Data Augmentation for Text-based Person Retrieval Using Large Language Models
这篇论文主要研究文本基础的人员检索(Text-based Person Retrieval, TPR)任务中的数据扩充问题,并提出了一种基于大语言模型(Large Language Models, LLM)的数据增强方法(LLM-DA)来解决该问题。
问题描述
构建大规模高质量的TPR数据集存在两个主要挑战:
- 数据匮乏:由于隐私保护问题,难以获取大规模的人员图像数据。
- 高质量标注困难:文本标注工作繁琐且不可避免地会引入标注偏差,现有的TPR数据集中的文本通常较短,无法全面描述目标人员的特征,并且存在偏差。
- 传统的数据扩充方法局限性:(如图像扩充和文本扩充)在提升TPR模型性能方面有限,尤其是简单的文本扩充方法(如随机删除、来回翻译)可能会破坏正确的句子结构,甚至改变原始语义概念,反而对模型训练有负面影响。
解决方法
为了解决上述问题,本文提出了一种基于大语言模型的文本数据增强方法(LLM-DA),框架如下:
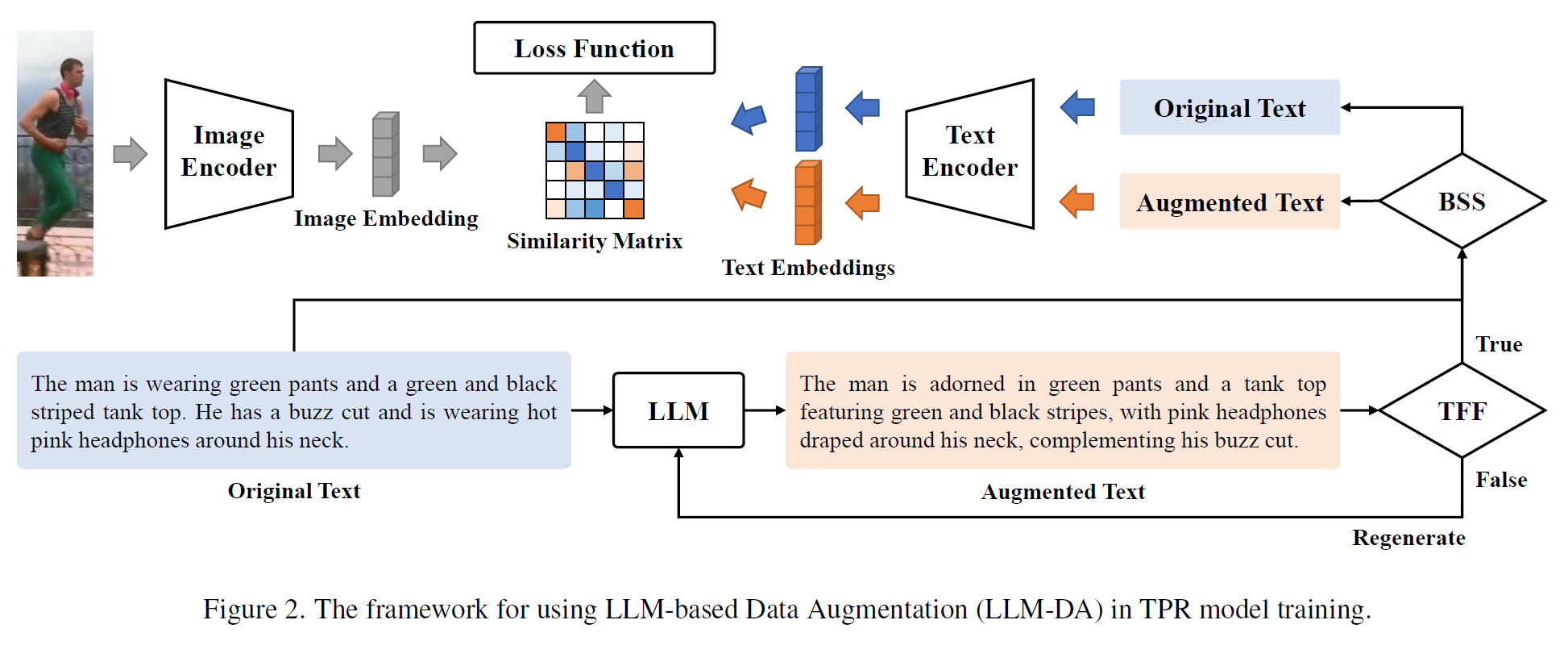
主要包括以下几个步骤:
-
LLM文本重写:使用大语言模型(如Vicuna)对现有TPR数据集中的文本进行重写,以生成多样化的文本。这些重写的文本在增加词汇和句子结构多样性的同时,保留了原始的关键概念和语义信息。
prompt:Rewrite this image caption.
-
文本真实性过滤器(Text Faithfulness Filter, TFF):由于LLM在生成文本时可能出现与原始文本不一致的“幻觉”问题(hallucination),TFF被引入以过滤掉存在噪声的重写文本。该过滤器通过计算原始文本和增强文本的语义相似度,确保增强文本与原始文本在语义上保持一致。
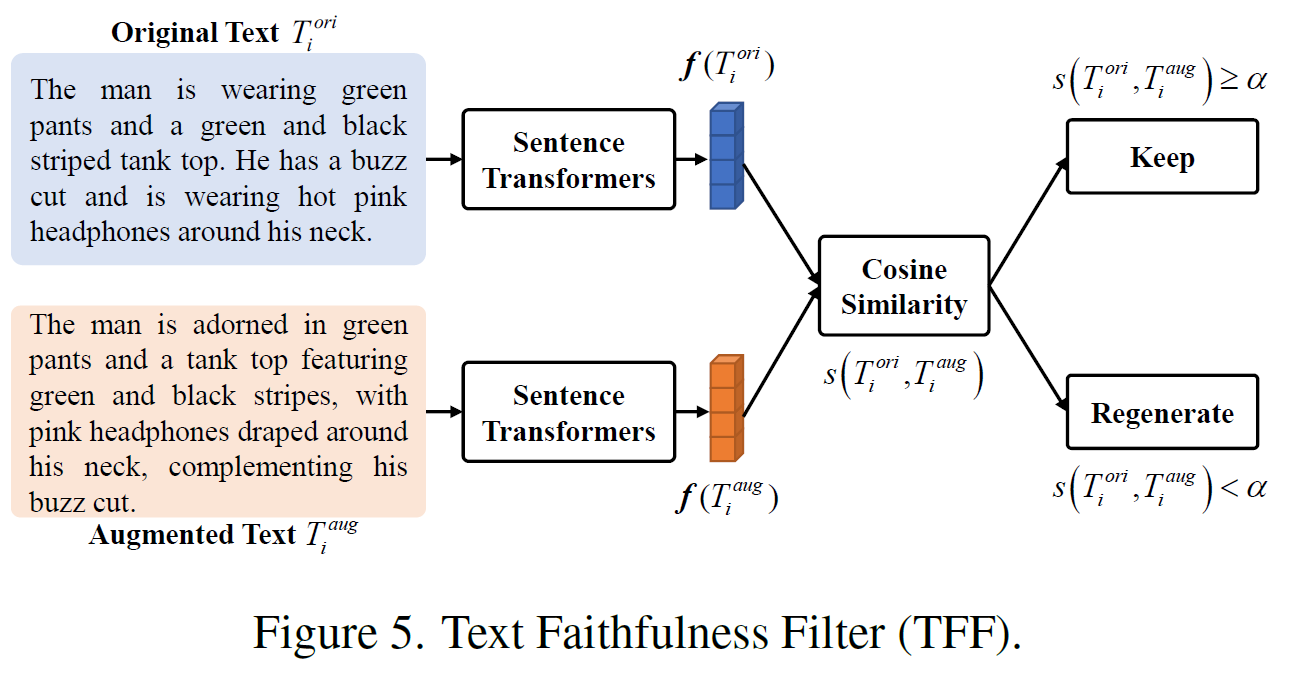
-
平衡采样策略(Balanced Sampling Strategy, BSS):为了平衡原始文本和增强文本在训练中的比例,BSS被用来控制训练中使用的原始文本和增强文本的比例。该策略通过抽样来生成一个混合相似性矩阵,该矩阵既包含图像和原始文本之间的相似性,也包含图像和增强文本之间的相似性,从而更好地实现模型训练。
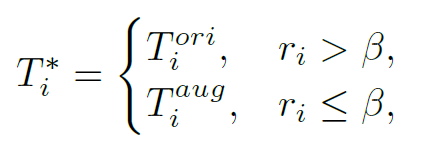
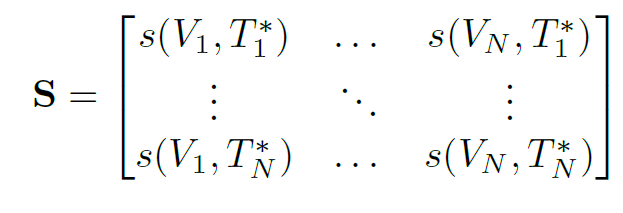
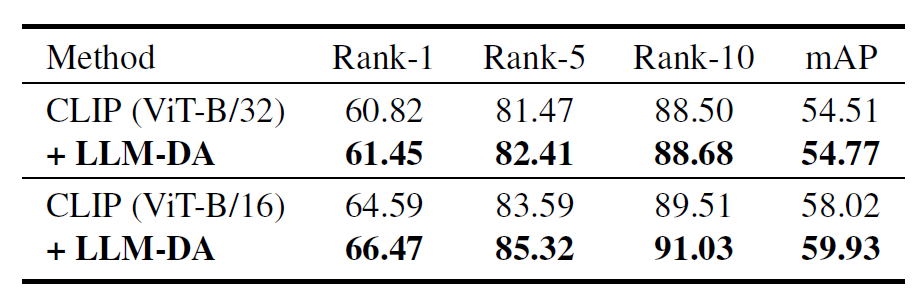
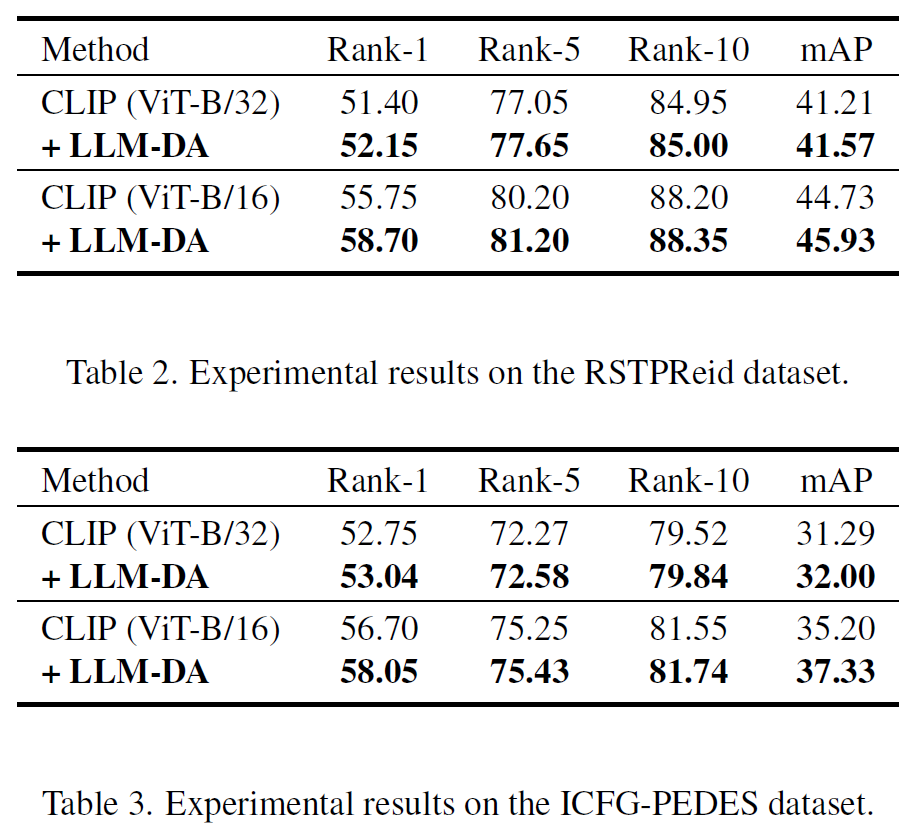
实验结果
本文提出的LLM-DA方法是一种易于集成的“即插即用”方法,可以在不改变原始模型结构或损失函数形式的情况下显著提升TPR模型的性能。
Diverse Person: Customize Your Own Dataset for Text-Based Person Search
提出的问题
现有的数据集在多样性和细粒度特征上仍存在不足。此外,生成新的现实世界数据集面临行人隐私泄露的风险以及标注成本高的问题。现有的虚拟数据集虽然在一定程度上解决了这些问题,但其生成的文本注释的多样性和真实性远不及人工标注。

解决方案
为了解决上述问题,论文提出了一种名为“Diverse Person (DP)”的新框架来生成高质量且多样化的文本描述行人搜索数据集。
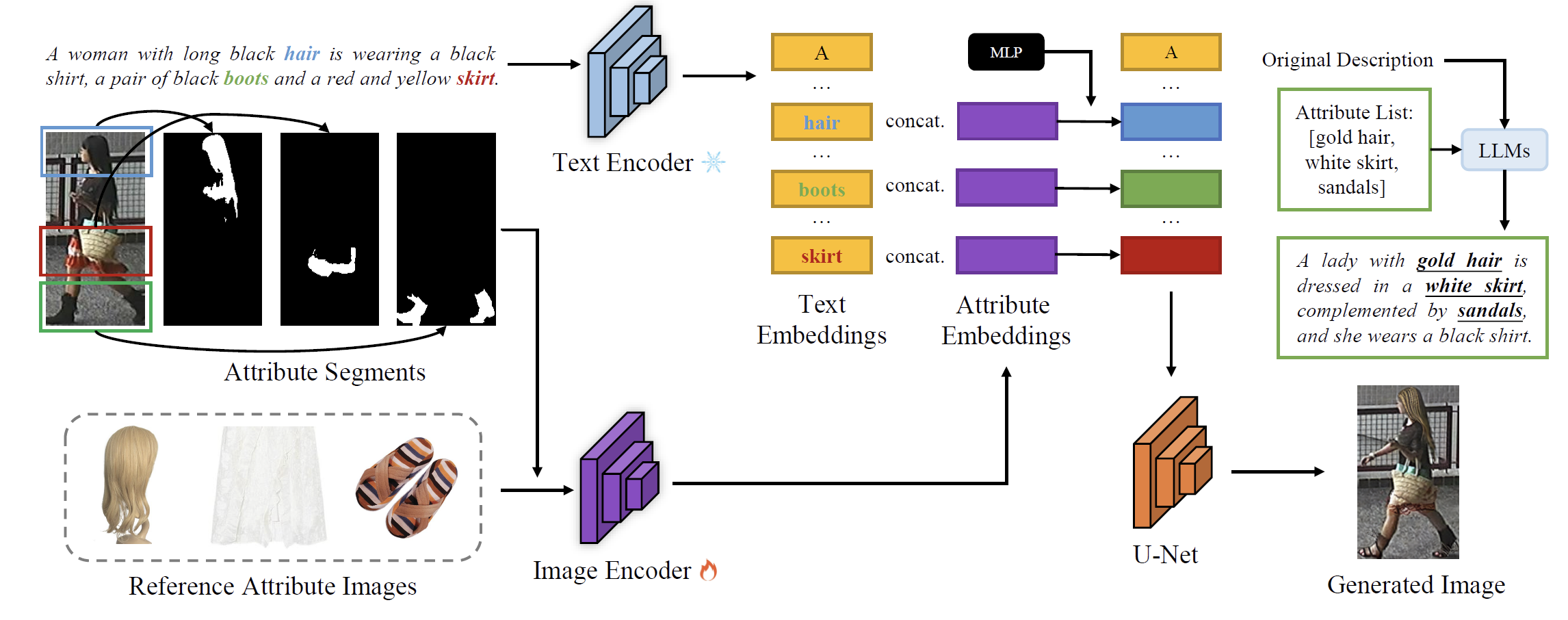
其方法主要包括以下几个步骤:
-
基于扩散模型的数据编辑:利用现有的服装和配饰图像作为参考属性图像,通过扩散模型对原始数据集图像进行编辑,从而生成多样化的图像数据。
-
大语言模型(LLM)生成注释:采用大语言模型(例如ChatGPT)基于原始注释并结合参考属性图像生成高质量的文本注释,这些注释在风格上与现实世界数据集保持一致。
-
基于属性的嵌入表示:通过视觉和文本特征的融合来增强生成图像与参考属性的对应关系,从而提高模型的判别能力。
结果
Harnessing the Power of MLLMs for Transferable Text-to-Image Person ReID
提出的问题:

-
文本描述的多样性问题:多模态大语言模型(MLLMs)在生成图像的文本描述时,往往具有相似的句子结构。这导致训练得到的文本到图像ReID模型容易过拟合特定的句子模式,降低了模型对真实世界中各种人类描述风格的泛化能力。
-
文本描述中的噪声问题:MLLMs生成的文本描述中可能存在错误,一些词汇可能与图像不匹配。错误的文本描述会影响模型的训练效果。
解决办法:
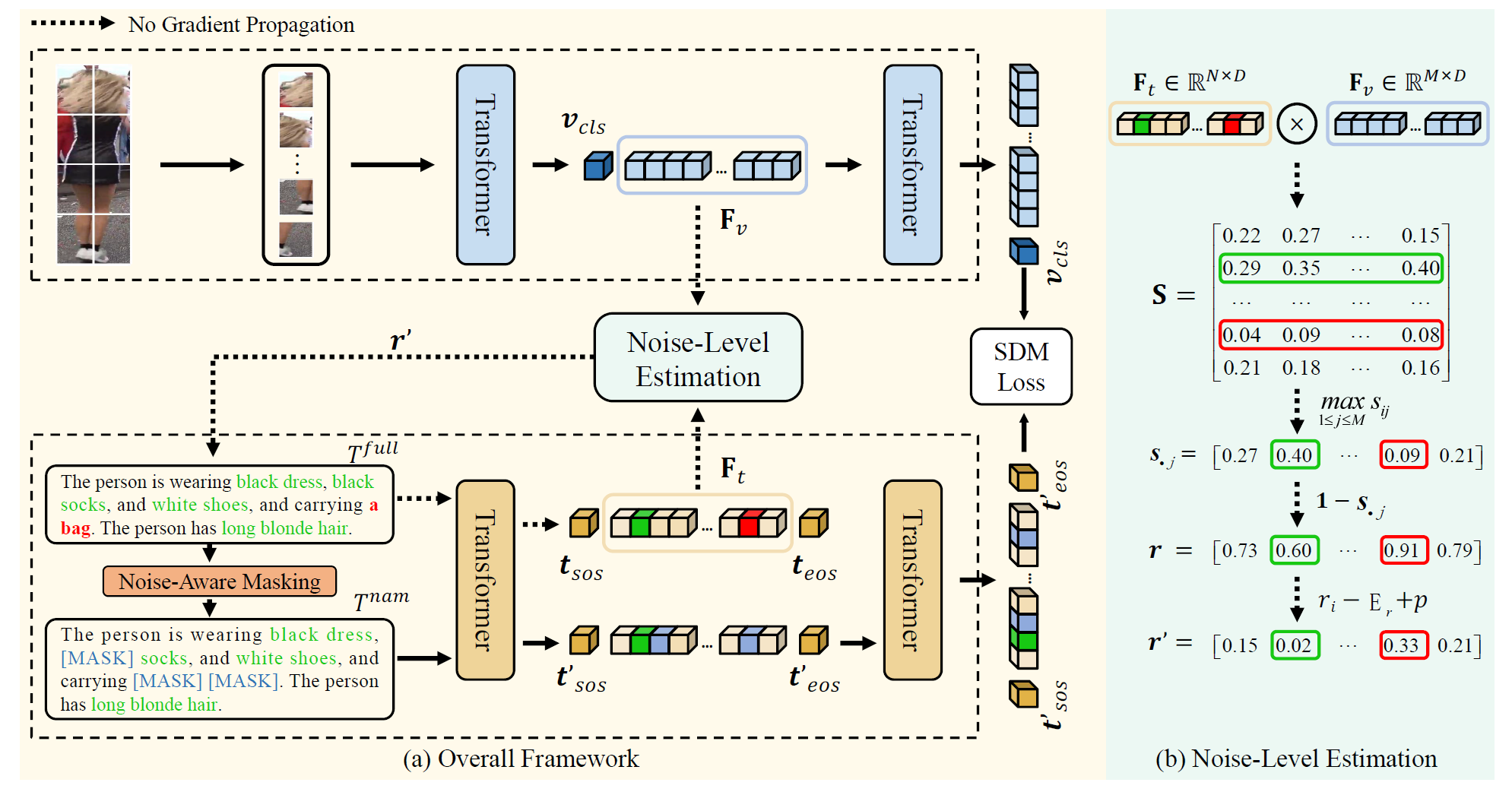
-
模板多样性增强(Template-based Diversity Enhancement, TDE)方法:
- 针对文本描述的多样性问题,论文提出了一种基于模板的多样性增强方法。通过与ChatGPT进行多轮对话,生成多种描述模板,然后让MLLMs根据这些模板来生成图像的文本描述。这种方法显著增加了文本描述的多样性,使得生成的描述具有不同的句子结构,减少模型的过拟合问题。
- “Wearing [clothing description], the [person/woman/man] also has [hair description] and is carrying [belongings description].”,
- “Sporting [hair description], the [person/woman/man] is dressed in [clothing description] and is carrying [belongings description].”,
- “With [hair description], the [person/woman/man] is wearing [clothing description] and is also carrying [belongings description].”,
- 针对文本描述的多样性问题,论文提出了一种基于模板的多样性增强方法。通过与ChatGPT进行多轮对话,生成多种描述模板,然后让MLLMs根据这些模板来生成图像的文本描述。这种方法显著增加了文本描述的多样性,使得生成的描述具有不同的句子结构,减少模型的过拟合问题。
-
噪声感知掩码(Noise-aware Masking, NAM)方法:
- 针对文本描述中的噪声问题,论文提出了一种新的噪声感知掩码方法。具体来说,计算每个文本标记与图像标记之间的相似性来识别潜在的错误词汇。对于不匹配的词汇,在后续训练中以较大的概率进行掩码,从而减少噪声文本描述对模型训练的负面影响。该方法与传统的掩码语言建模(MLM)不同,NAM根据噪声水平来掩码词汇,而不是均匀掩码。
相似性矩阵计算:
- 使用图像和文本编码器在第 l l l 层的特征嵌入,计算文本标记和图像标记之间的相似性。具体来说,给定文本特征嵌入 F t = [ t 1 l , . . . , t N l ] F_t = [t_1^l, ..., t_N^l] Ft=[t1l,...,tNl] 和图像特征嵌入 F v = [ v 1 l , . . . , v M l ] F_v = [v_1^l, ..., v_M^l] Fv=[v1l,...,vMl],通过内积计算相似性矩阵 S ∈ R N × M S \in \mathbb{R}^{N \times M} S∈RN×M,其中 s i j s_{ij} sij 表示第 i i i 个文本标记和第 j j j 个图像标记之间的余弦相似度: S = F t T F v S = F_t^T F_v S=FtTFv
文本标记的噪声水平估计:
- 如果某个文本标记与图像不匹配,那么该文本标记的嵌入与所有图像标记的嵌入之间的相似性得分通常较低。因此,可以使用以下公式估计每个文本标记的噪声水平 r i r_i ri: r i = 1 − ( max 1 ≤ j ≤ M s i j ) r_i = 1 - \left( \max_{1 \leq j \leq M} s_{ij} \right) ri=1−(max1≤j≤Msij)
- 上述公式计算出向量 r = [ r 1 , . . . , r N ] r = [r_1, ..., r_N] r=[r1,...,rN],它记录了所有文本标记的噪声水平。
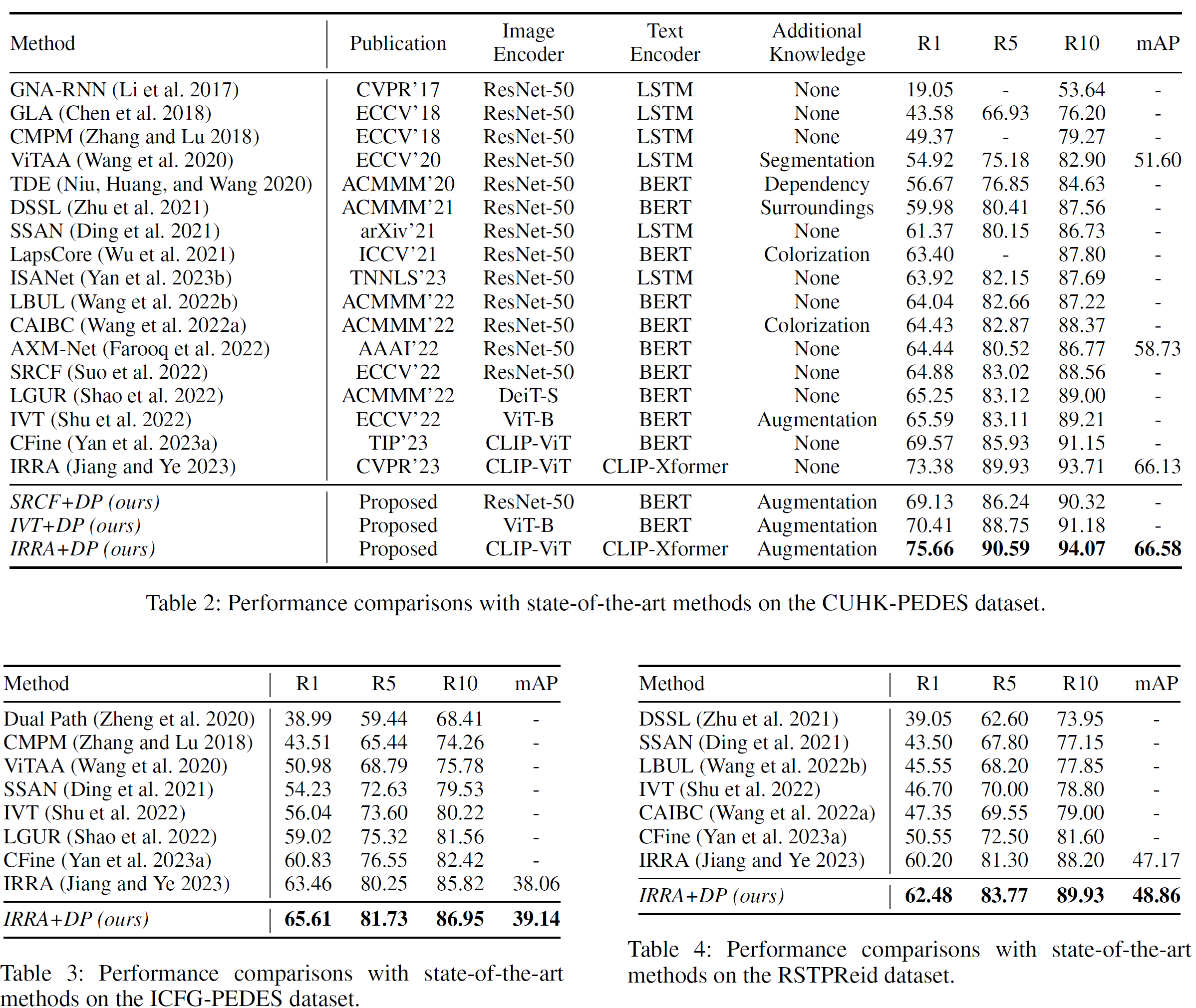
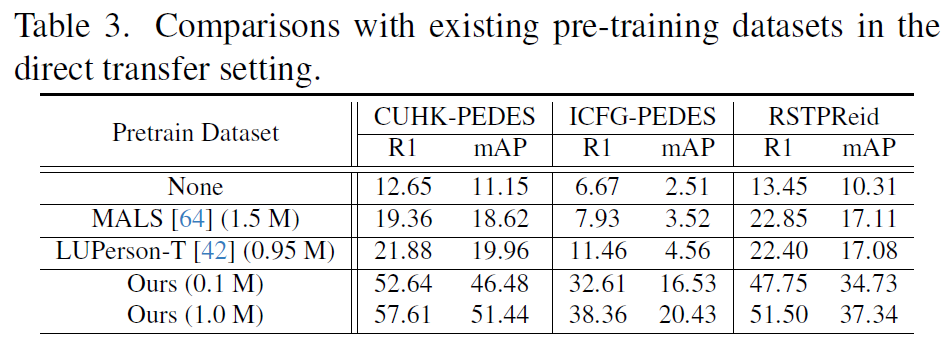
**整体训练策略:**首先在大规模的LUPerson-MLLM数据集上进行模型的预训练,然后直接在三个主流的ReID基准(CUHK-PEDES、ICFG-PEDES和RSTPReid)上进行测试。也尝试了在三个数据集上的微调。
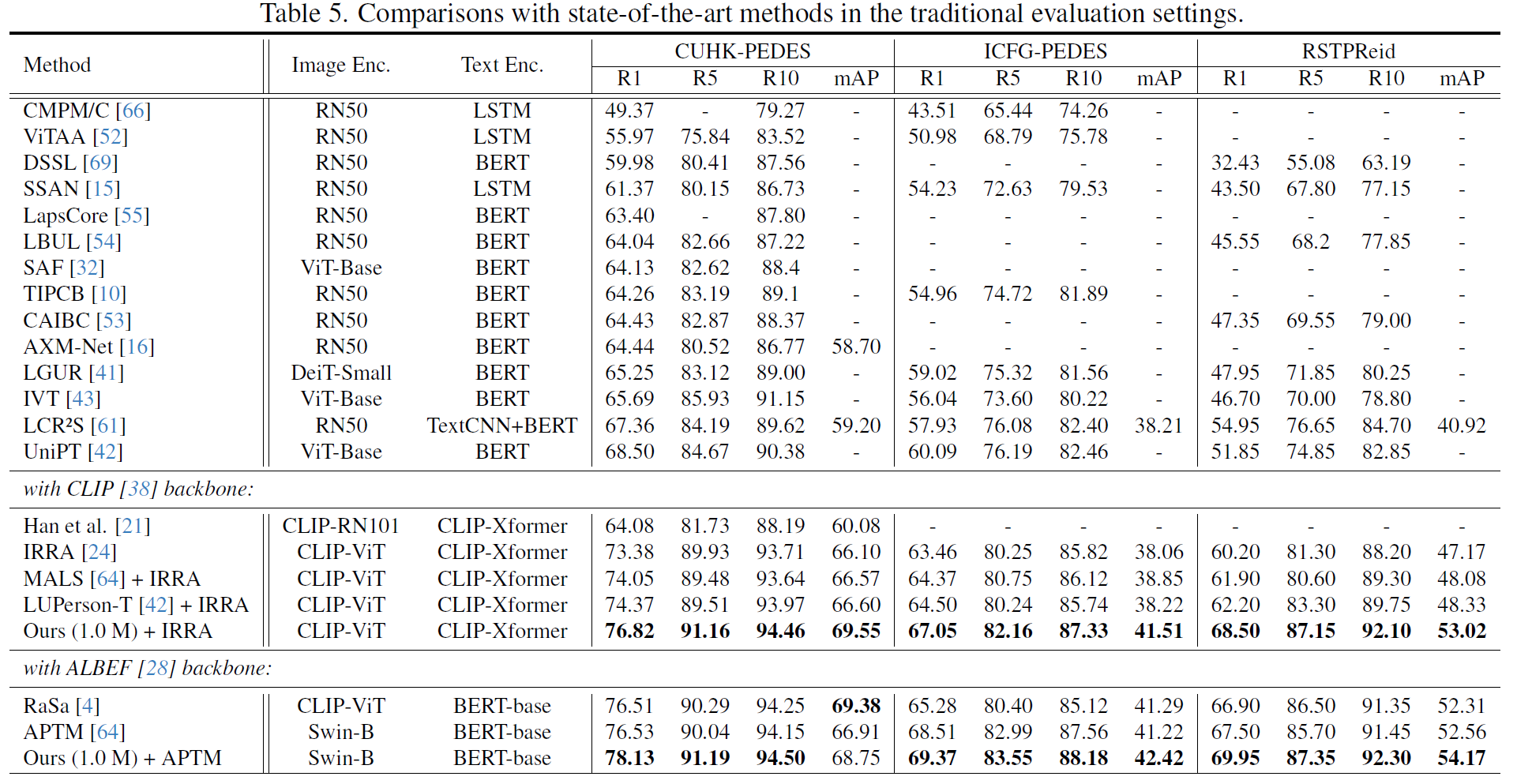
实验结果:
MLLMReID: Multimodal Large Language Model-based Person Re-identification
CVPR-2024
提出的问题
-
指令设计问题:在将多模态大语言模型(MLLM)应用于行人重识别(ReID)任务时,需要对模型进行指令学习。然而,设计适用于ReID任务的多样化指令既复杂又昂贵,同时可能会导致模型过拟合于特定指令,降低对未见样本的泛化能力。
-
视觉编码器与ReID任务的同步训练问题:在微调MLLM的视觉编码器时,视觉编码器与ReID任务并不是同步训练的。这种方式可能导致在ReID任务中无法直接反映视觉编码器的优化效果,从而降低了特征提取的效率和性能。
解决方法
为了应对上述问题,论文提出了两项主要的解决方案:
- 通用指令(Common Instruction)设计:为了解决指令设计问题,作者提出了一种简单的通用指令方法,利用了**大语言模型(LLM)自然生成连续文本的本质能力。**这样可以避免设计复杂和多样化的指令所带来的高昂成本,同时保持模型的多样性和泛化能力。具体来说,使用简单的文本延续指令,使得图像和文本都能生成相同的延续文本,从而解决指令设计的复杂性问题。
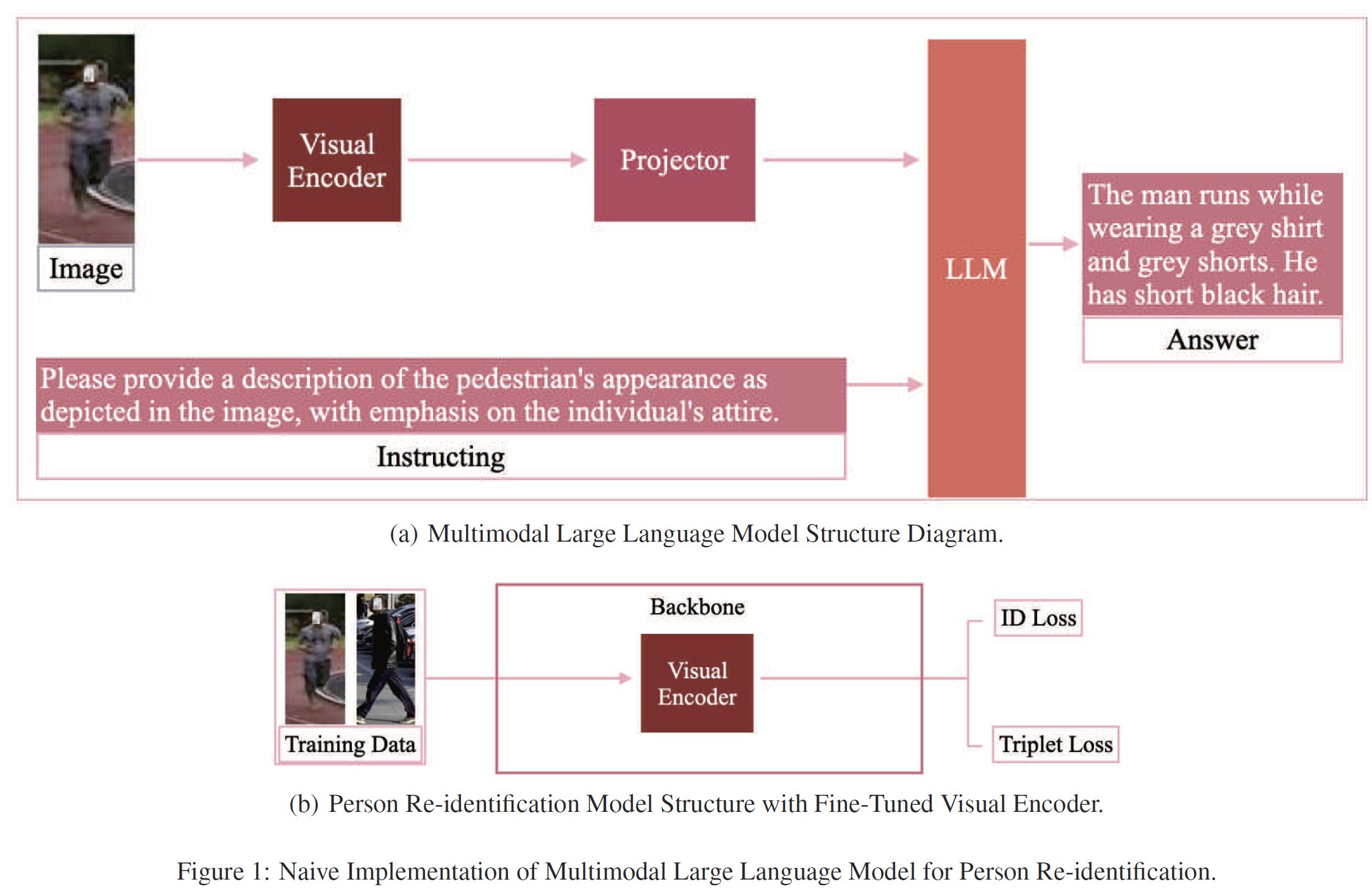
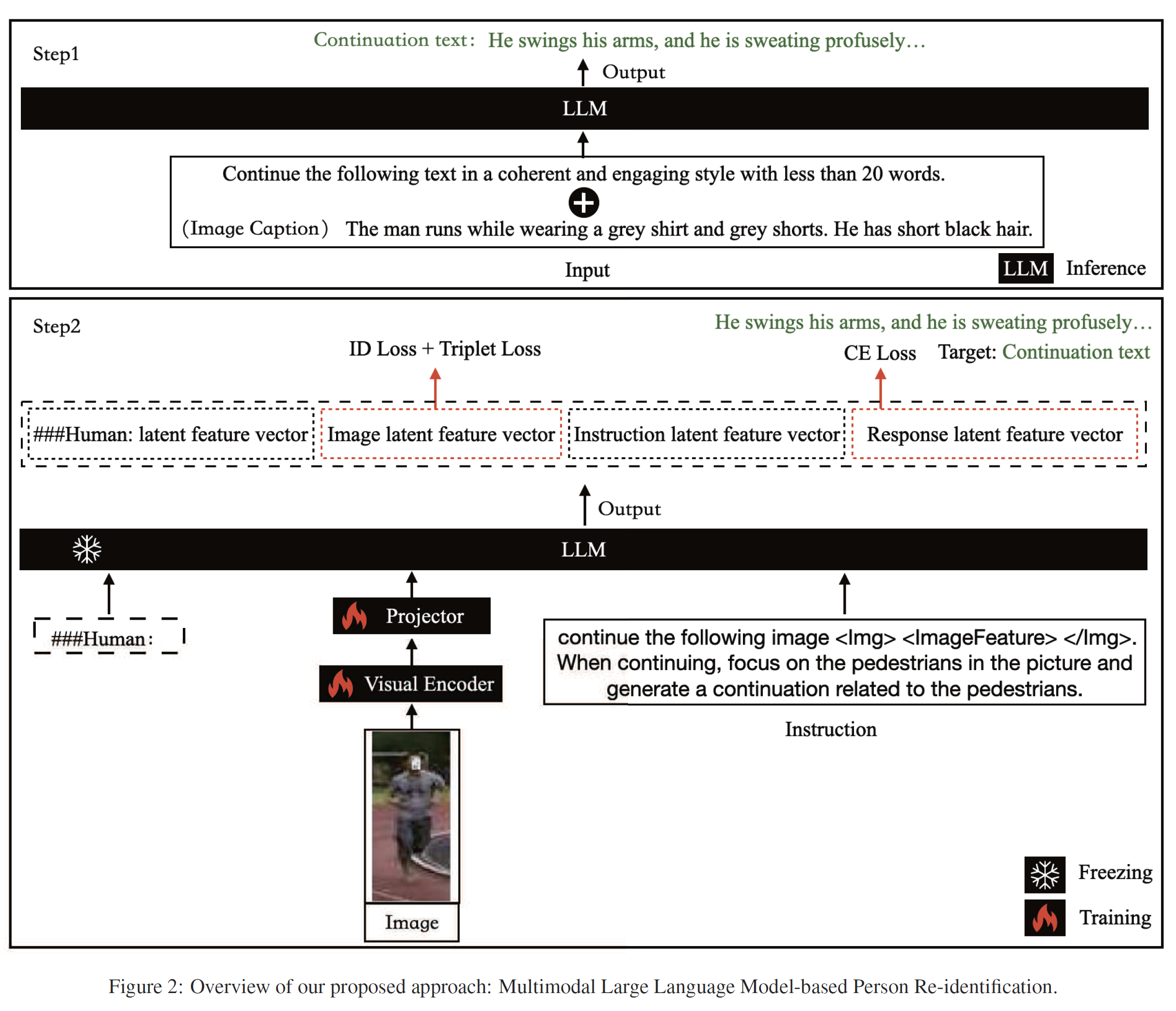
视觉模型:采用CLIP预训练的视觉编码器(ViT-L/14)来处理图像输入,并提取视觉特征(fv)。
特征映射与投影矩阵:为了在图像特征和语言嵌入空间之间架起桥梁,模型使用了一个简单的线性层(投影矩阵)。投影矩阵将视觉特征(fv)转换为语言嵌入标记,以匹配语言模型中的单词嵌入空间的维度。
这种架构确保了图像和文本输入能够产生一致的输出,从而优化视觉特征的提取和利用。
- 基于多任务学习的同步模块(SyncReID):为了解决视觉编码器和ReID任务不同步训练的问题,论文提出了一个基于多任务学习的同步训练模块。该模块确保MLLM的视觉编码器与ReID任务同步训练,通过直接使用ReID任务生成的损失来优化视觉编码器。这种方法提高了视觉编码器对行人特征的理解和提取能力,从而增强了模型在ReID任务中的表现。
SyncReID模块直接将大语言模型(LLM)输出的潜在图像特征向量(latent image feature vectors)应用于ReID任务,体现在损失上。
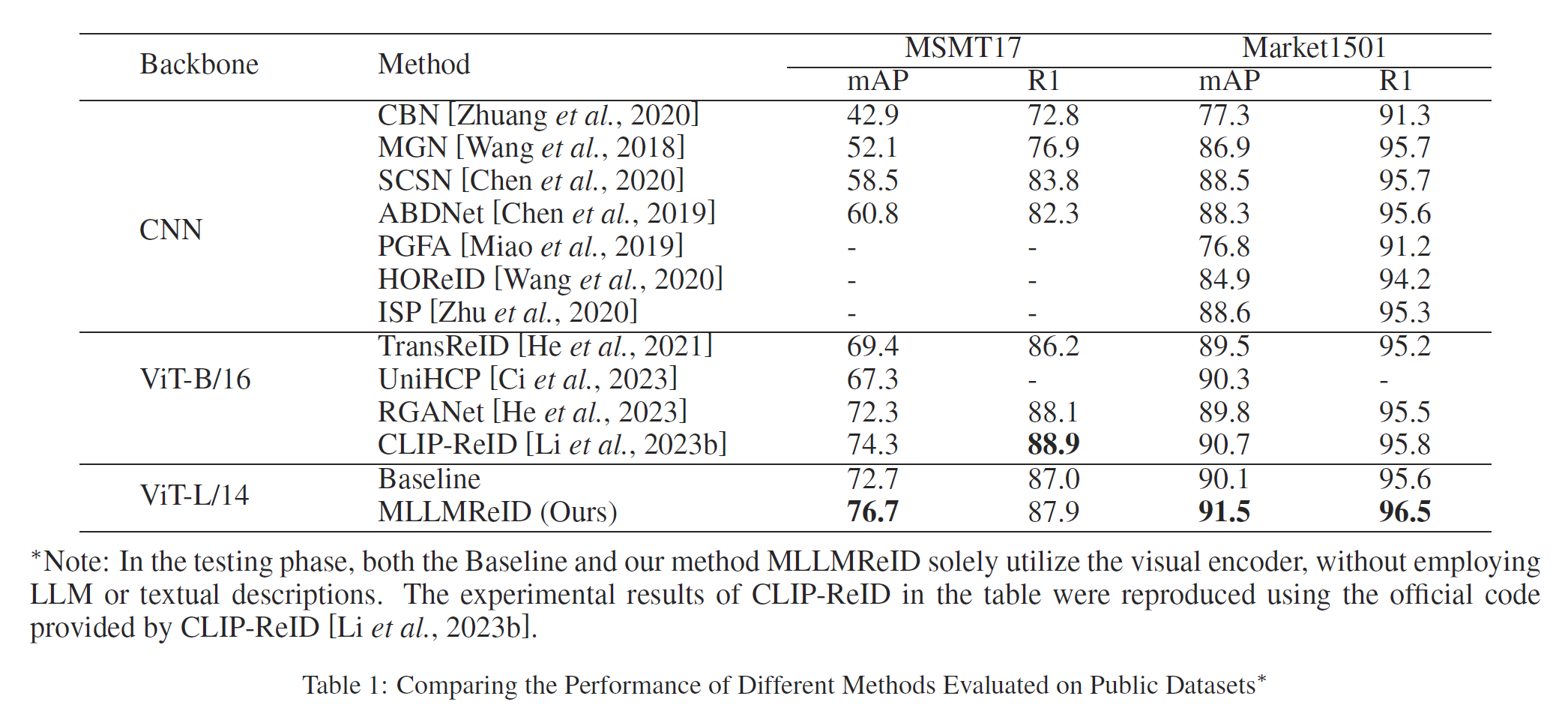
实验结果




搜索、倒排索引)