文章目录
- 相关资料
- 摘要
- 引言
- 方法
- CLIP回顾
- 伪标签生成
- 课程学习策略
- 实验
- 数据集
- 不同文本提示
- 失败案例分析
- 课程学习
- zero-shot分类
相关资料
论文:RS-CLIP: Zero shot remote sensing scene classification via contrastive vision-language supervision
摘要
零样本遥感场景分类旨在解决未见类别的场景分类问题,在遥感领域吸引了大量研究关注。现有方法大多使用浅层网络进行视觉和语义特征学习,并且在零样本学习过程中,语义编码器网络通常是固定的,因此无法捕获强大的特征表示进行分类。
在这项工作中,我们介绍了一种基于对比视觉-语言监督的遥感场景分类的视觉-语言模型。我们的方法能够使用对比视觉-语言损失在嵌入空间中学习语义感知的视觉表示。通过在大规模图像-文本数据集上预训练,我们的基线方法在遥感场景上显示出良好的迁移能力。为了在零样本设置中启用模型训练,我们引入了一种伪标记技术,可以自动从未标记的数据中生成伪标记。开发了一种课程学习策略,通过多阶段模型微调来提高零样本遥感场景分类的性能。
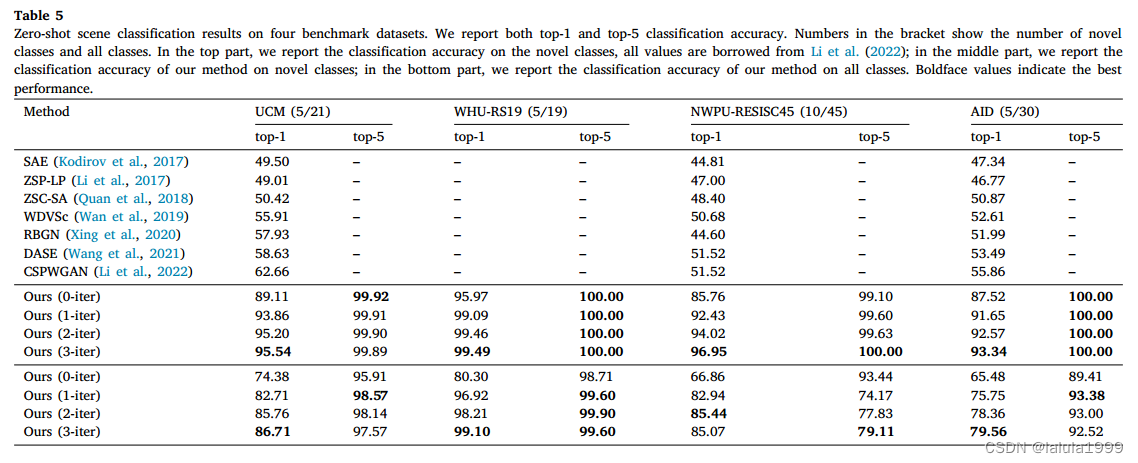
我们在四个基准数据集上进行了实验,并展示了在零样本和少样本遥感场景分类上都取得了显著的性能提升。所提出的RS-CLIP方法在UCM-21、WHU-RS19、NWPU-RESISC45和AID-30数据集的新类别上分别达到了95.94%、95.97%、85.76%和87.52%的零样本分类准确率。我们的代码将在https://github.com/lx709/RS-CLIP上发布。
引言
然而,现有方法大多使用在 Wikipedia 语料库上预训练的 word2vec 模型来从类别名称或描述中提取语义嵌入。在零样本学习过程中,语义嵌入被预处理并固定,而不与要对齐的视觉特征进行适应。这可能导致提取的语义嵌入的表示能力不足,以及视觉和语义特征之间的相当大的差异。以前的方法提出的另一个挑战是,它们通常使用浅层网络来学习视觉和语义特征。
为了解决这些问题,我们在本文中引入了一个用于遥感场景理解的视觉-语言模型。近年来,视觉-语言模型在计算机视觉中得到了广泛探索,并且为各种视觉识别任务构建了众多基础模型,特别是对于零样本和少样本学习。与自监督视觉特征学习方法不同,视觉-语言模型可以学习强大的视觉特征表示,并直接将视觉表示与自然语言在整体框架中连接起来,从而在语义知识的引导下实现更好的零样本迁移。
为了使模型适应遥感领域,我们引入了一种伪标记技术,可以自动从未标记的数据集中生成伪标记,从而在遥感领域上对模型进行微调。此外,开发了一种课程学习策略,通过多阶段模型微调来提高零样本遥感场景分类的性能。
方法
CLIP回顾
CLIP模型使用语言监督学习视觉表示,如图1所示。给定一批 N N N图像-文本对,CLIP模型试图预测图像和文本输入之间的正确对应关系。为了实现这一点,CLIP模型使用视觉编码器网络 E i E_i Ei来学习视觉表示,使用语言编码器网络 E t E_t Et来学习文本表示。在训练期间,CLIP模型预测一个相似度矩阵 S ∈ R N × N S∈ \mathbb{R}^{N×N} S∈RN×N,其中每一行表示一个图像与所有 N N N文本匹配的概率。CLIP模型通过最大化 N N N正对的相似度得分和最小化 N 2 − N N^2-N N2−N负对的相似度得分来优化。这是通过优化相似度矩阵上的对称交叉熵损失来实现的。

对于下游分类任务的 C C C个类别,{1, 2, … , C C C},CLIP使用预定义的提示,例如,“an image of a [CLASS]”,来构建文本输入 I I I,其中[CLASS]标记表示每个类别的名称/描述。然后,可以使用文本编码器网络生成所有类别的语义特征,即 F t = E t ( T ) ∈ R C × d F_t= E_t(T) \in \mathbb{R}^{C \times d} Ft=Et(T)∈RC×d,其中 d d d表示特征维度。给定一批输入图像表示为 I ∈ R B × H × W × 3 I \in \mathbb{R}^{B \times H \times W \times 3} I∈RB×H×W×3,其中 B B B, H H H,和 W W W分别表示批量大小、图像高度和宽度,我们可以通过图像编码器网络生成它们的视觉特征,即 F i = E i ( I ) ∈ R B × d F_i = E_i(I) \in \mathbb{R}^{B \times d} Fi=Ei(I)∈RB×d。之后,可以通过以下方式获得分类概率矩阵:
![[ P = \text{Softmax}(\frac{A^v A^l}{\sigma}) ]](https://img-blog.csdnimg.cn/direct/56b6c41672394769808108159fa452b0.png)
其中 F i F_i Fi和 F t F_t Ft是L2归一化的,它们的矩阵乘法等同于计算它们的余弦相似度。在类别维度上应用Softmax层,得到一个概率矩阵表示为 P ∈ R B × C P \in \mathbb{R}^{B \times C} P∈RB×C。 P P P的每一行表示将一张图像分配给所有可能类别的概率。最终的分类预测可以通过选择概率最大的类别来获得:
![[ \hat{y} = \text{argmax}(P) ]](https://img-blog.csdnimg.cn/direct/a230ed35f95e4cf2bf69f6eb0886a140.png)
伪标签生成
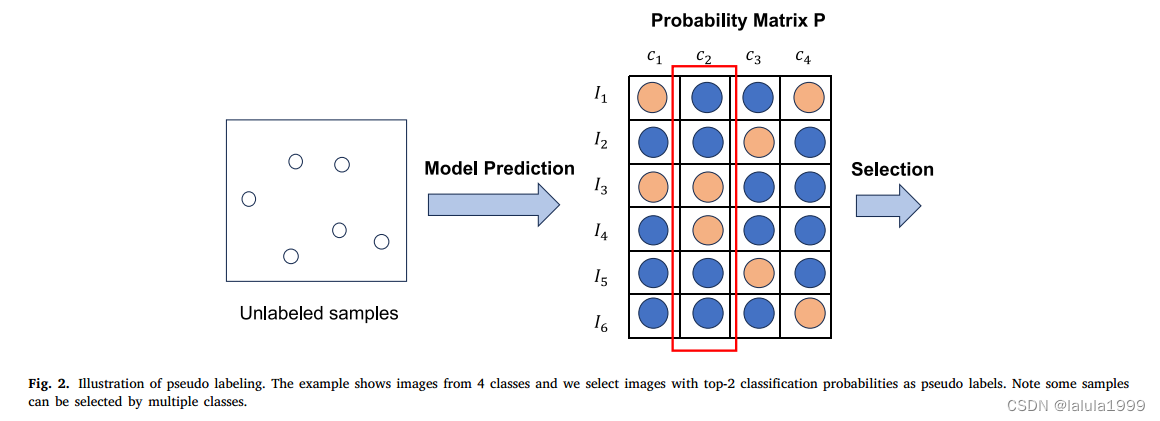
我们采用伪标记技术来启用模型在目标领域数据集上的训练,这在半监督学习中常用于自动从未标记数据生成伪样本。伪标记背后的直觉是,如果模型对某些样本给出了高置信度分数,我们可以使用预测的标签作为伪标签来重新训练模型并提高性能。
我们使用CLIP作为一个先验模型,为我们的零样本分类任务生成遥感图像的伪标签。我们遵循(Huang等人,2022)为每个类别选择相同数量的样本作为伪标签,这在在选择伪样本时防止了类别压倒性问题。
具体来说,对于每个类别 c c c,我们从概率矩阵中的方程(1)中选择置信度分数最高的top-K样本,可以表示为:
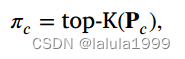
其中 P c P_c Pc表示概率矩阵 P P P的第 c c c列。通过所有可能类别的伪样本的并集,可以获得整体的伪标记样本,计算为:
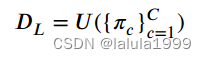
课程学习策略
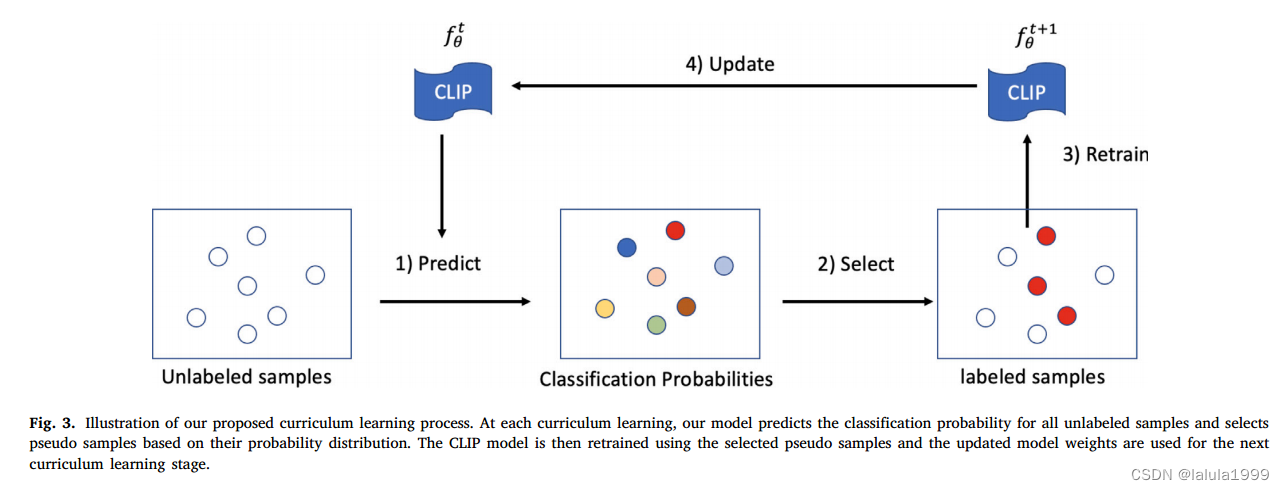
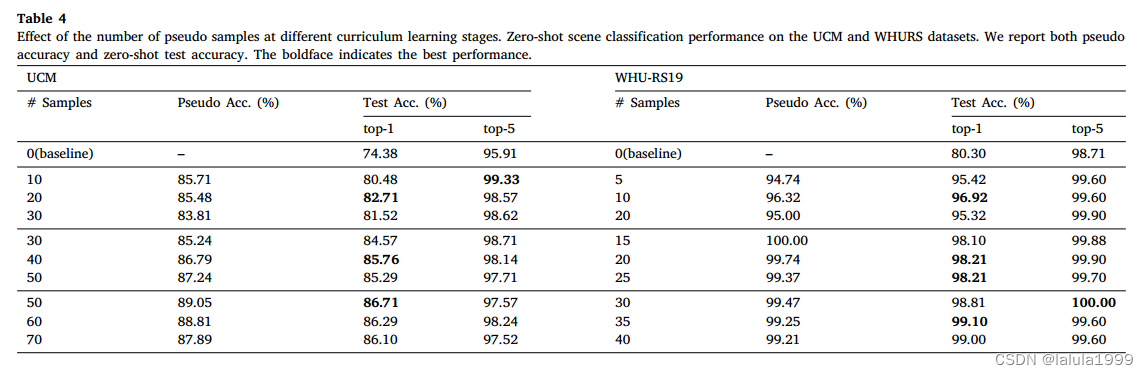
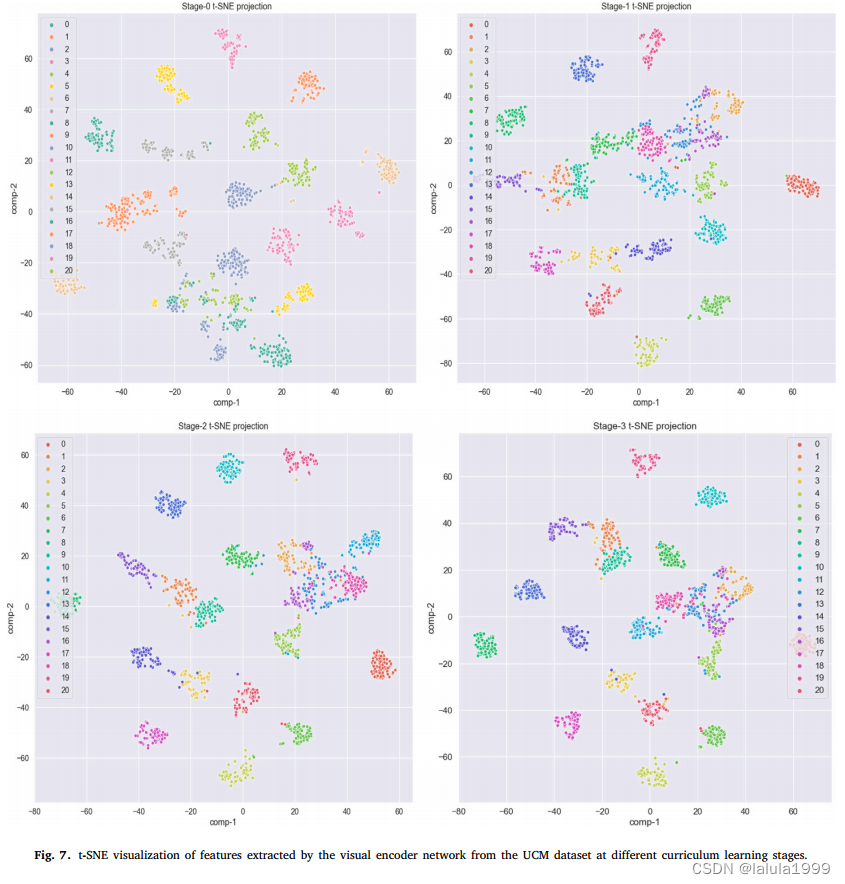
我们采用课程学习策略,在多轮中逐步选择更多样本进行模型训练。在早期的几轮中,模型对目标数据集的调整较少,因此,只有少数可信样本被选择作为伪数据进行训练。在后面的几轮中,模型对目标数据集的分类变得更有信心,从而可以选择更多未标记的样本作为伪标签。更具体地说,在迭代 r r r时,我们选择 K r K_r Kr样本作为伪标签,其中 K r K_r Kr是根据伪精度确定的。一般我们设 K r ≥ K r − 1 K_r≥K_{r-1} Kr≥Kr−1,表示后期会选择更多的伪样本。.
实验
数据集

不同文本提示

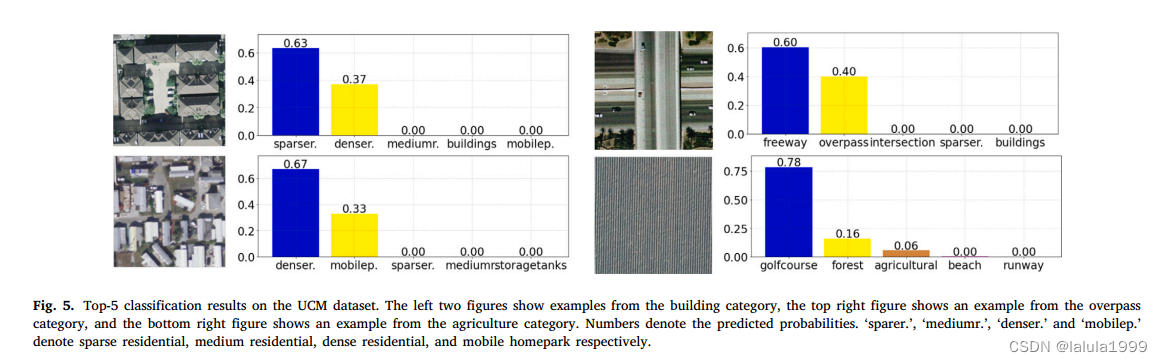
失败案例分析
课程学习
zero-shot分类




)
