小罗碎碎念
在医学AI领域,全切片图像(WSI)的生存分析对疾病预后评估至关重要。
现有基于WSI的生存分析方法存在局限性,经典生存分析规则使模型只能给出事件发生时间的点估计,缺乏预测稳健性和可解释性;且全监督学习方式依赖大量标记数据,而当前WSI数据集规模小,影响模型泛化能力。
针对这些问题,今天和大家分享的这篇论文,提出了对抗多实例学习(AdvMIL)框架。

该框架基于对抗时间到事件建模,融合了WSI表示学习所需的多实例学习。生成器采用通用MIL编码器和MLP层,可提取全局特征并生成时间到事件估计;判别器使用区域级实例投影(RLIP)融合网络,能有效处理大规模矩阵和标量值的融合。通过cGAN损失和监督损失优化网络,并提出k折半监督训练策略,充分利用无标记数据。
实验结果显示,AdvMIL在多个方面表现出色。它能以较低计算成本提升主流WSI生存分析方法的性能,帮助模型更有效地利用无标记数据进行半监督学习。
同时,AdvMIL还增强了模型对补丁遮挡和图像噪声的鲁棒性。这一框架为医学AI中基于WSI的生存分析研究提供了新方向,有望推动该领域进一步发展。
交流群
欢迎大家加入【医学AI】交流群,本群设立的初衷是提供交流平台,方便大家后续课题合作。
目前小罗全平台关注量61,000+,交流群总成员1400+,大部分来自国内外顶尖院校/医院,期待您的加入!!
由于近期入群推销人员较多,已开启入群验证,扫码添加我的联系方式,备注姓名-单位-科室/专业,即可邀您入群。
知识星球
对推文中的内容感兴趣,想深入探讨?在处理项目时遇到了问题,无人商量?加入小罗的知识星球,寻找科研道路上的伙伴吧!
一、文献概述
“AdvMIL: Adversarial multiple instance learning for the survival analysis on whole-slide images”提出了一种新的对抗多实例学习框架AdvMIL,用于基于全切片图像(WSI)的生存分析,能有效提升模型性能、利用无标记数据,并增强模型鲁棒性。
| 作者类型 | 姓名 | 单位 |
|---|---|---|
| 第一作者 | Pei Liu | 电子科技大学计算机科学与工程学院 |
| 通讯作者 | Luping Ji | 电子科技大学计算机科学与工程学院 |
1-1:研究背景
WSI生存分析对疾病预后评估意义重大,但现有方法受经典生存分析规则和全监督学习限制,只能给出事件发生时间点估计,且在小数据环境下训练。
生成对抗网络(GAN)可解决这些问题,本研究将GAN与多实例学习(MIL)结合,提出AdvMIL框架。
1-2:方法
框架设计
通过生成器中的MIL编码器和判别器中的区域级实例投影(RLIP)融合网络,将对抗时间到事件建模推广到MIL。
生成器利用MIL编码器提取全局特征,结合噪声生成时间到事件估计;判别器通过RLIP融合网络区分真实和虚假样本对。
网络训练
使用cGAN损失和监督损失优化网络。监督损失考虑了删失和未删失患者,使模型能通过隐式采样估计时间到事件分布。
k折半监督学习
提出k折半监督训练策略,将无标记数据分成k折,在不同训练轮次中依次使用不同折与标记数据训练,减少无标记数据主导训练的问题。
1-3:实验
设置
使用NLST、BRCA和LGG三个公开数据集,选择ABMIL、DeepAttnMISL、PatchGCN和ESAT作为基线模型。
详细设置了数据处理、模型参数、训练超参数和评估指标。
结果
AdvMIL能提升主流MIL网络性能,ESAT + AdvMIL在三个数据集上综合性能最佳。
AdvMIL计算开销小,在半监督学习中对训练时使用的无标记数据预测效果好,k折策略在标记数据较少时效果更好。
RLIP策略有效,均匀分布噪声性能更优。AdvMIL - 基于模型对补丁遮挡和图像噪声更鲁棒。案例分析表明AdvMIL能提供分布估计,更接近真实值。
1-4:讨论与结论
AdvMIL为计算病理学中的生存分析带来新方法,但存在无法定量评估分布估计覆盖度、实验采样次数有限和数据集类型有限等局限。
总体而言,AdvMIL能提升模型性能,辅助时间到事件分布估计和半监督学习,增强模型鲁棒性。
二、重点关注
2-1:嵌入级多实例学习(MIL)范式
这张图展示了用于全切片图像(WSI)表示学习的嵌入级多实例学习(MIL)范式 。
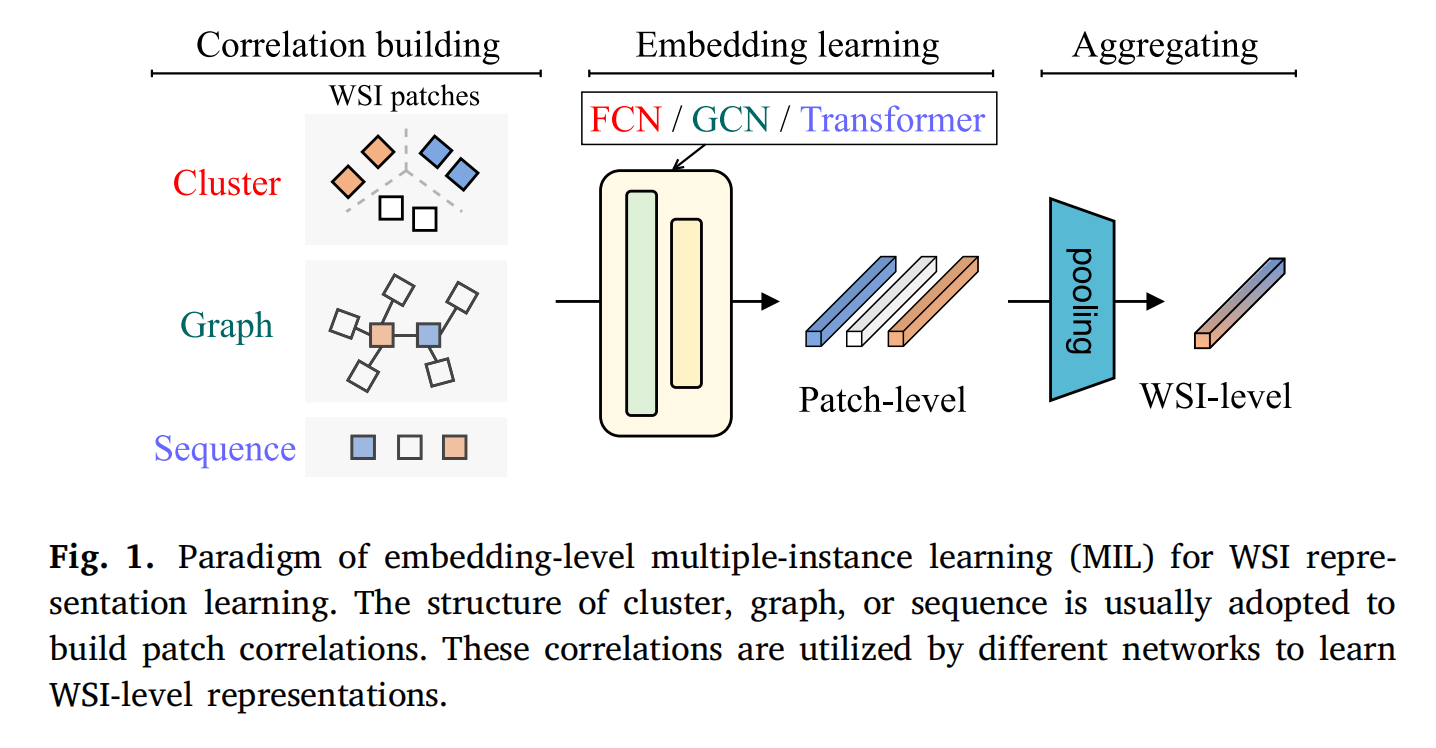
关联构建(Correlation building)
以簇(Cluster)、图(Graph)、序列(Sequence )三种结构来构建WSI图像块(WSI patches)之间的相关性。
比如簇结构将图像块分组关联;图结构用节点和边表示图像块关系;序列结构按顺序排列图像块建立关联 。
嵌入学习(Embedding learning)
利用全卷积网络(FCN)、图卷积网络(GCN)或Transformer等网络,基于前面构建的相关性,对图像块进行嵌入学习,得到图像块级(Patch - level)的特征表示 。
聚合(Aggregating)
通过池化(pooling)操作,将图像块级特征聚合成全切片图像级(WSI - level)的特征表示 。
这种范式旨在借助不同结构构建图像块相关性,再经特定网络学习和聚合操作,实现从图像块特征到全切片图像整体特征的有效学习,为后续基于WSI的分析任务(如疾病诊断、预后分析等)提供有力的特征表示基础 。
2-2:模型对比
这张图从模型输出和输入两方面,对比了现有全切片图像(WSI)生存分析模型与AdvMIL :
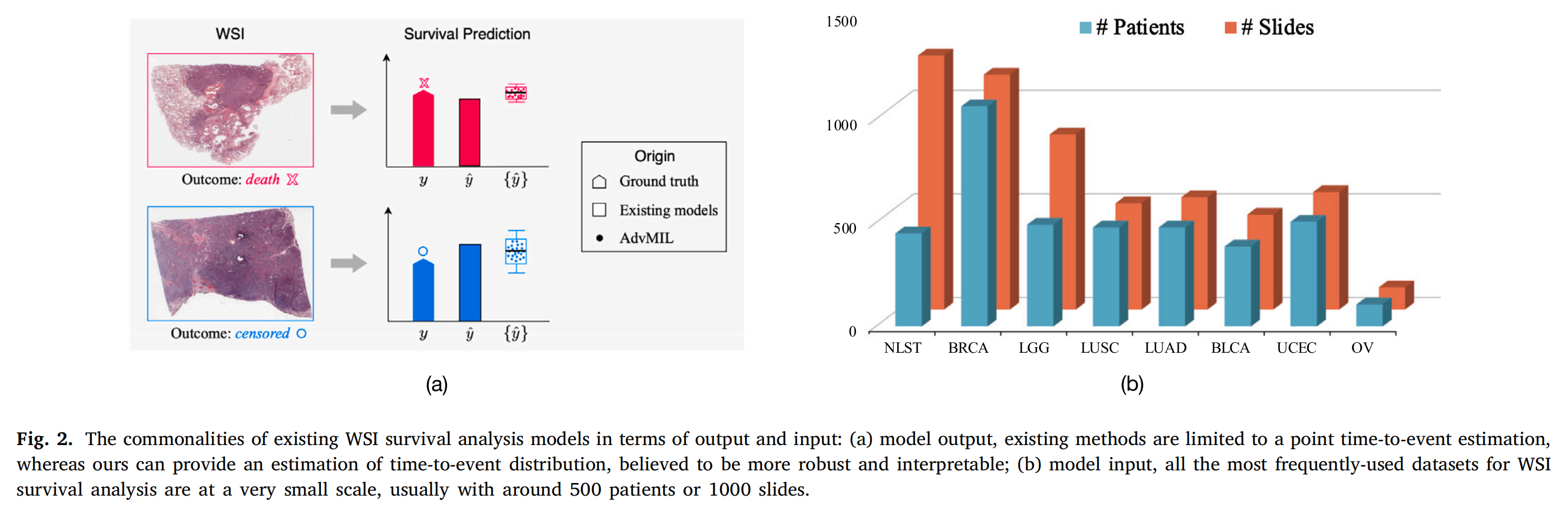
(a)模型输出
- 现有模型:局限于事件发生时间的点估计(用 y ^ \hat{y} y^ 表示) 。如针对结局为死亡(death ,红框)和删失(censored ,蓝框)的WSI图像,只能给出单一估计值 。
- AdvMIL:能提供事件发生时间分布的估计(用 { y ^ } \{\hat{y}\} {y^} 表示 ),相比点估计更稳健、可解释 。
(b)模型输入
展示了常用WSI生存分析数据集的规模,包括NLST、BRCA、LGG等 。
蓝色柱代表患者数量(# Patients) ,橙色柱代表切片数量(# Slides) 。可见这些数据集规模通常较小,患者数约500 ,切片数约1000 。
这反映出该领域数据规模小的现状,也凸显了AdvMIL在小数据环境下提升模型性能的研究意义。
2-3:AdvMIL的总体框架
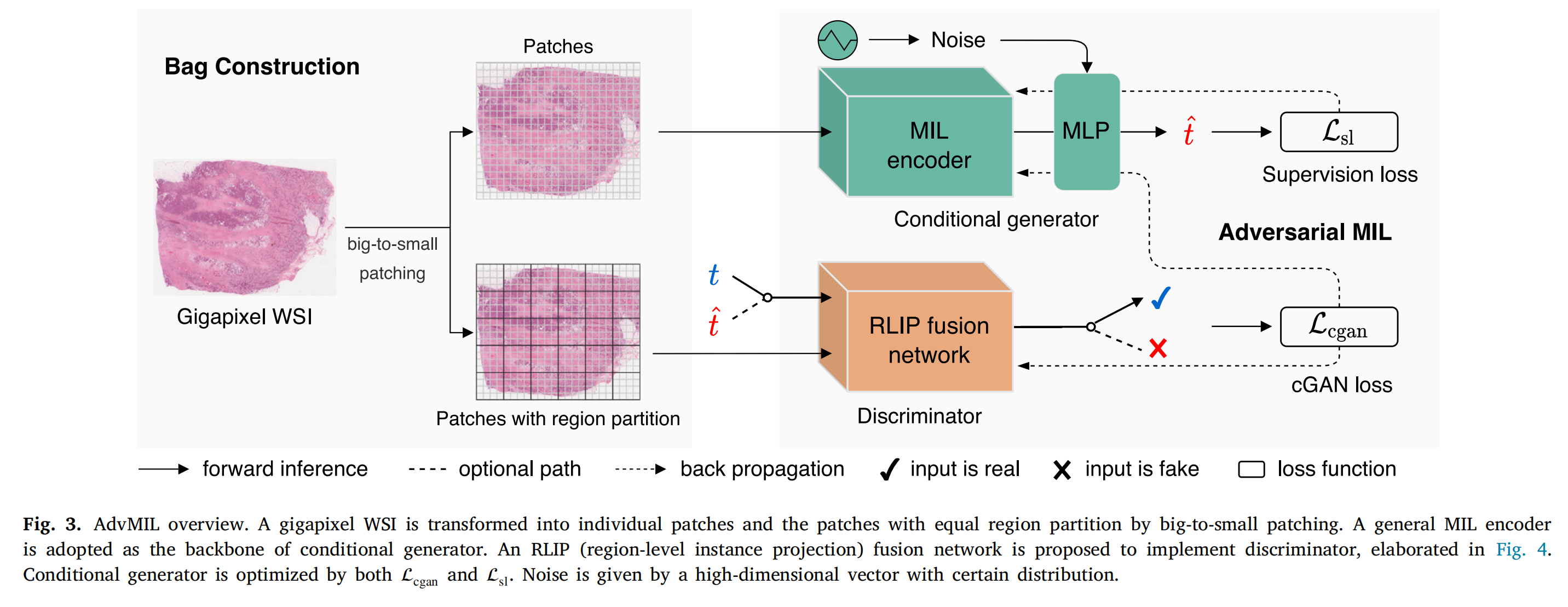
包构建(Bag Construction)
将千兆像素级的全切片图像(Gigapixel WSI)通过从大到小的切片方式(big - to - small patching),转化为单个图像块(Patches)以及带有区域划分的图像块(Patches with region partition) 。
条件生成器(Conditional generator)
以通用的多实例学习编码器(MIL encoder)作为骨干 。
将图像块输入MIL编码器,结合从特定分布的高维向量获取的噪声(Noise) ,再经多层感知机(MLP)处理,输出事件时间的估计值 t ^ \hat{t} t^ 。
判别器(Discriminator)
采用区域级实例投影(RLIP)融合网络 。
真实的事件时间 t t t 和生成器输出的估计时间 t ^ \hat{t} t^ 都可作为输入 。判别器判断输入是真实数据(标记为√ )还是生成的虚假数据(标记为× ) 。
损失函数
- 监督损失(Supervision loss, L s l \mathcal{L}_{sl} Lsl ):用于优化条件生成器,使生成的时间估计更接近真实值 。
- 条件生成对抗网络损失(cGAN loss, L c g a n \mathcal{L}_{cgan} Lcgan ):在生成器和判别器之间对抗博弈,提升生成器生成数据的真实性和判别器的判别能力 。
图中还通过箭头标识了前向推理(forward inference)、反向传播(back propagation)路径,以及可选路径(optional path) ,清晰呈现了AdvMIL的运行机制。
三、AdvMIL 复现流程概述
3-1:研究背景与贡献
AdvMIL 是一种基于对抗性多示例学习(MIL)的框架,专门用于处理千兆像素级别的全切片图像(WSI)的生存分析。其核心创新在于:
-
对抗性时间事件建模:通过生成器和判别器的对抗训练,直接估计WSI的生存时间分布。
-
灵活性与兼容性:可结合现有MIL网络(如ABMIL、PatchGCN等)提升预测性能。
-
半监督学习能力:有效利用未标注的WSI数据。
-
鲁棒性增强:对图像遮挡、模糊和颜色变化具有较强鲁棒性。
3-2:环境配置与数据准备
软件
-
Python ≥ 3.6, PyTorch ≥ 1.9.0, CUDA ≥ 11.1
-
依赖库:wandb, numpy, pandas
工具准备
安装CLAM工具包用于WSI预处理。
3-3:Level 2分块(16倍下采样)
# 在CLAM目录下运行
python create_patches_fp.py \--source DATA_DIRECTORY \--save_dir /data/nlst/processed/tiles-l2-s256 \--patch_level 2 --patch_size 256 --seg --patch --stitch
作用:在低分辨率层级(level 2)检测组织区域,保存区块坐标。
输出:/data/nlst/processed/tiles-l2-s256 包含每个WSI的区块坐标和分割掩码。
3-4:Level 1分块(4倍下采样)
# 在AdvMIL的tools目录下运行
python3 big_to_small_patching.py \/data/nlst/processed/tiles-l2-s256 \/data/nlst/processed/tiles-l1-s256
作用:根据level 2的坐标生成更高分辨率(level 1)的区块坐标。
原理:通过坐标映射,将低分辨率区块转换为高分辨率对应区域。
3-5:特征提取
# 在CLAM目录下运行
CUDA_VISIBLE_DEVICES=0,1 python extract_features_fp.py \--data_h5_dir /data/nlst/processed/tiles-l1-s256 \--data_slide_dir DATA_DIRECTORY \--csv_path /data/nlst/processed/tiles-l1-s256/process_list_autogen.csv \--feat_dir /data/nlst/processed/feat-l1-RN50-B \--batch_size 512 --slide_ext .svs
作用:使用ResNet-50提取每个区块的特征。
输出:/data/nlst/processed/feat-l1-RN50-B 包含每个WSI的.pt特征文件。
3-6:数据目录结构验证
确保生成以下目录结构:
/data/nlst/processed/
├── feat-l1-RN50-B/ # 特征文件
│ └── pt_files/
│ ├── 10015.pt
│ └── ...
├── tiles-l1-s256/ # Level 1区块坐标
│ ├── patches/
│ │ ├── 10015.h5
│ │ └── ...
│ └── process_list_autogen.csv
└── tiles-l2-s256/ # Level 2区块坐标(中间结果)
3-7:网络训练与测试
配置文件设置
编辑config/cfg_nlst.yaml,关键参数说明:
save_path: "/results/nlst" # 结果保存路径
wandb_prj: "AdvMIL-NLST" # Weights & Biases项目名
bcb_mode: "patch" # 骨干网络(可选:patch, graph, cluster, abmil)
disc_prj_iprd: "instance" # 融合方式(instance=RLIP, bag=常规融合)
semi_training: False # 是否启用半监督学习
test: False # 是否为测试模式
test_load_path: "/pretrained/model.pt" # 测试模式下的模型路径
模式1:常规训练/验证/测试
# 多折交叉验证
python3 main.py \--config config/cfg_nlst.yaml \--handler adv \--multi_run
输出:在save_path下生成模型文件、预测结果和评估指标。
模式2:测试模式
- 修改配置文件:
test: True test_load_path: "/path/to/pretrained_model.pt" - 运行命令:
python3 main.py --config config/cfg_nlst.yaml --handler adv
模式3:半监督训练
-
修改配置文件:
semi_training: True ssl_unlabel_csv: "/path/to/unlabeled_data.csv" # 未标注数据路径 -
运行常规训练命令。
-
可选模型结构
图模型(Graph-based):生成患者级图结构
python3 tools/patchgcn_graph_s2.py nlst
聚类模型(Cluster-based):生成区块聚类标签
python3 tools/deepattnmisl_cluster.py nlst 8 # 8个聚类
3-8:扩展应用
- 自定义数据集:修改
process_list_autogen.csv和nlst-foldk.npz以适应新数据。 - 新骨干网络:在
bcb_mode中添加自定义模型,需在代码中实现对应的特征处理逻辑。
结束语
本期推文的内容就到这里啦,如果需要获取医学AI领域的最新发展动态,请关注小罗的推送!如需进一步深入研究,获取相关资料,欢迎加入我的知识星球!
:ping命令出现问题)




