1. YOLO系列整体介绍
YOLO属于深度学习经典检测方法中的单阶段(one - stage)类型,与两阶段(two - stage,如Faster - rcnn、Mask - Rcnn系列)方法相对。
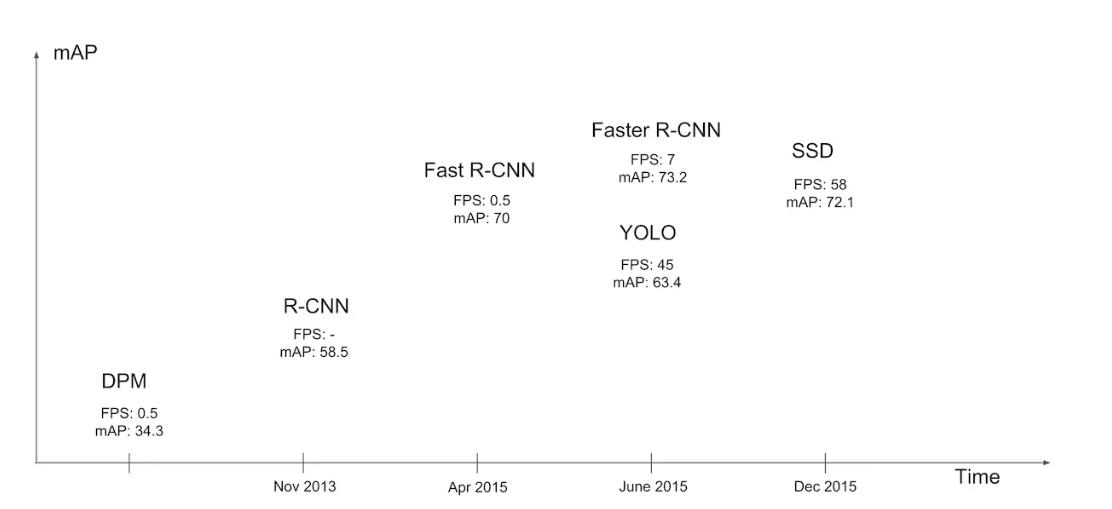
不同模型性能
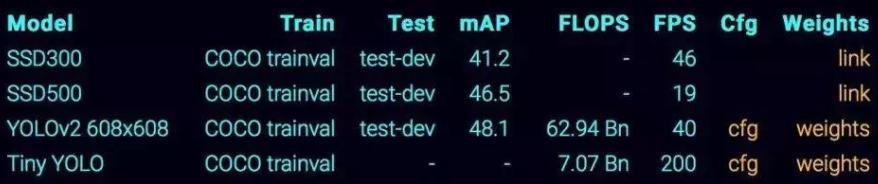
单阶段方法的最核心优势是速度非常快,适合做实时检测任务,但通常检测效果不如两阶段方法
2. 指标分析
map指标:综合衡量检测效果,不能仅依靠精度(Precision)和召回率(Recall)来评估检测模型性能。


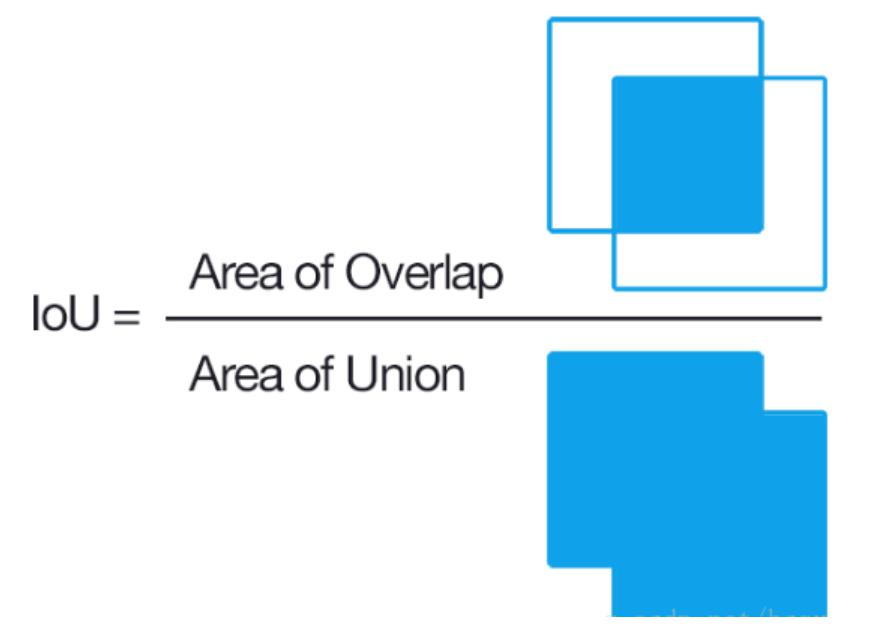
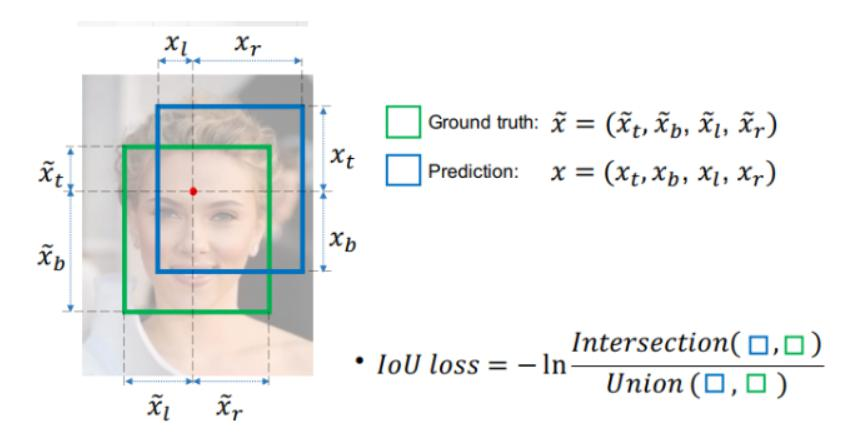
IOU(交并比):计算公式为,用于衡量预测框与真实框的重叠程度。
Precision和Recall:
Precision(精度)公式为,
Recall(召回率)公式为。
基于置信度阈值来计算,例如分别计算0.9;0.8;0.7
0.9时:TP+FP = 1,TP = 1 ;FN = 2;Precision=1/1;Recall=1/3;
AP与MAP:
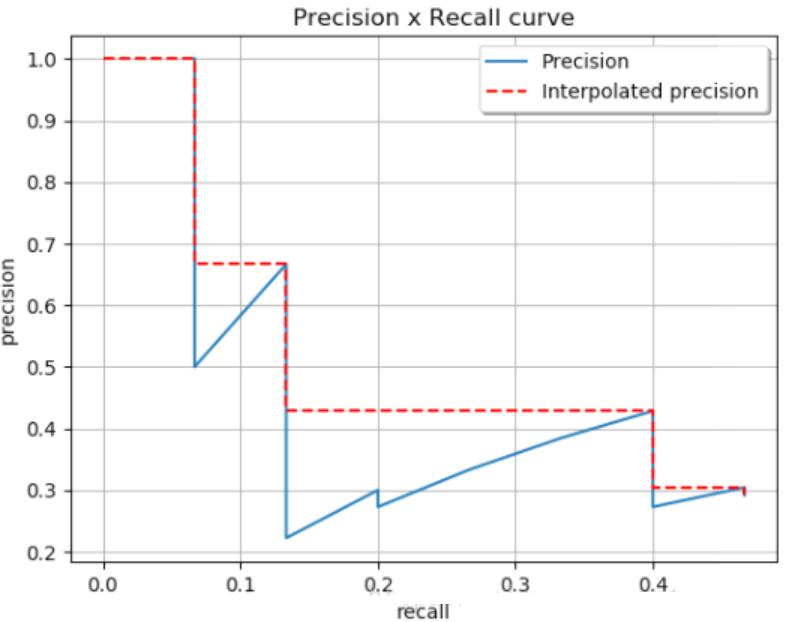
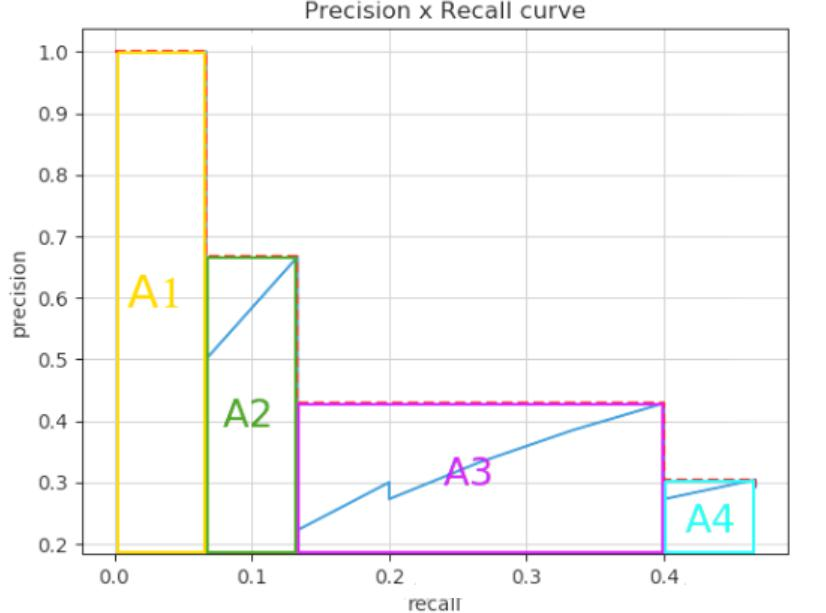
AP(Average Precision)计算需要考虑所有阈值,MAP(Mean Average Precision)是所有类别的平均AP,通过Precision - Recall曲线来理解。
3. YOLO - V1
核心思想与方法:
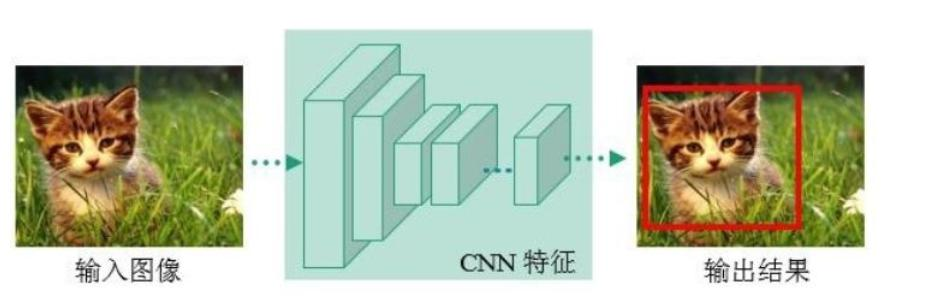
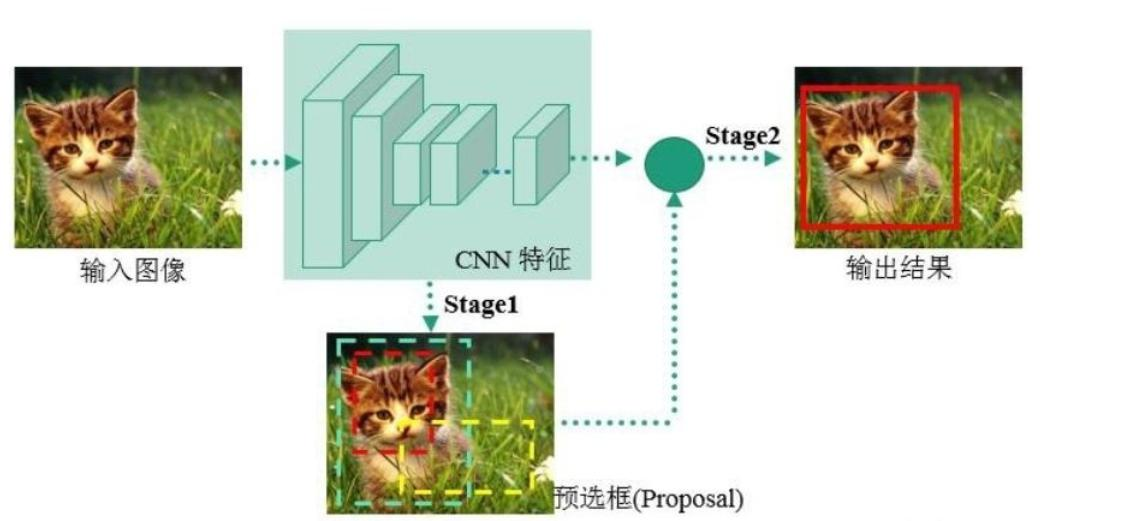
经典的one - stage方法,把检测问题转化成回归问题,使用一个CNN即可完成检测任务。
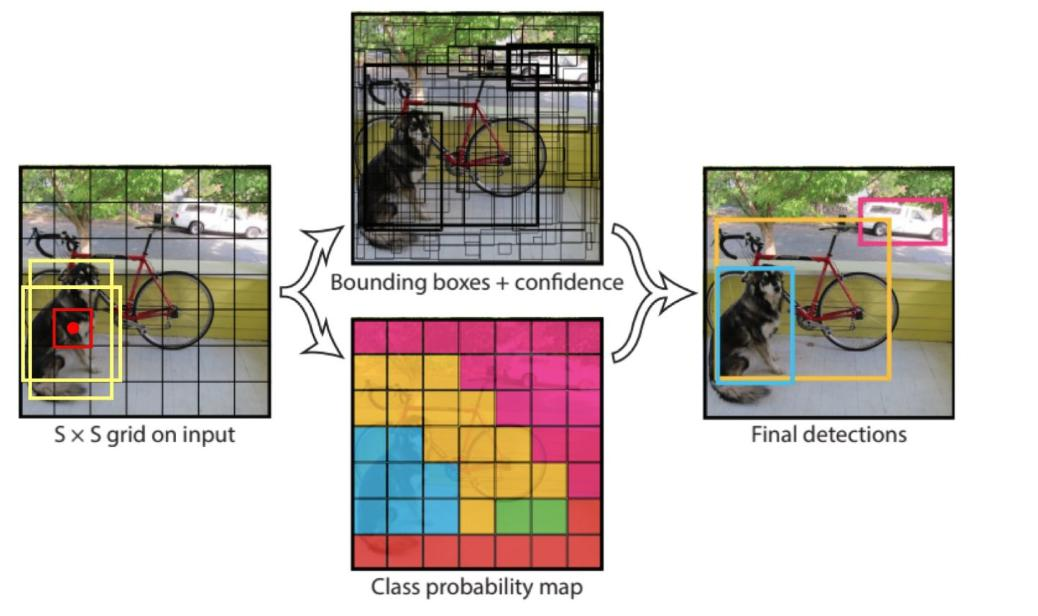
应用领域:可以对视频进行实时检测,应用领域广泛。
性能指标对比:
网络架构:输入图像后经过一系列卷积层(CR)、全连接层(FC)处理,最终输出预测结果。7×7表示最终网格的大小,每个网格预测B个边界框,每个边界框包含位置(X, Y, H, W)、置信度C等信息。
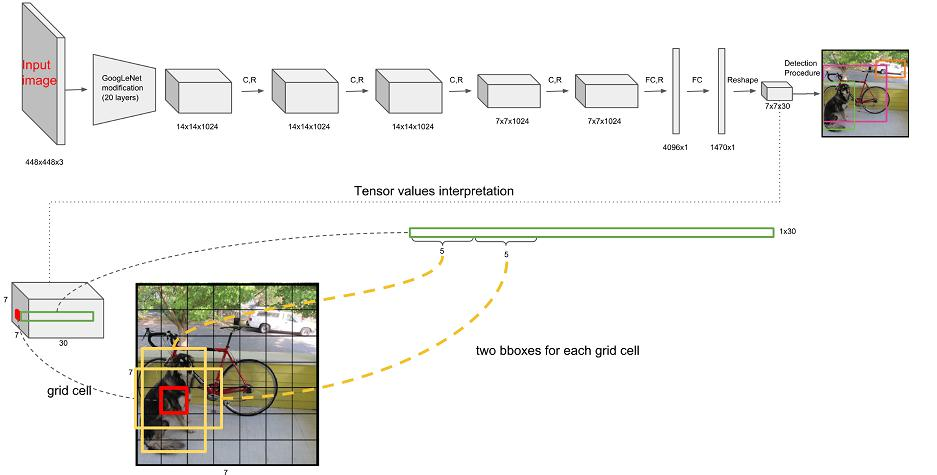
7×7表示最终网格的大小,每个网格预测B个边界框,每个边界框包含位置(X, Y, H, W)、置信度C等信息。
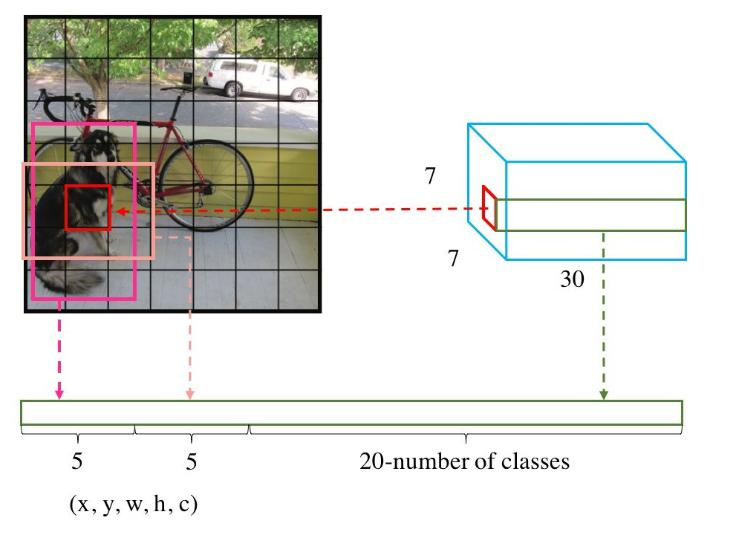
每个数字的含义:
10 =(X,Y,H,W,C)*B(2个)当前数据集中有20个类别,
7*7表示最终网格的大小(S*S)*(B*5+C)
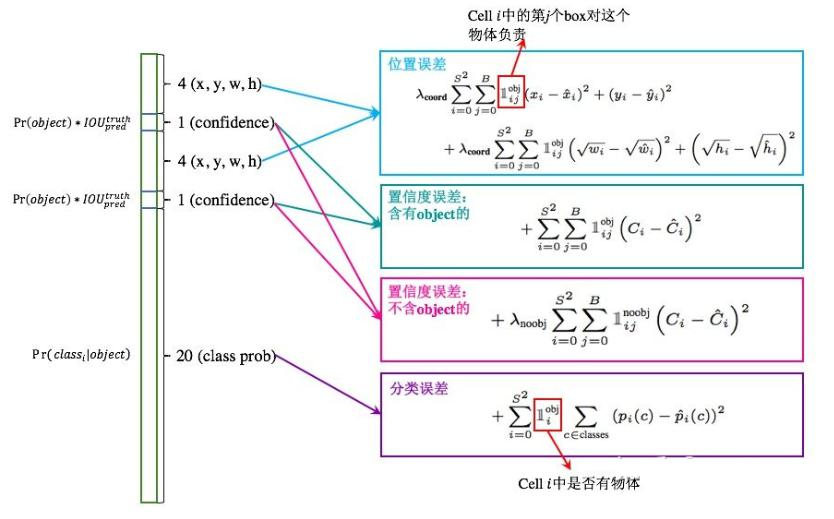
损失函数:包含位置误差、置信度误差(分含有物体和不含物体两种情况)、分类误差。
NMS(非极大值抑制)
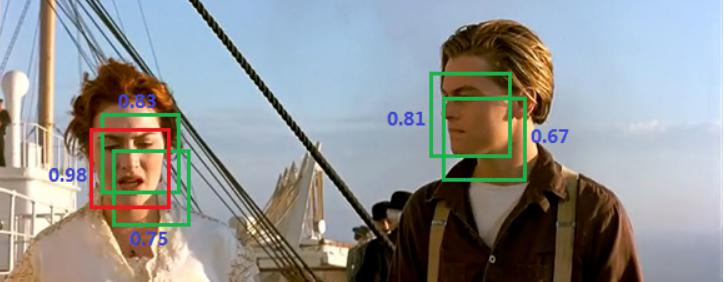
优点与问题:优点是快速、简单;问题在于每个Cell只预测一个类别,重叠物体检测存在困难,小物体检测效果一般,长宽比可选但单一。
4. YOLO - V2
整体提升:相比YOLO - V1更快、更强,在VOC2007数据集上mAP达到78.6。
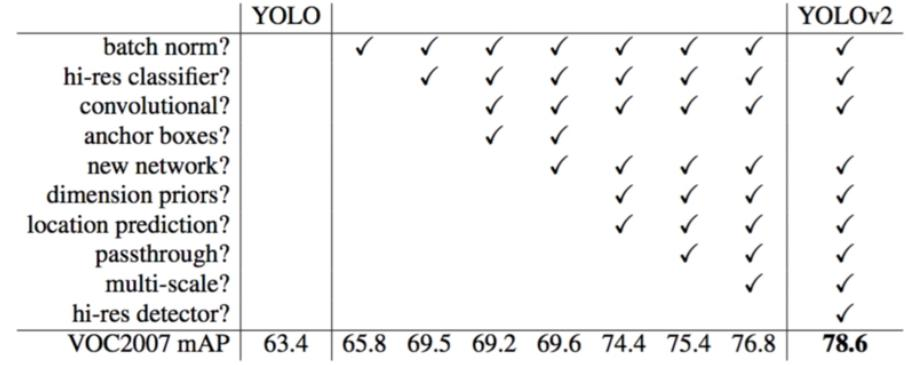
改进点
Batch Normalization:舍弃Dropout,卷积后全部加入Batch Normalization,使网络每一层输入归一化,收敛更容易,mAP提升2%。
更大的分辨率:V1训练和测试分辨率不同,训练时用的是224*224,测试时使用448*448,可能导致模型水土不服。V2训练时额外进行10次448×448的微调,使用高分辨率分类器后,mAP提升约4%。
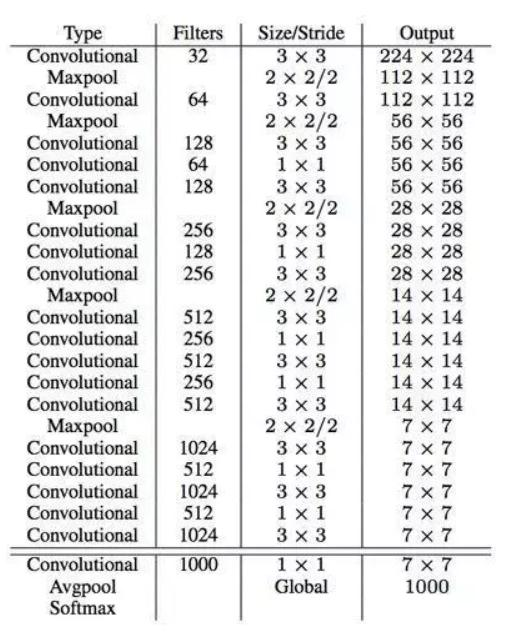
网络结构:采用DarkNet架构,实际输入为416×416,没有FC层,5次降采样,通过1×1卷积节省参数。
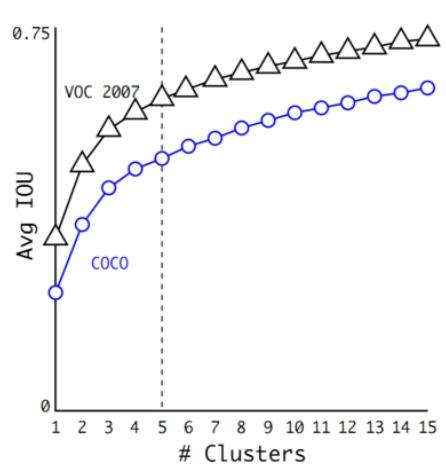
聚类提取先验框:通过K - means聚类确定先验框,使预测的box数量更多(13×13×n),先验框不是直接按固定长宽比给定,引入anchor boxes后召回率提升。
Anchor Box:
通过引入anchor boxes,使得预测的box数量更多(13*13*n)
跟faster-rcnn系列不同的是先验框并不是直接按照长宽固定比给定

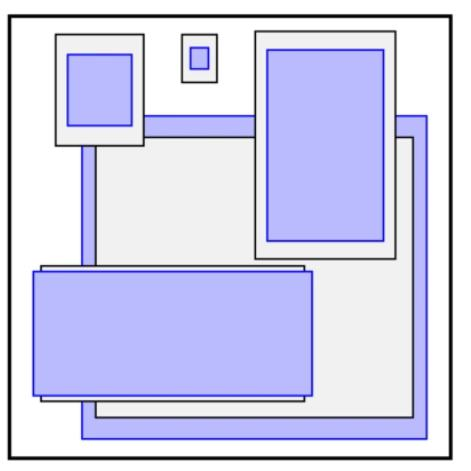
Directed Location Prediction:改进位置预测方式,使用相对grid cell的偏移量,避免模型不稳定问题,计算公式为
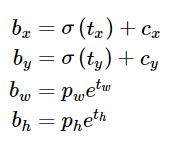
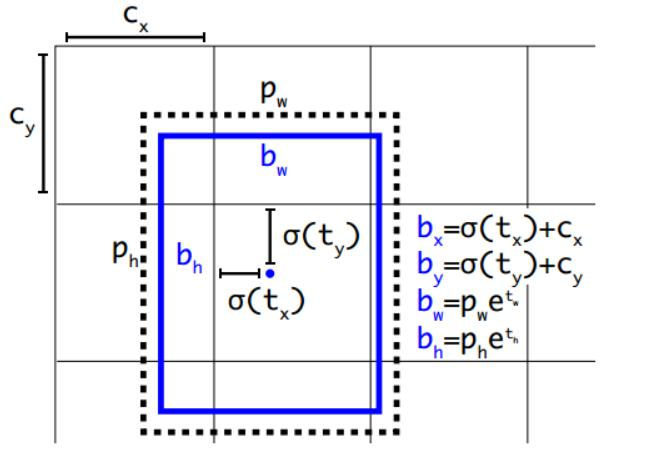
例如预测值(σtx,σty,tw,th)=(0.2,0.1,0.2,0.32),anchor框为:
![]()
在特征图位置:
在原位置:
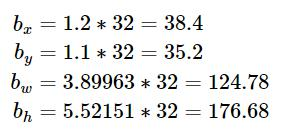
感受野与小卷积核优势:
概述来说就是特征图上的点能看到原始图像多大区域
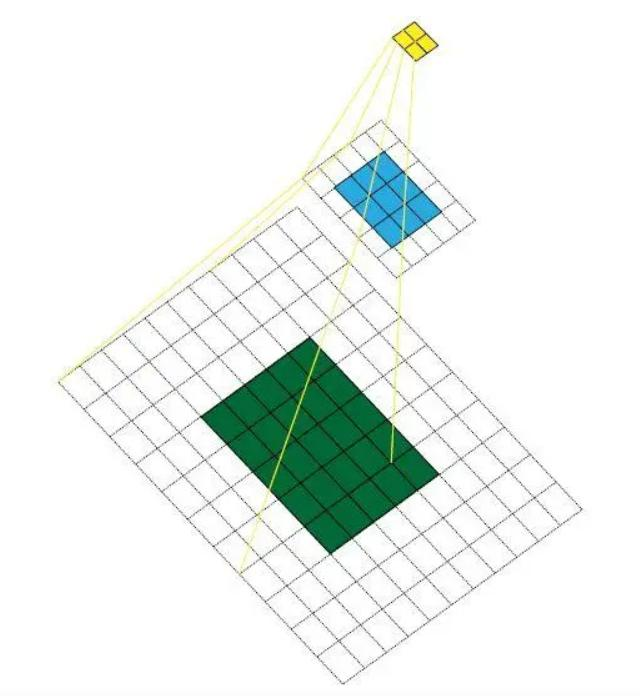
如果堆叠3个3*3的卷积层,并且保持滑动窗口步长为1,其感受野就是7*7的了,这跟一个使用7*7卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
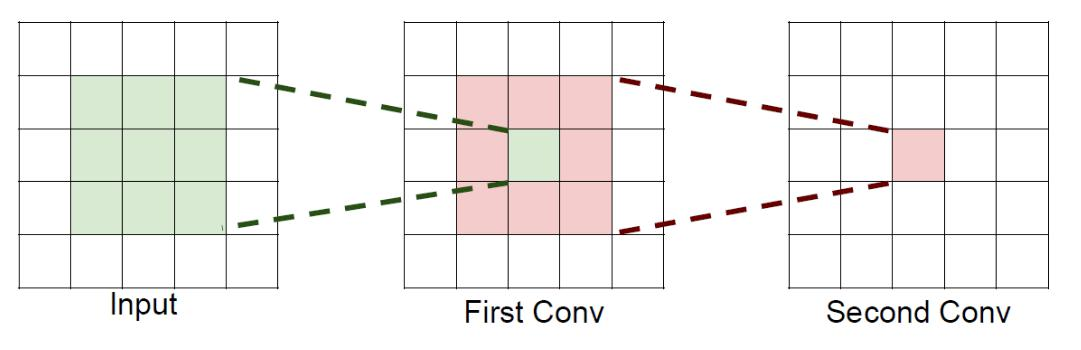
假设输入大小都是h*w*c,并且都使用c个卷积核(得到c个特征图),可以来计算一下其各自所需参数:
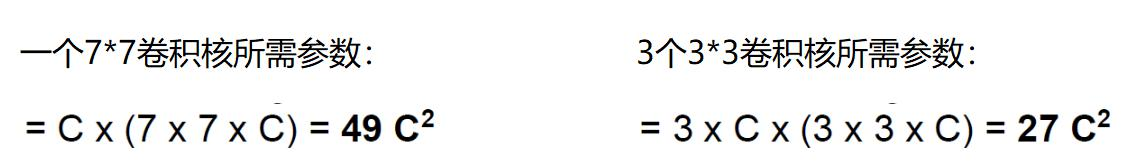
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,这就是VGG网络的基本出发点,用小的卷积核来完成体特征提取操作。
Fine - Grained Features:融合之前的特征,解决最后一层感受野太大导致小目标可能丢失的问题。
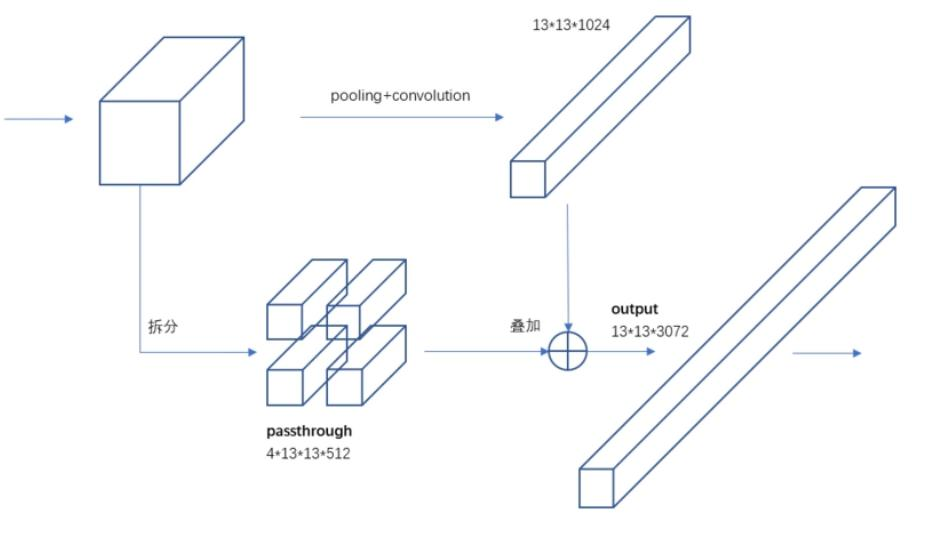
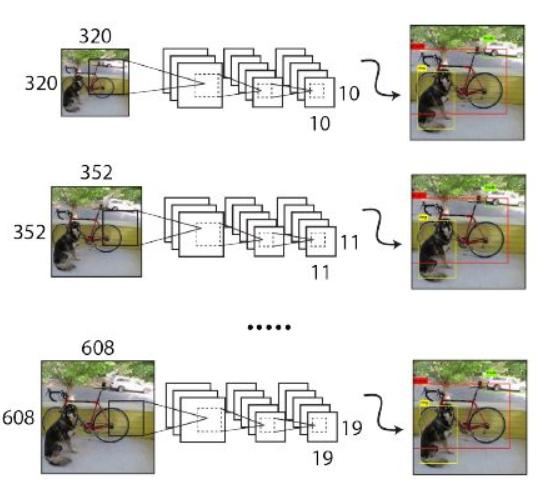
Multi - Scale:利用卷积操作特性,在一定iterations之后改变输入图片大小,最小320×320,最大608×608,以适应不同尺度目标检测。
5. YOLO - V3
主要改进:最大改进在于网络结构,更适合小目标检测。特征提取更细致,融入多尺度特征图信息预测不同规格物体,先验框更丰富(3种scale,每种3个规格,共9种),改进softmax用于预测多标签任务。
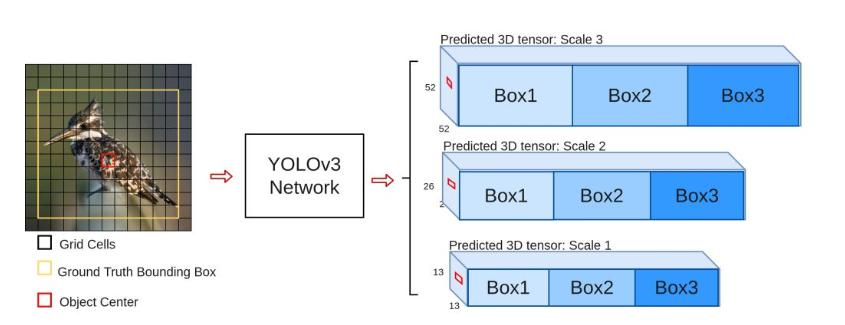
多scale检测:设计3个scale用于检测不同大小物体,介绍了不同scale的预测张量以及与特征图的关系。
cale变换经典方法
左图:对不同的特征图分别利用;右图:不同的特征图融合后进行预测
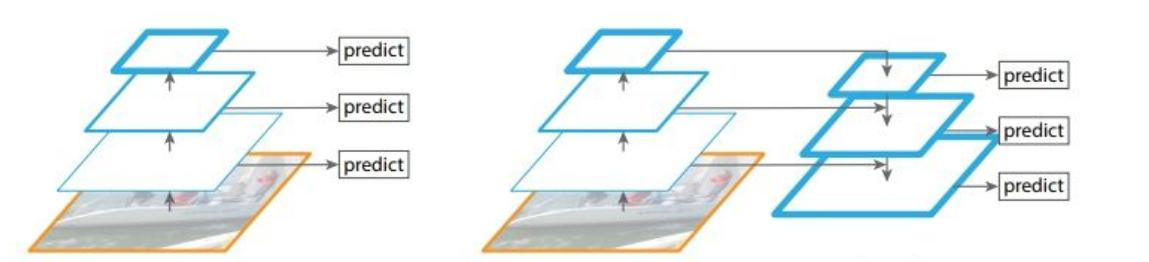
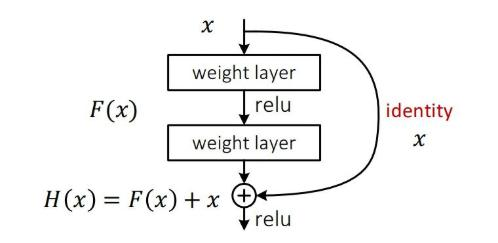
残差连接:采用resnet的思想,堆叠更多层进行特征提取,利用残差连接提升性能。从今天的角度来看,基本所有网络架构都用上了残差连接的方法
核心网络架构:没有池化和全连接层,全部采用卷积,下采样通过stride为2实现,展示了网络的输入、卷积层操作以及输出的相关信息。
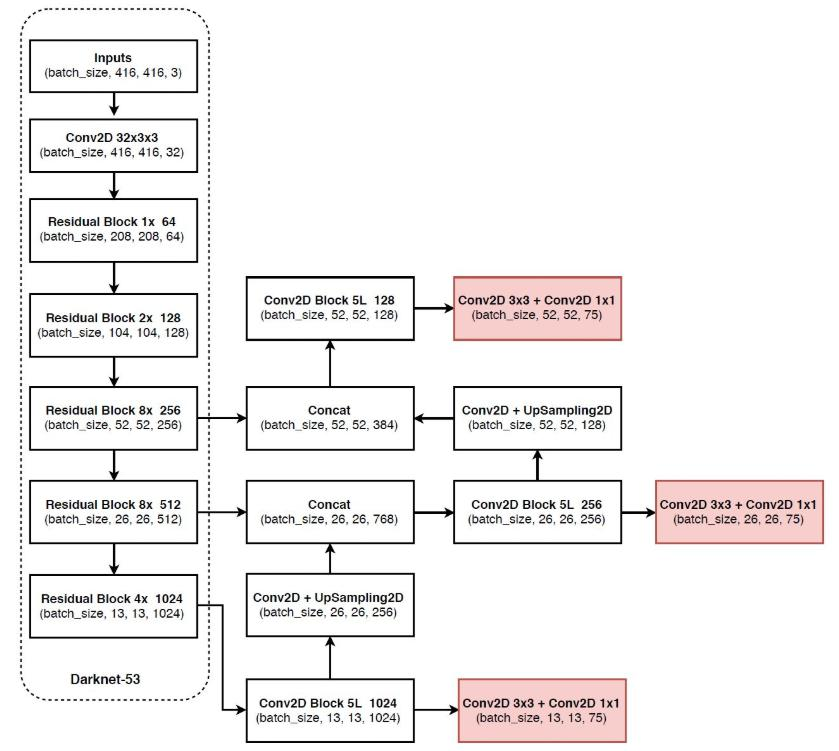
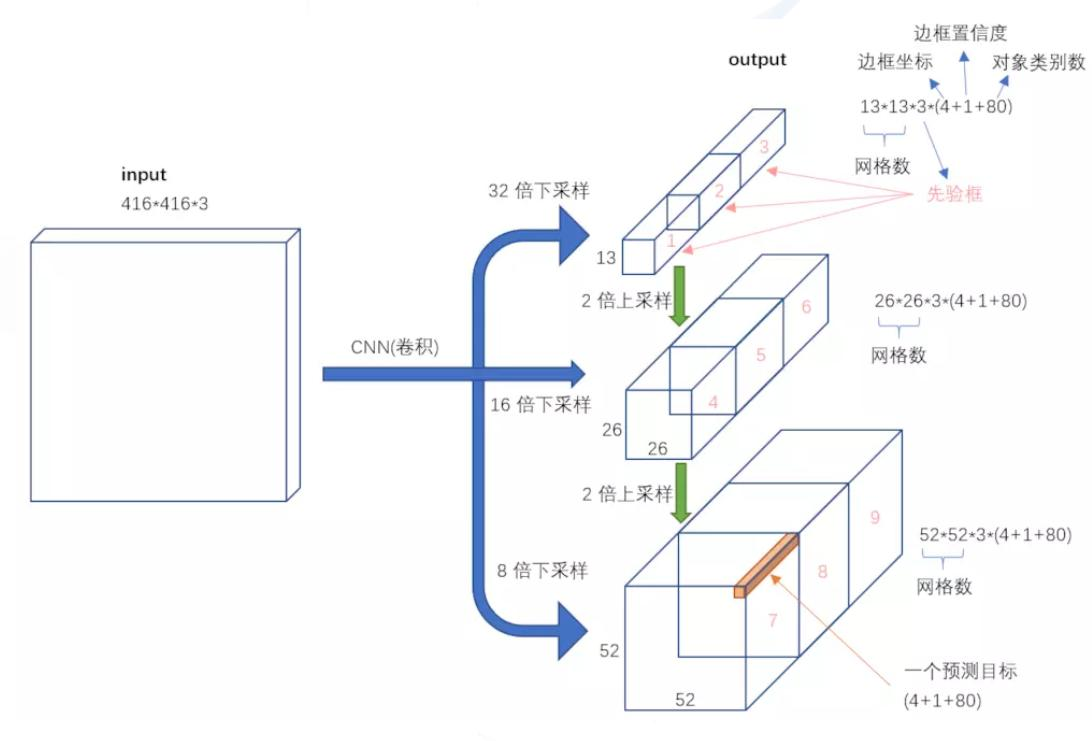
先验框设计:
13*13特征图上:(116x90),(156x198),(373x326)26*26特征图上:(30x61),(62x45),(59x119)
52*52特征图上:(10x13),(16x30),(33x23)

softmax层替代:使用logistic激活函数替代softmax,用于预测物体的多个标签。
6. YOLO - V4
整体介绍:虽作者更换,但核心精髓未变,在单GPU上训练效果良好,从数据层面和网络设计层面进行大量改进。
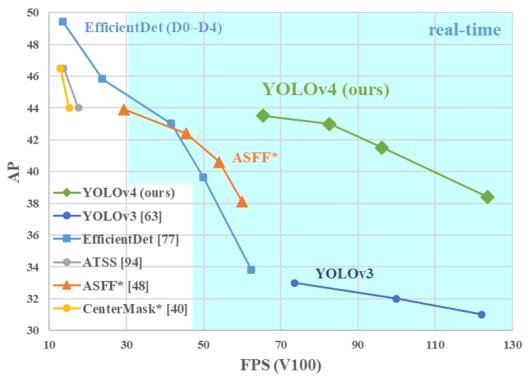
V4贡献:
亲民政策,单GPU就能训练的非常好,接下来很多小模块都是这个出发点两大核心方法,从数据层面和网络设计层面来进行改善
消融实验,工作量不轻全部实验都是单GPU完成
Bag of freebies(BOF)
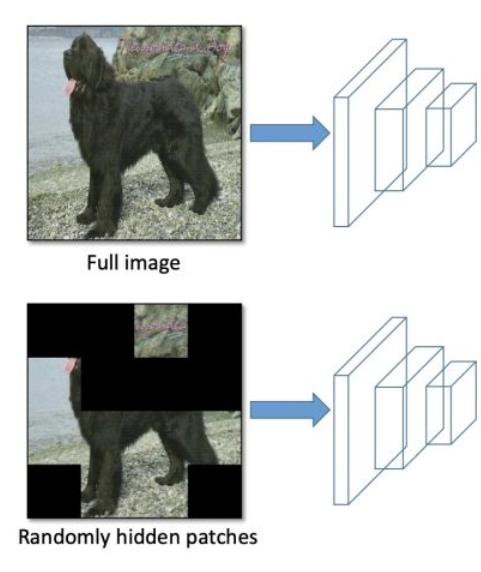
数据增强:包括调整亮度、对比度、色调、随机缩放、剪切、翻转、旋转,Mosaic数据增强(四张图像拼接成一张训练)、Random Erase(用随机值或训练集平均像素值替换图像区域)、Hide and Seek(根据概率随机隐藏一些补丁)等方法。
Mosaic data augmentation
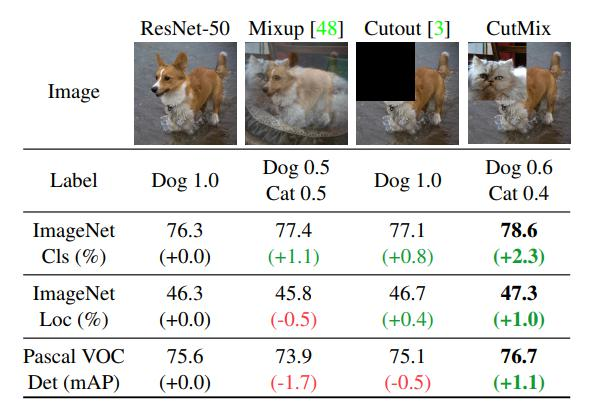

Random Erase:用随机值或训练集的平均像素值替换图像的区域
Hide and Seek:根据概率设置随机隐藏一些补丁

网络正则化与损失函数:采用Dropout、Dropblock等网络正则化方法,处理类别不平衡问题,设计合适的损失函数。
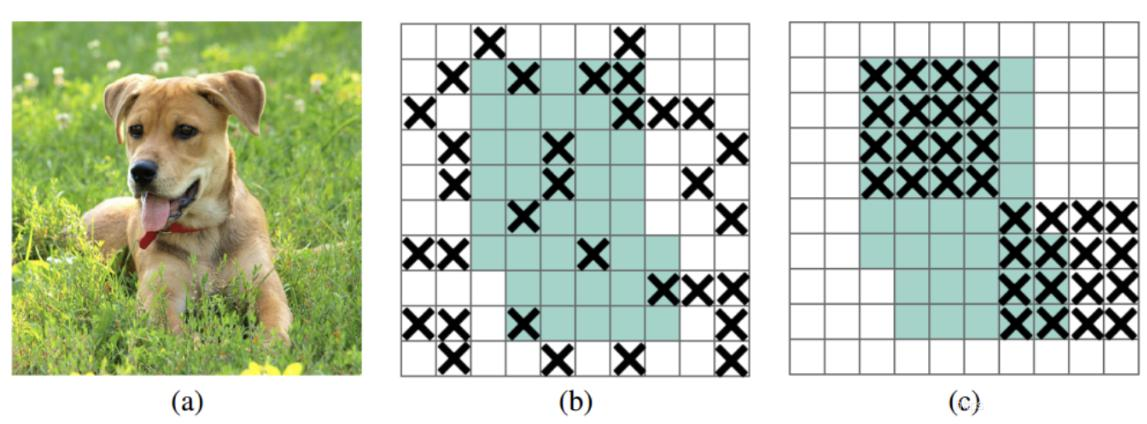
DropBlock
之前的dropout是随机选择点(b),现在吃掉一个区域
训练优化相关方法
Self-adversarial-training(SAT)
通过引入噪音点来增加游戏难度
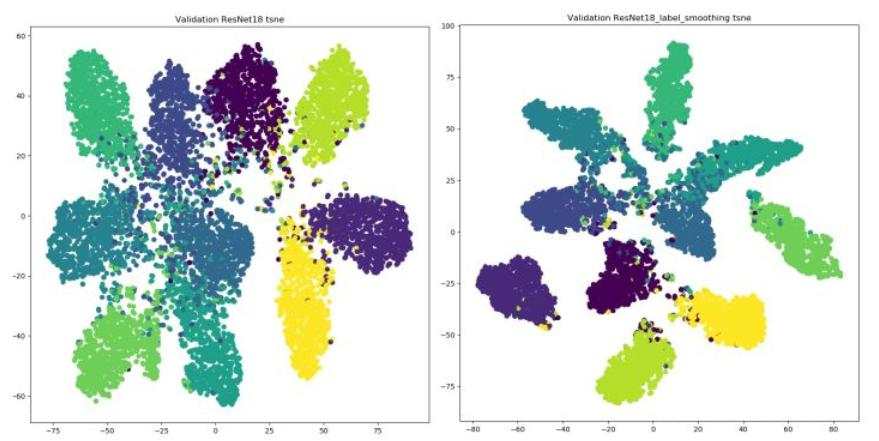
Label Smoothing:
神经网络最大的缺点:自觉不错(过拟合),让它别太自信例如原来标签为(0,1):![]()
缓解神经网络过拟合问题,使标签取值范围从(0,1)调整为[0.05,0.95],使用后能使簇内更紧密,簇间更分离。
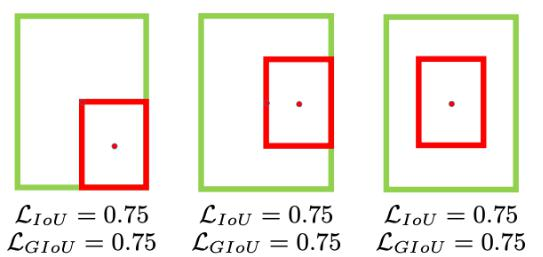
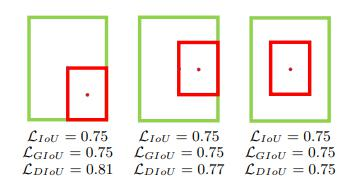
IOU相关损失函数:
IOU损失(1 - IOU)存在的问题,如无相交时无法梯度计算、相同IOU无法反映实际情况;
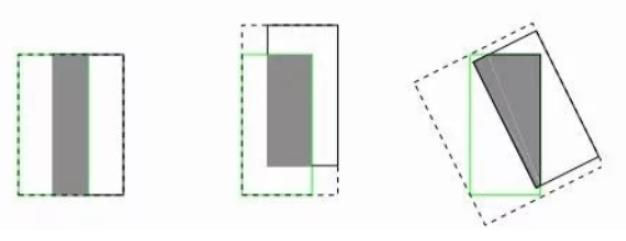
GIOU损失(引入最小封闭形状C)、DIOU损失(直接优化距离)、CIOU损失(考虑重叠面积、中心点距离、长宽比三个几何因素)。
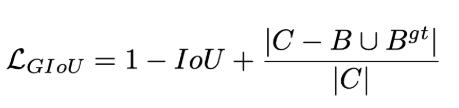
DIOU损失:
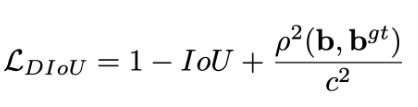
其中分子计算预测框与真实框的中心点欧式距离d 分母是能覆盖预测框与真实框的最小BOX的对角线长度c 直接优化距离,速度更快,并解决GIOU问题
CIOU损失:损失函数必须考虑三个几何因素:重叠面积,中心点距离,长宽比 其中α可以当做权重参数
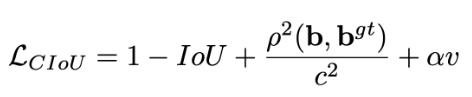
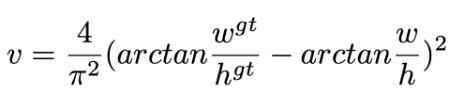
![]()
DIOU - NMS(不仅考虑IoU值,还考虑两个Box中心点之间的距离)和SOFT - NMS(柔和处理,更改分数而非直接剔除)。
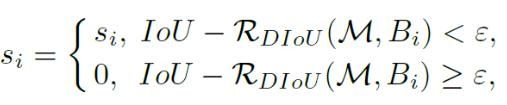
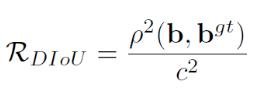
SOFT-NMS
Bag of specials(BOS)
网络改进方法:增加稍许推断代价但可提高模型精度,包括网络细节部分的改进,引入注意力机制、特征金字塔等方法。
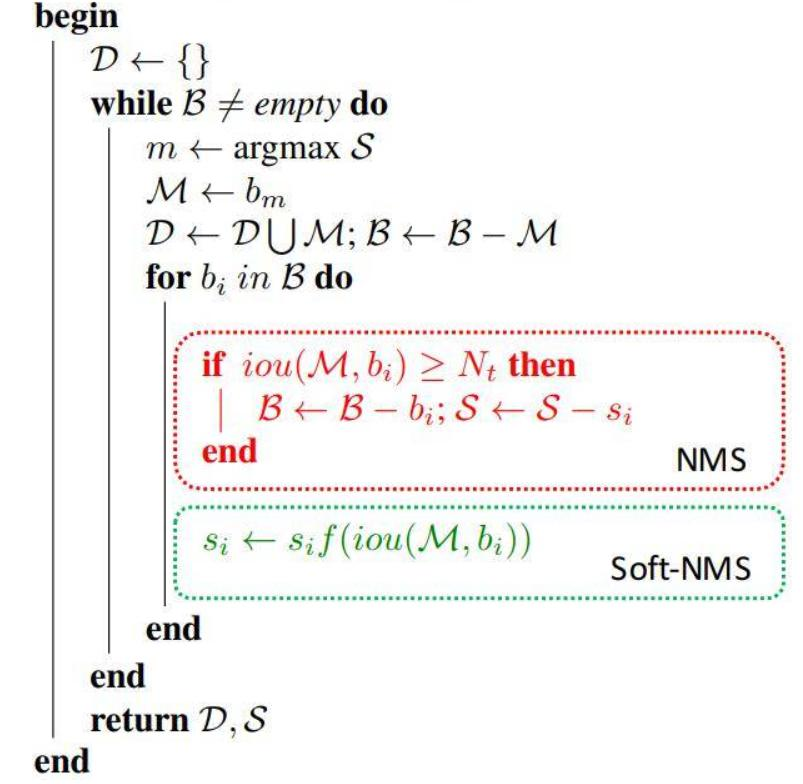
SPPNet(Spatial Pyramid Pooling)(用最大池化满足最终输入特征一致)
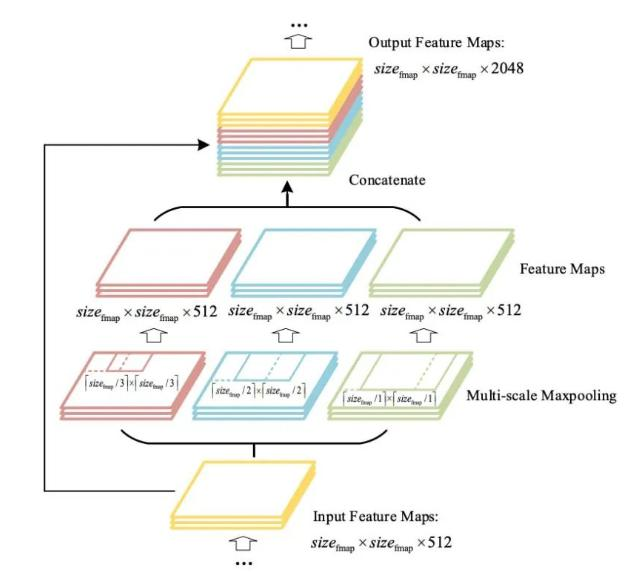
CSPNet(Cross Stage Partial Network)(按特征图channel维度拆分,一部分正常走网络,一部分直接concat到输出)
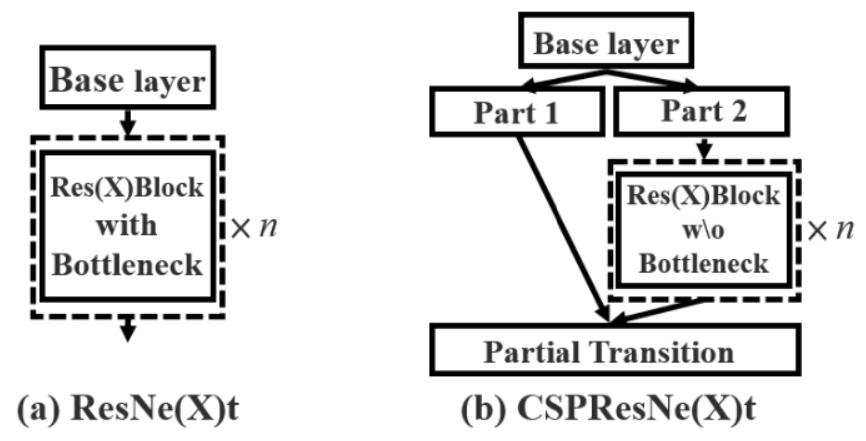
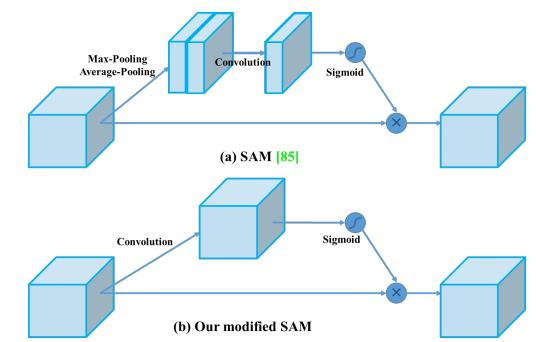
CBAM(引入注意力机制,V4中用的是空间注意力机制SAM)
V4中用的是SAM,也就是空间的注意力机制
不光NLP,语音识别领域在搞attention,CV中也一样
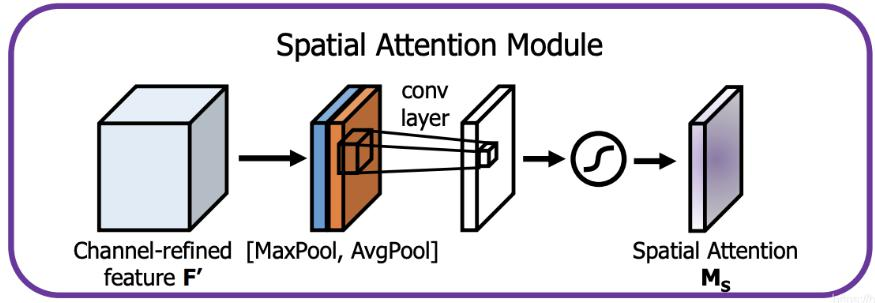
YOLOV4中的Spatial attention module
一句话概述就是更简单了,速度相对能更快一点
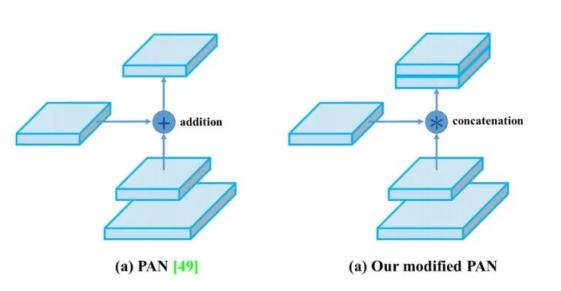
PAN(引入自底向上的路径,使底层信息更易传到顶部,且采用拼接而非加法)
先从FPN说起
自顶向下的模式,将高层特征传下来
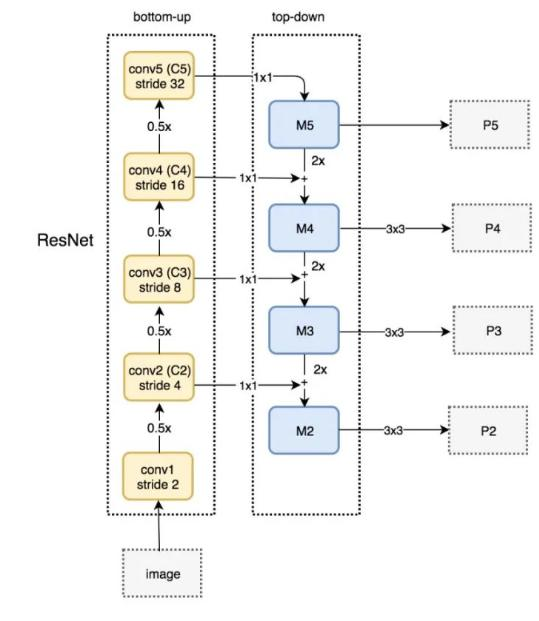
PAN(Path Aggregation Network)
引入了自底向上的路径,使得底层信息更容易传到顶部
并且还是一个捷径,红色的没准走个100层(Resnet),绿色的几层就到了
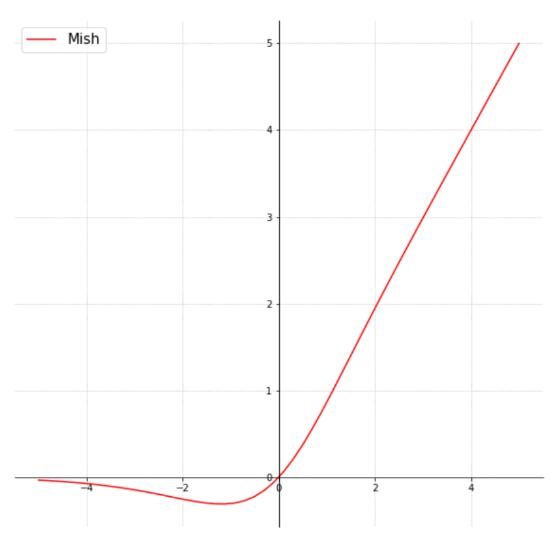
Mish激活函数公式为,计算量增加但效果有提升
消除网格敏感性:坐标回归预测值在0 - 1之间,在grid边界表示存在困难,通过在激活函数前加系数(大于1)缓解该问题。
为了缓解这种情况可以在激活函数前加上一个系数(大于1的):
![]()
整体网络架构:采用CSPDarknet53架构,展示了网络的输入、各层操作以及最终的输出等信息。
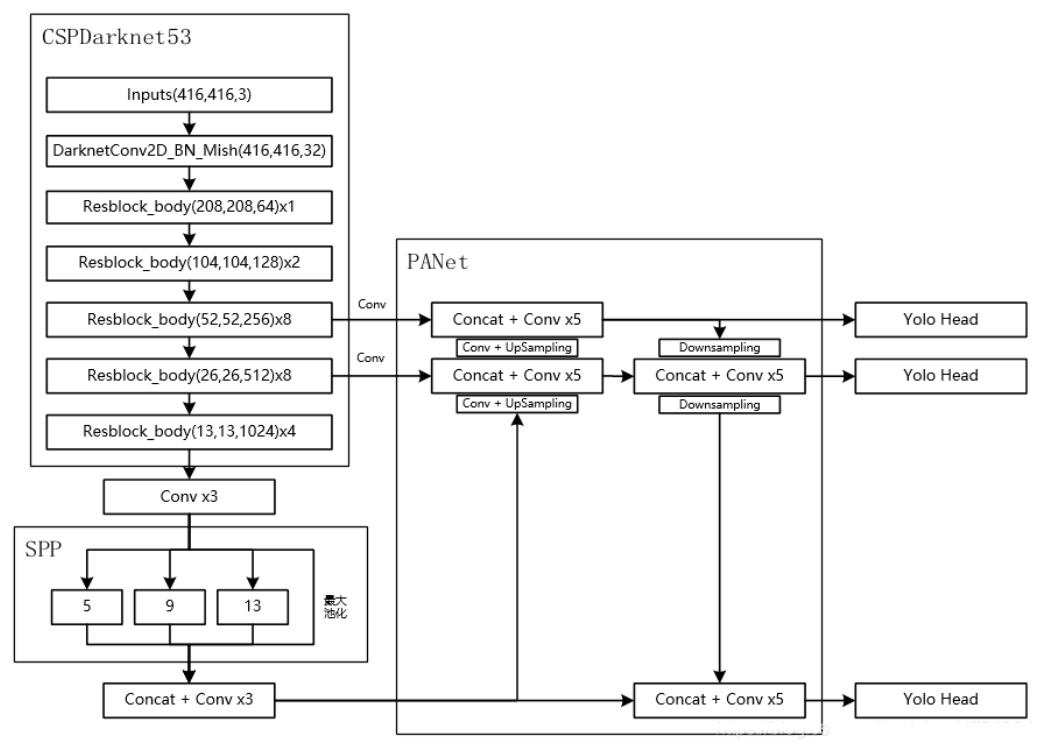
7. YOLOV5源码相关
可视化工具:
1.配置好netron,详情:https://github.com/lutzroeder/netron
桌面版:https://lutzroeder.github.io/netron/
2.安装好onnx,pip install onnx即可
3.转换得到onnx文件,脚本原始代码中已经给出
4.打开onnx文件进行可视化展示(.pt文件展示效果不如onnx)
Focus模块:先分块,后拼接,再卷积,间隔完成分块任务,使卷积输入的C变为12,目的是加速,不增加AP。
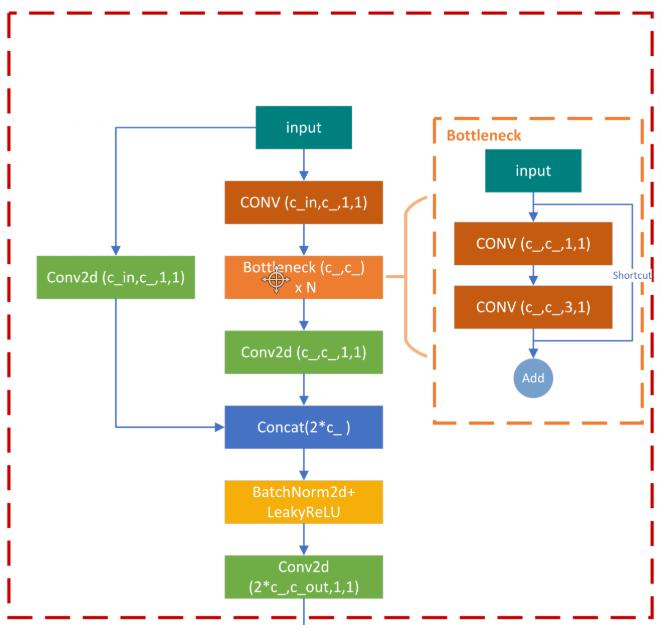
BottleneckCSP:注意叠加个数,里面包含resnet模块,相比V3版本多了CSP,效果有一定提升。
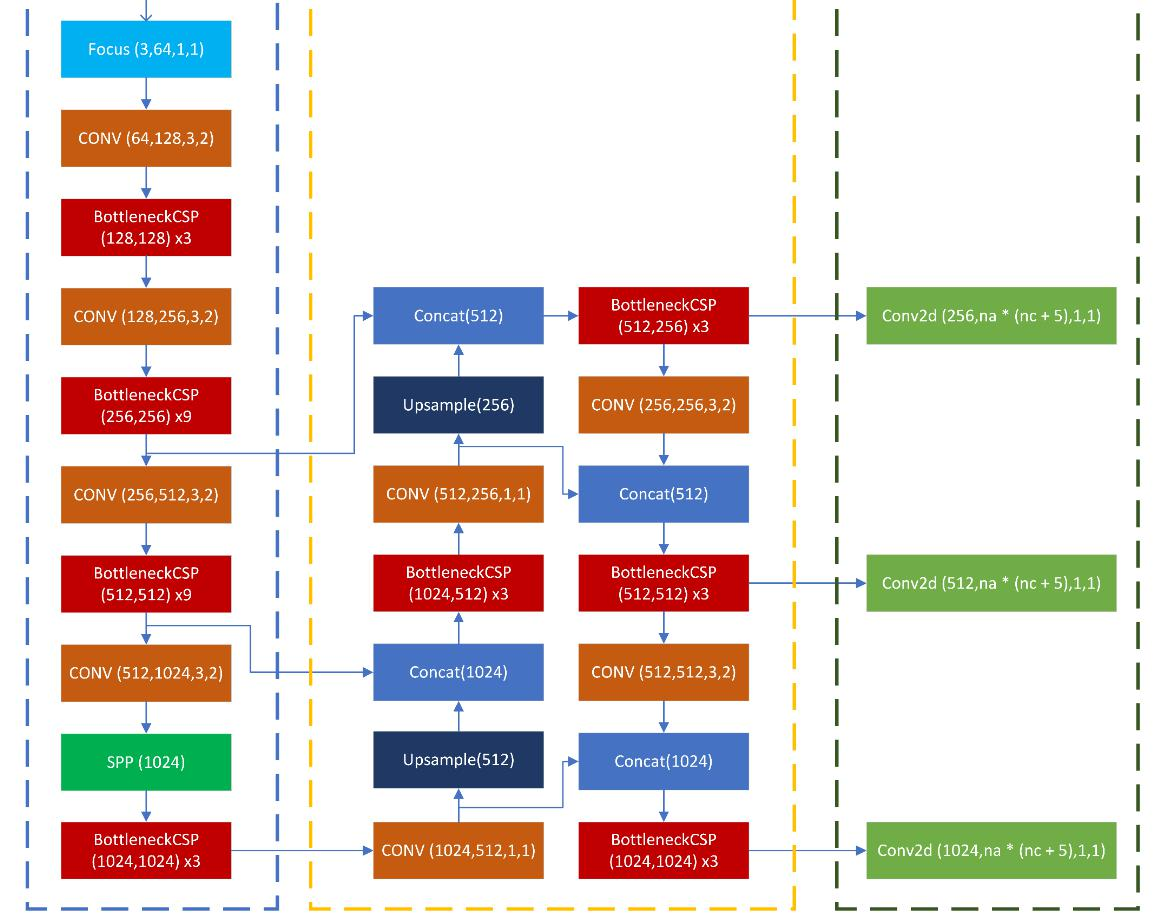
PAN流程:PAN流程中各模块的操作,如Focus、CONV、BottleneckCSP、Concat、Upsample等层的参数和连接关系。

)
![[mysql]窗口函数](http://pic.xiahunao.cn/nshx/[mysql]窗口函数)



