我自己的原文哦~ https://blog.51cto.com/whaosoft/12419881
#Batch Normalization
本文聚焦于Batch Normalization,Layer Normalization两个标准化方法,对其原理和优势等进行了详细的阐述。
这一篇写Transformer里标准化的方法。在Transformer中,数据过Attention层和FFN层后,都会经过一个Add & Norm处理。其中,Add为residule block(残差模块),数据在这里进行residule connection(残差连接)。而Norm即为Normalization(标准化)模块。Transformer中采用的是Layer Normalization(层标准化)方式。常用的标准化方法有Batch Normalization,Layer Normalization,Group Normalization,Instance Normalization等
Batch Normalization
本节1.2-1.3的部分,在借鉴天雨粟:Batch Normalization原理与实战解说的基础上,增加了自己对论文和实操的解读,并附上图解。上面这篇文章写得非常清晰,推荐给大家阅读~
提出背景
Batch Normalization(以下简称BN)的方法最早由Ioffe&Szegedy在2015年提出,主要用于解决在深度学习中产生的ICS(Internal Covariate Shift)的问题。若模型输入层数据分布发生变化,则模型在这波变化数据上的表现将有所波动,输入层分布的变化称为Covariate Shift,解决它的办法就是常说的Domain Adaptation。同理,在深度学习中,第L+1层的输入,也可能随着第L层参数的变动,而引起分布的变动。这样每一层在训练时,都要去适应这样的分布变化,使得训练变得困难。这种层间输入分布变动的情况,就是Internal Covariate Shift。而BN提出的初衷就是为了解决这一问题。

ICS所带来的问题
(1)在过激活层的时候,容易陷入激活层的梯度饱和区,降低模型收敛速度。
这一现象发生在我们对模型使用饱和激活函数(saturated activation function),例如sigmoid,tanh时。如下图:

可以发现当绝对值越大时,数据落入图中两端的梯度饱和区(saturated regime),造成梯度消失,进而降低模型收敛速度。当数据分布变动非常大时,这样的情况是经常发生的。当然,解决这一问题的办法可以采用非饱和的激活函数,例如ReLu。(2)需要采用更低的学习速率,这样同样也降低了模型收敛速度。
如前所说,由于输入变动大,上层网络需要不断调整去适应下层网络,因此这个时候的学习速率不宜设得过大,因为梯度下降的每一步都不是“确信”的。
1.1.2 解决ICS的常规方法
综合前面,在BN提出之前,有几种用于解决ICS的常规办法:
采用非饱和激活函数
更小的学习速率
更细致的参数初始化办法
数据白化(whitening)
其中,最后一种办法是在模型的每一层输入上,采用一种线性变化方式(例如PCA),以达到如下效果:
使得输入的特征具有相同的均值和方差。例如采用PCA,就让所有特征的分布均值为0,方差为1
去除特征之间的相关性。
然而在每一层使用白化,给模型增加了运算量。而小心地调整学习速率或其他参数,又陷入到了超参调整策略的复杂中。因此,BN作为一种更优雅的解决办法被提出了。
1.2 BN的实践
1.2.1 思路

上图所示的是2D数据下的BN,而在NLP或图像任务中,我们通常遇到3D或4D的数据,例如:
图像中的数据维度:(N, C, H, W)。其中N表示数据量(图数),C表示channel数,H表示高度,W表示宽度。
NLP中的数据为度:(B, S, E)。其中B表示批量大小,S表示序列长度,F表示序列里每个token的embedding向量维度。

训练过程中的BN
配合上面的图例,我们来具体写一下训练中BN的计算方式。

测试过程中的BN


采用这种方法的好处是:
节省了存储空间,不需要保存所有的均值和方差结果,只需要保存running mean和running variance即可
方便在训练模型的阶段追踪模型的表现。一般来讲,在模型训练的中途,我们会塞入validation dataset,对模型训练的效果进行追踪。采用移动平均法,不需要等模型训练过程结束再去做无偏估计,我们直接用running mean和running variance就可以在validation上评估模型。
1.3 BN的优势总结
通过解决ICS的问题,使得每一层神经网络的输入分布稳定,在这个基础上可以使用较大的学习率,加速了模型的训练速度
起到一定的正则作用,进而减少了dropout的使用。当我们通过BN规整数据的分布以后,就可以尽量避免一些极端值造成的overfitting的问题
使得数据不落入饱和性激活函数(如sigmoid,tanh等)饱和区间,避免梯度消失的问题
1.4 大反转:著名深度学习方法BN成功的秘密竟不在ICS?
以解决ICS为目的而提出的BN,在各个比较实验中都取得了更优的结果。但是来自MIT的Santurkar et al. 2019却指出:
就算发生了ICS问题,模型的表现也没有更差
BN对解决ICS问题的能力是有限的
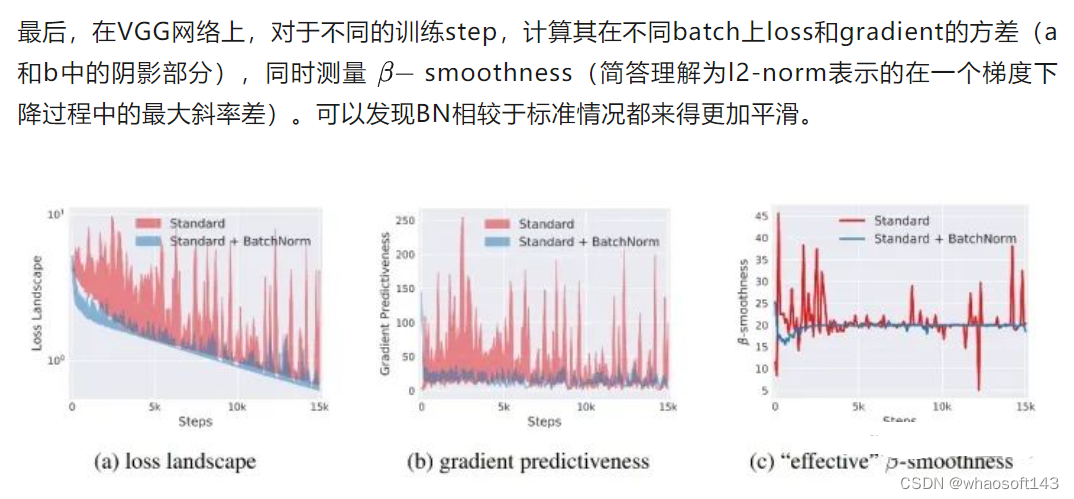
BN奏效的根本原因在于它让optimization landscape更平滑
而在这之后的很多论文里也都对这一点进行了不同理论和实验的论证。 (每篇论文的Intro部分开头总有一句话类似于:“BN的奏效至今还是个玄学”。。。)
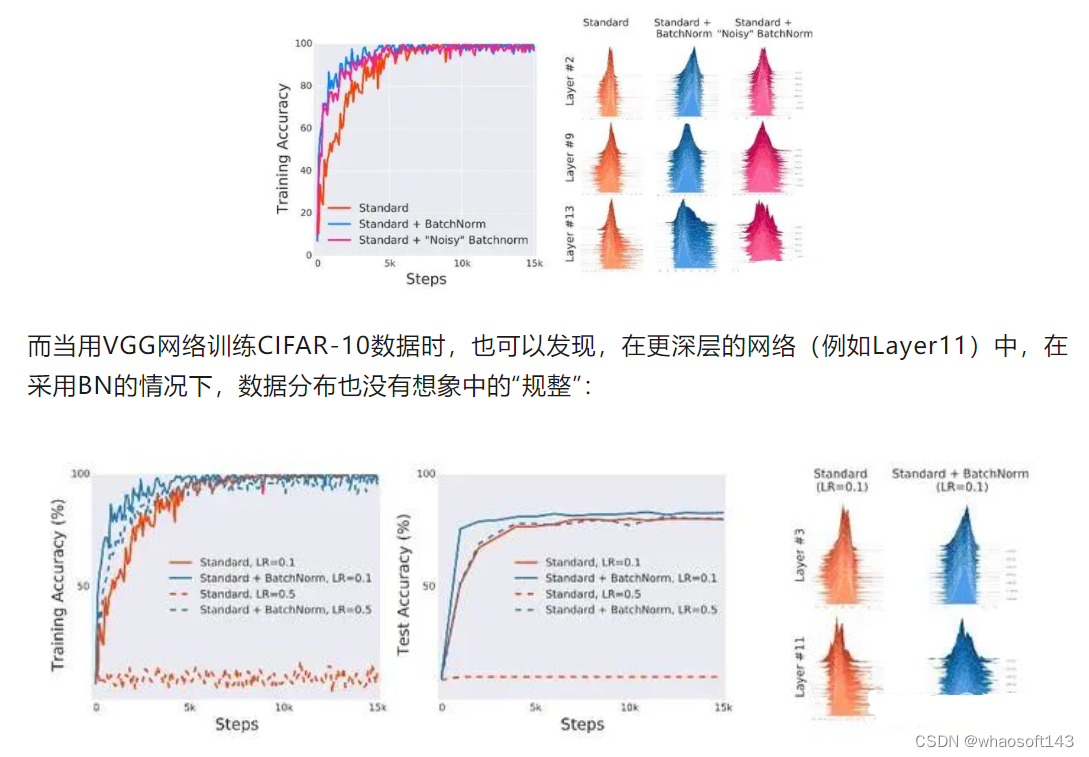
图中是VGG网络在标准,BN,noisy-BN下的实验结果。其中noisy-BN表示对神经网络的每一层输入,都随机添加来自分布(non-zero mean, non-unit variance)的噪音数据,并且在不同的timestep上,这个分布的mean和variance都在改变。noisy-BN保证了在神经网络的每一层下,输入分布都有严重的ICS问题。但是从试验结果来看,noisy-BN的准确率比标准下的准确率还要更高一些,这说明ICS问题并不是模型效果差的一个绝对原因。
Layer Normalization
这是一个结合实验的解释,而引起这个现象的原因,可能不止是“长短不一”这一个,也可能和数据本身在某一维度分布上的差异性有关。目前相关知识水平有限,只能理解到这里,未来如果有更确切的想法,会在这里补充。
2.2 思路
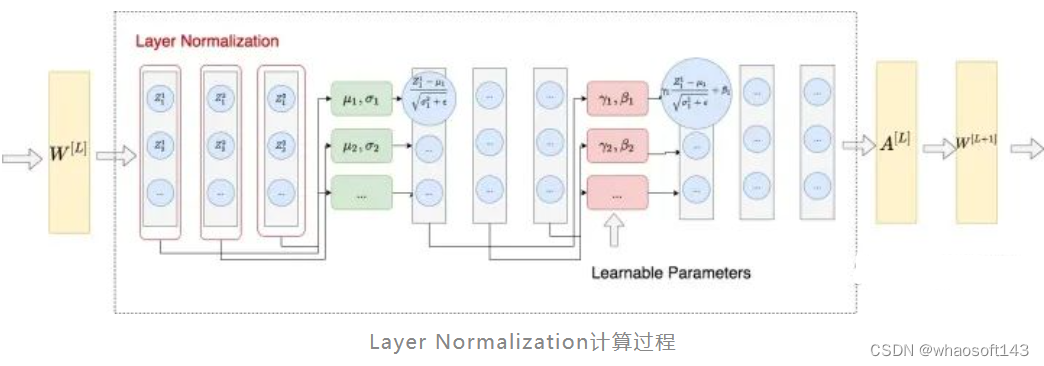
整体做法类似于BN,不同的是LN不是在特征间进行标准化操作(横向操作),而是在整条数据间进行标准化操作(纵向操作)
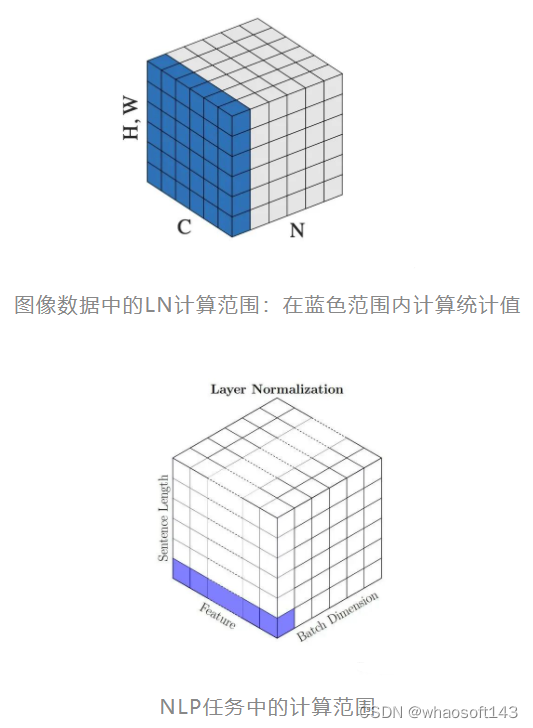
在图像问题中,LN是指对一整张图片进行标准化处理,即在一张图片所有channel的pixel范围内计算均值和方差。而在NLP的问题中,LN是指在一个句子的一个token的范围内进行标准化。
训练过程和测试过程中的LN

Transformer LN改进方法:Pre-LN
原始transformer中,采用的是Post-LN,即LN在residule block(图中addtion)之后。Xiong et al. (2020)中提出了一种更优Pre-LN的架构,即LN在residule block之前,它能和Post-LN达到相同甚至更好的训练结果,同时规避了在训练Post-LN中产生的种种问题。两种架构的具体形式可以见下图。
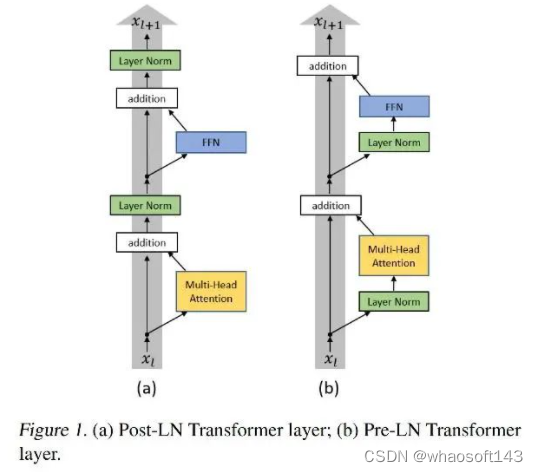
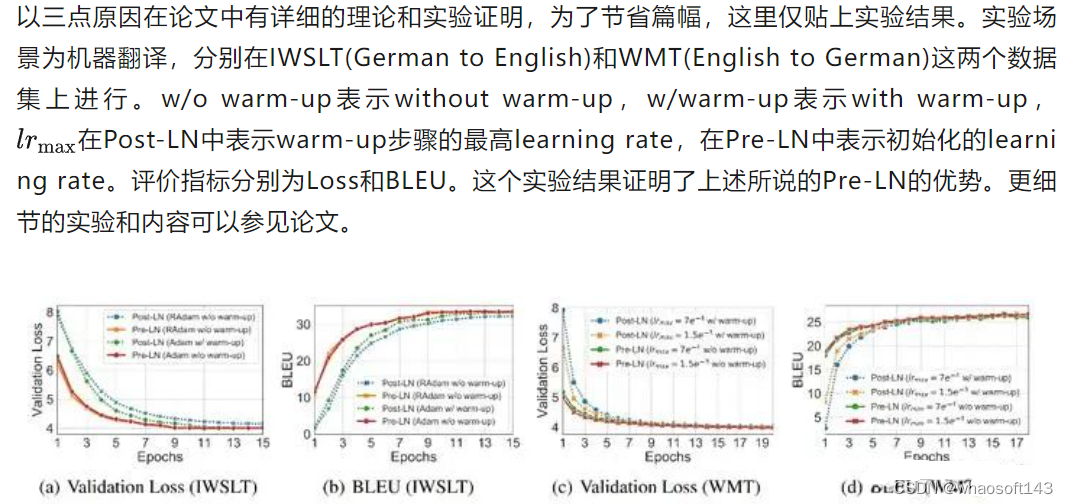
这篇论文通过理论分析和实验的方式,证明了Pre-LN相比的Post-LN的优势,主要表现在:
在learning rate schedular上,Pre-LN不需要采用warm-up策略,而Post-LN必须要使用warm-up策略才可以在数据集上取得较好的Loss和BLEU结果。
在收敛速度上,由于Pre-LN不采用warm-up,其一开始的learning rate较Post-LN更高,因此它的收敛速度更快。


总结看来,Pre-LN带来的好处,基本都是因为不需要做warm-up引起的。而引起这一差异的根本原因是:
- Post-LN在输出层的gradient norm较大,且越往下层走,gradient norm呈现下降趋势。这种情况下,在训练初期若采用一个较大的学习率,容易引起模型的震荡。
- Pre-LN在输出层的gradient norm较小,且其不随层数递增或递减而变动,保持稳定。
- 无论使用何种Optimzer,不采用warm-up的Post-LN的效果都不如采用warm-up的情况,也不如Pre-LN。
#Detection Transformer
都到33了 这是 Detection Transformer 数据高效的Transformer目标检测器
Detection Transformer于2020年ECCV被提出,作为一种新兴的目标检测方法,Detection Transformers以其简洁而优雅的框架取得了越来越多的关注。本工作由京东探索研究院和中科大联合完成。
对目标检测模型所需要的数据进行标注往往是十分繁重的工作,因为它要求对图像中可能存在的多个物体的位置和类别进行标注。本文旨在减少Detection Transformer类目标检测器对标注数据的依赖程度,提升其数据效率。

图1:不同目标检测模型在数据量充足的COCO和小数据集Cityscapes上的性能对比,模型名称下方的数字表示训练周期数。
目前的研究似乎表明Detection Transformers能够在性能、简洁性和通用性等方面全面超越基于CNN的目标检测器。但我们研究发现,只有在COCO这样训练数据丰富(约118k训练图像)的数据集上Detection Transformers能够表现出性能上的优越,而当训练数据量较小时,大多数Detection Transformers的性能下降显著。如图1所示,在常用的自动驾驶数据集Cityscapes[8](约3k训练图像)上,尽管Faster RCNN能够稳定的取得优良的性能,大多数Detection Transformers的性能显著下降。并且尽管不同Detection Transformers在COCO数据集上性能差异不到2AP,它们在小数据集Cityscapes上的性能有大于15AP的显著差异。
这些发现表明Detection Transformers相比于基于CNN的目标检测器更加依赖标注数据(data hungry)。然而标注数据的获得并非易事,尤其是对于目标检测任务而言,不仅需要标出多个物体的类别标签,还需要准备的标出物体的定位框。同时,训练数据量大,意味着训练迭代次数多,因此训练Detection Transformers需要消耗更多的算力,增加了碳排放。可见,要满足现有Detection Transformers的训练要求需要耗费大量的人力物力。
消融探究
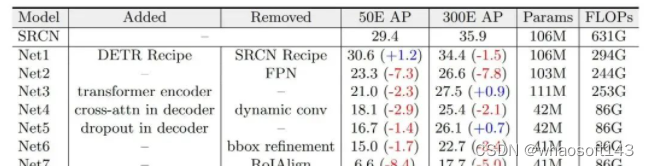
表1:从SparseRCNN(表中缩写为SRCN)到DETR的模型转化
为了寻找影响Data-efficiency的关键因素,我们将data efficient的RCNN逐步转化为data hungry的Detection Transformer检测器,来消融不同设计的影响。值得一提的是,ATSS[9]和Visformer[10]采用了类似的模型转化实验,但ATSS旨在寻找anchor free检测器和anchor-based检测器之间的本质区别,Visformer旨在寻找对分类任务有利的transformer backbone结构,而我们致力于寻找影响Detection Transformers数据效率的主要因素。
为了从模型转化中获得insightful的结果,我们需要选择合适检测器展开实验。综合一下因素,我们选择Sparse RCNN和DETR来展开实验:(1)它们分别是RCNN和Detection Transformer中有代表性的检测器;(2)二者有很多相似的地方,比如相同的优化器、标签匹配、损失设计、数据增强和端到端等,这有利于我们尽可能排除其他影响因素的干扰,专注于核心的区别;(3)二者在data efficiency上存在显著差异。模型转化过程如表1所示,接下来,我们挑选模型转化中的关键步骤进行介绍:
去除FPN。由于CNNs具有局部性,FPN中能够以较小的计算代价实现多尺度特征融合,从而在少量数据的情况下提升目标检测的性能。对比之下,DETR中的attention机制具有全局感受野,导致其在高分辨率的特征图上需要消耗大量的运算资源,因此在DETR上做多尺度特征的建模往往是难以实现的。在本步中,我们去除RCNN中的FPN,并且与DETR一致,我们仅将backbone中32倍下采样的特征送入检测头做RoI Align和后续解码和预测。和预期的一样,去除FPN的多尺度建模作用,在50代的训练周期下模型性能下降显著by 7.3 AP。
加入Transformer编码器。在DETR中,transformer编码器可以看作是检测器中的neck,用来对backbone提取的特征做增强。在去除FPN neck后,我们将DETR的编码器加入模型得到表1中的Net3。有趣的是,Net3在50个训练周期下的性能下降,而在300个训练周期下性能有所提升。我们猜想像ViT[11]一样,解码器中的attention具有平方复杂度,因此需要更长的训练周期来收敛并体现其优势。
将动态卷积替换为自注意力机制。SparseRCNN中一个非常有趣的设计是解码器中的动态卷积,它的作用和DETR中的cross-attention作用十分相似,即根据图像特征和特定object candidate的相似性,自适应地将图像中的信息聚合到object candidate中。在本步骤中,我们将动态替换为cross-attention,对应的结果如表中Net4所示。反直觉的,参数量大并不一定会使模型更依赖数据。事实上,含有大量参数的动态卷积能够比参数量很小的cross-attention表现出了更好的数据效率。
去除RoIAlign。SparseRCNN和RCNNs family中的其他检测器一样根据目标检测的候选框对图像中指定区域的特征做采样,再基于采样后的特征做预测。对比之下,DETR中content query直接从图像的全局特征中聚合特定物体的信息。在本步骤,我们去除RoI Align操作。可以看到,模型的性能发生了显著下降。我们猜想从全局特征中学习如何关注到包含特定物体的局部区域是non-trivial的,因此模型需要从更多的数据和训练周期中学习到locality的特性。而在见过的数据量小的情况下性能会显著下降。
去除初始的proposal。最后,DETR直接预测normalized检测框中心坐标和宽度和高度,而RCNNs预测gt检测框相较于初始proposal检测框的offsets。在本步骤中,我们消除此差异。这一微小的区别使得模型性能显著下降,我们猜想这是因为初始的proposal能够作为一种空间位置上的先验,帮助模型关注特定的物体区域,从而降低了从大量数据中学习关注局部区域的需要。
总结:综上,可以看出以下因素对模型的data efficiency其关键作用:(1)从局部区域的稀疏特征采样,例如采用RoIAlign;(2)多尺度特征融合,而这依赖于稀疏特征采样使得其运算量变得可接受;(3)相较于初始的空间位置先验作预测。其中(1)和(3)有利于模型关注到特定的物体区域,缓解从大量数据中学习locality的困难。(2)有利于充分利用和增强图像的特征,但其也依赖于稀疏特征。
值得一提的是,在DETR family中,Deformable DETR[4]是一个特例,它具有较好的数据效率。而我们基于Sparse RCNN和DETR的模型转化实验得到的结论同样也能够说明为什么Deformable DETR的具有较好的数据集效率:Multi-scale Deformable Attention从图像局部区域内做特征的稀疏采样,并运用了多尺度特征,同时模型的预测是相对于初始的reference point的。
模型增强
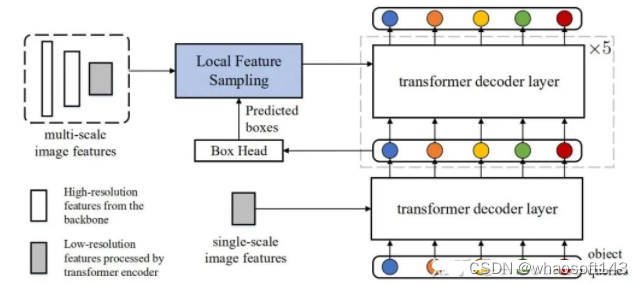
图2:我们的数据高效Detection Transformer模型结构。我们力求在尽可能少改动原模型的情况下,提升其数据效率。模型的backbone、transformer编码器和第一个解码器层均未变化
局部特征采样。从模型转化中的分析中可以看出,从局部物体区域做特征采样对实现数据效率是至关重要的。幸运的是,在Detection Transformer中,由于Deep Supervision[12]的存在,每一层解码器层中都为我们提供了物体检测框的信息。因此,我们可以在不引入新的参数的情况下,借助这些物体定位框来做局部特征采样。尽管可以采用更成熟的特征采用方法,我们采用最常用的RoI Align。从第二层解码器层开始,我们借助前一层解码器的输出来做稀疏特征采样。
迭代式预测和初始参考点。此外,Detection Transformer中级联的结构很自然地适合使用迭代式的检测框refinement来提升检测的性能。我们在模型转换中的实验也表明,迭代式的预测以及相对于初始的空间参考做预测有利于实现更准确的目标检测。为此,我们引入检测框的迭代式refinement和初始参考点。
多尺度特征融合。多尺度特征的运用有利于特征的高效利用,能够在数据量小的情况下提升检测性能。而我们的稀疏特征采样也使得在Detection Transformer中使用多尺度特征成为可能。尽管更成熟的多尺度融合技术可能被使用,我们仅仅利用bbox作为指导,对不同尺度的特征做RoIAlign,并将得到的序列concatenate在一起。
标签增强

图3:(a)现有Detection Transformer的标签分配方式;(b)使用标签增强后的标签分配。圆圈和矩形框分别表示模型的预测和图片上的物体标注。通过复制橙色方框表示的物体标注,蓝色圆圈表示的模型预测也在标签分配中匹配到了正样本,因此得到了更丰富的监督信号。
尽管一对一的标签匹配形式简单,并能够避免去重过程,但也使得在每次迭代中,只有少量的检测候选能够得到有效的监督。模型不得不从更大量的数据或者更多的训练周期中获得足够的监督信号。为了解决这一问题,我们提出一种标签增强策略,通过在二分图匹配过程中重复正样本,来为Detection Transformer提供更丰富的监督信号,如图3所示。
在实现过程中,我们考虑两种不同的方式来复制正样本的标签,即(1)固定重复次数(Fixed Repeat Time):我们对所有正样本标签重复相同的次数;(2)固定正负样本标签的比例(Fixed positive-negative ratio):我们对正样本的标签进行重复采样,最终保证标签集合中正样本的比例固定。默认的,我们采用固定重复两次的标签增强方式。
实验

表2:不同方法在小数据集Cityscapes上的性能比较
在本部分,我们首先将我们的方法和现有的Detection Transformer进行比较。如表2所示,大部分Detection Transformer面临数据效率低下的问题。而我们的DE-CondDETR在对CondDETR模型做微小改动的情况下能够取得和Deformable DETR相当的数据效率。而辅助以标签增强提供的更丰富的监督,我们的DELA-CondDETR能够取得比Deformable DETR更佳的性能。同样的,我们的方法也能够与其他Detection Transformer结合来显著提升其data efficiency,例如我们的DE-DETR和DElA-DETR能够在以仅仅50周期取得比DETR 500个周期要显著优越的性能。

图4:不同方法在下采样的COCO数据集上的性能比较。横轴表示数据下采样的比例(对数scale)。
此外我们对COCO 2017中的训练数据进行训练图像0.1,0.05,0.02和0.01倍的采样,来观察模型在不同数据量下的性能。如图4所示,在不同的训练数据量下,我们的方法始终能够取得显著优于基线方法的性能。特别的,仅用0.01倍的数据DELA-DETR的性能显著优于使用五倍数据的DETR基线。类似的,DELA-CondDETR性能始终优于用两倍数据训练的CondDETR基线。
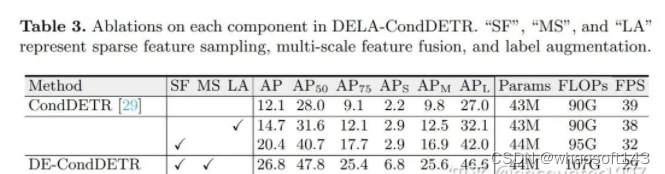
表3:对模型中不同组件的消融实验
我们首先消融我们方法中各个模块的作用,如表3所示。使用局部特征采样和多尺度特征均能够显著提升模型的性能,分别带来8.3 AP和6.4 AP的提升。此外,使用标签增强能够进一步带来2.7 AP的性能提升。并且单独使用标签增强也能够带来2.6的性能提升。

对标签增强的消融研究
如方法部分中讨论的,我们考虑了两种标签增强策略。包括固定重复次数和固定正负样本比例。在本部分,我们对这两种策略进行消融。如上表中左表所示,使用不同的固定重复倍数均能够提升DE-DETR的性能,但随重复次数增加,性能提升呈下降趋势。我们默认采用重复正样本标签2次。此外,如右表所示,尽管使用不同正负样本比例均能带来性能提升,在正负样本比例为1:3时,其取得的性能最佳,有趣的是,这也是RCNN系列检测器如Faster RCNN中最常用正负样本采样比例。
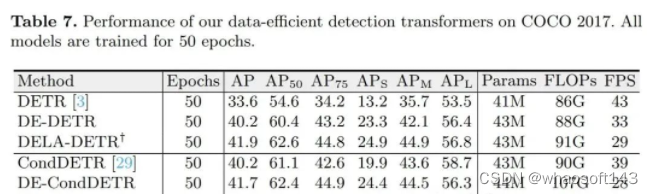
在训练数据充足的COCO 2017上的性能比较,所有模型都训练50个周期
尽管以上实验说明了我们的方法能够在数据量有限的情况下显著提升模型性能,它并不能表明我们的方法在数据量充足时依然有效。为此,我们在数据量充足的COCO2017上测试我们方法的性能。有趣的是,我们的方法不仅不会降低模型在COCO 2017上的性能,还能带来不小的提升。具体来说,DELA-DETR和DELA-CondDETR分别相较于它们的baseline提升8.1AP和2.8AP。

图5:不同模型在Cityscapes数据集上的收敛曲线,横轴表示训练周期数,纵轴表示mAP
最后,为了对本文方法带来的性能提升有一个直观的感受,我们提供了不同DETR变种在Cityscapes数据集上的收敛曲线,如图5所示。可以看出,我们的方法能够以更少的训练代价取得更加优越的性能,展示了其优越的数据效率。更多实验结果请参考原文及其附加材料。
总结
在本文中,我们指出了Detection Transformer数据效率低下的问题,并通过逐步的模型转化找了影响数据效率的关键因素。随后,我们以尽可能小的模型改动来大幅提升现有Detection Transformer的数据效率,并提出一种标签增强策略进一步提升其性能。随着Transformer在视觉任务中越发流行,我们希望我们的工作能够激发社区探究和提升Transformer在不同任务上的数据效率。
arxiv.org/abs/2203.09507
【代码链接】
https://github.com/encounter1997/DE-DETRs
https://github.com/encounter1997/DE-CondDETR
参考文献
End-to-end Object Detection with Transformers
Microsoft COCO: Common Objects in Context
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Conditional DETR for Fast Training Convergence
PnP-DETR: Towards Efficient Visual Analysis with Transformers
#Vision transformer总结
这里总结一下Vision transformer (主要包含图像分类/目标检测/语义分割等任务)
https://github.com/dk-liang/Awesome-Visual-Transformer
https://github.com/IDEACVR/awesome-detection-transformer
Image Classification
Uniform-scale
*ViT
paper:https://arxiv.org/abs/2010.11929
code:https://github.com/google-research/vision_transformer
最简洁的Vision Transformer模型,先将图片分成16x16的patch块,送入transformer encoder,第一个cls token的输出送入mlp head得到预测结果。
*DeiT
paper:https://arxiv.org/abs/2012.12877
code:https://github.com/facebookresearch/deit)
在ViT的基础上增加了一个distillation token,巧妙的利用distillation token提升模型精度。
T2T-ViT
paper:https://arxiv.org/abs/2101.11986
code:https://github.com/yitu-opensource/T2T-ViT
将ViT的patch stem改成重叠的滑窗形式,增强patch之间的信息交流。
Conformer
paper:https://arxiv.org/abs/2105.03889
code:https://github.com/pengzhiliang/Conformer
设计了一个CNN和Transformer双分支结构,利用FCU模块进行两个分支的信息交流,推理的时候使用两个分支的输出取平均进行预测。
TNT
paper:https://arxiv.org/abs/2103.00112
code:https://github.com/huawei-noah/noah-research/tree/master/TNT
在ViT的基础上,对每个patch进一步切分,用嵌套的方式提升每个patch对于局部区域的特征表达能力,然后将局部提升后的特征和patch特征相加送入下一个transformer block中。
XCiT
paper:https://arxiv.org/pdf/2106.09681.pdf
code:https://github.com/facebookresearch/xcit
XCiT通过置换q和k的计算,从tokens做self-attention转变成channels纬度做self-attention(也就是通道的协方差计算),复杂度从平方降到了线性。
DeepViT
paper:https://arxiv.org/abs/2103.11886
DeepViT发现随着深度的增加,ViT的self-attention会出现坍塌现象,DeepViT提出用Re-Attention来替代Self-Attention可以避免坍塌,可以训练更深的ViT,Re-Attention在MHSA之后增加了一个可学习的Matrix Transformation。
*Token Labeling ViT
paper:https://arxiv.org/abs/2104.10858
code:https://github.com/zihangJiang/TokenLabeling
为了增加ViT对于局部区域的定位和特征提取能力,token labeling在每个patch的输出都增加一个局部监督,token label通过一个预训练过的特征提取器获得(本文可以看成是AutoEncoder+CLS的预训练方法)。由于需要一个额外的特征提取器,所以需要更多的计算资源(可以用MaskFeat的方法改进)。
SoT
paper:https://arxiv.org/abs/2104.10935
code:https://github.com/jiangtaoxie/So-ViT
对patch输出的word token进行协方差池化,然后和cls token的输出进行融合,提高分类对局部区域的感知能力。
DVT
paper:https://arxiv.org/abs/2105.15075
DVT提出每个图片应该有自己独有的token数量,于是设计了一个级联tokens数量逐渐增加的多个transformer,推理的时候可以从不同级的transformer判断输出。
DynamicViT
paper:https://arxiv.org/abs/2106.02034
code:https://dynamicvit.ivg-research.xyz/
通过一个预测模块来决定token的重要程度,剪枝掉少量不重要的token,将剩余的token送入下一个block中。
PSViT
paper:https://arxiv.org/abs/2108.03428
为了减少ViT计算上的冗余,PSViT提出token pooling和attention sharing两个操作,其中token pooling用来减少token的数量,attention sharing作用在相关性较强的相邻层上。
*TokenLearner
paper:https://arxiv.org/abs/2106.11297
code:https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
利用spatial attention来提取出最重要的token信息,减少token数量。
Evo-ViT
paper:https://arxiv.org/abs/2108.01390
增加一个representative token,通过global class attention evolution来判断patch token的重要程度,重要程度高的送入block中缓慢更新,重要程度低的和representative token(由placeholder token得到)残差更新。其中vanilla transformer block的MSA输出和global cls attention相加得到重要性权重。
AugViT
paper:https://arxiv.org/abs/2106.15941
code:https://github.com/huawei-noah/CV-Backbones/tree/master/augvit_pytorch
为了避免ViT出现模型坍塌现象,AugViT设计了一个augmented shortcuts结构。具体地,在MSA结构上并行增加两个分支,一个分支做shortcut操作,另一分支对每个patch做augmentation来增加特征表达的多样性,最后将三个分支的输出相加到一起。
CrossViT
paper:https://arxiv.org/abs/2103.14899
code:https://github.com/IBM/CrossViT
将两种不同数量的patch序列分别送入encoder中,然后通过cross-attention对两个分支的cls token和patch token同时进行融合,最后将两个分支的cls token位置的输出结果进行融合。
AutoFormer
paper:https://arxiv.org/pdf/2107.00651.pdf
code:https://github.com/microsoft/AutoML
AutoFormer动态的搜索transformer中每一层的embedding纬度、head的数量、MLP比例和QKV纬度。
*CPVT
paper:https://arxiv.org/abs/2102.10882
code:https://github.com/Meituan-AutoML/CPVT
CPVT设计了一个PEG结构来替代PE(positional encoding),PEG通过feature token生成得到。
V-MoE
paper:https://arxiv.org/pdf/2106.05974v1.pdf
V-MoE用Sparse MoE来替换ViT中的MLP结构。Sparse MoE中的每个MLP分别保存在独立的device上,并且处理相同固定数量的tokens。
DPT
paper:https://arxiv.org/abs/2107.14467
code:https://github.com/CASIA-IVA-Lab/DPT
DPT设计另一个可形变的patch选取方式。
*EViT
paper:https://arxiv.org/pdf/2202.07800.pdf
EViT通过计算每个patch token和cls token的相关性来决定重要程度,重要程度高的直接送入FFN,重要程度低的融合成一个token。
Multi-scale
*SwinTv1
paper:https://arxiv.org/abs/2103.14030
code:https://github.com/microsoft/Swin-Transformer
*SwinTv2
paper:https://arxiv.org/abs/2111.09883
为了更好的应用于det、seg等下游任务,需要对ViT进行多尺度设计。SwinT通过patch merging减少token的数量,另外设计了W-MSA结构,只对windows内的patch进行self-attention计算来降低计算量,为了增加不同windows之间的信息传递,设计了SW-MSA结构。
为了更好的扩大SwinT的模型容量和window的分辨率,SwinTv2重新设计了block结构。
用post-norm替代pre-norm
用cosine attention替代dot product attention
用log-spaced continuous relative position替代parameterized relative position
1和2使得SwinT更容易扩大模型容量,3使得SwinT更容易跨window分辨率迁移。
*PVTv1
paper:https://arxiv.org/abs/2102.12122
code:https://github.com/whai362/PVT
*PVTv2
paper:https://arxiv.org/pdf/2106.13797.pdf
PVT设计了一个多stage的多尺度架构,为了做stage之间的下采样,将MHSA改造成SRA,SRA中的K和V都下采样R^2倍。
PVTv2在PVTv1的基础上做了三点改进:
将SRA的下采样conv替换成average pooling
将不重叠的patch embedding替换成重叠的patch embedding
移除position encoding,并且在FFN中增加一个dwconv
1可以将PVT计算量降到线性,2可以获得更多局部连续的特征,3可以处理任意尺寸的图像。
*Twins
paper:https://arxiv.org/abs/2104.13840
code:https://github.com/Meituan-AutoML/Twins
Twins沿用PVT的整体架构,并且用CPVT中的PEG来替代PE,同时将transformer block堆叠设计成global attention和local attention交替使用的形式,并且为了减少计算量,global attention将重要信息总结成mxn个表示,同时每个表示和其他sub-windows进行信息交流。
CoaT
paper:https://arxiv.org/abs/2104.06399
code:https://github.com/mlpc-ucsd/CoaT
CoaT设计了一个co-scale机制,通过一系列串行和并行的block来预测结果,同时设计了一个Conv-Attention结构来替代MHSA,用一个dwconv来得到position encoding,另一个dwconv来得到relative position encoding。
CvT
paper:https://arxiv.org/abs/2103.15808
code:https://github.com/leoxiaobin/CvT
CvT去掉position encoding,用conv同时替换掉token embedding和MHSA中的QKV projection,通过conv来引入位置信息。
Shuffle Transformer
paper:https://arxiv.org/abs/2106.03650
code:https://github.com/mulinmeng/Shuffle-Transformer
通过shuffle和unshuffle操作,来增加token之间的信息交流。
Focal Transformer
paper:https://arxiv.org/abs/2107.00641
code:https://github.com/microsoft/Focal-Transformer
改变SwinT的划分windows的方式,每个query patch对应三种粒度的windows尺寸,如图所示。将W-MSA替换成Focal Self-Attention整体架构和SwinT保持一致。
CSWinT
paper:https://arxiv.org/abs/2107.00652
code:https://github.com/microsoft/CSWin-Transformer
改变SwinT的划分windows的方式,每个query patch通过两个并行分支做self-attention,并且kv从dynaic stripe window中取。
*MViT
paper:https://arxiv.org/abs/2104.11227
code:https://github.com/facebookresearch/SlowFast
MViT通过对XQKV池化进行下采样构建金字塔架构。
Hybrid ViTs with Convolutions
LeViT
paper:https://arxiv.org/abs/2104.01136
code:https://github.com/facebookresearch/LeViT
LeViT的patch embedding设计成4个conv3x3堆叠,同时下采样的self-attention对Q进行下采样。
localViT
paper:https://arxiv.org/abs/2104.05707
code:https://github.com/ofsoundof/LocalViT
FC和1x1conv等效,在FFN中增加一个3x3的DWConv就变成了图c,输入输出增加Img2Seq和Seq2Img的操作。
ResT
paper:https://arxiv.org/abs/2105.13677
code:https://github.com/wofmanaf/ResT
ResT在MHSA中增加DWConv降低KV的纬度,另一个conv用来增加不同head的信息交流。
NesT
paper:https://arxiv.org/abs/2105.12723
NesT通过最大池化对patch进行聚合。
CoAtNet
paper:https://arxiv.org/pdf/2106.04803.pdf
通过交替堆叠depthwise conv和self-attention来设计架构。
BoTNet
paper:https://arxiv.org/abs/2101.11605
模仿ResNet的bottleneck,将Transformer的block设计成bottleneck的形式,一个bottleneck由1x1conv、MHSA、1x1conv堆叠而成。
ConViT
paper:https://arxiv.org/abs/2103.10697
ConViT设计了一个GPSA,只对patch token进行操作,并且引入了位置信息。10个GPSA堆叠之后接2个SA。
MobileViT
paper:https://arxiv.org/abs/2110.02178
MobileViT通过堆叠MobileNetv2 block和MobileViT block构成。
CeiT
paper:https://arxiv.org/abs/2103.11816
CeiT设计了一个局部增强的LeFF结构,只对patch token部分做linear projection和depth-wise conv。
CMT
paper:https://arxiv.org/abs/2107.06263
CMT设计了一个CMT block,如图所示。
Object Detection
CNN backbone
*DETR
paper:https://arxiv.org/abs/2005.12872
code:https://github.com/facebookresearch/detr
DETR是第一个使用Transformer做目标检测的算法。图片先通过CNN提取特征,然后和positional encoding相加送入transformer,最后通过FFN预测结果。其中decoder部分需要设置object queries,并行输出预测结果,训练的时候pred和target通过双边匹配算法进行匹配。
*UP-DETR
paper:https://arxiv.org/abs/2011.09094
为了对DETR进行预训练,UP-DETR处理了两个关键问题:
为了进行分类和定位对多任务训练,UP-DETR固定住预训练过的backbone和对patch特征进行重建来保留transformer的判别力。
为了对多个patch进行定位,不同queries设置不同的区域和大小。UP-DETR设计了两种预训练方式,一种是single-query,另一种是multi-query。对于multi-query设计了object query shuffle和attention mask操作来解决query patches和object queries对齐问题。
DETReg
paper:https://arxiv.org/abs/2106.04550
code:https://amirbar.net/detreg
上图是DETReg的整体框架。给定一张图片x,使用DETR得到embeddings v,总共设计了三个分支,一个分支预测box,一个分支预测embdding,还有一个分支预测目标分数cat。伪gt区域提议label通过selective search得到,伪gt目标embedding通过自监督算法SwAV得到,proposal的目标分数都设置为1。通过双边匹配将预测proposal和伪label进行匹配,不匹配的预测proposal分数用0填充。
SMCA
paper:https://arxiv.org/abs/2101.07448
code:https://github.com/abc403/SMCA-replication
SMCA设计了一个Spatially Modulated Co-Attention组件来加快DETR的收敛速度,具体地,decoder的每个query先做一个spatial prior,然后和key进行co-attention。另外SMCA还设计来一个Multi-Scale Self-Attention来进一步提升精度。
*Deformable DETR
paper:https://arxiv.org/abs/2010.04159
code:https://github.com/fundamentalvision/Deformable-DETR
Deformable DETR结合了deformable conv的稀疏空间采样和transformer的相关性建模能力的优点。提出的deformable attention module用一些采样位置作为重要的key元素,并且Deformable DETR将该谋爱拓展到multi-scale上。
Anchor DETR
paper:https://arxiv.org/abs/2109.07107
code:https://github.com/megvii-model/AnchorDETR
Anchor DETR在decoder部分设计了基于anchor points的object queries,并且row-column decoupled attention来替代MHSA,降低计算复杂度。
*Conditional DETR
paper:https://arxiv.org/abs/2108.06152
code:https://github.com/Atten4Vis/ConditionalDETR
Conditional DETR将content queries和spatial queries独立开,使得各自关注于content attention weights和spatial attention weights,加快训练的收敛速度。
*TSP-FCOS
paper:https://arxiv.org/abs/2011.10881
本文实验观察发现,影响DETR收敛速度的主要原因是cross-attention和双边匹配的不稳定。于是本文提出只使用transformer的encoder,其中TSP-FCOS设计了一种FoI Select来选择特征。并且还设计来一种新的双边匹配算法来加快收敛。
PnP-DETR
paper:https://arxiv.org/abs/2109.07036
code:https://github.com/twangnh/pnp-detr
PnP-DETR设计了两种采样方式来降低计算复杂度,poll sampler和pool sampler,poll sampler对feature map对每个位置预测分数,然后挑选出fine的特征,通过pool sampler对coarse特征进行聚合。
D^2ETR
paper:https://arxiv.org/pdf/2203.00860.pdf
D^2ETR去掉了DETR的encoder部分,同时在backbone部分对不同stage的特征进行融合操作。
Sparse DETR
paper:https://arxiv.org/abs/2111.14330
code:https://github.com/kakaobrain/sparse-detr
Sparse DETR通过Deformable cross-attention得到binarized decoder cross-attention map(DAM),用来作为scoring network的监督信号,预测出token的重要程度,并且只保留top-p%的token进行训练。
*Efficient DETR
paper:https://arxiv.org/pdf/2104.01318.pdf
Efficient DETR通过预测结果来初始化object queries,具体地,选取top-K个位置的feature当作object queries,位置当作reference points,k组embedding送入decoder进行稀疏预测,最终Efficient DETR只需要一个decoder就能超过DETR 6个decoder的精度。
Dynamic DETR
paper:https://openaccess.thecvf.com/content/ICCV2021/papers/Dai_Dynamic_DETR_End-to-End_Object_Detection_With_Dynamic_Attention_ICCV_2021_paper.pdf
Dynamic DETR的dynamic encoder部分引入SE然后用deformable self-attention来提取多尺度特征,dynamic decoder部分引入可学习的box encoding,然后对encoder的特征做roi池化,最后和decoder的中间层embedding做相乘。
*DAB-DETR
paper:https://arxiv.org/abs/2201.12329 code](https://github.com/SlongLiu/DAB-DETR
DAB-DETR直接动态更新anchor boxes提供参照点和参照anchor尺寸来改善cross-attention的计算。
*DN-DETR
paper:https://arxiv.org/abs/2203.01305
code:https://github.com/FengLi-ust/DN-DETR
DN-DETR在DAB-DETR的基础上,增加来一个denoising辅助任务,从而避免训练前期双边匹配的不稳定,加快收敛速度。
*DINO
paper:https://arxiv.org/pdf/2203.03605.pdf
code:https://github.com/twangnh/pnp-detr
DINO在DN-DETR的基础上引入了三点改进:
增加了一个新的辅助任务contrastive denoising training,在相同的gt box添加两种不同的noise,noise小的当作正样本,noise大的当作负样本。
提出mixed query selection方法,从encoder的输出中选择初始anchor boxes作为positional queries。
提出look forward twice方法,利用refined box信息来帮助优化前面层的参数。
Pure Transformer
Pix2Seq
paper:https://arxiv.org/abs/2109.10852
Pix2Seq直接把目标检测任务当成是序列任务,将cls和bbox构建成序列目标,图片通过Transformer直接预测序列结果。
YOLOS
paper:https://arxiv.org/abs/2106.00666
code:https://github.com/IDEACVR/DINO
YOLOS只使用transformer encoder做目标检测,模仿vit在encoder部分设置det token,在输出部分接MLP预测出cls和bbox。
FP-DETR
paper:https://openreview.net/pdf%3Fid%3DyjMQuLLcGWK
FP-DETR只使用transformer encoder部分,先使用cls token来做pre-training,然后替换成visual prompts来做fine-tuning。其中visual prompts由query content embedding和query positional embedding相加得到。
Instance segmentation
SOTR
paper:https://arxiv.org/abs/2108.06747
code:https://github.com/easton-cau/SOTR
SOTR在FPN backbone的基础上最小修改构建的。将多尺度的feature map加上positional embedding送入transformer模型中,通过cls head和kernel head预测出instance cls和dynamic conv,另一个分支对多尺度特征进行上采样融合得到,最后和dynamic conv想乘得到不同instance cls的区域。
panoptic segmentation
Max-DeepLab
paper:https://arxiv.org/pdf/2012.00759.pdf
code:https://github.com/google-research/deeplab2
Max-DeepLab设计了两个分支pixel path和memory path,两个分支在dual-path tansformer中进行交互,最终pixel path预测出mask,memory path预测出cls。
MaskFormer
paper:https://link.zhihu.com/?target=http%3A//arxiv.org/abs/2107.06278
code:https://github.com/facebookresearch/MaskFormer
Mask2Former
paper:https://arxiv.org/abs/2112.01527
code:https://github.com/facebookresearch/Mask2Former
MaskFormer提出将全景分割看成是mask分类任务。通过transformer decoder和MLP得到N个mask embedding和N个cls pred。另一个分支通过pixel decoder得到per-pixel embedding,然后将mask embedding和per-pixel embedding相乘得到N个mask prediction,最后cls pred和mask pred相乘,丢弃没有目标的mask,得到最终预测结果。
Mask2Former在MaskFormer的基础上,增加了masked attention机制,另外还调整了decoder部分的self-attention和cross-attention的顺序,还提出了使用importance sampling来加快训练速度。
Image Segmentation
semantic segmentation
SETR
paper:https://arxiv.org/abs/2012.15840
code:https://fudan-zvg.github.io/SETR/
SETR用ViT/DeiT作为backbone,然后设计了两种head形式:SETR-PUP和SETR-MLA。PUP将backbone输出的feature reshape成二维形式,然后不断的上采样得到最终的预测结果;MLA将多个stage的中间feature进行reshape,然后融合上采样得到最终的预测结果。
SegFormer
paper:https://arxiv.org/abs/2105.15203
code:https://github.com/NVlabs/SegFormer
SegFormer设计了一个encoder-decoder的分割框架,其中transformer block由Efficient Self-Attn、Mix-FFN、Overlap Patch Merging构成。Efficient Self-Attn对K进行下采样,Mix-FFN额外使用了conv。
Segmenter
paper:https://arxiv.org/abs/2105.05633
code:https://github.com/rstrudel/segmenter
Segmenter设计了类别无关的cls token,最后预测的时候分别和patch token进行点乘,最后reshap成二维图像。
U-Net Transformer
paper:https://arxiv.org/abs/2103.06104
TransUNet
paper:https://arxiv.org/abs/2102.04306
code:https://github.com/Beckschen/TransUNet
Swin-Unet
paper:https://arxiv.org/abs/2105.05537
code:https://github.com/HuCaoFighting/Swin-Unet
在U-Net结构中引入Transformer
P2T
paper:https://arxiv.org/abs/2106.12011
用对KV做池化的MHSA做下采样。
HRFormer
paper:https://papers.nips.cc/paper/2021/hash/3bbfdde8842a5c44a0323518eec97cbe-Abstract.html
HRFormer的block由local-window self-attention和FFN组成。
#基于Transformer的目标检测及跟踪
这次是基于Transformer的目标检测及跟踪
现存的用检测跟踪的方法采用简单的heuristics,如空间或外观相似性。这些方法,尽管其共性,但过于简单,不足以建模复杂的变化,如通过遮挡跟踪。
多目标跟踪(MOT)任务的关键挑战是跟踪目标下的时间建模。现存的用检测跟踪的方法采用简单的heuristics,如空间或外观相似性。这些方法,尽管其共性,但过于简单,不足以建模复杂的变化,如通过遮挡跟踪。所以现有的方法缺乏从数据中学习时间变化的能力。

在今天分享中,研究者提出了第一个完全端到端多目标跟踪框架MOTR。它学习了模拟目标的长距离时间变化。它隐式地执行时间关联,并避免了以前的显式启发式方法。MOTR建立在TRansformer和DETR之上,引入了“跟踪查询”的概念。每个跟踪查询都会模拟一个目标的整个跟踪。逐帧传输和更新,以无缝地执行目标检测和跟踪。提出了时间聚合网络(Temporal aggregation network)结合多框架训练来建模长期时间关系。实验结果表明,MOTR达到了最先进的性能。
多目标跟踪(MOT)是一种视觉目标检测,其任务不仅是定位每一帧中的所有目标,而且还可以预测这些目标在整个视频序列中的运动轨迹。这个问题具有挑战性,因为每一帧中的目标可能会在pool environment中被遮挡,而开发的跟踪器可能会受到长期和低速率跟踪的影响。这些复杂而多样的跟踪方案在设计MOT解决方案时带来了重大挑战。
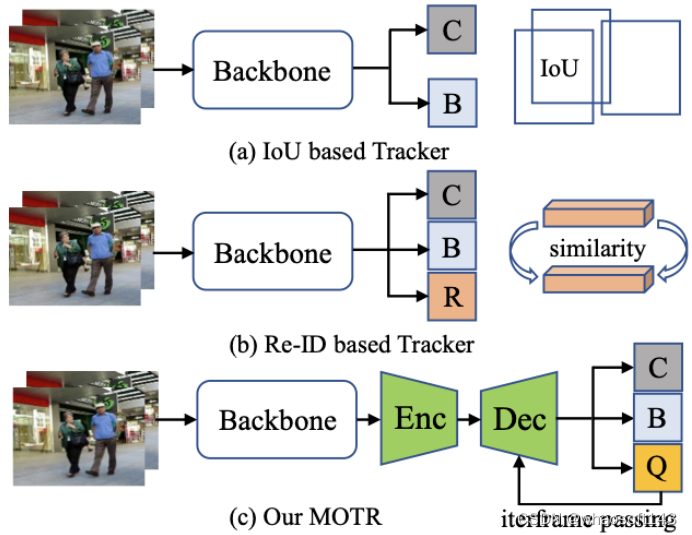
对于基于IoU的方法,计算从两个相邻帧检测到的检测框的IoU矩阵,重叠高于给定阈值的边界框与相同的身份相关联(见上图(a))。类似地,基于Re-ID的方法计算相邻帧的特征相似性,并将目标对与高相似性相关起来。此外,最近的一些工作还尝试了目标检测和重识别特征学习的联合训练(见上图(b))。
由于DETR的巨大成功,这项工作将“目标查询”的概念扩展到目标跟踪模型,在新框架中被称为跟踪查询。每个跟踪查询都负责预测一个目标的整个跟踪。如上图(c),与分类和框回归分支并行,MOTR预测每一帧的跟踪查询集。
最近,DETR通过采用TRansformer成功地进行了目标检测。在DETR中,目标查询,一个固定数量的学习位置嵌入,表示一些可能的实例的建议。一个目标查询只对应于一个使用bipartite matching的对象。考虑到DETR中存在的高复杂性和慢收敛问题,Deformable DETR用多尺度deformable attention取代了self-attention。为了展示目标查询如何通过解码器与特征交互,研究者重新制定了Deformable DETR的解码器。
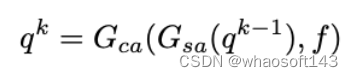
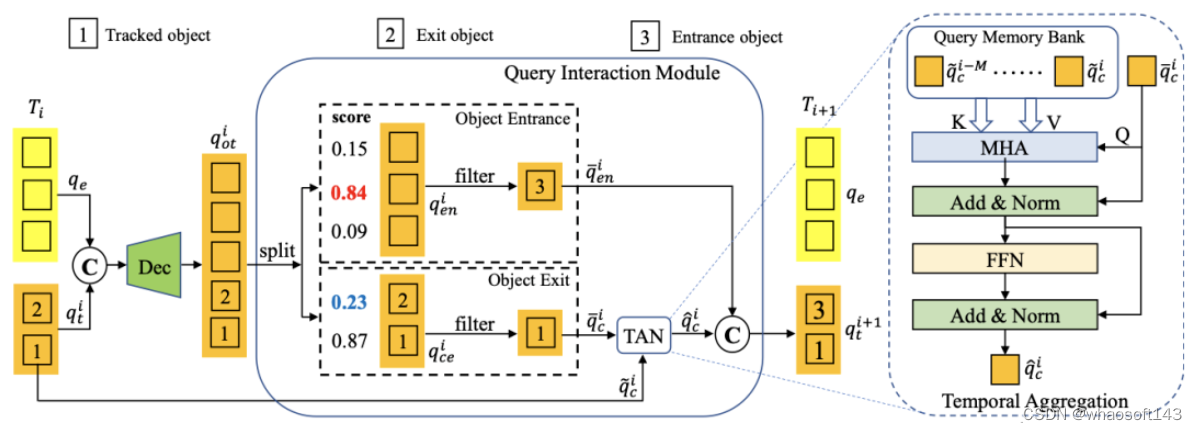
MOTR
在MOTR中,研究者引入了跟踪查询和连续查询传递,以完全端到端的方式执行跟踪预测。进一步提出了时间聚合网络来增强多帧的时间信息。

DETR中引入的目标(检测)查询不负责对特定目标的预测。因此,一个目标查询可以随着输入图像的变化而预测不同的目标。当在MOT数据集的示例上使用DETR检测器时,如上图(a),相同检测查询(绿色目标查询)预测两个不同帧预测两个不同的目标。因此,很难通过目标查询的身份来将检测预测作为跟踪值联系起来。作为一种补救措施,研究者将目标查询扩展到目标跟踪模型,即跟踪查询。在新的设计中,每个轨迹查询都负责预测一个目标的整个轨迹。一旦跟踪查询与帧中的一个目标匹配,它总是预测目标,直到目标消失(见上图(b))。

Overall architecture of the proposed MOTR
Query Interaction Module
在训练阶段,可以基于对bipartite matching的GTs的监督来实现跟踪查询的学习。而对于推断,研究者使用预测的轨迹分数来确定轨道何时出现和消失。
Overall Optimization
我们详细描述下MOTR的训练过程。给定一个视频序列作为输入,训练损失,即track loss,是逐帧计算和逐帧生成的预测。总track loss是由训练样本上的所有GT的数量归一化的所有帧的track loss的总和:
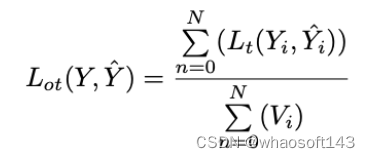
单帧图像Lt的track loss可表示为:
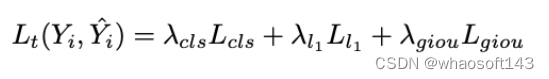
实验

Implementation DetailsAll the experiments are conducted on PyTorch with 8 Tesla V100 GPUs. We use the Deformable-DETR with ResNet50 as our basic network. The basic network is pretrained on the COCO detection dataset. We train our model with the AdamW optimizer for total 200 epochs with the initial learning rate of 2.0 · 10−4. The learning rate decays to 2.0 · 10−5 at 150 epochs. The batch size is set to 1 and each batch contains 5 frames.

The effect of multi-frame continuous query passing on solving ID switch problem. When the length of video sequence is set to two (top), the objects that are occluded will miss and switch the identity. When improving the video sequence length from two to five (bottom), the track will not occur the ID switch problem with the help of enhanced temporal relation.

#Transformer Adapter , ViT-Adapter
这次是用于密集预测任务的视觉 Transformer Adapter , ViT-Adapter
一种用于使得 ViT 架构适配下游密集预测任务的 Adapter。简单的 ViT 模型,加上这种 Adapter 之后,下游密集预测任务的性能变强不少。本文给出的 ViT-Adapter-L 在 COCO 数据集上达到了 60.9 的 box AP 和 59.3 的 mask AP。
我们之前使用 Vision Transformer 做下游任务的时候,因为 ViT 缺乏局部归纳偏置,所以人们提出一些为了下游任务而设计的 ViT 替代增强版,作者称之为:Vision-Specific Transformer,比如 Swin,PVT 等等。但是,你仔细观察就会发现这些模型只是名字和 ViT 相像,但却再也不是真正的 ViT 了,或多或少都掺杂了 CNN 的影子,初心没了。
为了弥补这个遗憾,本文提出了 ViT-Adapter,只用 ViT 作为密集预测任务的基本架构,不使用任何花里胡哨的替代增强版 (Vision-Specific Transformer)。使用最原始的 ViT,就是为了利用它跨模态学习 (multi-modal pre-training) 的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。
本文给出的 ViT-Adapter-L 在 COCO 数据集上达到了 60.9 的 box AP 和 59.3 的 mask AP。
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
论文名称:Vision Transformer Adapter for Dense Predictions
论文地址:
https://arxiv.org/pdf/2205.08534.pdf
近年来,Transformer 模型,得益于其动态建模的能力和长程依赖性,在计算机视觉领域取得了巨大的成功。使用 Vision Transformer 做下游任务的时候,用到的模型主要分为两大类:第1种是最朴素的直筒型 ViT[1],第2种是金字塔形状的 ViT 替代增强版,比如 Swin[2],CSwin[3],PVT[4] 等。一般来说,第2种可以产生更好的结果,人们认为这些模型通过使用局部空间操作将 CNN 存在的归纳偏置引入到 ViT 结构中。但是,你仔细观察就会发现这些模型只是名字和 ViT 相像,但却再也不是真正的 ViT 了,或多或少都掺杂了 CNN 的影子,初心没了。
问:为什么希望重新研究最朴素的直筒型 ViT 呢?
答: 因为这种最朴素的结构具有一些不可忽视的优势,即:多模态预训练 (multi-modal pre-training) 方面的优势。代表性的工作有:[5][6]。朴素的直筒型 ViT 和 Transformer 架构很类似,没有输入数据的假设。普通的 ViT 可以使用大量多模态数据进行预训练,包括图像、视频和文本,这鼓励模型学习到丰富的语义表示。
但是,这种最朴素的结构由于缺乏必要的与图像相关的归纳偏置,相较于 ViT 替代增强版会导致较慢的收敛过程和较低的下游任务性能。所以,这篇文章提出了一种用于使得 ViT 架构适配下游密集预测任务的 Adapter。ViT 模型,加上这种 Adapter 之后,下游下游密集预测任务的性能变强不少,即:
朴素的 ViT + 本文的 Adapter → 更强的下游任务性能
如下图1所示,Backbone 是一个普通 ViT,不仅可以用图像,还可以用多模态数据进行预训练。使用最原始的 ViT,就是为了利用它跨模态学习 (multi-modal) 的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。

图1:ViT-Adpater 范式
对于密集预测任务的迁移学习,我们使用一个随机初始化的 Adapter,将与图像相关的先验知识 (归纳偏差) 引入预训练的 Backbone,使模型适合这些任务。Adapter 是一种无需预训练的附加网络,可以使得最原始的 ViT 模型适应下游密集预测任务,且无需修改 ViT 架构。这里面就需要做一件事情就是将 ViT 模型所缺乏的图像相关的先验知识引入到普通 ViT 里面。因此,作者为 ViT- adapter 设计了3个定制模块:
空间先验模块 (图2 (c)):用于从输入图像中捕获局部语义 (空间先验)。
空间特征注入器 (图2 (d)):用于将空间先验纳入 ViT。
多尺度特征提取器 (图2 (e)):用于重建密集预测任务所需的多尺度特征。
ViT-Adapter 架构
如下图2所示,我们的模型可以分为两部分。第一部分是普通 ViT,即图2(a)。第二部分是 ViT- adapter,即图2(b)。它包含一个空间先验模块,空间特征注入器,多尺度特征提取器。
ViT 模型用的就是最原始的 ViT[1]架构,首先将输入图片分成 16×16 大小的不重叠的 Patch。之后进行 Patch Embedding 形成特征,特征分辨率降低到原始图像的 1/16。然后加上位置编码,得到的特征通过 个 Encoder Layer 向前传播。
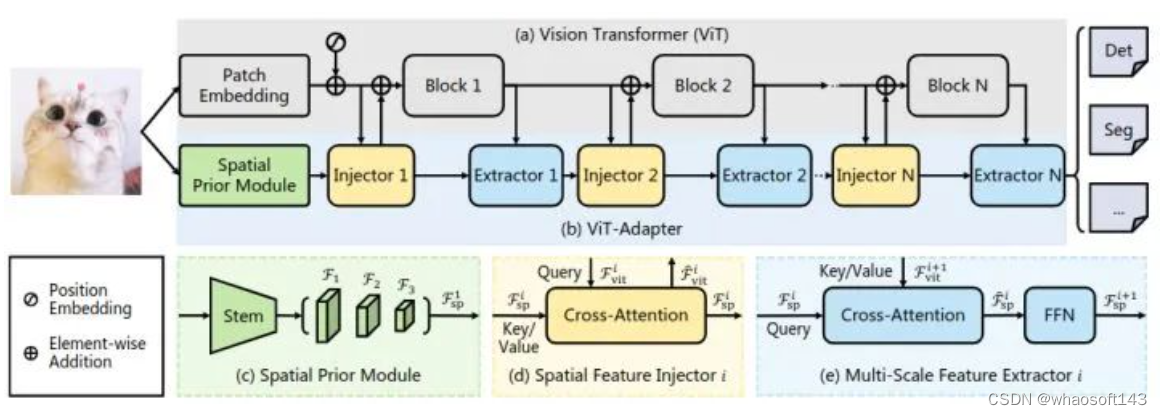
图2:ViT-Adapter 架构

空间先验模块

空间特征注入器
最简单的 ViT 结构由于缺乏必要的与图像相关的归纳偏置,相较于 ViT 替代增强版会导致较慢的收敛过程和较低的下游任务性能。为了缓解这一问题,作者提出了空间特征注入器 (Spatial Feature Injector) 和多尺度特征提取器 (Multi-Scale Feature Extractor)。

多尺度特征提取器

具体配置
作者为4种不同大小的 ViT 构建了 ViT-Adapter,包括 ViT-T,ViT-S,ViT-B,ViT-L。对于这些型号,Adapter 参数量分别为 2.5M、5.8M、14.0M 和 23.7M。作者使用[7]Deformable Attention 作为默认的稀疏注意力,采样点的数量固定为4。此外,作者将 FFN 的 Expansion Ratio 设置为0.25以节省计算开销。对于4个不同的适配器,FFN 的 Embedding diemnsion 大小分别为48、96、192和256。具体配置如下图3所示。

图3:ViT-Adapter 的具体配置
在本研究中,作者将重点放在如何更好地使现成的预训练 ViT 模型适应于下游的密集预测任务上,希望该方法也有助于上游预训练任务和下游微调过程的解耦。
COCO 目标检测实验结果
ImageNet-1K 预训练模型实验结果
使用 COCO 数据集,基于4种检测器:Mask R-CNN,Cascade Mask R-CNN,ATSS,GFL。为了节省时间和内存,作者参考 ViTDet [8]的做法并修改 LL 层 ViT 以使用 14×14 窗口注意力。使用 AdamW 优化器, Batch Size 设置为16,初始学习率为 1 × 10−4,权重衰减为0.05。
实验结果如下图4和5所示。

图4:COCO 目标检测和实例分割实验结果,使用 Mask R-CNN

图5:COCO 目标检测实验结果,使用不同检测头
作者使用 DeiT 发布的 ImageNet-1K 权重 (无蒸馏) 作为所有 ViT-T/S/B 模型的初始化,将 ViT-Adapter 与两种相关方法进行了比较。可以看到,当使用常规训练设置进行公平比较时,ViT 和 ViTDet 的检测性能不如 ViT-Adapter。
ViT-S 和 ViTDet-S 分别比 PVTv2-B2 低 3.8 APb 和 3.3 APb。ViT-Adapter-S的性能明显优于这两种方法,甚至比PVTv2-B2 高出 0.4 APb。这种观察也同样适用于其他3个检测器。这些结果表明,仅通过常规的 ImageNet-1K 预训练,ViT- adapter 就可以使普通 ViT 获得与这些 PVT 等模型相似甚至更好的性能。通过更大的 ImageNet-22K 预训练的模型也展示出了类似的结果。
多模态预训练模型实验结果
作者还研究了多模态预训练的效果。使用不同的预训练权重对 ViT-Adapter-B 与 Mask R-CNN 的方案进行微调,实验结果如下图6所示。只需将 ImageNet-22K 预训练替换为多模态预训练,就可以获得0.7的 APb 和 APm 的显著增益。这些结果表明,Adapter 可以很容易地从先进的多模态预训练中获得相当大的收益,这对于 Swin 等特定于视觉的模型来说是很难的。

图6:多模态预训练模型实验结果
ADE20K 语义分割实验结果
ImageNet-1K 预训练模型实验结果
使用 ADE20K 数据集,基于4种分割头:Semantic FPN (遵循 PVT 的训练设置,训练模型 80k iterations),UperNet (遵循 Swin 的训练设置,训练模型 160k iterations)。实验结果如下图7所示。
作者使用 DeiT 发布的 ImageNet-1K 权重 (无蒸馏) 作为所有 ViT-T/S/B 模型的初始化,可以看到,本文方法 ViT-Adapter 超过了 ViT 和许多具有代表性的视觉 Transformer。ViT-Adapter-S 使用 UperNet 达到了 47.1 MS mIoU,优于 Swin-T。同样,ViT-Adapter-B 达到的 49.7 MS mIoU 比 ViT-B 高2.6分,与 Swin-B 相当。这些结果表明,仅通过常规的 ImageNet-1K 预训练,ViT- adapter 就可以使普通 ViT 获得与这些 Swin 等模型相似甚至更好的性能。通过更大的 ImageNet-22K 预训练的模型也展示出了类似的结果。

图7:ADE20K 语义分割实验结果
多模态预训练模型实验结果
作者还研究了多模态预训练的效果。使用 Uni-Perceiver[9]的多模态预训练权重进行语义分割。如上图7所示,对于Semantic FPN 和 UperNet,用多模态预训练取代 ImageNet-22K 预训练使得 ViT-Adapter-L 分别获得了 1.3 mIoU 和 1.6 mIoU 的惊人收益。
与检测分割 SOTA 方案的比较
作者将 ViT-Adapter 与最先进的检测/分割框架结合起来,包括 HTC++ 和 Mask2Former,以及最近的多模态预训练 BEiTv2。如下图8所示,ViT-Adapter 达到了最先进的性能。虽然这些结果可能部分归因于高级预训练的有效性,但这也表明,普通的 ViT 检测器/分割器也可以达到金字塔 Backbone 的性能。

图8:与检测分割 SOTA 方案的比较
总结
这篇文章就属于希望使用朴素 ViT 模型做到高性能强于的 Swin 下游任务实验结果的一个工作。看这篇工作应该是受到了 ViTDet [8]的启发,想使用纯 ViT 获得更强的下游任务性能,而且很多做法也都是参考了 ViTDet (比如 Attention)。但是本文的3个针对性模块的设计很有新意,而且使用最原始的 ViT 之后,也利用了它对对模态预训练的强大潜质。当迁移到下游的密集预测任务时,使用一个无需预训练的 Adapter 将与图像相关的归纳偏置引入 ViT,使其适合这些任务。总体来看本文是一个很好的朴素 ViT 实现强下游任务的工作,很值得推广。
#Muse
推理速度比Stable Diffusion快2倍,生成、修复图像谷歌一个模型搞定
文本到图像生成是 2022 年最火的 AIGC 方向之一,被《science》评选为 2022 年度十大科学突破。最近,谷歌的一篇文本到图像生成新论文《Muse: Text-To-Image Generation via Masked Generative Transformers》又引起高度关注。
- 论文地址:https://arxiv.org/pdf/2301.00704v1.pdf
- 项目地址:https://muse-model.github.io/
该研究提出了一种使用掩码图像建模方法进行文本到图像合成的新模型,其中的图像解码器架构以来自预训练和 frozen T5-XXL 大型语言模型 (LLM) 编码器的嵌入为条件。
与谷歌先前的 Imagen 模型类似,该研究发现基于预训练 LLM 进行调整对于逼真、高质量的图像生成至关重要。Muse 模型是建立在 Transformer (Vaswani et al., 2017) 架构之上。
与建立在级联像素空间(pixel-space)扩散模型上的 Imagen (Saharia et al., 2022) 或 Dall-E2 (Ramesh et al., 2022) 相比,Muse 由于使用了离散 token,效率显著提升。与 SOTA 自回归模型 Parti (Yu et al., 2022) 相比,Muse 因使用并行解码而效率更高。
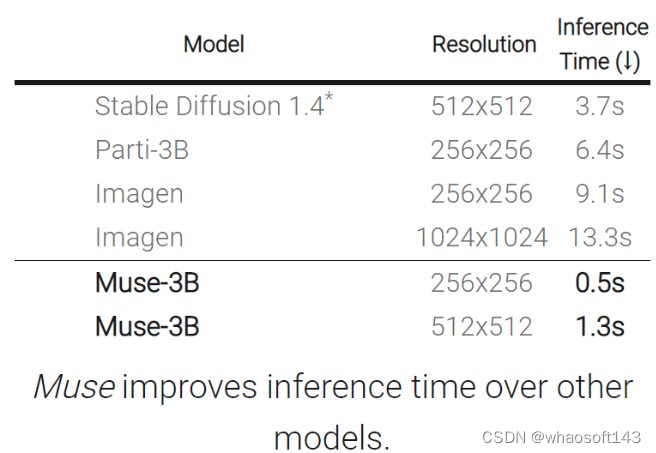
基于在 TPU-v4 上的实验结果,研究者估计 Muse 在推理速度上比 Imagen-3B 或 Parti-3B 模型快 10 倍以上,比 Stable Diffusion v1.4 (Rombach et al., 2022) 快 2 倍。研究者认为:Muse 比 Stable Diffusion 推理速度更快是因为 Stable Diffusion v1.4 中使用了扩散模型,在推理时明显需要更多次迭代。
另一方面,Muse 效率的提升没有造成生成图像质量下降、模型对输入文本 prompt 的语义理解能力降低的问题。该研究根据多个标准评估了 Muse 的生成结果,包括 CLIP 评分 (Radford et al., 2021) 和 FID (Heusel et al., 2017)。Muse-3B 模型在 COCO (Lin et al., 2014) 零样本验证基准上取得了 0.32 的 CLIP 分数和 7.88 的 FID 分数。
下面我们看看 Muse 生成效果:
文本 - 图像生成:Muse 模型从文本提示快速生成高质量的图像(在 TPUv4 上,对于 512x512 分辨率的图像需要时间为 1.3 秒,生成 256x256 分辨率的图像需要时间为 0.5 秒)。例如生成「一只熊骑着自行车,一只鸟栖息在车把上」:

Muse 模型通过对文本提示条件下的图像 token 进行迭代重新采样,为用户提供了零样本、无掩码编辑(mask-free editing)。

Muse 还提供了基于掩码的编辑,例如「在美丽的秋叶映照下,有一座凉亭在湖上」。

模型简介
Muse 建立在许多组件之上,图 3 提供了模型体系架构概述。

具体而言所包含的组件有:
预训练文本编码器:该研究发现利用预训练大型语言模型(LLM)可以提高图像生成质量。他们假设,Muse 模型学会了将 LLM 嵌入中的丰富视觉和语义概念映射到生成的图像。给定一个输入文本字幕,该研究将其通过冻结的 T5-XXL 编码器,得到一个 4096 维语言嵌入向量序列。这些嵌入向量线性投影到 Transformer 模型。
使用 VQGAN 进行语义 Tokenization:该模型的核心组件是使用从 VQGAN 模型获得的语义 token。其中,VQGAN 由一个编码器和一个解码器组成,一个量化层将输入图像映射到一个学习码本中的 token 序列。该研究全部使用卷积层构建编码器和解码器,以支持对不同分辨率图像进行编码。
基础模型:基础模型是一个掩码 transformer,其中输入是投影到 T5 的嵌入和图像 token。该研究保留所有的文本嵌入(unmasked),随机掩码不同比例的图像 token,并用一个特殊的 [mask] token 替换它们。
超分辨率模型:该研究发现使用级联模型是有益的:首先是生成 16 × 16 潜在映射(对应于 256 × 256 图像)的基础模型,然后是将基础的潜在映射上采样到的超分辨率模型,也就是 64 × 64 的潜在映射(对应于一个 512 × 512 的图像)。
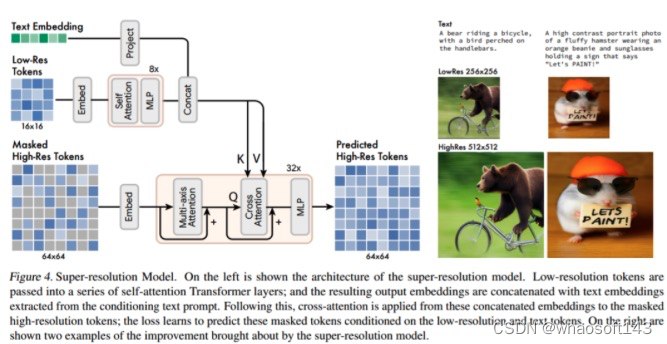
解码器微调:为了进一步提高模型生成精细细节的能力,该研究通过添加更多的残差层和通道来增加 VQGAN 解码器的容量,同时保持编码器容量不变。然后微调新的解码器层,同时冻结 VQGAN 编码器权重、码本和 transformer(即基础模型和超分辨率模型)。
除了以上组件外,Muse 还包含可变掩码比率组件、在推理时迭代并行解码组件等。
实验及结果
如下表所示,与其他模型相比,Muse 缩短了推理时间。
下表为不同模型在 zero-shot COCO 上测量的 FID 和 CLIP 得分:

如下表所示,Muse(632M (base)+268M (super-res) 参数模型)在 CC3M 数据集上训练和评估时得到了 6.06 的 SOTA FID 分数。

下图是 Muse 与 Imagen、DALL-E 2 在相同 prompt 下生成结果的例子。

#基于MLIR实现Layerout Transform
更多的深度学习编译器知识可以在 https://github.com/BBuf/tvm_mlir_learn 找到。同时也维护了一个cuda学习仓库 https://github.com/BBuf/how-to-optim-algorithm-in-cuda 以及一个如何学习深度学习框架(PyTorch和OneFlow)的学习仓库,https://github.com/BBuf/how-to-learn-deep-learning-framework , 有需要的小伙伴可以点一点star 。在https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/large-language-model-note 这个目录下收集了一系列和LLM训练,推理相关的文章。
在本文的描述中,存在一些接口和Interface的混用,这两个是一样的都表示MLIR的Interface。
继续深度学习编译器的优化工作解读,本篇文章要介绍的是OneFlow系统中如何基于MLIR实现Layerout Transform。在2D卷积神经网络中,除了NCHW数据格式之外一般还存在NHWC的数据格式,对于卷积操作来说使用NHWC格式进行计算可能会获得更好的性能。但深度学习网络的训练一般来说是采用NCHW进行的,我们一般只有在推理时才做NCHW到NHWC的Layerout Transform。这里存在两个问题:首先对于一个算子比如Conv2D,它以NCHW方式训练时保存的权重格式是[out_channels, in_channels, *kernel_size],但是要以NHWC格式进行推理时我们需要对权重的格式进行转换;然后对于没有权重的算子来说,我们也需要尽量的让算子支持NHWC的运算,来减少因为卷积算子前后插入的Transpose操作带来的额外开销。举个例子,假设有如下的一个小网络 x->conv->relu->conv->relu->out,如果我们要以NHWC格式执行那么我们除了对2个卷积的权重进行改动之外,我们还需要在conv前后插入transpose来修改输入到conv算子的数据格式,也就是x->transpose(0, 2, 3, 1)->conv->transpose(0, 3, 1, 2) -> relu -> transpose(0, 2, 3, 1)->conv->transpose(0, 3, 1, 2) -> relu->out。然后细心的读者可以发现,实际上这里存在很多冗余的Transpose,因为ReLU是支持以NHWC格式进行运算的,那么这个网络可以化简为x->transpose(0, 2, 3, 1)->conv->relu->conv->relu->transpose(0, 3, 1, 2)->out。这样可以减少一半的Transpose Op开销。
之所以要做transpose的化简是因为transpose算子本身也有运行以及调度的开销,如果我们不尽量减少transpose的个数,那么因为改用NHWC带来的计算加速可能会被 Transpose 的开销掩盖住。我们基于OneFlow实现了上述的Layerout Transform优化,以下给出测试结果。
在V100上对这个优化进行了测试,测试代码见 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/ir/test/OneFlow/auto_nhwc/test_resnet101_benchmark.py ,性能结果如下:
开启nn.Graph的AMP选项。
网络选取ResNet101,对其做前向推理。

在BatchSize=64时得到了13.6%的加速,随着BatchSize减少加速比会减小,但始终会保持一些加速。需要注意的是,这里对权重参数部分提前进行了transpose,所以这部分是没有额外开销的。实际上,我们采用了常量折叠的方式来完成,这个下篇文章再讲。
实现解析
在实现上主要需要搞定3个问题,第一个是如何确定哪些算子支持NHWC的运算,第二个是插入Transpose算子,第三个是消除多余的Transpose对。
基于Interface确定哪些算子支持NHWC运算
在OneFlow中如果我们要让某个Op支持NHWC的计算,只需在Op定义时声明一个NCHWCompatibleInterface。以卷积为例:
def OneFlow_Conv2DOp : OneFlow_ConvolutionBaseOp<"conv2d", [NoMemoryEffect, AttrSizedOperandSegments, DeclareOpInterfaceMethods, DeclareOpInterfaceMethods]> {}这里的 DeclareOpInterfaceMethods 表示这个 Operator 实现了 NCHWCompatibleInterface 接口,该接口定义了与 NCHW 格式兼容的 Operator 需要实现的方法。
我们想让其它的任意 Op 支持 NHWC 的运算,只需要定义这个接口并且重写这个接口的成员函数即可,接下来我们看一下NCHWCompatibleInterface 的定义。
bool Conv2DOp::IsNCHW() { return this->getDataFormat().str() == "channels_first"; }
llvm::DenseSet Conv2DOp::OperandsToTranspose() {if (this->get_addToOutput()) {return {this->getIn(), this->getWeight(), this->get_addToOutput()};} else {return {this->getIn(), this->getWeight()};}
}
llvm::DenseSet Conv2DOp::ResultsToTranspose() { return {this->getOut()}; }
llvm::SmallVector Conv2DOp::NchwToNhwc(llvm::SmallVector<value, 4> value,PatternRewriter& rewriter) {auto conv_op = *this;SmallVector<value, 4> operands;operands.push_back(value[0]);operands.push_back(value[1]);if (conv_op.getBias()) operands.push_back(conv_op.getBias());if (this->get_addToOutput()) { operands.push_back(value[2]); }NamedAttrList attributes = conv_op->getAttrs();attributes.set(conv_op.getDataFormatAttrName(), rewriter.getStringAttr("channels_last"));auto res = rewriter.create(conv_op.getLoc(), getNHWCResultTypes(conv_op), operands,attributes)->getResults();llvm::SmallVector<value, 4> results;results.push_back(res[0]);return results;
}其中,IsNCHW 方法返回一个 bool 值,表示该 Conv2DOp Operation 是否使用 NCHW 格式。它通过检查 Operation 的data_format 属性来判断。OperandsToTranspose 方法返回需要 Transpose 的输入值集合。对于 Conv2DOp 来说,主要输入包括input、weight、bias(可选) 和 addto_output(可选),其中bias不需要 Transpose,并且这个addto_output是OneFlow的一个特殊的输出用来做算子融合读者可以忽略。ResultsToTranspose 方法返回需要 Transpose 的输出值集合。对于 Conv2DOp 来说,仅有一个输出, 所以返回输出特征图的值。NchwToNhwc 方法接受 NCHW 格式的输入值和重写器,并返回 NHWC 格式的结果值。它通过创建一个新的 Conv2DOp Operation, 并将 data_format 属性设置为 channels_last, 来实现从 NCHW 到 NHWC 的转换。
插入Transpose算子
接下来就是贪心的给网络里的算子插入Transpose算子,这里的思路是我们尽可能的对网络里面的所有算子都前后分别插入一个Transpose,这样的话在消除Transopose对的时候才能获得最优的解。给网络中的算子插入Transpose的逻辑如下面的Pattern代码所述:
struct AutoNhwcPattern : public OpInterfaceRewritePattern {explicit AutoNhwcPattern(mlir::MLIRContext* context): OpInterfaceRewritePattern(context, /*benefit=*/1) {}public:LogicalResult matchAndRewrite(NCHWCompatible op, PatternRewriter& rewriter) const override {if (op->hasTrait()) {for (mlir::Value operand : op.OperandsToTranspose()) {if (operand.getType().cast().getShape().size() != 4) {return failure();}}const auto device_name = OpTrait::IsOpConfCompatible<void>::getDeviceTag(op).cast().getValue().str();if (device_name == "cpu") { return failure(); }}llvm::SmallVector<int32_t> perm = getChannelLastTransposePerm();llvm::SmallVector<int32_t> result_perm = getChannelFirstTransposePerm();NamedAttrList transpose_attributes;if (InitTransposeAttributes(op, transpose_attributes, rewriter).succeeded()) {transpose_attributes.append(llvm::StringRef("perm"), getSI32ArrayAttr(rewriter, perm));} else {return failure();}// when op op has no sense of data_format and pre op is transpose, we greedily insert transpose// into this op, seeking more opportunities to eliminate transpose pattern.const bool greedily_transpose_flag = !op.IsNCHW() && IsInsertTransposeOpBefore(op, rewriter);if (op.IsNCHW() || greedily_transpose_flag) {// create transpose op for input operandSmallVector<value, 4> tranposed_operands;llvm::DenseSet operand_transpose = op.OperandsToTranspose();int num_transposed_operand = 0;for (Value operand : op->getOperands()) {if (operand_transpose.find(operand) != operand_transpose.end()) {SmallVector<value, 4> input_res = getInputOperandTransposeOp(op, operand, transpose_attributes, num_transposed_operand, rewriter);tranposed_operands.push_back(input_res[0]);num_transposed_operand += 1;}}// create NHWC opSmallVector<value, 4> created_results = op.NchwToNhwc(tranposed_operands, rewriter);// create transpose op for resultsint num_transposed_result = 0;transpose_attributes.set(llvm::StringRef("perm"), getSI32ArrayAttr(rewriter, result_perm));llvm::DenseSet transpose_result = op.ResultsToTranspose();for (Value result : op->getOpResults()) {if (transpose_result.find(result) != transpose_result.end()) {if (auto result_transpose_op =getResultTransposeOp(op, created_results[num_transposed_result],transpose_attributes, num_transposed_result, rewriter)) {result.replaceAllUsesWith(result_transpose_op);num_transposed_result += 1;} else {return failure();}}}}return success();}
};首先 AutoNhwcPattern 类继承自 OpInterfaceRewritePattern,OpInterfaceRewritePattern 是一个用于重写 Operation 的基类。AutoNhwcPattern 针对实现了 NCHWCompatible Interface 的 Operation 进行重写,以实现 NCHW 到 NHWC 的格式转换。然后,AutoNhwcPattern 重写了 matchAndRewrite 方法。该方法会在遇到 NCHWCompatible Interface 的 Operation 时被调用,来实现从 NCHW 到 NHWC 的转换。接下来,matchAndRewrite 方法首先会检查 Operation 是否满足转换条件,如是否 4 维、是否在 CPU 设备上等。如果不满足则返回 failure。如果满足, matchAndRewrite 方法会获取 NCHW 到NHWC 和 NHWC 到 NCHW 的转换顺序。并初始化 Transpose Operation 的属性。然后对于当前 Op 是 NCHW 格式或者这个 Op 的前一个 Op 是Transpose Op,这里都进行插入 Transpose Op的操作来获得更多的优化机会。
这里还涉及到几个相关的工具函数,我们也解释一下:
llvm::SmallVector<int32_t> getChannelLastTransposePerm() { return {0, 2, 3, 1}; }
llvm::SmallVector<int32_t> getChannelFirstTransposePerm() { return {0, 3, 1, 2}; }
llvm::SmallVector getInputOperandTransposeOp(NCHWCompatible op, Value val,NamedAttrList transpose_attributes,int num_transposed_operand,PatternRewriter& rewriter) {std::string transpose_name = OpTrait::IsOpConfCompatible<void>::getOpName(op).str()+ "_transpose_input_" + std::to_string(num_transposed_operand);transpose_attributes.set(llvm::StringRef(OpTrait::IsOpConfCompatible<void>::getOpNameAttr()),rewriter.getStringAttr(transpose_name));SmallVector<value, 4> input_operands;input_operands.push_back(val);auto res = rewriter.create(op.getLoc(), getNHWCType(val.getType()),input_operands, transpose_attributes)->getResults();return res;
}
TransposeOp getResultTransposeOp(NCHWCompatible op, Value val, NamedAttrList transpose_attributes,int num_transposed_result, PatternRewriter& rewriter) {std::string transpose_name = OpTrait::IsOpConfCompatible<void>::getOpName(op).str()+ "_transpose_output_" + std::to_string(num_transposed_result);transpose_attributes.set(llvm::StringRef(OpTrait::IsOpConfCompatible<void>::getOpNameAttr()),rewriter.getStringAttr(transpose_name));SmallVector<value, 4> operands;operands.push_back(val);TransposeOp transpose_op = rewriter.create(op.getLoc(), getNCHWType(val.getType()), operands, transpose_attributes);return transpose_op;
}
bool IsInsertTransposeOpBefore(NCHWCompatible op, PatternRewriter& rewriter) {bool insert_transpose_op_flag = false;for (mlir::Value operand : op->getOperands()) {TransposeOp transposeInputOp = operand.getDefiningOp();if (!transposeInputOp) continue;const auto perm = transposeInputOp.getPermAttr();if (perm.size() == 4 && perm[0] == rewriter.getSI32IntegerAttr(0)&& perm[1] == rewriter.getSI32IntegerAttr(3) && perm[2] == rewriter.getSI32IntegerAttr(1)&& perm[3] == rewriter.getSI32IntegerAttr(2)) {insert_transpose_op_flag = true;break;}}return insert_transpose_op_flag;
}其中 getChannelLastTransposePerm 和 getChannelFirstTransposePerm 方法分别返回 NHWC 到 NCHW 和 NCHW 到NHWC 的转换顺序。getInputOperandTransposeOp方法为Operation 的输入创建一个Transpose Operation。它使用输入值、Transpose属性 和 重写器创建一个 TransposeOp , 并返回其结果。类似的,getResultTransposeOp 方法为 Operation 的输出创建一个Transpose Operation。它使用输出值、Transpose属性和重写器创建一个TransposeOp,并返回该Operation。IsInsertTransposeOpBefore方法检查Operation的输入是否已有 Transpose Operation。如果有,并且该 Transpose Operation 将 NHWC 转为 NCHW, 则返回 true, 否则返回false。
消除多余的Transpose对
接下来,我们需要把插入Transpose Op的图中所有相邻的Transpose对尽可能的消除,代码实现如下:
bool IsRedundantTransposeMatch(ArrayAttr pre, ArrayAttr afe, mlir::PatternRewriter& rewriter) {const auto prePerm = pre.getValue().vec();const auto afePerm = afe.getValue().vec();if (prePerm.size() == 4 && afePerm.size() == 4) {// handle nchw->nhwc->nchw: (0, 2, 3, 1) -> (0, 3, 1, 2)if (prePerm[0] == afePerm[0] && prePerm[1] == afePerm[3] && prePerm[2] == afePerm[1]&& prePerm[3] == afePerm[2] && prePerm[0] == rewriter.getSI32IntegerAttr(0)&& prePerm[1] == rewriter.getSI32IntegerAttr(2)&& prePerm[2] == rewriter.getSI32IntegerAttr(3)&& prePerm[3] == rewriter.getSI32IntegerAttr(1))return true;// handle nhwc->nchw->nhwc: (0, 3, 1, 2) -> (0, 2, 3, 1)if (prePerm[0] == afePerm[0] && prePerm[1] == afePerm[2] && prePerm[2] == afePerm[3]&& prePerm[3] == afePerm[1] && prePerm[0] == rewriter.getSI32IntegerAttr(0)&& prePerm[1] == rewriter.getSI32IntegerAttr(3)&& prePerm[2] == rewriter.getSI32IntegerAttr(1)&& prePerm[3] == rewriter.getSI32IntegerAttr(2))return true;}return false;
}
struct AutoNhwcEliminateRedundantTransposePattern : public mlir::OpRewritePattern {explicit AutoNhwcEliminateRedundantTransposePattern(mlir::MLIRContext* context): OpRewritePattern(context, /*benefit=*/1) {}mlir::LogicalResult matchAndRewrite(TransposeOp op,mlir::PatternRewriter& rewriter) const override {mlir::Value transposeInput = op.getOperand();TransposeOp transposeInputOp = transposeInput.getDefiningOp();if (!transposeInputOp|| !IsRedundantTransposeMatch(op.getPermAttr(), transposeInputOp.getPermAttr(), rewriter)) {return failure();}rewriter.replaceOp(op, {transposeInputOp.getOperand()});return success();}
};IsRedundantTransposeMatch 方法检查两个 Transpose Operation的顺序是否会导致冗余。它通过比较两个 Transpose 的 perm 属性来判断。类似 AutoNhwcPattern ,AutoNhwcEliminateRedundantTransposePattern 类继承自 OpRewritePattern 。它对TransposeOp 进行重写以实现 Transpose 消除。如果顺序是 NHWC->NCHW->NHWC 或NCHW->NHWC->NCHW , 则判定为冗余 Transpose 。如果输入也来自TransposeOp且两个 Transpose 顺序导致冗余,matchAndRewrite方法会用TransposeOp的输入替换TransposeOp。实现 Transpose 消除。matchAndRewrite 方法首先获取 TransposeOp 的输入,并检查该输入是否也来自一个 TransposeOp。如果不是, 或两个 Transpose 的顺序不导致冗余, 则返回 failure。最后返回 success 表示成功消除冗余 Transpose 。
最终,上面介绍的2个Pass都被封装到 AutoNhwcPass 中作用在 MLIR 的计算图上完成全局优化。从下面的代码可以看到这个优化只有在打开 ONEFLOW_MLIR_PREFER_NHWC 环境变量时才正常生效。
void populateAutoNhwcPatterns(::mlir::RewritePatternSet& patterns) {bool enable_nhwc = ::oneflow::ParseBooleanFromEnv("ONEFLOW_MLIR_PREFER_NHWC", false);if (enable_nhwc) {patterns.add(patterns.getContext());patterns.add(patterns.getContext());}
}
class AutoNhwcPass : public AutoNhwcPassBase {void runOnOperation() override {Operation* op = getOperation();RewritePatternSet patterns(op->getContext());oneflow::populateAutoNhwcPatterns(patterns);(void)applyPatternsAndFoldGreedily(op, std::move(patterns));}
};weight的transpose消除
这里还需要粗略的说明一下对于 weight 的 transpose 是如何处理的。在0x1.2中我们为 weight(常量constant op) 也插入了 Transpose Op,然后我们知道 weight 是常量,所以针对 weight 的 Transpose Op 完全可以在编译期折叠起来。这个过程是在 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/ir/oneflow-translate/lib/OneFlow/MLIROneFlowTranslation.cpp#L808-L811 这里完成的,我们后面会单独介绍一下 Constant Folding 的实现。
结论
本文介绍了一下OneFlow的编译器中的 Layerout Transform,这个技术在后来 OneFlow 版本的 Stable Diffusion 中也发挥了重要作用,提升了推理速度。在 TVM 的 Ansor 中也有类似的优化,通过将不同的 Layerout 设定为 Op 的 strategy 进而影响 Op 的 schedule,在搜索的时候考虑到 Layerout Transform 来获得更大的搜索空间和更好的结果。在处理Transpose 额外开销的方法并不是唯一的,这里只是采用了一种个人认为比较简单的方式,读者们如果有类似需要可以自由发挥。
#Attention Is All You Need
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
前段时间,一条指出谷歌大脑团队论文《Attention Is All You Need》中 Transformer 构架图与代码不一致的推文引发了大量的讨论。
对于 Sebastian 的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到 Transformer 论文的流行程度,这个不一致问题早就应该被提及 1000 次。
Sebastian Raschka 在回答网友评论时说,「最最原始」的代码确实与架构图一致,但 2017 年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
随后,Sebastian 在 Ahead of AI 发布文章专门讲述了为什么最初的 Transformer 构架图与代码不一致,并引用了多篇论文简要说明了 Transformer 的发展变化。
以下为文章原文,让我们一起看看文章到底讲述了什么:
几个月前,我分享了《Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed》,积极的反馈非常鼓舞人心!因此,我添加了一些论文,以保持列表的新鲜感和相关性。
同时,保持列表简明扼要是至关重要的,这样大家就可以用合理的时间就跟上进度。还有一些论文,信息量很大,想来也应该包括在内。
我想分享四篇有用的论文,从历史的角度来理解 Transformer。虽然我只是直接将它们添加到理解大型语言模型的文章中,但我也在这篇文章中单独来分享它们,以便那些之前已经阅读过理解大型语言模型的人更容易找到它们。
On Layer Normalization in the Transformer Architecture (2020)
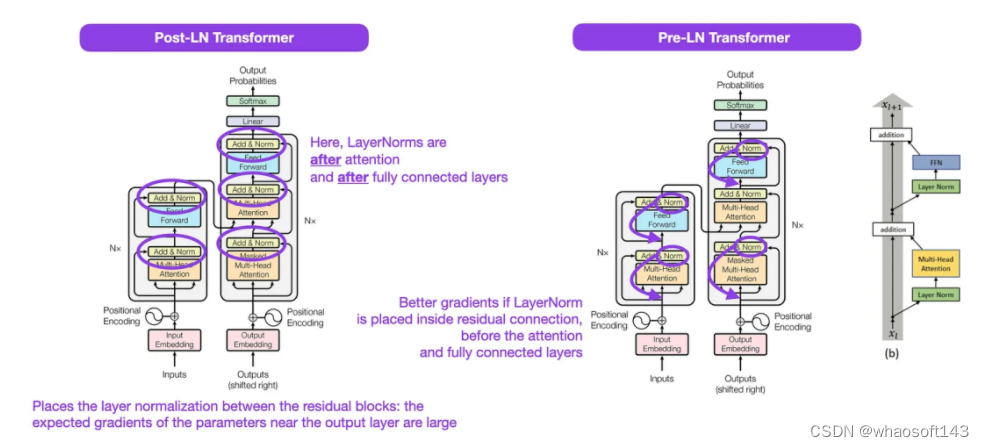
虽然下图(左)的 Transformer 原始图(https://arxiv.org/abs/1706.03762)是对原始编码器 - 解码器架构的有用总结,但该图有一个小小的差异。例如,它在残差块之间进行了层归一化,这与原始 Transformer 论文附带的官方 (更新后的) 代码实现不匹配。下图(中)所示的变体被称为 Post-LN Transformer。
Transformer 架构论文中的层归一化表明,Pre-LN 工作得更好,可以解决梯度问题,如下所示。许多体系架构在实践中采用了这种方法,但它可能导致表征的崩溃。
因此,虽然仍然有关于使用 Post-LN 或前 Pre-LN 的讨论,也有一篇新论文提出了将两个一起应用:《 ResiDual: Transformer with Dual Residual Connections》(https://arxiv.org/abs/2304.14802),但它在实践中是否有用还有待观察。
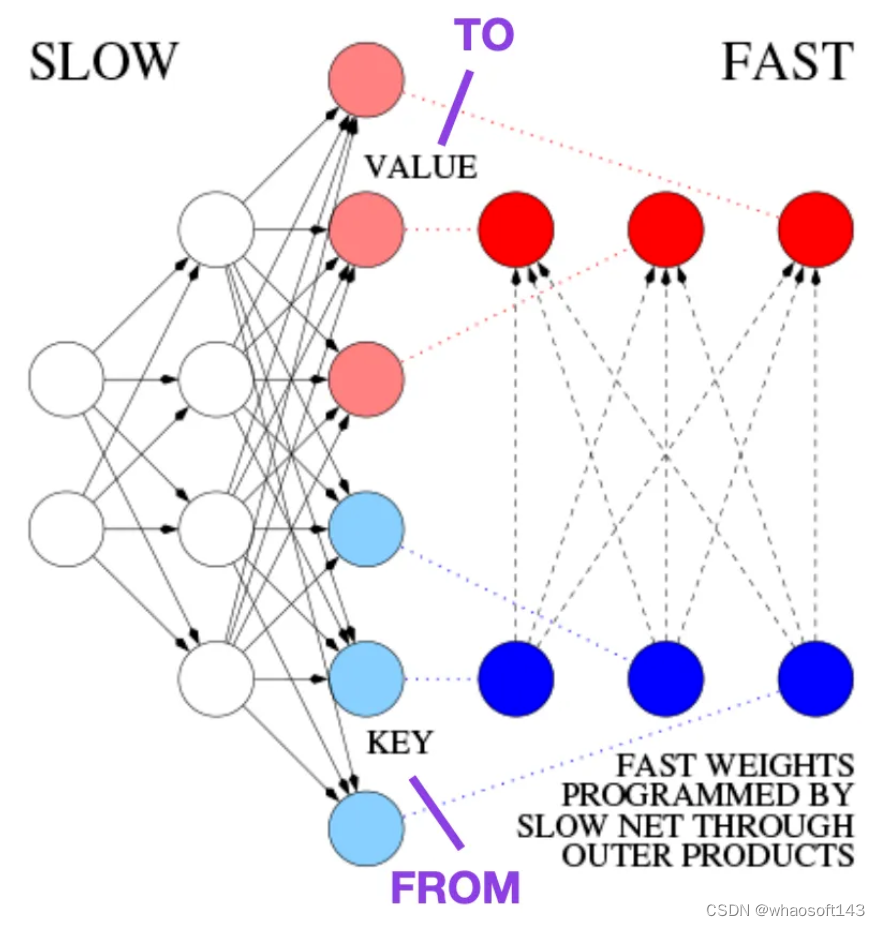
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
这篇文章推荐给那些对历史花絮和早期方法感兴趣的人,这些方法基本上类似于现代 Transformer。
例如,在比 Transformer 论文早 25 年的 1991 年,Juergen Schmidhuber 提出了一种递归神经网络的替代方案(https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922),称为 Fast Weight Programmers (FWP)。FWP 方法涉及一个前馈神经网络,它通过梯度下降缓慢学习,来编程另一个神经网络的快速权值的变化。
这篇博客 (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) 将其与现代 Transformer 进行类比,如下所示:
在今天的 Transformer 术语中,FROM 和 TO 分别称为键 (key) 和值 (value)。应用快速网络的输入称为查询。本质上,查询由快速权重矩阵 (fast weight matrix) 处理,它是键和值的外积之和 (忽略归一化和投影)。由于两个网络的所有操作都是可微的,我们通过加法外积或二阶张量积获得了端到端可微主动控制的权值快速变化。因此,慢速网络可以通过梯度下降学习,在序列处理期间快速修改快速网络。这在数学上等同于 (除了归一化之外) 后来被称为具有线性化自注意的 Transformer (或线性 Transformer)。
正如上文摘录所提到的,这种方法现在被称为线性 Transformer 或具有线性化自注意的 Transformer。它们来自于 2020 年出现在 arXiv 上的论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 》(https://arxiv.org/abs/2006.16236)以及《Rethinking Attention with Performers》(https://arxiv.org/abs/2009.14794)。
2021 年,论文《Linear Transformers Are Secretly Fast Weight Programmers》(https://arxiv.org/abs/2102.11174)明确表明了线性化自注意力和 20 世纪 90 年代的快速权重编程器之间的等价性。
Universal Language Model Fine-tuning for Text Classification (2018)
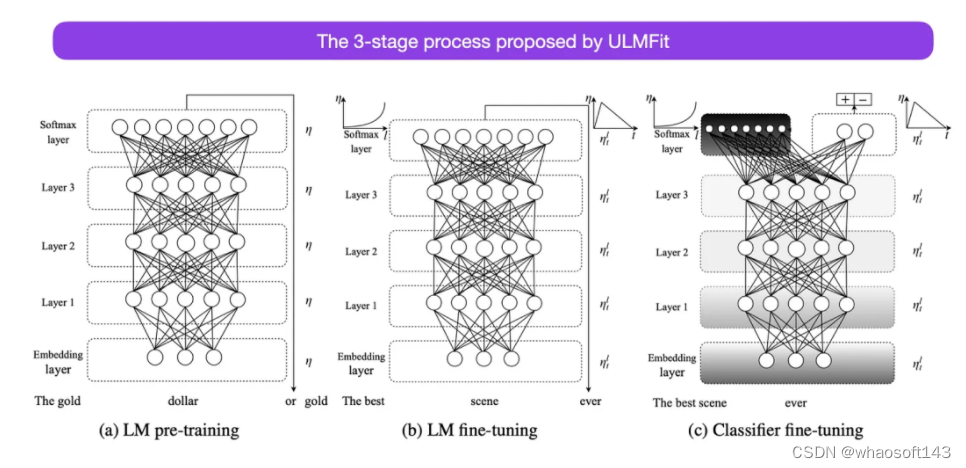
这是另一篇从历史角度来看非常有趣的论文。它是在原版《Attention Is All You Need》发布一年后写的,并没有涉及 transformer,而是专注于循环神经网络,但它仍然值得关注。因为它有效地提出了预训练语言模型和迁移学习的下游任务。虽然迁移学习已经在计算机视觉中确立,但在自然语言处理 (NLP) 领域还没有普及。ULMFit(https://arxiv.org/abs/1801.06146)是首批表明预训练语言模型在特定任务上对其进行微调后,可以在许多 NLP 任务中产生 SOTA 结果的论文之一。
ULMFit 建议的语言模型微调过程分为三个阶段:
- 1. 在大量的文本语料库上训练语言模型;
- 2. 根据任务特定的数据对预训练的语言模型进行微调,使其能够适应文本的特定风格和词汇;
- 3. 微调特定任务数据上的分类器,通过逐步解冻各层来避免灾难性遗忘。
在大型语料库上训练语言模型,然后在下游任务上对其进行微调的这种方法,是基于 Transformer 的模型和基础模型 (如 BERT、GPT-2/3/4、RoBERTa 等) 使用的核心方法。
然而,作为 ULMFiT 的关键部分,逐步解冻通常在实践中不进行,因为 Transformer 架构通常一次性对所有层进行微调。
Gopher 是一篇特别好的论文(https://arxiv.org/abs/2112.11446),包括大量的分析来理解 LLM 训练。研究人员在 3000 亿个 token 上训练了一个 80 层的 2800 亿参数模型。其中包括一些有趣的架构修改,比如使用 RMSNorm (均方根归一化) 而不是 LayerNorm (层归一化)。LayerNorm 和 RMSNorm 都优于 BatchNorm,因为它们不局限于批处理大小,也不需要同步,这在批大小较小的分布式设置中是一个优势。RMSNorm 通常被认为在更深的体系架构中会稳定训练。
除了上面这些有趣的花絮之外,本文的主要重点是分析不同规模下的任务性能分析。对 152 个不同任务的评估显示,增加模型大小对理解、事实核查和识别有毒语言等任务最有利,而架构扩展对与逻辑和数学推理相关的任务从益处不大。




摄像头读取延迟解决方法)

