基于协同过滤的推荐系统详解:从经典方法到前沿技术
在当今数据驱动的世界中,推荐系统已经成为众多互联网产品不可或缺的组成部分。无论是电子商务平台推荐相关商品,还是视频网站推荐感兴趣的内容,这些系统都在用户体验中扮演着重要角色。其中,协同过滤(Collaborative Filtering)作为一种经典且有效的推荐算法,被广泛应用于各类推荐场景。本文将深入探讨协同过滤的原理、实现方法及应用案例,同时介绍其前沿发展方向。
文章目录
- 基于协同过滤的推荐系统详解:从经典方法到前沿技术
- 1. 协同过滤概述与发展历程
- 1.1 历史发展
- 1.2 协同过滤的分类
- 1.3 协同过滤的理论基础
- 2. 基于用户的协同过滤
- 2.1 用户相似度计算
- 2.1.1 余弦相似度
- 2.1.2 皮尔逊相关系数
- 2.1.3 杰卡德相似度
- 2.2 基于用户的推荐算法实现
- 2.3 用户相似度可视化
- 3. 基于物品的协同过滤
- 3.1 物品相似度计算
- 3.2 基于物品的推荐算法实现
- 3.3 基于物品的协同过滤优势
- 4. 基于矩阵分解的协同过滤
- 4.1 矩阵分解的数学原理
- 4.2 奇异值分解(SVD)
- 4.3 矩阵分解算法实现
- 4.4 隐语义模型
- 4.5 矩阵分解的优势与应用
- 5. 深度学习与协同过滤
- 5.1 神经协同过滤(NCF)
- 5.2 自注意力机制在推荐系统中的应用
- 5.3 深度协同过滤的其他方法
- 6. 实际应用案例
- 6.1 电子商务网站商品推荐
- 6.2 流媒体平台内容推荐
- 6.3 社交网络推荐
- 7. 协同过滤的局限性及解决方案
- 7.1 冷启动问题
- 7.2 稀疏性问题
- 7.3 可扩展性问题
- 7.4 多样性与过度专业化问题
- 8. 评估框架与指标
- 8.1 常用评估指标
- 8.2 离线与在线评估方法
- 9. 协同过滤的前沿研究方向
- 9.1 图神经网络在推荐系统中的应用
- 9.2 跨域推荐系统
- 9.3 强化学习在推荐系统中的应用
- 9.4 因果推断与可解释推荐
- 10. 系统工程与实践考量
- 10.1 大规模推荐系统架构
- 10.2 性能优化和扩展性考量
- 10.3 在线学习与增量更新
- 11. 总结与展望
- 11.1 技术演进路线
- 11.2 未来发展趋势
- 11.3 产业应用前景
1. 协同过滤概述与发展历程
协同过滤是基于这样一种思想:具有相似偏好的用户可能对相似的物品感兴趣。该方法不需要了解用户或物品的具体特征,而是通过分析用户行为数据(如评分、点击、购买等)来发现用户之间或物品之间的相似性,进而做出推荐。
1.1 历史发展
协同过滤技术始于1990年代中期,最早可追溯到明尼苏达大学的GroupLens研究项目。该项目开发了一个新闻文章推荐系统,通过收集用户对文章的评价来预测他们对未读文章的兴趣程度。从此,协同过滤技术经历了以下几个重要发展阶段:
- 1994-1999年:基于记忆的协同过滤方法兴起,包括基于用户和基于物品的方法
- 2000-2006年:基于模型的方法开始发展,如贝叶斯网络、聚类模型等
- 2006-2009年:Netflix Prize比赛推动了矩阵分解技术的发展和应用
- 2010-2015年:上下文感知和时序推荐系统受到关注
- 2016年至今:深度学习技术在推荐系统中的应用迅速发展,特别是神经协同过滤、图神经网络等方法
1.2 协同过滤的分类
研究者们通常将协同过滤分为三大类:
-
基于记忆的协同过滤
- 基于用户的协同过滤(User-Based Collaborative Filtering):查找与目标用户相似的用户群体,推荐这些相似用户喜欢但目标用户尚未接触的物品。
- 基于物品的协同过滤(Item-Based Collaborative Filtering):查找与用户已接触物品相似的其他物品进行推荐。
-
基于模型的协同过滤
- 矩阵分解(Matrix Factorization):将用户-物品交互矩阵分解为低维潜在因子矩阵
- 概率模型:如贝叶斯网络、聚类模型等
- 隐语义模型(Latent Semantic Models)
-
混合方法
- 结合基于记忆和基于模型的方法
- 结合协同过滤与基于内容的推荐方法
- 集成多种算法的混合推荐系统
1.3 协同过滤的理论基础
从理论角度看,协同过滤建立在以下核心概念之上:
- 相似性度量:如何定量衡量用户间或物品间的相似程度
- 近邻选择:如何确定最相关的用户或物品集合
- 评分预测:如何基于相似用户或物品的已知评分预测未知评分
- 推荐生成:如何根据预测评分选择并排序推荐物品
这些概念共同构成了协同过滤算法的数学框架和实现基础。
2. 基于用户的协同过滤
基于用户的协同过滤首先需要计算用户之间的相似度,然后基于相似用户的偏好做出推荐。这种方法假设:如果用户A和用户B对许多物品的评价相似,那么用户A对其他物品的评价可能与用户B相似。
2.1 用户相似度计算
有多种方法可以计算用户间的相似度,以下是三种常用方法的数学定义和Python实现:
2.1.1 余弦相似度
计算两个用户评分向量间的余弦角:
sim ( u , v ) = ∑ i ∈ I u v r u i ⋅ r v i ∑ i ∈ I u v r u i 2 ⋅ ∑ i ∈ I u v r v i 2 \text{sim}(u, v) = \frac{\sum_{i \in I_{uv}} r_{ui} \cdot r_{vi}}{\sqrt{\sum_{i \in I_{uv}} r_{ui}^2} \cdot \sqrt{\sum_{i \in I_{uv}} r_{vi}^2}} sim(u,v)=∑i∈Iuvrui2⋅∑i∈Iuvrvi2∑i∈Iuvrui⋅rvi
其中 I u v I_{uv} Iuv是用户 u u u和 v v v共同评分过的物品集合, r u i r_{ui} rui表示用户 u u u对物品 i i i的评分。
def cosine_similarity(vector1, vector2):"""余弦相似度计算"""dot_product = sum(a * b for a, b in zip(vector1, vector2) if a > 0 and b > 0)magnitude1 = sqrt(sum(a * a for a in vector1 if a > 0))magnitude2 = sqrt(sum(b * b for b in vector2 if b > 0))if magnitude1 * magnitude2 == 0:return 0return dot_product / (magnitude1 * magnitude2)
2.1.2 皮尔逊相关系数
考虑用户评分偏好的相关性,减少评分尺度差异的影响:
sim ( u , v ) = ∑ i ∈ I u v ( r u i − r ˉ u ) ⋅ ( r v i − r ˉ v ) ∑ i ∈ I u v ( r u i − r ˉ u ) 2 ⋅ ∑ i ∈ I u v ( r v i − r ˉ v ) 2 \text{sim}(u, v) = \frac{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u) \cdot (r_{vi} - \bar{r}_v)}{\sqrt{\sum_{i \in I_{uv}} (r_{ui} - \bar{r}_u)^2} \cdot \sqrt{\sum_{i \in I_{uv}} (r_{vi} - \bar{r}_v)^2}} sim(u,v)=∑i∈Iuv(rui−rˉu)2⋅∑i∈Iuv(rvi−rˉv)2∑i∈Iuv(rui−rˉu)⋅(rvi−rˉv)
其中 r ˉ u \bar{r}_u rˉu是用户 u u u的平均评分。
def pearson_correlation(vector1, vector2):"""皮尔逊相关系数计算"""common_items = [i for i, (v1, v2) in enumerate(zip(vector1, vector2)) if v1 > 0 and v2 > 0]if len(common_items) == 0:return 0v1 = [vector1[i] for i in common_items]v2 = [vector2[i] for i in common_items]mean1, mean2 = sum(v1) / len(v1), sum(v2) / len(v2)numerator = sum((v1[i] - mean1) * (v2[i] - mean2) for i in range(len(v1)))denominator = (sum((v1[i] - mean1) ** 2 for i in range(len(v1))) * sum((v2[i] - mean2) ** 2 for i in range(len(v1)))) ** 0.5return numerator / denominator if denominator != 0 else 0
2.1.3 杰卡德相似度
仅考虑物品交互的重叠程度,不关注评分值:
sim ( u , v ) = ∣ I u ∩ I v ∣ ∣ I u ∪ I v ∣ \text{sim}(u, v) = \frac{|I_u \cap I_v|}{|I_u \cup I_v|} sim(u,v)=∣Iu∪Iv∣∣Iu∩Iv∣
其中 I u I_u Iu和 I v I_v Iv分别是用户 u u u和 v v v评分过的物品集合。
def jaccard_similarity(vector1, vector2):"""杰卡德相似度计算"""set1 = {i for i, v in enumerate(vector1) if v > 0}set2 = {i for i, v in enumerate(vector2) if v > 0}intersection = len(set1.intersection(set2))union = len(set1.union(set2))return intersection / union if union != 0 else 0
2.2 基于用户的推荐算法实现
下面通过Python代码详细说明基于用户的协同过滤推荐过程:
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 示例用户-物品评分矩阵
ratings = pd.DataFrame({'user_id': [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4],'item_id': [101, 102, 103, 101, 102, 104, 101, 103, 104, 102, 103, 104],'rating': [5, 3, 4, 3, 1, 5, 4, 3, 3, 5, 2, 1]
})# 将评分数据转换为用户-物品矩阵
user_item_matrix = pd.pivot_table(ratings, values='rating', index='user_id', columns='item_id', fill_value=0)
print("用户-物品评分矩阵:")
print(user_item_matrix)# 计算用户之间的余弦相似度
user_similarity = pd.DataFrame(cosine_similarity(user_item_matrix),index=user_item_matrix.index,columns=user_item_matrix.index
)
print("\n用户相似度矩阵:")
print(user_similarity)# 为目标用户生成推荐
def recommend_for_user(user_id, user_item_matrix, user_similarity, n_recommendations=2):# 获取用户尚未评分的物品unrated_items = user_item_matrix.columns[user_item_matrix.loc[user_id] == 0]# 计算这些物品的预测评分recommendations = {}for item in unrated_items:# 找出对该物品有评分的其他用户other_users = user_item_matrix.index[user_item_matrix[item] > 0]if len(other_users) == 0:continue# 计算加权评分weighted_ratings = 0similarity_sum = 0for other_user in other_users:similarity = user_similarity.loc[user_id, other_user]rating = user_item_matrix.loc[other_user, item]weighted_ratings += similarity * ratingsimilarity_sum += similarity# 避免除以零if similarity_sum > 0:recommendations[item] = weighted_ratings / similarity_sum# 排序并返回前N个推荐sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)return sorted_recommendations[:n_recommendations]# 为用户1生成推荐
user_id = 1
recommendations = recommend_for_user(user_id, user_item_matrix, user_similarity)
print(f"\n为用户{user_id}推荐的物品:")
for item, predicted_rating in recommendations:print(f"物品ID: {item}, 预测评分: {predicted_rating:.2f}")

2.3 用户相似度可视化
基于用户相似度矩阵,可以通过可视化技术直观地展示用户群体之间的关系,如下图所示:
3. 基于物品的协同过滤
基于物品的协同过滤计算物品之间的相似度,然后基于用户已评分的物品推荐相似物品。这种方法在用户数量远大于物品数量的场景中特别有效,同时可以提供更稳定的推荐结果,因为物品的特性通常比用户偏好更稳定。
3.1 物品相似度计算
物品相似度的计算与用户相似度类似,只是视角转换为物品间的关系。以余弦相似度为例,物品 i i i和 j j j之间的相似度可表示为:
sim ( i , j ) = ∑ u ∈ U i j r u i ⋅ r u j ∑ u ∈ U i j r u i 2 ⋅ ∑ u ∈ U i j r u j 2 \text{sim}(i, j) = \frac{\sum_{u \in U_{ij}} r_{ui} \cdot r_{uj}}{\sqrt{\sum_{u \in U_{ij}} r_{ui}^2} \cdot \sqrt{\sum_{u \in U_{ij}} r_{uj}^2}} sim(i,j)=∑u∈Uijrui2⋅∑u∈Uijruj2∑u∈Uijrui⋅ruj
其中 U i j U_{ij} Uij是同时对物品 i i i和 j j j评分的用户集合。
3.2 基于物品的推荐算法实现
以下是Python代码实现:
# 计算物品之间的余弦相似度
item_similarity = pd.DataFrame(cosine_similarity(user_item_matrix.T), # 注意这里需要转置矩阵index=user_item_matrix.columns,columns=user_item_matrix.columns
)
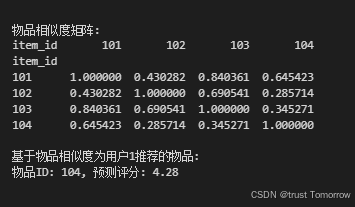
print("\n物品相似度矩阵:")
print(item_similarity)# 基于物品相似度为用户生成推荐
def recommend_items_based(user_id, user_item_matrix, item_similarity, n_recommendations=2):# 获取用户已评分的物品rated_items = user_item_matrix.columns[user_item_matrix.loc[user_id] > 0]user_ratings = user_item_matrix.loc[user_id]# 获取用户未评分的物品unrated_items = user_item_matrix.columns[user_item_matrix.loc[user_id] == 0]# 计算未评分物品的预测评分recommendations = {}for unrated_item in unrated_items:weighted_sum = 0similarity_sum = 0for rated_item in rated_items:# 获取物品相似度和用户对已评分物品的评分similarity = item_similarity.loc[unrated_item, rated_item]rating = user_ratings[rated_item]weighted_sum += similarity * ratingsimilarity_sum += abs(similarity) # 使用绝对值避免负相似度抵消# 避免除以零if similarity_sum > 0:recommendations[unrated_item] = weighted_sum / similarity_sum# 排序并返回前N个推荐sorted_recommendations = sorted(recommendations.items(), key=lambda x: x[1], reverse=True)return sorted_recommendations[:n_recommendations]# 为用户1基于物品相似度生成推荐
user_id = 1
item_based_recommendations = recommend_items_based(user_id, user_item_matrix, item_similarity)
print(f"\n基于物品相似度为用户{user_id}推荐的物品:")
for item, predicted_rating in item_based_recommendations:print(f"物品ID: {item}, 预测评分: {predicted_rating:.2f}")
3.3 基于物品的协同过滤优势
基于物品的协同过滤相较于基于用户的方法,具有以下优势:
- 可扩展性:在大多数商业系统中,物品数量远少于用户数量,计算复杂度更低
- 实时性:物品相似度可以预计算,新用户到来时能快速生成推荐
- 稳定性:物品特性比用户偏好更稳定,相似度不会频繁变化
- 可解释性:推荐结果更容易解释,如"与您喜欢的XX相似"
亚马逊的推荐系统主要采用这种方法,其著名的"购买了此商品的用户还购买了…"功能正是基于物品协同过滤实现的。
4. 基于矩阵分解的协同过滤
随着数据规模的增大,传统的基于记忆的协同过滤方法面临计算效率和稀疏性问题。矩阵分解作为一种基于模型的方法,能够很好地解决这些问题。
4.1 矩阵分解的数学原理
矩阵分解的核心思想是将用户-物品评分矩阵 R R R 分解为两个低维矩阵的乘积:
R ≈ P × Q T R \approx P \times Q^T R≈P×QT
其中:
- P P P 是用户-因子矩阵,维度为 ∣ U ∣ × k |U| \times k ∣U∣×k
- Q Q Q 是物品-因子矩阵,维度为 ∣ I ∣ × k |I| \times k ∣I∣×k
- k k k 是潜在因子的数量,通常远小于用户数和物品数
对于用户 u u u 对物品 i i i 的预测评分 r ^ u i \hat{r}_{ui} r^ui 可表示为:
r ^ u i = μ + b u + b i + p u T q i \hat{r}_{ui} = \mu + b_u + b_i + p_u^T q_i r^ui=μ+bu+bi+puTqi
其中:
- μ \mu μ 是全局平均评分
- b u b_u bu 是用户偏置项
- b i b_i bi 是物品偏置项
- p u p_u pu 是用户 u u u 的潜在因子向量
- q i q_i qi 是物品 i i i 的潜在因子向量
训练目标是最小化以下目标函数:
min P , Q , b ∑ ( u , i ) ∈ K ( r u i − r ^ u i ) 2 + λ ( ∣ ∣ p u ∣ ∣ 2 + ∣ ∣ q i ∣ ∣ 2 + b u 2 + b i 2 ) \min_{P,Q,b} \sum_{(u,i) \in \mathcal{K}} (r_{ui} - \hat{r}_{ui})^2 + \lambda(||p_u||^2 + ||q_i||^2 + b_u^2 + b_i^2) P,Q,bmin(u,i)∈K∑(rui−r^ui)2+λ(∣∣pu∣∣2+∣∣qi∣∣2+bu2+bi2)
其中 K \mathcal{K} K 表示已知评分集合, λ \lambda λ 是正则化参数。
4.2 奇异值分解(SVD)
矩阵分解的一种典型方法是奇异值分解(SVD),它将矩阵 R R R 分解为:
R = U Σ V T R = U \Sigma V^T R=UΣVT
其中 U U U 和 V V V 分别是包含左奇异向量和右奇异向量的正交矩阵, Σ \Sigma Σ 是包含奇异值的对角矩阵。通过保留前 k k k 个最大奇异值,可以获得矩阵的低秩近似。
4.3 矩阵分解算法实现
以下是使用Surprise库实现的矩阵分解算法示例:
from surprise import Dataset, Reader # pip install scikit-surprise
from surprise import SVD
from surprise.model_selection import train_test_split
from surprise import accuracy
import pandas as pd# 创建数据集
data = [['用户1', '物品A', 5],['用户1', '物品B', 3],['用户1', '物品C', 4],['用户2', '物品A', 3],['用户2', '物品B', 1],['用户2', '物品D', 5],['用户3', '物品A', 4],['用户3', '物品C', 3],['用户3', '物品D', 3],['用户4', '物品B', 5],['用户4', '物品C', 2],['用户4', '物品D', 1]
]# 定义评分范围
reader = Reader(rating_scale=(1, 5))
data = Dataset.load_from_df(pd.DataFrame(data, columns=['user', 'item', 'rating']), reader)# 划分训练集和测试集
trainset, testset = train_test_split(data, test_size=0.2, random_state=42)# 使用SVD算法
algo = SVD(n_factors=3, n_epochs=20, biased=True, random_state=42)
algo.fit(trainset)# 在测试集上评估模型
predictions = algo.test(testset)
rmse = accuracy.rmse(predictions)
print(f"\nRMSE: {rmse:.4f}")# 为指定用户预测评分
def predict_for_user(user_id, item_ids, algo):predictions = {}for item_id in item_ids:predicted_rating = algo.predict(user_id, item_id).estpredictions[item_id] = predicted_ratingreturn predictions# 为用户1预测未评分物品
user_id = '用户1'
items_to_predict = ['物品D'] # 用户1尚未评分的物品
predictions = predict_for_user(user_id, items_to_predict, algo)print(f"\n为{user_id}的预测评分:")
for item, rating in predictions.items():print(f"{item}: {rating:.2f}")

4.4 隐语义模型
除了传统的矩阵分解方法外,隐语义模型如概率隐语义分析(PLSA)和隐狄利克雷分配(LDA)也可用于协同过滤。这些方法假设用户的偏好由隐藏的主题或因子驱动,通过概率模型学习这些隐藏变量。
4.5 矩阵分解的优势与应用
矩阵分解方法具有以下优势:
- 处理稀疏数据的能力:能够通过潜在因子捕捉用户和物品之间的隐含关系
- 可扩展性:计算复杂度较低,适用于大规模数据
- 准确性:在许多基准测试中表现优异,如Netflix Prize竞赛
- 冷启动解决方案:可以通过引入侧信息改善冷启动问题
5. 深度学习与协同过滤
随着深度学习技术的发展,研究者开始将神经网络应用于推荐系统,创造了一系列新型协同过滤方法。
5.1 神经协同过滤(NCF)
神经协同过滤模型通过神经网络学习用户和物品之间的非线性交互关系,超越了传统矩阵分解的线性假设。下面是一个简化的NCF模型实现:
# 使用PyTorch实现简化版神经协同过滤模型
import torch
import torch.nn as nn
import torch.optim as optimclass NCF(nn.Module):def __init__(self, num_users, num_items, embedding_dim=8, layers=[16, 8, 4]):super(NCF, self).__init__()# 用户和物品嵌入层self.user_embedding = nn.Embedding(num_users, embedding_dim)self.item_embedding = nn.Embedding(num_items, embedding_dim)# MLP部分self.fc_layers = nn.ModuleList()input_size = 2 * embedding_dim # 连接用户和物品嵌入for output_size in layers:self.fc_layers.append(nn.Linear(input_size, output_size))input_size = output_size# 输出层self.output_layer = nn.Linear(layers[-1], 1)self.sigmoid = nn.Sigmoid()def forward(self, user_indices, item_indices):# 获取嵌入user_embedded = self.user_embedding(user_indices)item_embedded = self.item_embedding(item_indices)# 连接嵌入vector = torch.cat([user_embedded, item_embedded], dim=-1)# MLP层for layer in self.fc_layers:vector = torch.relu(layer(vector))# 输出层prediction = self.sigmoid(self.output_layer(vector))return prediction.squeeze()# 模型训练示例(简化版)
def train_ncf_model(model, train_data, epochs=10, lr=0.001):"""训练NCF模型参数:model: NCF模型实例train_data: 包含(user_id, item_id, rating)元组的列表epochs: 训练轮数lr: 学习率"""optimizer = optim.Adam(model.parameters(), lr=lr)criterion = nn.MSELoss()for epoch in range(epochs):epoch_loss = 0for user_id, item_id, rating in train_data:# 将ID转换为张量user_tensor = torch.LongTensor([user_id])item_tensor = torch.LongTensor([item_id])rating_tensor = torch.FloatTensor([rating / 5.0]) # 归一化评分# 前向传播prediction = model(user_tensor, item_tensor)loss = criterion(prediction, rating_tensor)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()epoch_loss += loss.item()print(f"Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/len(train_data):.4f}")return model
5.2 自注意力机制在推荐系统中的应用
自注意力机制(Self-Attention)能够捕捉序列数据中的长距离依赖关系,特别适合处理用户-物品交互序列。以下是基于自注意力的推荐模型示例:
# 简化版自注意力推荐模型
class SelfAttentionRecommender(nn.Module):def __init__(self, num_items, embedding_dim=32, num_heads=4):super(SelfAttentionRecommender, self).__init__()self.item_embedding = nn.Embedding(num_items, embedding_dim)self.position_embedding = nn.Embedding(50, embedding_dim) # 最多50个历史交互self.attention = nn.MultiheadAttention(embedding_dim, num_heads)self.fc = nn.Linear(embedding_dim, num_items)def forward(self, sequence, mask=None):# sequence: 用户的历史交互序列 [batch_size, seq_len]seq_len = sequence.size(1)# 获取物品嵌入和位置嵌入item_embedded = self.item_embedding(sequence) # [batch_size, seq_len, embedding_dim]position_ids = torch.arange(seq_len, device=sequence.device).unsqueeze(0)position_embedded = self.position_embedding(position_ids) # [1, seq_len, embedding_dim]# 结合物品嵌入和位置嵌入embedded = item_embedded + position_embedded# 应用自注意力机制 (需要转置以适应nn.MultiheadAttention的输入格式)embedded = embedded.transpose(0, 1) # [seq_len, batch_size, embedding_dim]attention_output, _ = self.attention(embedded, embedded, embedded, attn_mask=mask)attention_output = attention_output.transpose(0, 1) # [batch_size, seq_len, embedding_dim]# 取最后一个时间步的输出last_item_repr = attention_output[:, -1, :] # [batch_size, embedding_dim]# 预测下一个物品logits = self.fc(last_item_repr) # [batch_size, num_items]return logits
5.3 深度协同过滤的其他方法
除了上述方法外,还有多种深度学习方法应用于协同过滤:
- 深度矩阵分解:将传统矩阵分解与深度神经网络结合
- 自编码器:通过重构用户-物品交互矩阵学习隐藏表示
- 图神经网络:将用户-物品交互建模为二部图,利用GNN捕捉高阶连接关系
- 对比学习:学习用户和物品的表示,使相关对的表示相似而不相关对的表示不同
6. 实际应用案例
协同过滤技术已广泛应用于各种推荐系统中。以下是几个典型应用场景及其实现方式。
6.1 电子商务网站商品推荐
电商平台利用协同过滤向用户推荐可能感兴趣的商品。例如,当用户浏览某商品时,系统会显示"购买了此商品的用户还购买了…"或"与此商品相似的商品…"等推荐。
# 电商场景中的商品推荐示例代码
def recommend_products(user_id, purchase_history, product_similarity, n_recommendations=5):"""基于用户购买历史和商品相似度推荐商品参数:user_id: 用户IDpurchase_history: 用户购买历史字典 {user_id: [product_ids]}product_similarity: 商品相似度矩阵n_recommendations: 推荐商品数量"""# 获取用户已购买的商品purchased_products = purchase_history.get(user_id, [])if not purchased_products:return [] # 处理冷启动问题# 候选商品评分字典candidate_scores = {}# 基于用户已购买商品计算候选商品评分for purchased_product in purchased_products:# 获取与已购买商品相似的其他商品similar_products = product_similarity[purchased_product].items()for candidate, similarity in similar_products:# 排除用户已购买的商品if candidate not in purchased_products:# 累加相似度分数if candidate in candidate_scores:candidate_scores[candidate] += similarityelse:candidate_scores[candidate] = similarity# 排序并返回推荐结果recommendations = sorted(candidate_scores.items(), key=lambda x: x[1], reverse=True)return recommendations[:n_recommendations]
6.2 流媒体平台内容推荐
Netflix、Spotify等流媒体平台使用协同过滤为用户推荐电影、音乐等内容。这类平台通常结合多种方法,创建混合推荐系统。
# 在线视频平台的内容推荐系统示例
def hybrid_recommend(user_id, user_item_matrix, user_similarity, content_features, alpha=0.7):"""混合推荐函数:结合协同过滤和内容特征参数:user_id: 目标用户IDuser_item_matrix: 用户-物品评分矩阵user_similarity: 用户相似度矩阵content_features: 内容特征字典 {content_id: feature_vector}alpha: 协同过滤权重"""# 协同过滤推荐cf_recommendations = recommend_for_user(user_id, user_item_matrix, user_similarity)# 内容特征推荐 (简化版)viewed_contents = user_item_matrix.columns[user_item_matrix.loc[user_id] > 0]user_profile = np.zeros_like(list(content_features.values())[0])for content in viewed_contents:if content in content_features:rating = user_item_matrix.loc[user_id, content]user_profile += rating * content_features[content]# 计算内容相似度content_scores = {}for content_id, features in content_features.items():if content_id not in viewed_contents:similarity = np.dot(user_profile, features) / (np.linalg.norm(user_profile) * np.linalg.norm(features))content_scores[content_id] = similarity# 合并推荐结果hybrid_scores = {}all_items = set([item for item, _ in cf_recommendations] + list(content_scores.keys()))for item in all_items:cf_score = 0cb_score = 0# 获取协同过滤分数for cf_item, score in cf_recommendations:if cf_item == item:cf_score = scorebreak# 获取内容特征分数if item in content_scores:cb_score = content_scores[item]# 加权合并hybrid_scores[item] = alpha * cf_score + (1 - alpha) * cb_score# 排序并返回结果return sorted(hybrid_scores.items(), key=lambda x: x[1], reverse=True)
6.3 社交网络推荐
社交网络平台如Facebook、Twitter等使用协同过滤推荐好友、内容和广告。这些系统通常结合用户行为数据和社交关系数据,形成更复杂的混合推荐模型。推荐系统通常考虑以下因素:
- 用户行为相似性:喜欢或互动相似内容的用户
- 社交图谱关系:共同好友、社交距离等
- 内容特征:话题相关性、内容类型偏好等
- 时间因素:最近互动的内容和用户权重更高
7. 协同过滤的局限性及解决方案
尽管协同过滤在推荐系统中表现出色,但它也面临一些固有的挑战。
7.1 冷启动问题
新用户或新物品由于缺乏交互数据,难以纳入协同过滤模型。解决方案包括:
# 处理冷启动问题的示例代码
def recommend_for_new_user(user_demographic, item_demographics, popular_items):"""为新用户生成推荐参数:user_demographic: 用户人口统计特征item_demographics: 物品人口统计特征字典popular_items: 热门物品列表及其流行度"""# 基于人口统计特征的相似度计算demographic_scores = {}for item_id, item_demo in item_demographics.items():# 计算用户特征与物品目标受众特征的匹配度similarity = compute_demographic_similarity(user_demographic, item_demo)demographic_scores[item_id] = similarity# 结合物品流行度final_scores = {}for item_id, demo_score in demographic_scores.items():popularity = popular_items.get(item_id, 0)# 加权组合(可以调整权重)final_scores[item_id] = 0.6 * demo_score + 0.4 * popularity# 返回最终推荐return sorted(final_scores.items(), key=lambda x: x[1], reverse=True)def compute_demographic_similarity(user_demo, item_demo):"""计算人口统计特征相似度(示例)"""# 这里可以实现具体的相似度计算逻辑# 例如,基于年龄、性别、兴趣等维度计算return 0.5 # 占位返回值
其他冷启动解决方案包括:
- 基于内容的初始推荐:利用用户或物品的内容特征
- 主动学习:策略性地获取新用户对特定物品的反馈
- 混合模型:结合基于知识的推荐和协同过滤
- 迁移学习:从相关领域转移知识
7.2 稀疏性问题
在大多数推荐系统中,用户只与很小一部分物品有交互,导致用户-物品矩阵极度稀疏。矩阵分解和深度学习方法可以有效缓解这一问题,此外还有:
- 数据降维技术:如PCA、NMF等
- 图算法:利用图结构传播信息
- 聚类方法:在较密集的子空间内进行推荐
7.3 可扩展性问题
随着用户和物品数量的增加,计算复杂度也随之增加。常见解决方案包括:
- 使用基于物品的协同过滤:通常物品数量少于用户数量
- 局部敏感哈希(LSH):快速近似最近邻搜索
- 采样技术:随机选择用户或物品子集进行计算
- 分布式计算:利用Spark等框架并行处理大规模数据
7.4 多样性与过度专业化问题
纯粹的协同过滤可能导致推荐结果过于相似,缺乏多样性。解决方案包括:
- 再排序策略:在保持相关性的同时增加多样性
- 探索与利用平衡:引入一定比例的随机或不确定推荐
- 基于内容的多样性度量:确保推荐物品在特征空间中的分散性
8. 评估框架与指标
推荐系统的评估是确保其有效性的关键环节。评估可分为离线评估和在线评估两种主要方式。
8.1 常用评估指标
# 实现常用推荐系统评估指标
import numpy as np
from sklearn.metrics import mean_squared_error
from math import sqrtdef rmse(predictions, targets):"""均方根误差"""return sqrt(mean_squared_error(targets, predictions))def precision_at_k(recommended_items, relevant_items, k=10):"""计算Precision@K"""# 取前k个推荐物品recommended_k = recommended_items[:k]# 计算准确预测的物品数num_hit = len(set(recommended_k).intersection(set(relevant_items)))return num_hit / kdef recall_at_k(recommended_items, relevant_items, k=10):"""计算Recall@K"""# 取前k个推荐物品recommended_k = recommended_items[:k]# 计算准确预测的物品数num_hit = len(set(recommended_k).intersection(set(relevant_items)))return num_hit / len(relevant_items) if len(relevant_items) > 0 else 0def ndcg_at_k(recommended_items, relevant_items, k=10):"""计算NDCG@K (归一化折损累积增益)"""# 取前k个推荐物品recommended_k = recommended_items[:k]# 为推荐物品分配相关性分数 (二元相关性)relevance = [1 if item in relevant_items else 0 for item in recommended_k]# 计算DCGdcg = sum((2**rel - 1) / np.log2(i+2) for i, rel in enumerate(relevance))# 计算IDCG (理想情况下的DCG)ideal_relevance = sorted([1 if item in relevant_items else 0 for item in recommended_items], reverse=True)[:k]idcg = sum((2**rel - 1) / np.log2(i+2) for i, rel in enumerate(ideal_relevance))return dcg / idcg if idcg > 0 else 0def diversity(recommended_items, item_features):"""计算推荐列表的多样性"""if len(recommended_items) <= 1:return 0# 计算推荐物品之间的平均不相似度total_dissimilarity = 0count = 0for i in range(len(recommended_items)):for j in range(i+1, len(recommended_items)):item_i = recommended_items[i]item_j = recommended_items[j]# 计算特征之间的余弦相似度similarity = np.dot(item_features[item_i], item_features[item_j]) / (np.linalg.norm(item_features[item_i]) * np.linalg.norm(item_features[item_j]))# 转换为不相似度dissimilarity = 1 - similaritytotal_dissimilarity += dissimilaritycount += 1return total_dissimilarity / count if count > 0 else 0def novelty(recommended_items, item_popularity):"""计算推荐列表的新颖性 (基于物品流行度的倒数)"""return np.mean([-np.log2(item_popularity[item]) for item in recommended_items if item in item_popularity and item_popularity[item] > 0])
这些指标各自关注推荐系统的不同方面:
- 准确性指标:RMSE、MAE、Precision@K、Recall@K、NDCG@K
- 多样性指标:列表内部多样性、覆盖率
- 新颖性指标:推荐物品的平均流行度倒数
- 意外性指标:推荐与用户历史物品的不相似程度
- 用户满意度指标:用户点击率、转化率、停留时间等
8.2 离线与在线评估方法
# 离线评估:时间分割验证
def temporal_split_evaluation(user_item_data, timestamp_col, model_func, k=10):"""使用时间分割进行离线评估参数:user_item_data: 包含用户-物品交互的DataFrametimestamp_col: 时间戳列名model_func: 训练模型的函数,接收训练数据并返回能生成推荐的模型k: 推荐列表长度"""# 按时间戳排序sorted_data = user_item_data.sort_values(by=timestamp_col)# 使用前80%数据作为训练集train_size = int(len(sorted_data) * 0.8)train_data = sorted_data.iloc[:train_size]test_data = sorted_data.iloc[train_size:]# 训练模型model = model_func(train_data)# 评估模型results = {}precisions = []recalls = []ndcgs = []# 对测试集中的每个用户进行评估for user_id in test_data['user_id'].unique():# 获取用户在测试集中的实际交互user_test_items = test_data[test_data['user_id'] == user_id]['item_id'].tolist()if len(user_test_items) == 0:continue# 生成推荐recommended_items = model.recommend(user_id, k=k)# 计算评估指标precision = precision_at_k(recommended_items, user_test_items, k)recall = recall_at_k(recommended_items, user_test_items, k)ndcg = ndcg_at_k(recommended_items, user_test_items, k)precisions.append(precision)recalls.append(recall)ndcgs.append(ndcg)# 返回平均指标results['Precision@K'] = np.mean(precisions)results['Recall@K'] = np.mean(recalls)results['NDCG@K'] = np.mean(ndcgs)return results# 在线A/B测试模拟
def ab_test_simulation(user_groups, recommendation_strategies, metrics_func, simulation_days=7):"""模拟在线A/B测试参数:user_groups: 用户分组字典 {group_name: [user_ids]}recommendation_strategies: 推荐策略字典 {strategy_name: strategy_func}metrics_func: 用于计算指标的函数simulation_days: 模拟天数"""results = {strategy: [] for strategy in recommendation_strategies}for day in range(simulation_days):daily_metrics = {}for strategy_name, strategy_func in recommendation_strategies.items():user_group = user_groups[strategy_name]# 为该组用户生成推荐recommendations = {user: strategy_func(user) for user in user_group}# 模拟用户互动并计算指标metrics = metrics_func(recommendations, day)daily_metrics[strategy_name] = metricsresults[strategy_name].append(metrics)print(f"Day {day+1} results:", daily_metrics)# 计算累计指标for strategy in results:avg_metrics = {metric: np.mean([day[metric] for day in results[strategy]]) for metric in results[strategy][0]}print(f"Strategy '{strategy}' average metrics:", avg_metrics)return results
在线评估主要考量以下指标:
- 点击率(CTR):用户点击推荐物品的概率
- 转化率:用户完成目标行为(如购买)的比例
- 会话时长:用户在平台停留时间
- 留存率:用户继续使用系统的比例
- 收入指标:如ARPU(平均每用户收入)
9. 协同过滤的前沿研究方向
协同过滤领域正经历快速发展,以下是几个重要的前沿研究方向。
9.1 图神经网络在推荐系统中的应用
用户-物品交互自然形成二部图结构,图神经网络可以有效捕捉这种结构化信息。
# PyTorch Geometric实现的简化GNN推荐模型
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.data import Dataclass GNNRecommender(torch.nn.Module):def __init__(self, num_users, num_items, embedding_dim=64):super(GNNRecommender, self).__init__()self.num_users = num_usersself.num_items = num_items# 初始嵌入层self.embedding = torch.nn.Embedding(num_users + num_items, embedding_dim)# 图卷积层self.conv1 = GCNConv(embedding_dim, embedding_dim)self.conv2 = GCNConv(embedding_dim, embedding_dim)def forward(self, edge_index):# 获取所有节点的初始嵌入x = self.embedding.weight# 通过图卷积层x = F.relu(self.conv1(x, edge_index))x = F.dropout(x, p=0.2, training=self.training)x = self.conv2(x, edge_index)return xdef recommend(self, user_id, k=10):"""为用户生成前k个推荐"""with torch.no_grad():# 获取用户嵌入和所有物品嵌入user_emb = self.final_embeddings[user_id]item_embs = self.final_embeddings[self.num_users:self.num_users + self.num_items]# 计算用户与所有物品的点积相似度scores = torch.matmul(user_emb, item_embs.t())# 获取前k个物品索引_, indices = torch.topk(scores, k)return indices.cpu().numpy()
GNN推荐系统的优势包括:
- 高阶连接关系:捕捉用户和物品之间的多跳关系
- 异质图建模:可以统一建模不同类型的节点和关系
- 结构感知能力:利用图结构信息提升推荐质量
9.2 跨域推荐系统
跨域推荐利用不同领域的用户偏好信息来改进推荐质量。
# 跨域矩阵分解示例代码
class CrossDomainMF:def __init__(self, num_users, num_items_domain1, num_items_domain2, num_factors=10, alpha=0.01, beta=0.01):"""跨域矩阵分解模型参数:num_users: 用户数量num_items_domain1: 领域1的物品数量num_items_domain2: 领域2的物品数量num_factors: 潜在因子数量alpha, beta: 正则化参数"""self.num_factors = num_factorsself.alpha = alphaself.beta = beta# 初始化模型参数# 用户特征矩阵 - 共享部分self.user_features_shared = np.random.normal(0, 0.1, (num_users, num_factors))# 用户特征矩阵 - 领域特定部分self.user_features_domain1 = np.random.normal(0, 0.1, (num_users, num_factors))self.user_features_domain2 = np.random.normal(0, 0.1, (num_users, num_factors))# 物品特征矩阵self.item_features_domain1 = np.random.normal(0, 0.1, (num_items_domain1, num_factors))self.item_features_domain2 = np.random.normal(0, 0.1, (num_items_domain2, num_factors))def predict(self, user_id, item_id, domain):"""预测用户对物品的评分"""if domain == 1:user_features = self.user_features_shared[user_id] + self.user_features_domain1[user_id]item_features = self.item_features_domain1[item_id]else:user_features = self.user_features_shared[user_id] + self.user_features_domain2[user_id]item_features = self.item_features_domain2[item_id]return np.dot(user_features, item_features)def train(self, ratings_domain1, ratings_domain2, epochs=20, learning_rate=0.01):"""训练模型参数:ratings_domain1: 领域1的评分数据,格式为(user_id, item_id, rating)的列表ratings_domain2: 领域2的评分数据,格式为(user_id, item_id, rating)的列表"""for epoch in range(epochs):# 更新领域1参数for user_id, item_id, rating in ratings_domain1:predicted = self.predict(user_id, item_id, domain=1)error = rating - predicted# 梯度下降更新user_shared_grad = -2 * error * self.item_features_domain1[item_id] + 2 * self.alpha * self.user_features_shared[user_id]user_domain1_grad = -2 * error * self.item_features_domain1[item_id] + 2 * self.alpha * self.user_features_domain1[user_id]item_grad = -2 * error * (self.user_features_shared[user_id] + self.user_features_domain1[user_id]) + 2 * self.beta * self.item_features_domain1[item_id]self.user_features_shared[user_id] -= learning_rate * user_shared_gradself.user_features_domain1[user_id] -= learning_rate * user_domain1_gradself.item_features_domain1[item_id] -= learning_rate * item_grad# 更新领域2参数for user_id, item_id, rating in ratings_domain2:predicted = self.predict(user_id, item_id, domain=2)error = rating - predicted# 梯度下降更新user_shared_grad = -2 * error * self.item_features_domain2[item_id] + 2 * self.alpha * self.user_features_shared[user_id]user_domain2_grad = -2 * error * self.item_features_domain2[item_id] + 2 * self.alpha * self.user_features_domain2[user_id]item_grad = -2 * error * (self.user_features_shared[user_id] + self.user_features_domain2[user_id]) + 2 * self.beta * self.item_features_domain2[item_id]self.user_features_shared[user_id] -= learning_rate * user_shared_gradself.user_features_domain2[user_id] -= learning_rate * user_domain2_gradself.item_features_domain2[item_id] -= learning_rate * item_grad
跨域推荐的应用场景包括:
- 电商与媒体内容:利用用户购物习惯推荐视频内容
- 多类型商品:如图书和电影的联合推荐
- 多平台用户行为:整合用户在不同平台的行为数据
9.3 强化学习在推荐系统中的应用
强化学习可以将推荐问题视为连续决策过程,优化长期用户体验。
# 简化版强化学习推荐系统框架
class RLRecommender:def __init__(self, num_users, num_items, state_dim=50):"""基于强化学习的推荐系统参数:num_users: 用户数量num_items: 物品数量state_dim: 状态向量维度"""self.num_users = num_usersself.num_items = num_itemsself.state_dim = state_dim# 用户和物品嵌入self.user_embeddings = np.random.normal(0, 0.1, (num_users, state_dim//2))self.item_embeddings = np.random.normal(0, 0.1, (num_items, state_dim//2))# Q网络 (这里简化为线性模型)self.q_weights = np.random.normal(0, 0.1, (state_dim, num_items))def get_state(self, user_id, history_items):"""构建状态表示参数:user_id: 用户IDhistory_items: 用户历史交互物品列表"""# 获取用户嵌入user_emb = self.user_embeddings[user_id]# 获取历史物品嵌入的平均值if not history_items:history_emb = np.zeros(self.state_dim//2)else:history_emb = np.mean([self.item_embeddings[item_id] for item_id in history_items], axis=0)# 连接用户嵌入和历史嵌入state = np.concatenate([user_emb, history_emb])return statedef act(self, state, epsilon=0.1):"""选择动作(推荐物品)参数:state: 当前状态epsilon: 探索率"""if np.random.random() < epsilon:# 探索:随机选择物品return np.random.randint(self.num_items)else:# 利用:选择Q值最高的物品q_values = np.dot(state, self.q_weights)return np.argmax(q_values)def update(self, state, action, reward, next_state, alpha=0.01, gamma=0.9):"""更新Q值参数:state: 当前状态action: 选择的动作(物品ID)reward: 获得的奖励next_state: 下一个状态alpha: 学习率gamma: 折扣因子"""# 计算当前Q值current_q = np.dot(state, self.q_weights[:, action])# 计算下一状态的最大Q值next_max_q = np.max(np.dot(next_state, self.q_weights))# TD目标td_target = reward + gamma * next_max_q# TD误差td_error = td_target - current_q# 更新Q权重self.q_weights[:, action] += alpha * td_error * state
强化学习推荐系统的优势:
- 长期收益优化:关注用户长期满意度而非即时点击
- 实时交互:能够适应用户兴趣变化
- 探索与利用平衡:系统性地解决冷启动和多样性问题
9.4 因果推断与可解释推荐
随着对算法公平性和透明度的关注增加,可解释推荐和因果推断成为重要研究方向。核心思想包括:
- 因果关系建模:区分相关性和因果关系,理解用户行为背后的真实原因
- 反事实推理:分析"如果用户看到不同推荐会怎样"的假设情景
- 可解释模型设计:构建本质上可解释的模型架构
- 后验解释生成:为推荐结果生成自然语言解释
10. 系统工程与实践考量
将协同过滤算法应用于实际生产环境,需要考虑多方面的工程实现问题。
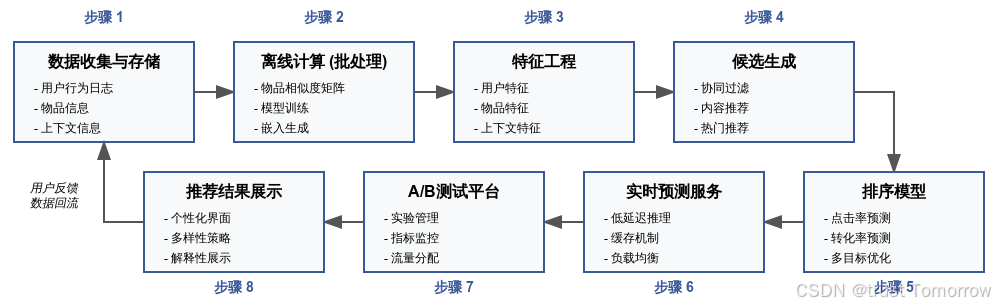
10.1 大规模推荐系统架构
实际的推荐系统通常包含以下主要组件:
10.2 性能优化和扩展性考量
在大规模应用场景中,需要考虑以下性能优化策略:
# 近似最近邻搜索示例 (使用Annoy库)
from annoy import AnnoyIndexdef build_ann_index(item_vectors, n_trees=10):"""构建近似最近邻索引参数:item_vectors: 物品向量字典 {item_id: vector}n_trees: 树的数量 (增加树可提高精度但增加内存使用)"""# 获取向量维度vector_dim = len(next(iter(item_vectors.values())))# 创建索引index = AnnoyIndex(vector_dim, 'angular') # 使用角度距离(适合余弦相似度)# 添加物品向量for item_id, vector in item_vectors.items():index.add_item(item_id, vector)# 构建索引index.build(n_trees)return indexdef get_similar_items(index, item_id, item_vectors, n=10):"""获取与指定物品最相似的n个物品参数:index: AnnoyIndex实例item_id: 目标物品IDitem_vectors: 物品向量字典n: 返回的相似物品数量"""# 获取目标物品的向量vector = item_vectors[item_id]# 查找最近邻similar_ids = index.get_nns_by_vector(vector, n+1) # +1 因为会包含物品自身# 过滤掉物品自身similar_ids = [idx for idx in similar_ids if idx != item_id]return similar_ids[:n]
其他性能优化策略包括:
- 分层推荐架构:将推荐过程分为候选生成和精排两个阶段
- 特征预计算:离线计算并缓存重要特征
- 模型压缩:量化、剪枝等技术减少模型大小
- 缓存策略:合理利用内存缓存热门结果
- 分布式计算:利用Spark、TensorFlow分布式等框架
10.3 在线学习与增量更新
实际系统中,用户行为数据持续产生,需要及时更新模型。
# 在线学习矩阵分解示例
class OnlineMF:def __init__(self, num_users, num_items, num_factors=10, learning_rate=0.01, regularization=0.01):"""支持在线学习的矩阵分解模型"""self.num_factors = num_factorsself.learning_rate = learning_rateself.regularization = regularization# 初始化用户和物品因子self.user_factors = np.random.normal(0, 0.1, (num_users, num_factors))self.item_factors = np.random.normal(0, 0.1, (num_items, num_factors))# 用户和物品偏置self.user_biases = np.zeros(num_users)self.item_biases = np.zeros(num_items)self.global_bias = 0def predict(self, user_id, item_id):"""预测用户对物品的评分"""prediction = self.global_biasprediction += self.user_biases[user_id]prediction += self.item_biases[item_id]prediction += np.dot(self.user_factors[user_id], self.item_factors[item_id])return predictiondef update(self, user_id, item_id, rating):"""在线更新模型参数参数:user_id: 用户IDitem_id: 物品IDrating: 实际评分"""# 计算预测评分predicted = self.predict(user_id, item_id)# 计算误差error = rating - predicted# 更新全局偏置self.global_bias += self.learning_rate * (error - self.regularization * self.global_bias)# 更新用户和物品偏置self.user_biases[user_id] += self.learning_rate * (error - self.regularization * self.user_biases[user_id])self.item_biases[item_id] += self.learning_rate * (error - self.regularization * self.item_biases[item_id])# 更新用户和物品因子user_factors_grad = error * self.item_factors[item_id] - self.regularization * self.user_factors[user_id]item_factors_grad = error * self.user_factors[user_id] - self.regularization * self.item_factors[item_id]self.user_factors[user_id] += self.learning_rate * user_factors_gradself.item_factors[item_id] += self.learning_rate * item_factors_grad
在线学习系统的设计考量包括:
- 增量更新机制:支持模型参数的高效局部更新
- 特征演化跟踪:检测并适应物品特征和用户兴趣的变化
- 系统架构设计:设计允许并行处理和分布式更新的架构
- 实时-批处理混合模式:结合实时更新和周期性批处理重训练
11. 总结与展望
协同过滤作为推荐系统的核心技术,已经从最初的基于记忆的简单算法发展为结合深度学习、强化学习等先进技术的复杂系统。本文详细介绍了协同过滤的基本原理、实现方法、评估框架以及前沿发展方向。
11.1 技术演进路线
协同过滤技术的发展经历了以下阶段:
- 基于记忆的方法:使用相似度计算的简单直观方法
- 基于模型的方法:如矩阵分解等利用机器学习的方法
- 深度学习方法:利用神经网络捕捉复杂非线性关系
- 混合与集成方法:综合多种技术的优势
- 情境感知推荐:考虑时间、位置等上下文信息
- 因果推断与可解释推荐:关注推荐的公平性和透明度
11.2 未来发展趋势
协同过滤技术未来可能的发展方向包括:
- 自监督学习:利用大量未标记数据进行预训练
- 多模态融合:整合文本、图像、视频等多种模态信息
- 知识图谱增强:结合知识图谱提升推荐系统的推理能力
- 元学习推荐:快速适应新用户和新场景的推荐方法
- 隐私保护推荐:在确保用户隐私的同时提供个性化推荐
- 大型语言模型(LLM)与推荐系统结合:利用LLM的强大语义理解和推理能力
11.3 产业应用前景
协同过滤技术在各行业的应用前景广阔:
- 电子商务:个性化产品推荐、购物路径优化
- 内容平台:视频、音乐、新闻等内容推荐
- 广告系统:精准广告投放、RTB(实时竞价)
- 社交网络:好友推荐、内容分发
- 智能教育:个性化学习路径和资源推荐
- 健康医疗:健康建议、医疗资源匹配
- 金融服务:金融产品推荐、智能投资顾问


---单向循环链表)

