我自己的原文哦~ https://blog.51cto.com/whaosoft/12501034
#SAM-PT
又一个「分割一切」视频版来了:点几下鼠标,动态的人、物就圈出来了
只要在视频中点几下鼠标,SAM-PT 就能分割并且追踪物体的轮廓。

视频分割在许多场景下被广泛应用。电影视觉效果的增强、自动驾驶的理解场景,以及视频会议中创建虚拟背景等等都需要应用到视频分割。近期,基于深度学习的视频分割已经有着不错的表现了,但这依旧是计算机视觉中一个具有挑战性的话题。
在半监督视频对象分割(VOS)和视频实例分割(VIS)方面,目前的主流方法处理未知数据时表现一般,是在零样本情况下更是「一言难尽」。零样本情况就是指,这些模型被迁移应用到未经过训练的视频领域,并且这些视频中包含训练之外的物体。而表现一般的原因就是没有特定的视频分割数据进行微调,这些模型就很难在各种场景中保持一致的性能。
克服这个难题,就需要将在图像分割领域取得成功的模型应用到视频分割任务中。这就不得不提到 Segment Anything Model(SAM,分割一切模型)了。
SAM 是一个强大的图像分割基础模型,它在规模庞大的 SA-1B 数据集上进行训练,这其中包含 1100 万张图像和 10 亿多个掩码。大量的训练让 SAM 了具备惊人的零样本泛化能力。SAM 可以在不需要任何标注的情况下,对任何图像中的任何物体进行分割,引起了业界的广泛反响,甚至被称为计算机视觉领域的 GPT。
尽管 SAM 在零样本图像分割上展现了巨大的能力,但它并非「天生」就适用于视频分割任务。
最近研究人员已经开始致力于将 SAM 应用于视频分割。虽然这些方法恢复了大部分分布内数据的性能,但在零样本情况下,它们还是无法保持 SAM 的原始性能。其他不使用 SAM 的方法,如 SegGPT,可以通过视觉 prompt 成功解决一些分割问题,但仍需要对第一帧视频进行掩码注释。这个问题在零样本视频分割中的关键难题。当研究者试图开发能够容易地推广到未见过的场景,并在不同的视频领域持续提供高质量分割的方法时,这个难题就显得更加「绊脚」。
现在,有研究者提出了 SAM-PT(Segment Anything Meets Point Tracking),这或许能够对「绊脚石」的消除提供新的思路。
- 论文地址:https://arxiv.org/pdf/2307.01197.pdf
- GitHub 地址:https://github.com/SysCV/sam-pt
如图 1 所示,SAM-PT 第一种将稀疏点追踪与 SAM 相结合用于视频分割的方法。与使用以目标为中心的密集特征匹配或掩码传播不同,这是一种点驱动的方法。它利用嵌入在视频中的丰富局部结构信息来跟踪点。因此,它只需要在第一帧中用稀疏点注释目标对象,并在未知对象上有更好的泛化能力,这一优势在 UVO 基准测试中得到了证明。该方法还有助于保持 SAM 的固有灵活性,同时有效地扩展了它在视频分割方面的能力。
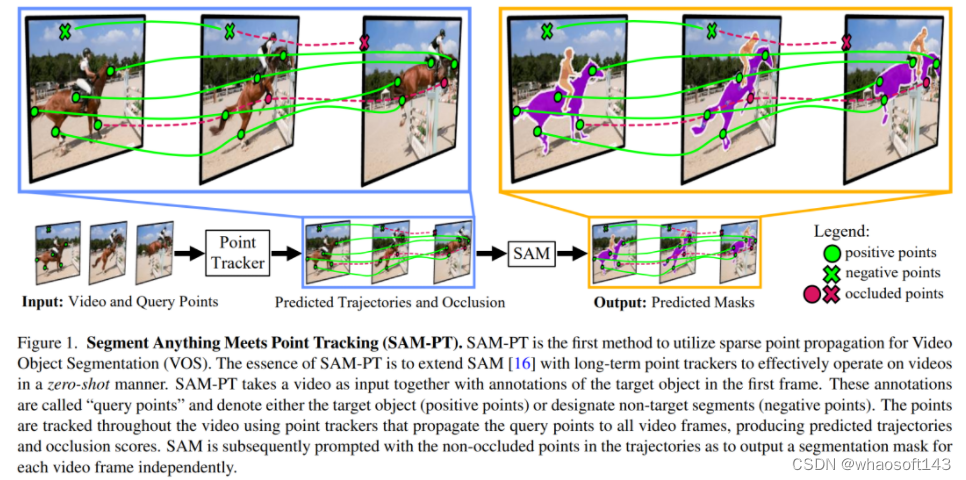
SAM-PT 使用最先进的点追踪器(如 PIPS)预测稀疏点轨迹,以此提示 SAM,利用其多功能性进行视频分割。研究人员发现,使用来自掩码标签的 K-Medoids 聚类中心来初始化跟踪点,是与提示 SAM 最兼容的策略。追踪正反两方面的点可以将目标物体从其背景中清晰地划分出来。
为了进一步优化输出的掩码,研究人员提出了多个掩码解码通道,将两种类型的点进行整合。此外,他们还设计了一种点重新初始化策略,随着时间的推移提高了跟踪的准确性。这种方法包括丢弃变得不可靠或被遮挡的点,并添加在后续帧 (例如当物体旋转时) 中变得可见的物体部分或部分的点。
值得注意的是,本文的实验结果表明,SAM-PT 在几个视频分割基准上与现有的零样本方法不相上下,甚至超过了它们。在训练过程中,SAM-PT 不需要任何视频分割数据,这证明了方法的稳健性和适应性。SAM-PT 具有增强视频分割任务进展的潜力,特别是在零样本场景下。
SAM-PT 方法概览
尽管 SAM 在图像分割方面展示出令人印象深刻的能力,但其在处理视频分割任务方面存在固有的局限性。我们提出的 "Segment Anything Meets Point Tracking"(SAM-PT)方法有效地将 SAM 扩展到视频领域,为视频分割提供了强大的支持,而无需对任何视频分割数据进行训练。
如图 2 所示,SAM-PT 主要由四个步骤组成:
1) 为第一帧选择查询点;
2) 使用点跟踪器,将这些点传播到所有视频帧;
3) 利用 SAM 生成基于传播点的逐帧分割掩码;
4) 通过从预测的掩码中抽取查询点来重新初始化这个过程。
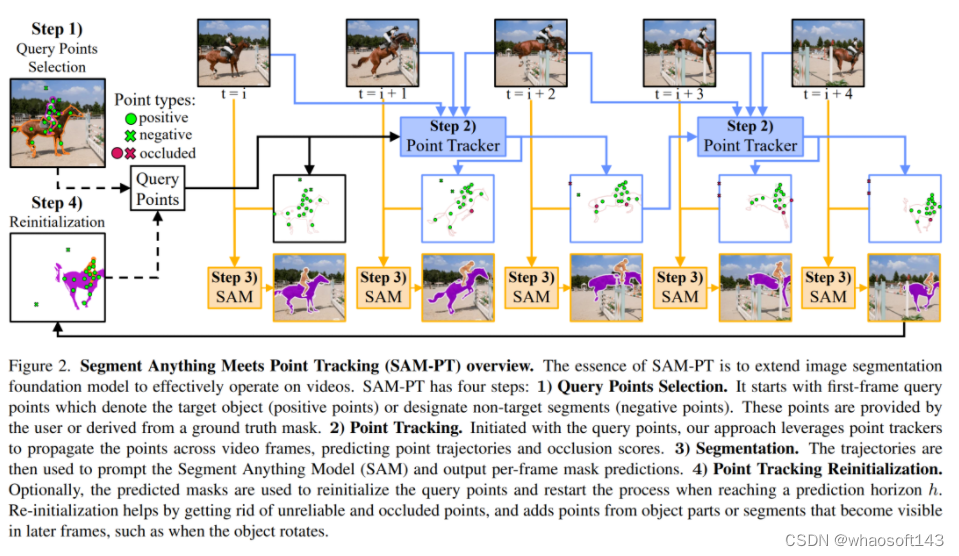
选择查询点。该过程的第一步是定义第一个视频帧中的查询点。这些查询点要么表示目标对象 (正点),要么指定背景和非目标对象 (负点)。用户可以手动、交互式地提供查询点,也可以从真实掩码派生出查询点。
考虑到它们的几何位置或特征差异性,用户可以使用不同的点采样技术从真实掩码中获得查询点,如图 3 所示。这些采样技术包括:随机采样、K-Medoids 采样、Shi-Tomasi 采样和混合采样。

点跟踪。从查询点开始,采用稳健的点跟踪器在视频中的所有帧中传播点,从而得到点的轨迹和遮挡分数。
采用最先进的点跟踪器 PIPS 来传播点,因为 PIPS 对长期跟踪挑战 (如目标遮挡和再现) 显示出适当的稳健性。实验也表明,这比链式光流传播或第一帧对应等方法更有效。
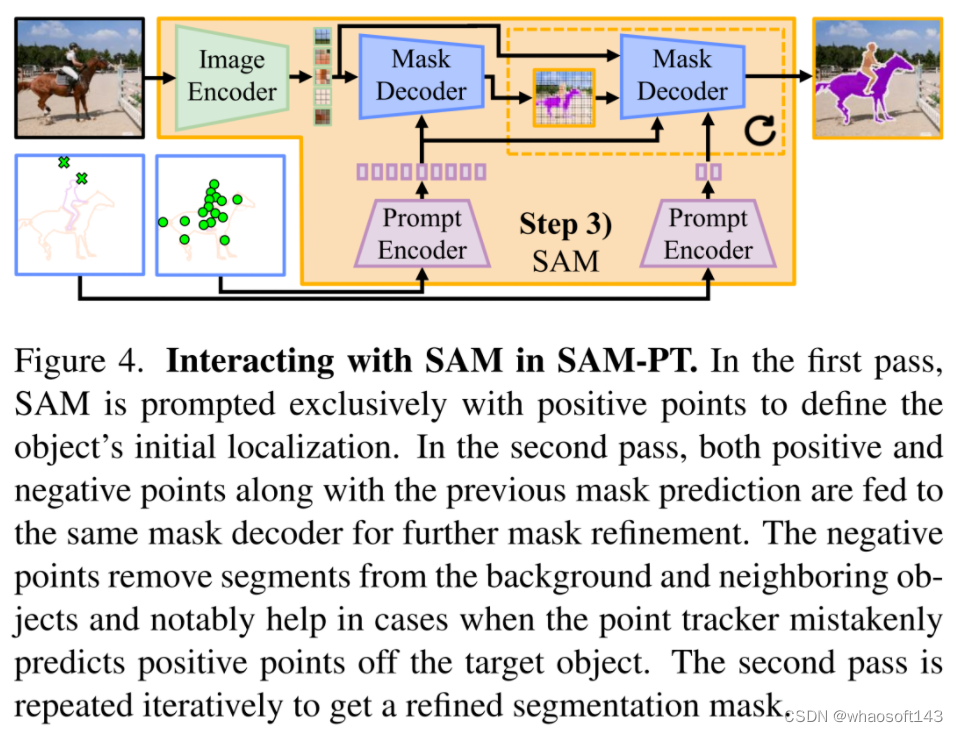
分割。在预测的轨迹中,未遮挡的点作为目标对象在整个视频中的位置的指示器。这时就可以使用非遮挡点来提示 SAM,并利用其固有的泛化能力来输出每帧分割掩码预测(如图 4 所示) 。
点跟踪重新初始化。一旦达到 h = 8 帧的预测期,用户就可以选择使用预测掩码对查询点进行重新初始化,并将变体表示为 SAM-PT-reinit。在到达这个水平线时,会有 h 个预测的掩码,并将使用最后一个预测的掩模来采样新的点。在这一阶段,之前所有的点都被丢弃,用新采样点来代替。
根据上面的方法,就可以将这个视频进行流畅的分割了,如下图:

看看更多的展示效果:

SAM-PT 与以目标为中心的掩码传播的比较
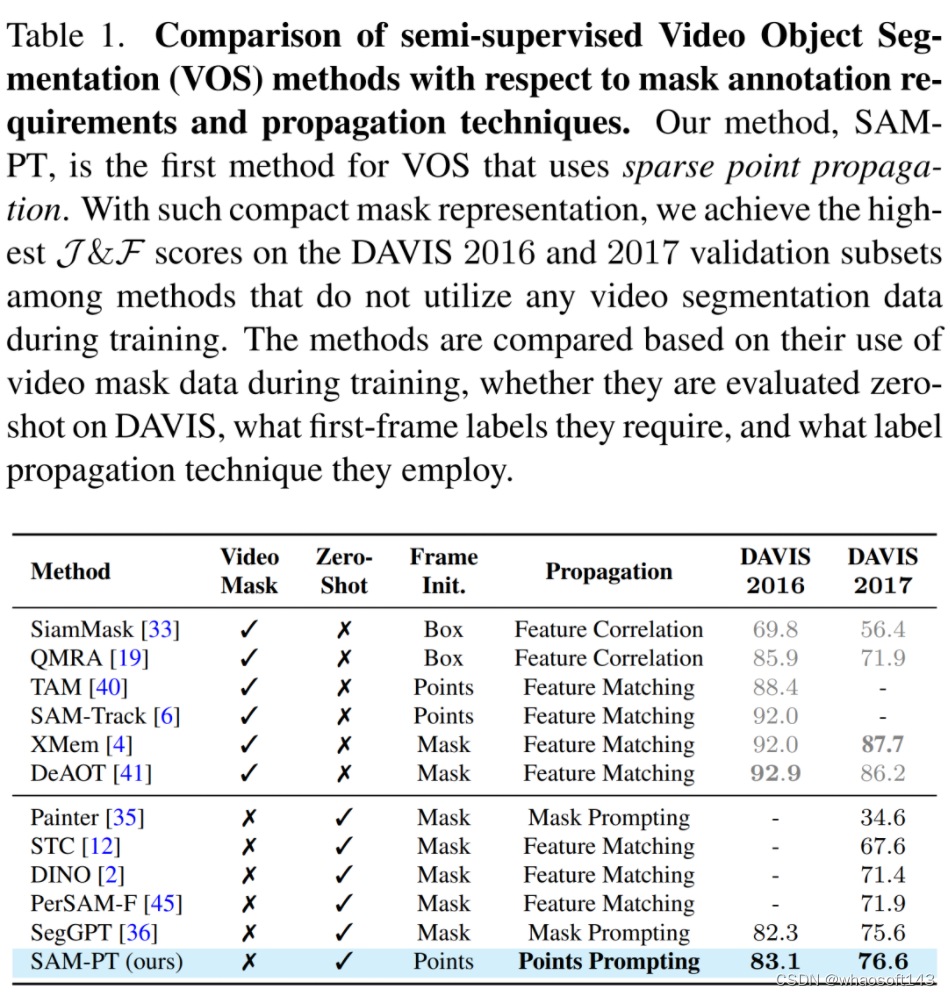
SAM- PT 将稀疏点跟踪与提示 SAM 相结合,并区别于传统依赖于密集目标掩码传播的视频分割方法,如表 1 所示。
与在训练期间不利用视频分割数据的方法相比,SAM-PT 有着与之相当甚至更好的表现。然而,这些方法与那些利用同一域中的视频分割训练数据的方法, 如 XMem 或 DeAOT 之间还是存在着性能差距。
综上所述,SAM-PT 是第一个引入稀疏点传播并结合提示图像分割基础模型,进行零样本视频对象分割的方法。它为关于视频对象分割的研究提供了一个新的视角,并增加了一个新的维度。
实验结果
对于视频物体分割,研究团队在四个 VOS 数据集上评估了他们的方法,分别是 DAVIS 2016, DAVIS 2017, YouTube-VOS 2018, 和 MOSE 2023。
对于视频实例分割,他们在 UVO v1.0 数据集的 densevideo 任务上评估了该方法。
他们还用图像实例分割中的标准评估指标来评估所提出方法,这也适用于视频实例分割。这些指标包括平均准确率(AP)和基于 IoU 的平均召回率(AR)。
视频物体分割的结果
在 DAVIS 2017 数据集上,本文提出的方法优于其他没有经过任何视频物体分割数据训练的方法,如表 3 所示。
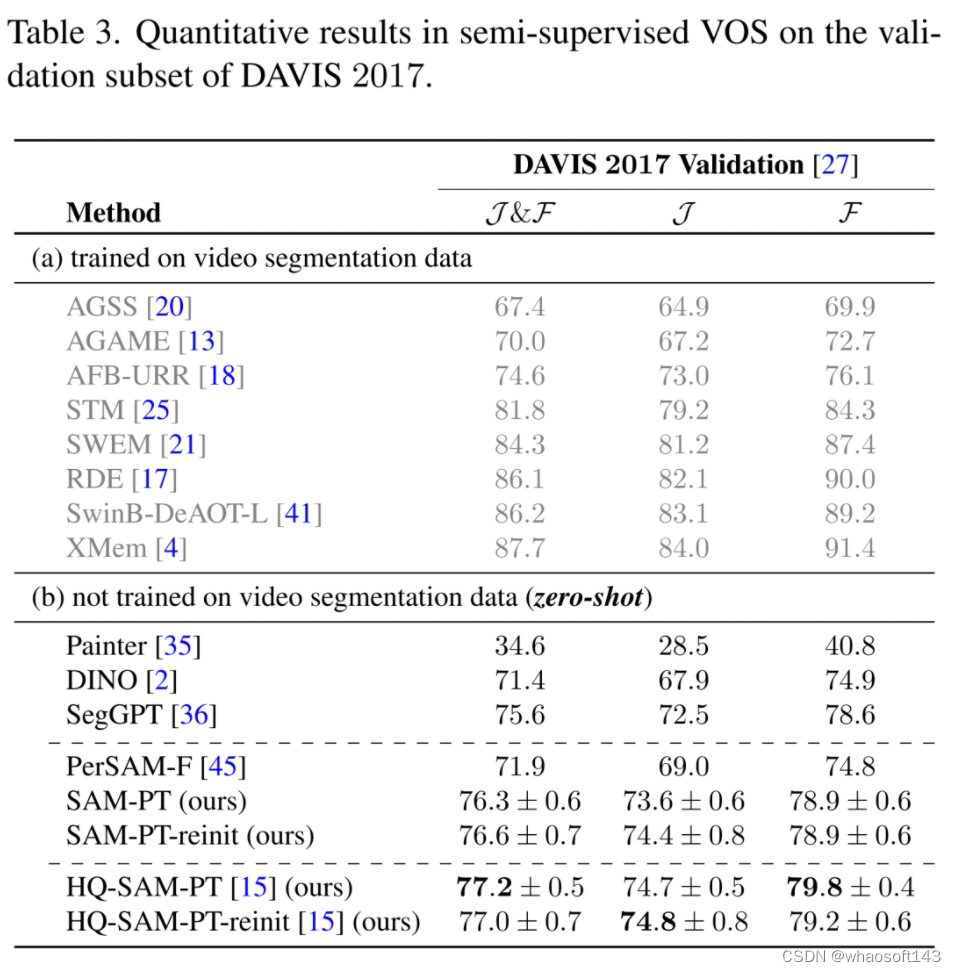
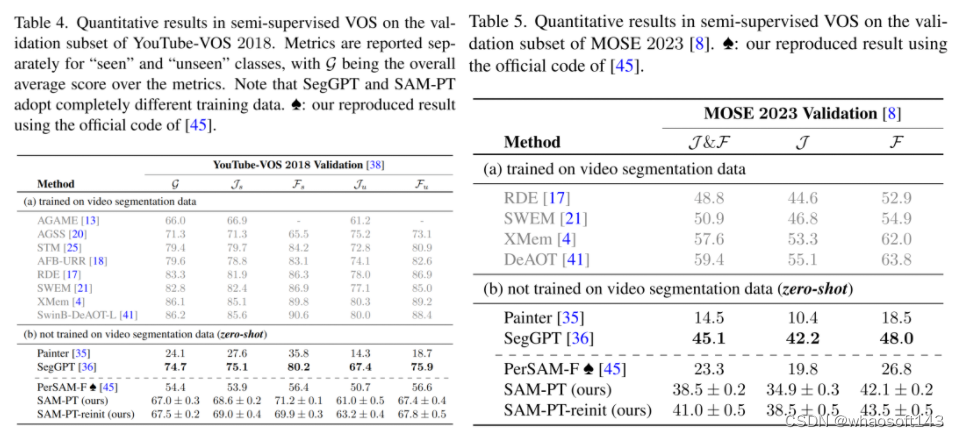
SAM-PT 在 YouTube-VOS 2018 和 MOSE 2023 数据集上的表现也超过了 PerSAM-F,取得了 67.0 和 41.0 的平均分,如表 4、表 5 所示。然而,在不同的掩码训练数据下,与 SegGPT 相比,SAM-PT 在这两个数据集上的表现有所欠缺。
定性分析。在 DAVIS 2017 上对 SAM-PT 和 SAM-PTreinit 成功的视频分割的可视化结果分别见图 7a 和图 7b。值得注意的是,图 8 展示了对未知网络视频的成功视频分割 —— 来自受动画影响的动画电视系列《降世神通:最后的气宗》的片段,这表明了所提出方法的零样本能力。


局限和挑战。SAM-TP 的零样本性能很有竞争力,但仍然存在着一些局限。这些局限主要集中在点跟踪器在处理遮挡、小物体、运动模糊和重新识别方面。在这些方面,点跟踪器的错误会传播到未来的视频帧中。
图 7c 展示了 DAVIS 2017 中的这些问题实例,图 9 展示了《降世神通:最后的气宗》片段中的其他实例。

视频实例分割的结果
在相同的遮罩建议下,SAM-PT 明显优于 TAM,尽管 SAM-PT 没有在任何视频分割数据上训练。TAM 是一个结合了 SAM 和 XMem 的并行方法,其中 XMem 在 BL30K 上进行了预训练,并在 DAVIS 和 YouTube-VOS 上进行了训练,但没有在 UVO 上训练。
另一方面,SAM-PT 结合了 SAM 和 PIPS 点跟踪方法,这两种方法都没有经过视频分割任务的训练。
#UV-SAM
清华大学提出UV-SAM,一种基于视觉基础模型的城市村庄识别框架。UV-SAM框架引入了一个类似专家的语义分割模型,用于生成四种城市村庄特定的提示,然后将其输入到类似于通才的SAM模型中,以从卫星图像中识别城市村庄边界。 巧妙结合SAM和SegFormer,得到一个新颖的通才-专家框架
城市村庄,被定义为城市中心附近的非正规居住区,其特征是基础设施不完善,生活条件恶劣,这与可持续发展的目标(SDGs)紧密相关,包括减贫、充足住房、和可持续城市。传统上,政府主要依赖实地调查方法来监测城市村庄,但这种方法耗时较长,需要大量人力,并且可能出现延误。得益于广泛可用的和及时更新的卫星图像,最近的研究开发了计算机视觉技术来高效地检测城市村庄。然而,现有研究要么关注简单的城市村庄图像分类,要么无法提供准确的边界信息。为了准确识别城市村庄的边界,作者利用视觉基础模型的力量,并适应了分割 Anything 模型(SAM)进行城市村庄分割,称为 UV-SAM。
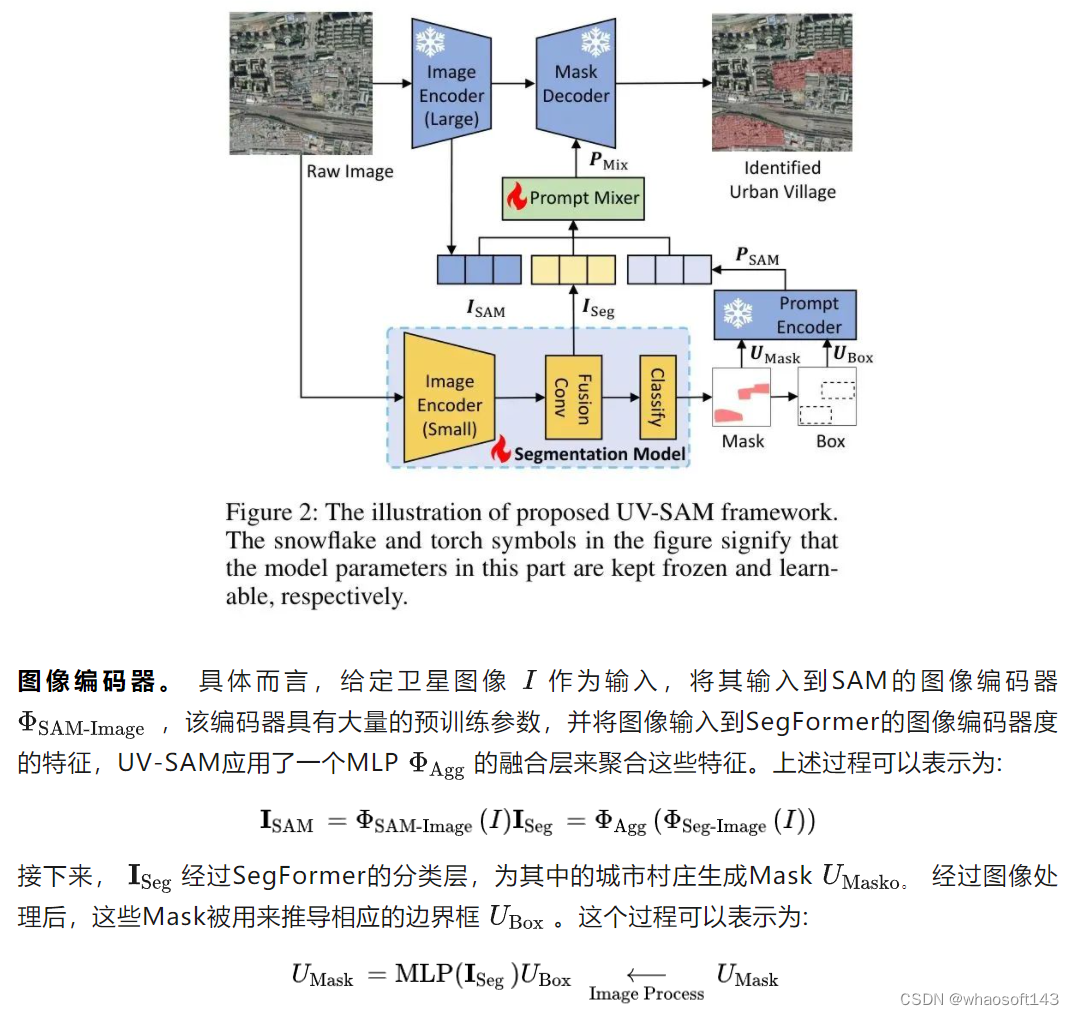
具体而言,UV-SAM 首先利用一个小型的语义分割模型来为城市村庄生成混合提示,包括Mask、边界框和图像表示,然后将这些提示输入到 SAM 中进行细粒度的边界识别。在中国两个数据集上的大量实验结果显示,UV-SAM 优于现有 Baseline ,并且多年的识别结果表明城市村庄的数量和面积随着时间的推移而减少,为城市村庄的发展趋势提供了更深入的洞察,并揭示了可持续城市的视觉基础模型。
论文链接:https://arxiv.org/abs/2401.08083
本研究的数据集和代码可在此处找到:https://github.com/tsinghua-fib-lab/UV-SAM
Introduction
城市村庄是我国非正规住区的典型代表,是主要大城市郊区和市中心密集的人口社区,通常由较老的多层建筑和狭窄的巷道组成。一方面,城市村庄为外来务工行人和低收入居民提供了经济适用房选择,有助于构成城市的社会经济结构。另一方面,城市村庄经常面临基础设施不完善、公共服务获取有限和居住条件恶劣等挑战。因此,准确识别城市村庄与联合国第11个可持续发展目标(SDG 11)相吻合,即“建设包容、安全、抗灾和可持续的人类住区”。在未来的可持续城市中,准确识别城市村庄对城市规划和治理至关重要。
传统上,城市村庄识别主要依赖于实地调查和手工制图,城市规划师会访问不同的区域,收集社会经济数据,并视觉上识别城市村庄边界。虽然这种方法提供了宝贵的洞察,但它们耗时较长,需要大量人力,并且空间和时间覆盖范围有限。近年来,利用卫星图像探索计算机视觉技术以识别城市村庄已经引起了广泛关注。大多数研究构建了图像分类模型,以判断给定的卫星图像是否包含一个城市村庄,而没有识别边界,其他研究则探索了语义分割模型,以在卫星图像中识别城市村庄边界。然而,由于卫星图像中的复杂背景干扰和城市村庄与周围社区之间没有明确的边界,现有研究在提供准确的城市村庄边界方面表现不佳,这进一步阻碍了城市村庄面积和扩张的估计。
此外,城市村庄的有限标注数据也使得分割模型容易过拟合,并且无法泛化到噪声卫星图像,例如遮挡和季节变化等。
与此同时,由于在超过一亿张图像上进行训练,最近Segment Anything Model (SAM)的视觉基础模型在泛化能力和类别无关的分割质量方面表现出显著的性能,对分割边界非常敏感,并在各种领域进行了研究。具体而言,SAM以一种需要伴随输入图像的预先提示的方式运行,例如参考点、边界框或Mask。显然,SAM提供的类别无关分割不能直接应用于语义分割。因此,一些研究探索了特定领域的精细手动提示以进行类别特定的分割,例如为医学图像分割手动标注边界框,显示出令人鼓舞的结果。因此,考虑到现有城市村庄识别研究中模糊边界识别的局限性以及SAM的泛化能力和边界敏感性,一个有趣的研究问题是SAM是否可以帮助从卫星图像中识别城市村庄。
关于上述研究问题,本文提出了一种类似于通才-专家框架的UV-SAM,用于适应SAM进行城市村庄识别。具体而言,适应的关键点在于生成能够鼓励SAM在卫星图像中关注城市村庄的类别特定的提示。因此,作者将具有大量冻结参数的SAM视为通才类别无关分割的通用模型,并开发一个具有有限可学习参数的语义分割模型作为城市村庄识别的专家模型,其中专家模型在通用模型生成提示的同时自动生成专家模型的提示,通用模型反过来更新专家模型的参数。
遵循所提出的框架,UV-SAM使用四种特定于卫星图像的城市村庄提示类别。首先,UV-SAM开发了一个类似于SegFormer的小型语义分割模型,用于为城市村庄生成粗略的分割Mask,基于此,生成城市村庄的Mask提示和框提示。其次,SAM和SegFormer中的图像编码器提取的特征图作为语义提示。此外,设计了一个提示混合模块来将这四种提示类型融合在一起,并将生成的城市村庄提示向量输入到SAM中进行城市村庄特定的分割。
总之,作者的贡献在于三个方面:
- 第一个引入视觉基础模型SAM进行城市村庄识别的人,这启发了在人工智能中使用基础模型为可持续城市和SDG应用。
- 建立了一个新颖的通用-专家框架UV-SAM,该框架可以自动生成四种独特的提示类型,并无缝地将SAM集成到城市村庄识别应用程序中。
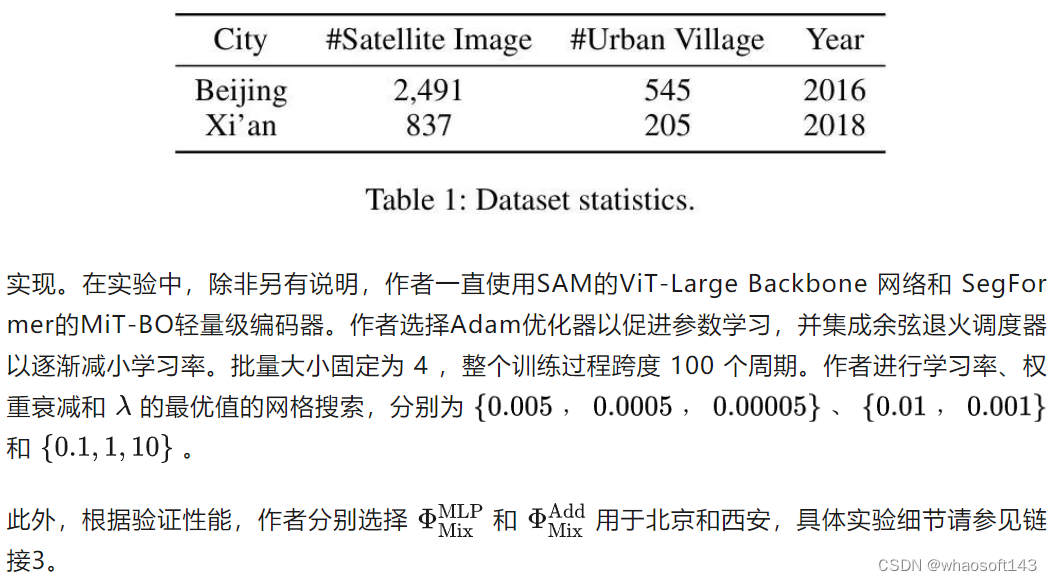
- 在中国两个城市北京和西安进行了广泛的实验,结果表明作者的提出框架与最先进的模型相比实现了显著的性能改进。进一步的案例研究揭示了城市村庄在数量和面积上的演变趋势,以及它们的 spatial distribution,这为城市规划和治理提供了有价值的洞察。
Related Works
基于卫星图像的城市村庄识别。 城市村庄识别是指识别出一个城市中具有城市村庄特征的区域或地区,这对于了解城市村庄的空间分布和演变至关重要。
许多研究探讨了卫星图像分类问题,以确定相应的图像中是否存在城市村庄。早期的研究应用传统的机器学习算法,如支持向量机,根据手工制作的特征来分类城市和非城市区域。近年来,采用深度学习技术,特别是卷积神经网络(CNN),从卫星图像中自动学习判别特征。例如,一些研究通过在卫星图像和街景图像上构建各种深度学习模型来分类城市村庄。另一项研究使用非常高分辨率的遥感图像和时间序列人口密度数据来分类城市非正规住区。此外,一项最近的工作[15]使用城市区域图并设计了一个上下文主-从框架来有效地检测城市村庄。然而,这些研究仅关注图像分类,而无法识别城市村庄的边界,为可持续城市提供了有限的信息。
另一方面,一些研究将城市村庄识别视为分割问题。例如,Mask R-CNN模型被用于从卫星图像中检测城市村庄并分割城市村庄的边界。另外两项研究分别利用了已建立的语义分割模型,包括全卷积神经网络(FCN)和U-Net,来映射深圳和广州的城市村庄区域。
此外,UVLens利用出租车轨迹将城市卫星图像划分为更小的块,并将其中的自行车共享上下车数据合并到这些图像块中,并使用Mask R-CNN模型来检测城市村庄。总的来说,现有的城市村庄研究要么过于关注分类,要么在语义分割上存在不准确的问题。此外,这些研究通常依赖于额外的数据来源,如街道视图和交通数据,这些数据并不适用于所有城市。
SAM应用。自2023年4月提出以来,SAM已在不同领域广泛应用,如医学图像处理,3D视觉,图像修复,目标跟踪等,可分为两种应用方式:
- 在SAM图像编码器上进行微调或添加 Adapter 。 例如,SAMed,MedSAM 和3DSAMadopter针对医学图像分割将SAM专门定制,并集成 Adapter ,以在医学图像分割任务上获得性能改进。
- 生成特定任务的提示。 例如,AutoSAM设计了一个辅助卷积网络,取代了医学图像领域的提示嵌入。RSPrompter 开发了基于 Anchor 点和 Query 的提示,并与SAM一起用于基于卫星图像的实例分割。由于基于SAM的应用,作者将SAM应用到城市村庄识别问题上。
Preliminary
在这一部分中,作者提供了SegFormer和SAM的问题陈述以及用于该方法的重要模型。
问题陈述。 城市村庄识别是指在给定的地理区域内识别和划分城市村庄的边界,并将其与周围区域分开。因此,利用卫星图像的城市村庄识别问题可以正式定义为:

SegFormer构建了一个编码器-解码器框架,在语义分割任务中实现了出色的性能。在编码器部分,SegFormer使用了一种分层金字塔视觉Transformer (ViT) 将输入图像分解为不同层次的区域,并在不同抽象 Level 上处理它们。在解码器部分,开发了一个多层感知机 (MLP) 来收集来自各个层的信息,有效地将局部注意力和全局注意力机制合并,以创建强大的表示,最终将它们上采样以生成最终的分割Mask。
SAM 设计了一个灵活的提示启用模型架构,用于类别无关的分割。具体而言,SAM由图像编码器、提示编码器和Mask解码器组成,其中图像编码器使用Mask自编码器技术预训练,提示编码器处理密集和稀疏输入,Mask解码器根据编码嵌入预测Mask。特别是,SAM支持外部提示,如框、点和文本,用于分割目标。
Methodology
通用-专家框架概述。 图2呈现了UV-SAM模型的一般-专家风格的框架,以解决城市村庄识别问题。考虑到现有模型在准确定义城市村庄边界方面的局限性,在通用部分,利用SAM的强大边缘检测能力来学习这些更细的边界。此外,在专家部分,为了为SAM提供城市村庄特定的提示,使用轻量级语义分割模型SegFormer进行提示生成。

Experiments
在这一部分,作者进行实验来回答以下研究问题:
RQ1:提出的UV-SAM模型与现有的基准方法相比表现如何?
RQ2:提出的UV-SAM模型中每个设计模块的有效性如何?
RQ3:提出的UV-SAM模型是否能够识别城市村庄的空间分布?
RQ4:提出的UV-SAM模型是否能够识别城市村庄的面积和数量的变化趋势?对于数据集,根据是否标记为真实阳性来计算精确度、召回率和F1分数。
对于分割精度,使用广泛使用的交点与并集(IoU)指标,该指标计算为分割出的城市村庄和对应的真实城市村庄之间的交点面积除以并集面积。
Overall Performance (RQ1)
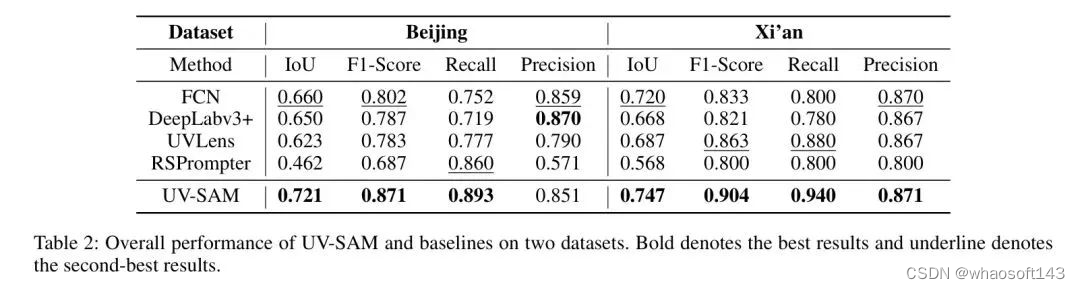
表2显示了在北京和西安数据集上的整体性能比较。从这些结果中,作者可以得出以下观察:
UV-SAM在两个数据集上都实现了最佳性能。结果表明,作者提出的模型达到了最先进的性能,成功地将SAM应用于城市村庄识别。在分割精度方面,与 Baseline 相比,UV-SAM在两个数据集上IoU方面分别比最佳 Baseline 提高了4%-9%。在检测精度方面,在两个数据集上,UV-SAM在F1-score方面也表现出比最佳 Baseline 更好的性能。值得注意的是,在DeepLabv3+上的性能差异。这是由于DeepLabv3+的结构与北京数据集的特征非常匹配。DeepLabv3+架构将高层语义信息与低层特征捕捉边界细节相结合。北京独特的特征,如密集的传统庭院式建筑和较短的建筑,与西安的高层密集建筑不同。此外,由于通用-专家框架,表2中的所有 Baseline 都可以作为专业模块集成到UV-SAM中,这可以带来城市村庄识别的进一步性能提升。
现有的基于SAM的模型在城市村庄识别方面表现不佳。根据表2中的结果,RSPrompter 在IoU和F1-score方面的表现明显落后于其他基准模型,例如,北京数据集的最差IoU和F1-score分别为0.462和0.687。这些结果表明,RSPrompter中的可学习提示无法捕捉到与城市村庄特别相关的高度复杂和抽象语义特征,因此对SAM没有提供有用的指导。此外,性能下降也强调了SAM在城市村庄识别方面的非易用性。
基于Transformer的编码器展示了比其他基于CNN的模型更好的城市村庄语义理解。在Transformer架构的能力下,作者提出的UV-SAM在IoU和F1-score指标方面明显优于其他CNN模型。如前所述,城市村庄包含复杂和高级的语义概念,其卫星图像中的边界划分受到周围环境上下文因素的影响。因此,具有注意力机制的Transformer架构可以更好地捕捉其中的细粒度特征,而CNN模型主要抓住高层次的语义抽象,导致不准确的边界和较差的性能。
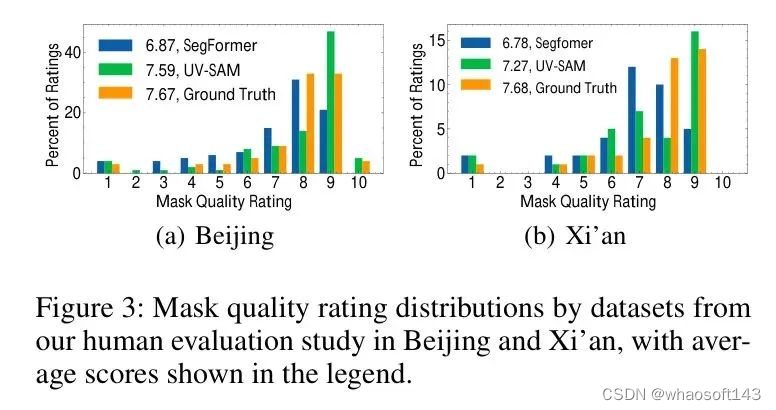
此外,为了更好地评估城市村庄的Mask质量,作者引入了人类评估。具体而言,将模型生成的Mask提供给标注者,并要求他们从1到10对每个Mask的质量进行评分。10分表示识别出的城市村庄区域边界没有明显的错误,而1表示Mask与城市村庄无关。作者比较了SAM和SegFormer生成的Mask以及 GT 数据,这些数据如图3所示。
结果表明,UV-SAM在两个数据集上都优于SegFormer,实现了更好的Mask质量。 例如,在Beijing数据集上,UV-SAM的平均评分达到7.59,而SegFormer为6.87,与 GT 数据7.67相比。在评分较低的范围内,UV-SAM的表现略低于 Baseline 。相反,在评分较高的范围内,UV-SAM的频率明显增加。这些结果表明SAM对于分割边界的有效性。
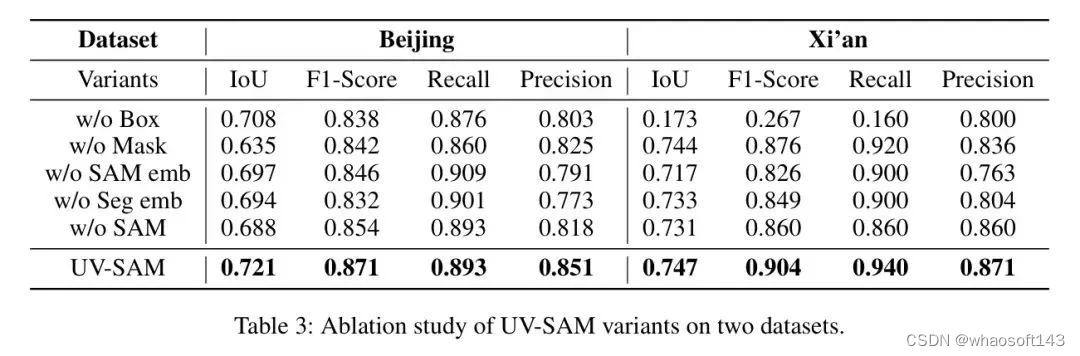
Ablation Study (RQ2)
为了评估UV-SAM中每个模块的有效性,表3显示了不同模型变体在两个数据集上的检测和分割性能。根据结果,如果没有框提示,UV-SAM性能分别下降了1.8%和75.9%。因此,框提示在性能保证中起着重要作用,它引导SAM的Mask解码器专注于感兴趣的区域。此外,西安数据集上的性能下降可以很大程度上归因于提示添加的简单方式。此外,Mask提示提供了密集的嵌入,特别强调图像中的物体边界,为两个数据集的IoU分别贡献了11.9%和0.4%。
此外,具有城市村庄特有的抽象语义信息,来自图像编码器(大型)的SAM嵌入进一步在两个数据集上实现了3%-4%的改进。最后,UV-SAM在从图像编码器(小)获得的分割嵌入的帮助下,可以获得2%-3%的改进,捕获了专业像元分割模型提供的高级语义信息。因此,所有四种类型的提示都是有效城市村庄识别的必要条件。此外,如果没有SAM,UV-SAM性能会下降4.6%和2.1%。因此,像SAM这样的通用模型为城市村庄识别提供了更准确的信息。
Spatial Distribution Analysis (RQ3)
为了减轻城市村庄对城市发展的潜在风险以及改善公民的生活条件,政府通常会逐步拆除并迁移其中的居民。因此,识别城市村庄的空间分布对于城市规划至关重要。在图4中,作者可视化了2020年北京六环路内城市村庄的空间分布。
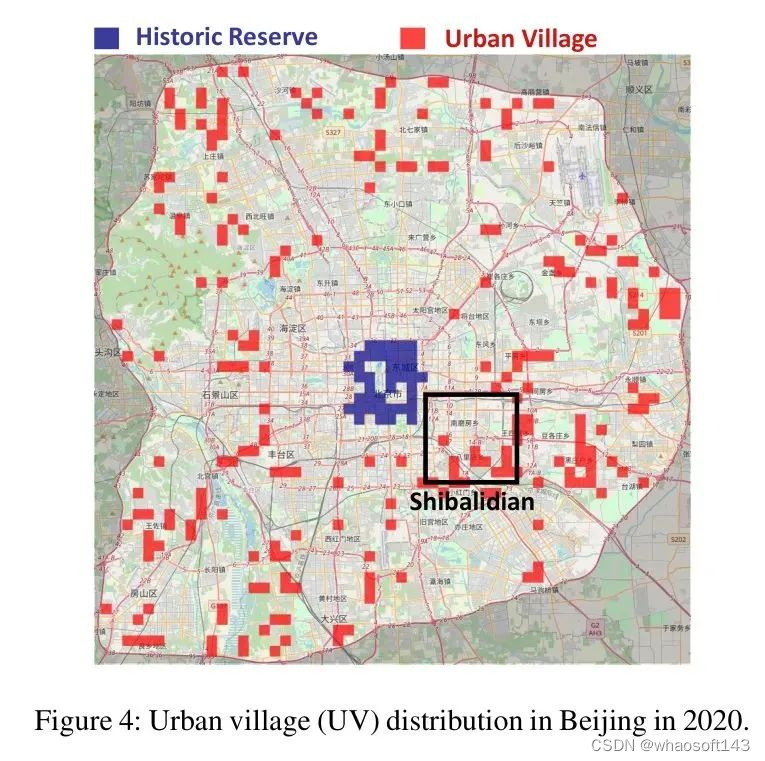
如图所示,在北京的第二环路内,有许多历史保护区,通常由庭院式住房组成,可以容纳几户人家。尽管这些地区具有历史和文化保护价值,但通常人均居住面积较小,卫生条件差,绿化覆盖率低,这与城市村庄的定义相符。相反,城市村庄在第三和第六环路之间的分布更为稀疏。特别是,北京著名的城市村庄集群石坝村附近明显集中了城市村庄。此外,该地区的南部和东部城市村庄的密度高于西部和北部。这种分布差异可能归因于历史人口迁移模式和当地经济水平的差异。
为了量化空间分布,作者在图5中进一步绘制了与北京环路相关的城市村庄分布曲线,以面积和数量为横坐标。作者通过使用卫星影像结果中的预测Mask数量和累积像素值来粗略确定城市村庄的数量和范围。根据结果,第五和第六环路之间的城市村庄面积和数量显著增加,这是因为距离市中心足够远,并且保留了原有村庄的建筑。

Evolving Trend (RQ4)
为了理解城市村庄的形成、扩张和收缩,作者在图7中使用北京和西安的卫星图像在不同时间点捕获的图像,展示了不同年份城市村庄面积和数量的变化。
根据结果,北京在2011年估计有1000个城市村庄,西安在2013年约有360个城市村庄。到2016年或2018年,城市村庄的面积只减少了不到10平方公里。然而,到了2020年,城市村庄的空间范围和数量都发生了显著的收缩,与之前的水平相比减少了50%。这种明显的趋势可能归因于政府当局推广的《北京城市总体规划(2016-2035年)》。
尤其是,吉家庙村的例子是目前正在经历转型的一个案例。如图7所示,吉家庙村被高楼环绕,它们陈旧的结构与现代景观不再协调。在2011年初,政策出台,逐步改造这些老旧建筑。因此,到2016年,它们的存在已经比2011年减少了。到2020年,它们几乎完全消失了。周围的绿色空间和高楼也在缓慢但稳定地发展。
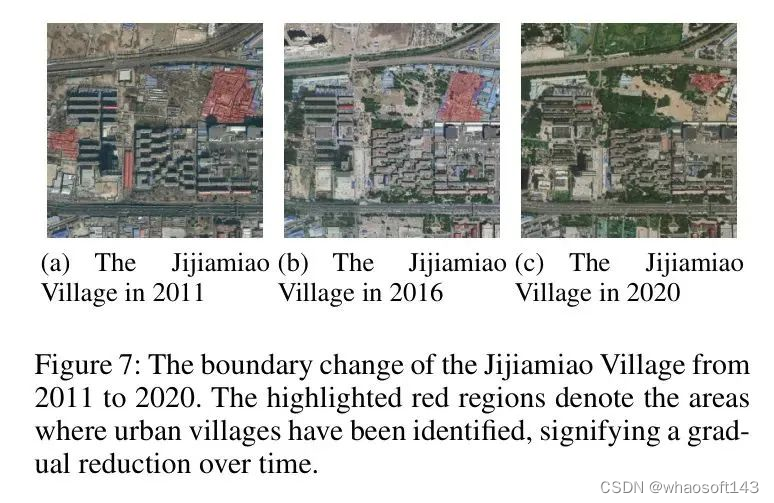
Conclusion
在本文中提出UV-SAM,一种基于视觉基础模型的城市村庄识别框架。UV-SAM框架引入了一个类似专家的语义分割模型,用于生成四种城市村庄特定的提示,然后将其输入到类似于通才的SAM模型中,以从卫星图像中识别城市村庄边界。通过全面的实验,作者在各种数据集上验证了UV-SAM的有效性,同时也为城市村庄的空间分布和时间趋势提供了深入的洞察。此外,作者的研究证明了视觉基础模型对于可持续发展目标和可持续城市的重要性。
尽管作者的结果超过了基准性能,但值得注意的是,作者的结果可能表现出一定程度的降低可解释性。因此,在未来的工作中,作者计划深入研究导致城市村庄出现和消失的复杂特征交互作用。作者还计划将所提出的框架转移到城市的贫民窟识别,以帮助理解全球非正规住区。
Experiment Details
Experiment Details for Spatial Distributions and Evolving Trends
在这里介绍了空间分布和演变趋势的预分类模块的详细信息。由于数据集的大小有限,作者引入了一个专门用于区分城市和非城市区域的二分类模型,在语义分割之前进行。该模块仅在特定城市的空间分析中应用,与作者的UV-SAM框架无关。
数据集。 对于训练分类模型,为每个特定城市构建一个数据集。城市村庄区域被用作正样本,非城市村庄区域被随机选择作为负样本,以确保训练、验证和测试集上的正负样本比例接近1:1。
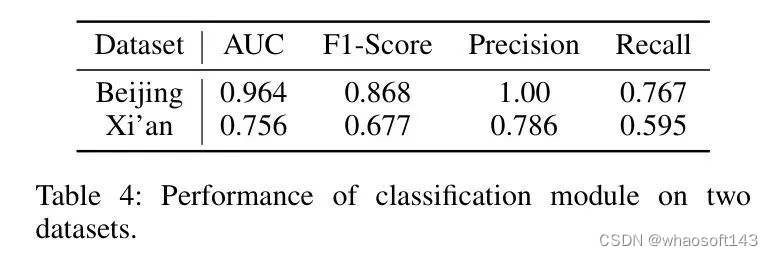
实现。 使用ResNet50实现分类模型。作者选择Adam优化器以促进参数学习,并集成余弦退火调度器以逐渐减小学习率。学习率设置为0.0001,批量大小固定为32。为了定量衡量分类模型的性能,作者采用AUC、召回率、精确度和F1-score作为评估指标。
性能。 表4显示了北京和西安数据集的性能。作者注意到,北京数据集在精确度方面取得了相当高的水平,而西安数据集的精确度明显较低。这种结果的巨大差异可以归因于多种因素的组合,尤其是西安数据集的范围有限以及可用卫星图像质量的固有差异。
Spatial Distribution Analysis with Street View Images in Beijing
由于收集街景图像的成本很高,作者只能将街景图像作为辅助工具来帮助观察城市村庄的演变。如图8所示,作者从石坝村的的历史保护区和城市村庄集群中分别选择了三个街景图像。这些图像旨在展示三种截然不同的城市村庄环境风格。

Evolving Trend with Street View Images in Beijing
如图9所示,作者在同一地点展示了不同年份的三个街景图像。与2013年城市村庄的混乱状况相比,该村庄在2015年被拆除。而在2019年,为了改善城市的外观,新墙被建成。

Spatial Distribution Analysis with Street View Images in Xi'an
在图10中,作者可视化了西安城市区域内城市村庄的空间分布,包括莲湖区、新城区、柏林区、雁塔区、八里坊区和渭阳区。在西安,历史保护区较少。如图所示,西安主要城市区域内的城市村庄呈现出明显的横向分布模式。值得注意的是,在西安的东部,靠近石狮子村附近有明显的城市村庄聚集。至于西安的中心区域,有几个城市村庄被识别出来,这可能是由于卫星图像质量较低导致的潜在误识别。
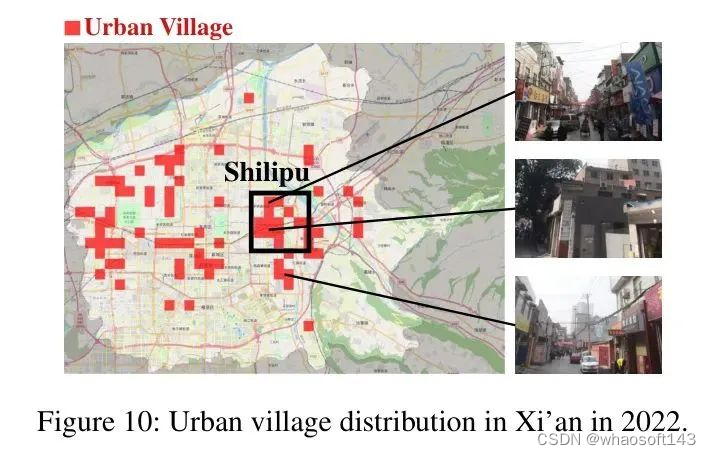
此外,作者绘制了分布曲线以直观地描绘空间分布模式。在图11中,展示了2022年西安城市区域内城市村庄的面积和数量与其距离市中心的关系。当距离市中心在7到11公里之间时,城市村庄的数量和面积呈现出急剧的线性增长。但是,在更大的距离上,增长速率变得不那么明显。这可以归因于城市扩张的快速过程所创建的"城市-郊区-农村"结构,其中大量城市村庄集中在郊区。
Evolving Trend in Xi'an
杨家村,位于明德门的遗址,由于其负担得起的租赁选项,成为了临时居民的受欢迎选择。2013年,政府计划拆除并改造该村庄。如图12所示,2018年杨家村的大部分地区被拆除。到2022年,杨家村的一部分被改造成高层建筑,而大部分则被开发成历史公园。

从图13中展示的杨家村的街景图像可以看出,该村庄早在2014年就开始进行改造。到2019年,高层建筑的出现变得明显。

#EfficientSAM
Meta 研究者提出了一种改进思路,利用 SAM 的掩码图像预训练 (SAMI)。这是通过利用 MAE 预训练方法和 SAM 模型实现的,以获得高质量的预训练 ViT 编码器。这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。借助MIM机制,MetaAI让SAM更高效,小模型也可以「分割一切」,Meta改进SAM,参数仅为原版5%
- 论文链接:https://arxiv.org/pdf/2312.00863.pdf
- 论文主页:https://yformer.github.io/efficient-sam/
名为EfficientSAM的模型,该模型通过利用遮罩图像预训练来提高图像分割的性能。作者使用了一个名为SAMI的方法,通过将SAM图像编码器的特征作为重建目标,从SAM图像编码器中重建特征,从而实现遮罩图像预训练。作者还使用SAMI预训练的轻量级图像编码器构建了EfficientSAM模型,并在SA-1B数据集上进行了验证。实验结果表明,EfficientSAM模型在图像分类、目标检测、实例分割和语义分割等任务中均取得了比其他预训练方法更好的性能。此外,作者还讨论了与遮罩图像预训练相关的方法和应用。
方案
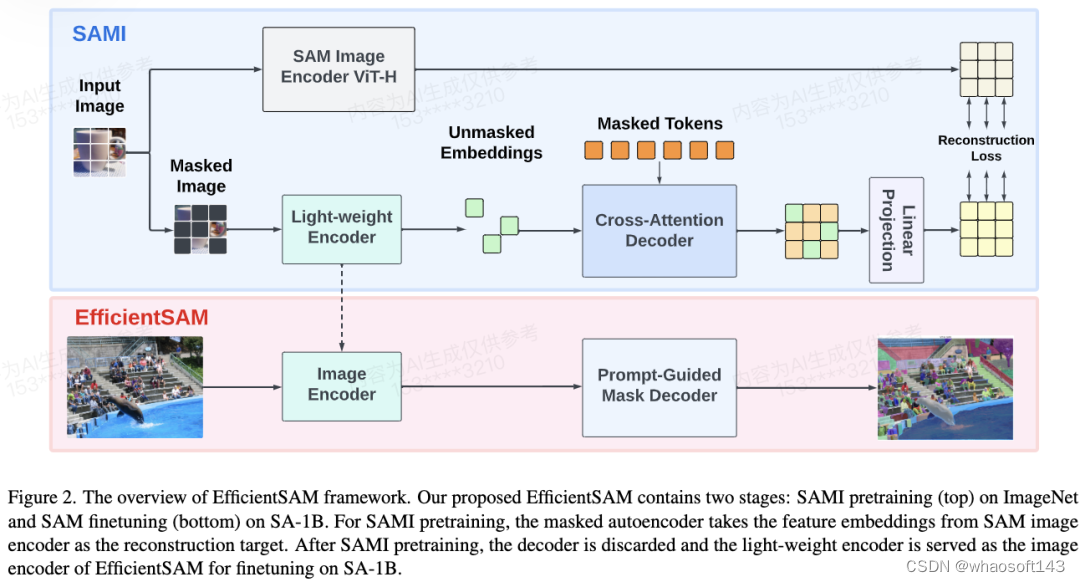
EfficientSAM 主要包含以下组件:
交叉注意力解码器:在 SAM 特征的监督下,本文观察到只有掩码 token 需要通过解码器重建,而编码器的输出可以在重建过程中充当锚点(anchors)。在交叉注意力解码器中,查询来自于掩码 token,键和值源自编码器的未掩码特征和掩码特征。本文将来自交叉注意力解码器掩码 token 的输出特征和来自编码器的未掩码 token 的输出特征进行合并,以进行 MAE 输出嵌入。然后,这些组合特征将被重新排序到最终 MAE 输出的输入图像 token 的原始位置。
线性投影头。研究者通过编码器和交叉注意力解码器获得的图像输出,接下来将这些特征输入到一个小型项目头(project head)中,以对齐 SAM 图像编码器中的特征。为简单起见,本文仅使用线性投影头来解决 SAM 图像编码器和 MAE 输出之间的特征维度不匹配问题。
重建损失。在每次训练迭代中,SAMI 包括来自 SAM 图像编码器的前向特征提取以及 MAE 的前向和反向传播过程。来自 SAM 图像编码器和 MAE 线性投影头的输出会进行比较,从而计算重建损失。
- Cross Attention Decoder 只有遮罩的标记需要通过解码器进行重构,而编码器的输出可以作为重构过程中的锚点。在交叉注意力解码器中,查询来自遮罩标记,键和值则来自编码器中的未遮罩特征和遮罩特征。然后,将来自交叉注意力解码器中遮罩标记的输出特征和来自编码器中未遮罩标记的输出特征进行合并,以生成MAE输出嵌入。最后,将合并后的特征重新排序到输入图像标记的原始位置,得到最终的MAE输出。
- Linear Projection Head 通过编码器和解码器获取图像输出,然后将特征输入到一个小型项目头(project head)以对齐来自SAM图像编码器的特征。为了简化,作者使用了线性投影头(linear projection head)来解决SAM图像编码器输出和MAE之间特征维度的 mismatch 问题.
- Reconstruction Loss 在每次训练迭代中,SAMI包括从SAM图像编码器进行的一次前馈特征提取,以及MAE的一次前馈和反向传播过程。通过比较SAM图像编码器和MAE线性投影头的输出,计算重构损失。
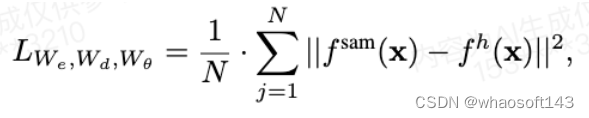
- SAMI for EfficientSAM.在预训练之后,我们的编码器提取各种视觉任务的特征表示,而解码器被丢弃。特别地,为了构建用于分割任何任务的 efficient SAM 模型,我们采用 SAMI 预训练的轻量级编码器(如 ViT-Tiny 和 ViT-Small)作为图像编码器,并使用 SAM 的默认遮罩解码器作为我们的 EfficientSAM 的解码器,如图 2(底部)所示。我们在 SA-1B 数据集上对 EfficientSAM 模型进行微调,以用于分割任何任务。
Segment Anything 的关键特征是基于提示的视觉 Transformer(ViT)模型,该模型是在一个包含来自 1100 万张图像的超过 10 亿个掩码的视觉数据集 SA-1B 上训练的,可以分割给定图像上的任何目标。这种能力使得 SAM 成为视觉领域的基础模型,并在超出视觉之外的领域也能产生应用价值。
尽管有上述优点,但由于 SAM 中的 ViT-H 图像编码器有 632M 个参数(基于提示的解码器只需要 387M 个参数),因此实际使用 SAM 执行任何分割任务的计算和内存成本都很高,这对实时应用来说具有挑战性。后续,研究者们也提出了一些改进策略:将默认 ViT-H 图像编码器中的知识提炼到一个微小的 ViT 图像编码器中,或者使用基于 CNN 的实时架构降低用于 Segment Anything 任务的计算成本。
在最近的一项研究中,Meta 研究者提出了另外一种改进思路 —— 利用 SAM 的掩码图像预训练 (SAMI)。这是通过利用 MAE 预训练方法和 SAM 模型实现的,以获得高质量的预训练 ViT 编码器。
这一方法降低了 SAM 的复杂性,同时能够保持良好的性能。具体来说,SAMI 利用 SAM 编码器 ViT-H 生成特征嵌入,并用轻量级编码器训练掩码图像模型,从而从 SAM 的 ViT-H 而不是图像补丁重建特征,产生的通用 ViT 骨干可用于下游任务,如图像分类、物体检测和分割等。然后,研究者利用 SAM 解码器对预训练的轻量级编码器进行微调,以完成任何分割任务。
为了评估该方法,研究者采用了掩码图像预训练的迁移学习设置,即首先在图像分辨率为 224 × 224 的 ImageNet 上使用重构损失对模型进行预训练,然后使用监督数据在目标任务上对模型进行微调。
通过 SAMI 预训练,可以在 ImageNet-1K 上训练 ViT-Tiny/-Small/-Base 等模型,并提高泛化性能。对于 ViT-Small 模型,研究者在 ImageNet-1K 上进行 100 次微调后,其 Top-1 准确率达到 82.7%,优于其他最先进的图像预训练基线。
研究者在目标检测、实例分割和语义分割上对预训练模型进行了微调。在所有这些任务中,本文方法都取得了比其他预训练基线更好的结果,更重要的是在小模型上获得了显著收益。
论文作者 Yunyang Xiong 表示:本文提出的 EfficientSAM 参数减少了 20 倍,但运行时间快了 20 倍,只与原始 SAM 模型的差距在 2 个百分点以内,大大优于 MobileSAM/FastSAM。
在 demo 演示中,点击图片中的动物,EfficientSAM 就能快速将物体进行分割:
EfficientSAM 还能准确标定出图片中的人:
本文实验
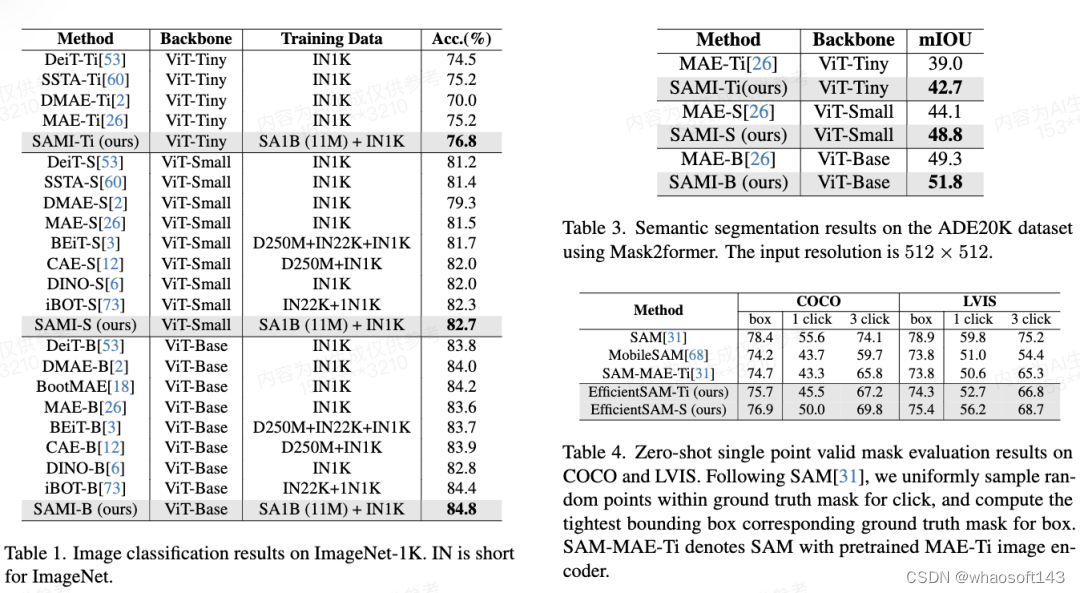

图像分类。为了评估本文方法在图像分类任务上的有效性,研究者将 SAMI 思想应用于 ViT 模型,并比较它们在 ImageNet-1K 上的性能。
如表 1 将 SAMI 与 MAE、iBOT、CAE 和 BEiT 等预训练方法以及 DeiT 和 SSTA 等蒸馏方法进行了比较。
SAMI-B 的 top1 准确率达到 84.8%,比预训练基线、MAE、DMAE、iBOT、CAE 和 BEiT 都高。与 DeiT 和 SSTA 等蒸馏方法相比,SAMI 也显示出较大的改进。对于 ViT-Tiny 和 ViT-Small 等轻量级模型,SAMI 结果与 DeiT、SSTA、DMAE 和 MAE 相比有显著的增益。
目标检测和实例分割。本文还将经过 SAMI 预训练的 ViT 主干扩展到下游目标检测和实例分割任务上,并将其与在 COCO 数据集上经过预训练的基线进行比较。如表 2 所示, SAMI 始终优于其他基线的性能。
这些实验结果表明,SAMI 在目标检测和实例分割任务中所提供的预训练检测器主干非常有效。
语义分割。本文进一步将预训练主干扩展到语义分割任务,以评估其有效性。结果如表 3 所示,使用 SAMI 预训练主干网的 Mask2former 在 ImageNet-1K 上比使用 MAE 预训练的主干网实现了更好的 mIoU。这些实验结果验证了本文提出的技术可以很好地泛化到各种下游任务。
表 4 将 EfficientSAMs 与 SAM、MobileSAM 和 SAM-MAE-Ti 进行比较。在 COCO 上,EfficientSAM-Ti 的性能优于 MobileSAM。EfficientSAM-Ti 具有 SAMI 预训练权重,也比 MAE 预训练权重表现更好。
此外, EfficientSAM-S 在 COCO box 仅比 SAM 低 1.5 mIoU,在 LVIS box 上比 SAM 低 3.5 mIoU,参数减少了 20 倍。本文还发现,与 MobileSAM 和 SAM-MAE-Ti 相比,EfficientSAM 在多次点击(multiple click)方面也表现出了良好的性能。
表 5 展示了零样本实例分割的 AP、APS、APM 和 APL。研究者将 EfficientSAM 与 MobileSAM 和 FastSAM 进行了比较,可以看到,与 FastSAM 相比,EfficientSAM-S 在 COCO 上获得了超过 6.5 个 AP,在 LVIS 上获得了 7.8 个 AP。就 EffidientSAM-Ti 而言,仍然远远优于 FastSAM,在 COCO 上为 4.1 个 AP,在 LVIS 上为 5.3 个 AP,而 MobileSAM 在 COCO 上为 3.6 个 AP,在 LVIS 上为 5.5 个 AP。
而且,EfficientSAM 比 FastSAM 轻得多,efficientSAM-Ti 的参数为 9.8M,而 FastSAM 的参数为 68M。
图 3、4、5 提供了一些定性结果,以便读者对 EfficientSAMs 的实例分割能力有一个补充性了解。
#EfficientViT-SAM
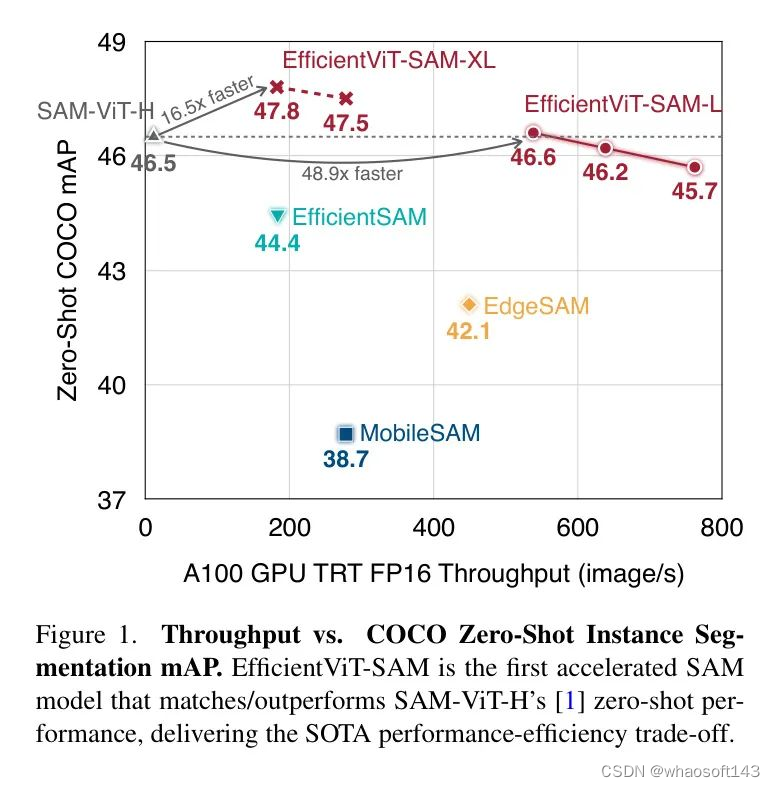
EfficientViT-SAM在性能和效率上显著优于所有之前的SAM模型。特别是,在COCO数据集上,与SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上实现了48.9倍的吞吐量提升,而mAP没有下降。
论文链接:https://arxiv.org/abs/2402.05008
作者提出了EfficientViT-SAM,这是一系列加速的SAM模型。在保留SAM轻量级的提示编码器和 Mask 解码器的同时,作者用EfficientViT替换了沉重的图像编码器。在训练方面,首先从SAM-ViT-H图像编码器向EfficientViT进行知识蒸馏。随后,在SA-1B数据集上进行端到端的训练。得益于EfficientViT的高效性和容量,EfficientViT-SAM在A100 GPU上实现了48.9的TensorRT速度提升,而且没有牺牲性能。
代码和预训练:https://github.com/mit-han-lab/efficientvit
1 Introduction
Segment Anything Model (SAM) 是一系列在高质量数据集上预训练的图像分割模型,该数据集包含1100万张图片和10亿个 Mask 。SAM 提供了惊人的零样本图像分割性能,并在许多应用中都有用途,包括增强现实/虚拟现实、数据标注、交互式图像编辑等。
尽管性能强大,但SAM的计算量非常大,这在时间敏感的情境中限制了其适用性。特别是,SAM的主要计算瓶颈在于其图像编码器,在推理时每张图像需要2973 GMACs。
为了加速SAM,已经进行了许多尝试,用轻量级模型替换SAM的图像编码器。例如,MobileSAM 将SAM的ViT-H模型的知识蒸馏到一个小型视觉 Transformer 中。EdgeSAM 训练了一个纯基于CNN的模型来模仿ViT-H,并采用了一种细致的蒸馏策略,过程中涉及到提示编码器和 Mask 解码器。EfficientSAM 利用MAE预训练方法来提高性能。
尽管这些方法可以降低计算成本,但它们都存在显著的性能下降(图1)。本文引入了EfficientViT-SAM来解决这一限制,通过利用EfficientViT来替换SAM的图像编码器。同时,作者保留了SAM的轻量级提示编码器和 Mask 解码器架构。作者的训练过程包括两个阶段。首先,作者使用SAM的图像编码器作为教师来训练EfficientViT-SAM的图像编码器。其次,作者使用整个SA-1B数据集端到端地训练EfficientViT-SAM。
作者全面评估了EfficientViT-SAM在一系列零样本基准测试上的表现。EfficientViT-SAM在性能和效率上显著优于所有之前的SAM模型。特别是,在COCO数据集上,与SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上实现了48.9倍的吞吐量提升,而mAP没有下降。
2 Related Work
Segment Anything Model
SAM 在计算机视觉领域已经获得广泛认可,作为该领域的一个里程碑,它在图像分割方面展示了卓越的性能和泛化能力。SAM 将图像分割定义为可提示的任务,旨在给定任何分割提示时生成有效的分割 Mask 。为了实现这一目标,SAM 使用图像编码器和提示编码器来处理图像并提供提示。两个编码器的输出随后被送入 Mask 解码器,该解码器生成最终的 Mask 预测。
SAM 在一个大规模的分割数据集上进行训练,该数据集包含超过1100万张图像和超过10亿个高质量 Mask ,这使得它能够在零样本开放世界分割中表现出强大的能力。SAM 在各种下游应用中展示了其高度的适应性,包括图像修复、目标跟踪和3D生成。然而,SAM的图像编码器组件带来了显著的计算成本,导致高延迟,限制了在时间敏感场景中的实用性。最近的工作集中在提高SAM的效率,旨在解决其计算限制。
Efficient Deep Learning Computing
提高深度神经网络的效率在边缘和云计算平台上的实际应用中至关重要。作者的工作与有效的模型架构设计相关,旨在通过用高效的模型架构替换低效的模型架构来改善性能与效率之间的权衡。作者的工作还与知识蒸馏相关,该方法利用预训练的教师模型指导学生模型的训练。此外,作者可以将EfficientViT-SAM与其他并行技术结合,以进一步提高效率,包括剪枝、量化和硬件感知神经架构搜索。
3 Method
作者提出了EfficientViT-SAM,该方法利用EfficientViT来加速SAM。特别是,EfficientViT-SAM保留了SAM的提示编码器和 Mask 解码器架构,同时用EfficientViT替换了图像编码器。作者设计了两系列模型,EfficientViT-SAM-L和EfficientViT-SAM-XL,它们在速度和性能之间提供了平衡。随后,作者以端到端的方式使用SA-1B数据集来训练EfficientViT-SAM。
EfficientViT
EfficientViT 是一系列用于高效高分辨率密集预测的视觉 Transformer 模型。其核心构建模块是一个多尺度线性注意力模块,它通过硬件高效的运算实现了全局感受野和多尺度学习。
具体来说,它用轻量级的ReLU线性注意力替代了效率低下的softmax注意力,以拥有全局感受野。通过利用矩阵乘法的结合性质,ReLU线性注意力可以在保持功能的同时,将计算复杂度从二次降低到一次。此外,它还通过卷积增强了ReLU线性注意力,以减轻其在局部特征提取上的局限性。更多细节可在原论文中找到。
EfficientViT-SAM
模型架构。 EfficientViT-SAM-XL的宏观架构如图2所示。其主干包含五个阶段。类似于EfficientViT,作者在早期阶段使用卷积块,而在最后两个阶段使用efficientViT模块。作者通过上采样和加法融合最后三个阶段的特征。融合后的特征被送入由几个融合的MBConv块组成的 Neck ,然后送入SAM Head 。
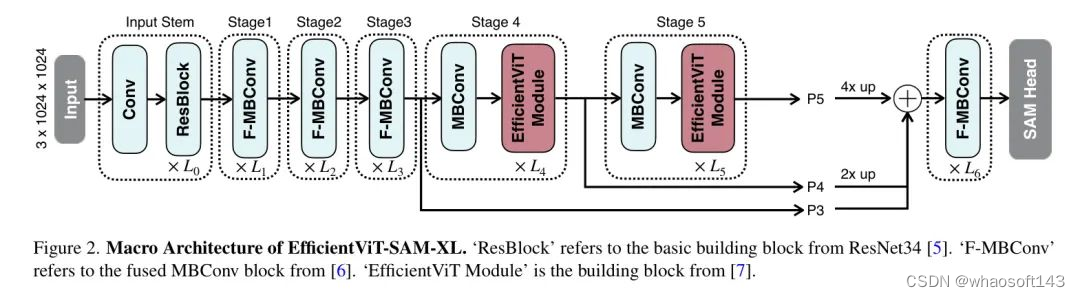
训练。 为了初始化图像编码器,作者首先将SAM-ViT-H的图像嵌入信息蒸馏到EfficientViT中。作者采用L2损失作为损失函数。对于提示编码器和 Mask 解码器,作者通过加载SAM-ViT-H的权重来初始化它们。然后,作者以端到端的方式在SA-1B数据集上训练EfficientViT-SAM。
在端到端的训练阶段,作者以相等的概率随机选择框提示和点提示。在点提示的情况下,作者从真实 Mask 中随机选择1-10个前景点,以确保作者的模型能够有效应对各种点配置。在框提示的情况下,作者使用真实边界框。对于EfficientViT-SAM-L/XL模型,作者将最长边调整至512/1024,并相应地填充较短边。作者每张图像选择多达64个随机采样的 Mask 。
为了监督训练过程,作者使用Focal Loss和骰子损失的线性组合,Focal Loss与骰子损失的比例为20:1。类似于SAM中采用的消除歧义的方法,作者同时预测三个 Mask ,并且只反向传播损失最低的那个。作者还通过添加第四个输出Token来支持单一 Mask 的输出。在训练期间,作者随机交替使用两种预测模式。
作者使用SA-1B数据集对EfficientViT-SAM进行了2个周期的训练,批量大小为256。采用AdamW优化器,动量参数设为0.9,设为0.999。初始学习率对于EfficientViT-SAM-L/XL分别设定为2e/1e,并使用余弦衰减学习率计划将其降低至0。在数据增强方面,作者应用了随机水平翻转。
4 Experiment
在本节中,作者在4.1节中对EfficientViT-SAM的运行时效率进行了全面分析。随后,作者在COCO 和 LVIS 数据集上评估了EfficientViT-SAM的零样本能力,这些数据集在训练过程中未曾遇到。作者执行了两项不同的任务:4.2节中的单点有效 Mask 评估以及4.3节中的边界框提示实例分割。这些任务分别评估了EfficientViT-SAM的点提示和边界框提示特征的有效性。此外,作者在4.4节还提供了SGlnW基准测试的结果。
Runtime Efficiency
作者比较了EfficientViT-SAM与SAM及其他加速工作的模型参数、MACs和吞吐量。结果展示在表1中。作者在单个NVIDIA A100 GPU上进行了吞吐量的测量,并使用了TensorRT优化。
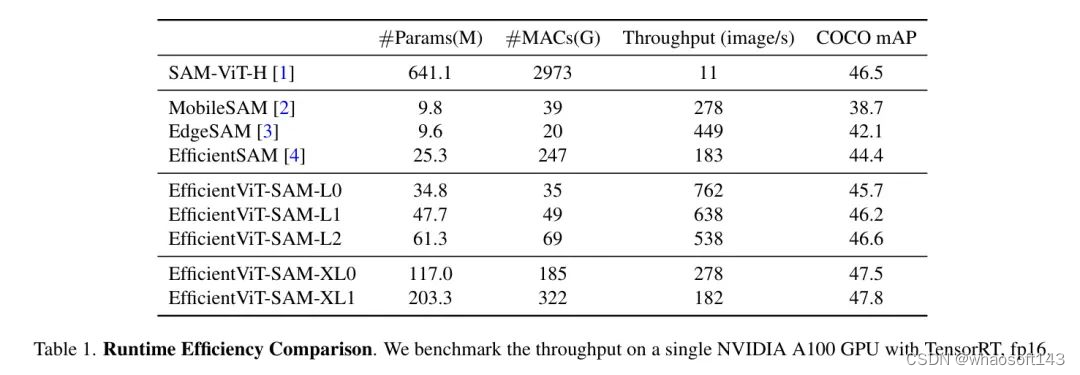
作者的结果显示,与SAM相比,作者实现了令人印象深刻的17到69倍的加速。此外,尽管EfficientViT-SAM的参数数量多于其他加速工作,但由于其有效地利用了硬件友好的运算符,因此其吞吐量显著提高。
Zero-Shot Point-Prompted Segmentation
作者在表2中评估了基于点提示对目标进行分割时EfficientViT-SAM的零样本性能。作者采用了文献[1]中描述的点选择方法。即初始点被选为距离目标边界最远的点。后续的每个点都选为距离错误区域边界最远的点,该错误区域被定义为真实值和先前预测之间的区域。
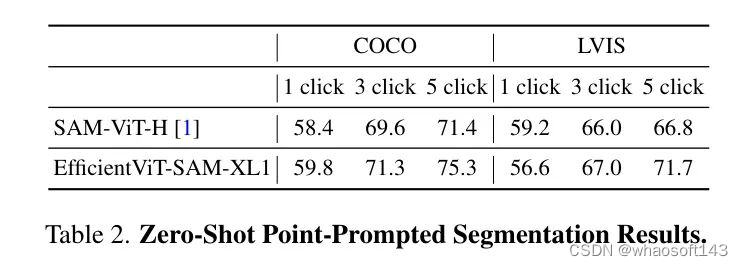
作者在COCO和LVIS数据集上使用1/3/5次点击报告性能,以mIoU(平均交并比)作为评价指标。作者的结果显示,与SAM相比,性能更优,尤其是在提供额外点提示时。
Zero-Shot Box-Prompted Segmentation
作者评估了EfficientViT-SAM在利用边界框进行目标分割中的零样本性能。首先,作者将真实边界框输入到模型中,结果展示在表4中。
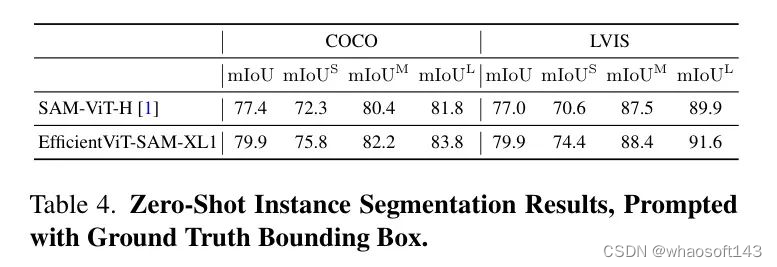
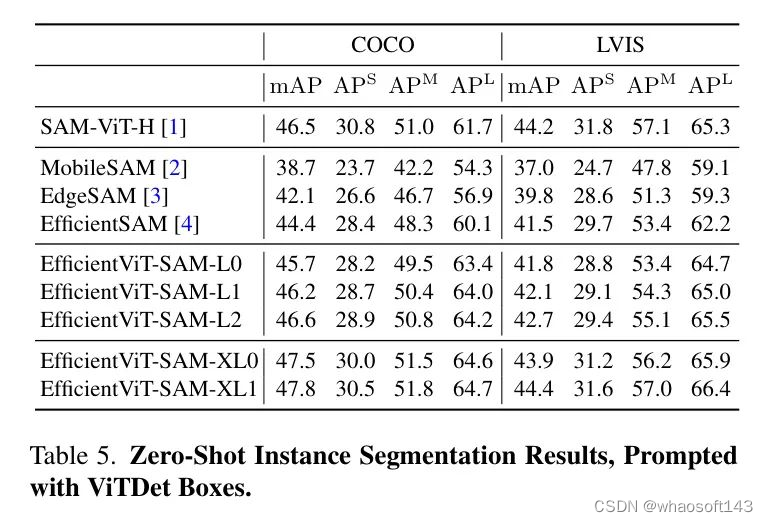
所有目标都报告了mIoU(平均交并比),并且分别为小型、中型和大型目标分别报告。EfficientViT-SAM在COCO和LVIS数据集上显著超过了SAM。接下来,作者采用一个目标检测器ViT-Det,并使用其输出框作为模型的提示。表5的结果显示,EfficientViT-SAM相比于SAM取得了更优的性能。值得注意的是,即使是EfficientViT-SAM的最轻版本,也显著优于其他加速工作。
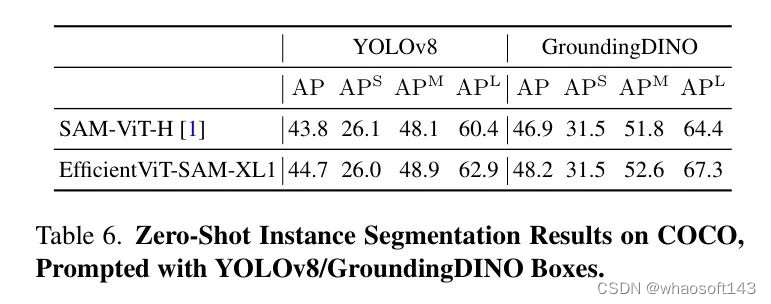
另外,作者使用YOLOv8和GroundingDINO 作为目标检测器,在COCO数据集上评估了EfficientViT-SAM的性能。YOLOv8是一种实时目标检测器,适用于实际应用场景。另一方面,GroundingDINO能够使用文本提示来检测目标,这使得作者可以基于文本线索进行目标分割。表6中展示的结果表明,EfficientViT-SAM相比于SAM具有卓越的性能。
Zero-Shot In-the-Wild Segmentation
野外分割基准包含25个零样本野外分割数据集。作者将EfficientViT-SAM与Grounding-DINO结合,作为框提示,执行零样本分割。每个数据集的全面性能结果在表3中展示。SAM达到48.7的mAP,而EfficientViT-SAM获得了更高的48.9分。
Qualitative Results.
图3展示了当提供点提示、框提示以及SAM模式时,EfficientViT-SAM的定性分割结果。结果显示,EfficientViT-SAM不仅在分割大型物体上表现出色,也能有效处理小型物体。这些发现强调了EfficientViT-SAM卓越的分割能力。

5 Conclusion
在这项工作中,作者引入了EfficientViT-SAM,它使用EfficientViT来替代SAM的图像编码器。EfficientViT-SAM在无需牺牲各种零样本分割任务性能的情况下,显著提高了SAM的效率。
#SAM-LSTSAM-LST
本文提出的方法能够灵活地集成额外的网络,同时避免在整个大模型(即SAM编码器)上进行反向传播,从而加快了训练速度并降低了资源成本。两张3090显卡就可以玩起来医疗SAM-LST大模型
最近,引入了基于计算机视觉领域的各种任务的基础模型。这些模型,比如Segment Anything Model (SAM),是使用大规模数据集进行训练的通用模型。目前,正在进行的研究聚焦于探索如何有效地利用这些通用模型应用于特定领域,比如医学影像。
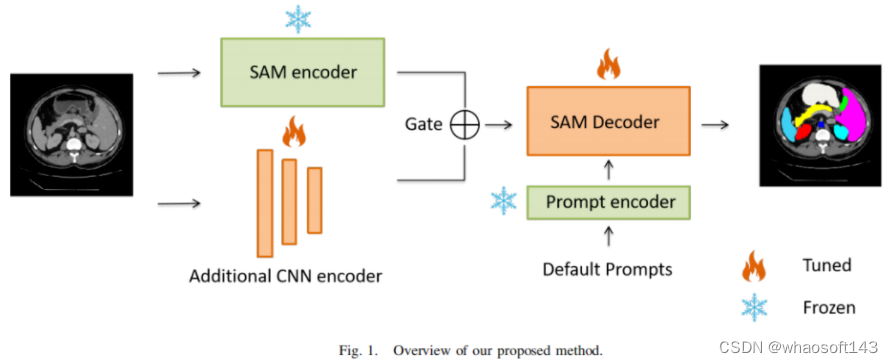
然而,在医学影像领域,由于隐私问题和其他因素导致缺乏训练样本,这对将这些通用模型应用于医学图像分割任务构成了重大挑战。为了解决这个问题,有效地微调这些模型对于确保它们的最佳利用至关重要。在本研究中提出结合一个互补的卷积神经网络(CNN)和标准的SAM网络进行医学图像分割。为了减轻对大型基础模型进行精细调整的负担并实现成本高效的训练方案,本文仅集中于对额外的CNN网络和SAM解码器部分进行微调。这种策略显著减少了训练时间,并在公开可用的数据集上取得了竞争性的结果。
代码:https://github.com/11yxk/SAM-LST
医学图像分割在医疗保健领域中起着至关重要的作用。它旨在使用各种医学成像模态(如X射线、CT扫描、MRI扫描或超声图像)对肝脏、脑部和病变等各种人体器官进行分割。因此,它在诊断、治疗计划和治疗后监测方面对临床医生有很大帮助。
在过去的十年中,卷积神经网络(CNN)在计算机视觉任务中变得流行起来。最近,Long等人提出了全卷积网络(FCN)。这种方法通过用卷积层替换全连接层,使得能够处理任意大小的输入图像并生成分割结果。U-Net是由Ronneberger等人开发的用于医学图像分割的最广泛使用的架构。它包括一个编码器和一个解码器,并且在相应层之间有Shortcut以保留重要的特征。编码器路径对输入图像进行下采样,同时捕捉High-Level特征。而解码器路径则对特征图进行上采样以预测分割结果。Zhou等人通过引入嵌套的Shortcut方案扩展了U-Net架构,这允许捕捉多尺度的上下文信息和更好地集成不同Level的特征。Chen等人提出了Deeplab系列模型,其中包括空洞卷积操作和全连接的条件随机场的概念。
最近,Transformer已经被引入到计算机视觉(CV)领域,它最初是为自然语言处理(NLP)而设计的。与传统的CNN架构相比,Transformer可以捕捉到远程依赖关系。多索维茨基等提出了基于自注意力机制的图像分类视觉Transformer(ViT)。随后,Chen等人提出了使用ViT进行分割任务的TransUNet。TransUNet联合利用CNN和ViT从输入图像中获取局部和全局上下文特征。Tang等人提出了采用ViT模型作为特征提取的主要编码器的Swin UNETR。Zhou等人提出了一个纯Transformer框架,它在编码器和解码器部分都使用ViT。Cao等人提出了采用双Transformer架构进行分割任务的双-unet。
目前,基础模型在自然语言处理领域已经证明了其能力。目前,SAM被引入用于各种计算机视觉任务。在SAM中,使用基础模型的prompt学习的概念可以在看不见的图像上执行多个任务。它允许通过有效的prompt工程将zero-shot转移到各种任务中。虽然将SAM模型直接应用于特定领域的任务,如医学图像分割,通常不能产生令人满意的性能。尽管SAM使用的是超过1100万张图像和10亿张GT Mask,但由于医学图像与真实图像相比的独特特征,其在医学图像分割中的应用带来了挑战。此外,医疗数据的缺乏也是调整SAM的一个主要问题。因此,对医学图像数据集的SAM进行有效的微调是非常必要的。
如今,已经引入了各种微调方法来优化在不同领域中的SAM。一些方法对SAM网络进行基于适配器的微调。然而,这些基于适配器的方法通常需要大量的训练模型的工作和资源成本。与以往的研究不同,本文的工作通过在SAM架构中结合一个额外的CNN作为补充编码器,引入了一种新颖的方法。
本文的方法受到了用于Transformer的Ladder-Side Tuning (LST)网络的启发。本文提出的方法能够灵活地集成额外的网络,同时避免在整个大模型(即SAM编码器)上进行反向传播,从而加快了训练速度并降低了资源成本。额外的CNN网络可以根据具体任务需求轻松替换为其他设计,包括基于Transformer的设计。
本文将预训练的ResNet18作为额外的网络进行了融合。在训练过程中,只有额外的CNN和解码器部分的参数进行微调,而保持原始的SAM编码器参数不变。
本文的贡献可以总结如下:
- 本文提出了在医学图像分割任务中,结合额外的CNN进行SAM微调的方法;
- 所提出的方法在设计额外网络时提供了灵活性,同时通过避免在整个模型上进行反向传播来最大程度地减少资源成本;
- 在一个公开可用的多器官分割数据集上,本文的方法在不使用任何prompt的情况下取得了与最先进方法相媲美的结果。
医学图像分割
精确可靠的医学图像分割对于辅助医学诊断至关重要。在过去的几年中,已经提出了许多分割方法。特别是基于CNN的网络在这个任务中取得了显著的成功。最近,一些基于Transformer的High-Level网络也被提出来,在这个任务中取得了新的里程碑。尽管在医学图像分割方面取得了显著进展,但由于数据有限和需要临床专家对数据进行注释的要求等因素,它仍然是一个具有挑战性的任务。这些因素通常导致模型的泛化能力较差。
基础模型
基础模型是指在广泛数据上训练并可适应各种下游任务的模型。这种范式通常包含一些其他技术,比如自监督学习、迁移学习和prompt学习。一个基础模型的例子是生成式预训练Transformer (GPT) 系列,这些模型在来自各种来源的大量文本数据上进行了预训练。这些模型在自然语言处理 (NLP) 的进展中做出了重大贡献。
具体而言,GPT-3是其中一个参数达到1750亿的大型语言模型 (LLM),可以应用于广泛的任务,包括翻译、问答和完形填空等。另一个值得注意的工作是对比语言图像预训练 (CLIP) ,它使用了一组大规模的带有图像和相应文本描述的数据集。CLIP能够根据给定的文本prompt有效地检索图像,这在图像分类和图像生成等领域有许多应用。这些基础模型已经取得了最先进的性能。它们在各个领域的发展方向广阔。
Parameter-Efficient Fine-Tuning
尽管基础模型取得了显著的成就,但它们仍然面临一些限制,比如需要大量标记数据进行训练和庞大的计算资源需求,这归因于它们巨大的参数数量。
为了降低巨大的计算成本,引入了参数高效微调(PEFT)的方法,通过训练现有模型中的一小部分参数或在架构中训练新添加的参数。Houlsby等人提出在原始基础模型中添加一个小的子网络,称为“适配器”。Lester等人提出在原始模型输入之前添加一个可训练的张量。Sung等人引入了一种新颖的阶梯侧调整(LST)范式,仅对原始模型旁边嵌入的一个小型Transformer网络进行微调。
在这种架构设计中,只更新新添加网络的参数以节省计算成本。Ben-Zaken等人建议仅训练原始网络的偏置,这也是一种简单而有效的方法。总体而言,基于PEFT的方法对GPU友好,在有限的计算资源下可以应用基础模型于各种下游任务中。
方法
Segment Anything Model
Segment Anything Model(SAM)是基础模型在分割任务中的首次尝试。SAM由3个组件构成:
- image编码器
- prompt编码器
- mask解码器
image编码器采用了MAE 预训练的ViT网络来提取图像特征。
prompt编码器支持4种类型的prompt输入:点、框、文本和Mask。点和框通过位置编码进行嵌入,而文本则使用CLIP中的文本编码器进行嵌入。Mask则使用卷积操作进行嵌入。
Mask解码器以轻量级的方式将图像嵌入和prompt嵌入进行映射。这两种嵌入类型通过交叉注意力模块进行交互,其中一个嵌入作为query向量,而另一个嵌入作为key向量和value向量。最后,使用转置卷积来上采样特征。Mask解码器具有生成多个结果的能力,因为提供的prompt可能存在歧义。默认输出数量设置为三个。
值得一提的是,image编码器只需对每个输入图像提取一次图像特征。之后,轻量级的prompt编码器和Mask解码器可以根据不同的输入prompt在Web浏览器中与用户实时交互。
SAM使用超过1100万张图像和10亿个Mask进行训练。实验结果表明其出色的零样本迁移能力。正如其名称所暗示的,该模型几乎可以分割任何东西,甚至是以前未见过的情况(未知的测试样本)。
Ladder-Side Tuning with SAM
在这里,本文描述了本文提出的方案和集成网络。概述如图1所示。为了有效地应用于医学图像分割任务的SAM模型,本文建议添加一个轻量级的侧网络,同时避免通过整个SAM模型进行反向传播。


损失函数本文使用交叉熵损失和Dice损失的组合来对网络进行微调。
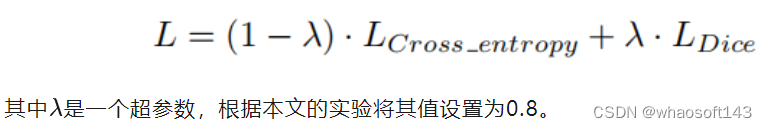
实验
数据集
本文使用Synapse数据集进行评估,这是MICCAI 2015多图谱腹部标记挑战的一个公开可用的多器官分割数据集。它包括30个腹部CT扫描。根据之前的工作,总共使用18个案例进行训练,12个案例用于测试。本文以Dice相似系数(DSC)和95% Hausdorff距离(HD95)的指标报告在8个腹部器官(即主动脉、胆囊、脾脏、左肾、右肾、肝脏、胰腺、胃)上的结果。
实施细节
输入图像的分辨率设置为224×224。本文使用随机旋转和翻转操作进行数据增强。本文使用ViT-B SAM模型作为基础Backbone模型。本文不微调SAM编码器和prompt编码器,而只微调SAM解码器的“输出上采样”部分,以避免过拟合。集成的CNN编码器在PyTorch Torchvision库提供的ImageNet上进行了预训练。该框架使用批量大小为24的Adam优化器进行200个epochs训练。学习率设置为0.001。在前250个迭代中采用了warmup策略。实验使用了2个RTX 3090显卡进行。
实验结果
表I报告了实验结果,并与其他最先进的方法进行了比较。本文提出的方法实现了79.45%的DSC和35.35mm的HD95分数。本文还观察到可学习权重参数的值为0.44。本文的方法在超过大多数最先进方法的同时取得了竞争性的得分。
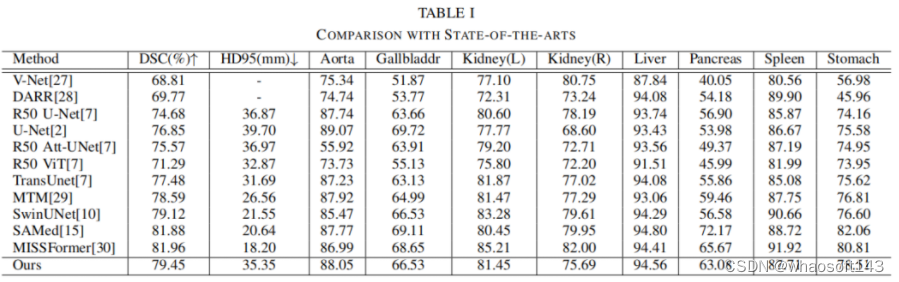
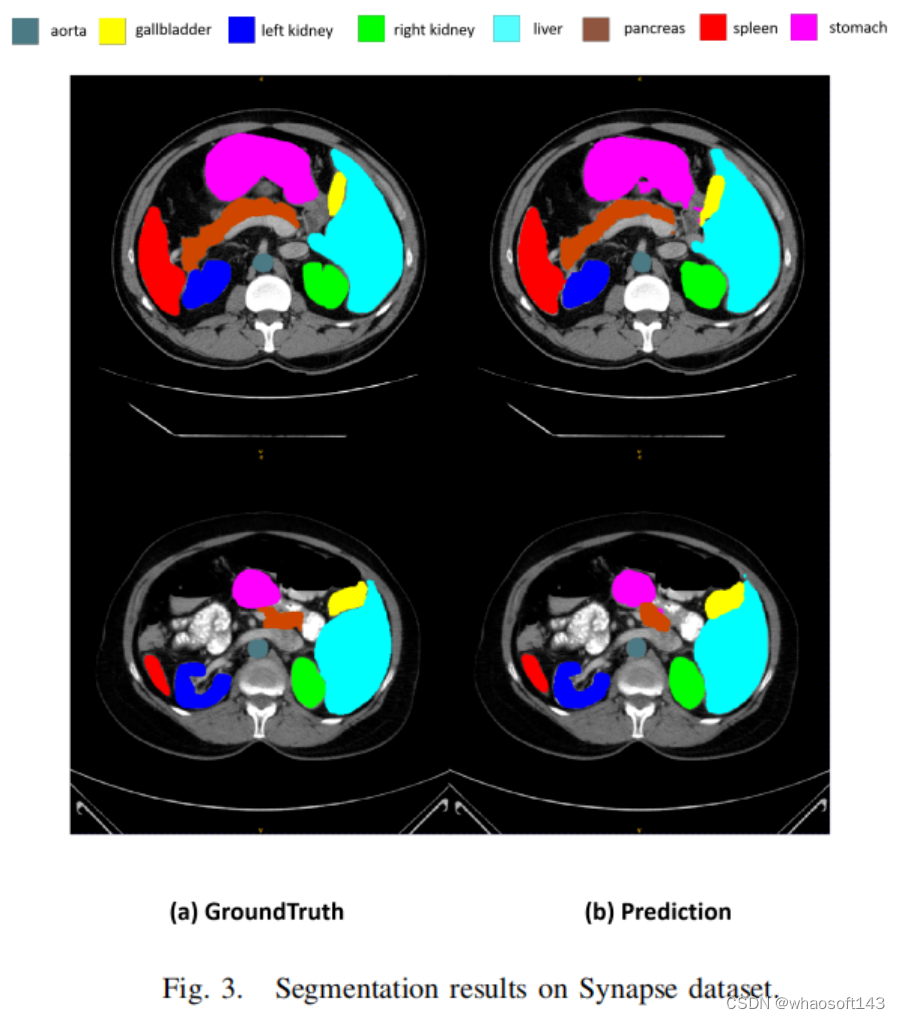
图3展示了一些分割结果。然而,集成CNN编码器和可学习权重参数的设计可以进行修改,以分析和评估所提出方法的性能。本文相信利用Transformer或其他有效的网络设计将会获得更高的性能。在未来,本文将探索更先进的设计选择,以达到最佳结果。
消融实验本文进行了消融实验来评估将CNN编码器与SAM编码器集成的有效性。
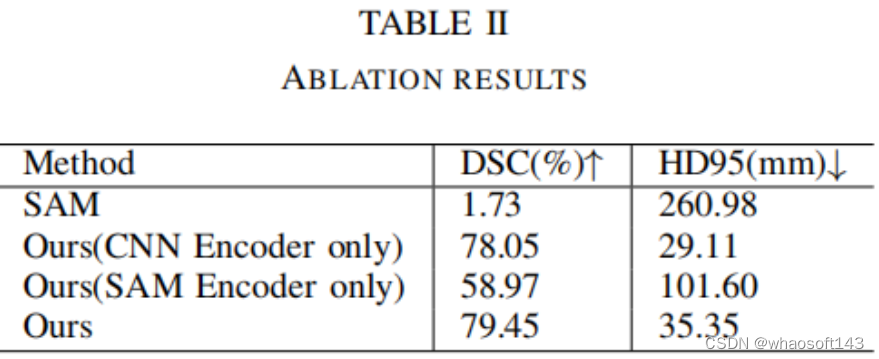
表II表明,SAM模型在没有对医学图像进行微调的情况下,仅实现了1.73%的Dice分数。需要注意的是,在此训练和评估过程中没有使用prompt,因此由于直接应用了通用模型,得分较低。通过对整个SAM应用微调方法,准确性提高到58.97的Dice分数。同样,当将CNN编码器与SAM解码器模块相结合时,性能保持在78.05的Dice分数。这凸显了有效微调方法的必要性。
然而,通过将CNN编码器与SAM网络集成并利用可学习的门(权重参数),准确性显著提高至79.45的Dice分数。此外,本文还观察到训练时间显著减少,与其他微调方法相比,减少了约30%到40%。本文提出的方法在资源利用方面更具成本效益。
#SAM-CLIP
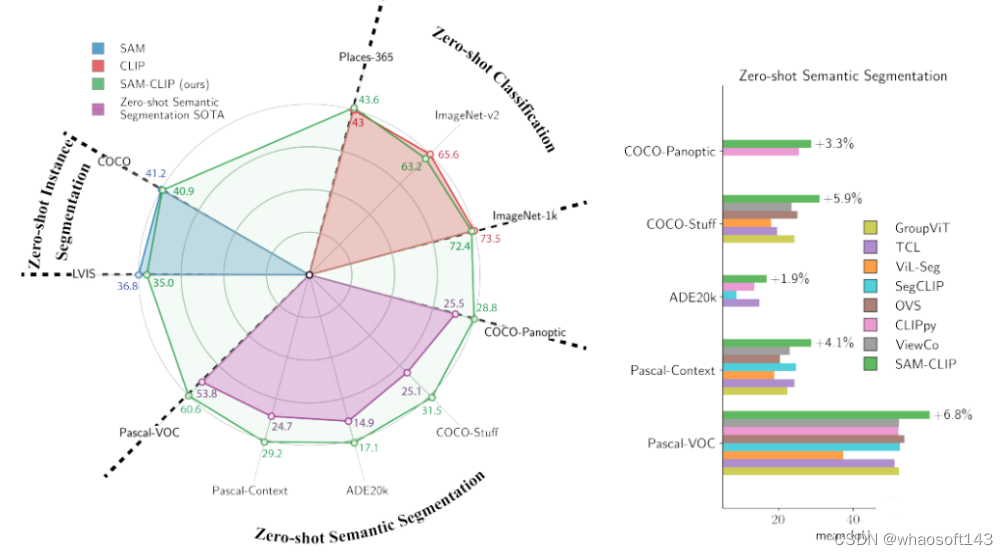
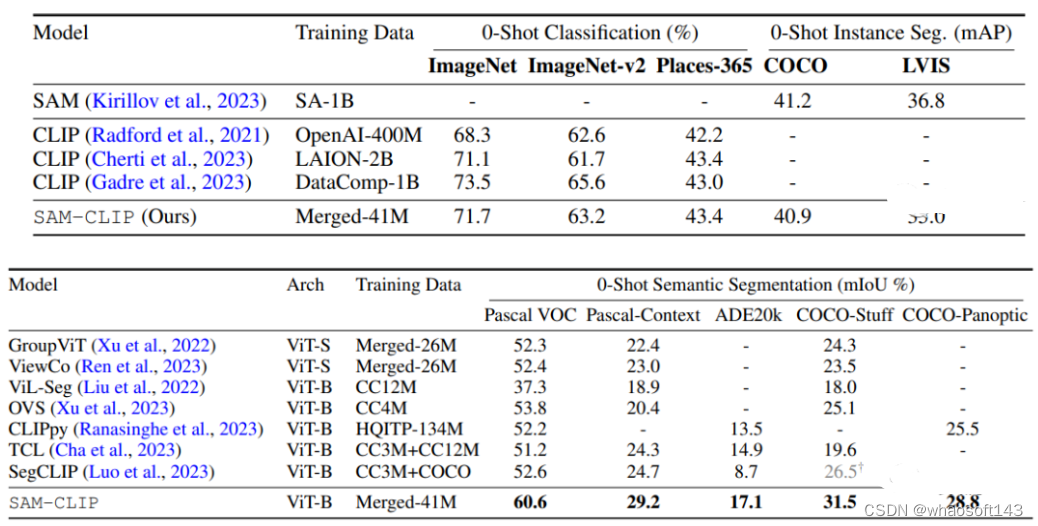
本研究提出了一种简单的方法,通过多任务学习、持续学习技术和教师-学生蒸馏,将视觉基础模型(VFMs)合并成一个统一的模型,以融合它们的专长。通过将这种方法应用于SAM和CLIP,我们得到了SAM-CLIP:一个将SAM和CLIP的优势融合到一个单一骨干中的统一模型,适用于边缘设备应用。SAM-CLIP在多个头部探测任务上表现出更好的性能,并在零样本语义分割任务上取得了新的最先进结果。
论文链接:https://arxiv.org/pdf/2310.15308.pdf
公开可用的视觉基础模型(VFMs)的领域正在迅速扩大,这些模型具有不同的能力,如语义理解和空间理解。然而,为不同的下游任务维护和部署单独的模型效率低下且缺乏跨模型学习的机会。
多任务学习是解决这个问题的一种方法,但通常需要昂贵的训练和同时访问所有任务的资源。此外,训练VFMs通常依赖于无监督或半监督方法,需要大量的计算资源。模型合并已经成为一个快速发展的研究领域,但大多数合并技术集中在将多个任务特定模型合并成一个模型,而不需要额外的训练。这些技术在不使用数据或不进行额外训练/微调的情况下,导致性能下降或无法推广到多样化的任务集。
这种模型合并方法,通过从持续学习和知识蒸馏中借鉴技术,将两个具有不同目标和能力的VFMs合并成一个统一的模型。这种方法不仅比传统的多任务训练要求更少的数据和计算成本,还能保留原始模型的知识,并在新任务上展现出更好的性能。
方法
本文使用 SAM 作为 基础VFM,而CLIP模型作为辅助VFM,这对模型呈现出一个有趣的组合,因为这两种模型都已成功部署在不同的任务中,并且表现出互补性 能力。SAM 在定位和高分辨率图像分割方面表现出色,但也有局限性 在语义理解上。相反,CLIP 为语义理解提供了强大的图像骨干。

总的来说,基础 VFM SAM 有一个图像编码器 (EncSAM)、提示编码器 (PromptEncSAM) 和光掩模解码器 (MaskDecSAM)。辅助 VFM CLIP 具有图像编码器 (EncCLIP) 和文本编码器 (TextEncCLIP)。我们的 目标是将两个图像编码器合并到一个名为 EncSAM-CLIP 的主干中,该主干已初始化 由 EnCSAM 提供。进一步,我们考虑每个VFM 对应的轻量级头,即HeadSAM 和 HeadCLIP。HeadSAM 使用 MaskDecSAM 初始化, HeadCLIP 使用 random 初始化 权重 (因为 CLIP 没有配备我们可以部署的头部)。我们部署其他方式 编码器 (即 PromptEncSAM 和 TextEncCLIP) 没有变化 (冻结)。

实验结果
使用的模型架构是Segment Anything Model(SAM)的ViT-B/16版本,具有12个Transformer层。对于CLIP蒸馏,将CC3M、CC12M、YFCC-15M和ImageNet-21k数据集的图像合并成训练数据集。对于SAM自蒸馏,使用SA-1B数据集的子集。训练分为两个阶段,模型的不同组件使用不同的学习率。CLIP蒸馏使用可变分辨率的224/448px,SAM蒸馏使用1024px的分辨率。
Zero-Shot指标结果
可视化结果

#RepViT-SAM
SAM轻量化的终点竟然是RepViT + SAM,移动端速度可达38.7fps。
对于 2023 年的计算机视觉领域来说,「分割一切」(Segment Anything Model)是备受关注的一项研究进展。尽管SAM具有各种优势,但速度慢是其不得不提的一个缺点,端侧根本就跑不动。研究者们也提出了一些改进策略:将默认 ViT-H 图像编码器中的知识提炼到一个微小的 ViT 图像编码器中,或者使用基于 CNN 的实时架构降低用于 Segment Anything 任务的计算成本。
就在今日,arXiv上同时公开两篇SAM轻量化的方法EdgeSAM、RepViT-SAM,更巧合的是两者采用了完全相同的Image Encoder模块:RepViT;两者也都在手机端达到了超快处理速度,值得一提的是:EdgeSAM能在iphone14手机上达到38.7fps的处理速度。
https://arxiv.org/abs/2312.05760 https://github.com/THU-MIG/RepViT
该方案延续了MobileSAM的处理方式,即采用原生SAM的ViT Encoder模块对所替换的Encoder模块进行知识蒸馏。
- 在实现方面,RepViT-SAM引入了移动端新秀[RepViT]的RepViT-M2.3作为图像编码器提取图像特征;
- 在老师模型方面,它选用了SAM-ViT-H版本进行蒸馏。
- 在应用方面,该方案进行了多种任务适配,如Mask预测、边缘检测等。

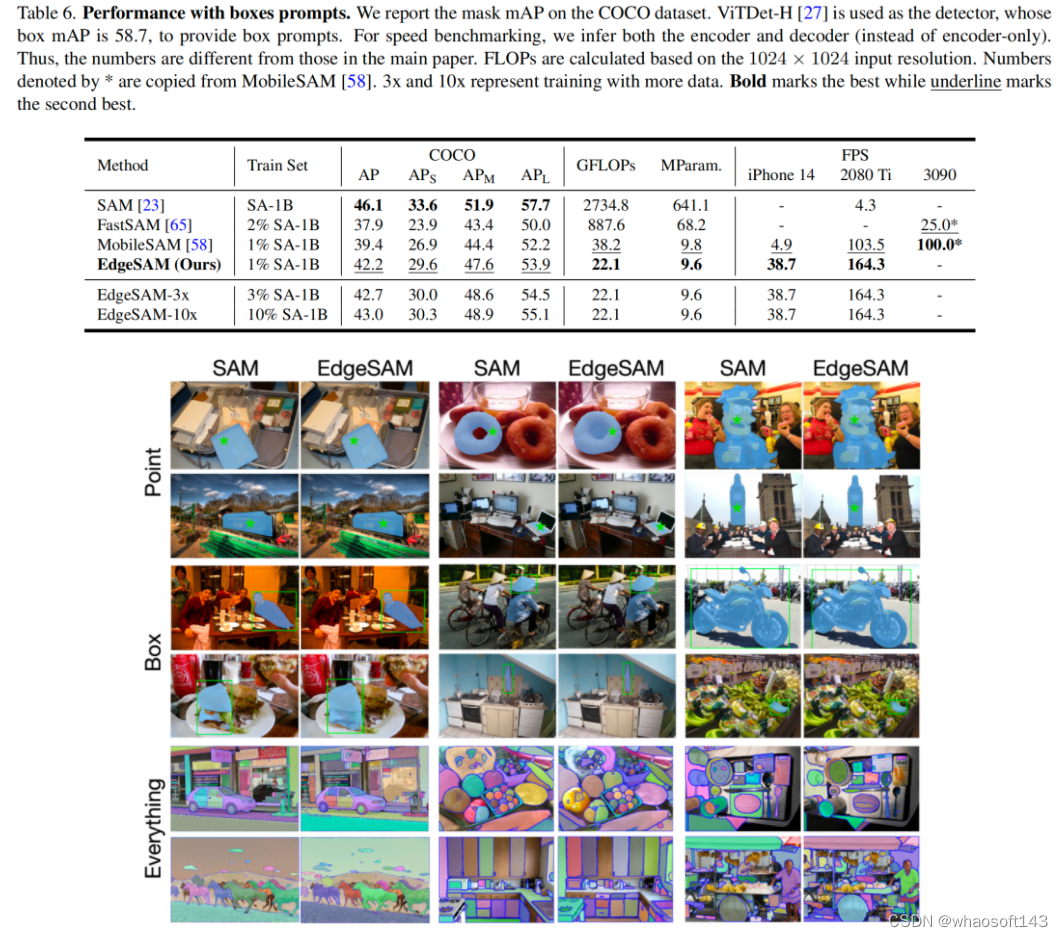
https://arxiv.org/abs/2312.06660 https://github.com/chongzhou96/EdgeSAM

相比而言,EdgeSAM方法上会显得更优异:它并非仅仅参考MobileSAM进行了Image Encoder的蒸馏,还仔细分析了不同蒸馏策略并证实:任务不可知的编码器蒸馏难以学习到SAM所具备的全部知识。
有鉴于此,作者提出:循环使用bbox与point提示词,同时对提示词编码器与Mak解码器进行蒸馏,以便于蒸馏模型能够准确的学习到提示词与Mask之间的复杂关系。

- 在2080Ti上,相比原生SAM,EdgeSAM推理速度快40倍;
- 在iPhone14上,相比MobileSAM,EdgeSAM推理速度快14倍,达到了38.7fps。
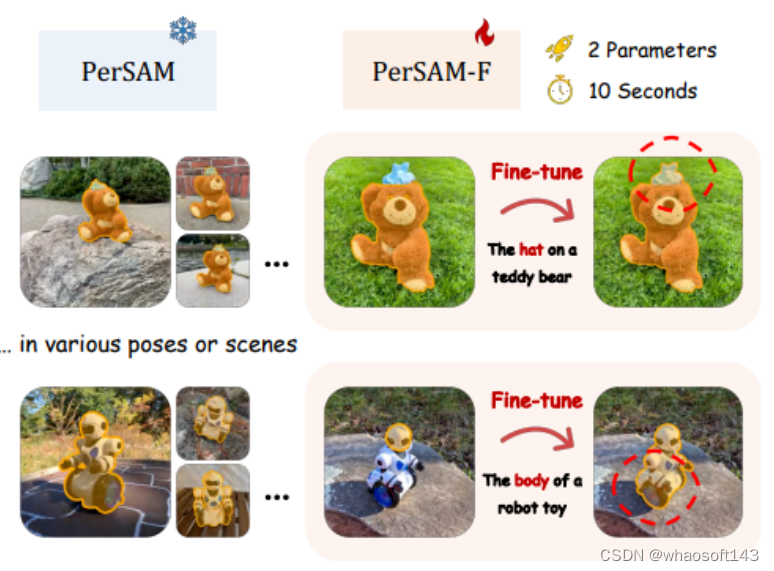
#PerSAM
无需训练的个性化分割Everything模型,可与文本提示联动,大数据预训练的驱动下,Segment Anything Model(SAM)已被证明是一个强大的可提示框架,彻底改变了分割领域。尽管具有普遍性,但在没有人工提示的情况下为特定视觉概念定制SAM的探索不足,例如,在大量图像中自动分割你的宠物狗。
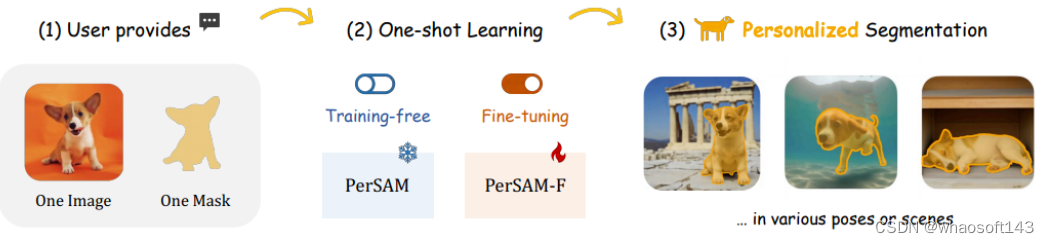
在今天分享中,我们为SAM介绍了一种无需训练的个性化方法,称为PerSAM。给定仅一个拍摄数据,即具有参考掩模的单个图像,我们首先在新图像中获得目标概念的正负位置。然后,在目标视觉语义的帮助下,我们提出两个技术:目标引导注意力和目标语义提示,为SAM提供个性化目标分割的能力。通过这种方式,我们可以有效地自定义通用SAM以供私人使用,而无需任何培训。为了进一步缓解分割尺度的模糊性,我们提出了一种有效的一次性微调变体PerSAM-F。冻结整个SAM,我们引入了一种尺度感知微调来聚合多尺度掩码,它只在10秒内调整2个参数,以提高性能。
为了证明我们的有效性,我们构建了一个新的数据集PerSeg,用于评估个性化目标分割,并在各种一次性图像和视频分割基准上测试了我们的方法。此外,我们利用PerSAM来改进DreamBooth的个性化文本到图像合成。通过减少训练集背景的干扰,我们的方法展示了更好的目标外观生成和对输入文本提示的更高保真度。
SAM固有地失去了分割特定视觉概念的能力。想象一下,打算把你可爱的宠物狗放在厚厚的相册里,或者从你卧室的照片中找到丢失的时钟。利用普通SAM将是高度劳动密集型和耗时的。对于每个图像,必须在复杂的上下文中精确地找到目标对象,然后通过适当的分割提示激活SAM。考虑到这一点,我们会问:我们能否个性化SAM,以简单高效的方式自动分割用户指定的视觉概念?
为此,我们 研究出了PerSAM,这是一种针对分割任意模型的无需训练的个性化方法。如上图所示,我们的方法只使用一次拍摄数据,即用户提供的参考图像和个人概念的粗略掩码,就可以有效地定制SAM。具体来说,我们首先通过特征相似性获得测试图像中目标对象的位置置信度图,该图考虑了每个前景像素的外观。根据置信度得分,选择两个点作为正负位置先验,最后将其编码为提示标记,并输入SAM的解码器进行分割。在解码器中,我们建议注入目标对象的视觉语义,用两种技术释放SAM的个性化分割能力:
- 目标引导注意力。我们通过位置置信度图将每个标记引导到SAM解码器中的图像交叉关注层。这明确地迫使提示标记主要集中在用于密集特征聚合的前景目标区域。
- 目标语义提示。为了明确地为SAM提供高级目标语义,我们将原始提示标记与目标对象的嵌入相融合,这为低级位置提示提供了用于个性化分割的额外视觉提示。
通过上述设计,再加上级联后细化,PerSAM在各种姿势或场景中对独特的主题表现出良好的个性化分割性能。值得注意的是,我们的方法可以很好地处理需要在多个相似目标中分割一个目标、同时分割同一图像中的几个相同对象或沿着视频跟踪不同对象的场景。然而,如下图所示,偶尔可能会出现故障情况,其中对象包括视觉上不同的子部分或要分割的层次结构,例如泰迪熊顶部的帽子或机器人玩具的头部。这种模糊性给PerSAM在确定作为输出的掩码的适当规模方面带来了挑战,因为SAM可以将局部部分和全局形状视为有效掩码。
此外,我们观察到,我们的方法还可以帮助DreamBooth更好地微调用于个性化文本到图像生成的扩散模型,如下图所示。

给定一些包含特定视觉概念的图像,例如你的宠物猫或背包,DreamBooth学会将这些图像转换为单词嵌入空间中的标识符[V],然而,它可以同时包括背景信息,例如楼梯或森林。这将覆盖新提示的背景,并干扰目标外观的生成。因此,我们利用PerSAM来分割训练图像中的目标对象,并且只通过前景区域来监督DreamBooth,从而实现更高质量的文本到图像合成。
Location Confidence Map
根据用户提供的图像IR和掩模MR,PerSAM首先获得置信度图,该置信度图指示目标对象在新测试图像I中的位置。如下图所示,我们应用图像编码器来提取IR和I的视觉特征。编码器可以是SAM的冻结骨干或其他预训练的视觉模型,为此,我们默认采用SAM的图像编码器EncI。

Target-guided Attention
尽管已经获得了正负点提示,但我们进一步提出了对SAM解码器中的交叉注意力操作的更明确的语义指导,该操作将特征聚合集中在前景目标区域内。如下图所示,总体置信度图S可以清楚地指示测试图像中目标视觉概念的粗略区域(颜色越热,分数越高)。基于这样的性质,我们利用S将每个令牌中的注意力映射引导到解码器的图像交叉注意力层。

Target-semantic Prompting.
普通SAM只接收具有低级位置信息的提示,例如点或框的坐标。为了给SAM的解码器提供更多的高级提示,我们利用目标概念的视觉特征作为额外的高级语义提示。我们首先通过不同局部特征之间的平均池化来获得参考图像中对象的全局嵌入TR:

然后,我们在将TR馈送到解码器块之前,将TR明智地添加到SAM预测的最终分割掩码中测试图像的所有输入tokens,如下图所示:

实验及可视化效果
在下表中,我们观察到微调后的PerSAM-F获得了最佳结果,它有效地将PerSAM总体mIoU和bIoU提高了+2.7%和+5.9%。我们在下图中展示了PerSAM-F改进的更多可视化效果。

测试结果充分说明了我们对时间视频数据和复杂场景的强大泛化能力,这些场景包含多个相似或遮挡的对象,如下图所示。

Visualization of PerSAM-guided DreamBooth
#SAM-Lightening
对于大小为1024×1024像素的图像,它可以实现每张图像7毫秒(ms)的推理速度,比普通SAM快30.1倍,比最先进的方法快2.1倍。此外,它仅需要244 MB内存,相当于普通SAM的(3.5%)。推理一张图仅需7毫秒
论文链接:https://arxiv.org/pdf/2403.09195.pdf
代码 & 权重地址:https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/
Segment Anything Model(SAM)由于其zero-shot泛化能力,在分割任务中引起了相当大的关注。然而,由于其低推理速度和高计算内存需求,SAM在实际应用中的广泛应用受到了限制,这主要源自注意力机制。现有工作集中在优化编码器上,然而尚未充分解决注意力机制本身的低效率问题,即使是在将其蒸馏到较小的模型时,这也为进一步改进留下了空间。
为此,这里引入了SAM-Lightening,SAM的一种变体,它具有重新设计的注意力机制,称为Dilated Flash Attention。它不仅促进了更高的并行性,增强了处理效率,而且还保留了与现有的Flash Attention的兼容性。相应地,提出了一种渐进式蒸馏方法,使得可以在不需要昂贵的从头训练的情况下,有效地从普通的SAM中传递知识。
在COCO和LVIS上的实验证明,SAM-Lightening在运行时效率和分割准确性方面明显优于最先进的方法。具体而言,对于大小为1024×1024像素的图像,它可以实现每张图像7毫秒(ms)的推理速度,比普通SAM快30.1倍,比最先进的方法快2.1倍。此外,它仅需要244 MB内存,相当于普通SAM的(3.5%)。
介绍
传统上,图像分割受到深度学习模型必须针对特定任务设计的数据集进行专门训练的限制。手工制作数据集的专门化通常限制了它们的生成能力。为了解决这一限制,Segment Anything Model(SAM)以其zero-shot学习能力代表了一种范式转变,使其能够对新的和未见过的图像进行分割。然而,SAM在增强现实(AR)、图像编辑、在智能手机上部署和医学成像等不同领域的应用受到其图像编码器中的计算负担挑战的影响,该编码器包含了巨大的6.32亿参数。这个尺寸大约是传统分割网络如U-Net的20倍,导致了高计算需求。
针对这一挑战,已经尝试了各种努力。例如,FastSAM采用了一种策略,即用更简化的卷积神经网络(CNN)替换SAM的transformer 编码器,旨在创建一个更轻量级的模型。然而,这往往会导致准确性降低,特别是在复杂的分割任务中。另一个显著的方法是MobileSAM,它采用蒸馏技术将知识从SAM的编码器传输到更紧凑的ViT-tiny编码器。类似地,像EfficientSAM这样的倡议旨在改进MobileSAM的训练过程以提高准确性。相反,SAMFast通过诸如量化和剪枝等技术,专注于对原始SAM的速度优化,但这些修改对性能提升的影响有限。
我们的研究确定了先前关于SAM的研究中的关键局限性,主要表现在注意力机制中计算效率低和内存使用不足方面。为了解决这些问题,将FlashAttention和Dilated Attention机制集成到我们的SAM框架中,提供了对现有方法的正交改进。这些增强不仅减少了内存消耗,还改善了并行处理,使它们与先前的进展相辅相成。然而,直接将这些机制应用于SAM将需要对模型进行完全重新训练,带来巨大的计算成本。
为了避免这一挑战,我们提出了一种动态分层蒸馏(DLD)方法。DLD通过逐渐分配特征权重,为图像编码器实现了一种渐进式蒸馏方案,有效促进了从SAM到轻量级模型的知识转移。实验证明,我们的模型(SAM-Lightening)不仅具有足够的表达能力来表示原始SAM,而且在计算上效率高,完成推理过程仅需7毫秒。
简而言之,本文的主要贡献有四个方面:
- 引入了一种新颖的SAM结构,SAM-Lightening,以显著降低计算复杂性。
- 设计了一种新颖的Dilated Flash Attention,用于取代普通的自注意力机制,以提高SAM-Lightening的效率和推理速度。
- 为了有效地将知识从普通SAM传输到SAM-Lightening,提出了一种动态分层蒸馏方法,而不会影响性能。
- SAM-Lightening实现了每张图像7毫秒的最先进性能,比普通SAM快30.1倍。
相关工作
Segment Anything Model: SAM 由三个主要部分组成:图像编码器、提示编码器和mask解码器。值得注意的是,图像编码器是SAM中参数最多的部分,占据了其处理时间的98.3%,这突显了优化的必要性。FastSAM采用了CNN编码器,具体是YOLOv8-seg,来替换ViT编码器以提高处理速度。然而,已经观察到这种做法会损害分割的精度,特别是在复杂场景和捕捉细微边缘细节方面。MobileSAM对编码器进行了蒸馏,以减小模型大小和计算需求。然而,MobileSAM编码器结构和参数分布的不平衡限制了其在实际部署和性能优化方面的潜力。SAMFast 代表了另一种优化策略,专注于使用量化和稀疏化等方法提高SAM的处理速度。虽然这种方案确实提供了一些加速,但其整体影响仍然适中。另一方面,EfficientSAM改进了MobileSAM的训练方法,具体针对MobileSAM方法的准确性方面进行了优化。
FlashAttention: FlashAttention机制引入了一种在神经网络中计算注意力的高效准确的方法。它通过策略性的切片和重计算技术,主要实现了高带宽内存读写的显著减少。在此基础上,FlashAttention-2通过增强的矩阵乘法操作进一步改进了这一过程。这些改进已经被证明在特定的计算设置中可以实现性能增加高达两倍。
知识蒸馏: 知识蒸馏是一种将复杂模型的知识转移到简单模型的技术。它们旨在保留较大模型的性能属性,同时显著减少其计算占用和模型大小。MobileSAM采用了一种解耦的知识蒸馏,通过从原始SAM的ViT-H图像编码器中提取输出,并将其直接蒸馏到预训练的ViT-tiny编码器中。这种策略对于已经具有预训练参数的较小模型特别有益。
方法
Dilated Flash Attention
为了解决SAM图像编码器中高计算需求的问题,我们设计了一种新颖的注意力操作,利用FlashAttention来加快推理速度。
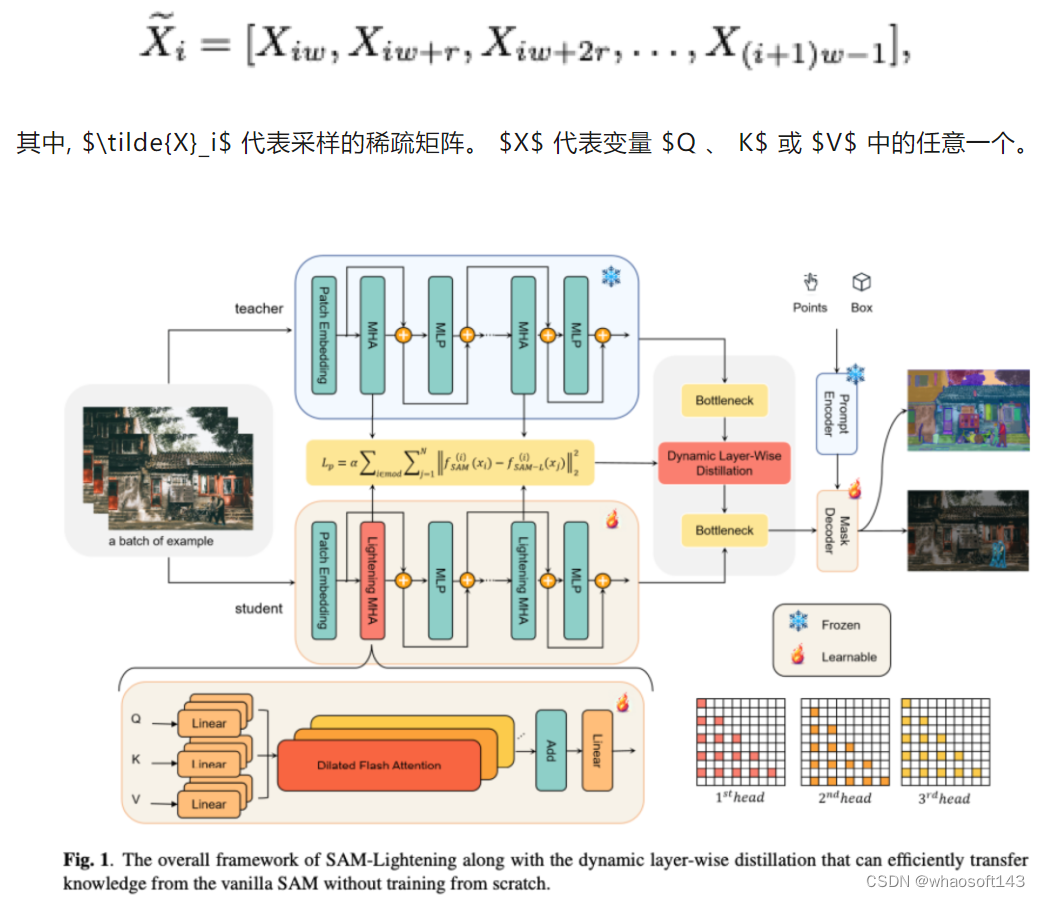
分割和稀疏化: 为了减轻在注意力操作中处理 $(Q, K, V)$ 中的计算负担, 将每个输入分成相等长度的部分 $(w)$ ,然后在每个部分的序列维度上应用稀疏化。这种稀疏化包括在固定间隔 $(r)$ 处选择行, 从而减少了注意力机制需要处理的数据量。如图1所示, 稀疏化过程可以表示为:
FlashAttention的并行处理: 每个输入数据的稀疏化段是可以独立参与注意力计算的稠密矩阵,因此可以并行处理。这种并行性对于高效管理大规模图像数据集至关重要,可以显著加快处理速度,提高模型在实时图像分割中的效率。通过将FlashAttention纳入其中,进一步增加了通过并行化稠密矩阵计算来提高效率的可能性。
输出重组: 在提出的Dilated Flash Attention框架中, 我们并行处理稀疏化的段, 实现对 $\tilde{Q_i}$和 $\tilde{K}_i$ 转置的乘积应用 softmax函数, 然后将其与 $\tilde{V}_i$ 相乘, 如下所示:

将这些输出重新组合成连贯的最终输出O,涉及一个经过精心设计的过程:
- (1) 首先, 建立一个与原始输入维度相同的零矩阵 $O_{i n i t}$, 用于累积各个段的输出。
- (2) 对于每个计算得到的段输出 $\tilde{Q_i}$, 确定一个特定的偏移量 $\gamma_i$ 。这个偏移量确定了 $\tilde{O}_i$ 在 $O_{i n i t}$ 矩阵中的精确起始位置。
- (3) 使用基于其 $\gamma_i$ 的映射操作将每个 $\tilde{Q_i}$ 映射到 $O_{i n i t}$ :

"MAP" 操作根据 $\gamma_i$ 确定的位置将每个 $\tilde{Q_i}$ 元素放置到 $O_{i n i t}$ 中。这确保了根据其原始输入位置, 每个段的输出在最终输出矩阵 $O$ 中的精确对齐。
计算效率: 通过提出的Dilated Flash Attention机制, 效率在数量上提高了一个因子 $\frac{N}{w r^2}$, 其中 $N$ 表示输入的总大小, $w$ 表示每个分割的长度, $r$ 表示稀疏化的间隔。这种数学关系表明, 对于任何给定的输入大小, Dilated Flash Attention需要的计算量大大减少。因此, 这提高了模型在高效处理大规模图像分割任务方面的能力, 显著提高了性能和实用性。
动态分层蒸馏 (DLD)
从头开始训练SAM-Lightening成本高昂,而由于SAM与以ViT-H为特征编码器的SAM-Lightening之间的结构差异,层适应性具有挑战性。为了实现从普通SAM到提出的框架的有效知识转移,我们提出了一种新颖的动态分层蒸馏(DLD)方法,该方法动态修改特征权重,以增强模型之间的逐层蒸馏。
动态分层权重: 当前面的层次没有很好地被蒸馏时,后续层次的性能可能会受到从前面层次提取的低质量特征的影响。通过给予这些初始层损失更大的权重,动态加权确保它们在训练过程中更受关注。这有助于在初始阶段更好地将学生模型与教师模型对齐。给定一个由 $L$ 层组成的深度神经网络, 每一层 $i$ 与一个时间权重 $\alpha_i(t)$ 相关联。这种机制调整了神经网络中每一层 $i$ 在各个训练阶段 $t$ 中的重要性。初始层保持最大的焦点 $\alpha_1(t)=1$, 后续层遵循动态加权方案, 可以用分段函数在数学上表示为:

其中, $T_i$ 表示第 $i^{t h}$ 层开始更新权重的时期, 前一层已经达到饱和, 即 $T_i=T_{i-1}+\Delta t$ 。参数 $\Delta t$ 捕获了权重从 0 过渡到 1 所需的epoch数。对于预定义的epoch增量 $\Delta t$, 每一层在前一层达到峰值权重后依次激活其学习潜力。这种机制有助于从教师模型中实现级联知识吸收。
解耦的特征蒸馏: 蒸馏过程将知识从SAM的编码器(教师模型)转移到我们提出的编码器(学生模型),如图1所示。选择了距离输出最近的层进行特征蒸馏。由于这些更深层次直接与模型的输出相关,蒸馏它们可以更有效地传递关键信息以获得预测结果。这些层被指定为“焦点层”。
在训练的初始阶段,靠近输入的层次被赋予优先权。这里的意图是将SAM-Lightning学生模型的主要特征表示,表示为 $f_{S A M-L}^i(x)$, 与教师模型的特征表示 $f_{S A M}^i(x)$ 对齐,与教师模型的特征表示对齐,对于最接近输入的层。随着训练的进行,逐层加权动态地转移。与后续层相关的损失被逐渐放大。在这个过程中,损失函数演变为吸收来自后续层的表示:

其中, $L$ 是完整层次的计数, 而系数 $\alpha(i)$ 是由训练epoch和层次 $i$ 确定的分段函数。集成的蒸馏损失被表述为:

其中, $L_P$ 封装了所有选择的特征层损失的加权和, $L_{\text {output }}$ 是图像编码器输出层的损失, $\lambda$是一个缩放因子, 用于平衡解码器输出在整体蒸馏过程中的重要性。
对齐解码器: 此外,通过解耦的蒸馏获得的轻量级图像编码器与冻结的解码器存在对齐问题,特别是对于基于点的提示分割任务。因此,我们通过在SA-1B数据集上对点提示和框提示进行采样,对解码器进行微调,以与图像编码器对齐。损失函数定义如下:

这里,IOU代表交并比损失,而Dice损失和Focal损失分别用于处理类别不平衡和具有挑战性的分割区域。
实验
实验设置
我们的模型利用SA-1B数据集的1%进行蒸馏和微调。它具有一个embedding维度为384的编码器,六个注意力头和一个六层结构。对于FlashAttention组件,使用bfloat16。蒸馏和微调过程分别进行了10个时期,学习率为$10^{-3}$,批量大小为32。梯度累积设置为4步。该模型在两个NVIDIA RTX 4090 GPU上进行训练。为了提高训练速度,SAM的图像编码器的输出被保存了下来。
结果
运行时间和内存效率评估: 将我们提出的SAM-Lightening与原始SAM(即SAM-ViT-H)、FastSAM、MobileSAM、EfficientSAM和SAMFast在表1和表2中进行了性能比较。就分割性能而言,原始SAM被视为上限。重要的是,表1显示SAM-Lightening在推理延迟和峰值内存使用方面优于所有对手,与原始SAM相比,实现了30.1倍的加速和96.5%的峰值内存减少,并且与现有技术相比实现了2.1倍的加速。表2中的吞吐量比较进一步强化了SAM-Lightening的优越性能,它在各种batch大小下均实现了最高的吞吐量。总的来说,这种高吞吐量与低延迟和内存使用率相结合,使SAM-Lightening成为图像分割任务的高效模型。


在框提示/点提示模式下的比较: 首先在边界框和基于点的提示下评估性能。对于边界框提示,按照原始SAM中的设置,利用COCO和LVIS中的真值标注,合成定义每个图像中感兴趣区域的边界框。对于点提示,在真值mask中随机采样点,挑战所有模型准确地分割与每个点相关的目标或区域。在定量上,使用平均交并比(mIoU)作为指标。如表3所示,与原始SAM相比,SAMFast和MobileSAM在边界框提示和点提示方面都表现出性能下降,特别是在点提示方面。作为基于CNN的模型,FastSAM显示出更为明显的下降,特别是在处理包含大量小目标的LVIS数据集时,这一点尤为明显。这种观察反映了CNN编码器在处理更复杂的分割场景时的局限性。相反,SAM-Lightening在分割性能方面与原始SAM最为匹配。即使在基于点的提示场景下,SAM-Lightening的mIoU也与原始SAM相似。


在任意模式下的比较: 虽然"segment-anything"模式是一种创新的方法,但并不是一种常用的分割方法,因此并不能有效地代表典型的分割任务。因此,我们的分析主要集中在通过基于点和基于框的方法在视觉上比较分割结果,这在实际应用中更为普遍。然而,为了完整性和展示模型的多功能性,还在比较中包含了"segment-anything"模式的输出。
从图3中展示的代表样本, SAM-Lightening和MobileSAM在分割结果上几乎与原始SAM无法区分。这种相似性在边缘清晰度和细节保留方面非常明显,这是高质量分割的特征。SAM-Lightening展示了其稳健性和准确性,与原始SAM的性能密切对齐。

消融研究
值得注意的是,许多先前的工作在SAM的输入尺寸上使用小于1024的尺寸。为了公平比较,我们也在这些场景下进行了实验,并发现保持FlashAttention的输入尺寸等于或小于512×512可以实现最佳性能。这表明FlashAttention的适用性取决于模型的输入尺寸和特定的硬件配置。决定使用FlashAttention应基于特定的应用背景和性能要求。
虽然FlashAttention可以加速模型蒸馏的训练过程,但其对推理性能的影响取决于各种硬件指标。在我们的推理平台上,特别是对于输入尺寸为1024的SAM,多头注意力运算符表现出更多的计算密集型特征。如下图4所示,这导致使用FlashAttention的推理速度略低于不使用FlashAttention的速度。因此,我们选择在蒸馏过程中使用FlashAttention来优化性能,而在评估阶段移除它。

结论
SAM-Lightening用来解决原始SAM中高计算需求和推理速度慢的主要局限性,使其更适合部署在资源受限设备上。方法涉及对SAM中图像编码器的重新设计,通过将自注意力操作符蒸馏成具有动态层次蒸馏的Dilated Flash Attention。这些优化措施显著降低了计算复杂度和内存使用量,同时没有损害分割性能。
具体来说,SAM-Lightening在图像上完成推理平均每张仅需7ms,实现了比SAM-ViT-H快30.1倍的速度提升。由于SAM-Lightening与剪枝和量化是互补的,未来的一个方向可以考虑将它们整合在一起。






