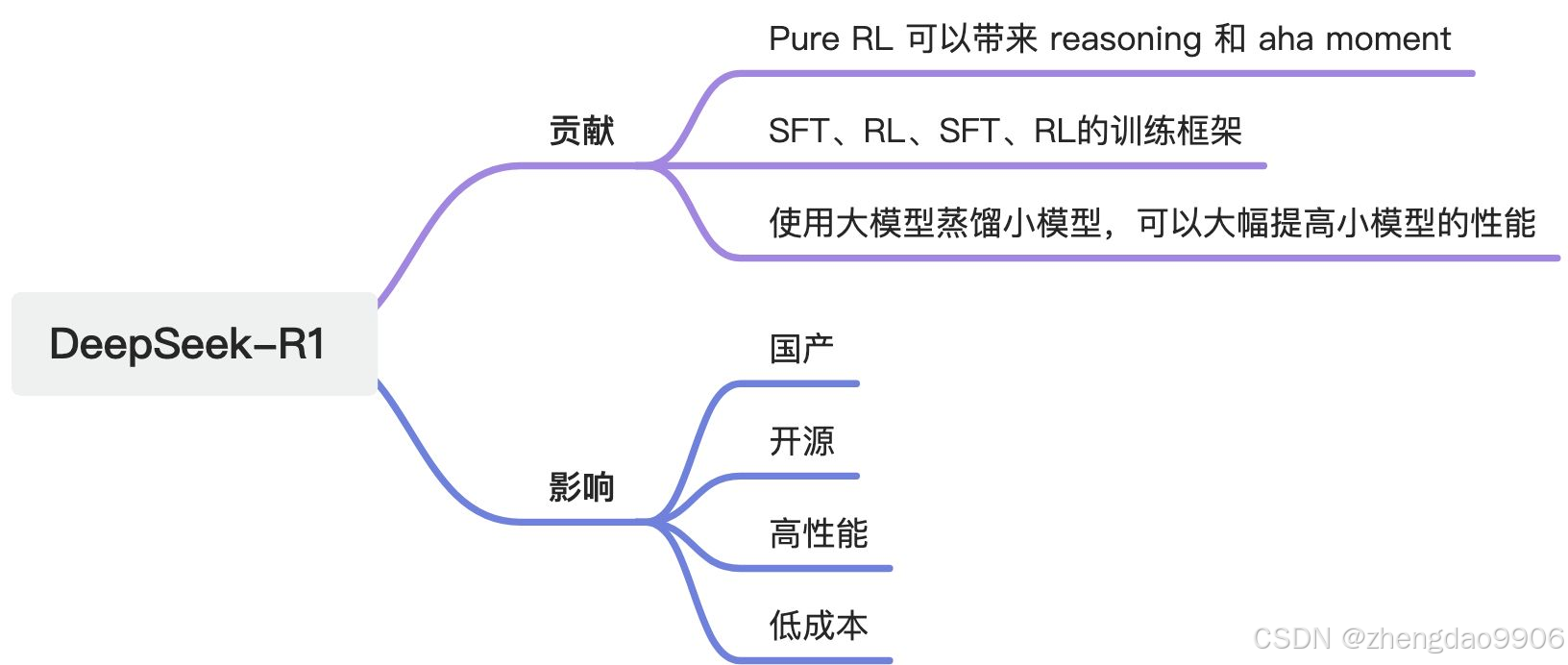
最强开源LLM,性能和效果都很棒;在数学、代码这种有标准正确答案的场景,表现尤为突出;一些其他场景的效果,可能不如DeepSeek-V3和Qwen。
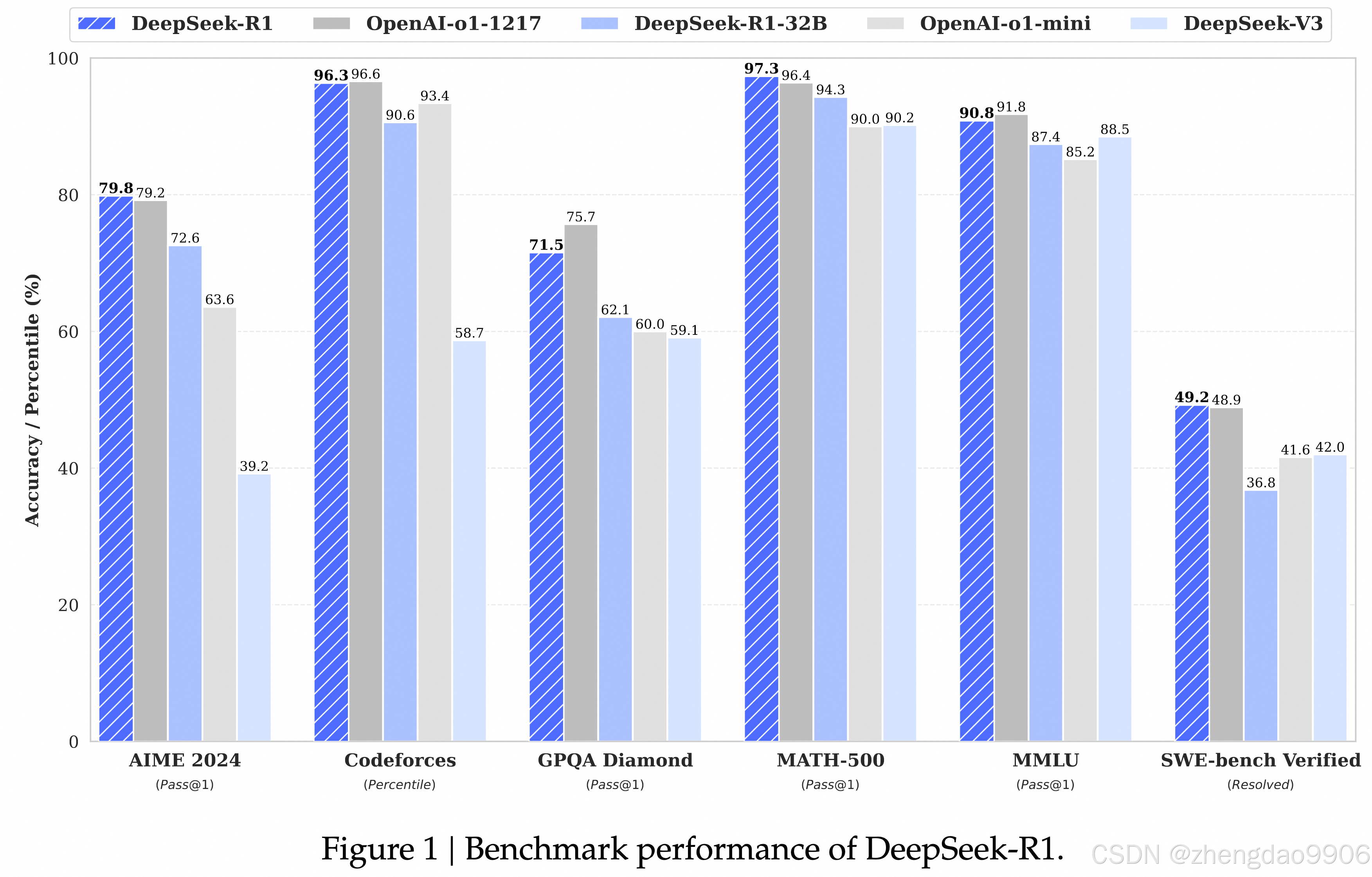
Deepseek-R1没有使用传统的有监督微调sft方法来优化模型,而使用了大规模强化学习RL来实现推理能力的提升。更进一步,通过引入冷启动解决仅RL遇到的缺陷。
以往的研究工作大多依赖于大量的监督数据来提升模型性能。在本研究中展示了即使不依赖监督微调(SFT)作为预训练步骤,通过大规模强化学习(RL)也能显著提升推理能力。此外,我们还展示了通过引入少量冷启动数据可以进一步提升性能。在接下来的章节中,将按顺序介绍:
(1)DeepSeek-R1-Zero,它直接在基础模型上应用 RL,不依赖任何监督微调数据;介绍了如何直接在基础模型上进行大规模强化学习,无需监督微调数据。
(2)DeepSeek-R1,它从经过长推理链(Chain-of-Thought, CoT)数据微调的检查点开始应用 RL;介绍了多阶段训练流程如何打造出性能卓越的推理模型。
(3)将 DeepSeek-R1 的推理能力蒸馏到小型dense模型中,介绍了如何将大模型的推理能力有效转移到小模型中。

DeepSeek-R1-Zero

RL算子
为了节省 RL 的训练成本,我们采用了 Group Relative Policy Optimization(GRPO)。GRPO 放弃了通常与策略模型大小相同的批判模型(critic model),而是通过组分数来估计Baseline。

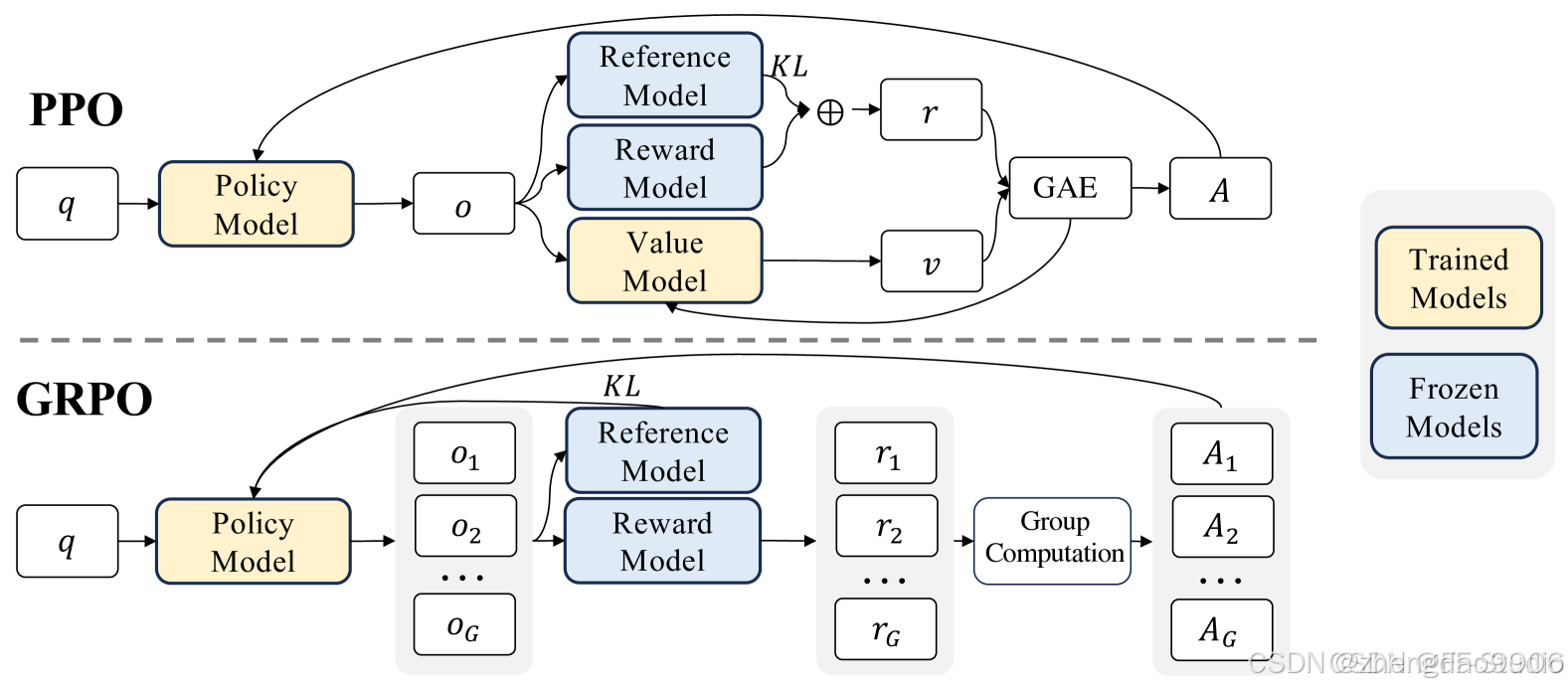
奖励模型
在这一步,只使用了基于规则的奖励模型。
奖励是训练信号的来源,决定了 RL 的优化方向。为了训练 DeepSeek-R1-Zero,我们采用基于规则的奖励系统,主要包括以下两种奖励:
● 准确性奖励:准确性奖励模型用于评估回答是否正确。例如,在数学问题中,模型需要以指定格式(例如在方框内)提供最终答案,以便可靠地通过基于规则的验证来确认正确性。同样,在 LeetCode 问题中,可以使用编译器根据预定义的测试用例生成反馈。
● 格式奖励:除了准确性奖励模型外,我们还采用格式奖励模型,强制模型将推理过程放在 和 标签之间。
没有在开发 DeepSeek-R1-Zero 时应用结果或过程神经奖励模型,因为我们发现神经奖励模型可能在大规模强化学习过程中出现奖励劫持(reward hacking)的问题,而重新训练奖励模型需要额外的训练资源,并且会使整个训练流程复杂化。
为了训练 DeepSeek-R1-Zero,设计了一个简单的模板,指导基础模型按照我们的指定指令进行操作。如上表所示,该模板要求 DeepSeek-R1-Zero 首先生成推理过程,然后提供最终答案。我们故意将约束限制在这一结构化格式上,避免任何内容相关的偏见——例如强制要求反思性推理或推广特定的解决问题策略——以确保我们能够准确观察模型在强化学习(RL)过程中的自然发展。
相关发现&总结
- “顿悟时刻”
在这个阶段,DeepSeek-R1-Zero 学会为问题分配更多的思考时间,通过重新评估其初始方法来实现。这种行为不仅是模型推理能力增长的证明,也是研究人员观察其行为的一个“顿悟时刻”。
它突显了强化学习的力量和美丽:我们不是明确地教模型如何解决问题,而是仅仅提供正确的激励,模型就会自主发展出高级的问题解决策略。“顿悟时刻” 有力地提醒我们,RL 解锁人工系统中智力新水平的潜力,为未来更自主、更适应性强的模型铺平了道路。 - DeepSeek-R1-Zero 的缺点
尽管 DeepSeek-R1-Zero 展示了强大的推理能力,并且能够自主发展出意外且强大的推理行为,但它面临着一些问题。例如,DeepSeek-R1-Zero 在可读性方面表现不佳,存在语言混用的问题。
DeepSeek-R1
受到 DeepSeek-R1-Zero 令人鼓舞的结果的启发,自然会提出两个问题:
1)通过引入少量高质量数据作为冷启动,是否可以进一步提升推理性能或加速收敛?
2)如何训练一个用户友好的模型,使其不仅能够产生清晰连贯的推理链(CoT),还具备强大的通用能力?
为了解决这些问题,我们重新设计了 DeepSeek-R1 的训练流程。该流程包括以下四个阶段:
● 冷启动:增加上千条CoT数据,引入人类先验知识,在DeepSeek-V3的基础上进行迭代优化,增加整体模型的可读性。在DeepSeek-V3-Base的基础上,让模型具备更好的可读性、回答模版以及潜力。
● 面向推理的强化学习,引入语言一致性奖励:计算方法是 CoT 中目标语言单词的比例。训练到在归因任务上收敛。该步骤类似DeepSeek-R1-Zero,但是额外增加了语言一致性奖励函数。
● 拒绝采样与监督微调:对于每个提示,采样多个回答,并仅保留正确的回答,提高数据质量。将标准答案和模型输出一起输入给DeepSeek-V3,令其判断是否采样该样本。总共收集了大约 600k 条与推理相关的训练样本。
● 面向所有场景的强化学习:旨在提升模型的有用性(泛化性)和无害性,同时优化其推理能力。具体来说,使用组合的奖励信号和多样化的提示分布来训练模型。
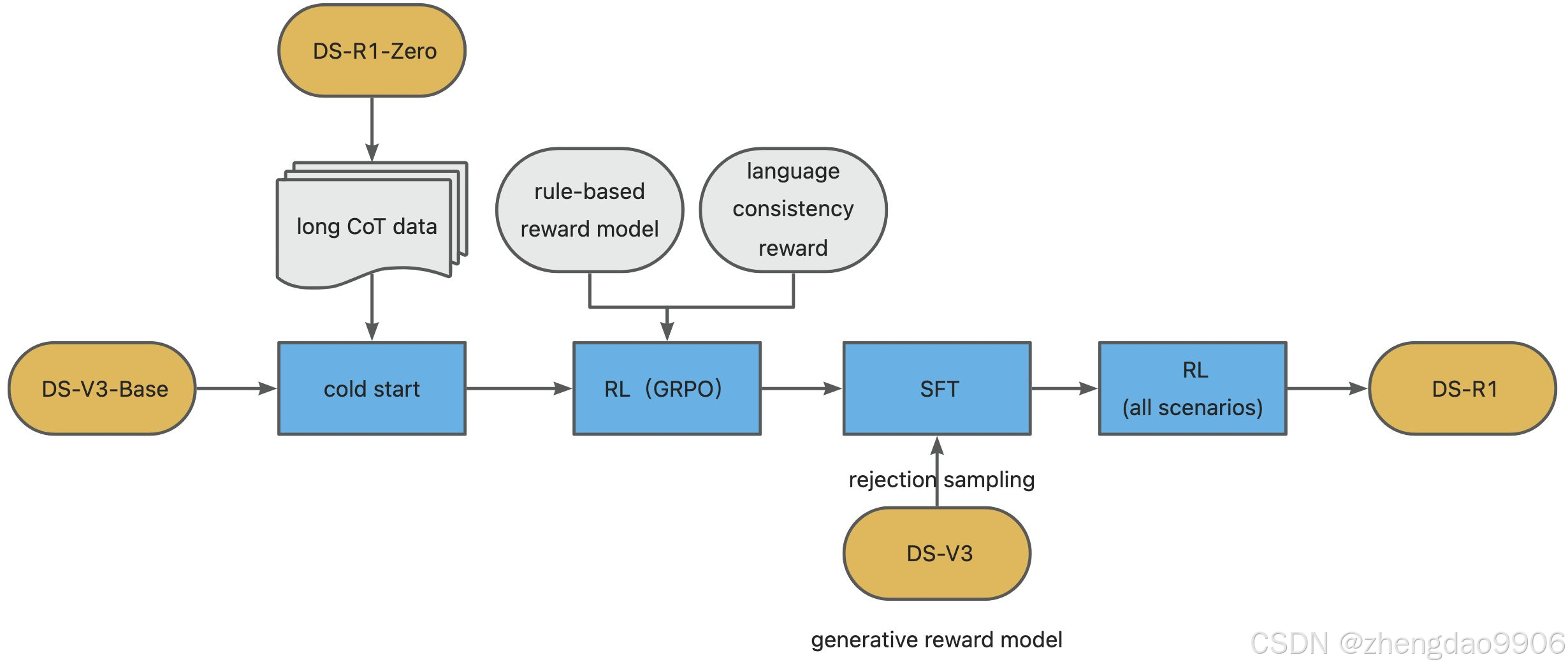
知识蒸馏
为了使更高效的小模型具备像 DeepSeek-R1 这样的推理能力,我们直接使用 DeepSeek-R1 生成的 800k 样本对开源模型(如 Qwen 和 Llama)进行微调,详细过程如上节所述。我们的研究结果表明,这种简单的蒸馏方法显著提升了小型模型的推理能力。
我们使用的基底模型包括 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。我们选择 Llama-3.3 是因为其推理能力略优于 Llama-3.1。
需要注意的是:对于蒸馏模型,我们仅应用了 SFT,并没有 RL 阶段,尽管加入 RL 可能会显著提升模型性能。我们的主要目标是展示蒸馏技术的有效性,将 RL 阶段的探索留给更广泛的学术界。
结合后文的实验结果,知识蒸馏主要有两个结论:
● 将更强大的模型的能力蒸馏到小型模型中可以取得出色的结果,而小型模型仅依靠本文提到的大规模 RL 训练需要巨大的计算资源,且可能无法达到蒸馏的效果。
● 虽然蒸馏策略既经济又有效,但要突破智能的边界,可能仍然需要更强大的基础模型和更大规模的强化学习。
参考资料:
● Github:https://github.com/deepseek-ai/DeepSeek-R1
● CSDN:https://blog.csdn.net/qq_38961840/article/details/145384852
● 论文:
http://arxiv.org/abs/2401.02954
http://arxiv.org/abs/2501.12948






