目录
一. 线程概念
1.1什么是线程
1.2分页式存储管理
1.2.1虚拟地址和页表的由来
1.2.2物理内存管理
1.2.3页表
1.2.4页目录结构
1.2.5二级页表地址转换
1.3线程的优点
二.进程VS线程
三.Linux线程控制
3.1POSIX线程库
3.2创建线程
编辑
pthread库是个什么东西
tid???
返回值
3.3pthread_create参数可以是任意类型
3.4线程终止
3.5分离线程
四.线程ID及进程地址空间布局
4.1部分源码
4.2线程栈
五.线程封装
线程的局部存储
一. 线程概念
1.1什么是线程
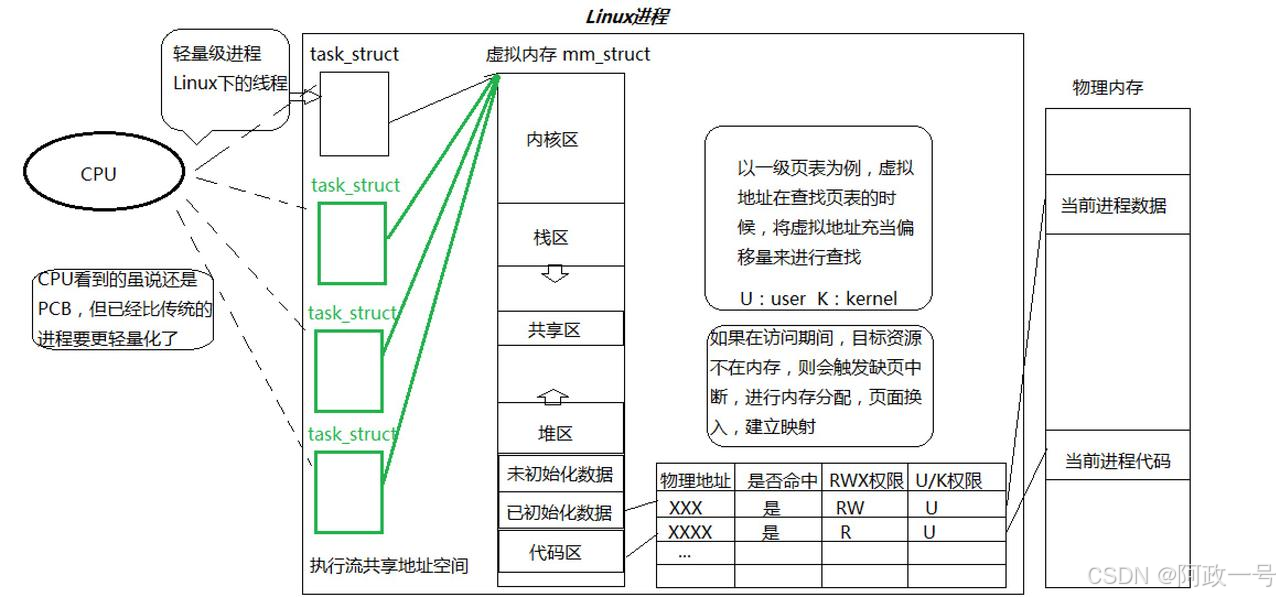
• 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
• 一切进程至少都有一个执行线程
• 线程在进程内部运行,本质是在进程地址空间内运行
• 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
• 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形 成了线程执行流
1.2分页式存储管理
1.2.1虚拟地址和页表的由来
如果没有虚拟地址和页表的话,每一个用户程序在物理内存上所对应的空间必须是连续的:
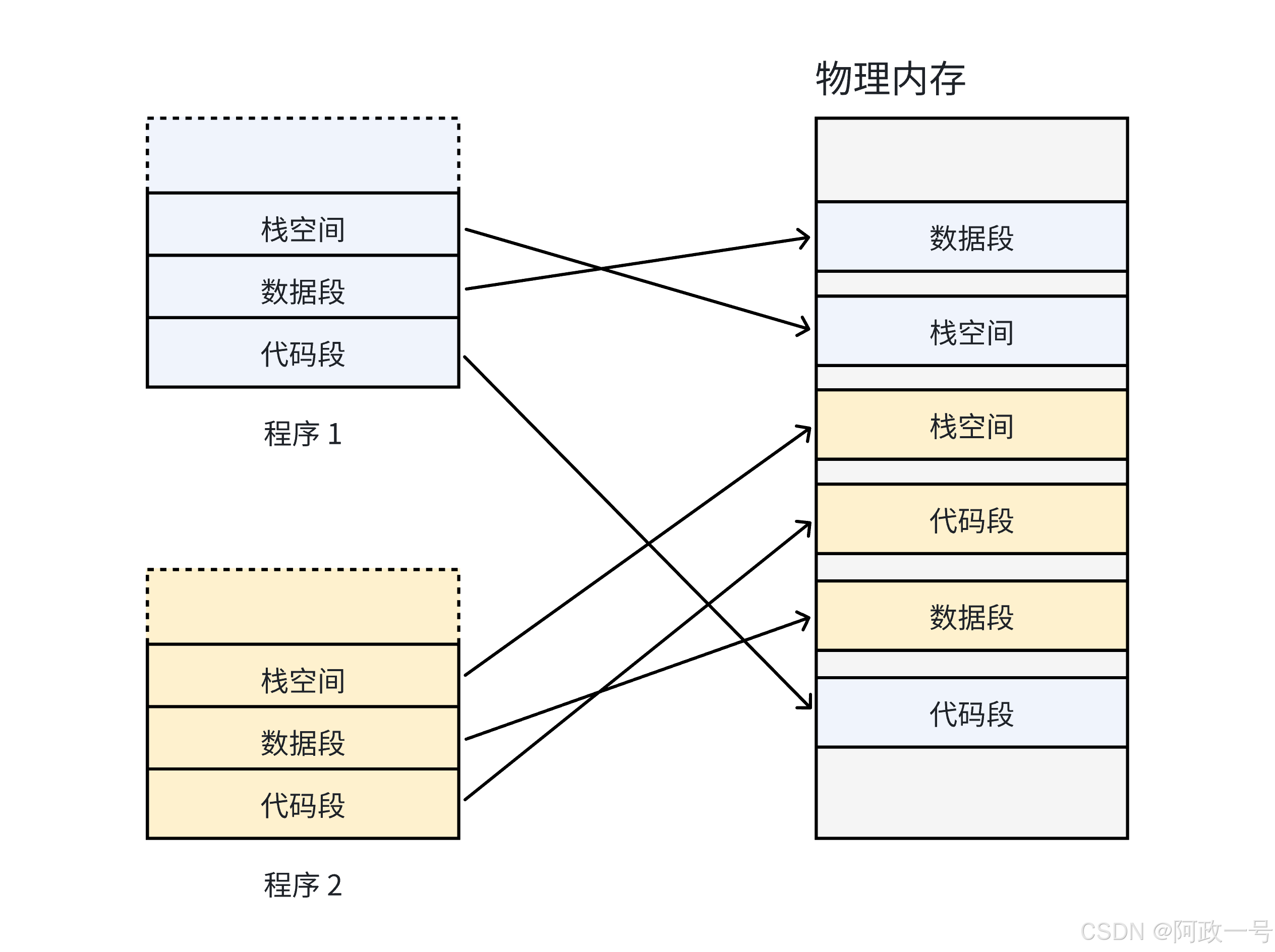
因为每一个程序的代码、数据长度都是不一样的,按照这样的映射方式,物理内存将会被分割成各种离散的、大小不同的块。经过一段运行时间之后,有些程序会退出,那么它们占据的物理内存空间可以被回收,导致这些物理内存都是以很多碎片的形式存在(假如程序一的栈空间被释放了4kb,现在要申请2kb,就必然有空间碎片)。而且如果我的代码段的函数跳转指向了其他程序的空间呢?这就出大问题了
我们希望操作系统提供用户的空间必须是连续的,但是物理内存最好不要连续。此时虚拟内存和分页便出现了:
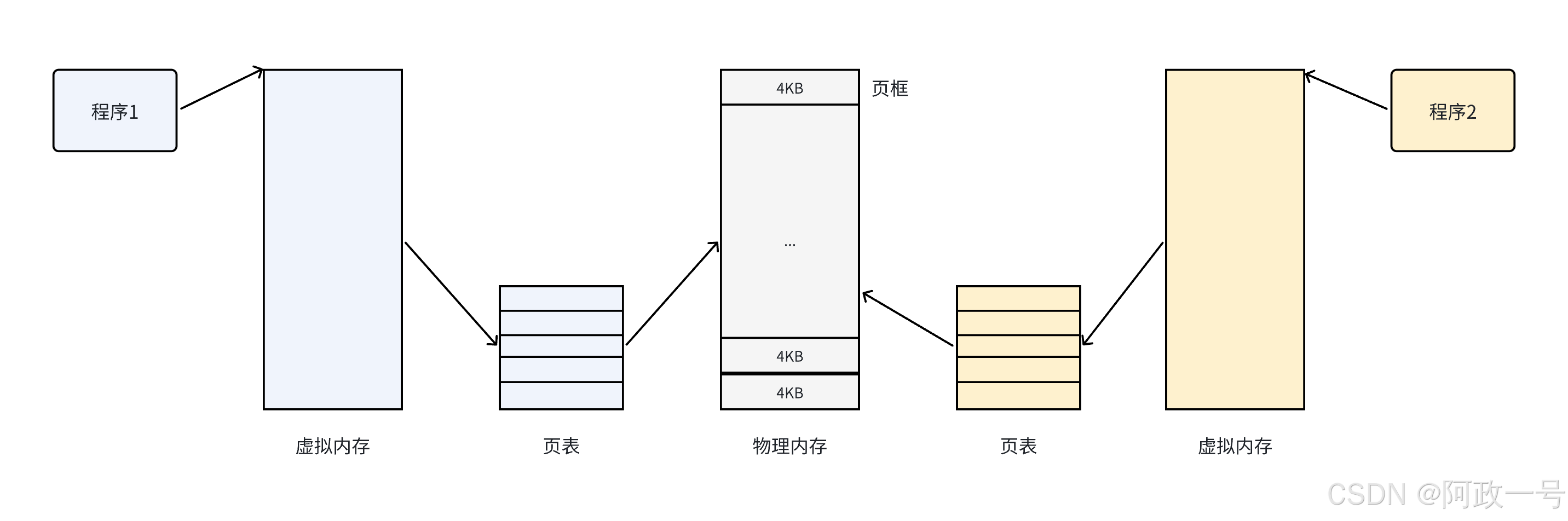
把物理内存按照一个固定的长度的页框进行分割,有时叫做物理页。每个页框包含一个物理页 (page)。一个页的大小等于页框的大小。大多数 32位 体系结构支持 4KB 的页,而 64位 体系结构一般会支持 8KB 的页。区分一页和一个页框是很重要的:
• 页框是一个存储区域;
• 而页是一个数据块,可以存放在任何页框或磁盘中。
页是虚拟内存的逻辑单位,用于把进程的地址空间划分成固定大小的块;而页框是物理内存的实际单位,用于存储和管理页面数据。
操作系统通过将虚拟地址空间和物理内存地址之间建立映射关系,也就是页表,这张表上记录了每一对页和页框的映射关系,能让CPU间接的访问物理内存地址。
其思想是将虚拟内存下的逻辑地址空间分为若干页,将物理内存空间分为若干页框,通过页表便能把连续的虚拟内存,映射到若干个不连续的物理内存页。这样就解决了使用连续的物理内存造成的碎片问题。
1.2.2物理内存管理
假设一个可用的物理内存有 4GB 的空间。按照一个页框的大小 4KB 进行划分, 4GB 的空间就是 4GB/4KB = 1048576 个页框。有这么多的物理页,操作系统肯定是要将其管理起来的,操作系统 需要知道哪些页正在被使用,哪些页空闲等等。
内核用 struct page 结构表示系统中的每个物理页,出于节省内存的考虑, struct page 中使用了大量的联合体union。

部分参数:
1. flags :用来存放页的状态。这些状态包括页是不是脏的,是不是被锁定在内存中等。flag的每一位单独表示一种状态,所以它至少可以同时表示出32种不同的状态。这些标志定义在 中。其中一些比特位非常重要,如PG_locked用于指定页是否锁定, PG_uptodate用于表示页的数据已经从块设备读取并且没有出现错误。
2. _mapcount :表示在页表中有多少项指向该页,也就是这一页被引用了多少次。当计数值变 为-1时,就说明当前内核并没有引用这一页,于是在新的分配中就可以使用它。
3. virtual :是页的虚拟地址。通常情况下,它就是页在虚拟内存中的地址。有些内存(即所谓的高端内存)并不永久地映射到内核地址空间上。在这种情况下,这个域的值为NULL,需要的时候,必须动态地映射这些页。 (有时候操作系统需要从物理地址转换为虚拟地址)
要注意的是 struct page 与物理页相关,而并非与虚拟页相关。
算 struct page 占40个字节的内存吧,假定系统的物理页为 4KB 大小,系统有 4GB 物理内存。 那么系统中共有页面 1048576 个(1兆个),所以描述这么多页面的page结构体消耗的内存只不过 40MB ,相对系统 4GB 内存而言,仅是很小的一部分罢了。因此,要管理系统中这么多物理页面,这 个代价并不算太大。
要知道的是,页的大小对于内存利用和系统开销来说非常重要,页太大,页必然会剩余较大不能利 用的空间(页内碎片)。页太小,虽然可以减小页内碎片的大小,但是页太多,会使得页表太长而占用内存,同时系统频繁地进行页转化,加重系统开销。因此,页的大小应该适中,通常为 512B - 8KB ,windows系统的页框大小为4KB。
1.2.3页表
页表中的每一个表项,指向一个物理页的开始地址。在 32 位系统中,虚拟内存的最大空间是 4GB , 这是每一个用户程序都拥有的虚拟内存空间。既然需要让 4GB 的虚拟内存全部可用,那么页表中就需要能够表示这所有的 4GB 空间,那么就一共需要 4GB/4KB = 1048576 个表项。
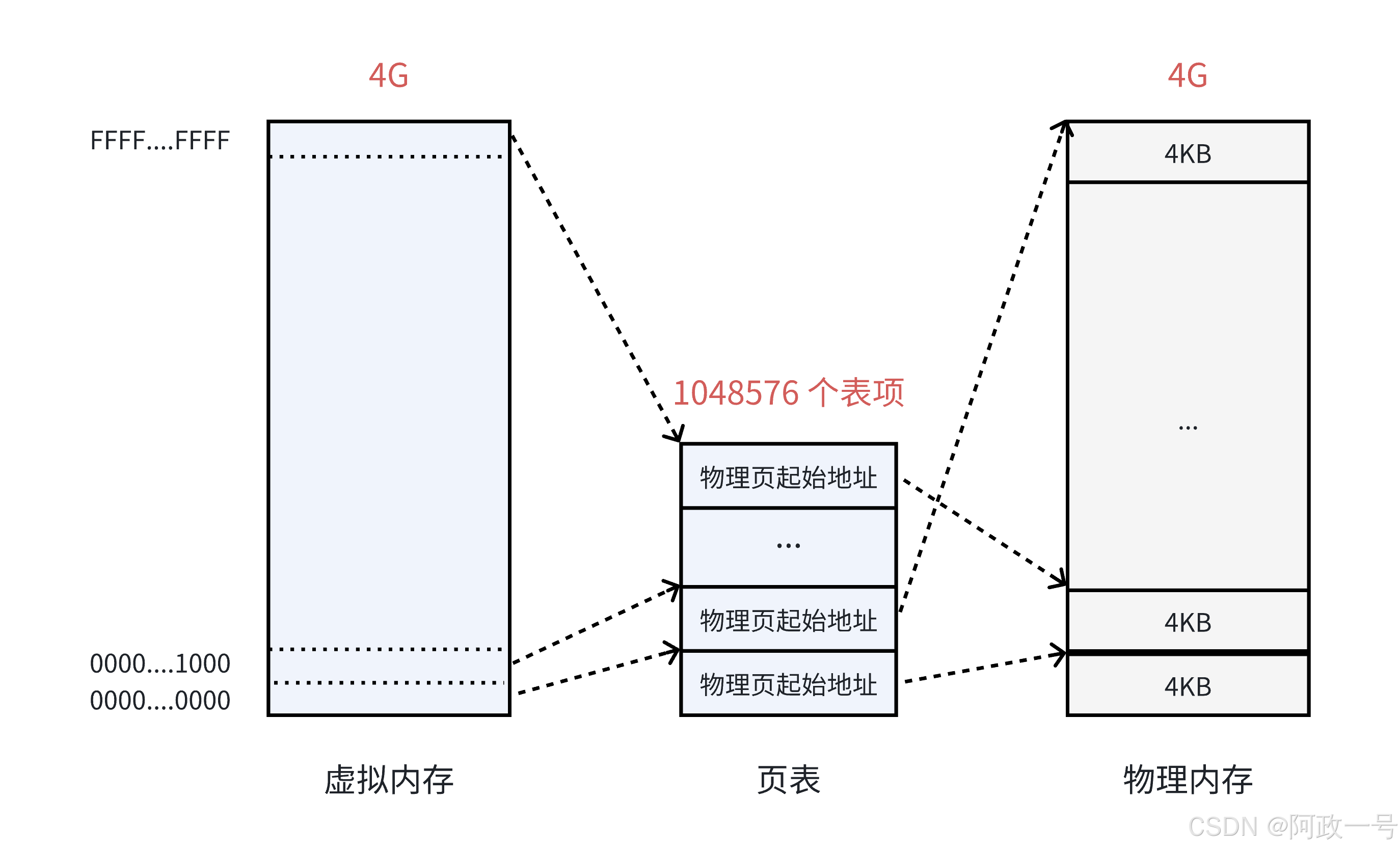
页表中的物理地址,与物理内存之间,是随机的映射关系,哪里可用就指向哪里(物理页)。虽然最终使用的物理内存是离散的,但是与虚拟内存对应的线性地址是连续的。处理器在访问数据、获取指令时,使用的都是线性地址,只要它是连续的就可以了,最终都能够通过页表找到实际的物理地址。
在 32 位系统中,地址的长度是 4 个字节,那么页表中的每一个表项就是占用 4 个字节。所以页表占据的总空间大小就是: 1048576*4 = 4MB 的大小。也就是说映射表自己本身,就要占用 4MB / 4KB = 1024 个物理页。
• 回想一下,当初为什么使用页表,就是要将进程划分为一个个页可以不用连续的存放在物理内存 中,但是此时页表就需要1024个连续的页框,似乎和当时的目标有点背道而驰了......
• 此外,根据局部性原理可知,很多时候进程在一段时间内只需要访问某几个页就可以正常运行 了。因此也没有必要一次让所有的物理页都常驻内存。
解决需要大容量页表的最好方法是:把页表看成普通的文件,对它进行离散分配,即对页表再分页, 由此形成多级页表的思想。为了解决这个问题,可以把这个单一页表拆分成 1024 个体积更小的映射表。如下图所示。这样一来,1024(每个表中的表项个数)*1024(表的个数),仍然可以覆盖 4GB 的物理内存空间。
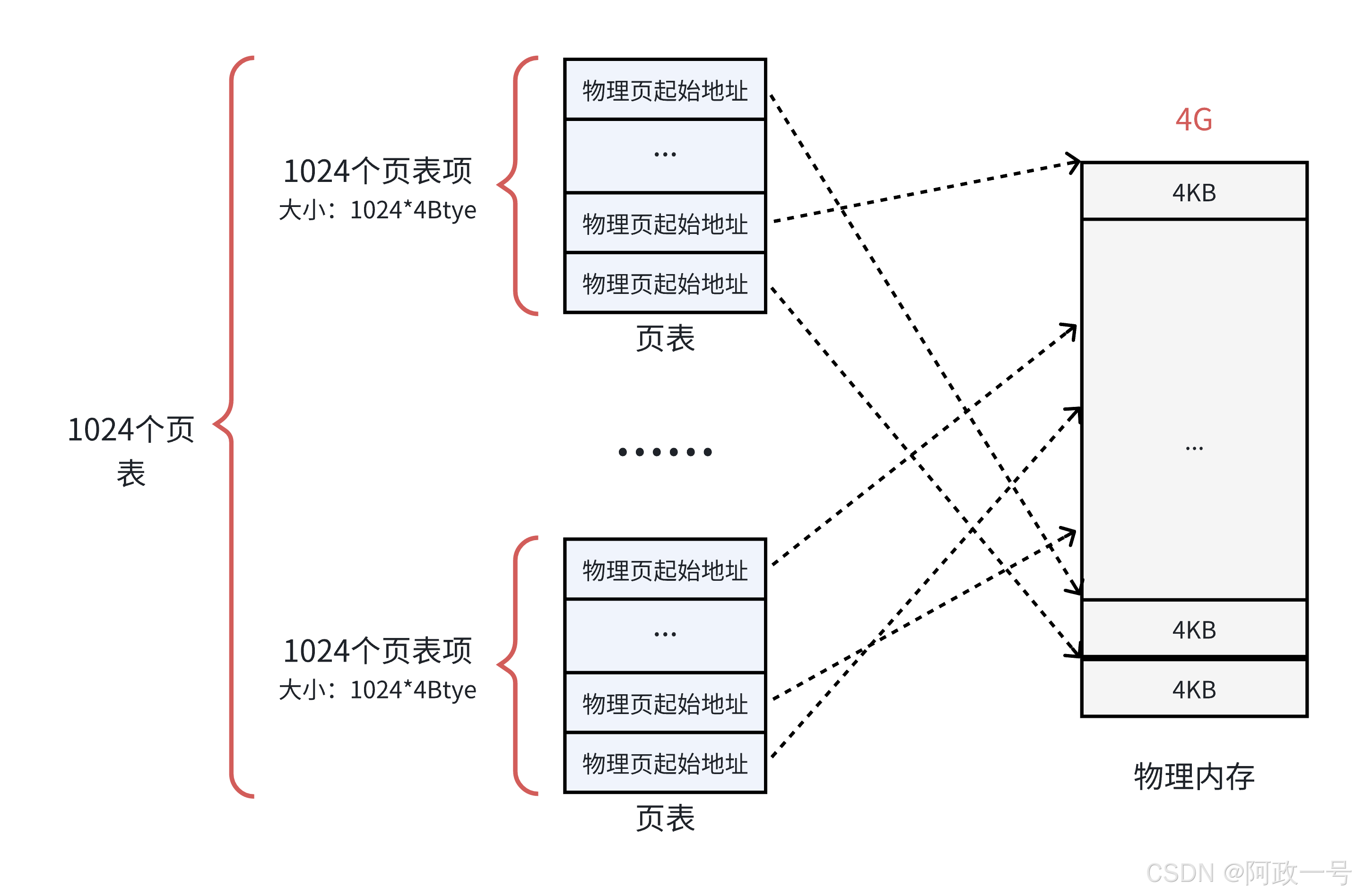
这里的每一个表,就是真正的页表,所以一共有 1024 个页表。一个页表自身占用 4KB ,那么 1024 个页表一共就占用了 4MB 的物理内存空间,和之前没差别啊?
从总数上看是这样,但是一个应用程序是不可能完全使用全部的 4GB 空间的,也许只要几十个页表就 可以了。例如:一个用户程序的代码段、数据段、栈段,一共就需要 10 MB 的空间,那么使用 3 个 页表就足够了。
每一个页表项指向一个4KB 的物理页,那么一个页表中 1024 个页表项,一共能覆盖 4MB 的物理内存;那么10MB的程序,向上对齐取整之后(4MB 的倍数,就是 12 MB),就需要 3 个页表就可以了。
1.2.4页目录结构
到目前为止,每一个页框都被一个页表中的一个表项来指向了,那么这 1024 个页表也需要被管理起来。管理页表的表称之为页目录表,形成二级页表。
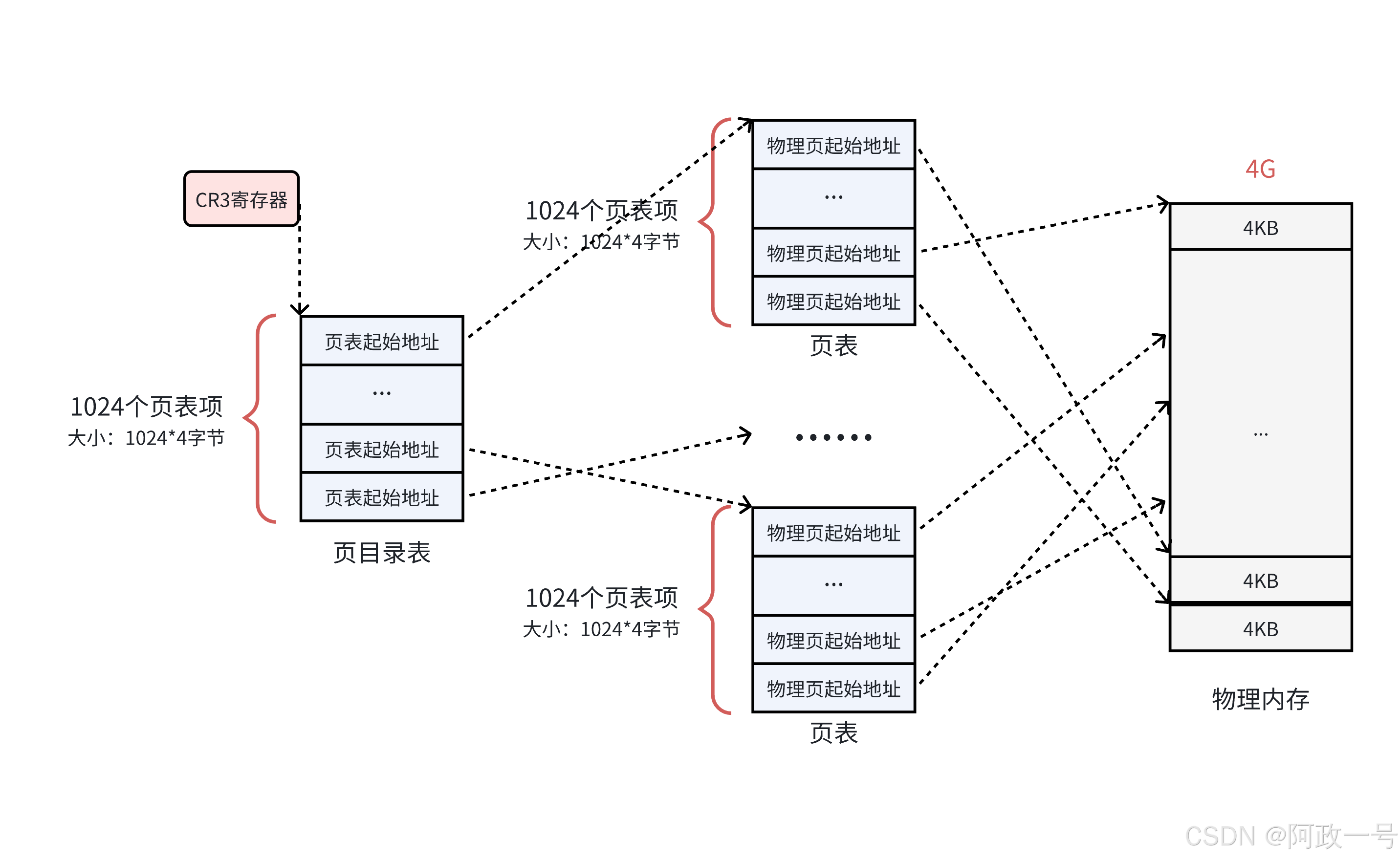
• 所有页表的物理地址被页目录表项指向
• 页目录的物理地址被 CR3 寄存器 指向,这个寄存器中,保存了当前正在执行任务的页目录地 址。
1.2.5二级页表地址转换
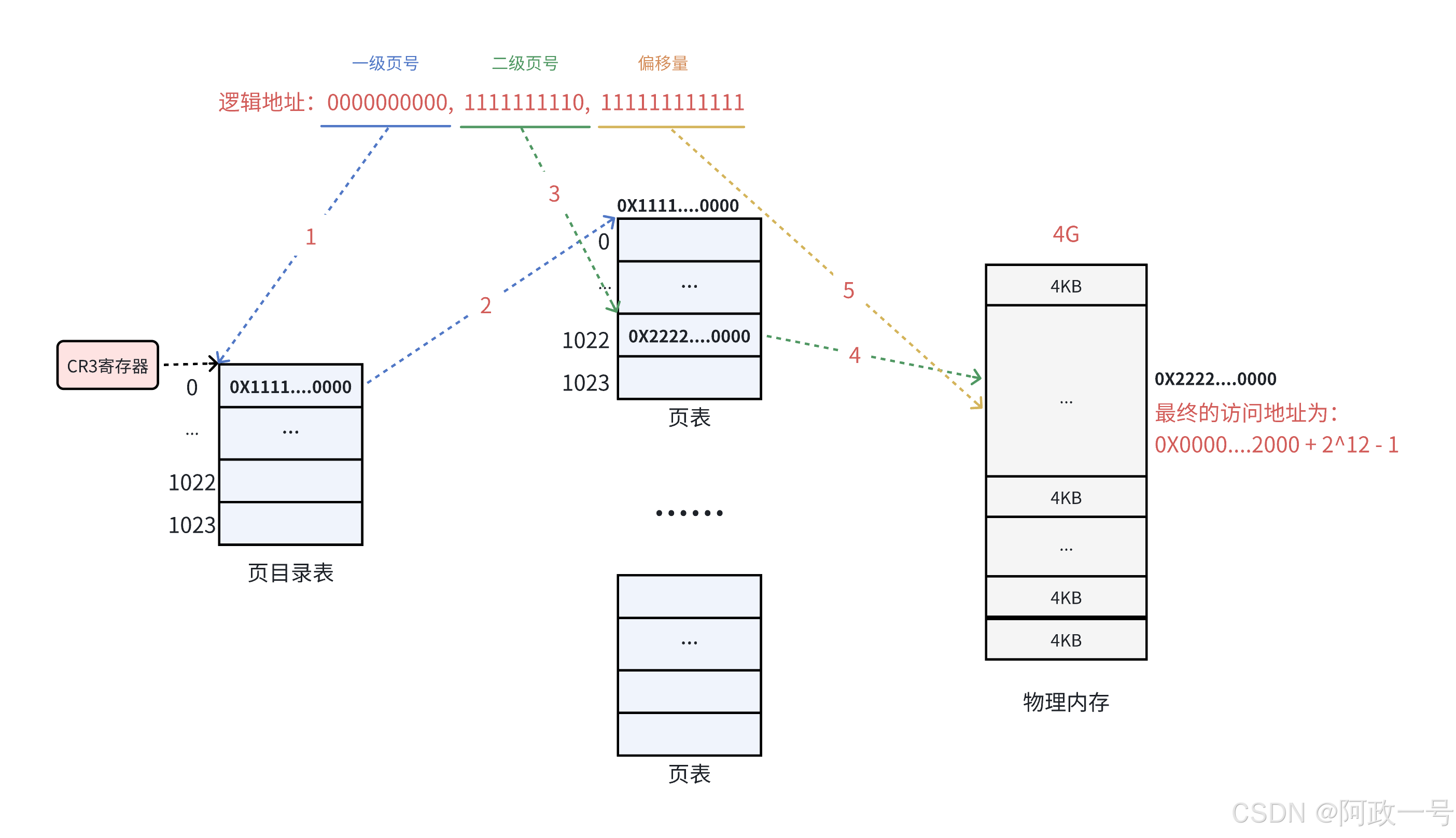
1. 在32位处理器中,采用4KB的页大小,则虚拟地址中低12位为页偏移,剩下高20位给页表,分成两级,每个级别占10个bit(10+10)。
2. CR3 寄存器 读取页目录起始地址,再根据一级页号查页目录表,找到下一级页表在物理内存中 存放位置。
3. 根据二级页号查表,找到最终想要访问的内存块号。
4. 结合页内偏移量得到物理地址。
5. 注:一个物理页的地址一定是 4KB 对齐的(最后的 12 位全部为 0 )(假如我们有物理地址,把物理地址的后12位全部清0,那么前面的地址就是页框的地址,这个数字除以4kb就是struct page mem[1048576]的数组下标,此时就可以找到page,page结构体里有virtual,此时可以找到虚拟地址),所以其实只需要记录物理页地址的高20位即可。
6. 以上其实就是 MMU 的工作流程。MMU(Memory Manage Unit)是一种硬件电路,其速度很快, 主要工作是进行内存管理,地址转换只是它承接的业务之一。
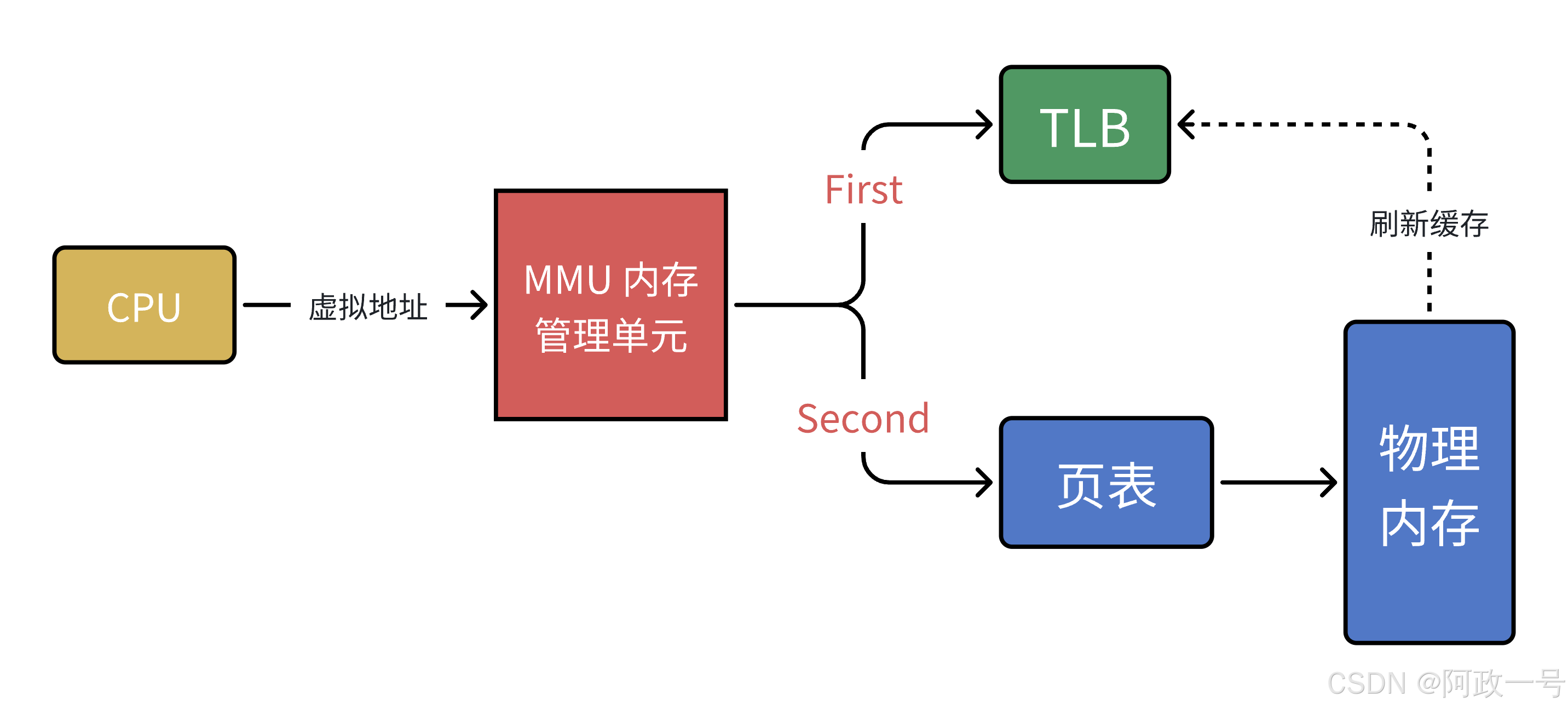
 单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双 刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。 有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。
单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双 刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。 有没有提升效率的办法呢?计算机科学中的所有问题,都可以通过添加⼀个中间层来解决。
MMU 引入 了新武器,江湖⼈称快表的 TLB (其实,就是缓存) 当 CPU 给 MMU 传新虚拟地址之后, MMU 先去问 TLB 那边有没有,如果有就直接拿到物理地址发到 总线给内存,齐活。
但 TLB 容量比较小,难免发生 Cache Miss ,这时候 MMU 还有保底的老武器页表,在页表中找到之后 MMU 除了把地址发到总线传给内存,还把这条映射关系给到TLB,让它记录一下刷新缓存。
假如申请一段空间,或者缺页中断,写时拷贝等等,先查找哪个页没有被用,申请这个内存,因为

查找数组的下标就可以找到page,找到物理页框的地址。

![]()
1.3线程的优点
• 创建一个新线程的代价要比创建一个新进程小得多
• 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
◦ 最主要的区别是线程的切换虚拟内存空间依然是相同的,但是进程切换是不同的。这两种上 下文切换的处理都是通过操作系统内核来完成的。内核的这种切换过程伴随的最显著的性能 损耗是将寄存器中的内容切换出。(切换完还是指向同一个进程地址空间,页表之间的映射还是不变,CR3寄存器不用变)
◦ 另外一个隐藏的损耗是上下文的切换会扰乱处理器的缓存机制。简单的说,一旦去切换上下文,处理器中所有已经缓存的内存地址一瞬间都作废了。还有一个显著的区别是当你改变虚 拟内存空间的时候,处理的页表缓冲 TLB (快表)会被全部刷新,这将导致内存的访问在一段时间内相当的低效。但是在线程的切换中,不会出现这个问题,当然还有硬件cache。(进程切换,会导致TLB,cache失效,需要重新缓存)
• 线程占用的资源要比进程少很
• 能充分利用多处理器的可并行数量
• 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
• 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
• I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
二.进程VS线程
• 进程是资源分配的基本单位
• 线程是调度的基本单位
• 线程共享进程数据,但也拥有自己的一部分数据:
◦ 线程ID
◦ ⼀组寄存器,线程的上下文数据(线程可以被独立调度)
◦ 栈
◦ errno
◦ 信号屏蔽字
◦ 调度优先级
三.Linux线程控制
3.1POSIX线程库
• 与线程有关的函数构成了一个完整的系列,绝大多数函数的名字都是以“pthread_”打头的
• 要使用这些函数库,要通过引入头文件pthread.h
• 链接这些线程函数库时要使用编译器命令的“-lpthread”选项
3.2创建线程


简单的代码了解pthread_create:
#include<iostream>
#include<pthread.h>
#include<unistd.h>
#include<string>void *threadrun(void *args)
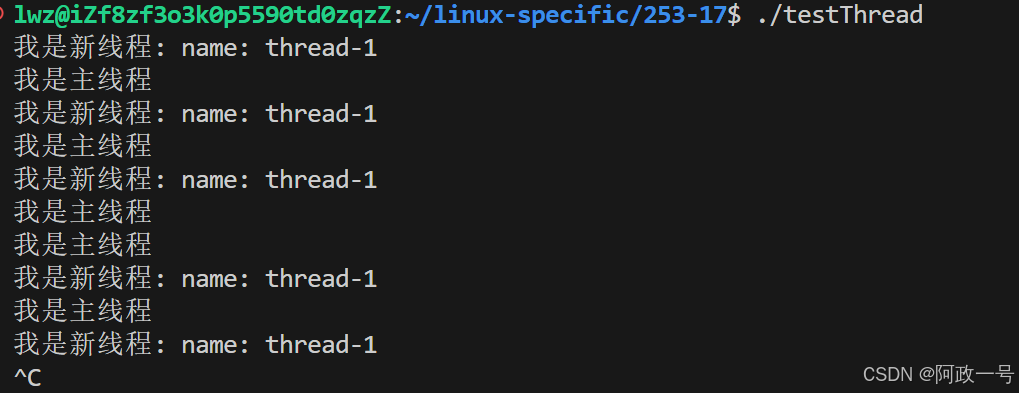
{std::string name = (const char*)args;while(true){std::cout<<"我是新线程: name: "<<name<<std::endl;sleep(1);}
}int main()
{pthread_t tid;pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");while(true){std::cout<<"我是主线程"<<std::endl;sleep(1);}return 0;
}这里需要注意的是在进行编译的时候要带上-lpthread:

之前在动静态库说过,需要找头文件(-I),需要路径(-L),还要指明哪个库(-l)。
这里前两个都可以找到:
路径:
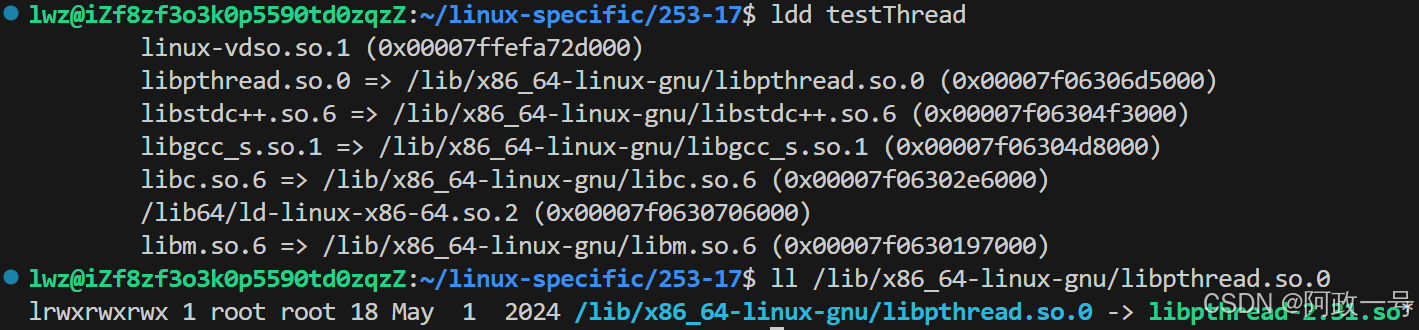
头文件:

所以这里就只是指明是哪个库就行了(-lpthread)。
打印出:
这里的-l是指明库名的,因为OS会在系统找库。
pthread库是个什么东西
Linux系统不会存在真正意义上的线程,只不过是用轻量级进程模拟的。在OS中只有轻量级进程。所以Linux 只会提供创建轻量级进程的系统调用。而pthread库就是把轻量级进程封装起来,给用户提供一批创建线程的接口。Linux的线程实现,是在用户层实现的,我们称之为用户级线程。pthread就是原生线程库
所以我把库的链接放开会报错:

而C++11的多线程,在Linux下本质是封装了pthread库!!
tid???
ps -aL查看:
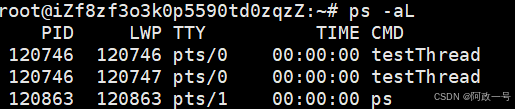
lwp就是轻量级进程的缩写 。
注意lwp是跟轻量级进程相关的,不是tid

实际上就是等待线程:
#include<iostream>
#include<unistd.h>
#include<pthread.h>
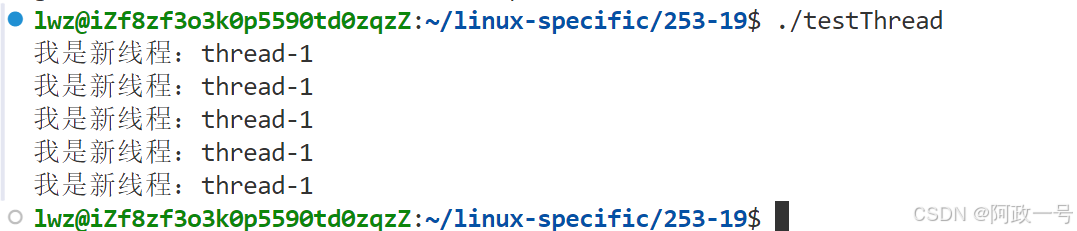
#include<string>void *threadrun(void* args)
{std::string name=static_cast<const char*> (args);int cnt=5;while(cnt--){std::cout<<"我是新线程:"<<name<<std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");(void)n;pthread_join(tid,nullptr);return 0;
}
现在来探讨一下什么是tid,在主线程中可以带上这样一个函数,查看我们线程带出来的id值:

实际上就是用16进制打印出来id值。

再来一个函数,查看我当前线程的id:这个是在线程中用

#include<iostream>
#include<unistd.h>
#include<pthread.h>
#include<string>void showtid(pthread_t &tid)
{printf("tid: 0x%lx\n",tid);
}std::string Format(pthread_t tid)
{char id[64];snprintf(id,sizeof(id),"0x%lx",tid);return id;
}void *threadrun(void* args)
{std::string name=static_cast<const char*> (args);pthread_t tid = pthread_self();int cnt=5;while(cnt--){std::cout<<"我是新线程:"<<name<<Format(tid)<<std::endl;sleep(1);}return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,threadrun,(void*)"thread-1");(void)n;showtid(tid);pthread_join(tid,nullptr);return 0;
}此时的主线程和线程获得的id是相同的:
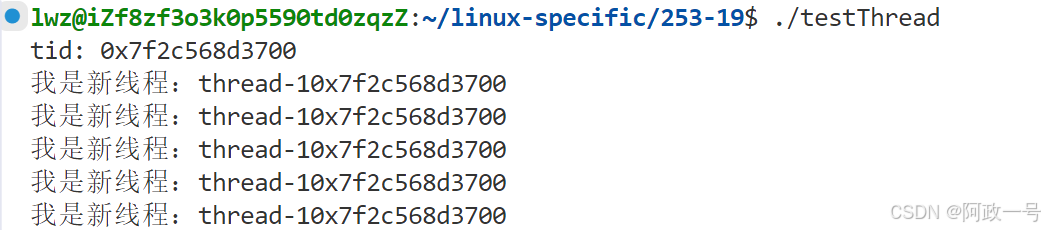
现在我让主线程也获取自己的线程id,看一看新线程和主线程的差别:


返回值
注意是二级指针:
![]()
相当于retval是一个输出型参数,这里使用的话要用二级指针。
新线程还是上面的线程,返回是100.

注意:
这里的线程没有异常的处理,还记得进程的异常处理,低7位是信号,然后一位是core dump标志,剩下的退出码。这里确没有,是因为线程退出,整个都结束,没有意义。
3.3pthread_create参数可以是任意类型
说的是第四个参数,因为参数类型是void*。这里就用两个类来实现
class Task
{
public:Task(int a,int b):_a(a),_b(b){}~Task(){}int Execute(){return _a+_b;}
private:int _a;int _b;
};class Result
{
public:Result(int result):_result(result){}~Result(){}int GetResult(){return _result;}
private:int _result;
};void *pthreadrun(void* args)
{Task* t = static_cast<Task*> (args);//强转// int ret = t->Execute();// Result* res = new Result(ret);Result* res = new Result(t->Execute());//在创建一个对象,作为退出码return res;
}int main()
{pthread_t tid;Task* t = new Task(10,20);///新建一个对象,创建在对堆上pthread_create(&tid,nullptr,pthreadrun,t);//创建新线程Result* ret=nullptr;//ret作为经过新线程后的输出结果pthread_join(tid,(void**)&ret);//等待新线程结束,因为要修改ret,所以要使用二级指针int n=ret->GetResult();std::cout<<"新线程结束,值为:"<<n<<std::endl;delete t;delete ret;return 0;
}打印出:

3.4线程终止
1. 从线程函数return。这种方法对主线程不适用,从main函数return相当于调用exit。
2. 线程可以调用pthread_exit终止自己。
3. 一个线程可以调用pthread_cancel止同一进程中的另一个线程。
注意:不要用exit终止新线程,exit是用来终止进程的。
return我们常用就不说。
pthread_exit:

void *pthreadrun(void* args)
{Task* t = static_cast<Task*> (args);//强转// int ret = t->Execute();// Result* res = new Result(ret);Result* res = new Result(t->Execute());//在创建一个对象,作为退出码//return res;pthread_exit(res);
}作用等价于return
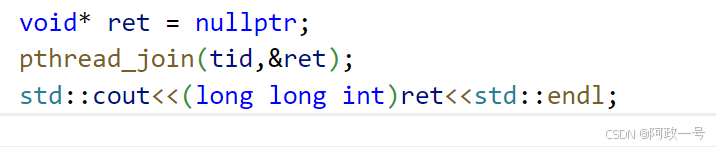
pthread_cancel:

执行下面的代码:
使用pthread_cancle取消新线程 ,这里拿到的ret 是-1??


其实就是一个宏值。
注意::
pthread_exit或者return返回的指针所指向的内存单元必须是全局的或者是用malloc分配的, 不能在线程函数的栈上分配,因为当其它线程得到这个返回指针时线程函数已经退出了。pthread_cancel取消的时候,新线程一定要启动了。
3.5分离线程
• 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
• 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
这个函数:

void* pthreadrun(void* args)
{std::string name = static_cast<char*>(args);std::cout<<"我是新线程,name: "<<name<<std::endl;return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,pthreadrun,(void*)"thread-1");pthread_detach(tid);//分离if(n!=0){std::cout<<"create thread error"<<std::endl;return 1;}int num = pthread_join(tid,nullptr);if(num==0){std::cout<<"wait success"<<std::endl;}else{std::cout<<"wait failed"<<std::endl;}return 0;
}分离成功,这里的等待就没有了意义:

因为有一个细节的点,这里再重新发一遍,子进程也可以自己直接退出:
void* pthreadrun(void* args)
{pthread_detach(pthread_self());std::string name = static_cast<char*>(args);std::cout<<"我是新线程,name: "<<name<<std::endl;return nullptr;
}int main()
{pthread_t tid;int n = pthread_create(&tid,nullptr,pthreadrun,(void*)"thread-1");//pthread_detach(tid);//分离if(n!=0){std::cout<<"create thread error"<<std::endl;return 1;}sleep(1);很重要,要让线程先分离,再等待int num = pthread_join(tid,nullptr);if(num==0){std::cout<<"wait success"<<std::endl;}else{std::cout<<"wait failed"<<std::endl;}return 0;
}joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
四.线程ID及进程地址空间布局
• pthread_create函数会产生一个线程ID,存放在第一个参数指向的地址中。该线程ID和前面说的 线程ID不是一回事。
• 前面讲的线程ID属于进程调度的范畴。因为线程是轻量级进程,是操作系统调度器的最小单位, 所以需要一个数值来唯一表示该线程。
• pthread_create函数第一个参数指向一个虚拟内存单元,该内存单元的地址即为新创建线程的线 程ID,属于NPTL线程库的范畴。线程库的后续操作,就是根据该线程ID来操作线程的。
• 线程库NPTL提供了pthread_self函数,可以获得线程自身的ID
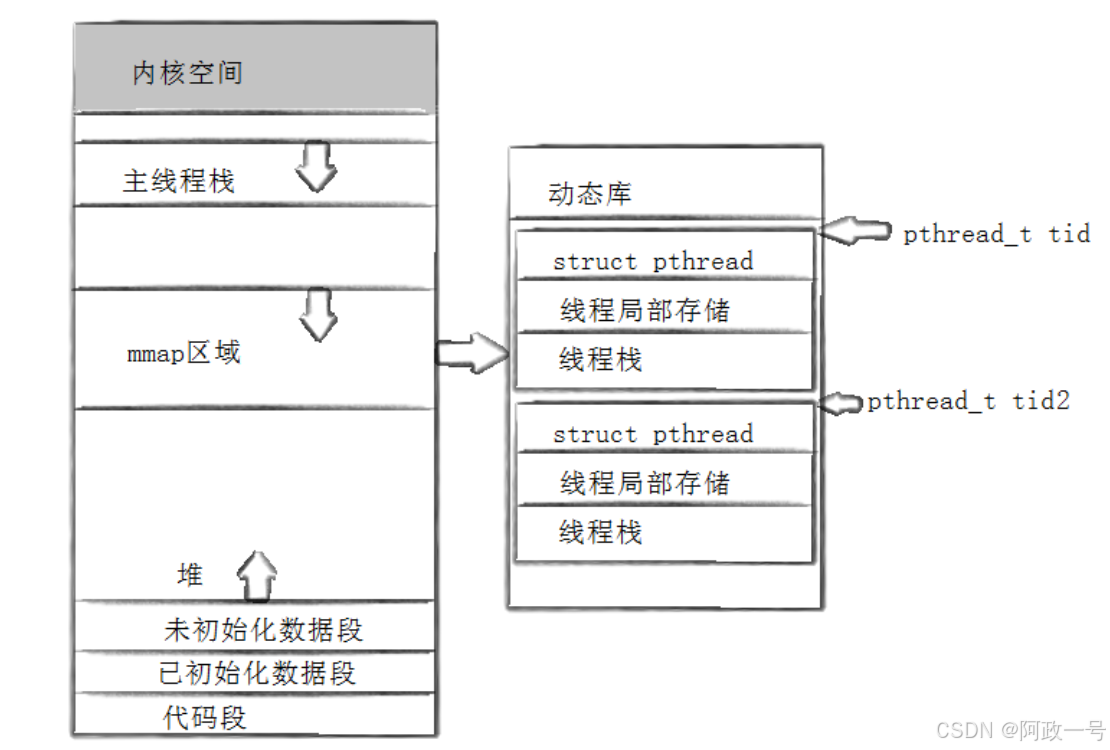
对于Linux目前实现的NPTL实现而言,pthread_t类 型的线程ID,本质就是一个进程地址空间上的一个地址。
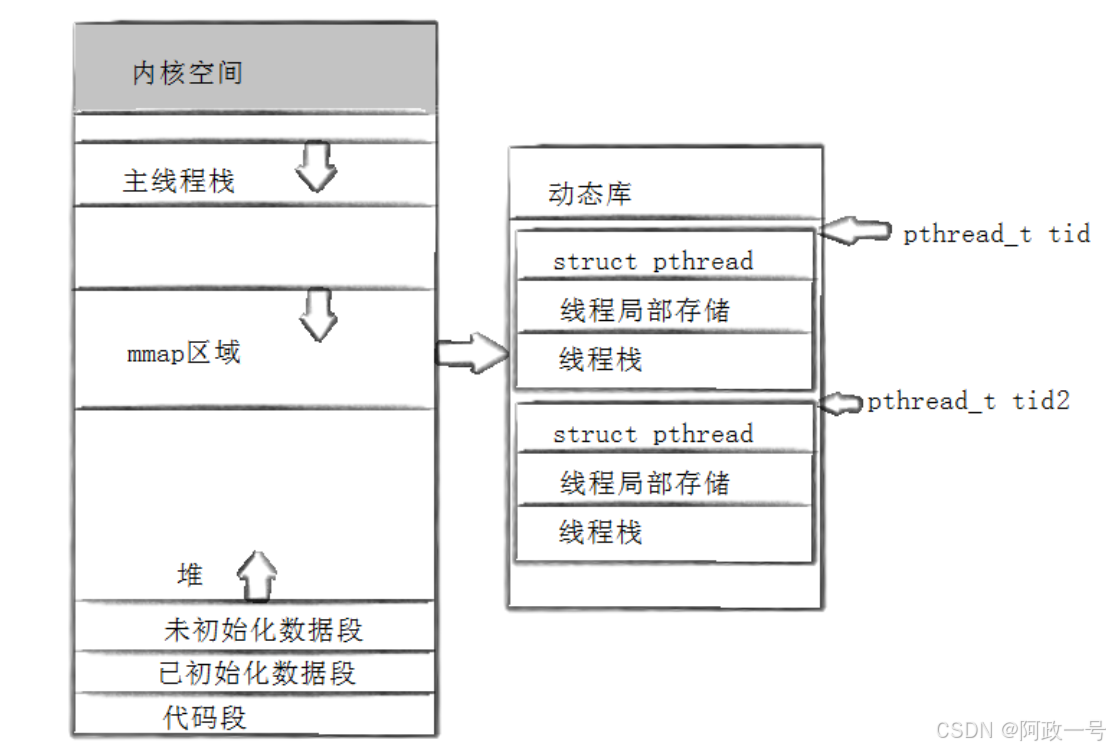
pthread_create在库中创建线程控制的管理块,要在内核中创建轻量级进程。
4.1部分源码
在源码中:
nptl/pthread_create.c:
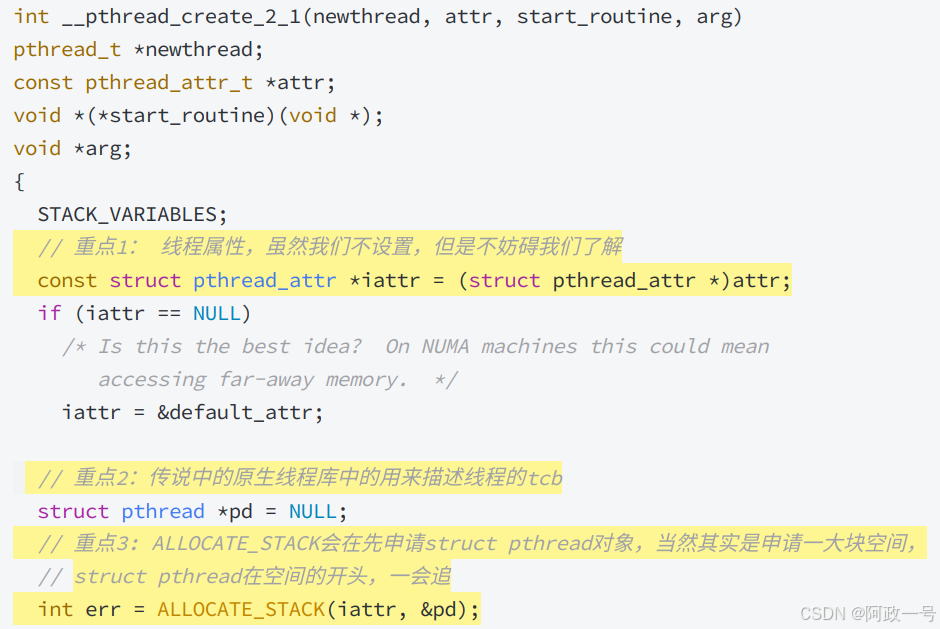
2其实就是上面第一个图的struct pthread。重点是3,会先申请一大块空间,struct pthread在开头的位置。 (这里是申请空间,在库中创建线程控制的管理块)
在struct pthread结构体中:
 其实就是lwp。
其实就是lwp。
我们在使用pthread_create的时候,第三个参数是让我们自定义函数,这个函数的返回的其实就是下面图中的result,类型是void*。用pthread_join可以获取,第二个参数是输出型参数所以要传二级指针.


nptl/pthread_create.c:
看了部分的struct pthread,下面堆pd指针的修改也就可以理解了:

下面的newthread就是我们pthread_create传入的第一个参数 ,要对其进行修改,得到的就是线程控制块地址:
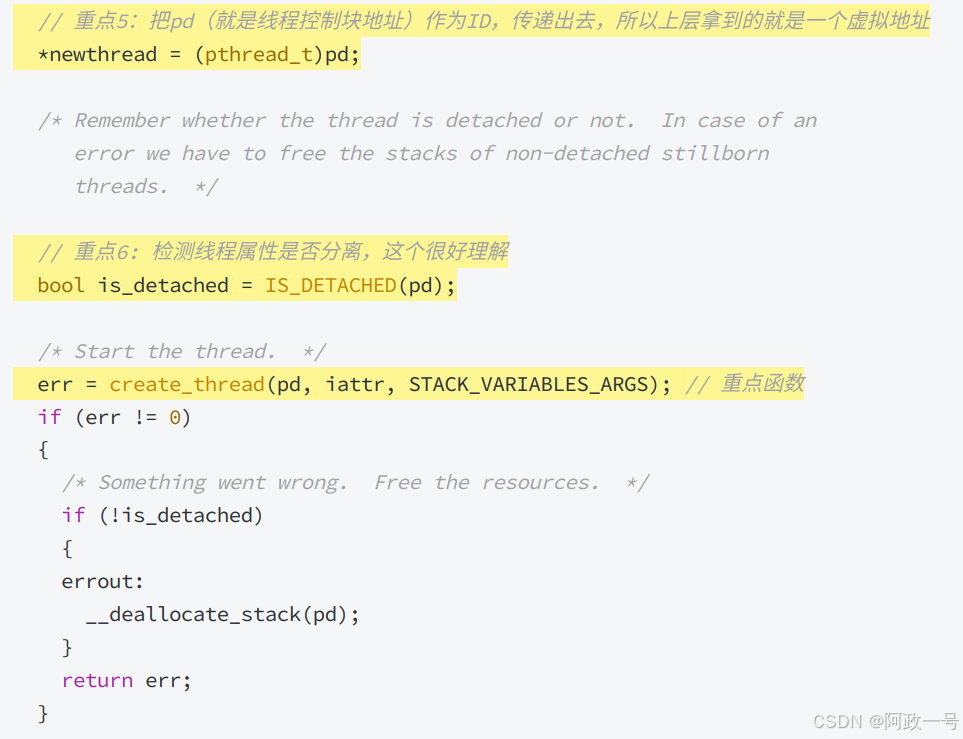
create_thread创建线程:




 所以,在创建线程的时候,其实就是在pthread库内部,创建好描述线程的结构体对象,填充属性。第二步就是调用clone,让内核创建轻量级进程,并执行传入的回调函数和参数 。 其实,库提供的无非就是未来操作线程的API,通过属性设置线程的优先级之类,而真正调度的过程,还是内核来的。 但是如果我们自己在上层,设计一些让线程暂停出让CPU,然后我们上次自定义队列,让线程的tcb 进行排队那么我们其实也可以基于内核,在用户层实现线程的调度,很多更高级的语言,可能会做这个工作。
所以,在创建线程的时候,其实就是在pthread库内部,创建好描述线程的结构体对象,填充属性。第二步就是调用clone,让内核创建轻量级进程,并执行传入的回调函数和参数 。 其实,库提供的无非就是未来操作线程的API,通过属性设置线程的优先级之类,而真正调度的过程,还是内核来的。 但是如果我们自己在上层,设计一些让线程暂停出让CPU,然后我们上次自定义队列,让线程的tcb 进行排队那么我们其实也可以基于内核,在用户层实现线程的调度,很多更高级的语言,可能会做这个工作。
clone就是创建轻量级进程,可以用AI测试一下。
pthread库,原生级线程库实际上就是创建一段空间(充当我们的独立栈结构),模拟线程,最本质还是对轻量级进程的封装。
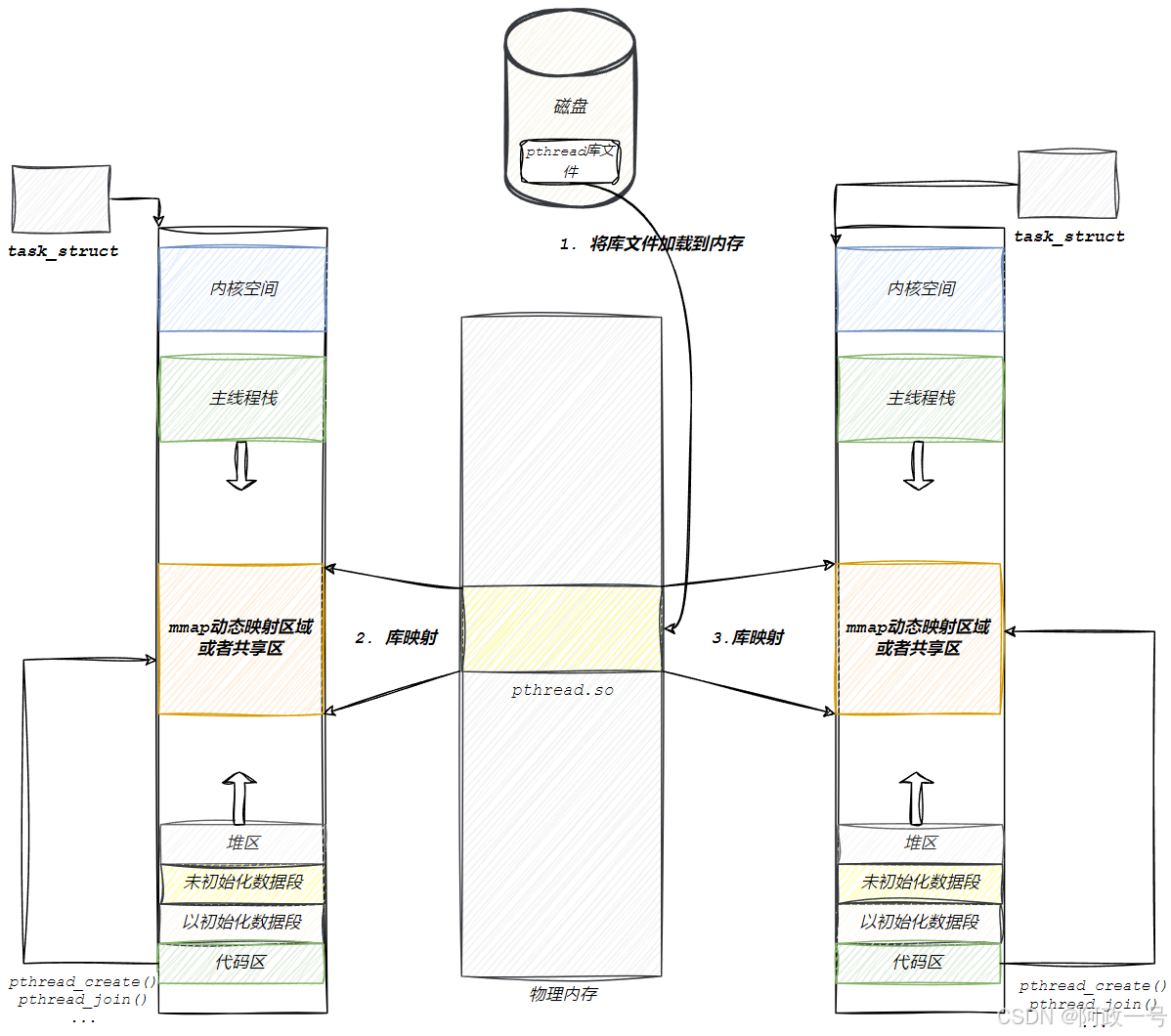
4.2线程栈
虽然 Linux 将线程和进程不加区分的统一到了 task_struct ,但是对待其地址空间的 stack 还是 有些区别的
• 对于Linux进程或者说主线程,简单理解就是main函数的栈空间,在fork的时候,实际上就是复 制了父亲的 stack 空间地址,然后写时拷贝(cow)以及动态增长。如果扩充超出该上限则栈溢出 会报段错误(发送段错误信号给该进程)。进程栈是唯一可以访问未映射页而不一定会发生段错误--超出扩充上限才报。
• 然而对于主线程生成的子线程而言,其 stack 将不再是向下生生长的,而是事先固定下来的。线 程栈一般是调用glibc/uclibc等的 pthread 库接口 pthread_create 创建的线程,在文件映射区(或称之为共享区)。其中使用 mmap 系统调用,这个可以从 glibc 的 nptl/allocatestack.c 中的 allocate_stack 函数中看到:

此调用中的 size 参数的获取很是复杂,你可以手工传入stack的大小,也可以使用默认的,一般而言就是默认的 8M 。这些都不重要,重要的是,这种stack不能动态增长,一旦用尽就没了,这是和生成进程的fork不同的地⽅。在glibc中通过mmap得到了stack之后,底层将调用 sys_clone 系 统调用:
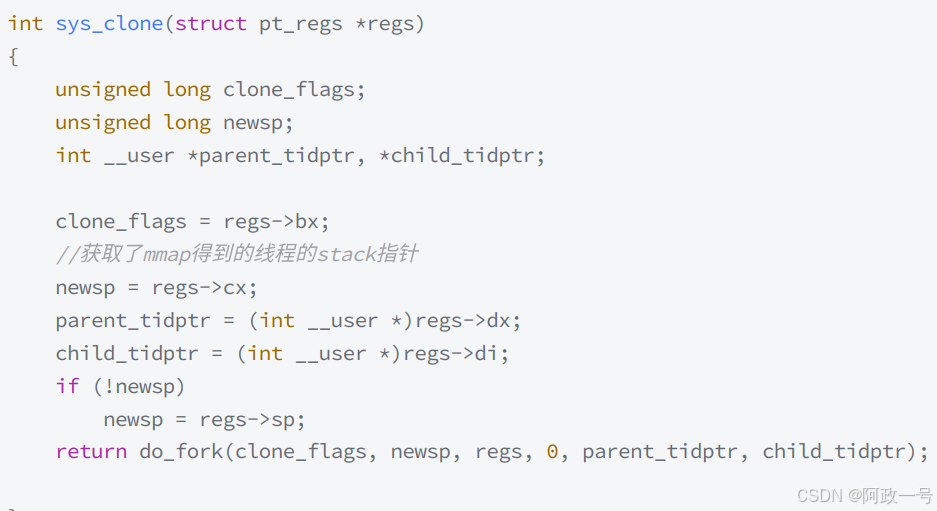 对于子线程的 stack ,它其实是在进程的地址空间中map出来的一块内存区域,原则上是线程私有的,但是同一个进程的所有线程生成的时候,是会浅拷贝生成者的 task_struct 的很多 字段,如果愿意,其它线程也还是可以访问到的。
对于子线程的 stack ,它其实是在进程的地址空间中map出来的一块内存区域,原则上是线程私有的,但是同一个进程的所有线程生成的时候,是会浅拷贝生成者的 task_struct 的很多 字段,如果愿意,其它线程也还是可以访问到的。
五.线程封装
#ifndef _THREAD_H_
#define _THREAD_H_#include <iostream>
#include <string>
#include <pthread.h>
#include <cstdio>
#include <cstring>
#include <functional>
#include <unistd.h>namespace ThreadModlue
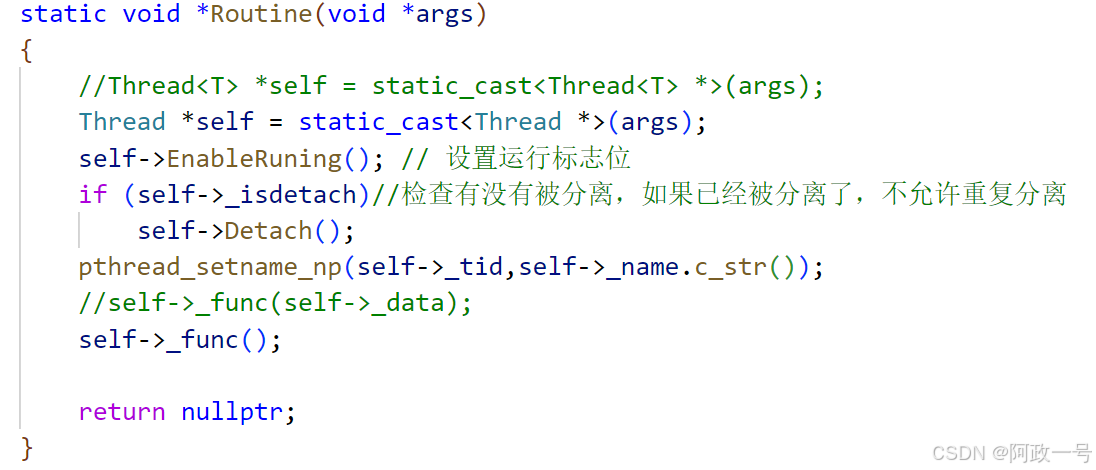
{static uint32_t number = 1;class Thread{using func_t = std::function<void()>;private:void EnableRuning(){_isruning = true;}void EnableDetach(){std::cout<<"线程被分离"<<std::endl;_isdetach = true;}static void *Routine(void *args){Thread *self = static_cast<Thread *>(args);self->EnableRuning(); // 设置运行标志位if (self->_isdetach)//检查有没有被分离,如果已经被分离了,不允许重复分离self->Detach();self->_func();return nullptr;}public:Thread(func_t func): _tid(0), _isdetach(false), _isruning(false), res(nullptr), _func(func){_name = "Thread-" + std::to_string(number++);}void Detach(){if (_isdetach)//这里是为了不让重复分离return;if (_isruning)//如果正在运行就调用phread_detach来分离pthread_detach(_tid);EnableDetach();}bool Start(){if (_isruning) // 不让重复启动return false;int n = pthread_create(&_tid, nullptr, Routine, this); // 创建线程,传this指针,为了在类内用我们外部定义的方法if (n != 0){std::cout << "create thread error: " << strerror(n) << std::endl;return false;}else{std::cout << "start success" << std::endl;return true;}}bool Stop(){if (_isruning){int n = pthread_cancel(_tid);if (n != 0){std::cout << "stop thread error: " << strerror(n) << std::endl;return false;}else{_isruning = false;std::cout << _name << "stop success" << std::endl;return true;}}return false;}void Join(){if (_isdetach){std::cout<<"线程被分离"<<std::endl;return;}int n = pthread_join(_tid, &res);if (n != 0){std::cout << "join thread error: " << strerror(n) << std::endl;return;}else{std::cout << "join success" << std::endl;}}~Thread(){}private:pthread_t _tid;std::string _name;bool _isdetach;bool _isruning;void *res;func_t _func;};
}#endif#include"Thread.hpp"using namespace ThreadModlue;int main()
{Thread t([](){while (true){std::cout<<"我是新线程"<<std::endl;sleep(1);}});//t.Detach();t.Start();//t.Detach();sleep(5);t.Stop();sleep(5);t.Join();return 0;
}
线程的局部存储
下面是一个全局变量
__thread int count = 1;成功count就叫做线程的局部存储。有什么用?全局变量我又不想让其他的线程看到,线程的局部存储只能存储内置类型和部分指针。
也就是说这个count在不同的线程里是不同的变量。

这两个函数的原理其实就是线程局部存储,设置名字,方便debug。






