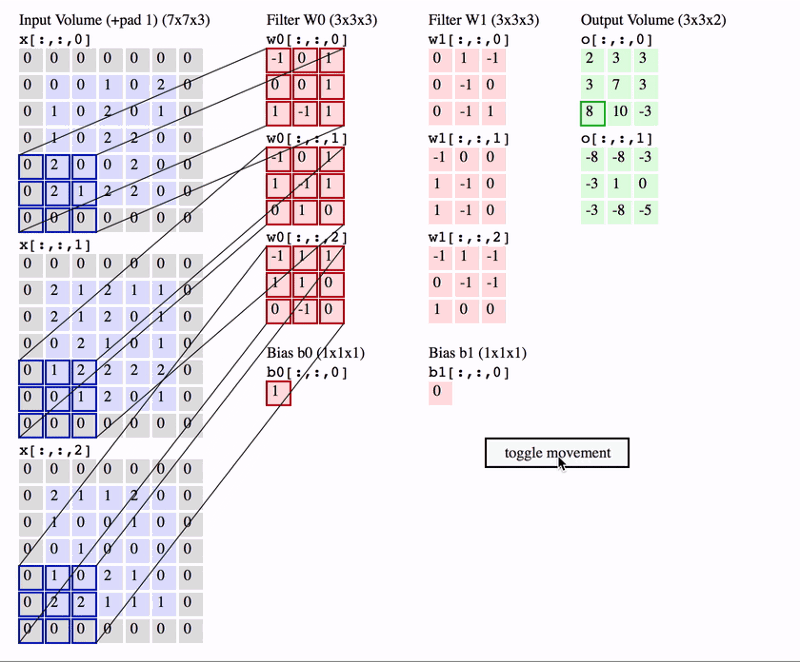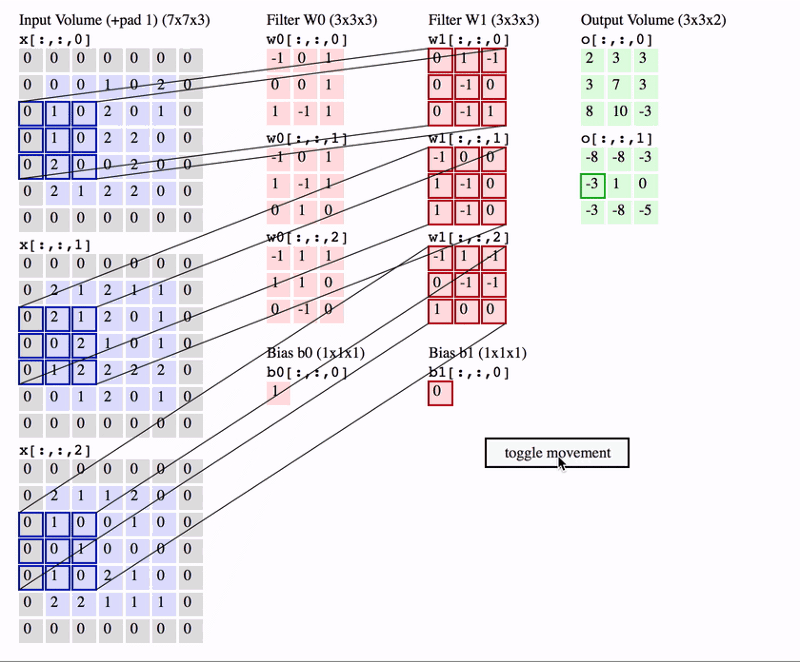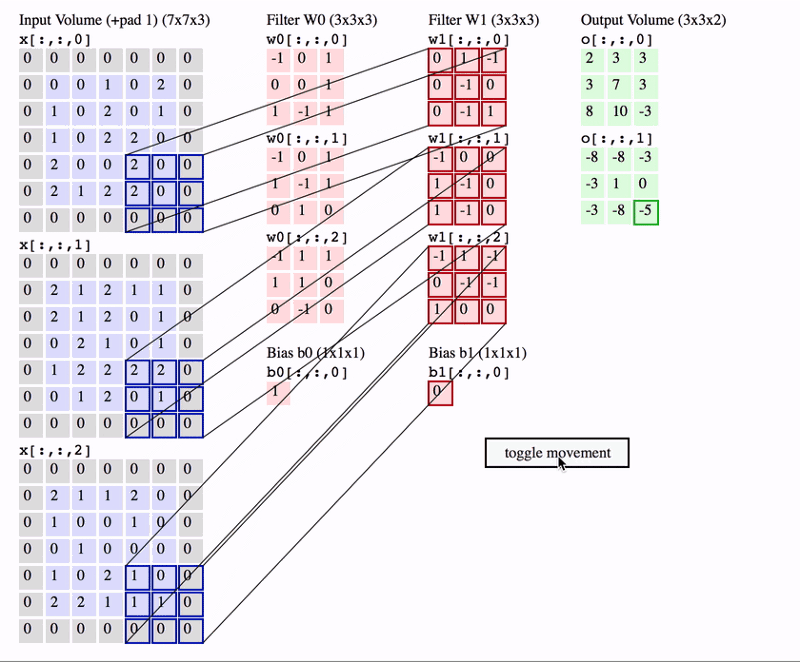
在上面的 GIF 中,我们有一个大小为 7x7x3 的输入量。两个过滤器的大小均为 3x3x3(k选择为3,最后一个深度由输入图片决定)。Padding =0,Strides = 2。因此,输出量为 3x3x2 。
想要真正理解卷积操作需要来看一个名词“感受野”。感受野是特定特征提取器(过滤器)正在查看的输入体积中的区域。在上面的 GIF 中,过滤器在任何给定实例中覆盖的输入体积中的 3x3 蓝色区域是感受野。这有时也称为上下文 。简单来说, 感受野(上下文)是过滤器在任何给定时间点覆盖的输入图像的区域 。
4.2 最大池化操作
简单来说,池化的作用是减少特征图的大小,以便网络中的参数更少(选取最大值是因为最大值能够保持更多的信息)。例如:

基本上,我们从输入特征图的每个 2x2 块中选择最大像素值,从而获得池化特征图。请注意,过滤器的大小和步幅是最大池化操作中的两个重要超参数。
这个想法是只保留每个区域的重要特征(最大值像素),并丢弃不重要的信息。重要的信息是指最能描述图像背景的信息。这里需要注意的一点是,卷积运算和池化运算都会减小图像的大小。这称为下采样 。在上面的例子中,池化之前的图像大小为 4x4,池化之后的图像大小为 2x2。实际上,下采样基本上意味着将高分辨率图像转换为低分辨率图像。
因此,在池化之前,4x4 图像中存在的信息,在池化之后,(几乎)相同的信息现在存在于 2x2 图像中。现在,当我们再次应用卷积运算时,下一层中的过滤器将能够看到更大的上下文,即,随着我们深入网络,图像的尺寸会减小,但感受野会增加。
解释池化层的作用+解释为什么越深能够提取更抽象的特征:这个角度很有意思,因为池化操作将更多信息蕴含到更少的框架内(4*4的信息蕴含到2*2里面),因此下一层的过滤器(虽然感受野一样)将看到更大的上下文,这样解释了为什么越深层次看到的东西越抽象,更接近语义信息。
例如下面是 LeNet 5 架构:
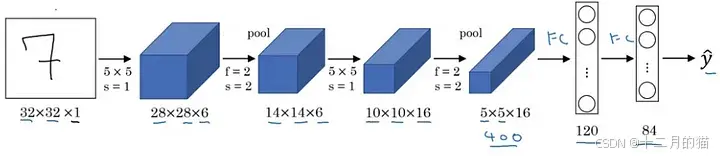
请注意,在典型的卷积网络中,图像的高度和宽度逐渐减小(由于池化而下采样),这有助于更深层的过滤器聚焦于更大的感受野(上下文)。然而,通道数/深度(使用的过滤器数量)逐渐增加,这有助于从图像中提取更复杂的特征。
这里蕴含一个点:越深层(越抽象的特征)需要更多的卷积核去提取。举个例子解释小学生的一道题目可能只要一个角度一门学科的知识就足够了,但是想要理解一个具身人工智能就需要多学科多角度的知识去理解。
4.3 上采样操作
如前所述,语义分割的输出不仅仅是一个类别标签或一些边界框参数。事实上,输出是一个完整的高分辨率图像,其中所有像素都被分类。因此,如果我们使用带有池化层和密集层的常规卷积网络,虽然不停卷积+池化,我们能够学习到从浅层到深层的很多信息,但是我们也将丢失许多细节的信息(因为下采样)。因此需要对图像进行上采样,将低分辨率图像转换为高分辨率图像。
有许多技术可以对图像进行上采样。其中一些是双线性插值、立方插值、最近邻插值、反池化、转置卷积等。然而,在大多数最先进的网络中,转置卷积是上采样图像的首选。
4.4 转置卷积
转置卷积(有时也称为反卷积或分数步长卷积)是一种使用可学习参数对图像进行上采样的技术。如果对转置卷积不熟悉的同学可以见另一篇文章:
- 【深度学习基础】深入理解 转置卷积与转置卷积核-CSDN博客
从高层次上讲,转置卷积恰好是普通卷积的相反过程,即输入量是低分辨率图像,而输出量是高分辨率图像。在上文中,很好地解释了如何将普通卷积表示为输入图像和滤波器的矩阵乘法以产生输出图像。只需对滤波器矩阵进行转置,我们就可以反转卷积过程,因此得名转置卷积。
4.5 总结
- 感受野。
- 卷积和池化操作对图像进行下采样,即将高分辨率图像转换为低分辨率图像。
- 最大池化操作通过增加感受野,有助于理解图像中“有什么”。然而,它往往会丢失物体“在哪里”的信息(丢失的是绝对位置信息,卷积的平移不变性会保证相对位置)。
- 在语义分割中,不仅要知道图像中存在“什么”,而且要知道它存在于“哪里”。因此,我们需要一种方法来将图像从低分辨率上采样到高分辨率,这将有助于我们恢复“哪里”的信息。
- 转置卷积是执行上采样的首选,它基本上通过反向传播学习参数,将低分辨率图像转换为高分辨率图像。
5. UNET网络
Unet由 Olaf Ronneberger 等人为生物医学图像分割而开发。该架构包含两条路径。第一条路径是收缩路径(也称为编码器),用于捕获图像中的上下文。编码器只是卷积层和最大池化层的传统堆栈。第二条路径是对称扩展路径(也称为解码器),用于使用转置卷积实现精确定位。 因此它是一个端到端的全卷积网络(FCN),即它只包含卷积层而不包含任何密集层,因此它可以接受任何大小的图像。在原始论文中,UNET 的描述如下:
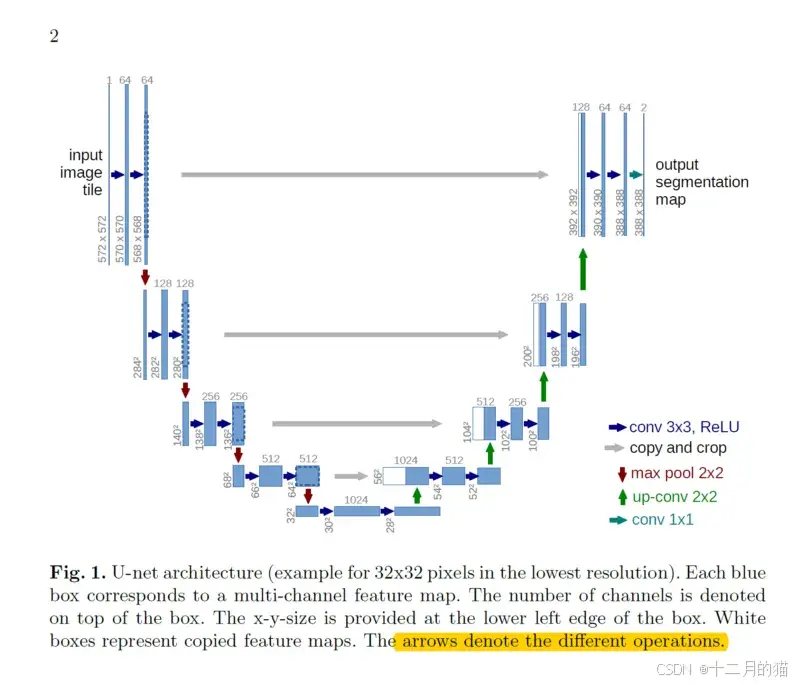
猫猫会尝试更直观地描述这个架构。请注意,在原始论文中,输入图像的大小为 572x572x3,但是,我们将使用大小为 128x128x3 的输入图像。因此,各个位置的尺寸将与原始论文中的尺寸不同,但核心组件保持不变(上面的卷积会不填充,猫猫下面展示的会填充,但是这都没有本质区别)。
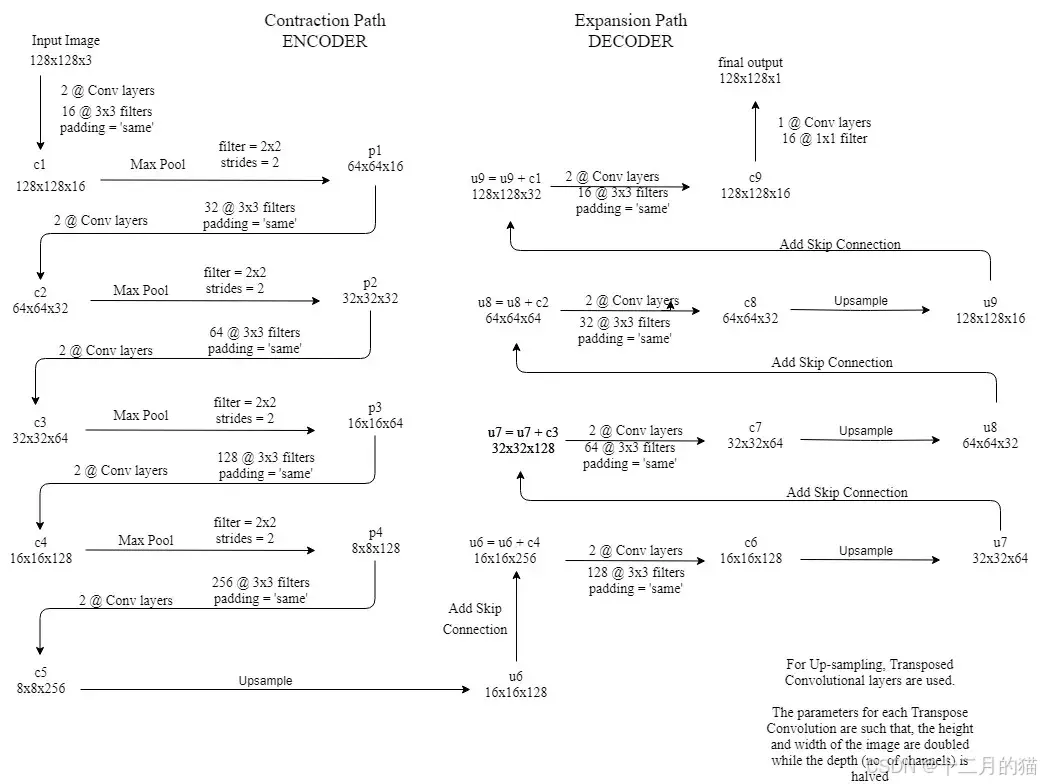
- 2@Conv 层表示应用两个连续的卷积层。
- c1, c2, .... c9 是卷积层的输出张量。
- p1、p2、p3 和 p4 是最大池化层的输出张量。
- u6、u7、u8 和 u9 是上采样(转置卷积)层的输出张量。
- 左侧是收缩路径(编码器),我们在其中应用常规卷积和最大池化层。
- 在编码器中,图像的尺寸逐渐减小,深度逐渐增加。从 128x128x3 开始到 8x8x256。
- 这基本上意味着网络学习了图像中的“什么”信息,但它丢失了“在哪里”的信息。
- 右侧是扩展路径(解码器),我们将转置卷积与常规卷积一起应用。
- 在解码器中,图像的尺寸逐渐增加,深度逐渐减小。从 8x8x256 开始到 128x128x1。
- 直观地讲,解码器通过逐步应用上采样来恢复“WHERE”信息(精确定位)。为了获得更精确的位置,在解码器的每一步我们都使用跳过连接,将转置卷积层的输出与来自同一级别的编码器的特征图连接起来:
u6 = u6 + c4
u6=u6+c4
u7 = u7 + c3
u7=u7+c3
u8 = u8 + c2
u8=u8+c2
u9 = u9 + c1
u9=u9+c1 - 本质上来说,跳跃连接就是将 卷积学习到的知识+图片原始信息 再糅合在一起(卷积学习到的知识里面可能包括模型对图片的类型理解、位置信息理解等;图片原始信息包括绝对位置信息、高分辨率像素等信息。)然后再利用卷积在这些信息中提取我们想要的(切割信息+绝对位置信息等)。之后再进行下一层上采样,一层层去恢复绝对位置信息。
6. 总结
【如果想学习更多深度学习知识,可以订阅热门专栏】
- 《AI认知筑基三十讲》
- 《PyTorch科研加速指南:即插即用式模块开发》
- 《深度学习理论直觉三十讲》
如果想要学习更多人工智能的知识,大家可以点个关注并订阅,持续学习、天天进步你的点赞就是我更新的动力,如果觉得对你有帮助,辛苦友友点个赞,收个藏呀~~~






