Title
题目
Grade-Skewed Domain Adaptation via Asymmetric Bi-Classifier DiscrepancyMinimization for Diabetic Retinopathy Grading
《通过不对称双分类器差异最小化进行糖尿病视网膜病变分级的领域偏斜适应》
01
文献速递介绍
糖尿病视网膜病变(DR)是糖尿病常见的并发症,也是全球可预防失明的主要原因之一。根据国际糖尿病联盟(IDF)糖尿病地图,2021年全球成人糖尿病患病率超过10%。更严重的问题是,预计未来糖尿病患者数量将继续大幅增长。准确分级糖尿病视网膜病变的严重程度对于有效管理和治疗至关重要,因为通过定期眼科检查和有效治疗,90%的严重视力丧失是可以预防的。
近年来,基于深度学习的方法在糖尿病视网膜病变分级中取得了令人鼓舞的成果,尤其是在自动化分级方面,提供了一种可靠且高效的替代传统分级系统的方案。像基于病变识别的像素级监督方法,在准确性上表现尤为突出。然而,视网膜图像的病变像素级标注成本较高,这使得图像级监督分级成为辅助临床诊断和治疗规划的重要方法。目前,现有的图像级监督方法通常假设数据集遵循独立同分布(i.i.d.)假设,即数据集随机划分为训练集和测试集,但跨域分级在实际应用中尚未得到充分探索。
Aastract
摘要
Diabetic retinopathy (DR) is a leading causeof preventable blindness worldwide. Deep learning hasexhibited promising performance in the grading of DR.Certain deep learning strategies have facilitated convenientregular eye check-ups, which are crucial for managing DRand preventing severe visual impairment. However, the generalization performance on cross-center, cross-vendor, andcross-user test datasets is compromised due to domainshift. Furthermore, the presence of small lesions and theimbalanced grade distribution, resulting from the characteristics of DR grading (e.g., the progressive nature of DRdisease and the design of grading standards), complicatesimage-level domain adaptation for DR grading. The generalpredictions of the models trained on grade-skewed sourcedomains will be significantly biased toward the majoritygrades, which further increases the adaptation difficulty.We formulate this problem as a grade-skewed domain adaptation challenge. Under the grade-skewed domain adaptation problem, we propose a novel method for imagelevel supervised DR grading via Asymmetric Bi-ClassifierDiscrepancy Minimization (ABiD). First, we propose optimizing the feature extractor by minimizing the discrepancybetween the predictions of the asymmetric bi-classifierbased on two classification criteria to encourage the exploration of crucial features in adjacent grades and stretch thedistribution of adjacent grades in the latent space. Moreover, the classifier difference is maximized by using theforward and inverse distribution compensation mechanismto locate easily confused instances, which avoids pseudolabel bias on the target domain. The experimental resultson two public DR datasets and one private DR datasetdemonstrate that our method outperforms state-of-the-artmethods significantly.
糖尿病视网膜病变(DR)是全球可预防失明的主要原因。深度学习在DR分级方面表现出了良好的性能。某些深度学习策略促进了定期眼部检查的便捷性,这对于管理DR并防止严重的视力障碍至关重要。然而,由于领域偏移,模型在跨中心、跨厂商和跨用户的测试数据集上的泛化性能受到影响。此外,由于DR分级的特点(例如,DR疾病的渐进性和分级标准的设计),小病变的存在和不平衡的分级分布使得DR分级的图像级领域适应变得复杂。在基于分级不平衡的源领域上训练的模型的总体预测将显著偏向于多数类分级,这进一步增加了适应的难度。
我们将这一问题定义为一个分级偏倚的领域适应挑战。在分级偏倚的领域适应问题下,我们提出了一种新颖的图像级监督DR分级方法——不对称双分类器差异最小化(ABiD)。首先,我们提出通过最小化基于两个分类标准的非对称双分类器预测之间的差异来优化特征提取器,以鼓励探索相邻分级中的关键特征,并拉伸相邻分级在潜在空间中的分布。此外,通过使用正向和逆向分布补偿机制最大化分类器之间的差异,以定位容易混淆的实例,从而避免目标领域的伪标签偏差。我们在两个公开的DR数据集和一个私有的DR数据集上的实验结果表明,我们的方法显著优于现有的最先进方法。
Method
方法
A. Problem Definition and Notations
According to the International Clinical Diabetic RetinopathyDisease Severity Scale [3], the DR is generally divided into 5grades (see Figure 5 (bottom right) for details). We use DR0-DR4 to denote the grade of no apparent retinopathy (DR0),mild nonproliferative diabetic retinopathy (DR1), moderatenonproliferative diabetic retinopathy (DR2), severe nonproliferative diabetic retinopathy (DR3) and proliferative diabeticretinopathy (DR4), respectively. The GSDA problem in DRgrading can be framed as a grading task for target domainwith the same label set with sources Y = {yi} 4 i=0 . The labeledsource domain is denoted as DS = {(xi , yi)} N i=1 S and unlabeledtarget domain is denoted as DT = {xi} N i=1 T , where xi ∈ Xstands for input, yi∈Y stands for the DR-i grade.
A. 问题定义与符号
根据国际临床糖尿病视网膜病变疾病严重程度分级标准,DR通常分为5个等级(详见图5(右下角))。我们用DR0-DR4表示不同的DR等级,分别为:无明显视网膜病变(DR0)、轻度非增殖性糖尿病视网膜病变(DR1)、中度非增殖性糖尿病视网膜病变(DR2)、重度非增殖性糖尿病视网膜病变(DR3)和增殖性糖尿病视网膜病变(DR4)。
在DR分级中,GSDA(Grade-Skewed Domain Adaptation,分级偏倚的领域适应)问题可以被框定为目标领域的分级任务,目标领域具有与源领域相同的标签集合 Y = {y₀, y₁, y₂, y₃, y₄}。
标记的源领域表示为 Dₛ = {(xᵢ, yᵢ)}ₙᵢ=₁ᵛ,其中 xᵢ ∈ X 表示输入,yᵢ ∈ Y 表示DR等级,N 为源领域中样本的数量。未标记的目标领域表示为 Dₜ = {xᵢ}ₙᵢ=₁ᵛ,其中 xᵢ ∈ X 为输入,N 为目标领域中的样本数量。
Conclusion
结论
In this paper, we study an unexplored but common problemin the medical scene, namely grade-skewed domain adaptation (GSDA). Based on this challenging setting, for diabeticretinopathy grading, we provide a novel methodology Asymmetric Bi-Classifier Discrepancy Minimization via introducingforward and reverse compensation based on skewed sourcedistribution, the divergence between the bi-classifier near thedecision boundary is enhanced to find confusing instancesof the classification boundary, and then the feature extractoris forced to generate features that minimize the difference.Extensive experiments based on one toy dataset and three realworld datasets demonstrate significant advantages of ABiDover previous state-of-the-art methods.
本文研究了一个在医学领域中尚未深入探讨但却非常常见的问题——等级偏斜的领域适应(Grade-Skewed Domain Adaptation, GSDA)。在这一具有挑战性的背景下,针对糖尿病视网膜病变(DR)分级任务,提出了一种新的方法——不对称双分类器差异最小化(Asymmetric Bi-Classifier Discrepancy Minimization, ABiD)。该方法通过引入基于偏斜源分布的正向和反向补偿机制,增强了双分类器在决策边界附近的差异,以识别分类边界上的混淆实例。然后,强制特征提取器生成能够最小化差异的特征。基于一个玩具数据集和三个真实世界数据集的广泛实验表明,ABiD 相较于以往的最先进方法具有显著的优势。
Results
结果
Table II (sorted by method type) shows the experimentalresults on IDRiD. We observe that grading results of the twoclassifiers tend to be the same after convergence. The gradingresults of CERM is reported. Table III and Table IV (sortedby Acc. value) present the experimental results of 6 crossdomain adaptation tasks on the DDR dataset and 12 crossdomain adaptation tasks on the Aier dataset, respectively.
Comparison with ERM*: Compared with the ERM, ourmethod exhibits superior performance across all datasets onaverage. We utilize the distinctions generated by asymmetric bi-classifiers to evaluate the extractor, fostering intrinsicmotivation for discovering essential differences and mitigating the impact of grade-skewed domain shift. Specifically,the most significant performance improvements attained withour ABiD (ABiD‡ ) method were 7.44% (8.42%), 2.45%(5.05%), 3.67% (4.52%) in term of overall accuracy (Acc.)and 10.00% (12.88%), 6.19% (9.25%), 3.06% (3.61%) in termof quadratic-weighted kappa (κ) for each of the three datasets,respectively. Meanwhile, the average performance of manycompared methods, even those that take label distribution shiftinto account, is worse than ERM.
表 II(按方法类型排序)展示了在 IDRiD 数据集上的实验结果。我们观察到,两个分类器的分级结果在收敛后趋于相同。报告了 CERM 的分级结果。表 III 和表 IV(分别按准确率(Acc.)排序)展示了在 DDR 数据集上进行的 6 个跨领域适应任务和在 Aier 数据集上进行的 12 个跨领域适应任务的实验结果。
1) 与 ERM 的比较:与 ERM 相比,我们的方法在所有数据集上平均表现出优越的性能。我们利用非对称双分类器(ABiD)生成的区分性来评估提取器,促进了发现关键差异的内在动机,并减轻了因等级偏斜的领域转移影响。具体来说,我们的 ABiD(ABiD‡)方法在三个数据集上取得了最显著的性能提升:在总体准确率(Acc.)方面分别为 7.44%(8.42%)、2.45%(5.05%)、3.67%(4.52%);在二次加权 kappa(κ)方面分别为 10.00%(12.88%)、6.19%(9.25%)、3.06%(3.61%)。与此同时,许多对比方法的平均性能,甚至是那些考虑到标签分布转移的方法,均不及 ERM。
Figure
图

Fig. 1. Cross-center diabetic retinopathy grading is a typical gradeskewed domain adaptation (GSDA) problem. We highlight three mainchallenges in GSDA: covariate shift (in the four domains of the Aierdataset), grade skew, and small inter-grade differences (small lesions).
图1. 跨中心糖尿病视网膜病变分级是一个典型的分级偏斜领域适应(GSDA)问题。我们强调了GSDA中的三个主要挑战:协变量偏移(在Aier数据集的四个领域中)、分级偏斜和小的分级间差异(小病变)。

Fig. 2. Illustration of the Asymmetric Bi-Classifier framework for GSDA.The framework includes a shared feature extractor (blue), a generalclassifier (yellow), and a Bayes-optimal classifier (green)
图2. GSDA的非对称双分类器框架示意图。该框架包括一个共享特征提取器(蓝色),一个普通分类器(黄色)和一个贝叶斯最优分类器(绿色)。

Fig. 3. An overview of the asymmetric bi-classifier adversarial trainingprocess. First, identify the confusion instances by the forward andinverse distribution compensation of the dual classifiers. Then, minimizebi-classifier discrepancy in the feature extractor to uncover the essentialdistinguishing features between the grades.
图3. 非对称双分类器对抗训练过程概述。首先,通过双分类器的正向和反向分布补偿识别混淆实例。然后,在特征提取器中最小化双分类器差异,以揭示不同等级之间的关键区分特征。
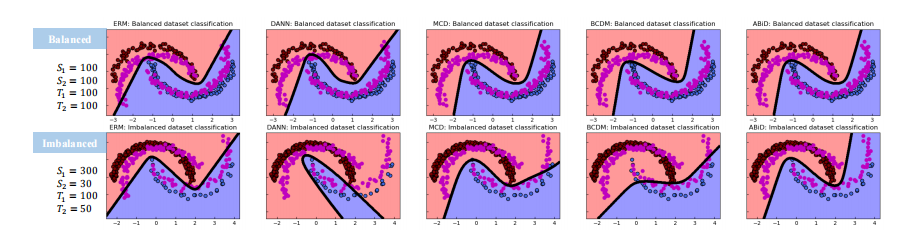
Fig. 4. Visualizations of comparisons of decision boundaries on balanced and imbalanced inter-twining moons datasets. The purple dots representthe target domain data, and the red and blue dots represent the source data points belonging to classes 1 and 2, respectively
图4. 平衡和不平衡交织月亮数据集上决策边界的比较可视化。紫色点表示目标领域数据,红色和蓝色点分别表示属于类别1和类别2的源数据点。

Fig. 5. CAM heatmaps resulting from the trained model using ABiD. (Bottom right) The description of each grade in the International DR Scale.
图5. 使用 ABiD 训练模型生成的 CAM 热图。(右下)每个等级在国际 DR 量表中的描述。
Table
表

TABLE I the detailed information (sample size proportion) of the real-world datasets.
表I 真实世界数据集的详细信息(样本大小比例)。

TABLE II results (average ± s.d.) on idrid with convnext-tiny backbone. double dagger (‡) denotes the methods using augmented data. the best results w/ augmentation annotated in red, best results w/o augmentation annotated in blue.
表II使用ConvNext-Tiny骨干网络在IDRiD数据集上的结果(平均值±标准差)。双十字标记(‡)表示使用增强数据的方法。增强数据的最佳结果标注为红色,未使用增强数据的最佳结果标注为蓝色。
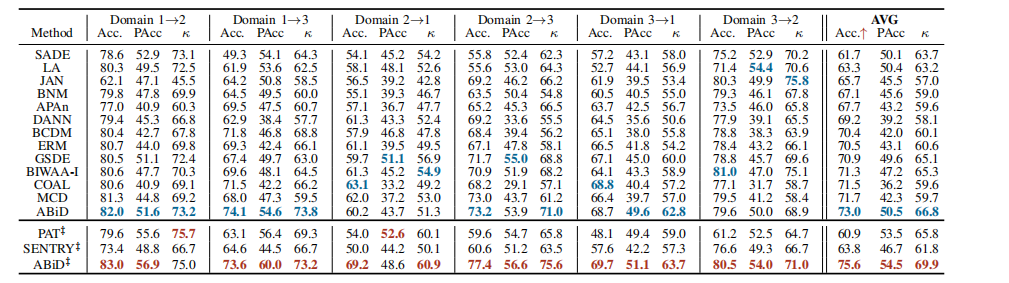
TABLE III results on the aier dataset with convnext-tiny backbone (source domain → target domain)
表III使用ConvNext-Tiny骨干网络在DDR数据集上的结果(源域→目标域)。
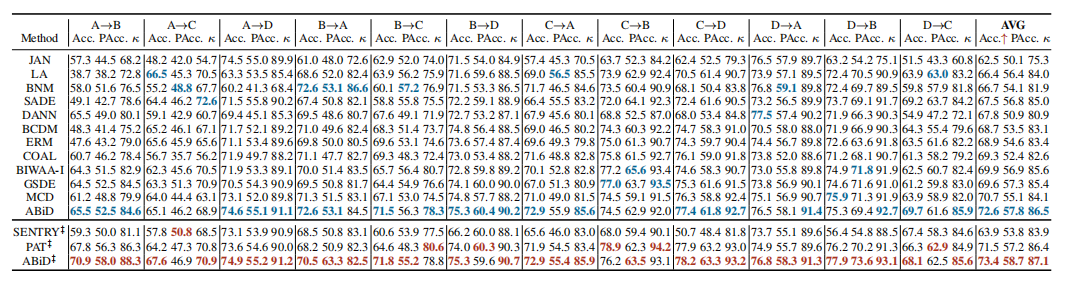
TABLE IV results on the aier dataset with convnext-tiny backbone (source domain → target domain)
表IV使用ConvNext-Tiny骨干网络在AIER数据集上的结果(源域→目标域)。

TABLE V results on each grade (aier: d→b)
表V每个等级上的结果(AIER: D→B)。
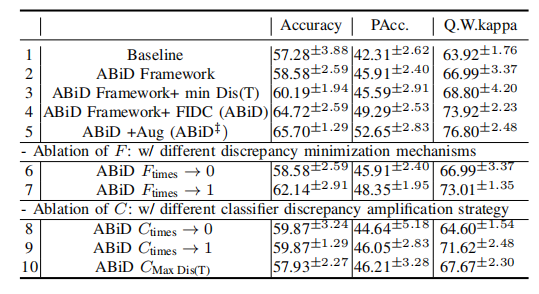
TABLE VI ablation study on each component with convnext-tiny
表 VI基于 ConvNext-Tiny 的每个组件消融研究。

TABLE VII results with different hyper-parameter µ
表VII 不同超参数 µ 的结果。
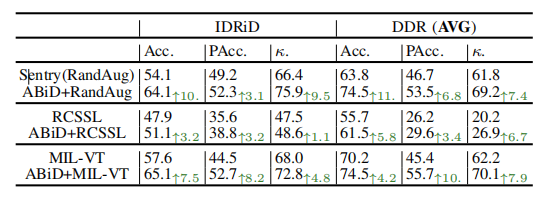
TABLE VIII combine abid with other deep learning strategies for dr
表VIII将 ABiD 与其他深度学习策略结合用于糖尿病视网膜病变(DR)。

TABLE IX results of method abid‡ with different input sizes
表IX不同输入大小下方法 ABiD‡ 的结果。
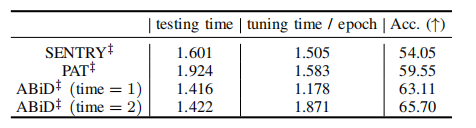
TABLE X tuning and testing time (seconds) on idrid dataset
表X在 IDRID 数据集上的调优和测试时间(秒)。





、优化(蒸馏、剪枝、量化)、部署细节)
