作者:来自 Elastic Andre Luiz

了解如何使用 LLM 来自动识别和生成同义词, 使术语可以通过程序方式加载到 Elasticsearch 同义词 API 中。
提高搜索结果的质量对于提供高效的用户体验至关重要。优化搜索的一种方法是通过同义词自动扩展查询词。这样可以更广泛地解释查询内容,覆盖语言变体,从而改进结果匹配。
本博客探讨了如何利用 大语言模型(LLMs) 自动识别和生成同义词,使这些术语可以通过程序方式加载到 Elasticsearch 的 synonym API 中。
何时使用同义词?
使用 同义词 相较于 向量搜索 是一种更快速且更具成本效益的解决方案。它的实现更简单,因为它不需要深入了解 embeddings 或复杂的向量摄取过程。
此外,同义词的 资源消耗更低,因为向量搜索需要更大的存储空间和内存来进行 embedding 索引和检索。
另一个重要方面是 搜索的区域化。通过 同义词,可以根据本地语言和习惯调整术语,这在 embeddings 可能无法匹配地区表达或特定国家术语的情况下非常有用。例如,一些单词或缩写在不同地区可能有不同的含义,但本地用户通常会将它们视为同义词:
-
在 巴西,"abacaxi" 和 "ananás" 都指 菠萝(pineapple),但在东北部,第二个词更常见。
-
在巴西东南部,常见的 "pão francês"(法式面包)在东北部可能被称为 "pão careca"。
这种 区域化 的差异使得 同义词 在搜索优化中发挥关键作用。
如何使用 LLMs 生成同义词?
为了自动获取同义词, 你可以使用 LLMs, 这些模型可以分析术语的上下文并建议合适的变体。 这种方法可以动态扩展同义词, 确保更广泛和更精准的搜索, 而无需依赖固定的词典。
在本示例中, 我们将使用 LLM 来为 电商产品 生成同义词。 许多搜索由于查询词的不同变体而返回较少甚至没有结果。 通过 同义词, 我们可以解决这个问题。 例如, 搜索 "smartphone" 时, 结果可以涵盖不同型号的手机, 确保用户能够找到他们需要的产品。
先决条件
在开始之前, 需要设置环境并定义所需的依赖项。 我们将使用 Elastic 提供的解决方案 在 Docker 中本地运行 Elasticsearch 和 Kibana。 代码将使用 Python v3.9.6 编写,并需要以下依赖项:
pip install openai==1.59.8 elasticsearch==8.15.1创建产品索引
首先, 我们将创建一个不支持同义词的产品索引。 这将使我们能够验证查询, 然后将其与包含同义词的索引进行比较。
要创建索引, 我们使用以下命令在 Kibana DevTools 中批量加载产品数据集:
POST _bulk
{"index": {"_index": "products", "_id": 10001}}
{"category": "Electronics", "name": "iPhone 14 Pro"}
{"index": {"_index": "products", "_id": 10007}}
{"category": "Electronics", "name": "MacBook Pro 16-inch"}
{"index": {"_index": "products", "_id": 10013}}
{"category": "Electronics", "name": "Samsung Galaxy Tab S8"}
{"index": {"_index": "products", "_id": 10037}}
{"category": "Electronics", "name": "Apple Watch Series 8"}
{"index": {"_index": "products", "_id": 10049}}
{"category": "Electronics", "name": "Kindle Paperwhite"}
{"index": {"_index": "products", "_id": 10067}}
{"category": "Electronics", "name": "Samsung QLED 4K TV"}
{"index": {"_index": "products", "_id": 10073}}
{"category": "Electronics", "name": "HP Spectre x360 Laptop"}
{"index": {"_index": "products", "_id": 10079}}
{"category": "Electronics", "name": "Apple AirPods Pro"}
{"index": {"_index": "products", "_id": 10115}}
{"category": "Electronics", "name": "Amazon Echo Show 10"}
{"index": {"_index": "products", "_id": 10121}}
{"category": "Electronics", "name": "Apple iPad Air"}
{"index": {"_index": "products", "_id": 10127}}
{"category": "Electronics", "name": "Apple AirPods Max"}
{"index": {"_index": "products", "_id": 10151}}
{"category": "Electronics", "name": "Sony WH-1000XM4 Headphones"}
{"index": {"_index": "products", "_id": 10157}}
{"category": "Electronics", "name": "Google Pixel 6 Pro"}
{"index": {"_index": "products", "_id": 10163}}
{"category": "Electronics", "name": "Apple MacBook Air"}
{"index": {"_index": "products", "_id": 10181}}
{"category": "Electronics", "name": "Google Pixelbook Go"}
{"index": {"_index": "products", "_id": 10187}}
{"category": "Electronics", "name": "Sonos Beam Soundbar"}
{"index": {"_index": "products", "_id": 10199}}
{"category": "Electronics", "name": "Apple TV 4K"}
{"index": {"_index": "products", "_id": 10205}}
{"category": "Electronics", "name": "Samsung Galaxy Watch 4"}
{"index": {"_index": "products", "_id": 10211}}
{"category": "Electronics", "name": "Apple MacBook Pro 16-inch"}
{"index": {"_index": "products", "_id": 10223}}
{"category": "Electronics", "name": "Amazon Echo Dot (4th Gen)"}使用 LLM 生成同义词
在此步骤中, 我们将使用 LLM 动态生成同义词。 为此, 我们将集成 OpenAI API, 定义合适的模型和提示词。 LLM 将接收产品类别和名称, 确保生成的同义词在上下文中具有相关性。
import json
import loggingfrom openai import OpenAIdef call_gpt(prompt, model):try:logging.info("generate synonyms by llm...")response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}],temperature=0.7,max_tokens=1000)content = response.choices[0].message.content.strip()return contentexcept Exception as e:logging.error(f"Failed to use model: {e}")return Nonedef generate_synonyms(category, products):synonyms = {}for product in products:prompt = f"You are an expert in generating synonyms for products. Based on the category and product name provided, generate synonyms or related terms. Follow these rules:\n"prompt += "1. **Format**: The first word should be the main item (part of the product name, excluding the brand), followed by up to 3 synonyms separated by commas.\n"prompt += "2. **Exclude the brand**: Do not include the brand name in the synonyms.\n"prompt += "3. **Maximum synonyms**: Generate a maximum of 3 synonyms per product.\n\n"prompt += f"The category is: **{category}**, and the product is: **{product}**. Return only the synonyms in the requested format, without additional explanations."response = call_gpt(prompt, "gpt-4o")synonyms[product] = responsereturn synonyms从创建的产品索引中, 我们将检索 "Electronics"(电子产品) 类别中的所有商品, 并将它们的名称发送到 LLM。 预期的输出将类似于:
{"iPhone 14 Pro": ["iPhone", "smartphone", "mobile", "handset"],"MacBook Pro 16-inch": ["MacBook", "Laptop", "Notebook", "Ultrabook"],"Samsung Galaxy Tab S8": ["Tab", "Tablet", "Slate", "Pad"],"Bose QuietComfort 35 Headphones": ["Headphones", "earphones", "earbuds", "headset"]
}使用生成的同义词, 我们可以通过 Synonyms API 将它们注册到 Elasticsearch 中。
使用 Synonyms API 管理同义词
Synonyms API 提供了一种有效的方式, 让我们直接在系统中管理同义词集合。 每个同义词集合由同义词规则组成, 在这些规则中,一组词在搜索中被视为等同。
创建同义词集合的示例:
PUT _synonyms/my-synonyms-set
{"synonyms_set": [{"id": "rule-1","synonyms": "hello, hi"},{"synonyms": "bye, goodbye"}]
}这将创建一个名为 “my-synonyms-set” 的同义词集,其中将 “hello” 和“ hi” 视为同义词,“bye” 和 “goodbye” 也视为同义词。
实现产品目录的同义词创建
以下是负责构建同义词集并将其插入 Elasticsearch 的方法。 同义词规则是基于 LLM 提供的同义词映射生成的。 每条规则都有一个 ID,对应于产品名称的 slug 格式,以及由 LLM 计算得出的同义词列表。
import json
import loggingfrom elasticsearch import Elasticsearch
from slugify import slugifyes = Elasticsearch("http://localhost:9200",api_key="your_api_key"
)def mount_synonyms(results):synonyms_set = [{"id": slugify(product), "synonyms": synonyms} for product, synonyms inresults.items()]try:response = es.synonyms.put_synonym(id="products-synonyms-set",synonyms_set=synonyms_set)logging.info(json.dumps(response.body, indent=4))return response.bodyexcept Exception as e:logging.error(f"Error create synonyms: {str(e)}")return None以下是创建同义词集的请求负载:
{"synonyms_set":[{"id": "iphone-14-pro","synonyms": "iPhone, smartphone, mobile, handset"},{"id": "macbook-pro-16-inch","synonyms": "MacBook, Laptop, Notebook, Computer"},{"id": "samsung-galaxy-tab-s8","synonyms": "Tablet, Slate, Pad, Device"},{"id": "garmin-forerunner-945","synonyms": "Forerunner, smartwatch, fitness watch, GPS watch"},{"id": "bose-quietcomfort-35-headphones","synonyms": "Headphones, Earphones, Headset, Cans"}]
}在集群中创建了同义词集后,我们可以进入下一步,即使用定义的同义词集创建一个带有同义词支持的新索引。
下面是使用 LLM 生成的同义词和通过 Synonyms API 定义的同义词集创建的完整 Python 代码:
import json
import loggingfrom elasticsearch import Elasticsearch
from openai import OpenAI
from slugify import slugifylogging.basicConfig(level=logging.INFO)client = OpenAI(api_key="your-key",
)es = Elasticsearch("http://localhost:9200",api_key="your_api_key"
)def call_gpt(prompt, model):try:logging.info("generate synonyms by llm...")response = client.chat.completions.create(model=model,messages=[{"role": "user", "content": prompt}],temperature=0.7,max_tokens=1000)content = response.choices[0].message.content.strip()return contentexcept Exception as e:logging.error(f"Failed to use model: {e}")return Nonedef generate_synonyms(category, products):synonyms = {}for product in products:prompt = f"You are an expert in generating synonyms for products. Based on the category and product name provided, generate synonyms or related terms. Follow these rules:\n"prompt += "1. **Format**: The first word should be the main item (part of the product name, excluding the brand), followed by up to 3 synonyms separated by commas.\n"prompt += "2. **Exclude the brand**: Do not include the brand name in the synonyms.\n"prompt += "3. **Maximum synonyms**: Generate a maximum of 3 synonyms per product.\n\n"prompt += f"The category is: **{category}**, and the product is: **{product}**. Return only the synonyms in the requested format, without additional explanations."response = call_gpt(prompt, "gpt-4o")synonyms[product] = responsereturn synonymsdef get_products(category):query = {"size": 50,"_source": ["name"],"query": {"bool": {"filter": [{"term": {"category.keyword": category}}]}}}response = es.search(index="products", body=query)if response["hits"]["total"]["value"] > 0:product_names = [hit["_source"]["name"] for hit in response["hits"]["hits"]]return product_nameselse:return []def mount_synonyms(results):synonyms_set = [{"id": slugify(product), "synonyms": synonyms} for product, synonyms inresults.items()]try:es_client = get_client_es()response = es_client.synonyms.put_synonym(id="products-synonyms-set",synonyms_set=synonyms_set)logging.info(json.dumps(response.body, indent=4))return response.bodyexcept Exception as e:logging.error(f"Erro update synonyms: {str(e)}")return Noneif __name__ == '__main__':category = "Electronics"products = get_products("Electronics")llm_synonyms = generate_synonyms(category, products)mount_synonyms(llm_synonyms)创建支持同义词的索引
将创建一个新索引,其中所有来自 products 索引的数据将被重新索引。该索引将使用 synonyms_filter,该过滤器应用之前创建的 products-synonyms-set。
下面是配置为使用同义词的索引映射:
PUT products_02
{"settings": {"analysis": {"filter": {"synonyms_filter": {"type": "synonym","synonyms_set": "products-synonyms-set","updateable": true}},"analyzer": {"synonyms_analyzer": {"type": "custom","tokenizer": "standard","filter": ["lowercase","synonyms_filter"]}}}},"mappings": {"properties": {"ID": {"type": "long"},"category": {"type": "keyword"},"name": {"type": "text","analyzer": "standard","search_analyzer": "synonyms_analyzer"}}}
}重新索引 products 索引
现在,我们将使用 Reindex API 将数据从 products 索引迁移到新的 products_02 索引,该索引包括同义词支持。以下代码在 Kibana DevTools 中执行:
POST _reindex
{"source": {"index": "products"},"dest": {"index": "products_02"}
}迁移后,products_02 索引将被填充并准备好验证使用配置的同义词集的搜索。
使用同义词验证搜索
让我们比较两个索引之间的搜索结果。我们将在两个索引上执行相同的查询,并验证是否使用同义词来检索结果。
在 products 索引中搜索(没有同义词)
我们将使用 Kibana 执行搜索并分析结果。在 Analytics > Discovery 菜单中,我们将创建一个数据视图来可视化我们创建的索引中的数据。
在 Discovery 中,点击 Data View 并定义名称和索引模式。对于 "products" 索引,我们将使用 "products" 模式。然后,我们将重复这个过程,为 "products_02" 索引创建一个新的数据视图,使用 "products_02" 模式。
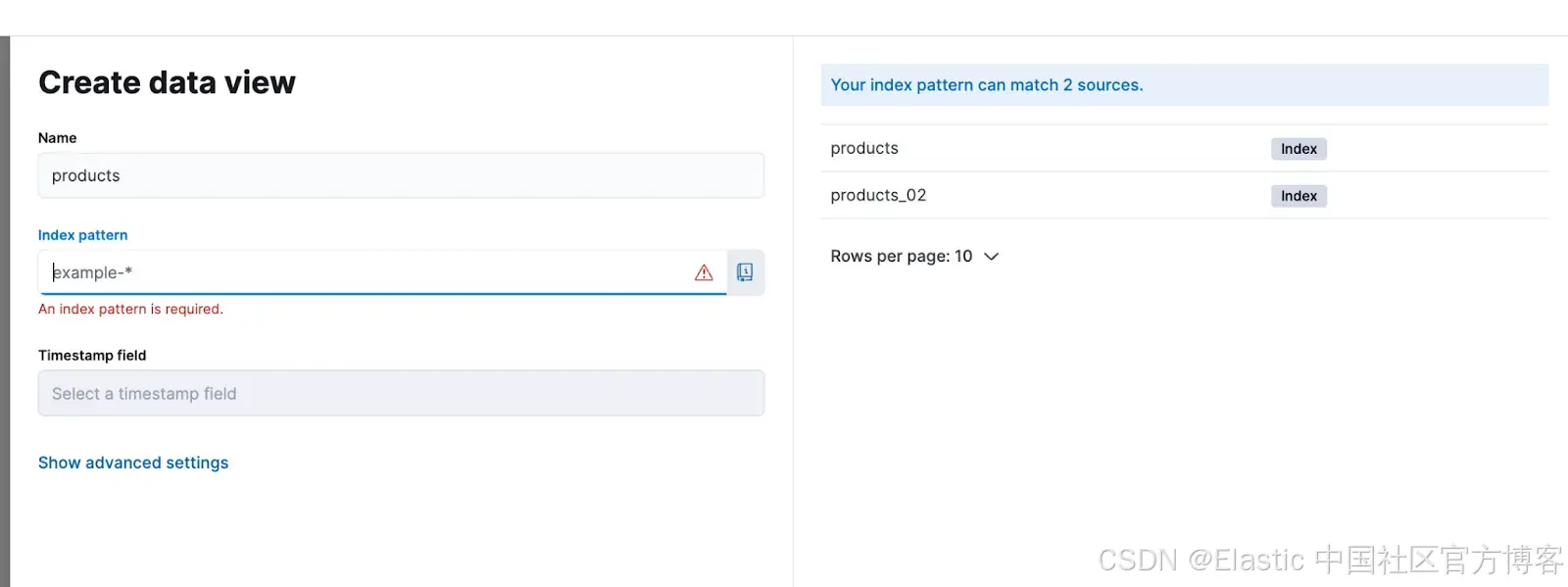
配置好数据视图后,我们可以返回 Analytics > Discovery 并开始验证。
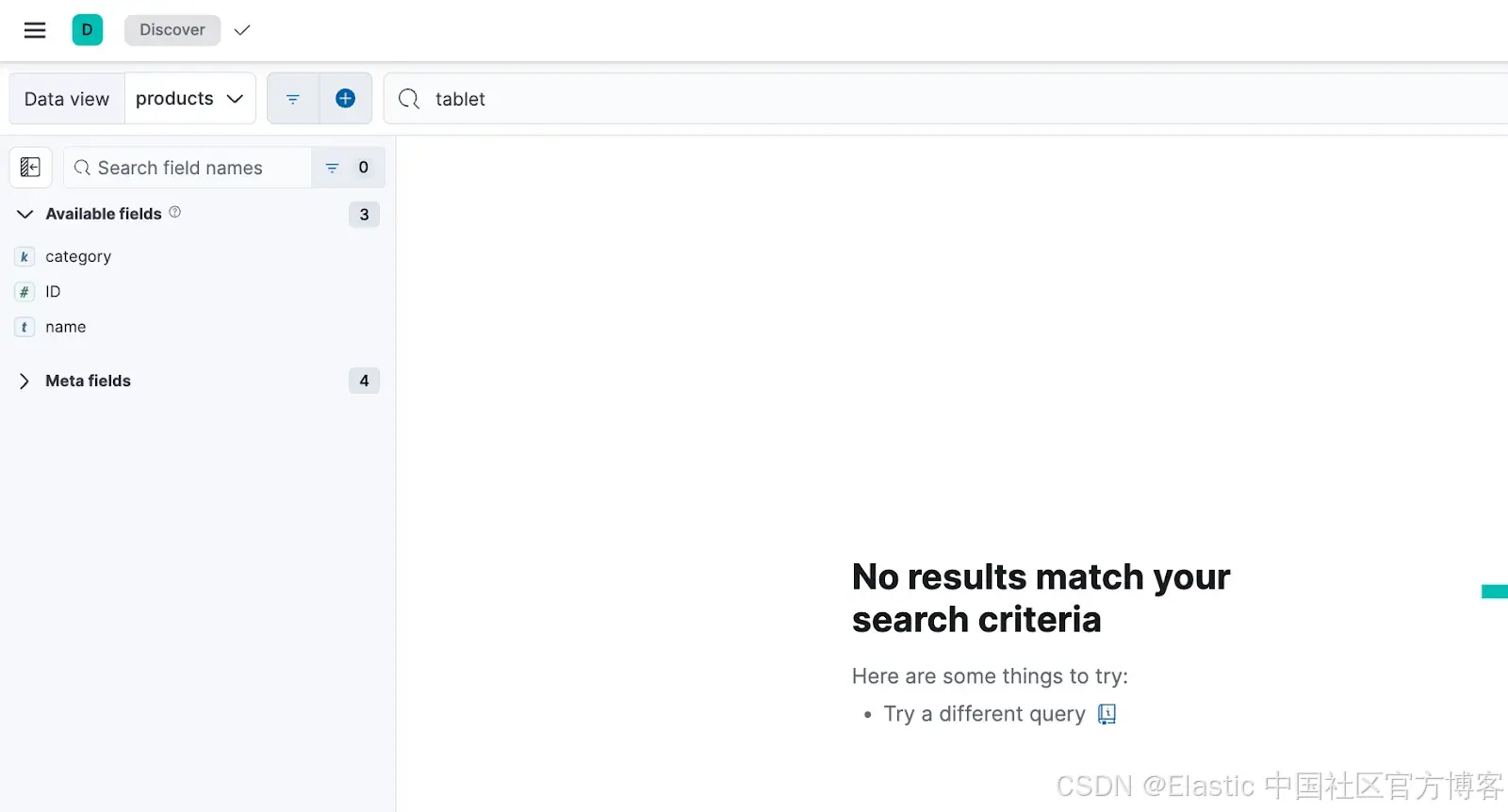
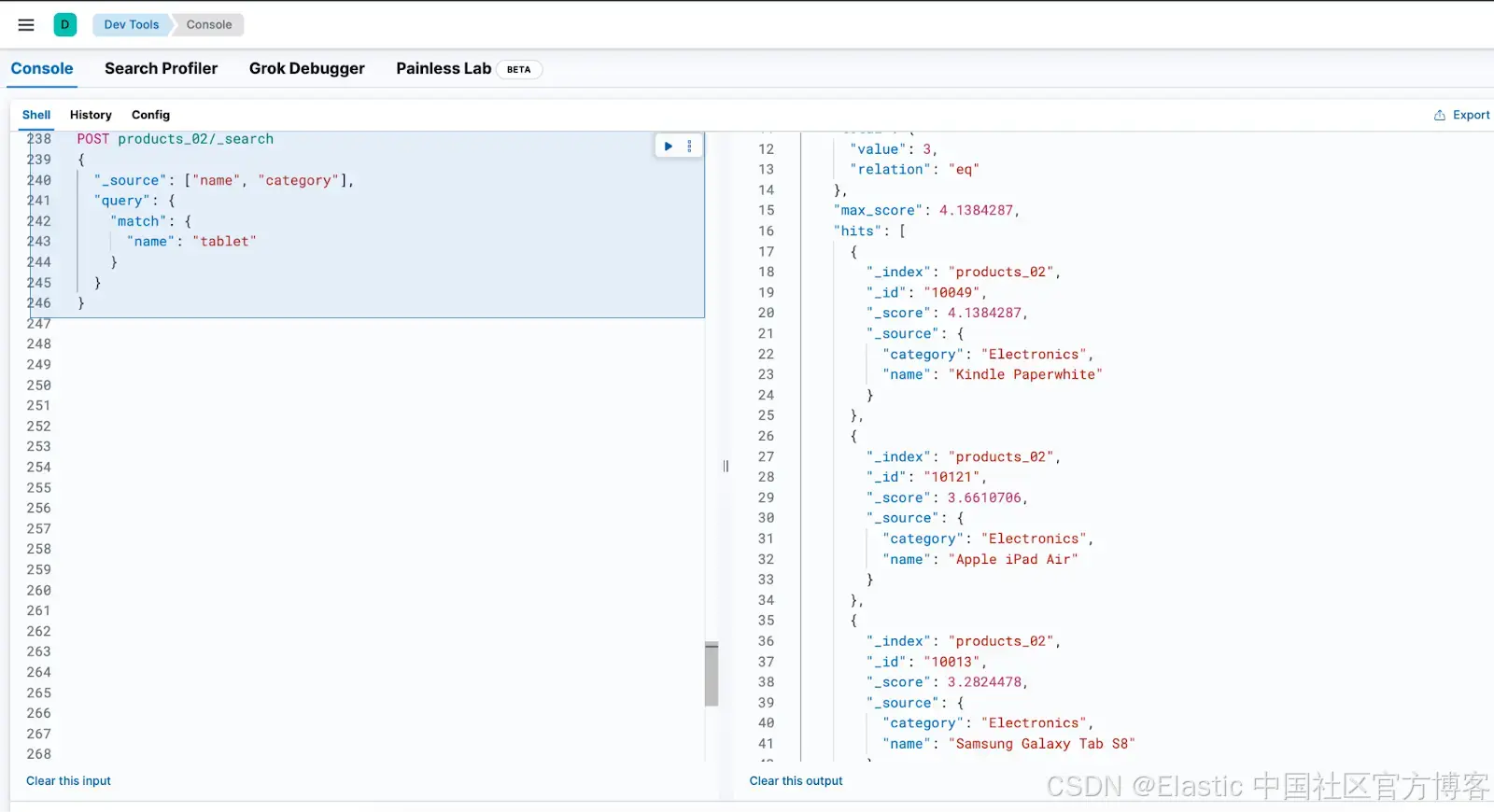
在这里,选择 DataView products 并搜索术语 "tablet" 后,我们没有得到任何结果,尽管我们知道有像 "Kindle Paperwhite" 和 "Apple iPad Air" 这样的产品。
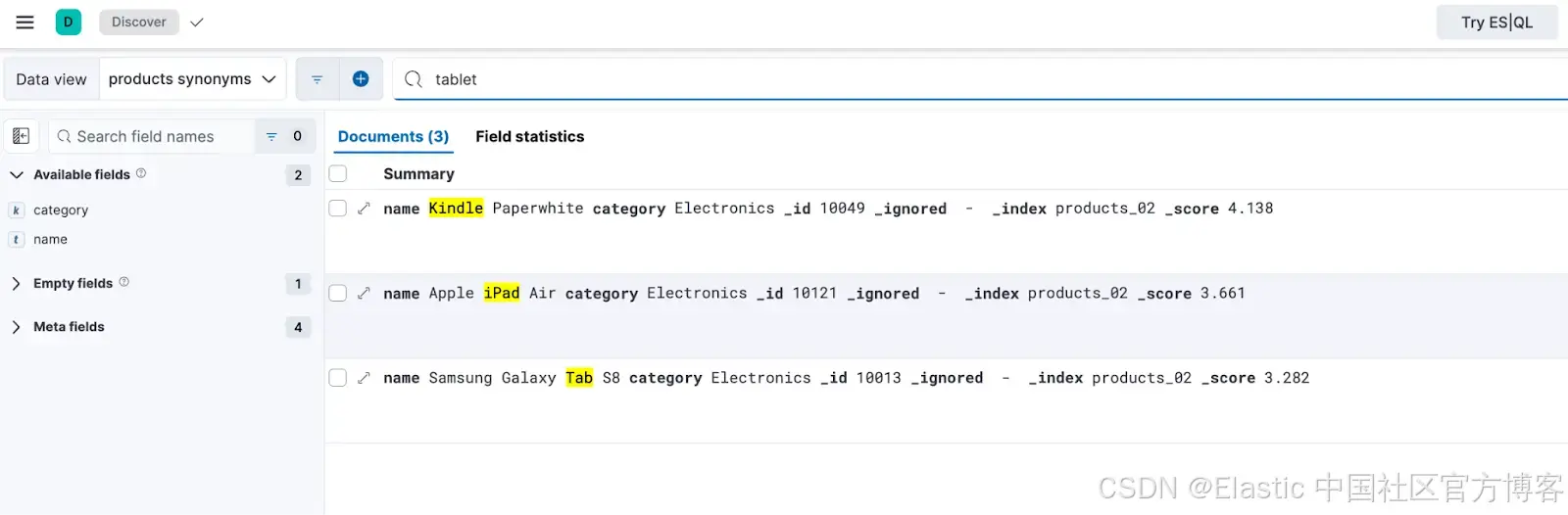
在 products_02 索引中搜索(支持同义词)
在支持同义词的 "products_synonyms" 数据视图上执行相同的查询时,产品成功地被检索到了。这证明了配置的同义词集正常工作,确保搜索词的不同变体返回预期的结果。
我们可以通过直接在 Kibana DevTools 中运行相同的查询来实现相同的结果。只需使用 Elasticsearch Search API 搜索 products_02 索引:
结论
在 Elasticsearch 中实现同义词提高了产品目录搜索的准确性和覆盖面。关键的区别在于使用了 LLM,它自动且上下文相关地生成同义词,消除了预定义列表的需求。该模型分析了产品名称和类别,确保了与电子商务相关的同义词。
此外,Synonyms API 简化了词典管理,允许动态修改同义词集。通过这种方法,搜索变得更加灵活,能够适应不同的用户查询模式。
这一过程可以通过新数据和模型调整不断改进,确保越来越高效的研究体验。
参考资料
在本地运行 Elasticsearch
Run Elasticsearch locally | Elasticsearch Guide [8.17] | Elastic
Synonyms API
Synonyms APIs | Elasticsearch Guide [8.17] | Elastic
想获得 Elastic 认证?了解下次 Elasticsearch 工程师培训的时间!
Elasticsearch 拥有丰富的新功能,帮助你为使用案例构建最佳搜索解决方案。深入了解我们的示例笔记本,了解更多内容,开始免费云试用,或立即在本地机器上尝试 Elastic。
原文:How to automate synonyms and upload using our Synonyms API - Elasticsearch Labs






