在我们使用Python来和数据库打交道中,SQLAlchemy是一个非常不错的ORM工具,通过它我们可以很好的实现多种数据库的统一模型接入,而且它提供了非常多的特性,通过结合不同的数据库驱动,我们可以实现同步或者异步的处理封装。
1、SQLAlchemy介绍
SQLAlchemy 是一个功能强大且灵活的 Python SQL 工具包和对象关系映射(ORM)库。它被广泛用于在 Python 项目中处理关系型数据库的场景,既提供了高级的 ORM 功能,又保留了对底层 SQL 语句的强大控制力。SQLAlchemy 允许开发者通过 Python 代码与数据库进行交互,而无需直接编写 SQL 语句,同时也支持直接使用原生 SQL 进行复杂查询。下面是SQLAlchemy和我们常规数据库对象的对应关系说明。
Engine 连接对象 驱动引擎
Session 连接池 事务 由此开始查询
Model 表 类定义
Column 列
Query 若干行 可以链式添加多个条件
在使用SQLAlchemy时,通常会将其与数据库对象对应起来。以下是SQLAlchemy和常规数据库对象的对应关系说明:
1)数据库表 (Database Table)
-
SQLAlchemy: 使用
Table对象或Declarative Base中的类来表示。 -
对应关系: 数据库中的每一个表对应于SQLAlchemy中的一个类,该类继承自
declarative_base()。
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_baseBase = declarative_base()class User(Base):__tablename__ = 'users' # 数据库表名id = Column(Integer, primary_key=True)name = Column(String)email = Column(String)2)数据库列 (Database Column)
-
SQLAlchemy: 使用
Column对象来表示。 -
对应关系: 每个数据库表中的列在SQLAlchemy中表示为
Column对象,并作为类的属性定义。
id = Column(Integer, primary_key=True)
name = Column(String(50))3)数据库行 (Database Row)
-
SQLAlchemy: 每个数据库表的一个实例(对象)代表数据库表中的一行。
-
对应关系: 在SQLAlchemy中,通过实例化模型类来表示数据库表中的一行。
new_user = User(id=1, name='John Doe', email='john@example.com')4)主键 (Primary Key)
-
SQLAlchemy: 使用
primary_key=True参数定义主键。 -
对应关系: 在数据库表中定义主键列,这列在SQLAlchemy中也需要明确标注。
id = Column(Integer, primary_key=True)5)外键 (Foreign Key)
-
SQLAlchemy: 使用
ForeignKey对象来表示。 -
对应关系: 在SQLAlchemy中使用
ForeignKey指定关系,指向另一个表的主键列。
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationshipclass Address(Base):__tablename__ = 'addresses'id = Column(Integer, primary_key=True)user_id = Column(Integer, ForeignKey('users.id'))user = relationship('User')6)关系 (Relationships)
-
SQLAlchemy: 使用
relationship对象来表示。 -
对应关系: 数据库中表与表之间的关系在SQLAlchemy中通过
relationship来定义。
addresses = relationship("Address", back_populates="user")7)会话 (Session)
-
SQLAlchemy: 使用
Session对象进行事务性操作(如查询、插入、更新、删除)。 -
对应关系:
Session对象类似于数据库连接对象,用于与数据库进行交互。
from sqlalchemy.orm import sessionmakerSession = sessionmaker(bind=engine)
session = Session()session.add(new_user)
session.commit()通过以上对应关系,SQLAlchemy允许开发者以面向对象的方式与数据库交互,提供了一个Pythonic的接口来操作数据库。
2、SQLAlchemy 的同步操作
SQLAlchemy 提供了同步和异步两种操作方式,分别适用于不同的应用场景。以下是如何封装 SQLAlchemy 的同步和异步操作的方法说明:
在同步操作中,SQLAlchemy 使用传统的阻塞方式进行数据库操作。首先,定义一个基础的 Session 和 Engine 对象:
from sqlalchemy import create_engine
from sqlalchemy.orm import declarative_base, sessionmaker
from typing import Generator
from core.config import settings# 常规同步处理
engine = create_engine(settings.DB_URI)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)def get_db() -> Generator:"""创建一个 SQLAlchemy 数据库会话-同步处理."""try:db = SessionLocal()yield dbfinally:db.close()前面说了,使用SQLAlchemy可以实现不同数据库的统一模型的处理,我们可以对应创建不同数据库的连接(engine),如下是常规几种关系型数据库的连接处理。
# mysql 数据库引擎
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/WinFramework",pool_recycle=3600,# echo=True,
)# Sqlite 数据库引擎
engine = create_engine("sqlite:///testdir//test.db")# PostgreSQL 数据库引擎
engine = create_engine("postgresql+psycopg2://postgres:123456@localhost:5432/winframework",# echo=True,)# SQLServer 数据库引擎
engine = create_engine("mssql+pymssql://sa:123456@localhost/WinFramework?tds_version=7.0",# echo=True,)我们可以根据数据库的CRUD操作方式,封装一些操作,如下所示。
class CRUDOperations:def __init__(self, model):self.model = modeldef create(self, db, obj_in):db_obj = self.model(**obj_in.dict())db.add(db_obj)db.commit()db.refresh(db_obj)return db_objdef get(self, db, id):return db.query(self.model).filter(self.model.id == id).first()def update(self, db, db_obj, obj_in):obj_data = obj_in.dict(exclude_unset=True)for field in obj_data:setattr(db_obj, field, obj_data[field])db.commit()db.refresh(db_obj)return db_objdef remove(self, db, id):obj = db.query(self.model).get(id)db.delete(obj)db.commit()return obj使用时,构建数据访问类进行操作,如下测试代码所示。
crud_user = CRUDOperations(User)# Create
with get_db() as db:user = crud_user.create(db, user_data)# Read
with get_db() as db:user = crud_user.get(db, user_id)# Update
with get_db() as db:user = crud_user.update(db, user, user_data)# Delete
with get_db() as db:crud_user.remove(db, user_id)3、SQLAlchemy 的异步操作封装
对于异步操作,SQLAlchemy 使用 AsyncSession 来管理异步事务。
首先,定义一个异步的 Session 和 Engine 对象:
from sqlalchemy import create_engine, URL
from sqlalchemy.ext.asyncio import AsyncSession, async_sessionmaker, create_async_engine
from typing import AsyncGeneratordef create_engine_and_session(url: str | URL):try:# 数据库引擎engine = create_async_engine(url, pool_pre_ping=True)except Exception as e:print("❌ 数据库链接失败 {}", e)sys.exit()else:db_session = async_sessionmaker(bind=engine, autoflush=False, expire_on_commit=False)return engine, db_session# 异步处理
async_engine, async_session = create_engine_and_session(settings.DB_URI_ASYNC)async def get_db() -> AsyncGenerator[AsyncSession, None]:"""创建一个 SQLAlchemy 数据库会话-异步处理."""async with async_session() as session:yield session和同步的处理类似,不过是换了一个对象来实现,并且函数使用了async await的组合来实现异步操作。
为了实现我的SQLSugar开发框架类似的封装模式,我们参考SQLSugar开发框架中基类CRUD的定义方式来实现多种接口的封装处理。
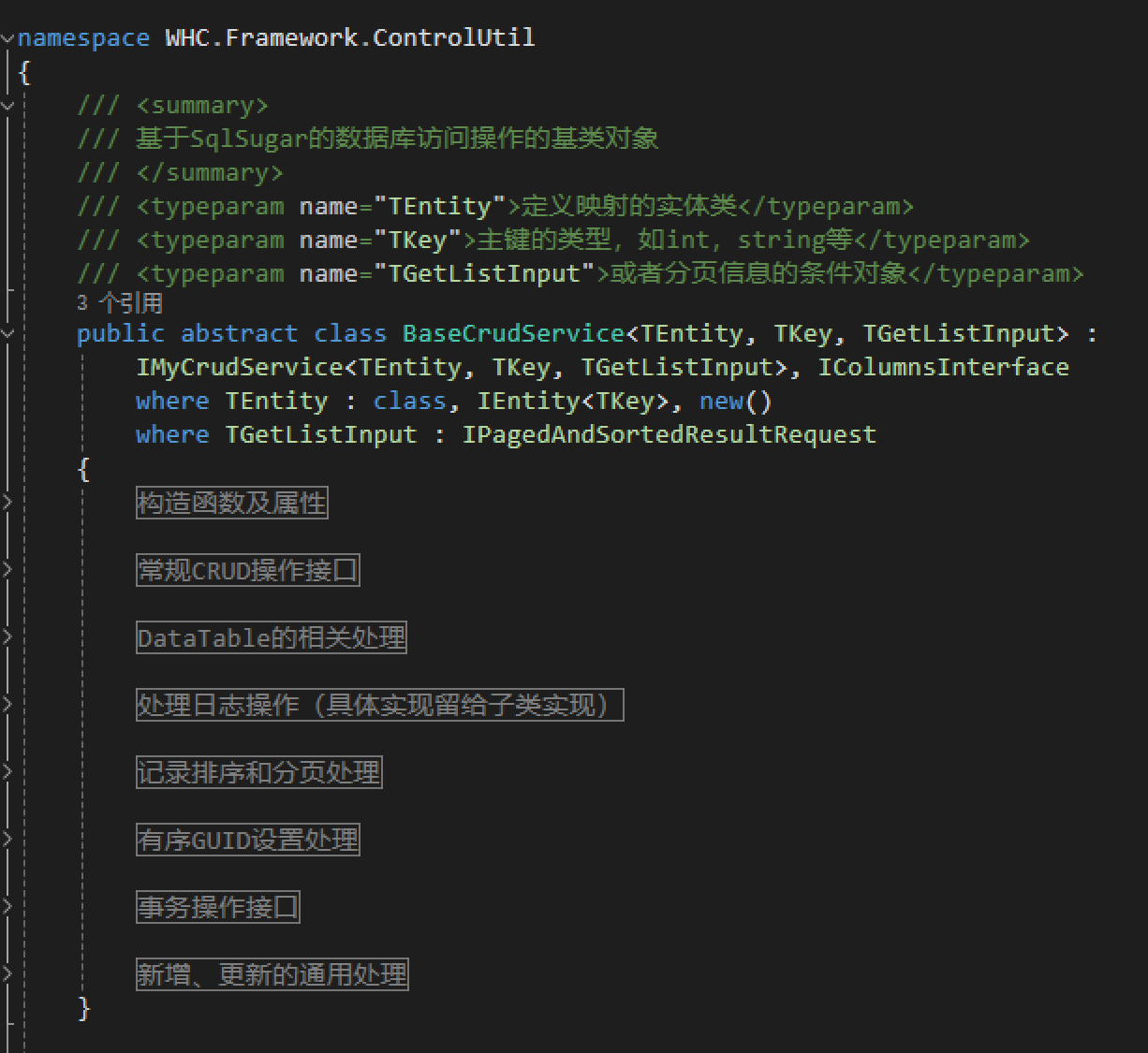
这样,我们就可以通过泛型定义不同的类型,以及相关的处理类的信息。
该基类函数中,异步定义get_all的返回所有的数据接口如下所示。
async def get_all(self, sorting: Optional[str], db: AsyncSession) -> List[ModelType] | None:"""根据ID字符串列表获取对象列表:param sorting: 格式:name asc 或 name asc,age desc"""query = select(self.model)if sorting:query = self.apply_sorting(query, sorting)result = await db.execute(query)items = result.scalars().all()return items而对应获得单个对象的操作函数,如下所示。
async def get(self, id: PrimaryKeyType, db: AsyncSession) -> Optional[ModelType]:"""根据主键获取一个对象"""query = select(self.model).filter(self.model.id == id)result = await db.execute(query)item = result.scalars().first()return item这个异步函数 create 旨在通过 SQLAlchemy 在数据库中创建一个对象,同时允许通过 kwargs 参数动态扩展创建对象时的字段。
-
async def: 表明这是一个异步函数,可以与await一起使用。 -
self: 这是一个类的方法,因此self引用类的实例。 -
obj_in: DtoType:obj_in是一个数据传输对象(DTO),它包含了需要插入到数据库中的数据。DtoType是一个泛型类型,用于表示 DTO 对象。 -
db: AsyncSession:db是一个 SQLAlchemy 的异步会话(AsyncSession),用于与数据库进行交互。 -
**kwargs: 接受任意数量的关键字参数,允许在对象创建时动态传入额外的字段。 -
obj_in.model_dump(): 假设obj_in是一个 Pydantic 模型或类似结构,它可以通过model_dump()方法转换为字典格式,用于创建 SQLAlchemy 模型实例。 -
db.add(instance): 将新创建的对象添加到当前的数据库会话中。 -
await db.commit(): 提交事务,将新对象保存到数据库。 -
SQLAlchemyError: 捕获所有 SQLAlchemy 相关的错误。 -
await db.rollback(): 在发生异常时,回滚事务,以防止不完整或错误的数据被提交。
from crud.customer import customer as customer_crud
from models.customer import Customer
from pydantic import BaseModel
from schemas.customer import CustomerDto, CustomerPageDtoasync def test_list_customer():async with get_db() as db:print("get_list")totalCount, items = await customer_crud.get_list(CustomerPageDto(skipCount=0, maxResultCount=10, name="test"),db,)print(totalCount, items)for customer in customers:print(customer.name, customer.age)print("get_by_name")name = "test"customer = await customer_crud.get_by_name(name,db,)if customer:print(customer.name, customer.age)else:print(f"{name} not found")print("soft delete")result = await customer_crud.delete_byid(customer.id, db, is_deleted=1)print("操作结果:", result)print("soft delete_byids")result = await customer_crud.delete_byids(["11122", "2C5F8672-2AA7-4B14-85AD-DF56F5BF7F1F"], db, is_deleted=1)print(f"Soft delete successful: {result}")print("update_by_column")result = await customer_crud.update_by_column("id", customer.id, {"age": 30}, db)print("操作结果:", result)await db.close()同步和异步处理的差异:
-
同步操作 适用于传统的阻塞式应用场景,比如命令行工具或简单的脚本。
-
异步操作 更适合异步框架如
FastAPI,可以提高高并发场景下的性能。
通过封装数据库操作,可以让代码更具复用性和可维护性,支持不同类型的操作场景。
文章转载自:伍华聪
原文链接:https://www.cnblogs.com/wuhuacong/p/18373356
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构




