1 问题
为什么需要叶子节点?
2 方法
在Pytorch中,为了节省显存,引入了叶子张量的概念,在反向传播过程中,只有叶子张量的求导结果会被保存,因为其他的非叶子张量是由用户所定义的叶子张量的一系列运算所形成的(下面会解释),非叶子张量都是中间变量,一般情况下用户不会去使用这些中间变量的导数,所以为了节约显存,它们在用过之后就都被释放了。对于任意一个张量来说,我们都可以用tensor.is_leaf来判断它是否是叶子张量,对于requires_grad=False的张量,我们默认为叶子张量,当requires_grad=True时,张量是否是叶子张量是这样进行判断的:当一个tensor是用户创建的时候,它是一个叶子节点,当一个tensor是由其他运算操作产生的时候,它就不是一个叶子节点。
 2 方法
2 方法
结果:
。
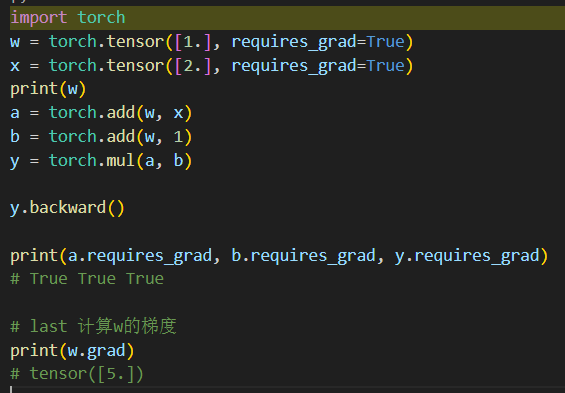
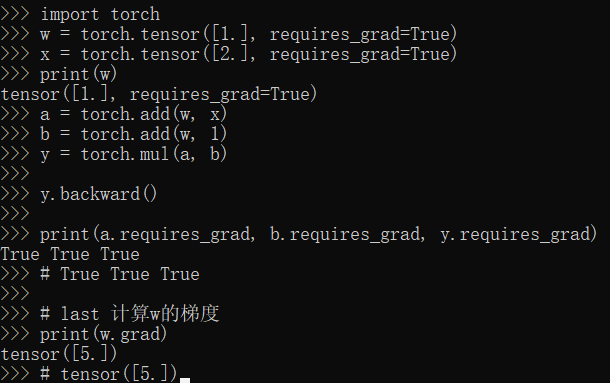
| import torch w = torch.tensor([1.], requires_grad=True) x = torch.tensor([2.], requires_grad=True) print(w) a = torch.add(w, x) b = torch.add(w, 1) y = torch.mul(a, b) y.backward() print(a.requires_grad, b.requires_grad, y.requires_grad) # True True True # last 计算w的梯度 print(w.grad) # tensor([5.]) |
3 结语
叶子节点:用户创建的节点被称之为叶子节点。(即Tensor有一个属性,叫is_leaf。) 所以可以Tensor调用is_leaf属性来判断是否为叶子节点,只有叶子节点才有梯度。非叶子节点的梯度在运行后会被直接释放掉。依赖于叶子节点的节点 requires_grad默认为True。
requires_grad:即是否需要计算梯度,当这个值为True时,我们将会记录tensor的运算过程并为自动求导做准备。,但是并不是每个requires_grad()设为True的值都会在backward的时候得到相应的grad.它还必须为leaf。只有是叶子张量的tensor在反向传播时才会将本身的grad传入到backward的运算中,如果想得到其他tensor在反向传播时的grad,可以使用retain_grad()这个属性。






