💓博主CSDN主页:杭电码农-NEO💓
⏩专栏分类:Linux从入门到精通⏪
🚚代码仓库:NEO的学习日记🚚
🌹关注我🫵带你学更多操作系统知识
🔝🔝

Linux网络
- 1. 前言
- 2. 序列化和反序列化
- 3. 认识URL
- 4. HTTP的报文格式
- 5. HTTP方法详解
- 6. HTTP的状态码和header
- 7. HTTP会话管理
- 8. 总结以及拓展
1. 前言
在理解了网络套接字编程后, 后续的文章会从应用到链路层, 详解的讲解每一层的协议都做了些什么工作, 并且会拆分协议的格式内容, 深入的理解网络四层模型
本章重点:
本篇文章会先带大家了解序列化和反序列化过程.然后会带大家进入到HTTP协议的学习, 包括URI, 协议格式, HTTP的方法以及常见的状态码和header. 当然,由于TCP协议是最常用的, 所以讲解的内容是基于TCP协议的
2. 序列化和反序列化
TCP协议中, 数据在网络中传输是以字节流的形式, 然而我们想发给对端的数据可不一定是单纯的字符串, 有可能是结构体数据.
打个比方:
一个网络版本的计算机, 用户输入操作数和操作符后,会通过网络发给服务器, 比如: 用户想计算1+2,那么它可能会使用一个结构体保存操作数和操作符, 并且可能会使用一个结构体来保存计算后返回后的结果和错误描述:
class req
{float left;//左操作数char op;//操作符float right;//右操作数
};class rsp
{float ret;//返回结果string comment;//返回的错误描述
};
但是我们进行网络传输时不能直接传输结构体数据,必须先把结构体数据转换成字节流才能发送到网络, 同理,得到的结果也不可能是一个i结构体数据, 而是一段字节流, 我们需要想办法将结构体数据转化为字节流,这个过程称为序列化过程. 将字节流的数据转换为结构体数据的过程叫反序列化
并且由于TCP协议发包时, 一个完整的数据可能会分多次发送过去, 所以我们一个完整的字节流数据不能只有数据,还需要有一些特殊的符号来标识一个数据的开始和结尾.这里我们可以自己制定协议,用前后三个问好标识数据的完整性

聪明的你可能已经发现了, 不仅仅需要特殊符号来标识数据的完整性, 来需要一些特殊符号来将结构体中的不同字段分隔开来. 今天的示例中结构体的数据很少, 我们可以自己制定协议, 只要服务器和客户端都按照我们制定的协议进行序列化和反序列化也可以正常工作. 但是一旦遇见一个结构体有很多字段,甚至传递数组类型时,我们自己设定的方案未免太简陋了,所以这里给出几个常用的序列化/反序列化工具:
json有字符串,整型,布尔类型, 数组, 对象等数据类型
{ "firstName": "Brett", "lastName":"McLaughlin", "email": "brett@newInstance.com" }
json是以key:value的格式来序列化的,比如我们的示例中:
{ "left" : 1, "op" : "+", "right" : 2}
XML, 和json类似
<person age="too young" experience="too simple" result="sometimes naive" />或者这样:<person><age value="too young" /><experience value="too simple" /><result value="sometimes naive" />
</person>
protobuf,这个比较复杂,初学者了解前两个就可以了
不管你使用什么协议, 都必须做到客户端和服务器双方进行序列化和反序列化时使用的同一种加解密方法. 否则是行不通的!
3. 认识URL
先来看一个全面的URL:
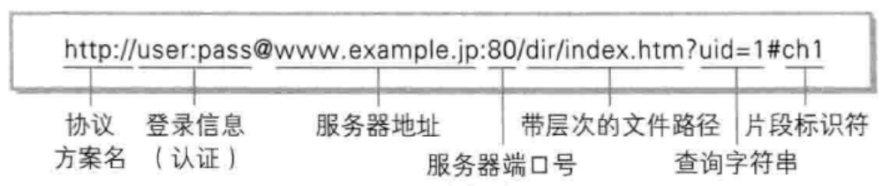
重点看问号?之前的信息:
www.example.jp代表IP地址. 80代表端口号. 所以IP和port就能定位到全网唯一一个服务. 80后面的/dir/index代表的是你想要访问这个服务下的哪一个资源, 这个后面会讲. 最后就是问号后面的数据了. URL中的问号是特殊符号,它代表问号后的所有信息都是某些参数
注意,不管是一张图片,一段文字还是一个视频. 这些资源在没有被你获取到时,它都在服务器上. 一个Linux服务器可能存在很多资源, 这里所谓的资源也就是文件中的内容(Linux下一切皆文件). 所以端口号后面的/代表的是想要获取的资源(文件)的路径!!!
4. HTTP的报文格式
HTTP的报文格式分为请求的格式和响应的格式
真实的HTTP请求格式:
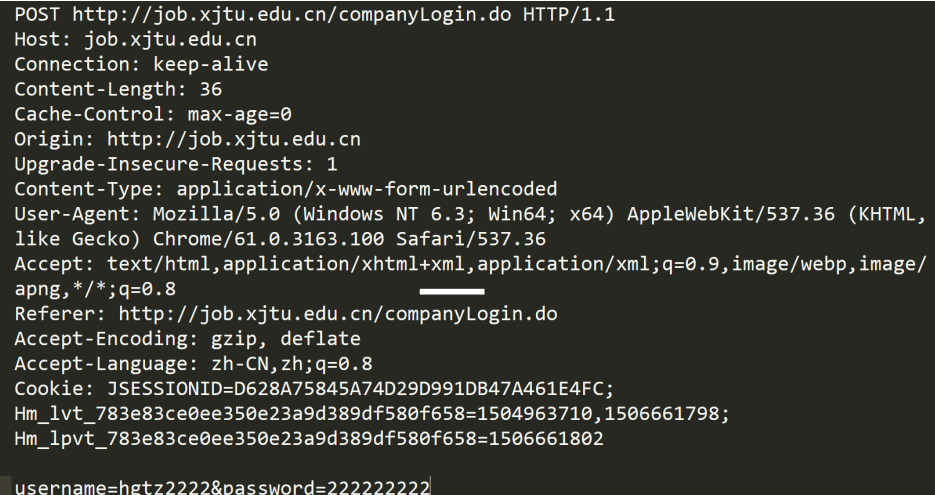
这个看起来很杂乱,很没有规律, 但是其实可以将报文分为三个部分: 请求行, 请求报头(存放属性), 空行(分隔符), 请求正文(可有可无).
- 首行: [方法] + [url] + [版本]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;

真实的HTTP响应格式:
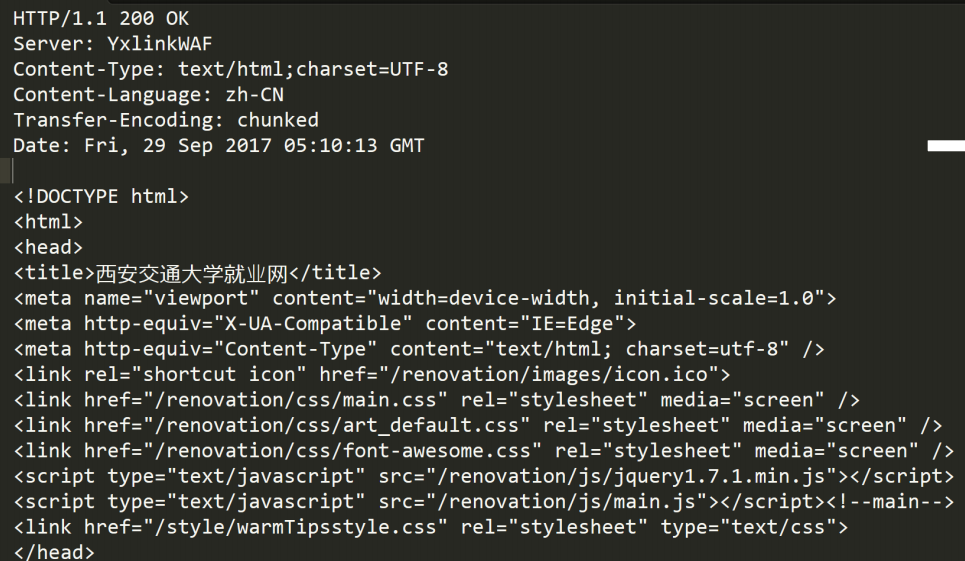
我们也可以将它分为三部分: 1. 状态行 2. 响应报头 3. 空行(用于分割) 4. 响应正文(视频,图片等资源)
- 首行: [版本号] + [状态码] + [状态码解释]
- Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.

5. HTTP方法详解
HTTP的方法列举:
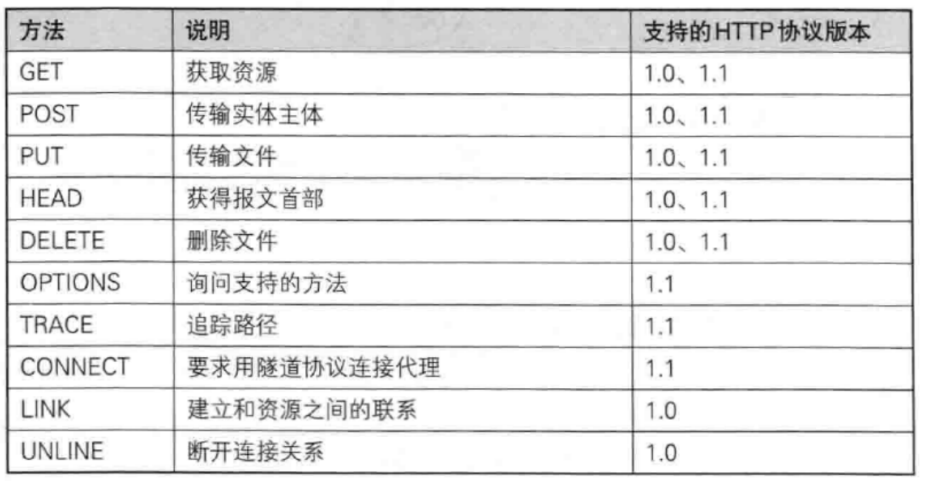
最常用的就是GET和POST方法
我们平时上网的行为其实可以归结于两种: 1. 从服务器上拿下来资源数据 2. 把客户端的数据上传到服务器进行处理. 所以GET和POST方法就是来完成这两种事情的!
GET方法详解
首先, GET方法分为带参的GET方法和不带参的GET方法. 带参的GET方法是为了完成情况二: 上传数据给服务器. 而不带参数的GET方法是为了完成情况一: 从服务器拿下来数据. 那么带参的GET方法的参数在什么地方呢? 相信你肯定还记得前面在讲URL的时候说到,问号后面的都代表参数. 是的没错,GET方法的参数就在URL上面
比如我现在写博客的链接是:
https://editor.csdn.net/md?articleId=139577030
articleId=139577030就是参数
综上所述, 带参的GET方法通过URL将参数传递给服务器
POST方法详解
首先,使用POST方法只有一种情况, 那就是上传数据到服务器进行处理, 但是POST方法的参数并不直接放在URL上. 那么它放在哪里呢? 相信你一定记得前面在讲HTTP报头时, 有一行叫做请求正文. 是的没错, POST方法的参数不会回显到URL上,而是放在了请求正文中.

6. HTTP的状态码和header
状态码的本质就是一个整数,常见的状态码:
- 200 表示ok,请求正常处理完毕
- 404 这个相信大家很熟悉,就是没找到服务
- 505 表示服务器内部错误
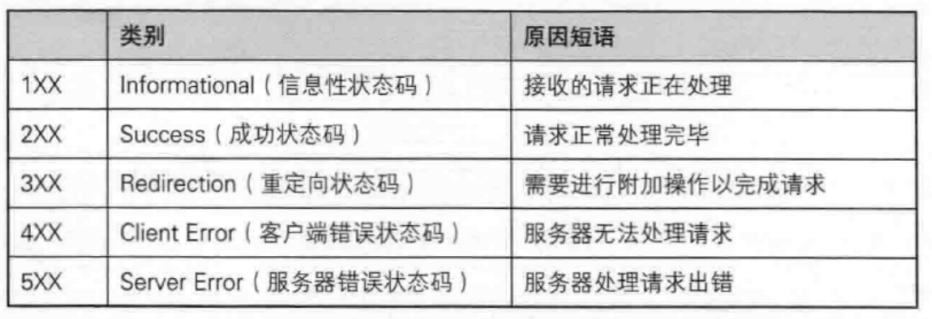
HTTP常见的header
- Content-Type: 数据类型(text/html/json等)
- Content-Length: Body的长度

7. HTTP会话管理
你有没有发现, 一个网站如果你经常访问或只访问过一次, 当你下一次访问时会自动登录你的账号以及相关信息, 这是怎么做到的?
答案是HTTPheader中有一个字段叫cookie, 当我们第一次访问一个网站时, 会注册我们的账号信息, 这个账号信息是被放在你当前计算机的文件中的,被称为cookie文件. 当你再次打开这个网站后, 你cookie文件中保存的用户相关的信息,比如你曾经输入的账号密码就会被放在HTTP的header中的cookie字段中, 一起发送给服务器, 服务器一看你曾经来过, 就直接给你身份使用了!

虽然cookie能方便你的使用,但是它并不安全, 所以会有session来代替cookie.这里就不过多讲诉了, 有兴趣可以自行去了解session的工作原理
8. 总结以及拓展
HTTP是明文发送数据的,所以HTTP并不安全, 我们访问的网站很多都是HTTPs开头的. 这是因为HTTPs增加了对称加密和非对称加密,以及CA认证的方式保证了数据的安全. 有兴趣的可以自行了解HTTPs的工作原理是什么.
其实看到这儿你会发现,所谓的协议其实就是为了方便通信双方进行数据交互而存在的, HTTP协议也不例外.




