- 模型权重文件:存储训练好的模型参数,也就是w和b,是模型推理和微调的基础
.pt、.ckpt、.safetensors、gguf
- 配置文件:确保模型架构的一致性,使得权重文件能够正确加载
config.json、generation_config.json
- 词汇表文件:保证输入输出的一致性
tokenizer.json、tokenizer_config.json
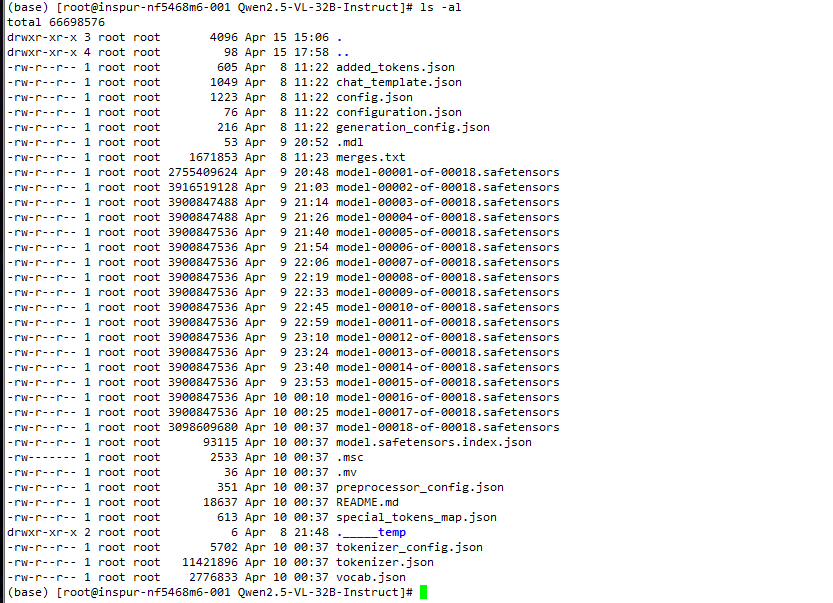
1、模型权重文件
- 模型权重文件是存储训练好的模型参数,是模型推理和微调的基础 ,常见的有.pt、.ckpt、.safetensors
- 不同的框架(如TensorFlow、PyTorch)使用不同的模型文件格式
例如:
- safetensors:适配多种框架,支持transformers库的模型加载
- PyTorch:选择下载.pt或.bin格式的模型文件。
- TensorFlow:选择下载.ckpt或.h5格式的模型文件。
1.1 safetensors是什么?
- .safetensors是由Hugging Face提出的一种新型的模型权重文件格式,有以下特点:
- 安全性:.safetensors采用了加密和校验机制,防止模型文件被篡改或注入恶意代码
- 性能:优化了数据加载和解析速度
- 跨框架支持:有多种深度学习框架的兼容性,便于在不同环境中使用
- .safetensors中,大模型可被分为多个部分,格式类似modelname-0001.safetensors、modelname-0002.safetensors
- model.safetensors.index.json是索引文件,记录了模型的各个部分的位置和大小信息
2、配置文件
- config.json、generation_config.json
2.1 config.json
- config.json包含模型的配置信息(如模型架构、参数设置等),可能包含隐藏层的数量、每层的神经元数、注意力头的数量等
- config.json的基本结构如下:
(base) [root@inspur-nf5468m6-001 Qwen2.5-VL-32B-Instruct]# cat config.json
{"architectures": ["Qwen2_5_VLForConditionalGeneration"],"attention_dropout": 0.0,"eos_token_id": 151645,"hidden_act": "silu","hidden_size": 5120,"image_token_id": 151655,"initializer_range": 0.02,"intermediate_size": 27648,"max_position_embeddings": 128000,"max_window_layers": 64,"model_type": "qwen2_5_vl","num_attention_heads": 40,"num_hidden_layers": 64,"num_key_value_heads": 8,"pad_token_id": 151643,"rms_norm_eps": 1e-06,"rope_scaling": {"mrope_section": [16,24,24],"rope_type": "default","type": "default"},"rope_theta": 1000000.0,"sliding_window": 32768,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.49.0","use_cache": true,"use_sliding_window": false,"video_token_id": 151656,"vision_config": {"hidden_size": 1280,"in_chans": 3,"intermediate_size": 3456,"model_type": "qwen2_5_vl","out_hidden_size": 5120,"spatial_patch_size": 14,"tokens_per_second": 2,"torch_dtype": "bfloat16"},"vision_end_token_id": 151653,"vision_start_token_id": 151652,"vision_token_id": 151654,"vocab_size": 152064
}- 例如architectures字段指定了模型的架构,hidden_act字段指定了隐藏层的激活函数,hidden_size字段指定了隐藏层的神经元数
- num_attention_heads字段指定了注意力头的数量,max_position_embeddings字段指定了模型能处理的最大输入长度等
2.2 generation_config.json
generation_config.json是用于生成文本的配置文件,包含了生成文本时的参数设置,如max_length、temperature、top_k等generation_config.json的基本结构如下:
(base) [root@inspur-nf5468m6-001 Qwen2.5-VL-32B-Instruct]# cat generation_config.json
{"bos_token_id": 151643,"pad_token_id": 151643,"do_sample": true,"eos_token_id": [151645,151643],"repetition_penalty": 1.05,"temperature": 0.000001,"transformers_version": "4.49.0"
}- 例如bos_token_id字段指定了开始标记的ID,eos_token_id字段指定了结束标记的ID,do_sample字段指定了是否使用采样,temperature字段用于控制生成文本的随机性,max_length字段指定了生成文本的最大长度,top_p字段指定了采样的概率等
- config.json 和 generation_config.json 都可能包含 "bos_token_id"(Beginning of Sequence Token ID)和 "eos_token_id"(End of Sequence Token ID)。在config.json中,这两个字段用于模型的加载和训练,而在generation_config.json中,这两个字段用于生成文本时的参数设置
- config.json 提供模型的基本信息,而 generation_config.json 则细化为生成任务的具体需求
3、词汇表文件
词汇表文件包含了模型使用的词汇表或标记器信息,是自然语言处理模型理解和生成文本的基础。
tokenizer.json、tokenizer_config.json
3.1 tokenizer.json
tokenizer.json包含了模型使用的词汇表信息,如词汇表的大小、特殊标记的ID等tokenizer.json的基本结构如下:
{"version": "1.0","truncation": {"max_length": 128,"strategy": "longest_first"},"padding": {"side": "right","pad_id": 0,"pad_token": "[PAD]"},"added_tokens": [{"id": 128010,"content": "[CUSTOM]"}],"normalizer": {"type": "NFD","lowercase": true,"strip_accents": true},"pre_tokenizer": {"type": "ByteLevel","add_prefix_space": true},"post_processor": {"type": "AddSpecialTokens","special_tokens": {"cls_token": "[CLS]","sep_token": "[SEP]"}},"decoder": {"type": "ByteLevel"},"model": {"type": "BPE",...}
}
- 其中truncation是定义截断策略,用于限制输入序列的最大长度,padding用于统一输入序列的长度,added_tokens列出分词器额外添加到词汇表中的特殊标记或自定义标记
- normalizer用于定义文本标准化的步骤和规则,用于在分词前对输入文本进行预处理,pre_tokenizer定义分词器如何将输入文本分割为初步的tokens,post_processor定义分词后处理的步骤
- decoder定义如何将tokens ID 序列解码回原始文本,model定义了分词器的模型信息,如词汇表、合并规则(对于 BPE)等
3.2 tokenizer_config.json
tokenizer_config.json是用于生成文本的配置文件,包含了生成文本时的参数设置,如max_length、temperature、top_k等tokenizer_config.json的基本结构如下:
{"added_tokens_decoder": [],"bos_token": "begin_of_text |>","clean_up_tokenization_spaces": true,"eos_token": "<|end_of_text|>","model_input_names": ["input_ids", "attention_mask"],"model_max_length": 1000000,"tokenizer_class": "PreTrainedTokenizerFast"
}
- 其中added_tokens_decoder定义分词器在解码(将 token ID 转换回文本)过程中需要额外处理的特殊标记或自定义标记
- bos_token、eos_token定义开始、结束标记,clean_up_tokenization_spaces定义了是否清除分词后的多余空格等
- tokenizer.json和tokenizer_config.json的区别:tokenizer.json侧重于分词器的训练和加载,而tokenizer_config.json更侧重于生成文本时的参数设置
为什么很多模型都没有 vocab.txt 了?现代分词器采用了更为丰富和灵活的文件格式,如 tokenizer.json,以支持更复杂的分词策略和特殊标记处理
一、背景介绍
在AI模型部署领域,模型格式的选择直接影响推理效率、内存占用和跨平台兼容性。Safetensors和GGUF作为两种重要格式,分别服务于不同的应用场景:
- Safetensors
- 基于protobuf的二进制格式,提供安全的张量存储
- 支持分片(sharding)和加密功能
- 广泛用Hugging Face生态系统
- 典型应用:模型微调、分布式训练
- GGUF
- 基于GGML生态的新型格式(GGML v2)
- 针对CPU推理优化的内存布局
- 支持多种量化模式(4/5/8bit)
- 典型应用:边缘设备部署、低资源环境
本文将详细讲解如何通过Transformers框架将Safetensors模型转换为GGUF格式,并深入探讨转换过程中的关键技术细节。
二、转换原理与核心流程
2.1 格式转换的本质
Safetensors到GGUF的转换本质是: 1. 张量数据的序列化格式转换 2. 内存布局的优化重组 3. 可选的量化参数调整
2.2 核心转换流程
graph TDA[Safetensors模型] --> B[加载模型权重]B --> C[转换为PyTorch张量]C --> D[执行量化操作]D --> E[生成GGUF格式文件]E --> F[验证输出文件]三、环境准备
3.1 依赖安装
# 安装Transformers库
pip install transformers# 安装GGUF工具链
pip install llama-cpp-python3.2 硬件要求
- CPU:Intel/AMD x86-64架构(推荐支持AVX2指令集)
- 内存:至少为模型未量化状态的2倍
- 存储:SSD推荐(处理大模型时提升速度)
公司环境 .
四、转换步骤详解
4.1 加载Safetensors模型
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "Qwen/Qwen2.5-VL-32B-Instruct"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="gpu")
tokenizer = AutoTokenizer.from_pretrained(model_name)4.2 初始化GGUF转换器
from llama_cpp import GGUFConverterconverter = GGUFConverter(model=model,tokenizer=tokenizer,max_seq_len=2048,target_format="ggufv2"
)4.3 执行转换操作
output_path = "Qwen2.5-VL-32B-Instruct.gguf"
converter.convert(output_path=output_path,quantization="q4_0", # 可选量化模式force=True # 覆盖已有文件
)4.4 验证转换结果
from llama_cpp import Llamallm = Llama(model_path=output_path,n_ctx=2048,n_threads=8
)prompt = "你好,我是jettech"
output = llm(prompt, max_tokens=512)
print(output["choices"][0]["text"])五、高级配置选项
5.1 量化参数设置
| 参数名称 | 说明 | 推荐值 |
|---|---|---|
| quantization | 量化模式 | "q4_0" |
| group_size | 量化分组大小(影响精度) | 128 |
| use_mmap | 使用内存映射加速加载 | True |
5.2 内存优化策略
# 启用内存优化模式
converter = GGUFConverter(...,memory_friendly=True,temp_dir="/tmp/gguf_conversion"
)六、常见问题与解决方案
6.1 转换失败处理
- 错误信息:
Invalid tensor shape
解决方案:检查模型架构是否兼容(需为CausalLM类型) - 错误信息:
Out of memory
解决方案:分块处理模型(使用chunk_size参数)
七、格式对比与应用场景
7.1 关键指标对比
| 指标 | Safetensors | GGUF |
|---|---|---|
| 典型文件大小 | 原始浮点数 | 量化后1/4-1/8 |
| 加载速度 | 较慢(需反序列化) | 极快(内存映射) |
| 推理速度 | CPU/GPU优化 | CPU极致优化 |
| 跨平台支持 | 全平台 | x86/ARM |
7.2 适用场景推荐
- Safetensors:模型训练、GPU推理、云服务部署
- GGUF:边缘设备、低功耗CPU、嵌入式系统
八、未来发展趋势
- 多模态支持:GGUF计划支持图像/音频模型
- 动态量化:运行时自适应量化技术
- 生态整合:Hugging Face官方可能提供直接转换工具


---单向循环链表)

