目录
1. Java的JDBC编程
1.1 Java的数据库编程:JDBC
1.2 JDBC工作原理
1.3 如何在项目中导入数据库驱动包
如何下载数据库驱动包
jar包如何引入项目中
2. 编写JDBC代码
1. 创建并初始化一个数据源(DataSource)
2. 和数据库服务器建立连接
3. 构造 SQL 语句
4. 执行 SQL 语句
5. 释放必要的资源
总结
代码实现查询操作
3. JDBC常用接口和类
3.1 JDBC API
3.2 数据库连接Connection
3.3 Statement对象
3.4 ResultSet对象
耦合、内聚
1. Java的JDBC编程
JDBC(Java Database connect)就是用 Java代码操作数据库
真正在公司中操作数据库,99.9999%的情况都是通过代码来操作的,很少会手动在客户端里输入sql语句,所以我们之前用cmd,而不用navicat等之类的数据库客户端的原因。系统中执行了10w次sql,也不一定手动敲一次sql。
1.1 Java的数据库编程:JDBC
- 数据库编程,是需要数据库服务器提供一些API,供程序猿调使用的。
- API,即Application Programming Interface,应用程序编程接口。是一组类/函数提供给程序猿,让我们去调用,完成一些功能。
- 各种数据库,MySQL, Oracle, SQL Server在开发的时候,都提供了一组各自的编程接口(API)。
- 即给你个软件,你能对他干啥(代码层次上的),基于它提供的这些功能,就可以写一些其他代码了。
- 如MySQL, Oracle, SQL Server等其他关系型数据库,在开发时设置的API接口是不完全相同的,没有一个标准,大大增加了程序猿的学习成本。
- 于是Java设计出一套api的规范,其他数据库提供的api都要与Java设计api的规范对接上,其他数据库就在自己的api基础上加以修改,转换为java的api形状。程序猿只要了解一套api,就可以操作各种数据库了。java设计的标准API 就是JDBC
JDBC(Java Database Connectivity,Java数据库连接)是 Java语言用于连接和操作数据库的标准API,它提供了一套统一的接口,允许Java程序与多种关系型数据库(如MySQL、Oracle、SQL Server等)进行交互,而无需关心底层数据库的具体实现细节。它是一种用于执行SQL语句的Java API,是Java中的数据库连接规范。
这个API由 java.sql.*,javax.sql.*包中的一些类和接口组成,为Java开发人员操作数据库提供了一个标准的API,可以为多种关系数据库提供统一访问。
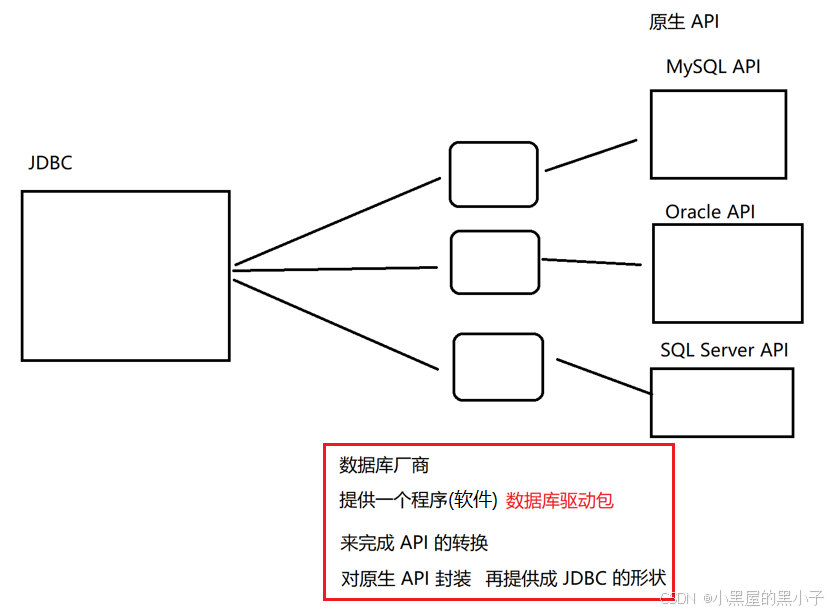
数据库的api是怎么对接上JDBC的:这些数据库有自己的原生api,数据库厂商专门提供了一个驱动程序(软件),通过这个驱动程序把原生api转换成符合JDBC要求的api。
- 驱动程序起到的作用,类似于转接头,扩展坞。平时经常见到硬件的驱动,例如鼠标驱动。
- 硬件的驱动是让操作系统认识新的硬件设备,数据库的驱动是让JDBC能认识数据库的api
- Java程序猿要想进行数据库开发,就需要在项目中导入对应数据库的驱动包,才能编写代码。
1.2 JDBC工作原理
JDBC 为多种关系数据库提供了统一访问方式,作为特定厂商数据库访问API的一种高级抽象,它主要包含一些通用的接口类。
JDBC访问数据库层次结构:
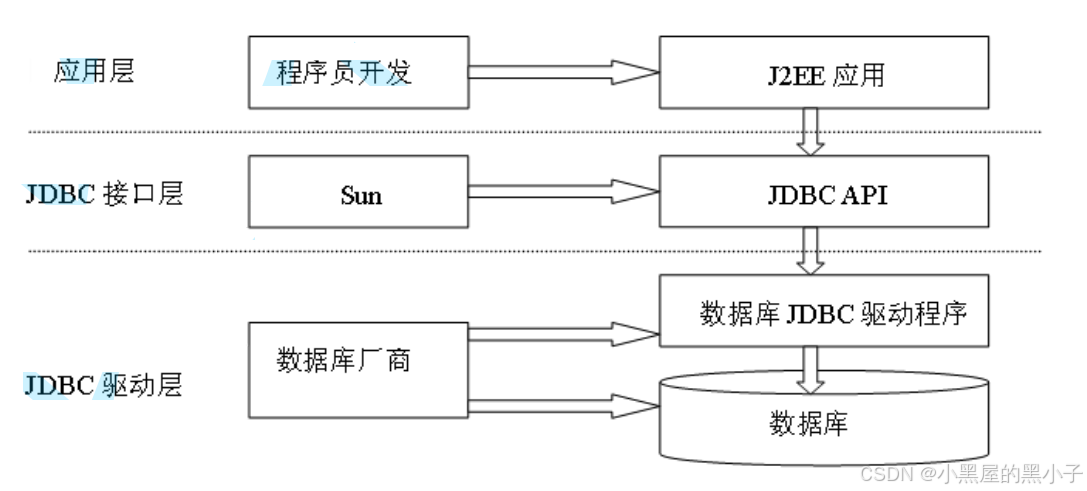
- Java语言访问数据库操作完全面向抽象接口编程。
- 开发数据库应用不用限定在特定数据库厂商的API。
- 程序的可移植性大大增强。
要想在程序中操作mysql就需要先安装mysql的驱动包,并且要把驱动包引入到项目里。
1.3 如何在项目中导入数据库驱动包
驱动包从哪里来?数据库厂商提供的:
- mysql的官方网站获取(下策,mysql被oracle 收购之后官网也合并,麻烦)
- github
- maven 中央仓库
maven相当于应用商店。通过应用商店,就可以访问到软件程序包下载下来。中央仓库是服务器,托管了各种软件程序包。
例如:手机app,金铲铲之战,可以去腾讯官网下载,也可以去应用商店(华为商店,小米商店...)
如何下载数据库驱动包
Maven Repository: mysql![]() https://mvnrepository.com/search?q=mysql
https://mvnrepository.com/search?q=mysql
注意此处的版本,大版本要和数据库服务器匹配,数据库服务器用的是5系列,此处的驱动包也得用5系列,不能用8系列。小版本无所谓大版本不能错。
- .jar 是 java 中常见的后缀类型。
- java写的程序,如何发布给别人。 JDBC是通过jar包发布的。读作架包,不是架包。

java发布程序的典型方式:
- java通过 .java源文件编译成 .class文件,jvm来解释执行 .class
- 每个.java 都 一 一对应一个 .class,如果代码里 .java非常多呢(类非常多)?
- 把一大堆的 .class 给打成压缩包(类似于.rar .zip).jar,把jar包拷贝给对方,对方就可以直接使用jvm来运行了。
- 此处,mysql 驱动包的这个jar不是单独运行的jar,可以把它导入到项目中,然后就可以调用其中的方法和类来进行编程了。
jar包如何引入项目中
数据库驱动包,每次创建项目就要导入一次。实际开发中,创建项目是非常低频的操作。一两年都没机会创建一次项目。
1)创建一个Directory(目录)
创建后,选中,将mysql驱动包复制粘贴到里面;这里不需要解压,jvm会自动识别
2)把这个目录标记成项目的库(library)
library(图书馆),在计算机中(idea)里面是库的意思
- 此时idea就识别出这里面有哪些目录,有哪些的类,以及.class文件,识别成功就导入成功了。
- idea能识别这个目录里的jar包,从而就可以调用里面的类来写代码了。
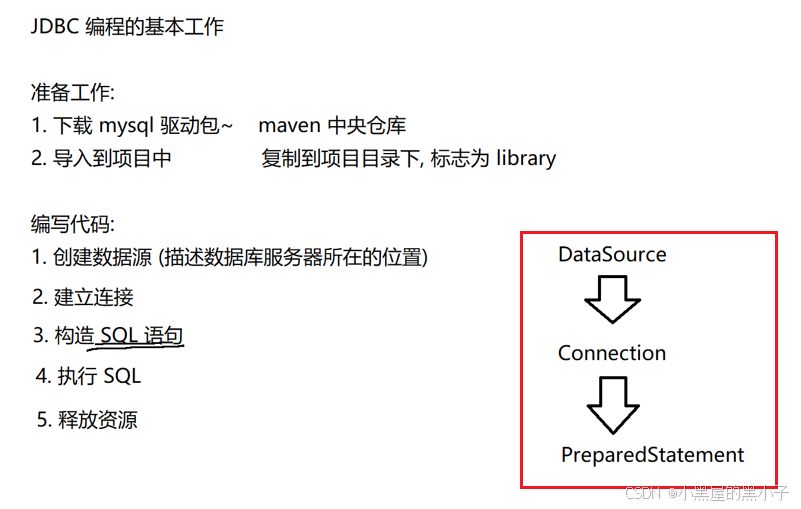
2. 编写JDBC代码
JDBC 需要通过以下步骤来完成开发:
- 创建并初始化一个数据源
- 和数据库服务器建立连接
- 构造 SQL 语句
- 执行 SQL 语句
- 释放必要的资源
这里的代码是固定套路。正因为如此,实际开发中,就会使用一些框架来简化数据库操作代码,MyBatis这样的框架就是如此。框架是一直在变的,但是JDBC是不变的。
数据源:数据从哪里来;这里描述数据库服务器在哪里,通过DataSource类(接口)来进行描述
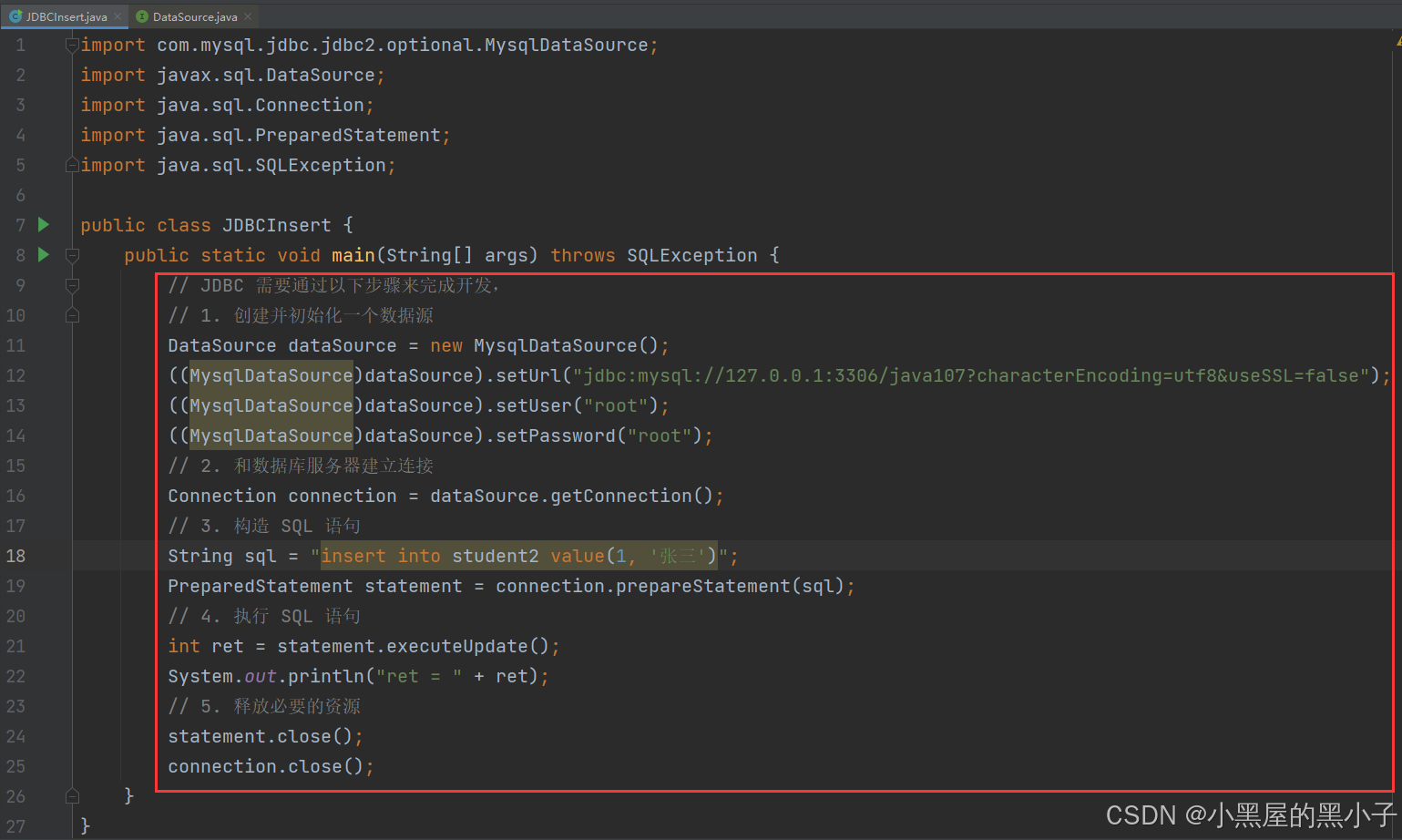
1. 创建并初始化一个数据源(DataSource)
DataSource 意思:数据源

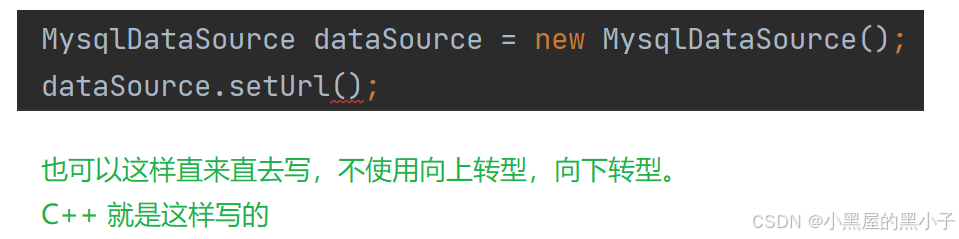
其中DataSource接口就是JDBC给我们提供的API,来自java.sql这个包中的接口;MysqlDataSoutce类(实体类)来自我们上面导入的mysql驱动包中,这里发生了向上转型(父类引用指向子类对象)
然后再向下转型,为什么呢? 因为 setUrl方法只有子类中有,父类中没有;父类引用不能调用子类中独有的方法,所以我要转回来,我要使用父类中没有但是子类拥有的方法。

上述方式写法仅仅是因为Java圈中流行那样写的
URL 计算机里的一个常见术语, 唯一资源定位符,描述网络上的某个资源所在的位置。
setUrl 与 setURL一样没区别,之所以这样设定,就是为了减少程序猿的心智负担


"jdbc:mysql://127.0.0.1:3306/java107?characterEncoding=utf8&useSSL=false"


用户名默认是root;安装数据库的时候密码是啥就写啥;这几个东西都设置进去,才能够访问数据库服务器
2. 和数据库服务器建立连接
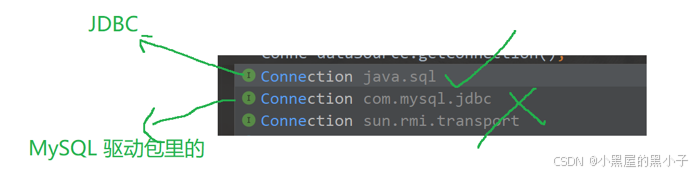
Connection 意思:连接
这里使用的Connection类 一定是JDBC提供的;建立成功就连接成功了,没成功就抛出异常(这里已经声明异常了)

3. 构造 SQL 语句
这里插入的前提是在数据库中已经创建过了这个表


由上图代码知,即使使用代码来操作数据库,还是靠sql语句,只不过是换成用代码来构造sql,前面sql的各种语法仍然有效

PreparedStatement 语句是对sql语句进行预编译一下,为什么要进行提前预编译一下:
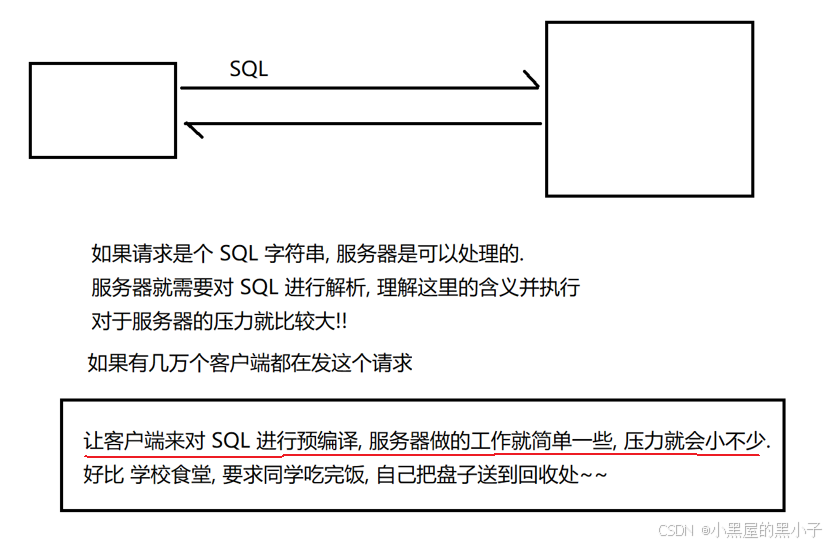
4. 执行 SQL 语句
把 sql语句(预编译过的)发送给数据库服务器,由服务器做出响应
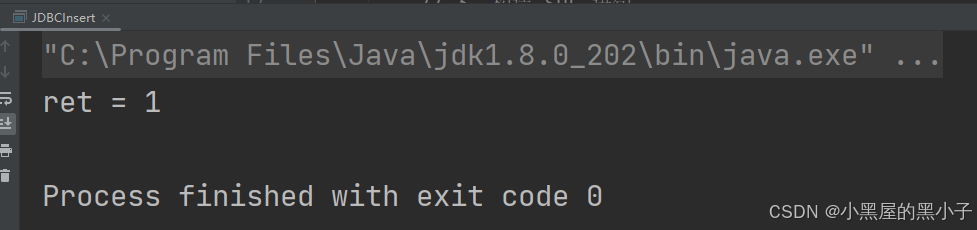
这里使用insert、delete、update ,sql语句操作,都是用executUpdate代码方法,返回值为int类型,表示影响到的行数
如果使用select ,sql语句操作,则用 executeQuery代码方法,更复杂一点,具体代码操作看最后


5. 释放必要的资源
谁是后创建的,谁就先释放 —— “后进先出”
数据库的客户端和服务器,之间进行通信的时候,是要消耗一定的系统资源的,包括不限于,CPU,内存,硬盘,带宽......
上述代码存在一些问题:
我们构造SQL语句的时候,要插入的数据是写死的(硬编码),更合适的做法是把数据通过其他方式让用户输入(比如通过控制台输入)
改进后:
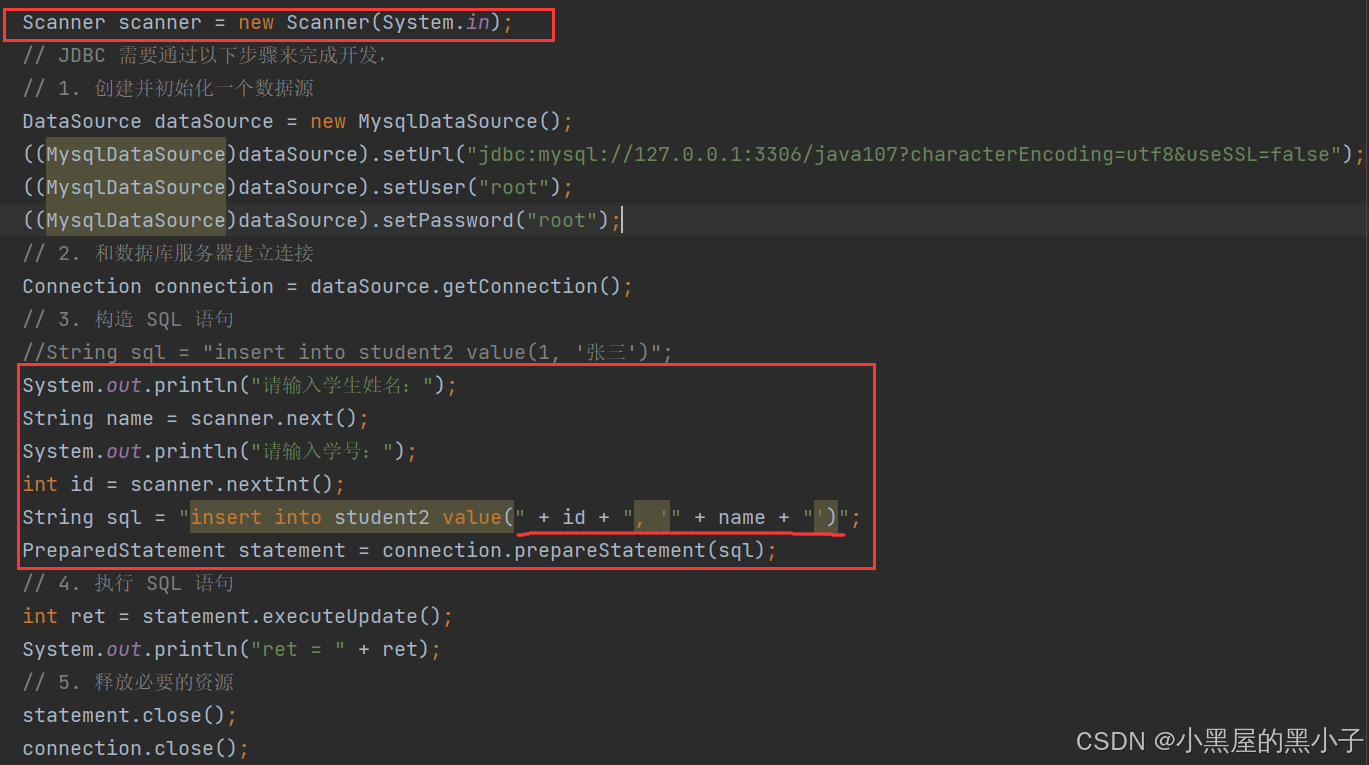
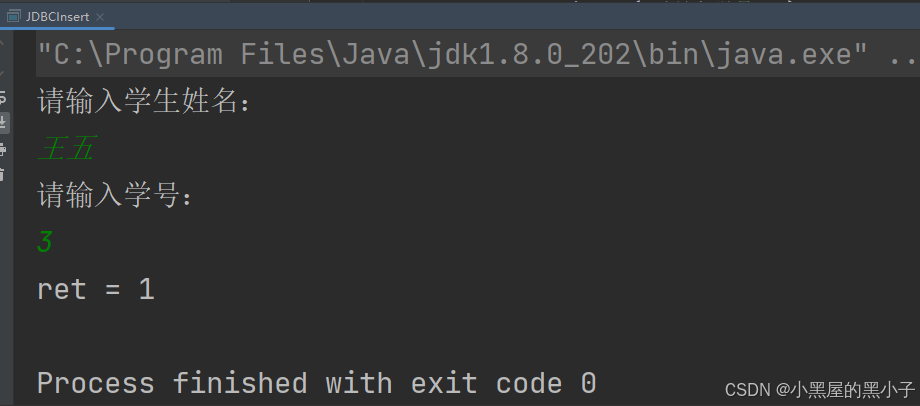
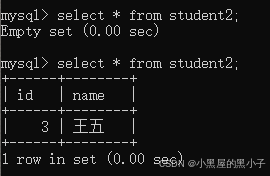
通过这种方式确实可以完成用户动态输入数据的效果,但是这种写法代码,非常容易出错,而且存在一个严重问题:
如果用户不好好输入,没有按照对应的数据输入,而是在控制台中输入了 王五'); select * from xxXX 或者删库语句 drop database....
因此这种写法容易被sql注入,也就是网络安全中的典型攻击方式(输入过程中夹带私货)
更好的写法是,借助这个PreparedStatement的拼装功能来实现

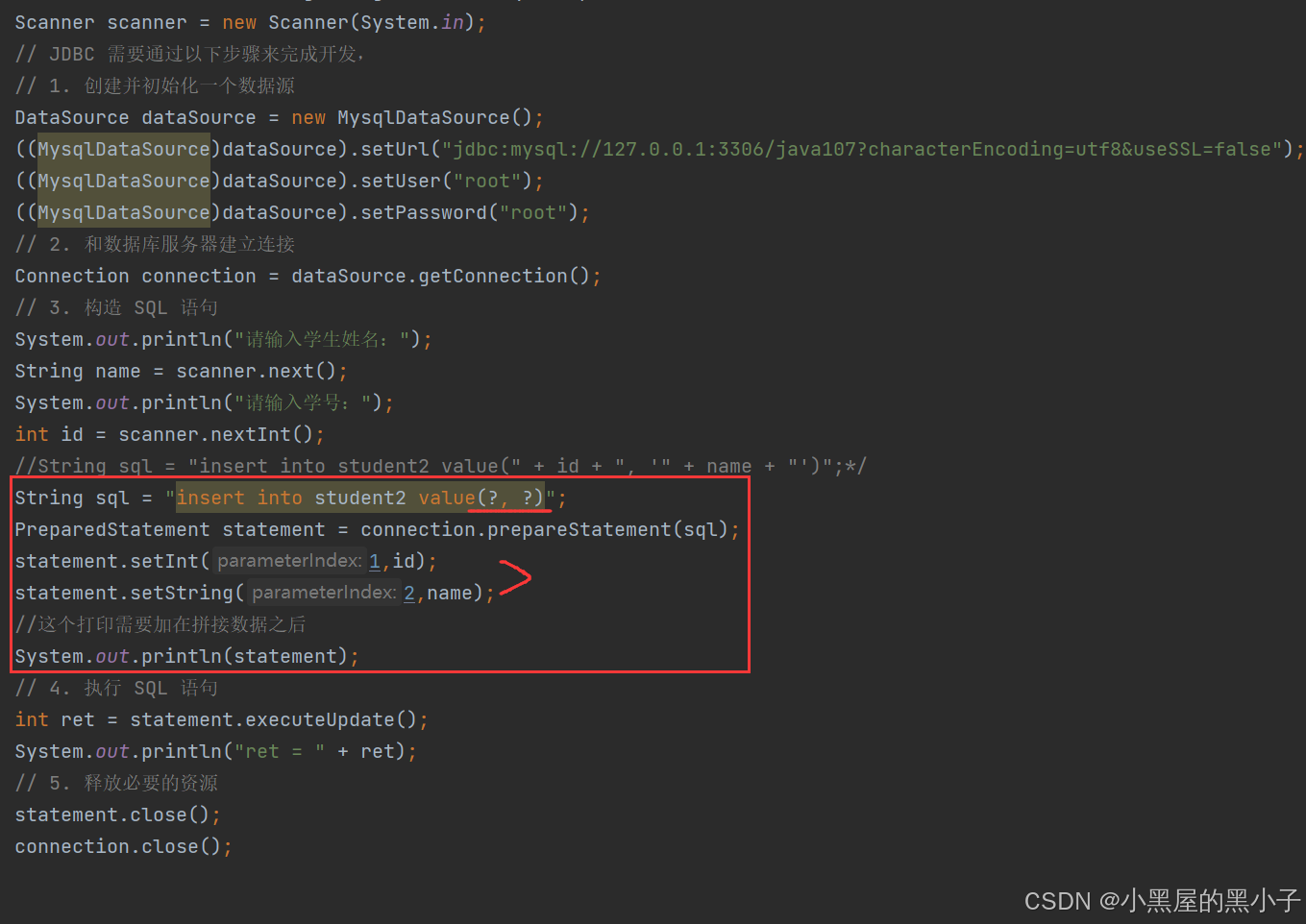
在拼接好数据后,打印一下statement,就在控制台中看到拼接后的语句了
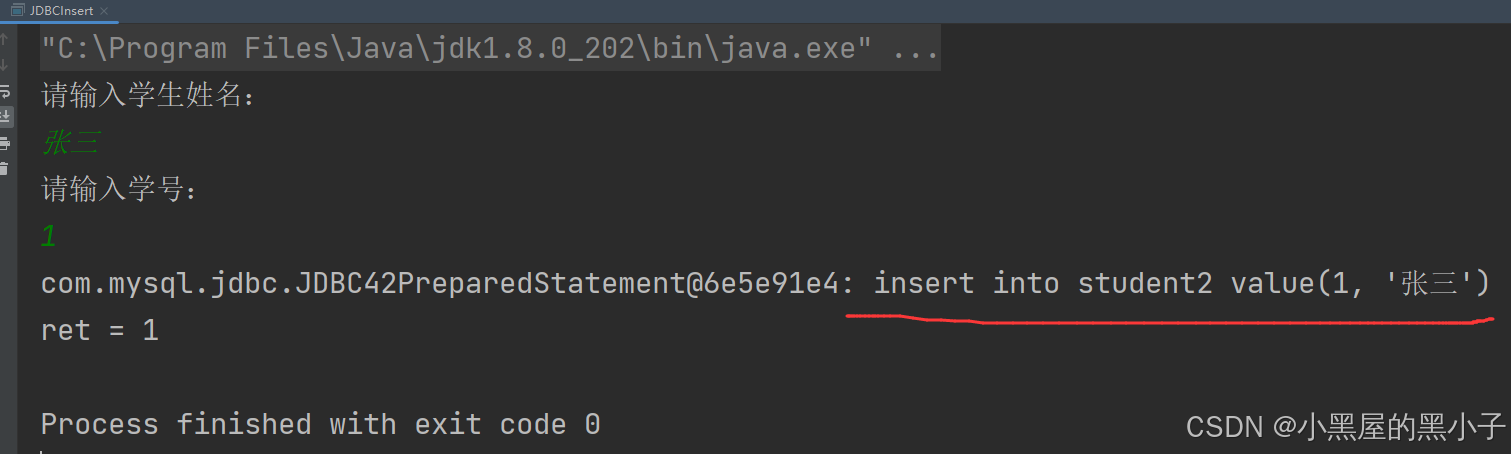

如果你执行这个代码,出错了,就可以把Statement打印出来,看看这里哪里有语法错误,或者也可以直接把这个sql拷贝到控制台中执行。
总结
JDBC编程的基本工作
准备工作:
- 下载mysql 驱动包 maven中央仓库
- 导入到项目中 复制到项目目录下,标志为库(library)
编写代码:
- 创建数据源(描述数据库服务器所在的位置)
- 建立连接
- 构造 SQL 语句
- 执行 SQL 语句
- 释放资源

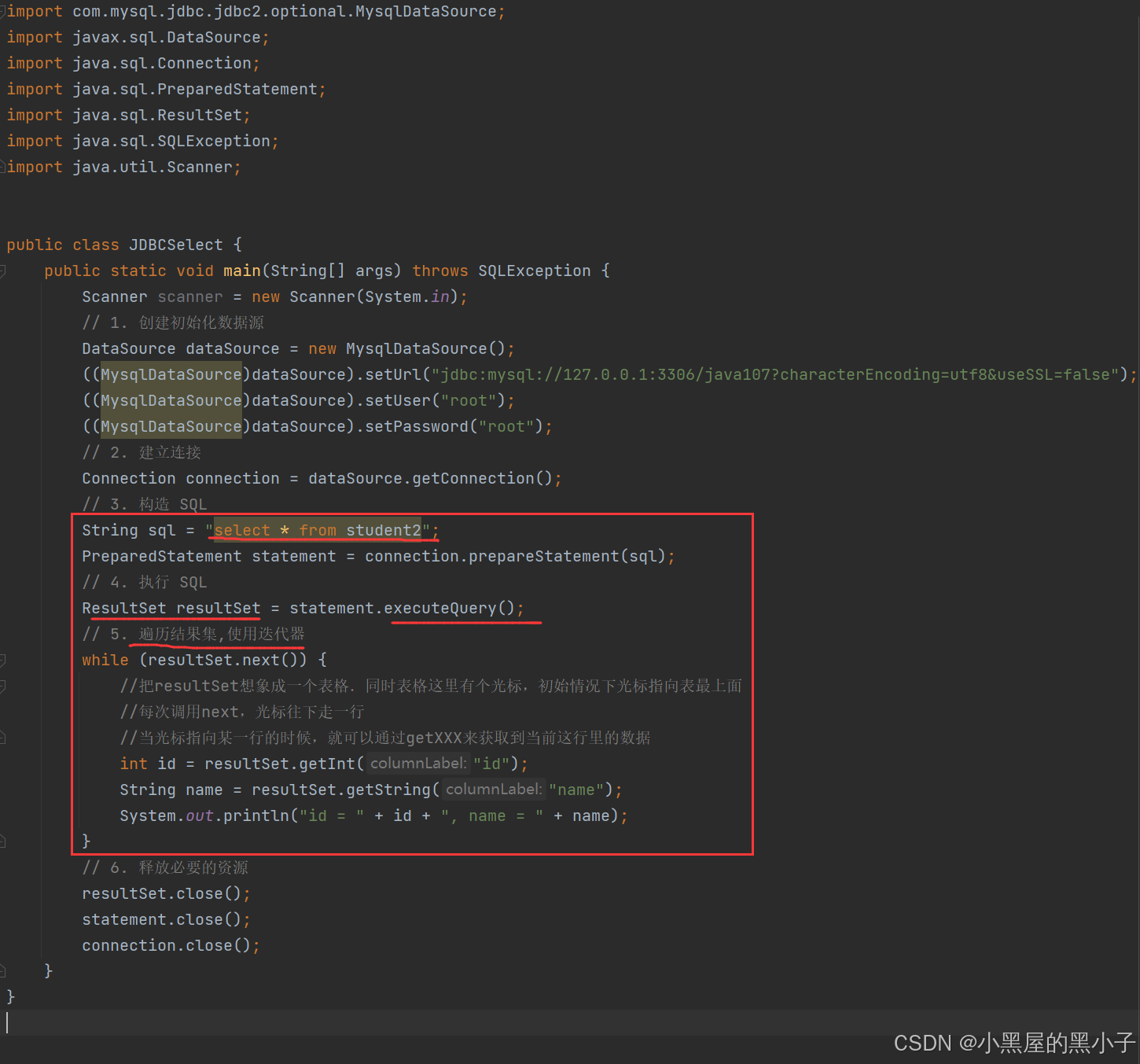
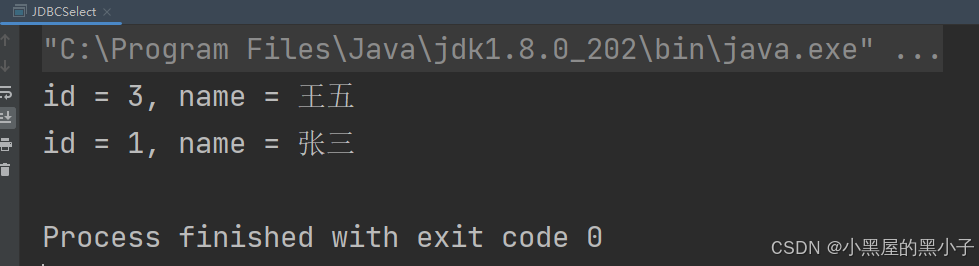
代码实现查询操作
执行SQL语句的时候分情况:
如果构造SQL语句,是使用insert、delete、update 操作,都是用executUpdate代码方法,返回值为int类型,表示影响到的行数
如果构造SQL语句,是使用select 操作,则用 executeQuery代码方法
对查询来说,返回结果不是单纯的int 了,而是ResultSet对象;resultSet 可以认为是返回了一张表,使用迭代器遍历这张表,然后再控制中显示出来。
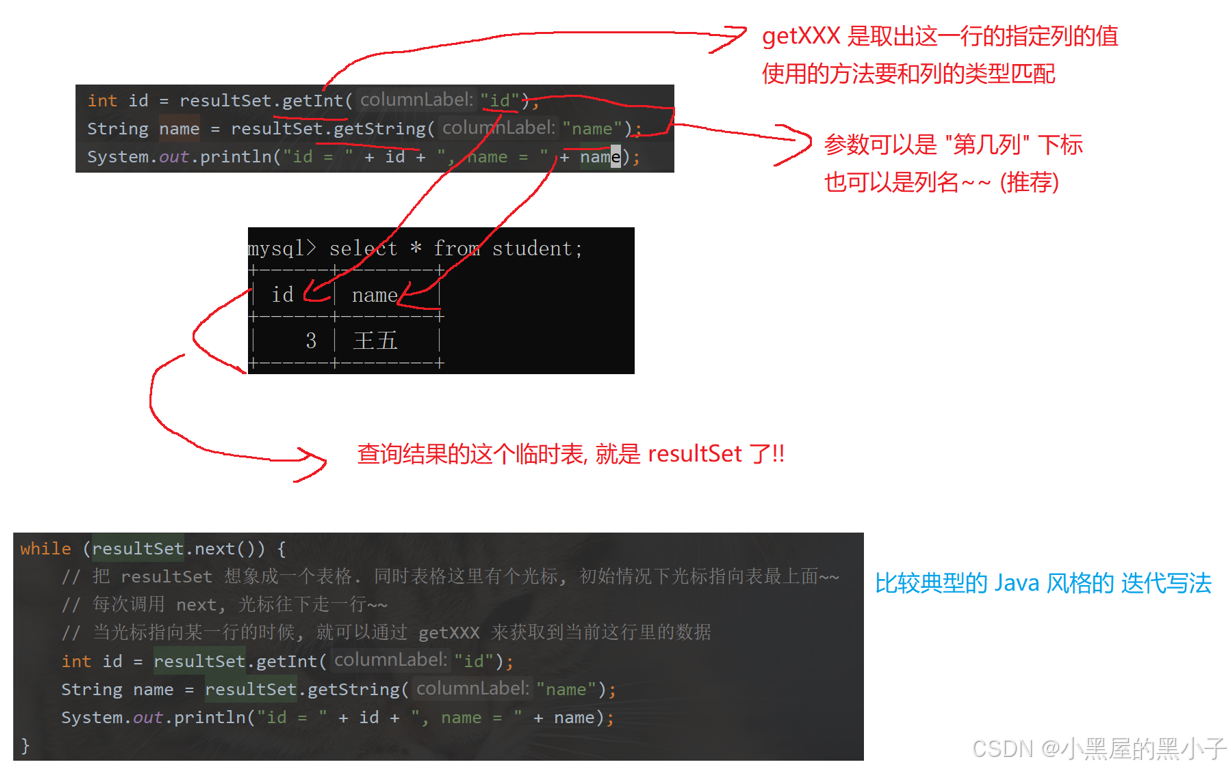
3. JDBC常用接口和类
3.1 JDBC API
3.2 数据库连接Connection
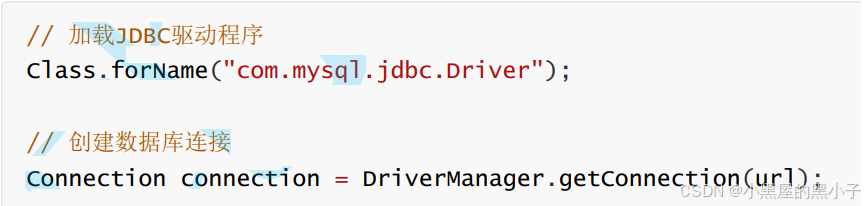
- 一种是通过DriverManager(驱动管理类)的静态方法获取:
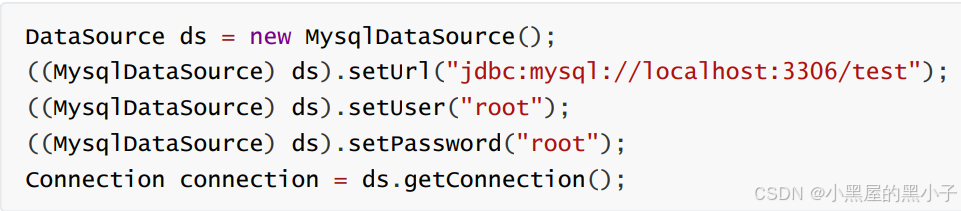
- 一种是通过DataSource(数据源)对象获取。实际应用中会使用DataSource对象。
- 以上两种方式的区别是:
3.3 Statement对象
Statement对象主要是将SQL语句发送到数据库中。JDBC API中主要提供了三种Statement对象

- SQL预编译
- 占位符:?下标从1开始
- 占位符不能使用多值
- 阻止常见SQL注入攻击
- 参数化SQL查询
- 性能比Statement高
- executeQuery() 方法执行后返回单个结果集的,通常用于select语句
- executeUpdate()方法返回值是一个整数,指示受影响的行数,通常用于update、insert、delete 语句
3.4 ResultSet对象
耦合、内聚
耦合:是两个模块之间的关联关系是不是非常紧密,是不是这边的变化会影响到另外一边。
高耦合,两个模块关联非常紧密,一边变化影响另一边程度比较大。
低耦合,两个模块关系不紧密,一边变化影响另一边程度比较小。
写代码要追求低耦合。如果耦合高了,随便改某个代码都会引起其他模块出现bug。
内聚:把相同的/相关联的功能,放到一起,内聚就高。零零散散哪里都有,内聚就低。
一个模块最好只实现一个功能。
写代码追求高内聚,低耦合。即相同功能代码放到一起,同时模块与模块之间不要有太大影响。
好啦Y(^o^)Y,本节内容到此就结束了。下一篇内容一定会火速更新!!!
后续还会持续更新MySQL方面的内容,还请大家多多关注本博主,第一时间获取新鲜的知识。
如果觉得文章不错,别忘了一键三连哟!
:ping命令出现问题)



